


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
rxy= 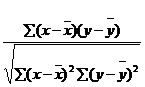
После преобразований получим: rxy= 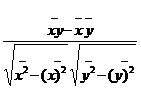 .
.
Однако, для вычисления линейного коэффициента корреляции необходимо, чтобы распределение было нормальным, поэтому на небольших выборках следует применять ранговый коэффициент корреляции, который вычисляется по формуле: rs=1-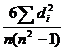 , где n-объем выборки, di - разность рангов соответствующих значений.
, где n-объем выборки, di - разность рангов соответствующих значений.
В практических исследованиях о тесноте связи судят по величине выборочного коэффициента корреляции и поскольку вычисленная величина является величиной случайной, то оценивается значимость коэффициента корреляции по t-статистике Стьюдента с (n-2) степенями свободы: tфакт.=![]()
Нулевая гипотеза Н0 – коэффициент корреляции не является статистически значимым, т. е. линейная корреляционная связь между переменными отсутствует, альтернативная гипотеза Н1 – выборочный коэффициент значимо отличается от нуля, т. е. между показателями наблюдается линейная корреляционная зависимость. Нулевая гипотеза отвергается, если tфакт.>tкри. на данном уровне значимости.
Регрессионный анализ. Изучение корреляционных зависимостей основывается на исследовании таких связей между переменными, при которых значения одной переменной (ее можно принять за зависимую переменную) “в среднем” изменяются в зависимости от того, какие значения принимает другая переменная.
Теоретической линией регрессии называется та линия, вокруг которой группируются точки корреляционного поля, и которая указывает основное направление, основную тенденцию связи.
Теоретическая линия регрессии должна отображать изменение средних величин результирующего признака у по мере изменения факторного признака х. Следовательно, эта линия должна быть проведена так, чтобы сумма отклонений точек поля корреляции от соответствующих точек теоретической линии регрессии была бы минимальной величиной. Важным этапом регрессионного анализа является определение типа функции, с помощью которой характеризуется зависимость между признаками. Приблизительное представление о линии связи можно получить на основе эмпирической линии регрессии, получаемой графическим методом.
РАЗДЕЛ II. ПОИСК ИНФОРМАЦИИ В ИНТЕРНЕТЕ
Для поиска информации в Интернете используются специальные поисковые серверы, которые содержат постоянно обновляемую информацию о Web-страницах, файлах и других документах, хранящихся на десятках миллионов серверов Интернета. Обращаясь к поисковой службе, мы формулируем запрос, в котором формально описываем то, что хотим найти. Проведя нужные операции, служба формирует Web-документ, состоящий из гиперссылок, ведущих к ресурсам WWW, соответствующим нашему запросу. Принцип действия у разных поисковых служб может быть различным, поэтому пользователи должны учитывать способ формирования баз данных, чтобы знать, на что они могут рассчитывать при поиске информации.
Различные поисковые серверы могут использовать различные механизмы поиска, хранения и предоставления пользователю информации. Поисковые серверы Интернета можно разделить на две группы:
Поисковые системы общего назначения - поисковые указатели и тематические каталоги.
Специализированные поисковые системы – серверы поиска файлов, системы поиска в конференциях Usenet и службы поиска людей.
Следует отметить, что многие поисковые системы общего назначения, являясь поисковыми указателями, имеют списки тематических разделов, а серверы тематических каталогов оснащены средствами поиска по ключевым словам, кроме того, многие компьютеры содержат ссылки, типа, People Finder или People Search и Usenet или News для поиска в специализированных поисковых системах.
Поисковые системы общего назначения. Поисковые системы общего назначения являются базами данных, содержащими тематически сгруппированную информацию об информационных ресурсах Internet. Такие поисковые системы позволяют находить Web-сайты или Web-страницы по ключевым словам в базе данных или путем поиска в системе каталогов.
Интерфейс поисковых систем общего назначения содержит список разделов каталога и поле поиска. В поле поиска пользователь может ввести ключевые слова для поиска документа, а в каталоге выбрать определенный раздел, что сужает поле поиска и таким образом ускоряет его.
В отличие от каталогов, поисковая система – это полностью автоматизированная структура, потому количество Web-страниц, к которым ведет поисковый указатель, намного больше. Поисковый указатель содержит часто обновляемую базу ссылок на разные сайты в Интернете. При запросе какой-либо информации, Поисковый указатель, прежде всего, просматривает свою базу и подсчитывает релевантность. Релевантность – это соответствие найденной страницы поисковому запросу. Каждый поисковый указатель обладает собственным механизмом подсчета уровня релевантности. Главное отличие поисковых систем друг от друга – это база ссылок и система подсчета уровня релевантности, поэтому результата их поиска различаются.
Наиболее мощными поисковыми указателями в русскоязычной части Интернета являются серверы:
Тематические каталоги. Это пионеры навигации в Сети. Они представляют из себя каталог (собрание) сайтов по различным тематикам. Вся информация в каталогах обрабатывается вручную. Для того, чтобы добавить новый сайт в какой-либо раздел, необходимо прислать заявку. И только после того, как сотрудник, отвечающий за наполнение каталога, ознакомится с содержанием ресурса, может решаться вопрос о его добавлении в каталог. Из этого следует, что вся работа в каталогах не автоматизирована.
Любой сайт в каталоге снабжается кратким описанием, по которому пользователь может определить его краткое содержание. К сожалению, размещение ресурса в каталоге и его описание целиком и полностью зависит от администрации каталога. Иногда случается, что ресурс помещается не в тот тематический раздел или его аннотация не соответствует действительности.
Порталы. Современные поисковые системы часто являются информационными порталами, которые предоставляют пользователям не только возможности поиска документов в Интернете, но и доступ к другим информационным ресурсам (новостям, информации о погоде, о валютном курсе и так далее).
Порталы предоставляют пользователю возможность персональной настройки. Для этого надо установить флажки против тех поставщиков информации, которые вам интересны, и выключить у тех, которые неактуальны.
Часто название порталов начинается со слова My (Мой). Например, если на поисковых системах Yahoo! или Alta Vista вам предлагают подписаться на службу MyYahoo или MyAltaVista, то, значит, речь идет о том, чтобы стать постоянным клиентом портала.
Другой причиной того, что поисковые системы постепенно превращаются в порталы, стал тот факт, что им стало трудно одновременно «копировать» пространство WWW и индексировать гигантские базы данных. Поисковые системы начинают распределять обязанности. Задачи по контролю за Web-пространством постепенно передаются на партнерских основаниях «третьим» фирмам, а сами поисковые системы сосредоточиваются на обслуживании клиентов и привлечении рекламодателей, то есть превращаются в порталы.
Специализированные поисковые системы позволяют искать информацию в серверах файловых архивов, почтовых серверах и других.
Интернет является самым большим в мире хранилищем файлов, в котором десятки тысяч компьютеров – FTP-серверов, предоставляют свои файлы пользователям сети. Вы можете скачивать файлы с доступных FTP-серверов, а также записывать файлы на некоторые FTP-серверы. Общедоступные FTP-серверы называются анонимными серверами. На легальных анонимных FTP-серверах коммерческие версии программ отсутствуют, но есть бесплатные (FreeWare) и условно бесплатные (ShareWare) программы.
Для поиска файлов на серверах файловых архивов существуют специализированные поисковые системы двух типов: поисковые системы на основе использования баз данных и каталоги файлов. Например, в базе данных российской файловой поисковой системы http://www. ***** содержатся сведения о 6 миллионах файлов, размещенных на двух тысячах серверов файловых архивов российской части Интернета. Для поиска файла в системе с использованием базы данных достаточно ввести имя файла в поле поиска и поисковая система выдаст URL-адреса мест хранения данного файла.
Отметим, что скачивать файлы из Интернета можно и с помощью браузеров, но для работы с каталогами файлов более удобно и эффективно использовать специальные программы-качалки для обмена файлами в сети, например: бесплатная, русифицированная программа ReGet (http://www. /).
Программа-качалка FlashGet «прописывается» в меню браузера и резедентна в ОЗУ. При копировании файлов из Интернета программа предлагает скачать файл.
Программа FlashGet не предназначена для просмотра файлов на FTP-серверах, для этого можно воспользоваться программой CuteFTP.
CuteFTP – условно бесплатная программа (ftp:///pub/cuteftp/) для работы с файлами в Интернете, позволяет:
• не только скачивать, но и отправлять файлы на FTP-сервер;
• докачивать файл, в случае разрыва связи и прекращения процесса копирования;
• произвести поиск файлов с помощью популярных поисковых систем.
• запомнить адреса FTP-серверов в адресной книге
• сохранить полный путь к нужной папке на выбранном FTP-сервере;
• сравнить содержимое папок на вашем и удаленном компьютерах.
Окно программы содержит область для сообщений о ходе подключения, копирования файлов и возникающих проблемах при работе с FTP-сервером. В левой части окна отображается текущий локальный каталог с файлами на вашем компьютере, справа – находится поле для текущего каталога на FTP-сервере.
В окне программы нажмите кнопку Site Manager для работы с адресной книгой FTP-серверов, в которой уже содержатся адреса популярных FTP-серверов. После выбора нужной папки в левой части окна диалога, в правой части будет появляться содержимое необходимого раздела со списком серверов.
Нажав кнопку New можно добавить папку, а кнопка Wizard запускает мастера добавления узла. При заполнении данных для анонимных FTP-серверов устанавливается тип подключения – Anonymous.
Для соединения с выбранным FTP-сервером нажмите кнопку Connect – в поле сообщений окна программы появится информация о ходе соединения с сервером. После подключения к узлу в правой части рабочего окна появится список файлов и каталогов удаленного компьютера. Копирование выделенной группы файлов производится перетаскиванием (Drag&Drop) из одной папки в другую. Для разрыва связи с FTP-сервером в окне программы CuteFTP нажмите кнопку Disconnect.
Специализированные поисковые системы позволяют искать адрес электронной почты по имени человека или, наоборот, имя человека, хозяина определенного адреса электронной почты. Примером такой системы может служить поисковая система WhoWhere? (КтоГде?), расположенная по адресу: http://www. /.
WHOIS обеспечивает каталожную службу для пользователей сети. Эта служба заключается в поиске e-mail адресов, почтовых адресов и телефонных номеров. WHOIS может поставлять информацию о сетях, о структуре доменов и т. д. Главная база данных, относящихся к сетям, (в которую при регистрации доменов и при выдаче IP-адресов автоматически заносятся сведения) поддерживается Регистрационной службой Интернет (InterNic).
Служба каталогов – средство поиска, при помощи которого можно проводить поиск людей и фирм по всему миру. Адресная книга программы Outlook Express поддерживает протокол LDAP для работы со службами каталогов. В ней имеется встроенный доступ к нескольким популярным службам каталогов. В адресную книгу можно добавить службы каталогов, доступ к которым предоставляется поставщиком услуг Интернета.
Как и другие средства поиска в Интернете, разные службы каталогов используют различные методы сбора данных. В связи с этим имеет смысл проводить поиск не только в одной службе каталогов.
В некоторых англоязычных системах перед началом поиска можно выбрать язык представления информации, либо использовать Интернет-переводчик, например, «Сократ Интернет».
Объем базы данных http://www.Google.com/ в 2003 г. составил 3 млрд Web-страниц. Язык интерфейса автоматически подстраивается под пользователя.
Система (http://www. ) была запущена в эксплуатацию в декабре 1995 г. По количеству индексированных Web-страниц Alta-Vista – одна из крупнейших поисковых систем мира. Огромный объем охвата Web-пространства и мощный набор поисковых команд делают эту систему излюбленным средством поиска для большинства пользователей.
Кроме поисковых возможностей Infoseek (http://www. ) портал предоставляет зарегистрированным пользователям возможность персональной настройки среды, бесплатную электронную почту и другие полезные сервисы. Пользователи этой системы отмечают высокое качество ссылок, возвращаемых системой, что объясняется специальным «фирменным» алгоритмом поиска. Кроме автоматизированного указателя система имеет также обширный каталог Web-узлов, составляемый вручную.
Первоначально служба Lycos (http://www. ) была запущена как поисковая система, основанная на программе-роботе, собирающей информацию из WWW. Запущенная в эксплуатацию еще в мае 1994 г., сегодня она считается одной из старейших поисковых служб. В качестве альтернативной услуги Lycos ведет еще один каталог – каталог Web-узлов Lycos Community Guides.
Excite (http://www. ) – одна из самых популярных поисковых систем World Wide Web. Она имеет указатель среднего размера и кроме поиска Web-страниц предоставляет услуги по поиску других материалов, например сведений о компаниях или результатов спортивных соревнований. Система была создана в конце 1995 г., прошла этап бурного развития и в 1996 г. поглотила двух ближайших конкурентов: систему Magellan и WebCrawler, хотя те по-прежнему сохраняют свои торговые марки и предоставляют поисковые услуги как самостоятельные службы.
Российские поисковые указатели. Важную роль в становлении и развитии отечественного сектора Интернета сыграли российские поисковые службы. В России есть и универсальные поисковые службы (поисковые указатели и каталоги), и специализированные поисковые службы.
Апорт (http://www. *****) – один из первых поисковых указателей российского Интернета – детище компании «Агама» (http://www. *****/). В прошлом служба предоставляла традиционные общепринятые средства поиска, но в конце 1999 года внедрила новую систему («Апорт 2000») и сделала большой шаг вперед, особенно в том, что касается представления результатов поиска. Следует отметить, что системе «Апорт 2000» удается сочетать «компьютерный» и «человеческий» факторы. Это достигнуто за счет тесной интеграции с партнерским каталогом @Rus. Так, например, когда по результатам поиска выводится адрес Web-страницы, то он может сопровождаться кратким описанием Web-узла, взятым из каталога @Rus. Хотя пользователь и не видит глубинных процессов, но система «Апорт 2000» уделяет особое внимание рейтингованию результатов поиска. В частности, она использует наиболее эффективную сегодня систему рейтингования по количеству ссылок, ведущих к данному ресурсу (по индексу цитирования). По способу представления результатов поиска служба «Апорт 2000» является одной из самых передовых не только в России, но и в мире.
Rambler (http://www. *****) – рейтинговая система, обладающая всеми основными функциями поисковых указателей. Как поисковый указатель, служба обладает одним из крупнейших индексов в России, но ей явно недостает быстродействия и современных алгоритмов рейтингования результатов поиска. Сервер ведет статистику посещаемости ссылок из собственной базы данных, что позволяет быстро выявить круг Web-узлов, поставляющих информацию на заданную тему и оценить их популярность по количеству посещений за последние сутки. На главной странице Rambler в раздел "Рейтинг", можно просмотреть содержимое тематического каталога, отсортированного по убыванию числа посещений сайтов.
Яndex (http://www. *****) – мощная поисковая служба, основанная на указателе, обладающая как большой и представительной базой данных по отечественным Web-ресурсам, так и изощренной системой индексации. Функционирование службы обеспечивает компания CompTek (http://*****/). Яndех предоставляет уникальные в своем роде инструменты, сосредоточенные в разделе расширенного поиска, имеет интеллектуальный механизм морфологического разбора слов, что особенно важно для русского языка.
Для корпоративных клиентов Яndex бесплатно предоставляет «облегченную» версию программы – Яndeх. site, выполняющей индексацию содержимого Web-узла. Это удобно тем владельцам Web-узлов, которые хотели бы организовать локальную систему для поиска информации в пределах собственного узла.
Сбор информации поисковыми указателями. Поисковые программы - роботы
Заполнение баз данных поисковых серверов осуществляется с помощью специальных агентских программ, которые периодически «обходят» Web-серверы Интернета и просматривают Web-страницы. Агентские программы по сбору информации называют «червяками», «пауками», «поисковыми роботами» (сокращенно «ботами»), «поисковыми машинами», «краулерами» и т. п. Многообразие названий связано с тем, что каждая поисковая система создает свою собственную, неповторимую программу и дает ей свое имя, которое впоследствии становится нарицательным. Большинство современных поисковых систем начинались с того, что в 1993-94 годах в университетских лабораториях были разработаны экспериментальные программы для мониторинга Сети.
Программы – роботы читают все встречающие документы, выделяют в них ключевые слова и заносят в базу данных, содержащую URL-адреса документов. Если при чтении Web-страницы поисковый робот находит на ней ссылки на другие страницы того же Web-узла, он переходит по этим ссылкам, читает их содержание и так далее. Так как почти любая страница WWW имеет множество ссылок на другие страницы, то при подобной работе поисковый указатель в конечном результате теоретически может обойти все сайты в Интернет. Например, популярный поисковый указатель AltaVista содержит 11 миллиардов слов, извлеченных из 30 миллионов WWW-страниц.
Сайты в базе данных ранжируются по количеству их посещений, определяемых с помощью специальных счетчиков, установленных на сайте. Счетчики фиксируют каждое посещение сайта и передают информацию о количестве посещений на сервер поисковой системы.
Так как информация в Интернете постоянно меняется, поисковые роботы не всегда успевают отследить все изменения. Информация, хранящаяся в базах данных поисковых систем, может отличаться от реального состояния Интернета, и тогда пользователь в результате поиска может получить адрес уже не существующего или перемещенного документа.
Регистрация владельцем сайта. В целях обеспечения большого соответствия между содержанием базы данных поисковой системы и реальном состоянием Интернета, большинство поисковых систем разрешают автору нового или перемещенного Web-сайта самому внести информацию в базу данных, заполнив регистрационную анкету. В анкете разработчик сайта вносит URL-адрес сайта, его название, краткое описание содержания сайта, а также ключевые слова, по которым можно найти сайт. Сайт попадает в очередь на индексацию. Сроки индексации различные, например, неделя у Яндекса, месяц – у Рамблера.
Западная поисковая система Google начинает индексировать Ваш сайт только при условии, что на него есть хотя бы одна ссылка. Это обязательное условие индексации для данного поискового указателя.
Индексация ресурсов. Процесс преобразования данных из той формы, в которой они хранятся на Web-страницах, в другие формы, удобные для быстрого просмотра, называется индексацией. В результате индексации и образуется база данных, которую называют поисковым указателем (индексом).
У каждой поисковой системы свои приемы и методы индексации. В частности, перед индексацией большинство систем очищают документ от зарезервированных слов (stop-words), к которым относятся артикли, предлоги, союзы, местоимения и другие слова, имеющие менее 4 символов. Однако не только короткие слова могут быть зарезервированными. Очень распространенные слова, такие как Computer и Интернет тоже резервируются. Искать что-то по ним бесполезно, так как они встречаются повсеместно.
Специализированные поисковые службы могут использовать и другие слова в качестве зарезервированных. Например, если служба занимается поиском книг (books), то слово book для нее может считаться зарезервированным.
На этапе подготовки к индексации может происходить нормализация слов (stemming) за счет отбрасывания суффиксов и окончаний.
Некоторые системы производят нормализацию всегда. Ряд систем могут действовать как тем образом, так и другим. Служба Alta Vista не производит нормализацию никогда, и эта ее уникальная особенность, активно используется для контекстного поиска.
На основе «зачищенного» документа готовится индекс. Индекс – это особая база данных, созданная специальным образом, чтобы ускорить поиск. Существует множество методов индексации. Приведем простейший тип индекса – обратный файл. Суть обратного файла состоит в том, что составляется словарь из всех слов, встреченных во всех документах, собранных поисковым роботом, а затем для каждого слова записывается группа чисел, указывающих на то, в каких документах оно встречается, насколько часто, а также кое-какая служебная информация.
Исполнение запроса клиента. Поисковая система анализирует ключевые слова, которые клиент использовал в запросе. С ними производятся те же операции освобождения от зарезервированных слов и нормализации, после чего выполняется поиск совпадений с содержимым поисковых индексов. Эти операции в большинстве поисковых систем происходят примерно одинаково, но самая последняя операция, когда по найденным совпадениям формируется итоговый список ссылок, всегда различается. У каждой поисковой системы своя политика формирования результирующего списка.
Итак, если найдено очень много ссылок на ресурсы, удовлетворяющие запросу, то встает проблема их упорядочения. Здесь важно, какие ссылки дать в начале списка, а какие – в конце, то есть, надо вводить какой-то рейтинг. Разные поисковые системы имеют разные рейтинговые системы. При исчислении рейтинга учитывается множество параметров. За некоторые начисляются положительные баллы, а за некоторые – наоборот штрафные. Положительный рейтинг начисляется, в частности, при следующих обстоятельствах:
• если разыскиваемые слова встречаются на Web-странице неоднократно (но не слишком часто, и не подряд);
• если они расположены близко к началу страницы;
• если эти слова присутствуют в заголовке страницы;
• если Web-страница имеет иллюстрацию, альтернативный текст которой тоже содержит слова, введенные пользователем.
Лучшие поисковые системы ввели свои рейтинговые службы. Одни, например, Яндекс учитывают количество ссылок в проиндексированном пространстве Web, ведущих к данному ресурсу. Другие, например, Рамблер, сортирует сайты по счетчику – числу обращений к ним пользователей. В обоих случаях, – чем больше ссылок на сайт, либо число обращений к сайту, тем выше вероятность того, что она будет полезной автору запроса.
Некоторые поисковые системы (в том числе Alta Vista) повышают рейтинг тем, кто готов за это платить. Такой подход оправдывается тем, что тот, кто заплатил деньги за рейтингование своей страницы, наверное, будет больше уделять внимания и ее качеству.
Поиск по ключевым словам. Поиск документов в базе данных поискового указателя осуществляется с помощью введения запросов в поле поиска. Простой запрос содержит одно или несколько ключевых слов, которые, по вашему мнению, являются главными для данного документа. Можно также использовать сложные запросы, использующие логические операции, шаблоны и так далее.
Через некоторое время после отправки запроса поисковая система вернет аннотированный список URL-адресов документов, в которых были найдены указанные вами ключевые слова. Для просмотра этого документа в браузере достаточно активизировать указывающую на документ ссылку.
Список URL-адресов документа может быть слишком большим. Для того чтобы уменьшить список, можно в поле поиска ввести дополнительные ключевые слова или воспользоваться каталогом поисковой системы.
При поиске для каждого нужного документа вычисляется величина релевантности содержания этого документа поисковому запросу. Список найденных документов перед выдачей пользователю сортируется по этой величине в порядке убывания.
Релевантность документа зависит от следующих факторов:
• Частота искомых слов;
• Вес слова или выражения, заданный пользователем;
• Факт расположения искомых слов в заголовке документа;
• Операторы, применяемые в запросе, их области действия;
• Близость искомых слов в тексте документа друг к другу.
При поиске информации в Интернет в каждом конкретном случае надо действовать по-разному. Общие рекомендации таковы:
• Работать с несколькими поисковыми указателями или, если Вы ищите конкретный запрос по тематике – привлекать к поиску и специализированные каталоги.
• Выделение тематических и географических регионов поиска. Для поиска документов на русском языке лучше использовать русские поисковые серверы. Это связано с тем, что на их зарубежных аналогах эти документы представлены в небольших количествах.
• Начинать поиск надо с короткого запроса – один - два слова. Конкретизировать информацию можно, используя флажок «Искать в найденном».
• Точнее (конкретнее) формулировать задание на поиск, руководствуясь синтаксисом выбранного поискового инструмента.
• Составление тезауруса. Переход от описания предметной области к формализованным описаниям, и построение в конечном счете формального текста, т. е. составление списка ключевых слов.
Ниже приводятся некоторые, часто используемые правила записи комбинации ключевых слов. Для эффективного поиска на конкретном поисковом сервере необходимо уточнить эти правила в его справочной системе, однако и это не гарантирует, что поиск будет проведен «строго по правилам».
В случае использования кавычек поисковая система разыскивает документы, в которых абсолютно точно есть тот текст, который в них заключен, например, «стихи Пушкина». Поиск с помощью кавычек называется контекстным поиском.
Поисковые системы – AltaVista, Excite, GoTo, Infoseek, Yahoo!, Яndex рассматривают группу слов, введенных через пробел, как задание на поиск любого из этих слов.
Поисковые системы – Google, Aport 2000 и Rambler (в режиме простого поиска), наоборот, ищут Web-страницы, где одновременно присутствуют все использованные ключевые слова.
Если вы хотите, чтобы слова из запроса обязательно были найдены, поставьте перед каждым из них «+».
Если вы хотите исключить какие-либо слова из результата поиска, поставьте перед каждым из них «-».
Например, если Вам нужно описание Парижа без рекламы турагентств, то запрос может иметь вид: +путеводитель +Париж - агентство - тур. Обратите внимание, знак «-» надо писать через пробел от предыдущего и слитно с последующим словом.
В системе Rambler знак «+» (или несколько знаков «+») можно использовать для увеличения весового коэффициента при рейтинговании результатов.
Некоторые из крупнейших поисковых служб поддерживают нормализацию слов по умолчанию, то есть, они уже учитывают сокращение слов до основы, и поэтому в них не надо использовать подстановочный символ «*».
Подстановочный символ «*» можно использовать в поисковых системах: Alta Vista и Yahoo!. Если запрос сформулировать следующим образом: +стих* +Пушкин* то его результаты будут шире, чем в случае: +стихи +Пушкина.
Если в ключевых словах есть прописные буквы, то поисковые системы разыскивают тексты, в которых слова записаны точно такими же буквами. Если в ключевых словах есть строчные буквы, то регистр букв в Web-странице не различается. Например, поиск по словам: + красная + шапочка вернет результаты, в которых будут и красная шапочка, и Красная шапочка, и красная Шапочка, и Красная Шапочка.
С другой стороны, поиск по словам: + Красная + Шапочка, даст гораздо более узкий результат: Красная Шапочка.
Вместо одного слова, в запросе можно подставить целое выражение. Для этого его надо взять в скобки. Например, запрос: (история, технология, изготовление) /+1 (сыра, творога) задает поиск документов, которые содержат любую из фраз: «история сыра», «технология творога», «изготовление сыра», «история творога». Здесь знаки «/+1» используются (в Яndex), чтобы ограничить максимальное расстояние между выражениями – единицей, что означает, что слова должны идти подряд.
Многие поисковые системы позволяют разыскивать Web–страницы по тесту, содержащемуся в заголовках. Такой поиск существенно уменьшает количество возвращаемых ссылок, но очень точно выводит нужные материалы. Например, если нужны данные для доклада о Солнечной системе, то имеет смысл искать не просто словосочетание «Солнечная система», а страницы, в которых это сочетание присутствует в заголовке. Командой такого поиска является title:, например: Title: Солнечная система. Поиск заголовков Web – страниц по команде title: поддерживают следующие поисковые системы: Alta Vista, GoTo, HotBot, InfoSeek.
Поисковый каталог Yahoo! имеет команду для поиска заголовков – t:.
Поисковая система Aport 2000 имеет несколько альтернативных команд для поиска заголовков: title=; t= ; заг= ; з= .
В поисковой системе Яndex команда поиска заголовка записывается в виде:
$ title (Солнечная система), а в поисковой системе Rambler через двоеточие: $ title: Солнечная система.
Применяется для того, чтобы увеличить релевантность документов, содержащих «взвешенное» выражение.
Синтаксис: Слово: число или (поисковое _выражение): число.
Сам по себе поиск Web-узлов используется достаточно редко, но команды этого поиска часто применяются для сокращения числа ссылок, возвращенных другими методами с целью ограничения их одним Web-узлом или, наоборот, исключения некого Web-узла из результатов поиска. Одной из команд такого поиска является команда host. В команду можно включать не полное доменное имя сервера, а только его часть, например, только имя домена.
Этот поиск похож на поиск Web-узлов, только команда другая – URL для Alta Vista, u: для Yahoo!. В России поисковая система Яndex использует команду #url =, после которой следует записать URL-адрес в кавычках. Поисковая система Aport 2000 обходится более простым синтаксисом, например: url = www. *****, а в поисковой системе Rambler команда должна начинаться с символа «$», например: $ url: www. *****.
Главная проблема при работе с поисковыми средствами заключается в том, что они извлекают множество документов, не вполне соответствующих целям поиска. Например, страницы, содержащие ключевое слово, но использующие его не в том контексте, какой нужен. Подобное явление получило название ложное попадание (false drops).
Для достижения лучших результатов используют расширенные поисковые команды. В большинстве поисковых систем команды расширенного поиска формируются с помощью логических команд и рассчитаны на профессионалов. Удобство использование логических команд в частности связанно с тем, что команды простого поиска у многих поисковых систем реализованы по-разному. Каждая система стремится сделать средства простого поиска наиболее удобными, а средства расширенного поиска – наиболее стандартными.
Для логических операций «одинарный» оператор имеет смысл операции в пределах абзаца, «двойной» – пределах документа. Аргументом операторов являются слова или фразы. Операторы приведены в порядке убывания приоритета, при этом приоритет у операторов пересечения и исключения – одинаковый. Порядок действия операторов можно изменить расстановкой скобок.
&, && – логическое пересечение (И)
~, ~ ~ – логическое исключение (И НЕ)
«ô» или «,» – логическое объединение (ИЛИ)
Например, по запросу: рецепты && (плавленый сыр) будут найдены документы, в которых есть и слово рецепты и словосочетание (плавленый сыр).
Знак, тильда «~» (не), позволит найти документы с предложением, содержащим первое слово, но не содержащим второе. Например, по запросу: банки ~ закон будут найдены документы, содержащие слово банки, рядом с которым (в пределах абзаца) нет слова закон.
Чтобы найти Web-страницы, содержащие любое из ключевых слов, нужно между словами можно поставить знак «|» (или). Например, запрос: фото | фотография | фотоснимок | снимок задает поиск документов, содержащих хотя бы одно из перечисленных слов.
Логическая команда OR (или) служит для формирования поискового задания из нескольких ключевых слов, если надо, чтобы разыскиваемый документ содержал любые из этих слов в любой комбинации.
Команду OR поддерживают абсолютное большинство основных поисковых служб. Yahoo! по умолчанию выполняет поиск по принципу ИЛИ, если через пробел задано несколько ключевых слов, и поэтому не нуждаются в этой команде. Лишь поисковая система Google вообще не имеет таких средств.
Aport 2000 позволяет использовать как английское ключевое слово OR, так и русское ИЛИ. Можно также использовать знак «|».
Система Rambler использует слово OR, или знак «|».
Система Яndex – только знак «|».
Логическая команда AND (и) служит для формирования поискового задания, когда надо, чтобы разыскиваемый документ содержал одновременно все слова, введенные пользователем. Это аналогично команде «+» простого поиска.
Команду AND поддерживают абсолютное большинство основных поисковых служб.
Google и Yahoo! вместо AND используют знак «+»:
Aport 2000 позволяет использовать как английское ключевое слово AND, так и русское И, а также знаки «&» и «+».
Система Rambler использует ключевое слово AND или знак «&».
Система Яndex знак «&» или пробел, если требуется одновременное присутствие слов в одном предложении, или пару знаков «&», если требуется одновременное присутствие слов во все документе.
Логической командой NOT (не) устанавливают исключение из результатов поиска, то есть это аналогично рассмотренной выше команде простого поиска «-». Эту команду поддерживает большинство служб за исключением: Google, Infoseek, LookSmart, Yahoo!

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
