


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
На этом этапе осуществляется параметрическая адаптация предпочтительности тестовых заданий, которая заключается в том, что в процессе оценки качества заключений испытуемых осуществляется анализ вероятностей их правильных выводов и на основании этих характеристик принимается решение о действительной принадлежности каждого ЭФТК к заданию с конкретной мерой трудности.
Тестовые задания, на которые испытуемые с большой вероятностью (75% и более) дают правильные заключения, переносятся автоматически в банк для более простых тестовых ситуаций. Если такие ситуации встречаются в самых простых тестовых заданиях, то подобные ПДТЗ вообще исключаются из банка данных. При малой вероятности прагматически корректных выводов на определенные тестовые ситуации, последние переносятся программой принятия решения в банки более трудных заданий. Если подобная ситуация возникает в банке наиболее трудных ЭФТК, то последние также исключаются из банка тестовых утверждений и предъявляются преподавателю для корректировки содержания учебного материала или с целью изменения содержания этих заданий. Благодаря параметрической адаптации постепенно формируется прагматически корректный фонд ПДТЗ с устойчивыми показателями валидности.
На рис.6, схематично представлена структурная схема банка тестовых ситуаций, содержащая ЭФТК различной меры трудности. Стрелками показан «перенос» тестовых заданий по результатам анализа тестирующей системой заключений испытуемых с конкретными степенями обученности.
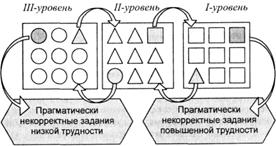
Обозначения: О – задание малой степени трудности;
Δ – задание средней меры трудности;
– задание повышенной категории трудности.
Рис. 6. Схематическая структура размещения ПДТЗ
С культурологической точки зрения испытуемый в процессе рациональной (промежуточной) аттестации изучается как субъект с потребностью в объективной самоидентификации, когда объективная и субъективная свобода проверки собственных достижений становится для него не самоцелью, а средством преодоления антропоцентризма, утверждения своей творческой сущности как соответствия обученности личности и трудности соответствующей области знания. Движители такого испытуемого — его собственная мотивация к установлению объективного уровня достижений и сопричастность к установлению качественного БТЗ. Здесь не только «обстоятельства творят» ПДТЗ, сколько испытуемые «творят обстоятельства».
Вычисление реального балла достижений стало возможным только после введения 2-го этапа КАТ, когда появилась возможность выделения испытуемым себя из образа себе подобных. Происходит как бы возвращение к античному человеку, но в индивидуальном его понимании. На философском языке это означает превращение тестируемого в субъекта деятельности и появление KCT3, на модификацию которой она направлена. Мотивами здесь выступают культурные потребности, изначально простые, но постепенно развивающиеся и усложняющиеся. В мотивационную характеристику субъекта включаются его достижения, которые в совокупности с осознанными потребностями создают необходимый и достаточный механизм для порождения рациональной деятельности. Эта деятельность характеризуется культурным, творческим, свободным и созидательным началами, когда испытуемый стоит перед выбором решения, перед возможностями направить свои устремления на утверждение себя в заданном классе достижений с учетом собственных целей, возможностей и желаний. Важным на этапе рациональной аттестации является то, что автоматическая корректировка меры трудности (или содержания ЭФТК) осуществляется при участии коллектива испытуемых из данного образа, когда субъекты выступают как носители культурной активности.
Предлагаемый авторами метод параметрической адаптации меры трудности ЭФТК выступает в системе КАТ на уровне межличностного воздействия. Это – совместная деятельность множества испытуемых, которую можно рассматривать как своеобразный социальный фактор культуры управления параметров БТЗ коллективом испытуемых. Этот эффект совместной деятельности индивидуален для каждого конкретного субъекта, в то время как результат уточнения системой мер трудностей ПДТЗ является следствием деятельности многих испытуемых, составляющих данный образ.
Поскольку КФТ ориентированы на проверку конкретного параметра личности, они должны быть предварительно проверены на педагогическую целесообразность и сертифицированы. Сертификация является одним из инструментов регулирования взаимоотношений между тестируемыми, разработчиками (экспертами) ПДТ и представляет собой «систему, располагающую собственными правилами процедуры и управления для проведения сертификации соответствия» [37].
В заключение к разделам III – V скажем следующее. Гипотетическими, правдоподобными были в свое время все фундаментальные законы и теории современного естествознания. Поэтому, сколь бы парадоксальными не казались нам правила конструирования тестовых материалов, одно из важнейших требований, которым они должны удовлетворять, состоит в их принципиальной проверяемости. Эта существенная особенность методологических правил отличает последние от всякого рода умозрительных построений, опровержением которых тестологам время от времени приходится заниматься. Цитируя Аристотеля в части введения им шкалы субъективной вероятности, , утверждая сказанное выше, подчеркивал, что «...правдоподобная невозможность всегда предпочтительнее неубедительной возможности».
Ниже представлены фрагменты Конструктора тестов ACT, отображающие процесс формирования композиции теста на примере БТЗ по учебной дисциплине «История».

В силу того, что стандартные строения тестовых суждений являются общепризнанными, они устанавливают границы всякому процессу отражения содержания фрагмента учебного материала в тестовое суждение, причем именно формы ПДТЗ определяют условие его представления a priori (они есть высшая трансцендентальная инстанция). При этом формы будут оставаться пустыми без их содержательного наполнения. В диалектической паре содержания и структуры фиксируются, с одной стороны, сущностное единство предмета или отношения и, с другой, способ его организации.
Форма определяет материальное выражение содержания ПДТЗ и определяется заданными стандартом образцами. Как элемент нормативной системы культуры стандарт устанавливает общепризнанную совокупность норм и требований к структуре ЭФТК. Представление смысла и значения тестовых ситуаций в стандартизированных формах способствует: узнаванию эмпирическими объектами их структуры; совершенствованию строения ЭФТК и повешению уровня их унификации.
Разделы, темы и подтемы учебных дисциплин тем совершеннее, чем больше понятий они включают. С другой стороны, понятие тем совершеннее, чем в большую систему тестовых суждений оно входит. Совершенные по Шлейермахеру знания являются специфицируемыми и осуществляются благодаря их частичной координированности и частичной субординированности. Чем больше число различных фрагментов знания охватывается совершенными понятиями, тем оно выше по уровню иерархии. При этом каждое последующее в иерархии понятие может получать дефиницию лишь благодаря предыдущему. Важно то, что каждое понятие на любом уровне иерархии считается чем-то единым. Чем совершеннее понятие, тем более трудные тестовые ситуации могут быть из него образованы.
301 Структуризация и качественная спецификация ПДТ способствует проектированию валидной KCT3. Понятийные спецификации – один из основных документов на БТЗ, выполняемый обычно в виде дерева, в котором перечисляются названия разделов, тем, базовых понятий и т. п. с учетом их смысла и значения. Термин «базовый» подразумевает минимум входящих в него смысловых единиц минимальной трудности. Технологические спецификации определяет требования к удовлетворению высокоуровневого интерактивного человеко-машинного коммуникацирования, связанные с вводом, хранением и модификацией ПДТЗ, хранящихся в KCT3. Такой фактор, как хранение большого объема ЭФТК и информации для управления этими заданиями, является определяющим для выбора логической структуры базы данных.
Проверка качественных показателей KCT3 осуществляется в процессе верификации – путем сопоставления их с данными эксперимента. Эксперимент в отличие от научного наблюдения предполагает активное вмешательство позиционеров в ход КАТ с целью проведения научных исследований. Как и наблюдение, верификация носит качественный и количественный характер.
В первом случае участники компьютерного тестирования выясняют корректность установленных в процессе шкалирования уровней-интервалов обученности; во втором – осуществляют проверку механизма оценки свойств и поведения объектов нечисловой природы путем соотнесения изучаемых атрибутов KCT3 с поведением групп испытуемых с априорно известными значениями степени обученности. Эксперимент позволяет избавиться от субъективности количественных показателей ПДТЗ, установленных разработчиками и экспертами. Результатом эксперимента является коррекция меры трудности и смысла ЭФТК, генерируемых из KCT3.
Композиция ПДТ – ориентирующий элемент тестовых ситуаций в КФТ, придающий ей единство и целостность, соподчиняющий ПДТЗ друг другу и целому. Корректная композиция теста способствует развертыванию его содержания и нацелена на достижение достижимого результата. Гармонично спроектированный из KCT3 ПДТ не подчиняется сюжету, он его создает. Из принципа субстанциальной рациональности следует принцип формальной реальности, а из содержательной системы конкретной области знания – формальная структура БТЗ. Но не наоборот.
VII. ОПТИМАЛЬНАЯ ОЦЕНКА ДОСТИЖЕНИЙ
Применение критериально-ориентированных программно-дидактических тестовых заданий (ПДТЗ) к итоговой аттестации студентов высших учебных заведений в рамках coциосемиотического подхода можно рассматривать как процесс разбиения их на 2 класса: соответствующих и несоответствующих уровню учебных достижений (знаний, умений и навыков) установленных требованиями Государственных образовательных стандартов (ГОС). При этом необходимо:
· наличие инструментальной среды оценки УУД, основным элементом которой является банк тестовых заданий (БТЗ), включающая в себя ядро знаний по конкретной специальности;
· адаптация традиционной стратегии определения оценки к новой концепции определения достижений, когда в качестве партнеров асимметричных отношений друг к другу выступают тестируемые и квазисубъект (тестирующая программа);
· разработка неизменной (единой) шкалы оценки достижений студентов различных вузов.
Целью итоговой аттестации (ИА) является проверка соответствия УУД величине некоторого критерия, устанавливаемого с учетом оценки ядра знаний по каждой специальности. Поэтому мера трудности тестовых заданий, хранящихся в БТЗ, должна быть одинаковой для всей совокупности ПДТЗ.
Суть задачи оценки достижений тестируемых состоит в анализе качества их заключений на требования тестовых ситуаций и сравнении этих результатов с заранее выбранным критерием. Таким критерием может служить вероятностная числовая характеристика степени возможного отнесения поведения тестируемого к тому или иному классу обученности при определенных, могущих повторяться неограниченное число раз условиях проведения сеанса компьютерных тестовых испытаний.
Критериально-ориентированный ПДТ – это система ПДТЗ заданной меры трудности, позволяющая оценить уровень учебных достижений выпускников вуза относительно полного объема знаний, умений, навыков, которые должны быть усвоены тестируемыми в соответствии с требованиями ГОС.
Сущность ИА студентов старших курсов состоит в разделении их на 2 класса обученности с учетом величины заранее установленного критерия. Для отнесения к тому или иному классу тестируемый должен корректно выполнить заданное a priori количество ПДТЗ. Если респондент выполняет правильно установленное экспертами число заданий, то компьютерная программа относит его к классу аттестованных, в противном случае – к классу неаттестованных.
Гетерогенный ПДТ состоит из ПДТЗ, каждое из которых оценивает уровень достижений студента вуза по дисциплинам ГОС. Это позволяет установить результат достижений тестируемых не только по тесту в целом, но по различным учебным предметам. Содержательная валидность БТЗ и мера трудности ПДТЗ оценивается экспертами заранее. Количество заданий в тесте может быть фиксированным или определяться программой тестовых испытаний. В первом случае применяются классические процедуры оценивания результатов тестирования, обеспечивающие минимальную ошибку принятия решения при фиксированном количестве тестовых заданий (критерии Байеса, Неймана-Пирсона, минимакса), а во втором – применяются методы последовательного анализа, минимизирующие выборку наблюдений, т. е. количество предъявляемых студенту тестовых заданий при заданных неопределенностях принятия решений (критерий Вальда)[7].
Постановка задачи оптимальной оценки достижений
Базисным понятием для прикладной статистики является статистическая однородность объектов в наблюдаемых группах. Поведение тестируемых внутри однородной группы должно быть похожим в известном смысле друг на друга. Термин «похожесть» отражает близость, сходство результатов заключений индивидов в пространстве оценок. Будем считать, что респонденты, поведение которых предстоит определить при помощи ПДТ, представляет собой однородную совокупность. Подобное допущение возможно, если мы желаем на основании тестовых проверок разделить подобную группу тестируемых на аттестованных и неаттестованых. Индивидуальный успех испытуемого в данном случае не имеет принципиального значения. В исследуемом случае важна лишь обоснованность однородности группы респондентов, подлежащих ИА, когда к ней могут быть применены традиционные методы математической статистики.
До настоящего времени количественные методы анализа уровня обученности целеустремленных объектов разработаны недостаточно глубоко. В связи с этим возникает потребность создания математической модели оценки УУД тестируемых и разработки на ее основе автоматизированной программы, которая с заданной верностью оценивала бы степень их обученности.
При наличии БТЗ программно-дидактические тестовые задания предъявляются тестируемым случайно. Это обстоятельство само по себе не препятствует формированию истинного суждения о степени обученности индивида. Наличие же пробелов в освоении ядра знаний учебного материала приводит к тому, что выводы пропонента не всегда тождественны требованиям ПДТЗ. Все же и в этих условиях возможно поставить вопрос о разработке программы оценки УУД, которая наилучшим (оптимальным) образом обработает поступающие на вход автоматизированной системы тестовых испытаний заключения на требования ПДТЗ и обеспечит предельно достижимую верность установления соответствия исходного уровня обученности каждого конкретного индивида требованиям ГОС. Программа, обеспечивающая предельно допустимую верность оценки учебных достижений телеологических объектов, называется оптимальной.
Возникают вопросы: как определить степень верности процесса стандартизированной компьютерной дидактической оценки (СКДО), что должно служить критерием этой верности и, соответственно, оптимальности программы анализа поведения тестируемых?
Такие критерии, основанные на учете вероятностных закономерностей, присущих источнику ПДТЗ и поведению тестируемых, называются статистическими критериями оценки. Если статистический критерий обработки заключений целеустремленных объектов выбран, то оказывается возможным построить алгоритм работы оценивающего устройства компьютерной системы тестовых испытаний, т. е. указать правило принятия решения о поведении индивида на основе обработки его заключений и наметить пути его программной реализации.
Рассмотрим задачу оценки УУД тестируемых (например, выпускников – студентов старших курсов вузов) как задачу различения статистических гипотез.
Пусть на вход системы компьютерного тестирования поступают реализации заключений респондентов в виде корректных (1) или ошибочных (0) выводов. На интервале анализа (сеанса тестирования) в оценивающем устройстве будет зафиксирована случайная последовательность нулей и единиц, определяющая качество заключений конкретного индивида. В этом случае компьютерная программа должна выбрать одну из двух возможных взаимоисключающих (альтернативных) гипотез:
· УУД тестируемого отвечает требованиям ГОС;
· УУД студента не соответствует требованиям ГОС.
Совокупность всех возможных реализаций представим в виде последовательностей Z(n), которые можно геометрически интерпретировать точками в n-мерном пространстве наблюдений Z.
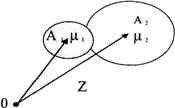
Рис. 1. Разбиение пространства наблюдений Z на два подпространства А1 и А2 , соответствующих одной из двух гипотез
Если алгоритм оценки поведения тестируемых выбран, то это означает, что каждой точке пространства приписывается одна и только одна из 2-х гипотез, т. е. индивид относится либо к классу освоивших учебную программу, либо к классу выпускников, уровень достижений которых не соответствует требованиям ГОС. Пространство, отображающее возможные реализации поведения тестируемых, окажется разбитым на две непересекающиеся области A1 и А2, каждая из которых соответствует принятию определенной гипотезы. При таком подходе различные системы оценки достижений отличаются друг от друга способом разбиения на области Аi, отображающего пространства Z (рис. 1)
Если бы реализация оценки достижений индивидов не содержала в себе случайных заключений на требования ПДТЗ, то возможные значения z(n) изображались бы в пространстве Z точками, принадлежащими только каждой из данных областей. При наличии неопределенных отклонений от среднего значения поведение тестируемого одного или другого класса обученности с номером i отклоняются от точки μi. Решение об отнесении поведения выпускника оказывается правильным лишь в тех случаях, когда случайные ошибки в заключениях тестируемого не выводят точку z(n) за пределы области Ai (i 1,2). В противном случае принимается неверное решение. Очевидно, изменяя границу между классами, можно влиять на вероятность ошибочного принятия решения. Например, если в разбиении, показанном на рис. 1, расширить область А2, изменив ее границы относительно области A1, то уменьшится вероятность ошибочного оценивания поведения индивида μ2 относительно тестируемого, УУД которого относится к области А1. Однако в этом случае возрастает вероятность ошибочного отнесения системой пропонента μ1 при оценивании поведения тестируемого из области А2·
Класс обученности респондентов определяется как множество объектов нечисловой природы, обладающих заданной общностью свойств. Так как в процессе сеанса тестирования имеются лишь сведения о конечном числе образцов – представителей данного класса (выборка конечна), то понятие категории, к которой должно быть отнесено поведение других респондентов является термином асимптотическим.
С геометрической точки зрения сходство поведения тестируемых должно выражаться в том, что точки (концы векторов) в пространстве наблюдений Z аттестованных и неаттестованных индивидов располагаются более или менее близко, а собственные области классов обученности в пространстве Z разнесены (рис.1).
Каждый класс удобно характеризовать посредством типичного представителя, который назовем образцом поведения выпускника данного класса. На рис.1 образцовые поведения выпускников двух классов изображены точками μ1 и μ2.
В итоге, относительное описание поведения студента состоит из выборки в виде N-разрядного кода, включающего в себя заключения индивида (0 или 1) на требования ПДТЗ. Взяв сумму значений признака этой выборки, можно установить оценку уровня достижений тестируемого. С точки зрения отнесения его к тому или иному классу достижений, существенно следующее: превышает или не превышает эта сумма величину некоторым образом сформированного оптимального порога обученности тестируемого.
Оценка на основе биноминального закона
Задача оценки уровня учебных достижений тестируемых предполагает следующую постановку. Тестируемому выдается n заданий, результаты выполнения которых могут быть представлены, как уже говорилось, в виде последовательной совокупности 0 и 1. Тогда каждому индивиду в результате проверки n заданий может быть поставлена в соответствие кодовая комбинация из нулей и единиц, например (0, 1, 1, 0, 1...1). Считается, что результаты выполнения заданий независимы, а вероятность выполнения задания или вероятность появления 1 в кодовой комбинации равна p и она не меняется от испытания к испытанию. Соответственно, вероятность появления 0 в кодовой комбинации, соответствующей последовательности заключений выпускника, равна q = 1 — р.
В качестве оценки уровня достижений респондентов будем определять вероятность выполнения m заданий в n независимых испытаниях. Такая схема испытаний называется схемой Бернулли, а вероятность выполнения т заданий из n предъявляемых определяется как
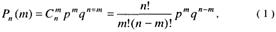
где p + q = 1, p > 0, q > 0.
Т. е. значения w = 0, 1, 2, ...,n распределены по биномиальному закону, где p – параметр биномиального распределения. Числовые характеристики этого распределения [15]:
· математическое ожидание


На основании локальной и интегральной теорем Муавра-Лапласса [18], можно утверждать, что для достаточно большого n и не очень малой вероятности p биномиальное распределение можно с заданной точностью заменять нормальным распределением с математическим ожиданием т = np и средним квадратическим отклонением δ = ![]() .
.
Рассмотрим задачу определения вероятности попадания случайной величины т выполненных заданий, распределенных по биномиальному закону, в заданный интервал [K1, K2], где K1 и K2 – целые числа.
По теореме сложения для несовместных событий, вероятность Pn (K1, К2) того, что событие т – решенных заданий появилось в N испытаниях от К1 до K2 раз, равна
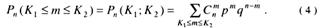
При больших n эта формула приводит к громоздким вычислениям. В этом случае на основании интегральной теоремы Муавра-Лапласа можно записать
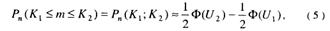
где
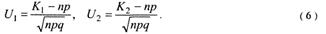
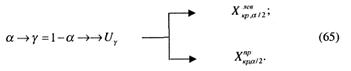
Откуда после некоторых преобразований получим
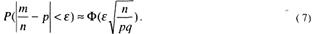
Здесь

Точечная оценка
Найдем выборочные характеристики случайной величины правильно выполненных заданий т, распределенной по биномиальному закону. Выборочной характеристикой, используемой в качестве приближенного значения неизвестной характеристики генеральной совокупности, является ее точечная оценка.
Для схемы испытаний Бернулли, на основе которой происходит анализ процесса тестирования, оценка вероятности выполнения т заданий, то есть определение приближенного значения ![]() вероятности p вычисляется как частота появления правильно выполненного задания среди всех предъявляемых ПДТЗ, т. е. частота появления 1 в кодовой комбинации из N разрядов. Тогда
вероятности p вычисляется как частота появления правильно выполненного задания среди всех предъявляемых ПДТЗ, т. е. частота появления 1 в кодовой комбинации из N разрядов. Тогда

где т – число правильно выполненных заданий теста;
n=N – количество заданий в тесте.
В [18] доказано, что ![]() – состоятельная, несмещенная и эффективная оценка вероятности р. Это же касается и дисперсии этой оценки, которая определяется как
– состоятельная, несмещенная и эффективная оценка вероятности р. Это же касается и дисперсии этой оценки, которая определяется как

Интервальная оценка
Из вычислений (9) и (10) точечной оценки числовой характеристики биномиального закона на основании результатов наблюдений следует, что величина ![]() является лишь приближенным ее значением. В силу несмещенности, состоятельности и эффективности этой оценки ясно, что для большего числа N ее точность приближения к истинному значению р бывает достаточной.
является лишь приближенным ее значением. В силу несмещенности, состоятельности и эффективности этой оценки ясно, что для большего числа N ее точность приближения к истинному значению р бывает достаточной.
Для выборок небольшого объема, т. е. по кодовой комбинации, полученной в результате проверки N заданий, находится точечная оценка ![]() неизвестной характеристики генеральной совокупности. Задавшись вероятностью γ , найдем такое число ε > 0, чтобы выполнялось соотношение
неизвестной характеристики генеральной совокупности. Задавшись вероятностью γ , найдем такое число ε > 0, чтобы выполнялось соотношение
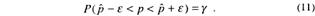
Напишем тождественное выражение

Из него видно, что абсолютная неопределенность оценки ![]() не превосходит величину ε с вероятностью γ. Тогда число ε является точностью оценки
не превосходит величину ε с вероятностью γ. Тогда число ε является точностью оценки ![]() . Обозначив p1 =
. Обозначив p1 = ![]() — ε, р2=
— ε, р2= ![]() + ε получим p1 и p2 , которые являются доверительными границами p, а интервал (p1, p2) ~ доверительным интервалом или интервальной оценкой характеристики р. Вероятность γ называется доверительной вероятностью или верностью интервальной оценки. Выражение (11) перепишем в виде
+ ε получим p1 и p2 , которые являются доверительными границами p, а интервал (p1, p2) ~ доверительным интервалом или интервальной оценкой характеристики р. Вероятность γ называется доверительной вероятностью или верностью интервальной оценки. Выражение (11) перепишем в виде

Соотношение (13) следует понимать так: «вероятность того, что интервал (p1, p2) накроет характеристику p, равна γ». Вероятность γ или надежность интервальной оценки принято выбирать равной 0.95, 0.99, 0.999. Тогда событие, состоящее в том, что интервал (p1, р2) накроет характеристику p, будет практически достоверным.
Решим следующую задачу: зададимся вероятностью γ и найдем числа p1 и p2 такие, чтобы выполнялось (13). Интервальную оценку построим для двух случаев: когда число испытаний Бернулли велико, т. е. число заданий теста N >30, а также для малого числа N<30. Так как выполнение и невыполнение задания тестируемым случайно, т. е. появление 1 или 0 в выборке непредсказуемо, то количество выполненных заданий т тоже случайно. В силу локальной и интегральной теорем Муавра-Лапласа при большом т и немалом значении вероятности p распределение т будет близко к нормальному с математическим ожиданием, равным Np, а дисперсией, равной Npq, т. е.

При делении т на постоянную величину N закон распределения не изменяется, а изменяются только его параметры. Поэтому при большом N распределение частоты ![]() так же как и распределение частот т, близко к нормальному закону, но с другими параметрами.
так же как и распределение частот т, близко к нормальному закону, но с другими параметрами.
Математическое ожидание становится равным
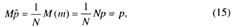
а дисперсия
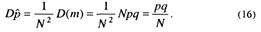
Таким образом, при большом числе испытаний N p распределено по нормальному закону и может быть представлено как

Откуда находим, что распределение величины 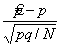 — подчиняется также нормальному закону, но с нулевым математическим ожиданием и единичной дисперсией, т. е.
— подчиняется также нормальному закону, но с нулевым математическим ожиданием и единичной дисперсией, т. е.

Далее, используя таблицы функции Лапласа, представленные в [6], найдем для заданной вероятности γ такое число U γ, при котором Ф(Uу)= γ, или, иначе, такое, что
P(|N(0,1)|< Uγ)=γ,
где Uγ – квантиль нормального распределения N(0,1).
Учитывая (18), получим
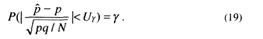
Неравенство, стоящее в скобках выражения (19), решим относительно p.
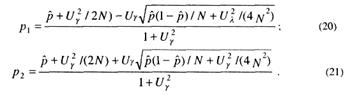
Отсюда после вычисления р1 и p2 по формулам (20) и (21), определим вероятность

В [18] показано, что при N≥ 100 зависимости (20) и (21) упрощаются:
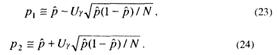
Теперь можно утверждать, что интервал (p1, р2) накроет неизвестную величину p с вероятностью γ, или, иначе, с вероятностью γ можно быть уверенным в том, что вычисленная по результатам испытаний Бернулли частота ![]() = т /N определяет значение неизвестной вероятности pс верностью
= т /N определяет значение неизвестной вероятности pс верностью

Тогда схема определения интервальной оценки будет такова.
Назначаем величину γ по табл. функций Лапласа определяем Uγ по формуле (25 ) находим ε .
В итоге, вычисляются
Пример: в тесте, состоящем из W=100 заданий, тестируемый решил m=78 заданий. Интервальную оценку определим по схеме (26) для γ =0.9. По табл. функций Лапласа из [6] для γ =0.9 определяем Uγ=l,643.
Используя зависимости (20) и (21), находим:
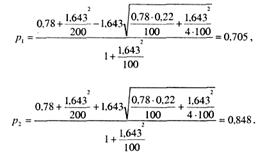
Следовательно, с надежностью 0,9 интервал (0,705, 0,848) накроет неизвестную вероятность р.
В случае, когда имеется малая выборка N, то необходимо пользоваться не приближенными формулами нормального закона управления, а точными зависимостями биноминального закона:
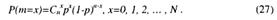
Зададимся вероятностью γ и найдем p1 и p2, чтобы
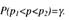
Можно показать (см. [18]), что при использовании закона (27) число p1 является решением уравнения
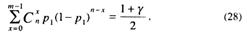
а число p2 – решением уравнения
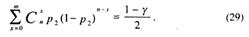
Отметим, что в (27) т – конкретное число положительных исходов испытаний Бернулли. В [6] существуют специальные таблицы, вычисленные на основе зависимостей (28) и (29), где по заданным n, n-m и γ определяют p1 и р2. ·
Определение минимального объема заданий для оценки параметра биномиального закона
Рассмотрим обратную задачу относительно той, которая решалась в предыдущем разделе. Определим объем выборки или количество тестовых заданий, которое позволяет оценить любой заранее неизвестный параметр p биномиального закона с заданной ε при требуемой надежности γ, т. e. задача состоит в том, чтобы найти такое N0, при котором N>N0:
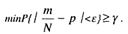
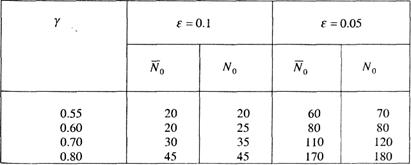
Решение этой задачи представлено в [32]. Минимальные значения объемов выборки ![]() , обеспечивающие оценивание параметров биномиального закона с заданной верностью ε и надежностью γ, и значения N0, для которых при W > N0 гарантируется заданная верность, приведены в табл. 1.
, обеспечивающие оценивание параметров биномиального закона с заданной верностью ε и надежностью γ, и значения N0, для которых при W > N0 гарантируется заданная верность, приведены в табл. 1.
Таблица 1
Оценка на основе нормального закона
Так как УУД тестируемых определяется суммой значений признака, присвоенных тестируемым на основе проверки заданий теста, то будем полагать, что распределение уровня обученности в обоих классах респондентов подчиняется нормальному (гауссовскому) закону. Теоретическим обоснованием этого утверждения является одна из центральных предельных теорем, согласно которой распределение среднего т независимых достижений тестируемых с уровнями обученности, распределенными по различным законам, но с конечными математическими ожиданиями и дисперсиями, при увеличении числа наблюдений в выборке (т. е. при п → ∞) приближается к нормальному.
Несмотря на то, что применение центральной предельной теоремы обусловлено большим количеством заданий в течение сеанса тестирования, распределение выборочного среднего стремится к нормальному даже при относительно небольших значениях n, если величина дисперсии какого-либо достижения индивида из данного класса обученности не является преобладающей и распределение достижений целеустремленных объектов не слишком отклоняется от нормального.
Тогда плотность распределения вероятностей учебных достижений выпускников в рассматриваемом случае описывается функциями вида
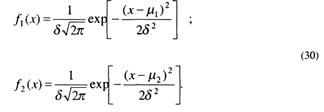
Здесь μ1, μ2 и δ – соответственно параметры, характеризующие центры распределений и их масштаб. Величина μ1 – среднее значение учебных достижений тестируемых, уровень которых не соответствует требованиям ГОС, величина μ2 – среднее значение учебных достижений тестируемых, уровень которых соответствует требованиям ГОС.
Считаем, что дисперсии нормальных распределений одинаковы и равны δ2.
Точечное оценивание
Пусть случайные величины Х1,Х2,...,Хn получаются из выборки объема n, случайно отобранной из однородной совокупности результатов тестирования.
Тогда среднее выборки или точечная оценка среднего значения учебных достижений тестируемых
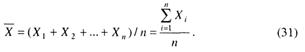
Если X – случайная величина, имеющая нормальный закон распределения Ν(μ, δ2), то оценка среднего ![]() распределена также по нормальному закону, но с параметрами Ν(μ, δ2 /n). Однако, если X – случайная величина не будет иметь нормального распределения, то с ростом n согласно центральной предельной теореме ее распределение будет стремиться к Ν(μ, δ2/n).
распределена также по нормальному закону, но с параметрами Ν(μ, δ2 /n). Однако, если X – случайная величина не будет иметь нормального распределения, то с ростом n согласно центральной предельной теореме ее распределение будет стремиться к Ν(μ, δ2/n).
В свою очередь, точечная оценка дисперсии определяется как

Интервальное оценивание
Найдем интервальную оценку среднего значения учебных достижений при известной дисперсии. Итак, Χ=Ν(μ,δ), где μ – математическое ожидание неизвестно, а δ2 – дисперсия известна. По наблюдениям Х1,Х2,...,Хn определяем точечную оценку μ согласно (31).Зададимся вероятностью γ и найдем такое число ε , при котором выполняется соотношение
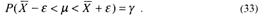
Пусть Х1,Х2,...,Хn – результаты n независимых наблюдений нормально распределенной случайной величины. Тогда величина 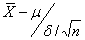 имеет нормальное распределение с нулевым математическим ожиданием и единичной дисперсией, т. е.
имеет нормальное распределение с нулевым математическим ожиданием и единичной дисперсией, т. е.
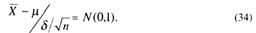
Теперь, воспользовавшись таблицами функций Лапласа, найдем для заданной γ число υγ такое, при котором Ф(Uγ)= γ ,

Учитывая (34), получим
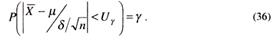
После несложных преобразований неравенства в (36) находим
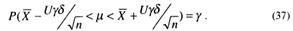
Сравнивая (37) и (33), заключаем, что

Теперь определим интервальную оценку среднего значения учебных достижений при неизвестной дисперсии. По наблюдениям Х1,Х2,...,Хn вычислим точечные оценки среднего ![]() и дисперсии
и дисперсии ![]() по формулам (31) и (32). Зададимся доверительной вероятностью γ и найдем такое число ε , при котором выполняется соотношение
по формулам (31) и (32). Зададимся доверительной вероятностью γ и найдем такое число ε , при котором выполняется соотношение
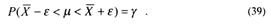
Пусть далее Х1,Х2,...,Хn – результаты и независимых наблюдений нормально распределенной случайной величины, проводимых в одинаковых условиях. Тогда величина ![]() имеет распределение Стьюдента (или t-распределение) с (n-1)-й степенями свободы:
имеет распределение Стьюдента (или t-распределение) с (n-1)-й степенями свободы:
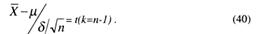
Воспользовавшись табл. из [6], найдем для заданной вероятности γ и числа k-n-1 значение tγ такое, при котором вероятность

Учитывая (40), получаем
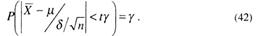
В итоге, после несложных преобразований (42) можно переписать как
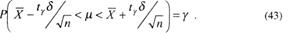
Сравнивая (43) и (39), находим

Пусть, например, определяется уровень достижений девяти выпускников. На основе результатов компьютерных тестовых испытаний установлено, что ![]() =10 и δ =2. Полагая, что уровень достижений тестируемых – нормально распределенная случайная величина, найдем доверительный интервал для неизвестного истинного среднего μ . При n-1=8 и γ = 0,95 из таблицы [6] находим ίγ =2.31. Применяя формулу (43), вычислим доверительный интервал. Согласно (43) он равен 10±2,31. В результате получен 95%-ный доверительный интервал (8,46; 11,54), в котором находится величина μ. Увеличивая число наблюдений можно сделать μ сколь угодно малым. Интервал, в котором с заданной вероятностью находится не менее требуемой доли учебных достижений тестируемых данного класса обученности, называется статистическим толерантным интервалом.
=10 и δ =2. Полагая, что уровень достижений тестируемых – нормально распределенная случайная величина, найдем доверительный интервал для неизвестного истинного среднего μ . При n-1=8 и γ = 0,95 из таблицы [6] находим ίγ =2.31. Применяя формулу (43), вычислим доверительный интервал. Согласно (43) он равен 10±2,31. В результате получен 95%-ный доверительный интервал (8,46; 11,54), в котором находится величина μ. Увеличивая число наблюдений можно сделать μ сколь угодно малым. Интервал, в котором с заданной вероятностью находится не менее требуемой доли учебных достижений тестируемых данного класса обученности, называется статистическим толерантным интервалом.
Определение минимального объема заданий
Если заданы абсолютная верность Δ вычисления среднего значения ![]() , относительная верность ε вычисления среднего квадратического отклонения
, относительная верность ε вычисления среднего квадратического отклонения ![]() и уровень значимости а, то минимальные объемы выборок могут быть определены с помощью приближенных формул [17]:
и уровень значимости а, то минимальные объемы выборок могут быть определены с помощью приближенных формул [17]:
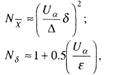
где Uα – квантиль уровня α стандартного нормального распределения;
δ – среднее квадратическое отклонение генеральной совокупности.
В приводимых ниже примерах примем α = 0.05 и α = 0,01. По таблицам [6] находим, что
U0.975 = -U0.025 = 1.96; U0.995 = - U0.005 = 2,576.
Значения точности ε как функции доверительной вероятности γ = l – α и объема выборки N приведены в табл.2. При заданной ε эта таблица может использоваться для определения объема выборки.
Например, если α =0,05, a ε =0,14, то необходимый объем выборки N для вычисления δ равен 100. По соответствующей формуле определим Nδ =l + 0.5(l,96/0.14)2 =99. Если α =0,05 , Δ=0,2, δ =3, то для оценки среднего значения X необходимо предъявить N![]() = 1,962 · 0,22 · 3 = 288; заданий, для оценки среднего квадратического отклонения δ при заданной относительной точности ε = 0,2 необходимо проверить
= 1,962 · 0,22 · 3 = 288; заданий, для оценки среднего квадратического отклонения δ при заданной относительной точности ε = 0,2 необходимо проверить 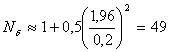 заданий.
заданий.
Таблица 2
|
N |
Значения ε при γ, равном | |||
|
0.99 |
0.95 |
0.90 |
0.80 | |
|
6 |
0.77 |
0.60 |
0.50 |
0.40 |
|
12 |
0.54 |
0.41 |
0.35 |
0.27 |
|
30 |
0.34 |
0.26 |
0.22 |
0.17 |
|
100 |
0.18 |
0.14 |
0.12 |
0.09 |
|
1000 |
0.06 |
0.04 |
0.04 |
0.13 |
Объем выборки, необходимый для построения интервальной оценки δ будем определять на основе табл. 3 [17]. Для этого необходимо, имея заданную относительную верность 100 ε % и значение Q= (l- α)/2, по табл.3 найти v, отвечающее выбранным ε и Q. Причем, следует учитывать, если истинное значение математического ожидания μ известно, то N=v, если же неизвестно, то N=v+1. Например, требуется построить доверительный интервал для δ с коэффициентом доверия 90% и относительной погрешностью 20%. Для этого случая Q=5%, а ε =0.2. По табл.3 находим ε=0.202 при v=160 и ε=0.190 при v=180. Линейной интерполяцией для ε=0,2 получим v=164. Если математическое ожидание неизвестно, то N=165.
Таблица 3
|
V |
Значения ε (%) npnQ, равном | |||
|
0.5 |
2.5 |
5.0 |
25 | |
|
1 |
446.94 |
70.52 |
30.26 |
2.61 |
|
2 |
31.51 |
11.07 |
6.64 |
1.20 |
|
3 |
12.38 |
5.58 |
3.71 |
0.84 |
|
5 |
5.38 |
2.93 |
2.11 |
0.57 |
|
7 |
3.53 |
2.08 |
1.55 |
0.46 |
|
10 |
2.42 |
1.51 |
1.16 |
0.36 |
|
13 |
1.89 |
1.22 |
1.95 |
0.31 |
|
15 |
1.67 |
1.10 |
0.86 |
0.29 |
|
20 |
1.32 |
0.89 |
0.70 |
0.24 |
|
25 |
1.11 |
0.76 |
0.61 |
0.21 |
|
30 |
0.97 |
0.67 |
0.54 |
0.19 |
|
40 |
0.79 |
0.56 |
0.45 |
0.16 |
|
50 |
0.68 |
0.49 |
0.39 |
0.14 |
|
60 |
0.61 |
0.43 |
0.35 |
0.13 |
|
70 |
0.55 |
0.39 |
0.32 |
0.12 |
|
80 |
0.51 |
0.37 |
0.30 |
0.11 |
|
90 |
0.47 |
0.34 |
0.28 |
0.10 |
|
100 |
0.44 |
0.32 |
0.26 |
0.10 |
|
120 |
0.40 |
0.29 |
0.24 |
0.09 |
|
140 |
0.36 |
0.26 |
0.22 |
0.08 |
|
160 |
0.34 |
0.25 |
0.20 |
0.078 |
|
180 |
0.31 |
0.23 |
0.19 |
0.074 |
|
200 |
0.29 |
0.22 |
0.18 |
0.070 |
|
240 |
0.26 |
0.20 |
0.16 |
0.064 |
|
300 |
0.24 |
0.17 |
0.14 |
0.057 |
Оценка на основе проверки статистических гипотез
Под статистической гипотезой понимают всякое высказывание о генеральной совокупности (случайной величине), которое проверяется по выборке, т. е. по результатам наблюдений. Для задачи оценки УУД тестируемых, под которой понимается вероятность правильного выполнения т заданий теста, статистической гипотезой являются следующие высказывания:
· если процесс тестирования представлен схемой Бернулли и вероятность p правильного выполнения задания неизвестна, выдвигается гипотеза о том, что p = p0 ; эта гипотеза проверяется на основе полученной выборки, т. е. на основе результатов проверки качества выполнения респондентом заданий теста;
· если считаем, что вероятность правильного выполнения заданий т является случайной величиной, распределенной no нормальному закону, причем тестируемые, аттестованные положительно, в среднем решают μ2 заданий, а аттестованные отрицательно, – μ1 задание, то выдвигается гипотеза в виде высказывания: математическое ожидание т равно μ1 ( или μ2).
В этой задаче, не располагая сведениями о всей генеральной совокупности, по определенным правилам на основе выборочных данных необходимо принять или не принять высказанную гипотезу. Процедура сопоставления высказанной гипотезы с выборочными данными называется проверкой гипотезы.
Этапы проверки гипотезы об оценке уровня достижений
Рассмотрим этапы проверки гипотезы.
Этап 1. Располагая выборочными данными x1,x2,...,xN и конкретными условиями поставленной задачи формулируют гипотезу H0, которую называют основной или нулевой, а гипотезу Н1, конкурирующую с гипотезой H0, называют альтернативной.
По наблюдаемой выборке случайной величины принимается решение о справедливости для генеральной совокупности гипотезы H0 или гипотезы H1.
Этап 2. Задаются величиной α – вероятностью ошибки первого рода, которую называют уровнем значимости, при чем

где P(H1 / H0) – вероятность того, что будет принята гипотеза Η1, в то время как для генеральной совокупности верна гипотеза H0 .
Вероятность α задается заранее, обычно в виде стандартных значений: 0,05; 0,01; 0,005; 0,0001. Вероятность ошибки второго рода β определяется как

где P(H0 / H1) – вероятность того, что будет принята гипотеза H0, в то время как для генеральной совокупности верна гипотеза Н1.
В результате проверки гипотез H0 и Н1 может быть принято и правильное решение относительно состояния генеральной совокупности. Тогда

где P(H0 / H0) – вероятность принятия решения о гипотезе H0, когда она в действительности имеет место,
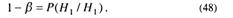
где P(H1 / H1) – вероятность принятия гипотезы H1, когда она верна для рассматриваемой генеральной совокупности.
Этап 3. Формируют статистику φ, которая является функцией выборочных данных φ=φ(Χ1,Χ2,...ΧΝ); ее значения позволяют судить о «расхождении выборки с гипотезой H0»; статистика φ является функцией от случайных значений выборки и, следовательно, она также случайна. При выполнении гипотезы Н0 значения статистики соответствуют известному закону распределения. В итоге, величину φ называют критерием.
Этап 4. Из области допустимых значений критерия φ выделяют подобласть ω таких значений, которые свидетельствуют о существенном расхождении выборки с гипотезой Н0 . Тогда, при попадании значений φ в эту область гипотеза H0 отвергается, а принимается гипотеза Н1. Подобласть ω называют критической.
Если критическая подобласть выделена, то руководствуются следующим правилом: если вычисленное по выборке значение критерия φ попадает в ω, то гипотеза Н0 отвергается, а принимается гипотеза Н1.
Необходимо иметь в виду, что такое решение может быть ошибочным: на самом деле для генеральной совокупности справедлива гипотеза H0. Т. е., ориентируясь на критическую ω, можно совершить ошибку первого рода, вероятность которой задана заранее и равна α. Отсюда следует требование к критической подобласти ω:
вероятность того, что критерий φ примет значение из критической ω, должна быть равна заданному числу α, т. е.

и критическая величина ω должна быть определена так, чтобы при заданной вероятности ошибки первого рода α вероятность ошибки второго рода β была бы минимальной.
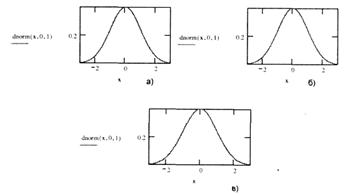
Рис.2 . Функции распределения значений статистики с критическими областями ω)
Относительно функции распределения значений статистики возможны три вида расположения критической значениями ω (рис.2):
- правосторонняя критическая подобласть (рис.2а), состоящая из интервала
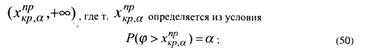
– левосторонняя критическая область (рис.2б), состоящая из интервала (![]() ) , где
) , где ![]() , определяется из условия
, определяется из условия

- двусторонняя критическая область (рис.2в), состоящая из следующих двух интервалов: (![]() ) и ( ),где точки
) и ( ),где точки ![]() и
и ![]() определяются из условий
определяются из условий
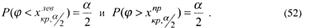
Этап 5. На основании наблюдаемых выборочных данных в формулу критерия φ=φ(Χι,Χ2,···,ΧΝ) вместо Х1,Х2,...,ХN подставляют конкретные числа и вычисляют значение критерия φ. Если это значение попадает в критическую подобласть ω, то гипотеза H0 отвергается и принимается гипотеза H1. Если не попадает, то гипотеза H0 не отвергается. Это не означает, что Н0 единственная гипотеза. Тогда следует считать, что расхождение между выборочными данными и гипотезой Н0 не противоречит результатам наблюдений.
Алгоритмы оценки
Правильность выполнения ПДТЗ тестируемым является случайным событием и вероятность p появления этого события при единичном испытании неизвестна. После постановки задачи проверки статистической гипотезы и определения этапов ее решения определим алгоритм оценки числового значения вероятности правильного выполнения задания р.
Выскажем гипотезу

о том, что вероятность p равна числу р0 . В основе ее проверки лежит сравнение числа р0 с приближенным значением вероятности p. найденным в результате проверки качества выполнения заданий ПДТ. Приближением к р является частость ![]() , где N— число заданий в тесте, которые независимы друг от друга и их решение проводится в одинаковых условиях; т – число правильно выполненных заданий. Для больших N(N > 30), согласно (18), имеем
, где N— число заданий в тесте, которые независимы друг от друга и их решение проводится в одинаковых условиях; т – число правильно выполненных заданий. Для больших N(N > 30), согласно (18), имеем
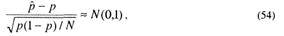
т. е. распределение значений этой величины близко к нормальному закону N(0,1) .
Если гипотеза (53) выполняется, то из последнего равенства (54) находим, что критерий

имеет нормальное распределение с нулевым математическим ожиданием и единичной дисперсией, т. е. φ = N(0,1).
Теперь сформулируем различные варианты альтернативных гипотез Н1.
1. H1 : p > р0, т. е. неизвестная вероятность р больше числа р0 . В этом случае критическая область имеет вид (![]() ,+∞), где точка определяется из условия (50 ), которое, учитывая (55), перепишем в виде
,+∞), где точка определяется из условия (50 ), которое, учитывая (55), перепишем в виде

На основе этого равенства найдем критическую точку ![]() , воспользовавшись таблицами значений функций Лапласа. Полагая γ = 1 – 2α, найдем квантиль Uγ, такой, при котором
, воспользовавшись таблицами значений функций Лапласа. Полагая γ = 1 – 2α, найдем квантиль Uγ, такой, при котором

или
![]()
Тогда вероятность противоположного события
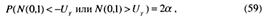
а так как для случайной величины с распределением N(0,1)
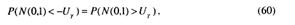
то из (59) следует

Сопоставим (61) и (56). В итоге получаем, что

отсюда следующая схема определения критической точки ![]() .
.
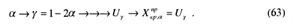
Теперь в формулу (55) подставим числовое значение частости p и заданные значения p0 и Ν.
В результате получим φ чис. Если φчис попадает в критическую область, то принимаем гипотезу Н1, в противном случае принимаем гипотезу Н0 .
2. H1 : p < р0, т. е. неизвестная вероятность р меньше заданного числа p0 .
В этом случае критическая область имеет вид (–∞,![]() ). где точка
). где точка ![]() определяется по аналогичной схеме:
определяется по аналогичной схеме:
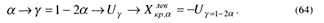
.Если числовое значение критерия φчис попадает в интервал (–∞ , Хкр, а) , то принимаем гипотезу Н1, в противном случае принимаем гипотезу Н0 .
3. H1 : p ≠ p0.
В этом случае критическая область состоит из двух интервалов (–∞,![]() /2) и (
/2) и (![]() /2,+ ∞), где критические точки определяются по следующей схеме
/2,+ ∞), где критические точки определяются по следующей схеме
И как в предыдущих случаях, если Uчис критерия (55) попадает в критическую область, то принимаем Н1, в противном случае – Н0. При малом числе наблюдений, n в тесте соотношения (54) и (55) не работают. В этом случае проверка гипотезы Н0 : p > р0. проводится следующим образом. Как и в предыдущем случае высказываются альтернативные гипотезы:
1. H1: p>p1.
Задаемся уровнем значимости α . Полагая, что γ = 1 – 2α, для заданного числа N испытаний Бернулли и значения т таких испытаний, в которых произошло событие А (событие правильно выполненного задания), по таблицам оценки доверительных границ параметра распределения Бернулли определяем нижнюю границу при назначенном значении надежности γ. Если p0 <p1, то принимаем гипотезу H1 :p >р0, в противном случае принимаем гипотезу H0 : p = р0.
2. H1 : р<р0.
Полагая γ = 1 – 2α и зная N и т, по той же таблице находим р2 – верхнюю границу доверительного интервала. Если р0 >р2, то принимаем гипотезу H1 :р<р0; в противном случае останавливаемся на гипотезе Я0 : p = р0.
3. H1 : p≠p0.
Полагая у = 1 – 2d и зная N и m, по тем же таблицам находим p1 u р2.
Если р0 <р1 или р0 >р2, то принимаем гипотезу Hi : р ≠ р0.
если р1 < р0 < р2 , то принимается гипотеза Н0 : p – р0.
Задачи классификации
Задача классификации учебных достижений тестируемых предполагает их разделение на два класса: аттестованных и неаттестованных. Это разбиение проводится по результатам тестовых проверок уровня знаний, умений и навыков на основе заданного количества положительно выполненных заданий. Изложим постановку этой задачи и разработаем алгоритмы классификации выпускников на основе теории статистических гипотез.
Алгоритмы классификации тестируемых относительно двух гипотез
Кавзисубъект выдает тестируемому выпускнику N заданий, из которых последний решает положительно X,{Q<X<N}. По предварительным исследованиям на основе статистической обработки и анализа проведенных тестовых проверок, а также экспертных оценок известно, что X является случайной величиной, распределенной по нормальному закону. Причем, выпускники, аттестованные положительно, в среднем решают μ, заданий, а аттестованные отрицательно, – μ, задание. Установлено что, если N=100, то μ1 = 25,3 μ2 = 75.
Разброс выполненных заданий относительно математических ожиданий μ1 и μ2 одинаков и определяется дисперсией δ2 .
Необходимо на основе теории статистических гипотез найти правило решений или стратегию принятия решений, с учетом на величины положительно выполненных ПДТЗ Х0, которая определяет допустимое (пороговое) число корректно выполненных заданий и делит всех тестируемых на две группы: аттестованных и неаттестованных.
Тогда, условные плотности вероятности случайной величины X корректно выполненных заданий относительно предполагаемых аттестованных и неаттестованных тестируемых можно представить в виде двух функций, изображенных на рис. 3 , где
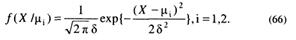
Правилом принятия решения или стратегией принятия решений для задачи классификации является выбор величины порога Х0, с помощью которого происходит разбиение интервала N на две области – N1 и N2.
Если число положительно выполненных заданий X попало в область N1, то принимается гипотеза А1 – тестируемый не обладает достаточными знаниями и не аттестовывается; если X попадает в область А2, то принимается гипотеза А2 – тестируемый обладает достаточными знаниями и аттестовывается положительно.
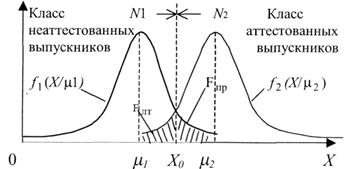
Рис. З. Функции распределения плотности вероятностей для гипотез А, и А2
Отсюда ясно, что по наблюдениям, т. е. по количеству положительно решенных заданий X гипотеза А, принимается при условии X < Х0, а гипотеза А2 – при условии X > Х0. В решаемой задаче величину порога принятия решения Х0 или стратегию принятия решения тестирующей системы необходимо выбрать так, чтобы последняя действовала оптимально в смысле какого-либо критерия. Рассмотрим выбор порога решения Х0 на основе известных в теории статистических решений критериев.
Критерий Байеса
Компьютерная программа с порогом принятия решения Х0 имеет четыре исхода:
1) верна гипотеза A1 и принимается решение о A1
2) верна гипотеза A1 а принимается решение о А2;
3) верна гипотеза А2 и принимается решение о A2;
4) верна гипотеза А2 а принимается решение о A1.
Первый и третий исходы соответствуют правильным решениям, второй и четвертый – ошибочным. Байесовский критерий основывается на двух допущениях: априорные вероятности гипотез Р1 и А известны и p1 +p2 =1; заданы стоимости четырех упомянутых действий: C11,C12,C22,C21.
Здесь первая цифра индекса в обозначении стоимостей означает выбранную гипотезу, вторая – гипотезу, которая была верна. При этих допущениях байесовский критерий строит правило решений так (или выбирает порог принятия решения Х0), чтобы в среднем потери или средние риски были минимальными.
С учетом полной группы событий при принятии решений ожидаемую величину потерь или значения риска запишем как
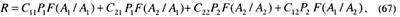
где F(Ai /Aj) – условные вероятности принятия решения о гипотезе Ai при верной Aj (i, j = l,2).
Следуя правилу решения выбирать либо A1, либо A2, разделим пространство наблюдений N на две части: N1 и N2 .Если результат тестирования X попадает в N1, принимается гипотеза A1, если в N2 – А, Тогда на основании данных, изложенных в постановке задачи и рис. 3, выражение (67) для риска перепишется в виде
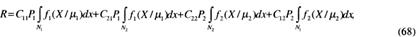
где fi(Χ/μj) – плотности вероятности принятия решений о гипотезе Ai при верности Aj, представленные в пространстве наблюдений X на оси N.
Так как N1 + N2 = N, то
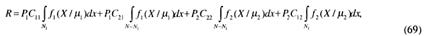
Учитывая, что
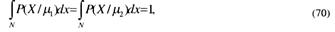
выражение (69) преобразуем к виду
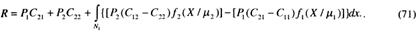
Первые два члена в (71) – фиксированные стоимости. Интеграл определяет стоимость тех наблюдений X, которые отнесены к области N1. При предположении, что стоимости правильных решений меньше стоимостей неправильных, т. е. C12 >С22 и С21 > С11, разности в круглых скобках положительны. Отсюда возможно следующее утверждение: чтобы минимизировать риск R при условии, что второй член подинтегрального выражения больше, чем первый, необходимо все значения X включать в N,, и наоборот.
Таким образом, области решений N1 и N2, соответствующие гипотезам A1 и А2 и минимизирующие риск R, определяются из следующих условий:
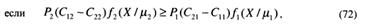
то X относится к N, и утверждается, что истинна гипотеза A2 (и наоборот). Формулу (72) обычно записывают в виде неравенства двух отношений:
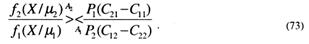
Левую часть (73) называют отношением правдоподобия и обозначают ![]() (x)
(x)

Правую часть (73) называют порогом принятия решений и обозначают η:

Порог принятия решения является const, зависящей от значения априорных параметров задачи. Таким образом, байесовский критерий сводится к критерию отношения правдоподобия, записывается в виде неравенства

и читается следующим образом:
если величина отношения правдоподобия для двух гипотез больше порога принятия решения, то принимается гипотеза А2, если меньше, то – А1.
Рассмотрим решение поставленной задачи, когда функции плотности вероятности гипотез А, и А2 определяются f(Χ/μ1) и f(Х/ μ2) согласно зависимости (66). Выражение (76) обычно логарифмируют и пользуются эквивалентной формой

Тогда отношение правдоподобия будет определено как
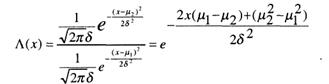
Откуда находим
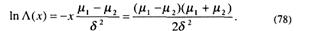
Решая это равенство относительно X с учетом (76), получим значение порога для принятия решений, минимизирующее средний риск:
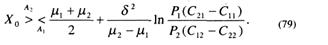
Для примера рассмотрим тривиальный случай, когда априорные данные p1 = p2=0,5, a C11 =C22=0, С21=С12. Тогда

Из (69) следует, если области решений N1 и N2 выбраны, то интегралы этого выражения становятся определенными. Тогда условные вероятности F(A1/A2) и F(A1/A2) являются мерой, определяющей ошибочные решения. В теории статистических решений эти вероятности обозначают:
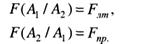
Для рассматриваемой задачи
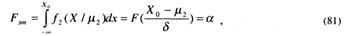
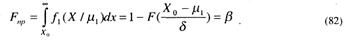
Fлт является вероятностью ошибки «ложной тревоги», которая определяет ошибку тестирующей системы, принявшей решение не аттестовывать выпускника, обладающего достаточными знаниями. Эту ошибку называют ошибкой первого рода или мерой значимости критерия. Fпр определяет вероятность ошибки «пропуска». Данная вероятность обозначает ошибку тестирующей системы, которая «аттестовала» студента, не обладающего достаточными знаниями, положительно. Эту ошибку называют ошибкой второго рода. Их величины соответствуют площадям под функциями f1(X/ μ1) и f2(Χ/μ2) относительно порога принятия решения Х0 (см. рис. 3).
Условные вероятности F(A1/A2) и F(A1/A2) определяют долю правильных решений при установление УУД тестируемых. Обозначим
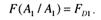
Для нашей задачи
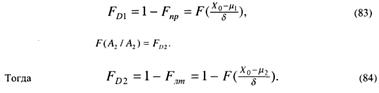
В теории статистических решений выражение (81) называют размером критерия, а (83) — мощностью критерия.
Если обозначить Fлт = α , то из (81) находим

где F-1 (α) – функция обратная функции Fлт. Подставив (20) в (18), находим
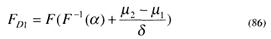
На основании формулы (86) строится рабочая характеристика критерия, по которой, задав ошибку первого рода α, определяют значение FDl при различных величинах μ1,μ2,Χ0 и δ . Т. е. (86) позволяет установить влияние параметров гипотез на вероятность правильного решения FD1 или на мощность критерия.
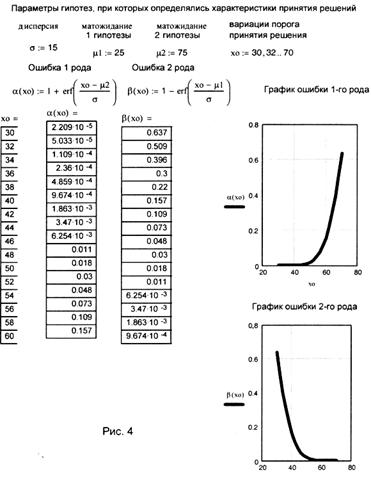
На рис. 4 представлены графики зависимости ошибок первого и второго родов от изменения величины порога принятия решения Х0. Они получены с помощью математической системы MathCAD, которая, на наш взгляд, наилучшим образом подходит для решения задач такого класса. На рис. 5 и 6 представлены графики меры правильного решения или мощности критерия Байеса в зависимости от назначенной ошибки первого рода α и величины порога принятия решения Х0. По этим графикам можно найти зависимость вероятности правильного решения от вариаций α и Х0.
Рассмотрим частный случай, когда стратегия принятия решения строится на основе минимума полной вероятности ошибки принятия решения. Выражение(68) для риска при условии, что C11=C22=0, a C12= C21=l, определяет полную вероятность ошибки принятия решения P(ε). Тогда (68) упрощается и запишется как
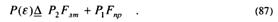
Выражение (87) называют критерием «идеального» наблюдателя или критерием Котельникова-Зильгерта.
При условии равенства априорных вероятностей P1 = Р2 =

Определение ошибки ложной тревоги α и ошибки пропуска β
Определение меры правильного решения или мощности критерия Байеса при изменении математического ожидания гипотезы с μ1=20, 25, 30
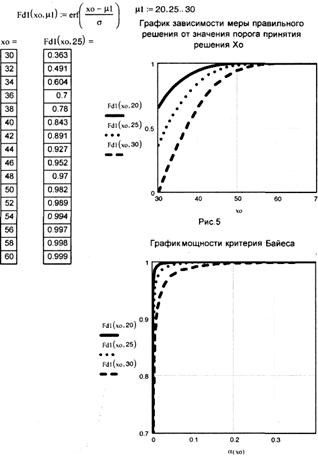
Рис.6
Определив Fлт и Fпр на основе зависимостей (81) и (82), находим
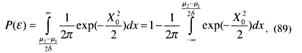
На рис. 7 и 8 Ρ(ε) получена как функция порога принятия решения Х0 для заданных μ1,μ2 u δ . Из рис. 7 видно, что при Р1 = Р2 и симметричных гипотезах min Ρ(ε) достигается при величине порога принятия решения Х0 =50. При изменении значений априорных вероятностей гипотез P1 u Р2 /см. рис. 8/ minΡ(ε) приходится на другие величины порога принятия решения Х0. Т. е. при наличии данных о значениях P1 u P2 можно выбирать порог принятия решений Х0 так, чтобы минимизировать ошибку на основании данных о μ1, μ2 u δ .
Вероятность полной ошибки принятия решения в зависимости от величины порога принятия решения Xo
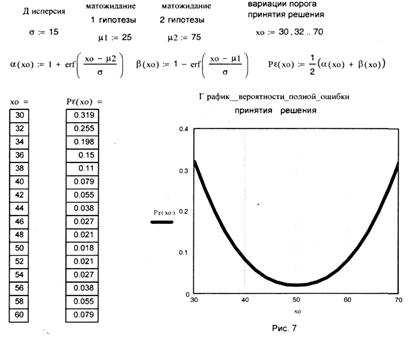
Графики зависимости вероятности полной ошибки принятия решения в зависимости от величины порога X0 и от априорных вероятностей P1 и P2
Рис. 8
Минимаксный критерий
Этот критерий применяется при отсутствии информации о величинах априорных вероятностей гипотез А1 и А2 — Р1 и Р0 соответственно. Обозначим: P1 = 1 — P, P2 = P. Тогда тестирующая система использует байесовскую стратегию только при таком значении P, для которого риск будет максимален.
Перепишем выражение риска (67) с учетом (81), (82) и (83) при любом выборе порога решений:
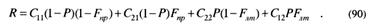
Для упрощения задачи рассмотрим случай, когда С11 = С22 = 0 .
Тогда риск R может быть представлен как функция априорной вероятности P
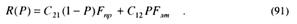
Если зафиксировать величину X0 = const, то Fлт(Х0) и Fnp(X0) становятся константами и риск R является функцией только от Ρ, т.е. R (P). Как видно из рис. 9, максимум функции риска зависит от значения априорной вероятности Р.
Если (91) продифференцировать по P, а производную приравнять нулю, то из уравнения R'(P) = 0, находим, что минимаксное решение есть байесовское решение, для которого риски, определяемые ошибками первого и второго родов, равны:
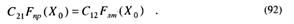
Решение этого трансцендентного уравнения является порогом принятия Ха, соответствующий минимаксному критерию, который при отсутствии знаний о величинах априорных вероятностей гарантирует минимальный средний риск при любом значении этих вероятностей.
Для решаемой задачи при условии, что С21 = C12 и с учетом (81) и (83), получаем следующую зависимость:
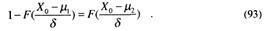
По формуле (93), задавшись μ1 и μ2, определяют порог принятия решения. Для симметричного случая стоимостей и функций распределения гипотез, представленных на рис.3, он равен
Минимаксный критерий
Рис . 9
Критерий Неймана-Пирсона
Если не определены априорные вероятности гипотез Р1 и P2 и не заданы стоимости принятия решений Cij, то к величинам вероятностей ошибок первого и второго родов предъявляют определенные требования и для решения поставленной задачи применяют критерий Неймана-Пирсона.
Согласно этому критерию уровень значимости критерия задают из необходимых требований задачи Fлт = α ≤ α ' и находят правила принятия решений, максимизирующие мощность критерия FD1 = 1 – Fпр или минимизирующие Fпp.
Решение реализуется на основе леммы Неймана-Пирсона.
Используя метод множителей Лагранжа, строят функцию F:
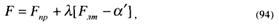
которую с учетом (81) и (82) переписывают как
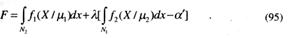
При Fлm = α минимизация F ведет к минимизации Fпр. Последнее выражение на основе (68) можно записать в виде:
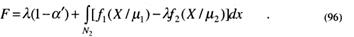
Отсюда следует, что для минимизации F все X относятся к области N2 тогда и только тогда, когда выражение, заключенное в квадратные скобки интеграла в (96), отрицательно.
Это утверждение эквивалентно следующему правилу принятия решения:

то наблюдение X относят к области N1, где принимается гипотеза A1, и, соответственно, наоборот:
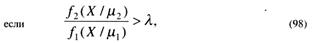
то наблюдение X относят к области N2, где принимается гипотеза А2.
Таким образом, функция F в (96) минимизируется по критерию отношения правдоподобия при любом положительном значении λ .
Согласно определению (74) полученную зависимость можно переписать как

На основе (99) определяют наилучшую критическую область (HKO), которая при заданном уровне значимости α обеспечивает минимальную вероятность ошибки второго рода Fпр. Отсюда следует, что критерий, использующий HKO, имеет максимальную мощность.
Для того чтобы удовлетворить указанному ограничению (99), выберем такое значение А, при котором Fлт = α '. Если обозначить плотность вероятности Λ (при условии, что верна гипотеза А2) через f(Λ (Х)/А2), то выбор λ равносилен выполнению требования
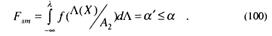
Решая (100) относительно λ, находим величину порога принятия решения по критерию Неймана-Пирсона. При условии, что Fлт определяется заштрихованной областью слева от порога принятия решения Х0, увеличение А эквивалентно уменьшению области N2, при попадании в которую утверждается, что истинна гипотеза А2 (Рис. 3). Поэтому мы увеличиваем λ до тех пор, пока не получим максимально возможное α '< α.
Теперь рассмотрим решение нашей задачи на основе критерия Неймана-Пирсона. Случайная величина X имеет нормальное распределение Ν(μ,δ) с известной дисперсией δ2. Определим наилучшую критическую область (НКО) для проверки гипотезы А2: μ = μ2 . A1 альтернативной гипотезы А1: μ = μ1, причем μ2 > μι.
Запишем функцию отношения правдоподобия

После подстановки (66) в (101) находим
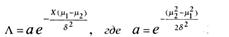
Согласно лемме Неймана-Пирсона НКО содержит только те точки выборочного пространства X, для которых удовлетворяется неравенство (99). Теперь выразим (99) на основе (101) и получим следующий результат: если при подстановке наблюдения X имеет место неравенство
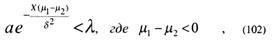
то это наблюдение соответствует гипотезе А1.
Так как функция отношения правдоподобия является возрастающей функцией аргумента X, то условие леммы удовлетворяется при X < Хθ, где Х0 – граница критической области. В свою очередь, границы критической области определяются или по заданному уровню значимости, или по заданной ошибке первого рода а из (100).
При условии, что справедлива гипотеза А2, а X имеет нормальное распределение N(μ2, δ) , на основании выражения (81) запишем
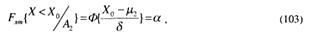
где Ф{.} – функция Лапласа.
Отсюда следует, что
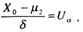
где Ua – значение аргумента функции Лапласа при ее величине, равной α ;
Ua находится по таблицам обратной функции Лапласа.
Граница Ха наилучшей критической области определяется из равенства Ха = μ2 – Ua · δ , a HKO определяется неравенством

Рассмотрим несколько примеров определения границы НКО для поставленной задачи.
При α = 0,5 функция Лапласа Ф(Uα) = 0,05,откуда согласно таблицам из [6] Ua=—1,65. При μ2=75 и δ=15 на основе (104) граница принятия решений Х0 = 50,25.
При байесовском критерии, дающем Ρε(Χ0) = min для μ 1=25 и μ 2=15 , при α = 0,18 => Х0 = 50 (см. рис.4).
По критерию Неймана-Пирсона при α =0,18 по таблицам из [6] определяем Ua = – 0,92 .Откуда следует Х0 61,5 , что дает min β .
Теперь найдем значение мощности критерия или значение вероятности правильного решения об отрицательной аттестации тестируемого выпускника.
При выборе НКО по критерию Неймана-Пирсона для μ1, FD2 = ![]() .
.
![]()
По рабочей характеристике этому значению F0, соответствует ошибка первого рода α = 0,05 (см. рис.6).

Данная процедура определения Х0 и значения функции мощности критерия легко реализуется в системе программирования MathCAD.
Алгоритмы классификации тестируемых относительно M гипотез
В первом разделе решалась задача классификации тестируемых и их разделение на два класса: аттестованных и не аттестованных.
Рассмотрим задачу разделения тестируемых, аттестованных положительно, на три группы:
– группу аттестованных на «удовлетворительно»;
– группу аттестованных на «хорошо»;
– группу аттестованных на «отлично».
Необходимо установить правило принятия решений на основе величины правильно выполненных заданий X
Как и в предыдущей задаче считаем, что условные плотности вероятности правильно выполненных заданий представлены в виде гаусовых законов распределения:
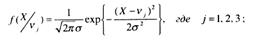
v1 – математическое ожидание числа правильно выполненных задании для аттестованных на «удовлетворительно», что соответствует гипотезе В1 ;
v2 – математическое ожидание числа правильно выполненных заданий для аттестованных на «хорошо», что соответствует гипотезе В2 ;
v3 – математическое ожидание числа правильно выполненных заданий для аттестованных на «отлично», что соответствует гипотезе В3 .
Дисперсия σ2 для всех гипотез одинакова.
При решении задачи для M гипотез выражение для риска в общем виде, аналогичное (67), запишется как
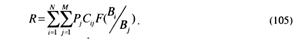
Здесь Pj – априорная вероятность гипотезы Bj ;
Cij – стоимости действий при аттестации;
F(![]() ) – условные вероятности принятия решений о Вi при верной Bj.
) – условные вероятности принятия решений о Вi при верной Bj.
Правилом принятия решения или стратегией для тестирующей системы в этом случае является выбор величин двух порогов Ха и Хь, с помощью которых происходит разбиение интервала наблюдений N, т. е. положительно выполненных заданий, натри области:
N1 , что соответствует гипотезе В1 ;
N2 , что соответствует гипотезе В2 ;
N3 , что соответствует гипотезе В3 ·
Причем эти области не пересекаются. Тогда выражение для риска (105) можно определить как
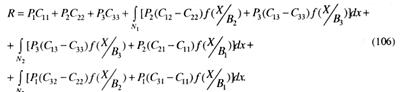
Как и для случая двух гипотез, чтобы получить минимум R, необходимо минимизировать подинтегральные выражения, выбирая определенным образом области N1 , N2 , Ν3 . Если обозначим подинтегральные выражения соответственно через N1(X) N2(X) N3(X) то ясно, что риски R будут минимальными:
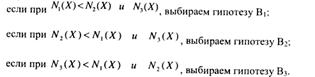
Обозначив отношения правдоподобия
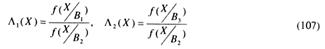
и, используя полученные выше неравенства, на основе (107) найдем величины порогов решений:
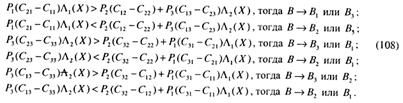
Из выражений (108) видно, что правила решений соответствуют трем линиям в плоскости Λ1, Λ2, т. e. для трех альтернативной задачи пространство решений является двумерным (см. рис. 11).
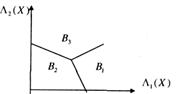
Рис. 11. Пространства решений в координатах (Λ 1(X), Λ 2(Х)
Далее рассмотрим частный случай, когда
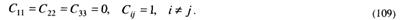
Условия (109) означают, что любая ошибка равнозначна. Из (69) следует, что это соответствует условию минимизации полной вероятности ошибки. Подставляя (109) в (107)-(108), получим:
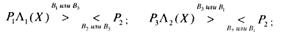

Области принятия решений показаны на рис. 12
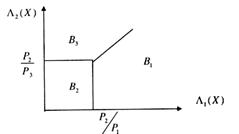
Рис. 12. Пространства решений в координатах Λ1(Х), Λ 2(Х)
Чтобы получить простой алгоритм определения гипотезы, произведем еще одну операцию. Подставим выражение (107) в неравенство (110) и, умножая обе части всех неравенства f( ), найдем:
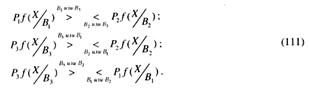
Из (111) видно, что алгоритм определения гипотезы заключается в вычислении апостериорных вероятностей P(![]() ), P(
), P(![]() ) и P(
) и P(![]() ) и в выборе из них наибольшей, что и является признаком гипотезы, имеющей минимальный байесовский риск при принятии решения, соответствующего этой гипотезе.
) и в выборе из них наибольшей, что и является признаком гипотезы, имеющей минимальный байесовский риск при принятии решения, соответствующего этой гипотезе.
Теперь определим ошибки принятия решений Fлт и Fпр при аттестации тестируемых, разбиваемых на три группы:
до значения X1 – I группа аттестуется «удовлетворительно»;
между значениями X1 и Х2 – II группа аттестуется «хорошо»;
и свыше Х2 – III группа аттестуется «отлично».
Согласно постановке задачи, вид распределений плотностей вероятностей можно представить на рис. 13, где обозначены вероятности ошибок:
Fлт1 – вероятность ошибки того, что тестируемый, имеющий «удовлетворительную» степень обучения, в действительности аттестуется на «хорошо»;
Fлт2 – вероятность ошибки того, что тестируемый, имеющий «хорошую» степень обучения, аттестуется или на «удовлетворительно» или на «отлично»;
Fлт3 – вероятность ошибки того, что тестируемый, имеющий «отличную» степень обучения, аттестуется на «хорошо».
Такие же обозначения имеют и вероятности ошибок пропуска:
Fпр1 – вероятность того, что тестируемый, имеющий степень обучения на «удовлетворительно», аттестуется на «хорошо»;
Fпр2 – вероятность того, что тестируемый, имеющий степень обучения на «удовлетворительно», аттестуется на «отлично»;
Fпр3 – вероятность того, что тестируемый, имеющий степень обучения на «хорошо», аттестуется на «отлично».
Причем, как видно из рис. 13, при рассмотрении гипотезы Bt, все соотношения для определения ошибок принятия решения сохраняются как для двуальтернативного случая. Это справедливо и относительно гипотезы B3. При решении о принятии гипотезы В2 ошибки решений увеличиваются вдвое, если расположение распределений гипотез будет симметрично относительно гипотезы В2, как это показано на рис.13.
Критерий Байеса для трехальтернативной задачи тестирования
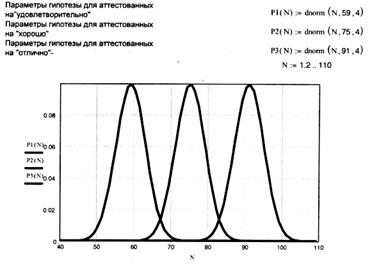
Рис.13. Функции распределения плотности, вероятности гипотез
Тогда
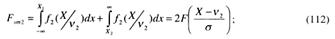
соответственно:
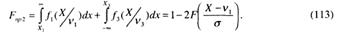
Следовательно, мощность критерия для трехальтернативного случая различения гипотез может быть представлена аналогично (83) как

Соответственно, может быть получена рабочая характеристика

В примере, представленном на рис. 14, относительно гипотез были приняты следующие значения математических ожиданий:
для гипотезы В1 v1 =59; для гипотезы В2 v2 =75; для гипотезы В3 v3 =91. Для всех гипотез среднее квадратическое отклонение σ =4. На рис. 14 представлен пример определения гипотезы для тестируемого, который выполнил 64 задания из 100 возможных.
Определение гипотезы по количеству положительно выполненных заданий
Аттестуемый выполнил 64 задания положительно. Определим его оценку на основе критерия Байеса при условии, что все априорные вероятности гипотез равны:
pl=p2=p3. Тогда истинная гипотеза имеет наибольшую величину апостериорной условной вероятности.
Вычислим значения условной вероятности для каждой гипотезы —
P1(64)=0,046 P2(64)=2,273×10-3 P3(64) =1,274×10-11
Из приведенный значений ясно, что необходимо выбрать гипотезу P1 и поставить аттестуемому «удовлетворительно».
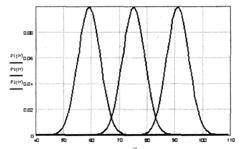
Рис.14 Функции распределения плотности вероятности гипотез
Алгоритм классификации достижений на основе последовательного анализа
Алгоритм классификации для двух гипотез
Если предыдущие алгоритмы принятия решений о классификации тестируемого выпускника предполагали, что N заданий, которые выдаются для тестирования выпускников, и X – число положительно решенных заданий фиксированы, то метод последовательного анализа предполагает принятие решения в зависимости от результатов последовательного выполнения ПДТЗ выпускником, которые тестирующая система анализирует по мере их выполнения.
Эта процедура дает возможность тестирующей системе принимать решение о классификации поведения студента, не проверяя все N заданий, что значительно сокращает число проверяемых заданий.
Сущность последовательного анализа заключается в том, что предварительно строят в пространстве наблюдений верхнюю и нижнюю границы, которые делят его на три области:
· область принятия решений о гипотезе A1 ;
· область принятия решений о гипотезе А2;
· область неопределенности, которая требует проверки и анализа еще одного задания.
В [7] А. Вальд дал как точное, так и упрощенное построение границ в пространстве наблюдений для двуальтернативного случая. Он показал, что, следуя изложенным правилам принятия решений относительно границ и областей пространства наблюдений, минимизируется среднее число наблюдений по сравнению с любыми другими критериями принятия решения относительно гипотез А1 и A2 которые имеют такие же вероятности ошибок первого и второго родов.
Процедура последовательного анализа строится на основе функции отношения правдоподобия:
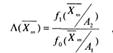
где 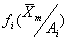 – вероятность (или плотность вероятности) получения выборки
– вероятность (или плотность вероятности) получения выборки
![]() = Х1,Х2,...,Хт при условии, что справедлива гипотеза Ai, где i=0,l. Значение Λ ( ) сравнивается с двумя порогами А и В.
= Х1,Х2,...,Хт при условии, что справедлива гипотеза Ai, где i=0,l. Значение Λ ( ) сравнивается с двумя порогами А и В.
Если Λ (![]() ) ≥ А, то принимается решение о гипотезе А2.
) ≥ А, то принимается решение о гипотезе А2.
Если Λ ( ) ≤ В, то принимается решение о гипотезе A1. (116)
Если В ≤ Λ ( ) ≤ А, то принимается решение о продолжении предъявления тестируемому заданий.
Согласно работам Вальда пороги принятия решений определяются зависимостями:
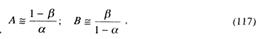
где α – вероятность ошибки 1 – го рода; β – вероятность ошибки 2-го рода.
Условия Λ = А и Λ = В представляют собой решающие функции, которые разбивают пространство наблюдений на области:
· относящуюся к гипотезе А1;
· относящуюся к гипотезе А2;
· неопределенности, которая требует для выбора гипотезы предъявления еще одного тестового задания.
Рассмотрим постановку и решение нашей задачи как задачу последовательного анализа.
Тестируемому система генерирует тестовые задания. Если он в процессе не выполняет относительную долю Р0 заданий, то аттестуется положительно. Если он не выполняет относительную долю P1 заданий, то он не аттестуется, т. к. P1 > Р0. На основе вышесказанного определяем гипотезы:
Р0 – выпускник соответствует требуемому уровню квалификации;

|
Из за большого объема эта статья размещена на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 |
