

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Тема 8. Элементы математической статистики
План:
1. Основные понятия математической статистики
2. Выборочный метод
3. Числовые характеристики выборки
4. Интервальные оценки, доверительные интервалы для параметров нормального распределения
Теоретические сведения
Наука "теория вероятностей" неотделима от другой математической науки, которая получила название "математическая статистика". Эти две науки дополняют друг друга во многих, общих и частных вопросах
1. Основные понятия
1.1. Математическая статистика как наука.
Для успешного функционирования человеческого общества требуется различные сведения о людях, входящих в него. Это, например, сведения о числе жителей, число детей, мужчин и женщин, стариков, рожденных в определенный год. Часто требуются сведения об образовании, наличии вооружения, денежных средств. Таковые сведения и им подобные образуют статистические данные. Их часто называют вариантами, переменными, значениями, величины и др. Над статистическими данными можно проводить определенные математические операции, по ним можно строить прогнозы, оценивать их достоверность. Всем этим занимается мат математическая наука, которая получила название «математическая статистика" Таким образом, в математике сформировалась новая область, изучающая общие закономерности статистических данных или явлений и взаимосвязи между ними.
Статистика представляет собой отрасль знаний, которая обрабатывает большие массивы данных
Объектом исследования статистических данных являются однородные массовые явления, которые отличаются друг от друга по единичному показателю или, как говорят, имеют, варьирующие показатели
Предметом исследования статистики является оценка статистических совокупностей, где применяется специальные математико-статистические методы, которые имеют определенную цель при обработке результатов.
Сфера применения математической статистики распространилась во многие, особенно экспериментальные, науки. Так появились экономическая статистика, медицинская статистика, биологическая статистика, статистическая физика и т. д. С появлением быстродействующих ЭВМ возможность применения математической статистики в различных сферах деятельности человека постоянно возрастает. Расширяется ее приложение и к области физической культуры и спорта. В связи с этим основные понятия, положения и некоторые методы математической статистики рассматриваются в курсе "Спортивная метрология".
На современном этапе развития математической статистики и метрологии можно говорить о новом направлении в математике как "Спортивная статистика", как науке об однородных массовых явлениях в практике физкультуры и спорта.
Одним из основных понятий математической статистики являются "статистические данные", которые трактуются как собранные сведения, об одном или нескольких объектах, которые могут подвергаться статистической обработке.
Виды статистических данных:
1. Качественные. Труднодоступные для измерения или не подвергающие измерению, ввиду того, что их невозможно измерить. К таковым можно отнести цвет объекта, результат выполнения операции сравнения (равно, больше, меньше; сильно, слабо),
2. Количественные. Их можно измерять и представить в виде числа общих мер (12 кг. 5м, 10 раз, 15с);
3. Точные. Величина или качество таких данных не вызывают сомнений. Группа состоит из 5 человек, в классе находится 5 столов.
4. Приближенные. Величина или качество которых - вызывает сомнение. Любые измерения приводят к приближенным данным. Например, рост, вес, время. К ним относятся близкие понятия: синий или голубой цвет, мокрый или влажный
5. Определенные (детерминированные). Причины их появления, не появления или изменения известны. Например, 2 + 3 = 5, подброшенный вверх камень обязательно будет в определенный момент иметь вертикальную скорость, равную 0.
6. Случайные. Причины их появляться, не появляться или изменения не известны. Например, пойдет дождь, команда выиграет, результат в беге на 100 будет равен 12,2с, принятая нагрузка вредная.
В большинстве случаев в физической культуре и спорте мы имеем дело с приближенными случайными или случайными данными.
Статистическим признаком называют общее свойство, присущее нескольким статистическим данным. Например, рост игроков команды, результат бега на 100 м, принадлежность объекта к какому-то виду. к виду спорта, частота сердечных сокращений и т. д.
1. 2. Статистические совокупности
Статистической совокупностью называют несколько статистических данных, объединенных в группу хотя бы одним статистическим признаком. Например, спортсмены, имеющие одинаковый разряд, пол, возраст. Общим признаком может служить и некоторый показатель: например, результаты прыжков в длину.
Объемом статистической совокупности называют число данных, входящих в нее. Например, в соревновании участвовали n=20 человек
Различают следующие совокупности:
1. Бесконечные - n=¥. Число элементов таких совокупностей не может быть уставлено ввиду того, что их большое количество (масса планет, число молекул, множество натуральных чисел)
2. Конечные - п - конечное число,
3. Большие - п > 30;
4. Малые - п < 30;
5. Генеральные - содержащие все данные, обусловленные постановкой задачи
6. Выборочные - некоторые части генеральных совокупностей.
Законы, свойства понятия математической статистки и весь ее математический аппарат позволяет не только механически обрабатывать статистические данные, но способствует анализировать, оценивать, сравнивать объекты о или нескольких совокупностей.
При проведении научных методических и иных исследований для чистоты эксперимента организуются одна или несколько контрольных группа и экспериментальных групп. Каждая из них должна быть равносильна остальным по исследуемым показателям. При этом перед экспериментатором и его оппонентами непосредственно могут возникнуть такие вопросы как:
1. Какова должна быть численность групп?
2. Можно ли утверждать то, что в экспериментальной группе не допущена фальсификация фактов?
3. Насколько достоверны полученные результаты?
4. С помощью какого математического аппарата надо обрабатывать полученные данные? и т. д.
Каждый из таких вопросов требует однозначного или приближенного, но с высокой точностью достоверности ответа. Надо отметить, что математическая статистика успешно решая проблемы, возникающие на основе перечисленных вопросов, вооружает исследователей необходимым математическим аппаратом, давая соответствующие теоретические обоснования и практические рекомендации.
2. Выборочный метод
2.1. Генеральная совокупность и выборка
Пусть требуется изучить множество однородных объектов (статистическую совокупность) относительно некоторого качественного или количественного признака, характеризующего эти объекты. Например, если имеется партия деталей, то качественным признаком может служить стандартность детали, а количественным - контролируемый размер детали.
Лучше всего произвести сплошное обследование, т. е. изучить каждый объект. Однако в большинстве случаев по разным причинам это сделать невозможно. Препятствовать сплошному обследованию может большое число объектов, недоступность их. Если, например, нужно знать среднюю глубину воронки при взрыве снаряда из опытной партии, то, производя сплошное обследование, мы уничтожим всю партию.
Если сплошное обследование невозможно, то из всей совокупности выбирают для изучения часть объектов.
Статистическая совокупность, из которой отбирают часть объектов, называется генеральной совокупностью. Множество объектов, случайно отобранных из генеральной совокупности, называется выборкой.
Число объектов генеральной совокупности и выборки называется соответственно объемом генеральной совокупности и объемом выборки.
Если выборку отбирают по одному объекту, который обследуют и снова возвращают в генеральную совокупность, то выборка называется повторной.
Если объекты выборки уже не возвращаются в генеральную совокупность, то выборка называется бесповторной.
На практике чаще используется бесповторная выборка.
Свойства объектов выборки должны правильно отражать свойства объектов генеральной совокупности, или, как говорят, выборка должна быть репрезентативной (от фр. (представительной).
Считается, что выборка репрезентативна, если все объекты генеральной совокупности имеют одинаковую вероятность попасть в выборку, т. е. выбор производится случайно.
Например, для того чтобы оценить будущий урожай, можно сделать выборку из генеральной совокупности еще не созревших плодов и исследовать их характеристики (массу, качество и пр.)- Если вся выборка будет сделана с одного дерева, то она не будет репрезентативной. Репрезентативная выборка должна состоять из случайно выбранных плодов со случайно выбранных деревьев.
Выборка – подмножество всей совокупности и поэтому она может содержать любое число элементов, но не большее, чем объем совокупности. Выборка формируются случайным образом, серийно, по некоторому закону или правилу и др.
2.2. Способы представления и обработки статистических данных
Исследуемая статистическая совокупность в оптимальном варианте должно иметь от 30 до 200 данных.
Большее число данных требует больших усилий при их обработке, меньшее их число не всегда дает достоверные результаты для анализа.
При испытаниях (тестировании, соревнованиях) статические данные, как правило, поступают в произвольном, случайном порядке. Поэтому возникает необходимость эти данные каким-то образом систематизировать, обработать., получить некоторые результаты. которые можно было бы анализировать, сопоставлять и др.
В статистике разработано несколько способов представления и обработки данных. Все они направлены на то, чтобы получить результаты обработки с требуемой точностью и достоверностью. Если число данных велико, то возникает вопрос, нельзя ли их число уменьшить, сжать. Причем это не должно повлиять на численные значения результатов обработки и не привести к спорным или не верным выводам.
К наиболее популярным методам обработки и представления статистических данных выделим следующие:
1. Метод средних величин. Он заключается в получении некоторых средних показателей, которые позволяют анализировать статистические данные.
2. Интервальный способ. Он основан на разбиении исходных численных значений на интервалы
3. Графический способ. Он предназначен для представления некоторых исходных и полученных результатов обработки данных в виде графика, гистограммы на координатной плоскости.
Пусть из генеральной совокупности извлечена выборка, объем которой равен n, которая изучается по нескольким однородным признакам. Признаками может служить любой численный параметр объекта: масса, объем, скорость перемещения и др.
Если некоторый признак xl из совокупности однородных признаков наблюдалось п1 раз, признак х2 - п2 раз, и т. д., то п1+п2 + ... = п - объем выборки.
Наблюдаемое значение признака называются вариантой – одно из наблюдаемых значений х1, x2, … x k.
Вариационный ряд - последовательность вариант, записанная в возрастающем порядке.
Частота - числа наблюдений п1, п2, ... nk
Относительные частоты - отношение соответствующей частоты п1, п2, ... nk к объему их выборки n. Причем сумма всех относительных частот равна единице:

Статистическим распределением выборки называют перечень вариант и соответствующих им частот или относительных частот.
Статистическое распределение можно задать также в виде последовательности интервалов и соответствующих им частот (непрерывное распределение). В качестве частоты, соответствующей интервалу, принимают сумму частот вариант, попавших в этот интервал.
В теории вероятностей под распределением понимают соответствие между возможными значениями случайной величины и их вероятностями, а в математической статистике - соответствие между наблюдаемыми вариантами и их частотами, или относительными частотами.
Задание 8-1.
Варианта xt | 2 | 6 | 12 |
Относительная частота рi | 0,15 | 0,50 | 0,35 |
Варианта xt | 1 | 2 | 3 | 5 |
Относительная | ||||
частота р* | 0,4 | 0,2 | 0,3 | 0,1 |
1. Перейти от частот к относительным частотам в следующем распределении выборки объема п. = 20:
Найдем относительные частоты:
![]()
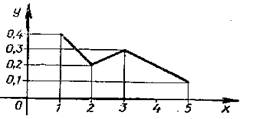
![]()
2. Распределение, представлено таблицей. Построить полигон
Для графического изображения статистического распределения используются полигоны и гистограммы.
Для построения полигона на оси Ох откладывают значения вариант xt, на оси Оу - значения частот рi (относительных частот),
Полигоном обычно пользуются в случае небольшого количества вариант. В случае большого количества вариант и в случае непрерывного распределения признака чаще строят гистограммы. Для этого интервал, в котором заключены все наблюдаемые значения признака, разбивают на несколько частичных интервалов длиной h и находят для каждого частичного интервала nL - сумму частот вариант, попавших в i интервал. Затем на этих интервалах, как на основаниях, строят прямоугольники с высотами g=ni /n. Площадь i-го частичного прямоугольника равна hni/ h=ni. Следовательно, площадь гистограммы равна сумме всех частот т. е. объему выборки. Возможет второй вариант построения гистограмм, когда площадь i-го частичного прямоугольника равна ni / nh и площадь гистограммы равна сумме всех относительных частот или единице.
Задание 8-2. Построить гистограмму непрерывного распределения выборки V=100 (n=100), Хmin=5, X max=40, h=5
Частичный интервал | Частота | Gi= ni /n |
5-10 | 4 | 0,8 |
10-15 | 6 | 1,2 |
15-20 | 16 | 3,2 |
20-25 | 36 | 7,2 |
25-30 | 24 | 4,8 |
30-35 | 10 | 2,0 |
35-40 | 4 | 0,8 |
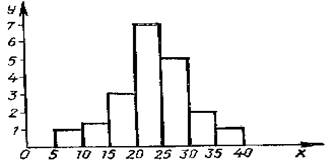
Третий столбик показывает отношение частоты к объему выборки, например:
G1= n1 /n=4:5=0,8; G2= n2 /n=6:5=1,2 и т. д.
2.3. Выборка как набор случайных величин.
Пусть имеется некоторая генеральная совокупность, каждый объект которой наделен количественным признаком X. При случайном извлечении объекта из генеральной совокупности становится известным значение xi признака Xi этого объекта. Таким образом, мы можем рассматривать извлечение объекта из генеральной совокупности как испытание, Xi - как случайную величину, а хi - как одно из возможных значений X.
Допустим, что из теоретических соображений удалось установить, к какому типу распределений относится признак X. Естественно, возникает задача оценки (приближенного нахождения) параметров, которыми определяется это распределение. Например, если известно, что изучаемый признак распределен в генеральной совокупности нормально, то необходимо оценить, т. е. приближенно найти математическое ожидание и среднее квадратическое отклонение, так как эти два параметра полностью определяют нормальное распределение.
Обычно в распоряжении исследователя имеются лишь данные выборки генеральной совокупности, например значения количественного признака x1 х2 …xn полученные в результате п наблюдений (здесь и далее наблюдения предлагаются независимыми). Через эти данные и выражают оцениваемый параметр.
Опытные значения признака X можно рассматривать и как значения разных случайных величин X1 Х2 .., Хn с тем же распределением, что и X, и, следовательно, с теми же числовыми характеристиками, которые имеет X. Значит, М (Хi) = М (X) и D (Xi;) = D (X). Величины X1 Х2 .., Хn можно считать независимыми в силу независимости наблюдений. Значения x1 х2 …xn в этом случае называются реализациями случайных величин Х1, Х2, ..., Хп Отсюда и из предыдущего следует, что найти оценку неизвестного параметра - это значит найти функцию от наблюдаемых случайных величин X1 Х2 .. Хn, которая и дает приближенное значение оцениваемого параметра.
3. Числовые характеристики выборки
3.1. Характеристика положения. К таковым характеристикам относятся все вопросы, касающиеся качественным показателям. В спортивной метрологии разработаны на этот счет соответствующие специальные методы количественной оценки качественных показателей. К ним относятся следующие показатели, получаемые в процессе обработки данных: ранжирование данных среднее арифметическое, медиана, мода. Рассмотрим отдельно каждый из этих показателей:
1. Ранжирование данных – расположение полученных значений признака в порядке возрастания. Одинаковым числовым данным присваиваются очередные последовательные числа. Ранжированные данные представляются в виде таблицы, в которой первый столбик – номера от 1 до n, второй столбик – значения признака.
2.Средне арифметическое (среднее, взвешенное среднее). ![]() , Хср, хср. Вычисляется по формуле:
, Хср, хср. Вычисляется по формуле: 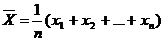 , где n - число данных, хi –числовые данные.
, где n - число данных, хi –числовые данные.
2. Медиана. Ме. В ранжированных данных выбирается номер, находящийся посредине. Если такой номер один, медиана равна значению признака, стоящего под соответствующим номером. Если таковых номеров два, то берется среднее значение признаков, находящихся под этими номерами. Срединный номер можно определить визуально или вычислить по формуле:
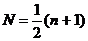 Если полученное число N - целое, то и есть срединный номер. Если число N - дробное, то срединных номеров два. Они непосредственно содержат это дробное число.
Если полученное число N - целое, то и есть срединный номер. Если число N - дробное, то срединных номеров два. Они непосредственно содержат это дробное число.
3. Мода. Мо. Мода значение признака, встречающееся наибольшее число раз. Если несколько признаков встречаются одинаковое число раз, то берется среднее значение этих признаков. Если данные сгруппированы по интервалам, интервал, содержащий Моду, называется модальным интервалом.
Замечания. Вполне вероятно, что все числовые данные окажутся различными, то в этом случае мода равна среднему арифметическому всех значений. Среднее значение, Медиана, Мода в общем случае не совпадают, но в частных случаях они могут совпасть все или попарно. Это дает возможность делать ряд дополнительных выводов и предположений по выборке.
2. Характеристика рассеивания. К таковым характеристикам относится: размах вариации, дисперсия, стандартное (среднее квадратичное) отклонение, коэффициент вариации.
4. Размах R, d, Δ. Вычисляется по формуле R=Хmax - Xmin
5. Дисперсия. δ2. Дисперсия – среднее значение квадратов отклонения каждого значения признака и их среднего значения. Дисперсия вычисляется по формуле:
Таблица 1. Квадрат отклонения | |||
№ | Значение признака xi | Отклонение Xi-Xср | Квадрат отклонения (Xi-Xср)2 |
1 | |||
2 | |||
… | |||
n | |||
Сумма |
δ2=((х1-хср)2+ (х2-хср)2+ (х3-хср)2+….+ (хn-хср)2)/n
Для вычисления дисперсии рекомендуется построить таблицу 1, которая можно получить из таблицы ранжированных значений, добавив к ней третий и четвертый столбики. В третьем столбике записываются отклонения соответствующих значений от среднего, в четвертом столбике – квадраты отклонений. Суммируются значения второго и четвертого столбиков
6. Среднее квадратичное отклонение σ. Вычисляется по формуле: ![]()
7. Коэффициент вариации V. Вычисляется по формуле V=![]() ·100%
·100%
2.1. Генеральная и выборочная средние.
При обработке данных могут быть рассмотренными средние показатели, которые могут быть генеральными или выборочными средними значениями.
Пусть изучается дискретная генеральная совокупность объема N относительно количественного признака X.
Генеральной средней хсред (или а) называется среднее арифметическое значений признака генеральной совокупности.
Если все значения x1 x2, ..., хп признака генеральной совокупности объема N различны, то
![]()
![]()
![]()
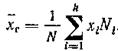
Как уже отмечалось ранее, извлечение объекта из генеральной совокупности есть наблюдение случайной величины X.
![]() Пусть все значения xit xz, ..., хп различны. Так как каждый объект может быть извлечен с одной и той же вероятностью 1 / N, то
Пусть все значения xit xz, ..., хп различны. Так как каждый объект может быть извлечен с одной и той же вероятностью 1 / N, то
![]()
Такой же итог следует, если значения x1t x2, ..., хk имеют соответственно частоты ni, N1, N2, …Nk
В случае непрерывного распределения признака X полагают xсред = М (X).
Пусть для изучения генеральной совокупности относительно количественного признака X произведена выборка объема п.
Выборочной средней называется среднее арифметическое значений признака выборочной совокупности.
Если все значения x1 x2, ..., хп признака выборки объема п различны, то
![]()
![]()
![]()
или
![]()
Задание 8-3. Выборочным путем были получены следующие данные о массе 20 яблок (в г): 30, 30, 25, 32, 30,25,33,32,29, 28, 27, 36, 31, 34, 30, 23.ЯВ. ЯП. Найти выборочную среднюю величину .
Решение:
![]()
Ответ ![]()
Ниже, не уменьшая общности рассуждений, будем считать значения x1 x2, ..., хп признака различными.
Выборочная средняя для различных выборок того же объема п из той же генеральной совокупности будет получаться, вообще говоря, различной. И это не удивительно - ведь извлечение 1- го по счету объекта есть наблюдение случайной величины Xt, а их среднее арифметическое есть тоже случайная величина.
Таким образом, всевозможные могущие получиться выборочные средние есть возможные значения случайной величины X, которая называется выборочной средней случайной величиной.
Найдем М (![]() ), пользуясь тем, что М (Xi) = М (X).
), пользуясь тем, что М (Xi) = М (X).
С учетом свойств МО получаем:
![]()
![]()
Итак, М(Х) (МО выборочной средней) совпадает с а (генеральной средней).
Найдем D (X). Так как D (Хi) = D (X) и X1 X2 … Х„ независимы, то согласно свойствам дисперсии получаем:
![]()
![]()
![]()
![]()
Если варианта хi большие числа, то для облегчения вычисления выборочной средней применяют следующий прием. Пусть С - константа.
Так как
![]()
то:
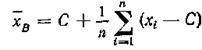
Константу С (так называемый ложный нуль) берут такой, чтобы, разности xi - С были небольшими и число С было "круглым", а именно, оканчивалось нулями.
Задание 8-4. Для заданной выборки найти выборочную среднюю величину.
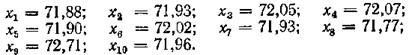
Решение. Берем ложный ноль С - 72,00 и вычисляем разности: ai= xi - С
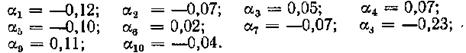
а1 + а2 + … + a10 = -0,38; среднее арифметическое: - =-038: 10 = -0,038» - 0,04.
Выборочная средняя равна разности между ложным нулем и найденным средним значением:
![]()
3.2. Генеральная и выборочная дисперсии.
Для того чтобы охарактеризовать рассеяние значений количественного признака X генеральной совокупности вокруг своего среднего значения, вводят следующую характеристику - генеральную дисперсию.
Генеральной дисперсией Dr называется среднее арифметическое квадратов отклонений значений признака X генеральной совокупности от генеральной средней хг.
Если все значения x1 х2, ..., xN признака генеральной совокупности объема N различны, то
![]()
Если же значения признака хг, х2, ..., xk имеют соответственно частоты N1, N2 … Nk причем ni + N2 + ... + Nk = N, то
![]()
xi | 2 | 4 | 5 | 6 |
Ni | 8 | 9 | 10 | 3 |
Задание 8-5. Найти генеральную дисперсию для генеральной совокупности, заданной таблицей распределения:
Решение.
![]()
![]()
Генеральным средним квадратическим отклонением (стандартом) называется s =
Пусть все значения x1 х2, ..., xN различны.
Найдем дисперсию признака X, рассматриваемого как случайную величину:
![]()
![]()
![]()
![]()
Таким образом, дисперсия D (X) равна Dr.
Такой же итог следует, если значения x1 х2, ..., xk имеют соответственно частоты N1t N2, ..." Nk.
В случае непрерывного распределения признака X по определению полагают:
![]()
![]() Эту формулу можно записать в виде:
Эту формулу можно записать в виде:
![]()
![]()
откуда или
![]() Величина называется средней квадратической ошибкой.
Величина называется средней квадратической ошибкой.
Для того чтобы охарактеризовать рассеяние наблюдаемых значений количественного признака выборки вокруг своего значения вводят выборочную дисперсию.
Выборочной дисперсией DB называется среднее арифметическое квадратов отклонений наблюдаемых значений признака X от выборочной средней ![]() .
.
Если все значения x1 x2, ..., хп признака выборки объема п различны, то
![]()
Если же значения признака x1 x2, ..., хk имеют соответственно частоты n1 n2…nk, причем n1 +n2+…+nk,= n, то
![]()
![]() Выборочным средним квадратическим отклонением (стандартным отклонением) называется квадратный корень из выборочной дисперсии:
Выборочным средним квадратическим отклонением (стандартным отклонением) называется квадратный корень из выборочной дисперсии:
xi | 1 | 2 | 3 | 4 |
nt | 20 | 15 | 10 | 5 |
Задание 8-6. Выборочная совокупность задана таблицей распределения. Найти выборочную дисперсию
Решение.
![]()
![]()
![]()
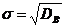 =1
=1
Не уменьшая общности рассуждений, будем считать значения x1 x2,…хп признака различными.
Выборочную дисперсию, рассматриваемую как случайную величину, можно обозначать Ŝ2:
![]()
![]()
![]()
Теорема. МО выборочной дисперсии равно или
Если варианты xj - большие числа, то для облегчения вычисления выборочной дисперсии DB в формулу вводится ложный нуль C:
![]()
Задание 8-7. Для данных задания 8-4 вычислить выборочную дисперсию, ложный нуль оставить равный C = 72,00
Решение.
![]()
![]()
![]()
![]()
3.3. Оценки параметров распределения.
Одной из задач статистики является оценка параметров распределения случайной величины X по данным выборки. Это значит, что по результатам, полученным по некоторой выборке данной совокупности, требуется сделать обобщение, которое распространяется на всю рассматриваемую выборку. Естественно такое обобщение будет не точным.
Выборочная дисперсия Dв считается смещенной оценкой генеральной дисперсии Dг. При этом ведется речь об исправлении выборочной дисперсии так. что бы ее математическое ожидание было равно генеральной дисперсии.
Исправленную дисперсию, как правило, обозначают S2. Доказано, что зависимость между выборочной и генеральной дисперсией находится в следующей зависимости:
S2= n/(n-1)· Dв
Отметим, что если варианты х, - большие числа, то для облегчения вычисления s2 формулу для s2 аналогично преобразуют к виду:
![]()
где С - ложный нуль.
Выборочное среднее квадратичное s считается также смещенным, что бы оно стало исправленным надо воспользоваться соотношением: 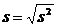
В теоретических рассуждениях считают, что генеральная совокупность бесконечна. Для оценки параметров распределения X из данных выборки составляют выражения, которые должны служить оценками неизвестных параметров.
Можно сразу вычислять исправленную дисперсию, если в формуле для вычисления выборочной дисперсии сумму квадратов отклонений делить не на число n, на число n-1.
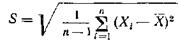
Естественно в качестве приближенного неизвестного параметра брать несмещенные оценки, для того чтобы не делать систематической ошибки в сторону завышения или занижения.
Ясно, что, чем меньше дисперсия оценки, тем меньше вероятность грубой ошибки при определении приближенного значения параметра. Поэтому необходимо, чтобы дисперсия оценки была минимальной. Оценка, обладающая таким свойством, называется эффективной.
Кроме понятия "смещенные оценки", часто рассматривают такое понятие как "состоятельность оценки".
Состоятельной оценкой называют такую оценку Ŵ параметра W, что для любого, заданного числа ε > 0, вероятность P(Ŵn-W)< ε.
Впрочем, любая оценка, предназначенная для практического применения должна быть состоятельной оценкой.
Задание 8-8. С плодового дерева случайным образом отобрано 10 плодов. Их веса (в граммах) записаны в первой колонке приведенной таблицы. Обработать статистические данные выборки.
Решение. Для вычисления хв и s по формулам введем ложный нуль С = 250 и все необходимые при этом вычисления сведем в расчетную таблицу:
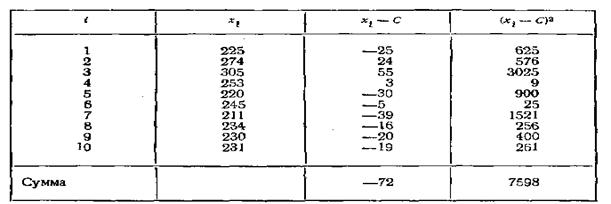
![]()
![]()
![]()
![]() Отсюда:
Отсюда:
Ответ. Генеральная средняя оценка веса плода равна 243 г со средней квадратической ошибкой в 9 г.
Оценка генерального среднего квадратического отклонения веса плода равна 28 г.
4. Интервальные оценки, доверительные интервалы для параметров
нормального распределения
4.1. Надежность, доверительные интервалы.
При оценивании многих параметров можно указать одно число, но на практике мы редко имеем дело с точными результатами, но всегда можно указать некоторый интервал, в который входит полученный результат либо при измерении или при обработке результатов измерений.
Точечной оценкой называется оценка, которая характеризуется одним число.
Например, число элементов в выборке, число проведенных испытаний и др.
Интервальной оценкой называется оценка, которая определяется двумя числами, которые являются концами (границами) интервала. Причем, изменяя длину такого интервала, можно добиться установленной заранее точности и надежности измерения или вычисления.
Точность оценки обозначается буквой δ, (δ>0) является оценкой неизвестного параметра R по его приближенному значению r, вернее, является отклонением r от R не более, чем на δ.
При этом имеет место выражение:
÷R-r÷ < δ
Очевидно, что чем меньше δ, тем точнее оценка.
Надежность оценки обозначается буквой γ, является оценкой вероятности с которой осуществляется неравенство: ÷R-r÷ < δ.
При этом имеет место выражение:
P(÷R-r÷ < δ)= γ
Надежность оценки γ обычно задается заранее, причем надежности γ обычно присваивают одно из значений 0,95, или 0,99, или 0,999.
Доверительным интервалом называется интервал, который покрывает неизвестный параметр с заданной точностью γ.
Понятие "покрывает" можно трактовать, как неизвестный показатель может попасть в доверительный интервал с указанной точностью.
Конечно, нельзя категорически утверждать, что найденный доверительный интервал покрывает параметр r. Но в этом можно быть уверенным на 95% при γ = 0,95, на 99% при γ = 0,99 и т. д. Это значит, что если сделать много выборок, то для 95% из них (если, например, γ = 0,95) вычисленные доверительные интервалы действительно покроют r
Замечание. В ряде учебных пособиях приближенное и точное значение обозначается не буквами R и r, другими, свойственными данному автору буквами. Например , учитывая трудность их написание на компьютере, мы ввели иные буквы, что не меняет сути вопроса.
4.2. Доверительный интервал математического ожидания a при известном среднем квадратичном отклонении σ.
В некоторых случаях среднее квадратическое отклонение σ ошибки измерения (а вместе с нею и самого измерения) бывает известно. Например, если измерения производятся одним и тем же прибором при одних и тех же условиях, то MO для всех измерений одно и то же и обычно бывает известно.
Пусть случайная величина X распределена нормально с параметрами:
a – не известное математическое ожидание,
σ – известное квадратичное отклонение.
Построим доверительный интервал, покрывающий неизвестный параметр а с заданной надежностью γ. Данные выборки есть реализации случайных величин X1 X2, … Хп имеющих нормальное распределение с параметрами а и σ. Оказывается, что и выборочная средняя случайная величина Xсред =(1/n)·(Х1 + Х2 + ... + Хn) тоже имеет нормальное распределение (примется без доказательства).
![]()
Потребуем, чтобы выполнялось соотношение
Р (÷ Xсред - а÷ < δ) = γ, где γ - заданная надежность.
Получим:
![]()
![]()
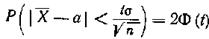
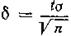
![]()
Так как Р задана и равна γ то окончательно имеем (для получения рабочей формулы выборочную среднюю заменяем на ):
![]()
![]() Здесь число t определяется из равенства 2Ф(t)= γ, которое находится по соответствующей таблице значений.
Здесь число t определяется из равенства 2Ф(t)= γ, которое находится по соответствующей таблице значений.
Точность оценки определяется формулой
Как было сказано выше, надежность γ принимают равной или 0,95, или 0,99, или 0,999.
Смысл полученного соотношения таков: с надежностью γ можно утверждать, что доверительный интервал, отраженный формуле, покрывает неизвестный параметр a – математическое ожидание, с точностью оценки δ.
Задание 8-9. Признак X распределен в генеральной совокупности нормально, σ = 0,40. Найти по данным выборки доверительный интервал для математического ожидания a с надежностью γ = 0,99, если п = 20, ![]() =6,34
=6,34
Решение.
![]()
По таблице значений этой функции находим t=2,56
![]()
Следовательно
Концы доверительного интервала 6,34 - 0,23 = 6,11 и 6,34 + 0,23 - = 6,57.
Ответ. Доверительный интервал (6,11; 6,57[ покрывает а с надежностью 0,99.
4.3. Доверительный интервал для МО при неизвестном среднем квадратичном отклонении σ.
Пусть случайная величина X имеет нормальное распределение с неизвестными нам параметрами а и σ.
По данным выборки можно построить случайную величину T - ее возможные значения будем обозначать через t:
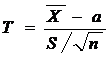 , где n – объем выборки,
, где n – объем выборки, ![]() - выборочная средняя, S - исправленное среднее квадратическое отклонение, имеет распределение, не зависящее от a и σ. Оно называется распределением Стьюдента (псевдоним английского статистика Госсета).
- выборочная средняя, S - исправленное среднее квадратическое отклонение, имеет распределение, не зависящее от a и σ. Оно называется распределением Стьюдента (псевдоним английского статистика Госсета).
Плотность вероятности распределения Стьюдента определяется формулой:
![]()
где коэффициент Вп зависит от объема выборки. Потребуем, чтобы выполнялось соотношение
![]()
где γ - заданная надежность.
Так как S (t, п) - четная функция от t, то, получим:
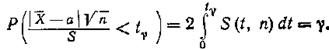
Следовательно, приходим к утверждению: с надежностью γ можно утверждать, что доверительный интервал
![]()
покрывает неизвестный параметр а, точность оценки
![]()
Здесь случайные величины X и S заменены неслучайными величинами и s, найденными по выборке.
В приложении 4 приведена таблица значений t = t (γ, п) для различных значений п и обычно задаваемых значений надежности.
Заметим, что при п ³ 30 распределение Стьюдента практически не отличается от нормированного нормального распределения
Это связано с тем, что
![]()
Задание 8-10. Признак X распределен в генеральной совокупности нормально. Найти доверительный интервал для с надежностью γ = 0,99, если п = 20, ![]() = 6,34, s = 0,40.
= 6,34, s = 0,40.
Решение.
Для γ = 0,99 и п = 20 находим по таблице приложения, что tγ = 2,861.
Следовательно, δ = ![]() =
= ![]() »0,26.
»0,26.
Концы доверительного интервала 6,34 - 0,26 = 6,08 и 6,34 + 0,26 = 6,60.
Ответ. Доверительный интервал (6,08; 6,60) покрывает с надежностью 0,99.
4.4. Доверительный интервал для среднего квадратического отклонения.
Доверительный интервал для среднего квадратического отклонения σ с надежность. γ имеет вид:
(s-sq; s + sq), при q <1 и (0; s + sq), при q >1, точность оценки δ = sq.
Параметр s – исправленное среднее квадратичное отклонение.
Параметр q, зависящий от значений γ и n, устанавливается из специальной таблицы значений q=q (γ;n для различных значений п и обычно задаваемых значений надежности у.
Задание 8-11.
1. Признак X распределен в генеральной совокупности нормально. Найти доверительный интервал для σr с надежностью γ = 0,95, если п = 20, s = 0,40.
Решение. Для γ = 0,95 и п = 20 находим в таблице приложения q = 0,37 < 1
sq = 0,40 • 0,37 » 0,15.
Концы доверительного интервала 0,40 - 0,35 = 0,25 и 0,40 + 0,15 = 0,55.
Ответ. Доверительный интервал (0,25; 0,55) покрывает σr с надежностью 0,95.
2. Дано: Объем выборки n=20, X cред =340, "исправленное" среднее квадратическое отклонение s= 20.
Определить:
1) Доверительный интервал для математического ожидания а с надежностью γ =0,95;
2) Доверительный интервал для среднего квадратического отклонения с той же надежностью.
При решении задачи исходить из предположения, что данные взяты из нормальной генеральной совокупности.
Решение.
1} Согласно условиям задачи = X cред = 340, s = 20, γ = 0.95, п = 20.
Пользуясь распределением Стьюдента, для надежности γ = 0,95 и п = 20 находим в таблице приложения tγ = 2,093. Следовательно,
δ = ![]() =
=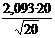 »9,4
»9,4
Концы доверительного интервала ,4 =330,6 и 340 + 9,4 = 349,4.
Ответ. Доверительный интервал (330,6; 349,4) покрывает а с надежностью 0,95.
2) Для надежности γ = 0,95 и п - 20 находим в таблице приложения q = 0,37 <1
sq = 20 · 0,37 = 7,4.
Концы доверительного интервала,4 =12,6 и 20 4+ 7,4 = 27,4.
Ответ 12,6 < а < 27,4,
3. Признак X генеральной совокупности распределен нормально. По выборке объема п = 10 найдено "исправленное" среднее квадратическое отклонение s = 0,16. Найти доверительный интервал для σ с надежностью 0,999.
Решение. Для надежности γ = 0,999 и п = 10 по таблице приложения находим q = 1,80.>1. Доверительный равен 0 < σ < 0,16+ 0,16 ·1,80 или 0 < σ < 0,448.
4.5. Оценка истинного значения измеряемой величины.
Производится п независимых равноточных измерений некоторой физической величины, истинное значение которой а неизвестно, которое надо найти или оценить с достаточной точностью.
Результаты отдельных измерений есть случайные величины Х1, Х2, ..., Хп.
Эти величины независимы - измерения независимы. Имеют одно и то же математическое ожидание а (истинное значение измеряемой величины). У них одинаковые дисперсии D(X)=σ2 (измерения равноточные) и также распределены нормально, что подтверждается опытом.
Таким образом, все предположения, которые были сделаны при выводе доверительных интервалов выполняются поэтому можно использовать полученные в них предложения.
Так как обычно σ неизвестно, следует правилом нахождения доверительного интервала для математического ожидания при неизвестном среднем квадратическом отклонении. пользоваться (пункт 4.3).
Задание 8-12. По данным 9 независимых равноточных измерений физической величины найдены среднее арифметическое результатов отдельных измерений ![]() = 42,319 и "исправленное" среднее квадратическое отклонение s = 5,0. Требуется оценить истинное значение а измеряемой величины с надежностью у = 0,99.
= 42,319 и "исправленное" среднее квадратическое отклонение s = 5,0. Требуется оценить истинное значение а измеряемой величины с надежностью у = 0,99.
Истинное значение измеряемой величины равно ее математическому ожиданию. Поэтому задача сводится к оценке математического ожидания (при неизвестном σ) при помощи доверительного интервала
![]()
покрывающего а с заданной надежностью γ = 0,99.
Пользуясь таблицей приложения 4 по γ = 0,99 и п = 9, находим tv = 3,36.
Найдем точность оценки:
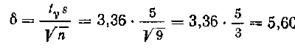
Концы доверительного интервала 42,,60 = 36,719 и 42,319 + 5,60 = 47,919.
Ответ. С надежностью y = 0.99 истинное значение измеренной величины а заключено в доверительном интервале 36,719 < а < < 47,919.
4.6. Оценка точности измерений.
В теории ошибок принято точность измерений (точность прибора) характеризовать с помощью среднего квадратического отклонения σ случайных ошибок измерений.
Для оценки σ используют "исправленное" среднее квадратическое отклонение s.
Поскольку обычно результаты измерений независимы, имеют одно и то же математическое ожидание (истинное значение измеряемой величины) и одинаковую дисперсию (в случае равноточных измерений), то оценка тонности измерений можно произвести согласно утверждениям, рассмотренных в пункте 4.4
Задание 8-13. По 16 независимым равноточным измерениям найдено "исправленное" среднее квадратическое отклонение s = 0,4. Найти точность измерений с надежностью γ= 0,99.
Как отмечено выше, точность измерений характеризуется средним квадратическим отклонением σ случайных ошибок измерений. Поэтому задача сводится к отысканию доверительного интервала вида:
(s – sq; s + sq),
Он покрывает σ с заданной надежностью γ = 0,99 (п. 4.4).
По таблице приложения по γ = 0,99 и п = 16 найдем q = 0,70.
Доверительный интервал
![]()
Ответ ![]()
Примерная тематика практических занятий.
1. Обработка числовых данных методом средних величин.
2. Обработка числовых данных методом интервалов
3. Вычисление математического ожидания нормального распределения; интервальное оценивание вероятности события.
Контрольные вопросы
1. Определение математической статистики как науки и как раздела математики
2. Виды статистических данных и статистических совокупностей.
3. Привести примеры детерминированных и случайных величин. Может ли величина одновременно, отвечать обоим указанным условиям одновременно?
4. Привести примеры статистических признаков.
5. Способы формирования выборки
6. Частота наступления событий
7. Числовые характеристики выборки
8. Генеральные и выборочные показатели.
9. Понятии дисперсии и ее виды.
10. Точечные и интервальные оценки
11. Понятие доверительного интервала.
12. Понятие оценки истинного значения измеряемой величины
Требования к знаниям умениям и навыкам
Студент должен иметь представление о выборке. Иметь понятие о дискретных и интервальных вариационных рядах. Уметь находить основные числовые характеристики выборки, строить полигоны и гистограммы. Иметь представление о точечной оценке для генеральной средней (математического ожидания), дисперсии и среднеквадратического отклонения. Иметь представление об интервальной оценке математического ожидания при известной дисперсии
