

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Министерство общего и специального образования
МОСКОВСКИЙ ГОСУДАРСТВЕННЫЙ ИНСТИТУТ ЭЛЕКТРОНИКИ И МАТЕМАТИКИ
( ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ)
Кафедры ТВМС и ИО
Математическая статистика ( II часть)
Учебное пособие
Москва 2004
Содержание:
Введение................................................................................................... 4
§1.Выборочные моменты. Их свойства.................................................. 5
§2.Свойства точечных оценок............................................................... 12
§3. Достаточные статистики. (д. с.)........................................................ 23
§4.Неравенство Рао-Крамера................................................................ 31
§5.Методы получения точечных оценок.............................................. 37
§6.Доверительное оценивание............................................................... 48
,
Математическая статистика
( II часть) Учебное пособие, изд. МИЭМ,2004г
В пособии подробно изложены вопросы, связанные с решением одной из основных задач математической статистики-параметрической задачи. Приведено много примеров. Рекомендуется всем студентам МИЭМ, изучающим математическую статистику.
Рецензенты:
Введение.
II часть пособия по математической статистике предполагает знание I – ой части и посвящена решению одной из основных задач математической статистики – параметрической задачи. Исходными данными здесь являются – изучаемая случайная величина (с. в.) Х, выборка 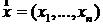 значений с. в. Х с точностью до параметра Ө=(Ө1,..,Ө2). Требуется оценить заданную функцию от
значений с. в. Х с точностью до параметра Ө=(Ө1,..,Ө2). Требуется оценить заданную функцию от ![]() :
: ![]() .
.
Рассматриваются два подхода к решению задачи: точечное и доверительное оценивание. Обсуждаются методы построения таких оценок.
Большое внимание отводится вопросу анализа качества полученных оценок с различных точек зрения и при различной природе неизвестного параиетра распределения с. в. Х.
Изложение теоретического материала сопровождается многочисленными примерами м подробными комментариями, а так же предложены задачи для самостоятельного решения.
Настоящее пособия имеет целью оказание помощи студентам подбором соответствующего материала и пояснениями при решении поставленной задачи.
§1.Выборочные моменты. Их свойства.
1. Начальные сведения.
В качестве оцениваемых функций в параметрической задаче статистики часто встречаются выборочные моменты. Пусть ![]() – наблюдаемая с. в.,
– наблюдаемая с. в., ![]() - выборка объема n.
- выборка объема n.
![]() -
- ![]() - ый начальный выборочный момент; при
- ый начальный выборочный момент; при ![]()
![]() - выборочное среднее;
- выборочное среднее;
![]() -
- ![]() - ый центральный выборочный момент; при
- ый центральный выборочный момент; при ![]() ;
;
![]() - выборочная дисперсия;
- выборочная дисперсия;
![]() - выборочное среднеквадратическое отклонение;
- выборочное среднеквадратическое отклонение;
при ![]() – известном
– известном ![]() -
- ![]() - ый центральный выборочный момент;
- ый центральный выборочный момент;
если выборки значений с. в. ![]() и
и ![]() есть соответственно
есть соответственно ![]() , то
, то ![]() - выборочная корреляция;
- выборочная корреляция;
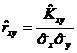 - выборочный коэффициент корреляции;
- выборочный коэффициент корреляции;
![]() - выборочный коэффициент ассиметрии;
- выборочный коэффициент ассиметрии;
![]() - выборочный коэффициент эксцесса.
- выборочный коэффициент эксцесса.
2. Свойства выборочных моментов
Сформулируем их в форме задач.
1). Исследовать ![]() на несмещенность и состоятельность для
на несмещенность и состоятельность для ![]()
![]() -го начального момента (
-го начального момента (![]() )
)
Решение: 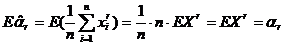 , т. е.
, т. е. ![]() - несмещенная оценка для
- несмещенная оценка для ![]() ; по теореме Хинчина при
; по теореме Хинчина при ![]() имеем, если
имеем, если
![]() , то для с. в.
, то для с. в. ![]() выполняется ЗБЧ, т. е.
выполняется ЗБЧ, т. е. ![]() - состоятельная оценка для
- состоятельная оценка для ![]() . В частности, при
. В частности, при ![]()
![]() - несмещенная состоятельная оценка, для
- несмещенная состоятельная оценка, для ![]() .
.
2). Исследовать на несмещенность и состоятельность ![]() , для
, для ![]() .
.
Решение: ![]() ;
;
![]()
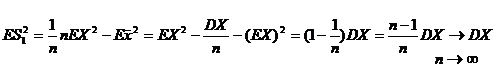 =>
=>
=>![]() - смещенная, но асимптотически несмещенная оценка для
- смещенная, но асимптотически несмещенная оценка для ![]() ; смещение
; смещение 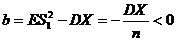 =>
=> ![]() в среднем занижает значение
в среднем занижает значение ![]() : Т. к. смещение линейно, можно его подправить:
: Т. к. смещение линейно, можно его подправить:
![]() ;
; 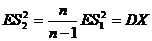 =>
=> ![]() - несмещенная оценка для
- несмещенная оценка для ![]() .
.
Состоятельность ![]() для
для ![]() следует из теоремы Хинчина для
следует из теоремы Хинчина для ![]() и состоятельности
и состоятельности ![]() для ЕХ, так как
для ЕХ, так как ![]() .
.
3). Исследовать ![]() (
(![]() - известно) на несмещенность и состоятельность для
- известно) на несмещенность и состоятельность для ![]()
Решение:
Состоятельность ![]() для
для ![]() следует из теоремы Хинчина, если в качестве
следует из теоремы Хинчина, если в качестве ![]() взять
взять ![]() :
:
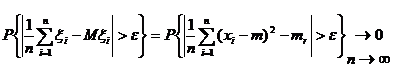 .
.
Отсюда, в частности, следует, что при известном 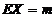
![]() - несмещенная и состоятельная оценка для
- несмещенная и состоятельная оценка для ![]() .
.
4). Исследовать точность и надежность ![]() для
для ![]() .
.
Решение:
Обозначим L(Z) - закон распределения с. в. ![]() .
.
Если P=P(![]() ) , то
) , то ![]() - точность, а P – надежность оценки
- точность, а P – надежность оценки ![]() для m; найдем распределение статистики
для m; найдем распределение статистики ![]() . Обозначим
. Обозначим ![]() ;
; ![]() ;
; 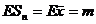 ;
; 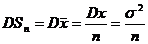 ;
;
![]() .Тогда по теореме Леви
.Тогда по теореме Леви ![]() ;
; ![]() ,
,
P =![]() Таким образом, надежность
Таким образом, надежность ![]() для EX с точностью e есть
для EX с точностью e есть 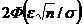 и может быть увеличена за счет выбора большего n.
и может быть увеличена за счет выбора большего n.
Приведем числовые примеры.
C какой вероятностью (надежностью) совершается ошибка ![]() при замене
при замене ![]() на
на ![]() при:
при:
а) ![]() ;
; 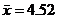 ;
; 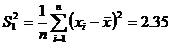 .
.
Решение:
По 4). При 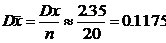 ;
; ![]() ; P=
; P=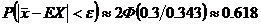 .
.
б). ![]() ; ; .
; ; .
Решение:
![]() ; P=
; P=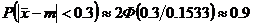 .
.
При сравнении результатов а). и б). наглядно видно повышение надежности P с ростом n.
5. Исследовать на несмещенность ![]() для
для ![]() .
.
Решение:
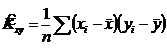 ;
; ![]() ;
; 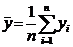 ;
; ![]() .
. ![]() (*)
(*)
![]() т. к.
т. к. ![]() и
и ![]() независимы;
независимы; 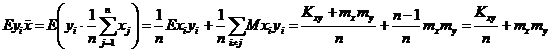 ;
; 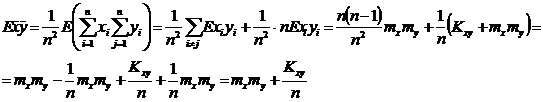
Подставим все это, в выражение (*):
![]() Þ
Þ![]() - смещенная, но асимптотически несмещенная оценка для Kxy. Смещение
- смещенная, но асимптотически несмещенная оценка для Kxy. Смещение 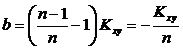 линейное и отрицательное. Подправим смещение оценки
линейное и отрицательное. Подправим смещение оценки ![]() :
: 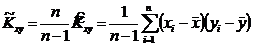 - несмещенная оценка для
- несмещенная оценка для ![]() .
.
3. Законы распределения и моменты статистик ![]() и
и ![]() для
для ![]() .
.
а). 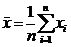 ;
; ![]() ;
; 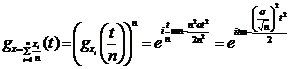 Þ
Þ
Þ 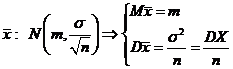
б). 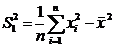
Подвергнем ![]() линейному преобразованию с матрицей преобразования следующего вида:
линейному преобразованию с матрицей преобразования следующего вида:
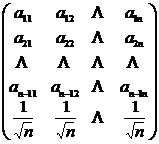 , т. е.
, т. е. 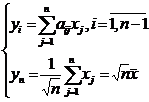 (1)
(1)
при выполнении условий 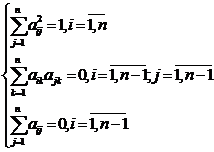 (2)
(2)
Покажем, что (2) – ортогональные преобразования, т. е. (по определению) такие 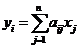 , для которых выполняются условия:
, для которых выполняются условия: 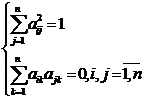 (3)
(3)
т. е. нужно показать, что для данного преобразования (1) условия (2) следуют из условий (3). Действительно, ![]() по (2), (и при
по (2), (и при 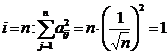 ), а из условия
), а из условия 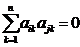 при i=n имеем
при i=n имеем 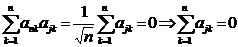 . Таким образом, доказано, что для преобразований (1) выполнены условия (3), а значит (1) – ортогональное преобразование, сохраняющее сумму квадратов:
. Таким образом, доказано, что для преобразований (1) выполнены условия (3), а значит (1) – ортогональное преобразование, сохраняющее сумму квадратов: ![]() .
.
![]() - независимые с. в. как элементы выборки, каждая из которых
- независимые с. в. как элементы выборки, каждая из которых ![]() , значит их совместное распределение нормально (с плотностью, равной произведению их одинаковых плотностей). Известно, что ортогональное преобразование переводит нормальный вектор (
, значит их совместное распределение нормально (с плотностью, равной произведению их одинаковых плотностей). Известно, что ортогональное преобразование переводит нормальный вектор (![]() ) в другой нормальный вектор (
) в другой нормальный вектор (![]() ).
).
Найдем моменты с. в. {![]() } (i=1,n) при условиях (2), обозначив
} (i=1,n) при условиях (2), обозначив 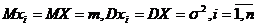 ;
;
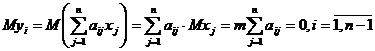 ;
; ![]() ;
; 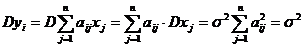 ; при i≠j
; при i≠j 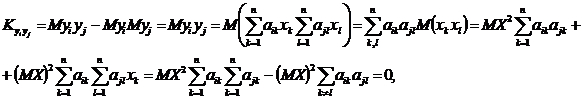
а это значит для нормального вектора (![]() ) независимость его компонент с учетом следующего замечания (без доказательства):
) независимость его компонент с учетом следующего замечания (без доказательства):
Замечание 1. Для гауссовского вектора некоррелированность эквивалентно их независимости.
Т. к. ортогональное преобразование сохраняет сумму квадратов и 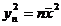 , то верно равенство:
, то верно равенство: 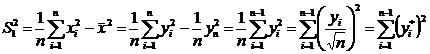 , где
, где ![]() ;
; 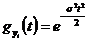 ;
; 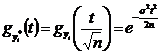 Þ
Þ
Þ 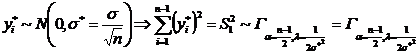 , что соответствует плотности гамма распределения
, что соответствует плотности гамма распределения 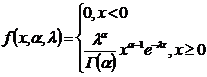 , где
, где 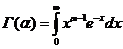 ;
;
![]() ;
; ![]() ;
; 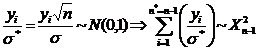
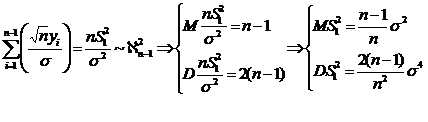
Замечание 2. Не нарушая общности, можно считать, что исходные с. в. ![]() , т. к.
, т. к. ![]() для
для ![]() и
и ![]() для
для ![]() совпадают, покажем это:
совпадают, покажем это: ![]() ;
; ![]() ;
; ![]() , т. к.
, т. к. ![]() . Т. е.
. Т. е. ![]() и
и ![]() совпадают.
совпадают.
Замечание 3. Для матрицы ортогонального преобразования ![]()
![]() (где
(где ![]() - транспонированная матрица, а
- транспонированная матрица, а ![]() - обратная матрица).
- обратная матрица).
Тогда из условий ортогональности (3) ÜÞ условия:
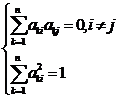 (4)
(4)
, т. е. условия (3) и (4) эквивалентны.
Покажем, что с учетом замечания 2 и эквивалентности условий (2) и (3) для для рассматриваемых преобразований (1) сохраняются суммы квадратов, т. е. 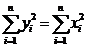 . Действительно:
. Действительно: 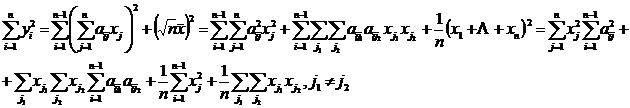
Отдельно вычисляем следующие суммы:
![]() ;
; ![]() , по этому
, по этому 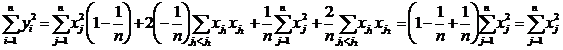 , что и утверждалось.
, что и утверждалось.
Замечание 4. Если 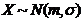 , то
, то ![]() и
и ![]() независимы.
независимы.
Действительно по (1) ![]() , а
, а ![]() , т. е.
, т. е. ![]() и
и ![]() зависят от разных, независимых между собой с. в. соответственно
зависят от разных, независимых между собой с. в. соответственно ![]() и (
и ( ), а значит,
), а значит, ![]() и
и ![]() независимы между собой.
независимы между собой.
§2.Свойства точечных оценок.
1. Задача точечного оценивания
Исследуется случайная величина Х, распределение которой относится к параметрическому множеству ![]() , где
, где ![]() - неизвестный k-мерный параметр. В дальнейшем будем обозначать это короче: X~
- неизвестный k-мерный параметр. В дальнейшем будем обозначать это короче: X~![]() .
.
Имеется выборка наблюденных значений случайной величины X:![]() oбъема n. Требуется построить точечную оценку (статистику) для данной функции
oбъема n. Требуется построить точечную оценку (статистику) для данной функции 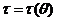 или исследовать качество данной оценки.
или исследовать качество данной оценки.
Замечание. При такой постановке задачи нет проблемы построения оценки для ![]() , так как требования к ее качеству (близости к истинному значению) не высказаны. Математическая задача возникает тогда, когда эти требования математически формализованы. А в связи с тем, что они не все и не всегда выполнимы, будем называть их желательными свойствами оценок.
, так как требования к ее качеству (близости к истинному значению) не высказаны. Математическая задача возникает тогда, когда эти требования математически формализованы. А в связи с тем, что они не все и не всегда выполнимы, будем называть их желательными свойствами оценок.
2. Простейшие свойства точечных оценок ![]()
а). Несмещенность: 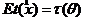 (ЕХ – математическое ожидание с. в. Х) или асимптотическая несмещенность
(ЕХ – математическое ожидание с. в. Х) или асимптотическая несмещенность 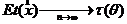
б). Состоятельность: ,т. е.
,т. е. 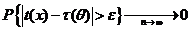 для любого
для любого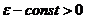 ;
;
в). Эффективность несмещенной оценки характеризуется дисперсией ![]() и используется для сравнения качества несмещенных оценок.
и используется для сравнения качества несмещенных оценок.
Эти свойства или пожелания к качеству точечной оценки объединены стремлением достичь определенной степени концентрации возможных значений оценки 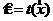 вокруг истинного значения оцениваемой функции
вокруг истинного значения оцениваемой функции![]() .
.
Одновременное выполнение этих желательных свойств не всегда возможно, поэтому представление о «хорошей» оценке зависит от цели и возможностей исследования, определяющих приоритетные свойства оценки. Так, для малых выборок часто важна несмещенность оценки, а для больших – асимптотическая несмещенность и состоятельность. А иногда, сознательно отказываясь от одних свойств оценок, добиваются выполнения других, более важных с точки зрения исследования свойств.
3. Оптимальные оценки.
Если же оценка является несмещенной с минимальной дисперсией, то она называется оптимальной.
Теорема. Если оптимальная оценка существует, то она единственна.
Доказательство (от противного). Пусть не так, т. е. существеут вде оптимальные оценки для :  и
и . Тогда
. Тогда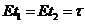 ;
; 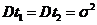 - минимальная возможная дисперсия несмещенных оценок для
- минимальная возможная дисперсия несмещенных оценок для ![]() .
.
Построим оценку 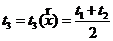 и изучим ее свойства.
и изучим ее свойства. ![]() - снова несмещенная оценка для
- снова несмещенная оценка для ![]() .
.
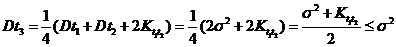 , т. к. по неравенству Коши-Буняковского
, т. к. по неравенству Коши-Буняковского ![]() . Но
. Но ![]() не может быть <
не может быть <![]() по условию. Отсюда следует, что
по условию. Отсюда следует, что ![]() (поэтому
(поэтому ![]() - оптимальная оценка для
- оптимальная оценка для ![]() ), а это значит, что
), а это значит, что 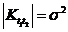 или
или ![]() и t1 и t2 линейно зависимы
и t1 и t2 линейно зависимы ![]() , где a и b – const.
, где a и b – const.
Тогда 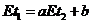 или
или 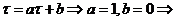
![]() , что и утверждалось.
, что и утверждалось.
4. Общий подход к сравнению оценок
Функция потерь -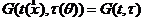 - это любая неотрицательная функция, дающая потерю (ущерб) в результате того, что за принята ее оценка
- это любая неотрицательная функция, дающая потерю (ущерб) в результате того, что за принята ее оценка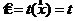 ;
;
Однако, важным являются не единичные потери, а средние при многократном использовании оценки вместо истинного значения оцениваемой функции. Поэтому введем функцию риска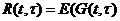 ) - это средние потери относительно выбранной функции потерь.
) - это средние потери относительно выбранной функции потерь.
Часто функция потерь выбирается в виде: ![]() и называется квадратичной функцией потерь, а соответствующий риск
и называется квадратичной функцией потерь, а соответствующий риск 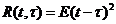 - квадратичным риском.
- квадратичным риском.
Для несмещенных оценок квадратичный риск ![]() , поэтому сравнение качества несмещенных оценок по квадратичному риску лежит в русле этого общего подхода и совпадает с их сравнением по эффективности.
, поэтому сравнение качества несмещенных оценок по квадратичному риску лежит в русле этого общего подхода и совпадает с их сравнением по эффективности.
5. Смещение оценки
Пусть 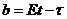 . Тогда b называется смещением оценки t для
. Тогда b называется смещением оценки t для 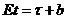 . Если b=0, оценка называется несмещенной, если b>0 (b<0), то оценка в среднем завышает (занижает) истинное значение оцениваемой функции. В случае линейного смещения его легко устранить, т. е. подправить оценку по смещению. Пусть
. Если b=0, оценка называется несмещенной, если b>0 (b<0), то оценка в среднем завышает (занижает) истинное значение оцениваемой функции. В случае линейного смещения его легко устранить, т. е. подправить оценку по смещению. Пусть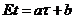 , где a и b – const, тогда получаем, что
, где a и b – const, тогда получаем, что 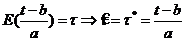 - несмещенная оценка для
- несмещенная оценка для ![]() .
.
6. Связь смещения, квадратичного риска и дисперсии оценки.
Пусть 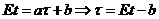 ; тогда
; тогда 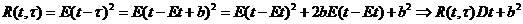 - эта формула часто упрощает вычисление квадратичного риска.
- эта формула часто упрощает вычисление квадратичного риска.
7. Достаточное условие состоятельности несмещенных и асимптотически несмещенных оценок
Теорема 1. Для состоятельности несмещенной оценки ![]() достаточно, чтобы
достаточно, чтобы ![]() .
.
Доказательство. Пусть 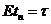 и
и  воспользуемся неравенством Чебышева
воспользуемся неравенством Чебышева![]() , получив
, получив ![]() или, с учетом несмещенности t для
или, с учетом несмещенности t для![]() :
: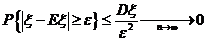 , откуда и следует утверждение.
, откуда и следует утверждение.
Теорема 2. Для состоятельности асимптотически несмещенной оценки t для ![]() достаточно, чтобы .
достаточно, чтобы .
Доказательство. Пусть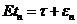 ;
;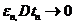 ;
;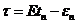 . Рассмотрим событие
. Рассмотрим событие 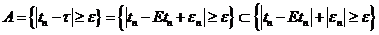 =
=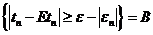 , тогда из того, что
, тогда из того, что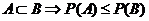 , тогда по неравенству Чебышева имеем
, тогда по неравенству Чебышева имеем![]() , что и доказывает утверждение.
, что и доказывает утверждение.
Замечание. Результаты этих теорем в указанных условиях часто упрощают установление состоятельности.
8. Выборочные моменты
Выборочные моменты – распространенный вид оцениваемых функций от неизвестного параметра ![]() распределения с. в. Х. Приведем сначала наиболее общие формы выборочных моментов (
распределения с. в. Х. Приведем сначала наиболее общие формы выборочных моментов (![]() - выборка)
- выборка)
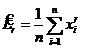 - начальный r-ый выборочный момент; при r=1
- начальный r-ый выборочный момент; при r=1 ![]() - выборочное среднее с. в. Х;
- выборочное среднее с. в. Х; 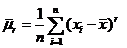 центральный r-ый выборочный момент; при r=2
центральный r-ый выборочный момент; при r=2 ![]() - выборочная дисперсия. При известном EX=m _
- выборочная дисперсия. При известном EX=m _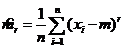 - выборочный r-ый центральный момент.
- выборочный r-ый центральный момент.
![]() - выборочная корреляция (здесь
- выборочная корреляция (здесь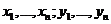 - выборки значений соответственно с. в. X и Y);
- выборки значений соответственно с. в. X и Y);
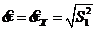 - выборочное среднее квадратичное отклонение с. в. Х,
- выборочное среднее квадратичное отклонение с. в. Х,
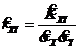 - выборочный коэффициент корреляции;
- выборочный коэффициент корреляции;
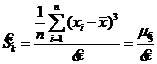 - выборочный коэффициент асимметрии;
- выборочный коэффициент асимметрии;
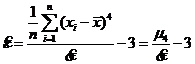 - выборочный эксцесс.
- выборочный эксцесс.
9. Примеры
9.1 примеры на определение свойств оценок.
1). Проверить на состоятельность и несмещенность выборочное среднее 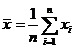 для математического ожидания ЕХ.
для математического ожидания ЕХ.
Решение.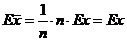 , то есть статистика
, то есть статистика ![]() – несмещенная оценка для ЕХ.
– несмещенная оценка для ЕХ.
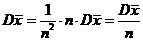 при
при![]() , откуда следует и состоятельность статистики
, откуда следует и состоятельность статистики ![]() для ЕХ. Этот факт сразу следует и из теоремы Хинчина (ЗБЧ).
для ЕХ. Этот факт сразу следует и из теоремы Хинчина (ЗБЧ).
Замечание 1. Отсюда получаем, например, что статистика ![]() есть несмещенная состоятельная оценка для параметра L распределения Пуассона П(L), параметра a нормального распределения N(а, б).
есть несмещенная состоятельная оценка для параметра L распределения Пуассона П(L), параметра a нормального распределения N(а, б).
Замечание 2. Если при исследовании смещенности оценки Т(х) получается линейная функция L от параметра Q, то для построения несмещенной оценки для Q нужно применить к оценке Т(х) преобразование![]() .
.
2). Проверить на состоятельность и несмещенность выборочную дисперсию 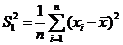 для дисперсии DX.
для дисперсии DX.
Решение. Преобразуем выражение для ![]() :
:
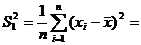
![]()
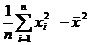 (1)
(1)
Тогда 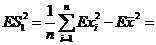
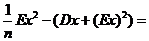
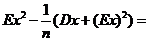
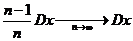 , то есть,
, то есть, ![]() - смещенная, но асимптотически несмещенная оценка для DX. Подправим оценку
- смещенная, но асимптотически несмещенная оценка для DX. Подправим оценку ![]() для DX. По замечанию 2 оценка
для DX. По замечанию 2 оценка ![]() - несмещенная оценка для DX.
- несмещенная оценка для DX.
Состоятельность оценки ![]() для DX следует (по определению) из теоремы Хинчина, примененной к каждому слагаемому выражения (1).
для DX следует (по определению) из теоремы Хинчина, примененной к каждому слагаемому выражения (1).
3). Самостоятельно показать, что статистика ![]() при известном значении ЕХ = m является несмещенной для дисперсии.
при известном значении ЕХ = m является несмещенной для дисперсии.
В дальнейшем будем использовать обозначение L(X) – закон распределения с. в. X.
4). L(X) = R[0,Q]. Проверить свойства оценки ![]() для Q.
для Q.
Решение.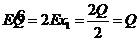 ;
; 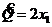 от объема выборки n не зависит, поэтому при
от объема выборки n не зависит, поэтому при ![]() не сходится к Q, то есть является несостоятельной оценкой для Q. Здесь мы имеем пример несмещенной и несостоятельной оценки для Q.
не сходится к Q, то есть является несостоятельной оценкой для Q. Здесь мы имеем пример несмещенной и несостоятельной оценки для Q.
5). L(X) = R[0,Q]. Проверить свойства оценки ![]() для Q. В случае смещенности подправить ее.
для Q. В случае смещенности подправить ее.
Решение.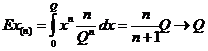 , то есть данная оценка
, то есть данная оценка ![]() является смещенной, но асимптотически несмещенной. Подправим ее. По замечанию 2 получаем, что оценка
является смещенной, но асимптотически несмещенной. Подправим ее. По замечанию 2 получаем, что оценка ![]()
![]() - несмещенная оценка для параметра Q.
- несмещенная оценка для параметра Q.
Для исследования состоятельности оценки ![]() вычислим дисперсию оценки
вычислим дисперсию оценки ![]() :
:
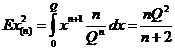 ;
;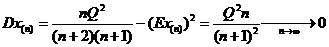 , откуда следует, что оценки
, откуда следует, что оценки ![]() и
и ![]() являются состоятельными.
являются состоятельными.
6). С. в. Х распределена по закону Коши![]() . Состоятельна ли оценка
. Состоятельна ли оценка 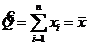 для Q?
для Q?
Решение. Функция распределения закона Коши есть ![]() .
.
Характеристическая функция (х. ф.) с. в. Х ![]()
Х. ф. с. в.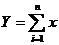 ;
;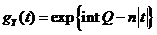 ;
;
Х. ф. с. в.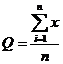 ;
;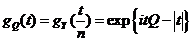 , то есть с. в. X и Q имеют одинаковое распределение (данное распределение Коши).
, то есть с. в. X и Q имеют одинаковое распределение (данное распределение Коши).
![]() = =
= =![]() при
при![]() , что означает несостоятельность приведенной оценки
, что означает несостоятельность приведенной оценки ![]()
 для Q.
для Q.
9.2 Примеры на простейшие свойства точечных оценок.
1). Найти распределение и моменты статистики 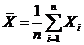 если Х~N (m,
если Х~N (m,![]() ) ,
) , ![]() - выборка значений λ.
- выборка значений λ. ![]() ;
;
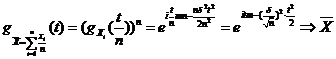 ~N(m,
~N(m, M
M![]() =m; D
=m; D![]() =
=![]() .
.
Примеры, когда несмещенной оценки нет:
2). Х~R[0,![]() ] ;
] ; 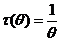 . Пусть t(x)- несмещенная оценка для , тогда
. Пусть t(x)- несмещенная оценка для , тогда ![]() =
=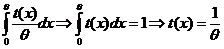 , но это не статистика
, но это не статистика ![]() несмещенной оценки для
несмещенной оценки для ![]() нет.
нет.
3). Х~![]() ;
;![]() . Пусть t(x)- несмещенная оценка для , тогда
. Пусть t(x)- несмещенная оценка для , тогда ![]() =
=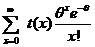 или
или 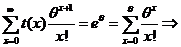 , т. е. это не статистика
, т. е. это не статистика ![]() несмещенной оценки для
несмещенной оценки для ![]() нет.
нет.
Примеры бесполезных (осциллирующих) несмещенных оценок
4). Х~Г(![]() );
);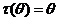 ; Р(X=x)=
; Р(X=x)=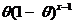 ,
, ![]()
![]() [0;1], x=1,2,… Пусть t(x)- несмещенная оценка для , тогда
[0;1], x=1,2,… Пусть t(x)- несмещенная оценка для , тогда ![]() =
=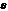
![]()
![]()
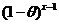 =1
=1![]() t(x)=
t(x)=![]() - это «плохая» оценка для , т. к.
- это «плохая» оценка для , т. к. ![]() - вероятность успеха в одном опыте и не равна нулю по смыслу, кроме того, оценка t(x) дает нулевую вероятность успеха в одном опыте, если успех не происходит в первом опыте, что не соответствует действительности.
- вероятность успеха в одном опыте и не равна нулю по смыслу, кроме того, оценка t(x) дает нулевую вероятность успеха в одном опыте, если успех не происходит в первом опыте, что не соответствует действительности.
5). Х ~![]() ;
; ![]()
![]() [0;
[0;![]() );
); ![]() . Пусть t(x)- несмещенная оценка для
. Пусть t(x)- несмещенная оценка для ![]() , тогда
, тогда ![]() =
=![]()
![]()
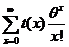 =
=![]()
![]() =
=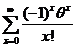
![]() t(x)=
t(x)=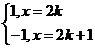 , k=0,1,2,…- это «плохая» оценкадля
, k=0,1,2,…- это «плохая» оценкадля 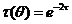 , т. к.
, т. к. ![]() >0, и t(x) реагирует только на четность значения с. в. Х.
>0, и t(x) реагирует только на четность значения с. в. Х.
6). Х~B(m=,p); ![]() ;
;![]() - предлагаемая оценка для
- предлагаемая оценка для ![]() .
.
E![]() = E
= E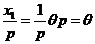
![]()
![]() - несмещенная оценка для
- несмещенная оценка для ![]() ; D
; D![]() = E
= E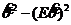 = =
= =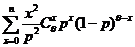 =
= 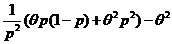 =
= 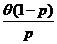 +
+![]() -
-![]() =
=
Если p близко к 1, то D![]() мала и
мала и ![]() - «хорошая» оценка для
- «хорошая» оценка для ![]() ,а при p малом D
,а при p малом D![]() велика и
велика и ![]() - «плохая» оценка для
- «плохая» оценка для ![]() . Значения
. Значения ![]() не целые, поэтому в качестве оценок для
не целые, поэтому в качестве оценок для ![]() следует выбрать натуральные числа, ближайшие к
следует выбрать натуральные числа, ближайшие к ![]() .
.
Примеры несостоятельных оценок.
7). Х~R[0, ![]() ]; ;
]; ;![]() =2
=2![]() ; E
; E![]() =2E
=2E![]() =2
=2![]() =
=![]()
![]()
![]() - несмещенная оценка для
- несмещенная оценка для ![]() , но
, но ![]() - несостоятельная оценка, т. к. не зависит от n.
- несостоятельная оценка, т. к. не зависит от n.
8). Х~![]() ;
; ![]() =
=![]() ; E
; E![]() =
=![]() , но
, но ![]() несостоятельная оценка, т. к. не зависит от n.
несостоятельная оценка, т. к. не зависит от n.
9). Пример несостоятельной оценки, зависящей от n. Х~Коши с плотностью распределения f (x, ![]() )=
)=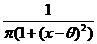 ;
; ![]() =
=![]() ; F(x)=
; F(x)= ; характеристическая функция
; характеристическая функция ![]() =
=![]() , тогда
, тогда ![]() = exp
= exp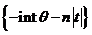 ;
; ![]() =
=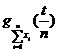 =
=![]() =
=![]()
![]()
![]() =P
=P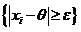 = 1-P
= 1-P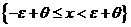 = 1-
= 1-
-(F(ε+![]() )-F(-ε+
)-F(-ε+![]() ))= 1-
))= 1-![]() при
при![]() , а это означает несостоятельность оценки
, а это означает несостоятельность оценки ![]()
Определение
Несмещенная оценка с минимальной дисперсией называется оптимальной.
10). Теорема единственности оптимальной оценки
Пусть 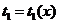 и
и 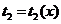 - две оптимальных оценки для
- две оптимальных оценки для ![]() с дисперсией. Тогда
с дисперсией. Тогда 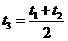 тоже несмещенная оценка для
тоже несмещенная оценка для![]() , т. к.
, т. к. ![]()
![]()
![]() .
. ![]() , т. к. по неравенству Коши-Буняковского
, т. к. по неравенству Коши-Буняковского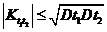 . Но
. Но ![]() - минимальная возможная дисперсия несмещенных оценок для
- минимальная возможная дисперсия несмещенных оценок для 
![]()
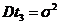
![]()
![]()
![]()
![]()
![]() и
и ![]() линейно зависимы
линейно зависимы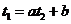 , где a и b – const. Из несмещенности оценок
, где a и b – const. Из несмещенности оценок ![]() и
и ![]()
![]()
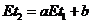 или
или ![]() , что и утверждалось.
, что и утверждалось.
9.3 Примеры на сравнение качества оценок по среднему квадратичному риску.
11). Х~R[0,![]() ]; =
]; =![]() ;
;![]() ;
;![]() ;
;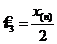 . Проверим их на несмещенность:
. Проверим их на несмещенность: ![]()
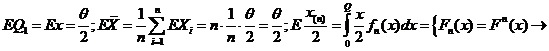
![]() при
при
![]()
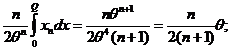
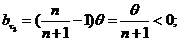
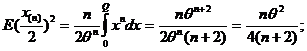
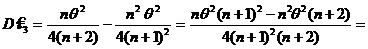
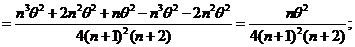
![]()
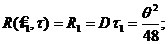
![]()
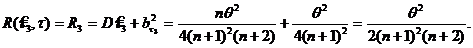
Теперь при n=1,2,… можно сравнивать риски данных оценок.
12) Х~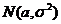 . Сравнить по риску оценки для
. Сравнить по риску оценки для ![]() :
: ![]() и
и![]() .
.
Решение. Раньше получено, что ![]() - смещенная оценка для
- смещенная оценка для ![]() со смещением
со смещением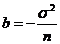 ;
; ![]() - несмещенная оценка (
- несмещенная оценка (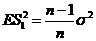 ;
;![]() )
)
Т. к. элементы выборки 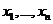 связаны равенством
связаны равенством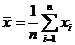 , то
, то ![]() ~
~![]()
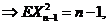
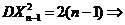
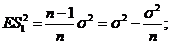
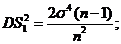
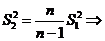
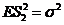 ;
;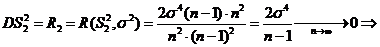
![]() - состоятельная оценка для
- состоятельная оценка для ![]() (состоятельность
(состоятельность ![]() для
для ![]() определена раньше)
определена раньше)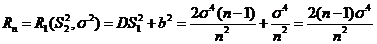 . Сравним
. Сравним ![]() и
и![]() : при n>1
: при n>1 ![]() <
<![]() , т. е.
, т. е. ![]() по риску лучше, чем
по риску лучше, чем ![]() .
.
9.4 Примеры на построение «лучшей» оценки из данного класса
При выборе оценок часто ограничиваются рассмотрением определенного класса оценок. Тогда в пределах этого класса при установлении приоритетных требований ищется «лучшая» в указанном смысле оценка.
1). Х~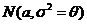 ,
, ![]() - неизвестный параметр. В классе оценок
- неизвестный параметр. В классе оценок ![]() построить оценку
построить оценку ![]() для
для ![]() с наименьшим квадратичным риском. Найти
с наименьшим квадратичным риском. Найти![]() .
.
Решение. Ранее рассматривались следующие оценки для![]() : и
: и 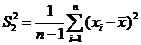 .
.
Получено, что ![]() - смещенная, но асимптотически несмещенная оценка для
- смещенная, но асимптотически несмещенная оценка для ![]() (,
(,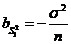 - смещение оценки для
- смещение оценки для![]() );
); ![]() - несмещенная оценка для
- несмещенная оценка для![]() .
. ![]() ~
~![]() (выборка связана равенством)
(выборка связана равенством)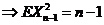 ;
;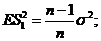 _
_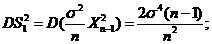 ;
;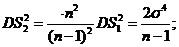
![]() = =
= =![]()
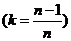 ;
;![]() =
=![]()
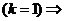
![]() и
и ![]()
![]() . Найдем квадратичный риск оценки
. Найдем квадратичный риск оценки ![]() (k):
(k):
![]()
![]()
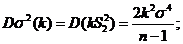
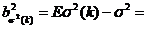
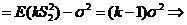
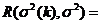
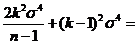
![]()
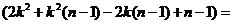
![]()
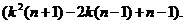 Найдем
Найдем 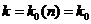 при котором f(k)=
при котором f(k)=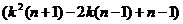 достигает минимального значения и при этом значении
достигает минимального значения и при этом значении ![]() риск оценки
риск оценки ![]() (k)
(k) 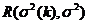 будет минимален.
будет минимален.
Искомое значение ![]() - абсцисса вершины параболы f(k)
- абсцисса вершины параболы f(k)![]() , тогда искомая оценка из V(k) с минимальным риском
, тогда искомая оценка из V(k) с минимальным риском ![]() =
=![]()
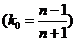 =
=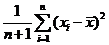 .
.
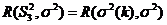 =
=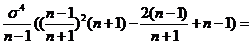
![]() .
.
2). ![]() и
и ![]() - независимые оценки для
- независимые оценки для![]() :
: ![]()
![]()
![]() ,
,![]()
![]() 0 (
0 (![]() и
и ![]() -const). В классе V:
-const). В классе V: ![]() построить несмещенную оценку для
построить несмещенную оценку для ![]() и ее дисперсию, если
и ее дисперсию, если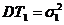 ,
,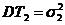 .
.
Решение. ![]()
![]() T – несмещенная оценка для
T – несмещенная оценка для ![]() , если
, если 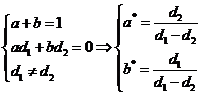 Тогда
Тогда 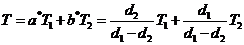
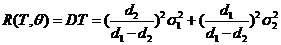 ,
,![]()

![]() . При
. При ![]() =
=![]() несмещенной оценки для
несмещенной оценки для ![]() в классе V не существует.
в классе V не существует.
Выводы
а) пример 2 дает алгоритм построения несмещенной оценки по двум любым смещенным с разным смещением.
б) по примеру 2 при ![]() =
=![]() можно строить примеры, когда не существует несмещенной оценки для
можно строить примеры, когда не существует несмещенной оценки для ![]() в классе V.
в классе V.
3). ![]() и
и ![]() - независимые оценки для
- независимые оценки для![]() ;_
;_![]() ,
,![]() . В классе V:
. В классе V: ![]() Найти несмещенную оценку
Найти несмещенную оценку ![]() для
для ![]() наименьшей возможной дисперсией D
наименьшей возможной дисперсией D![]() .
.
Решение. 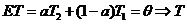 - несмещенная оценка для
- несмещенная оценка для![]() .
. ![]() достигает минимума при а, для которого
достигает минимума при а, для которого ![]() (т. к. коэффициент при
(т. к. коэффициент при ![]() положителен и равен
положителен и равен 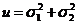 ).
).
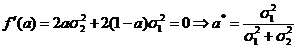
Таким образом, искомая оценка ![]()
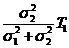 ;
; 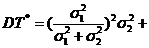
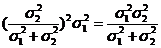
4). 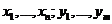 - две независимые выборки ~
- две независимые выборки ~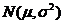 , (
, (![]() и
и ![]() - неизвестные параметры). В классе V:
- неизвестные параметры). В классе V: ![]() (
(![]() ;
;![]() ) найти оценку
) найти оценку ![]() для
для ![]() с минимальной дисперсией D
с минимальной дисперсией D![]() .
.
Решение. 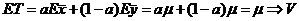 - класс несмещенных оценок. Тогда мы находимся в условиях задачи 3, из которой следует, что единственной несмещенной оценкой в классе V с наименьшей дисперсией является
- класс несмещенных оценок. Тогда мы находимся в условиях задачи 3, из которой следует, что единственной несмещенной оценкой в классе V с наименьшей дисперсией является 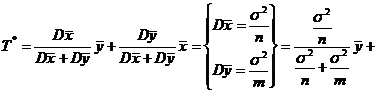
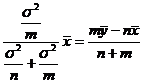 ; из задачи 3
; из задачи 3 ![]() ~
~![]() .
.
Выводы
а) пример 4 дает алгоритм построения лучшей по риску несмещенной оценки по данным для ![]() при X~:
при X~: ![]() и
и ![]() .
.
5). X~![]() ,
, ![]() - неизвестный параметр,. Сравнить квадратичные риски оценок
- неизвестный параметр,. Сравнить квадратичные риски оценок ![]() и
и 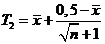 (оценка Ходжеста-Лемана) для
(оценка Ходжеста-Лемана) для ![]() .
.
Решение. 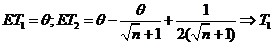 - несмещенная оценка, а
- несмещенная оценка, а ![]() - смещенная, но асимптотически несмещенная оценка для
- смещенная, но асимптотически несмещенная оценка для ![]() . Причем
. Причем ![]() несмещенно оценивает лишь значение
несмещенно оценивает лишь значение ![]() =0,5. Сравним
=0,5. Сравним ![]() и
и ![]() по квадратичным рискам.
по квадратичным рискам.
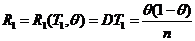 ;
; 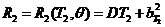 , где
, где 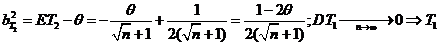 - состоятельная оценка для
- состоятельная оценка для ![]() .
.
![]()
![]()
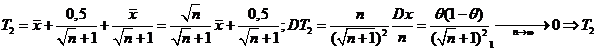 - состоятельная оценка для
- состоятельная оценка для![]() .
.
![]()
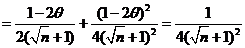 , т. е.
, т. е. ![]() не зависит от
не зависит от ![]() .
.
Изобразим ![]() и
и ![]() графически как функции от
графически как функции от ![]() .
.
Из графика следует, что, если есть основание считать, что значение ![]() близко к 0,5 (средняя зона), то по риску лучше оценка
близко к 0,5 (средняя зона), то по риску лучше оценка ![]() ,если же значение близко к 0 или 1 (крайние зоны), то лучше оценка
,если же значение близко к 0 или 1 (крайние зоны), то лучше оценка ![]() для
для ![]() .
.
§3. Достаточные статистики. (д. с.)
Определение: Статистика Т=Т(х) называется достаточной для семейства распределений ![]()
![]() (θ – неизвестный параметр), если вероятность любой выборки
(θ – неизвестный параметр), если вероятность любой выборки 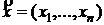 не зависит от значения неизвестного параметра θ. (смысл д. с.: она содержит в себе всю информацию о неизвестном параметре θ.)
не зависит от значения неизвестного параметра θ. (смысл д. с.: она содержит в себе всю информацию о неизвестном параметре θ.)
Для опознавания и построения д. с.приведём критерий факторизации:
Теорема 1: (Критерий факторизации (к. ф.)).
Для того чтобы Т(х) – была д. с. для ![]() (θ – неизвестный параметр) необходимо и достаточно чтобы функция правдоподобия
(θ – неизвестный параметр) необходимо и достаточно чтобы функция правдоподобия ![]() имела вид:
имела вид:
![]() (1)
(1)
Тогда из критерия следует, что приводя к виду (1), получим вид д. с. {из вида (1) следует, что д. с. определяется неоднозначно => достаточных статистик бесконечно много.}
Д. с. существует, так как например, выборка является д. с.
Доказательство:
1) Достаточность.
Пусть (1) выполнено, тогда покажем, что Т(х) является д. с., то есть распределение любой выборки при её фиксированном значении не зависит от параметра θ.
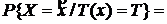 {по теореме умножения}
{по теореме умножения}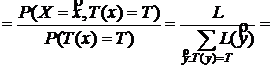
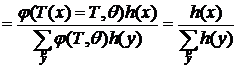 не зависит от θ.
не зависит от θ.
2) Необходимость.
Пусть Т(х) – д. с. Тогда покажем, что (1) имеет место:
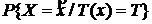
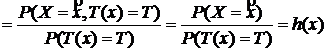 тогда по теореме умножения имеем:
тогда по теореме умножения имеем: ![]()
(т. к. P(T(x)=T)=φ(T,θ), а ![]() из определения д. с. Т(x)
из определения д. с. Т(x)
Пример применения критерия факторизации:
X ~ π(λ=θ) Найти д. с. для этого семейства.
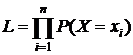 - функция правдоподобия в дискретном случае.
- функция правдоподобия в дискретном случае.
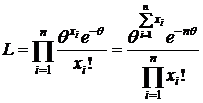 =>
=> 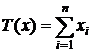 - вид д. с. (т. к.
- вид д. с. (т. к.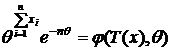 )
)
(проверка Т(х) на д. с. по определению проведена ниже).
Теорема 2 (Рао – Блэкуэлла - Колмогорова).
Оптимальная оценка, если она существует, является функцией от достаточной статистики.
Оптимальная оценка – несмещённая оценка (н. о.) с минимально возможной дисперсией.
Доказательство:
Пусть T=T(x) – д. с. для ![]() и Т1=Т(х) – н. о. для τ=τ(θ).
и Т1=Т(х) – н. о. для τ=τ(θ).
Рассмотрим статистику H(t)=E(T1/T) (при T=t имеем H(t)=E(T1/T=t) (1))
Тогда EH(t)=E(E(T1/T))=ET1=τ – н. о. для τ.
Теперь сравним DH(t) с DT1: DT1 = E(T1 - ET1)2 = E(T1 - τ)2=E(T1 - H(T) + H(T) - τ)2 = = E(T1 - H(T)) 2 + 2E(T1 - H(T))(H(T) - τ) + E(H(T) - τ)2.
Если показать, что E(T1 - H(T))(H(T) - τ)=0 (♦),
то, так как E(H(T) - τ)2≥0, а E(τ - H(T))2=DH(T), получим DT1 ≥ DH(T). Остаётся доказать (♦):
E(T1 - H(T))(H(T) - τ)= E((T1 - H(T))(H(T)) - τE(T1 - H(T));
E(T1 - H(T))= ET1 - EH(T) = τ – τ=0;
По формуле полной вероятности при гипотезах {T=t} получаем:
E((T1 - H(T))(H(T))=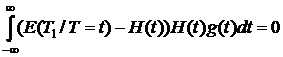
где – g(t) плотность распределения статистики H(t), так как E(T/T=t)-H(t)=0 по (1).
Теорема 2 доказана.
Определение полноты достаточной статистики:
Достаточная статистика T(x) называется полной, если для любой функции f(T(x))=f(T) из того, что Ef(T)=0 для всех θ следует, что f(T)=0 почти всюду (то есть кроме, может быть, множества меры ноль).
Теорема 3:
Если существует полная д. с., то вся функция от неё является оптимальной оценкой для своего математического ожидания.
Доказательство:
Пусть T=T(x) – полная д. с.; H(t) - произвольная функция от T(x); EθH(T)=τ(θ).
Тогда из определения полноты д. с. T(x) следует единственность для н. о. H(T) для τ(θ), так как в противном случае существует другая H1(T) н. о.
E(H(T) - H1(T))=0 => H(T) = H1(T). п. в. (из определения полноты д. с.)
Из предыдущей теоремы 2 следует, что оптимальную оценку следует искать в классе функций, зависящих от д. с. – Т(х). Но так как Н(Т) – единственная н. о. для τ(θ), зависимая от Т, то она является оптимальной оценкой для τ(θ).
Следствия из теорем:
Пусть Т=Т(х) – полная д. с.; τ(θ) – оцениваемая функция. Тогда:
1. когда оптимальная оценка существует она является функцией д. с. и однозначно определяется из уравнения несмещённости: ЕН(Т) = τ(θ) (где Т – полная д. с.);
2. оптимальная оценка, если она существует, ищется по формуле:
τ* = H(T) = E(T1/T=t); где T1 – н. о. для τ(θ).
Задачи:
Доказать, что:
1) Любая взаимно однозначная функция W(x) от д. с. – тоже является д. с.
Доказательство: Пусть – T(x) д. с., тогда P{x / T(x)=t}=P{x / W(T(x))=W(t)} что и требовалось доказать.
2) Любая выборка – д. с.
Доказательство:
![]() , то есть не зависит от θ.
, то есть не зависит от θ.
3) Вариационный ряд – д. с.
Доказательство следует из задач 1), 2).
4) Эмпирическая функция распределения – д. с.
Доказательство следует из задач 1), 3).
5) Для семейства распределений π(θ)найти д. с. и проверить её по определению.
Решение:
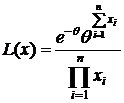 .По к. ф. получаем - д. с.
.По к. ф. получаем - д. с.
Проверка:
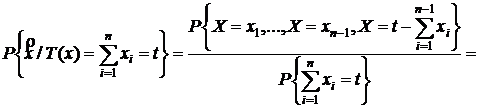
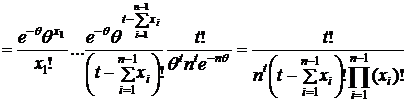 , то есть не зависит от θ.
, то есть не зависит от θ.
6) Найти д. с. для семейства распределений R[0, θ] и проверить её по определению.
Решение:
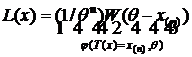 1, где
1, где 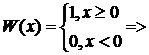 х – д. с.
х – д. с.
Проверка:
![]() , то есть не зависит от θ.
, то есть не зависит от θ.
7) Найти д. с. для семейства γ-распределений с плотностью распределения: 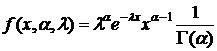 , 0 < x < ∞
, 0 < x < ∞
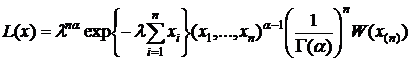 , по к. ф. получим
, по к. ф. получим
- д. с.
8) Экспоненциальным семейством (э. с.) называется семейство распределений с плотностью или вероятностью P(X=x) вида:
exp{A(Q)B(x)+C(Q)+D(X)}. Найти д. с. э. с.
Решение:
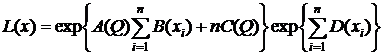 ,
,
по к. ф. получим 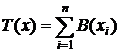 - д. с.,
- д. с.,
так как 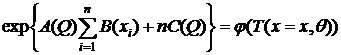 ;
; 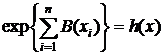 .
.
К э. с. относится γ – распределение, биномиальное, пуассоновское, геометрическое, Паскаля и другие. Методом приведения к виду э. с. с учётом результата задачи №8 найти д. с. для перечисленных выше законов распределения.
Нахождение д. с. путём приведения к экспоненциальному виду.
9)
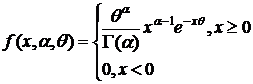 θ - неизвестно
θ - неизвестно
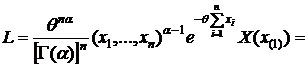 (●)
(●)
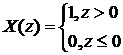 ;
; ![]()
(●)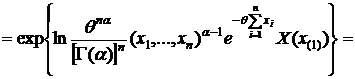
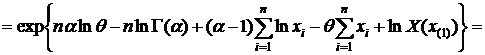
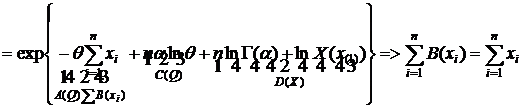 - д. с.
- д. с.
10) X~B(n, θ) ; ![]()
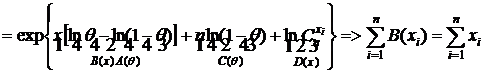 - д. с.
- д. с.
11) 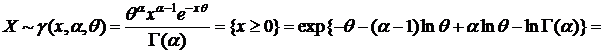
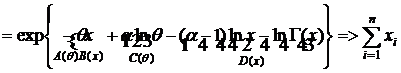 - д. с.
- д. с.
12) 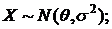
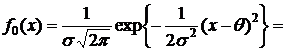
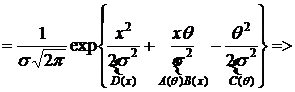
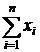 -д. с.
-д. с.
13) 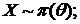
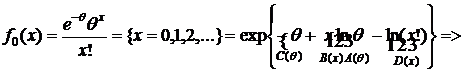
![]() -д. с.
-д. с.
Задачи на полную д. с.:
14) X~B(1,θ), где θ – неизвестно, ![]() Найти д. с. и проверить её на полноту.
Найти д. с. и проверить её на полноту.
Решение:
![]()
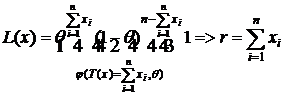 - д. с.
- д. с.
h(x)
r~B(n,θ). Пусть  такова, что
такова, что ![]() при всех
при всех ![]() то есть
то есть
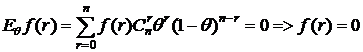 почти всюду как коэффициенты многочлена, то есть r – полная д. с.
почти всюду как коэффициенты многочлена, то есть r – полная д. с.
Теорема 4: Необходимым и достаточным условием полной д. с., относящеёся к э. с. является совпадение размерности статистики и неизвестного параметра.
Примеры на теорему :
15) 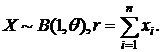 По теореме установить, для каких функций от θ будут оптимальными следующие оценки:
По теореме установить, для каких функций от θ будут оптимальными следующие оценки:
а) ![]() ; б)
; б) 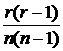 ; в)
; в) ![]() .
.
Решение:
а) 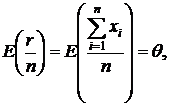 то есть для θ оптимальной оценкой является
то есть для θ оптимальной оценкой является ![]()
б) 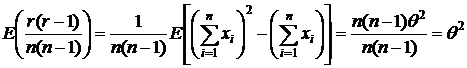 , т. е. для
, т. е. для ![]() оптимальной оценкой является
оптимальной оценкой является ![]() , так как
, так как
Е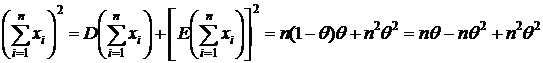 ;
;
в) решить самостоятельно.
Дома:
16) X~R[0,θ], (θ - неизвестно). Показать, что ![]() – полная д. с.
– полная д. с.
17) X~R[θ1,θ2], (θ1, θ2 - неизвестны). Показать, что ![]() – полная д. с.
– полная д. с.
Примеры полных и неполных достаточных статистик.
1) X~R[θ1,θ2]; 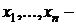 выборка значений с. в. Х. Доказать, что
выборка значений с. в. Х. Доказать, что 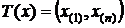 – полная д. с.
– полная д. с.
Решение:
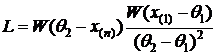 , где
, где 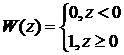
По к. ф. получим, что ![]() – д. с.
– д. с.
![]() плотность совместного распределения с. в. х(1) и х(n); F(х) – функция распределения с. в. Х:
плотность совместного распределения с. в. х(1) и х(n); F(х) – функция распределения с. в. Х:
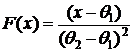 при θ1 ≤ х ≤ θ2 ;
при θ1 ≤ х ≤ θ2 ; 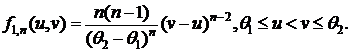
пусть ![]() такова, что для всех
такова, что для всех ![]() выполнится:
выполнится:
![]()
![]()
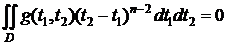
для всех ![]() .
.
Продифференцировав последнее выражение сначала по θ1, потом по θ2 получим: ![]() =0, откуда следует полнота д. с. Т (х).
=0, откуда следует полнота д. с. Т (х).
2) 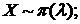
![]() выборка значений с. в. Х. Доказать, что статистика
выборка значений с. в. Х. Доказать, что статистика 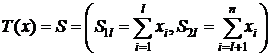 - д. с., но неполная.
- д. с., но неполная.
Решение:
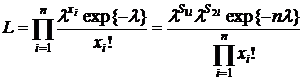 => Т(х) – д. с. по к. ф.
=> Т(х) – д. с. по к. ф.
Докажем неполноту д. с. Т(х). Рассмотрим функцию 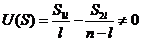 в то время как EU(S)=0 => T(x)=S – неполная д. с.
в то время как EU(S)=0 => T(x)=S – неполная д. с.
3) 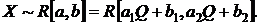 Доказать, что статистика
Доказать, что статистика ![]() - достаточна, но неполная.
- достаточна, но неполная.
Решение:
Ранее получено, что ![]()
![]() ;
;
Рассмотрим функцию: 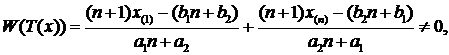 в то время как MW(T(x))=0 => T(x) – неполная д. с.
в то время как MW(T(x))=0 => T(x) – неполная д. с.
Решить самостоятельно аналогичные задачи 4 и 5 для случаев:
4) 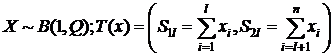
5) 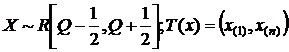 (решить с использованием задачи и непосредственно).
(решить с использованием задачи и непосредственно).
6) 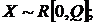 Доказать полноту д. с.
Доказать полноту д. с. ![]()
7) 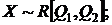 Используя теорему №3 (о полных д. с.), определить для каких функций от неизвестных параметров Q1,Q2 будут эффективными оценки:
Используя теорему №3 (о полных д. с.), определить для каких функций от неизвестных параметров Q1,Q2 будут эффективными оценки:
а) 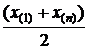 ; б)
; б) 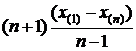 ;
;
Д. с. могут быть использованы для улучшения имеющихся н. о. неизвестного параметра θ в соответствие с теоремой 2.
Примеры:
1) 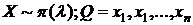 - выборка значений с. в. Х. Улучшить оценку для Q.
- выборка значений с. в. Х. Улучшить оценку для Q.
Решение:
![]() - н. о. - д. с.
- н. о. - д. с.
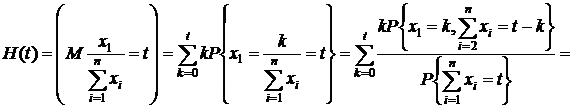
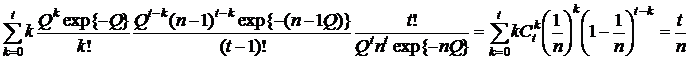 так как последняя сумма =MZ, где
так как последняя сумма =MZ, где 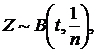 то
то
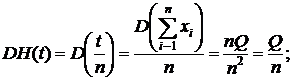
![]()
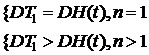
Решить самостоятельно аналогичные задачи в случаях:
2) 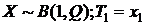
3) 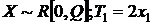
§4.Неравенство Рао-Крамера.
Введем функцию 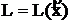 такую, что
такую, что
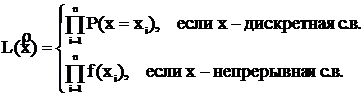
Эта функция обозначает вероятность данной выборки и называется функцией правдоподобия.
Теперь сформулируем условия регулярности x~Fθ(x):
1. Дифференцируемость L
2. {x: L ≠ 0} не зависит от неизвестного параметра θ
Теорема 1.
Неравенство Рао-Крамера дает нижнюю грань дисперсий несмещенных оценок в регулярном случае. Рассмотрим задачу точечного оценивания при x~Fθ(x), τ = τ(θ), тогда, если выполняются условия регулярности и t(x) – несмещенная оценка для τ = τ(θ), то дисперсия не может быть как угодно малой при построении разных оценок, а точнее:
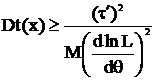 (1)
(1)
Если в неравенстве (1) достигается равенство, то оценка t(x) называется несмещенной оценкой с минимальной дисперсией (НОМД) или эффективной оценкой.
Доказательство неравенства Рао-Крамера опирается на преобразованное неравенство Коши-Буняковского.
Преобразуем неравенство Коши-Буняковского:
|rxy|≤1, причем |rxy|=1 тогда и только тогда, когда с. в. X и Y линейно зависимы. Рассмотрим неравенство |rxy|≤1 при условии MX=0 и MY=0. Получим, 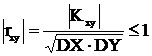 (по определению rxy) тогда
(по определению rxy) тогда
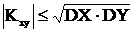 (2)
(2)
Kxy= MXY – MX ∙ MY = MXY; DX = MX 2 – (MX)2 = MX 2 и DY = MY 2. Подставляя значения дисперсии в формулу (2) имеем:
![]() или
или
![]() . (*)
. (*)
В этой форме и будем использовать неравенство Коши-Буняковского.
План доказательства:
1. выписать условие нормировки и продифференцировать его по θ;
2. для несмещенной оценики t(x) для τ = τ(θ) выписать уравнение несмещенности и продифференцировать обе части этого уравнения по θ;
3. из результата пункта 2 вычесть результат пункта 1, умноженный на τ;
4. применить неравенство Коши-Буняковского в форме (*).
1. 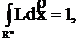 т. е.
т. е.
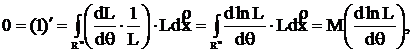 т. е.
т. е.
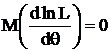 (3)
(3)
2. t=t(x) – несмещенная оценка для τ = τ(θ).
Выпишем уравнение несмещенности:![]() и продифференцируем его
и продифференцируем его
по θ
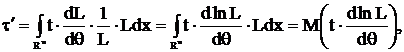 т. е.
т. е.
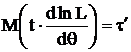 (4)
(4)
3. обозначим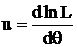 и вычтем из уравнения (4) уравнение (3), умноженное на τ, получим:
и вычтем из уравнения (4) уравнение (3), умноженное на τ, получим:
M(u ∙ t) – τ ∙ Mu = τ′, воспользуемся свойствами мат. ожидания MX
M(ut – τu) = M(u(t – τ)) = τ′, возведем обе части равенства в квадрат
(M(u(t – τ)))2 = (τ′)2
4. воспользуемся неравенством Коши-Буняковского в форме (*); это возможно, т. к. Mu=0 по формуле (3), а M(t – τ)=0, т. к. t – несмещенная оценка для τ.
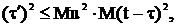 но т. к.
но т. к. 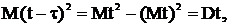 то
то 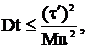 но
но
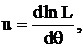 поэтому
поэтому 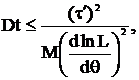 что и требовалось доказать.
что и требовалось доказать.
Критерий НОМД.
Дисперсия будет наименьший, если знак неравенства заменить знаком равенства, а это по неравенству Коши-Буняковского возможно только в том случае, если и t – τ линейно зависимы, т. е. искомый критерий формулируется следующим образом:
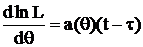 (5)
(5)
В этом случае получим более простой вид дисперсии:
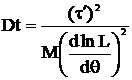 (6)
(6)
Возведем обе части (5) в квадрат и возьмем мат. ожидание от обеих частей:
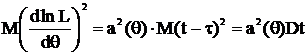
Подставляя в формулу (6), имеем: 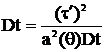 или
или 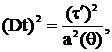 т. е.
т. е.
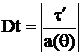 (7)
(7)
Теорема 2.
Если существует НОМД для θ, то НОМД существует для любой линейной функции от θ и не существует ни для какой другой функции от θ.
Доказательство. Пусть t(x)– НОМД для θ, а τ = Aθ + B. Используем критерий:
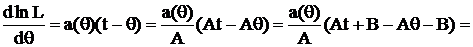
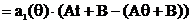
По критерию получим, что At + B – НОМД для τ = Aθ + B. 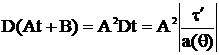
Замечание 1.
Ни для какой функции от τ = τ(θ), для которой есть НОМД, кроме линейной не существует НОМД.
Доказательство. Пусть ![]() – НОМД для τ = τ(θ и пусть τ1= φ(τ)– нелинейная функция от τ. Тогда
– НОМД для τ = τ(θ и пусть τ1= φ(τ)– нелинейная функция от τ. Тогда
![]() (a)
(a)
Пусть противное t1 – НОМД для τ1, т. е.
![]() (б)
(б)
C другой стороны из (а) имеем
![]() (в)
(в)
Тогда для совпадения (в) с (б) φ-1 должна быть вида умножения или деления на const или функцию от θ, что возможно лишь при линейной зависимости между τ и τ1, и кроме того должно быть равенство: φ(t – τ) = φ(t) – φ(τ) = t1 – τ1, где t1 = φ(t), τ1 = φ(τ), что также возможно лишь при линейной зависимости τ и τ1: τ1 = φ(τ). Эти выводы и доказывают утверждение замечания 1.
Практически это утверждение применяется в следующем случае: если получен вид (5) 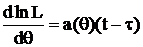 и требуется ответить на вопрос о существовании НОМД для какой либо функции от θ, отличной от линейной; ответ, очевидно отрицательный.
и требуется ответить на вопрос о существовании НОМД для какой либо функции от θ, отличной от линейной; ответ, очевидно отрицательный.
Замечание 2.
Если построена t(x) – НОМД для τ(θ), то для 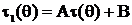 НОМД
НОМД 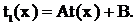
В более общем случае при выводе критерия можно говорить о τ(θ).
Замечание 3.
Если для θ НОМД существует, то ее дисперсию можно получить из неравенства Рао-Крамера, заменяя знак неравенства равенством, или по критерию (формула (6)).
Если НОМД не существует, то смысл неравенства Рао-Крамера состоит в том, что дает нижнюю грань дисперсии, которая не достигается.
Примеры.
Пример 1.
Проверим, является ли 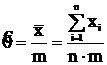 НОМД для X ~ B(m, θ), где θ – вероятность успеха в 1-м опыте и τ(θ) = θ.
НОМД для X ~ B(m, θ), где θ – вероятность успеха в 1-м опыте и τ(θ) = θ.
Известно, что MX = mθ, DX = mθ(1 – θ), тогда найдем ![]()
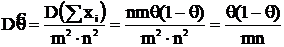
Вычислим нижнюю грань дисперсии несмещенных оценок по неравенству Рао-Крамера. Покажем несмещенность ![]() :
: 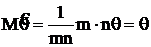 .
.
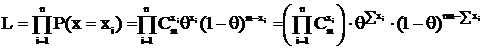 .
.
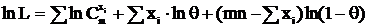 , тогда
, тогда
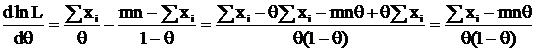
получим: 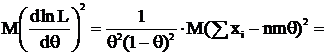
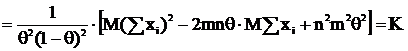
пользуясь тем, что 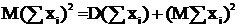 ,
, ![]() ,
, ![]() , получим:
, получим:
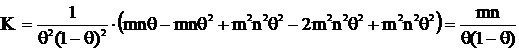 .
.
Теперь, применяя неравенство Рао-Крамера и учитывая, что ![]() , получим:
, получим: ![]() . Получили, что
. Получили, что![]() – НОМД, т. к. результат вычисления дисперсии совпадает с нижней гранью из неравенства Рао-Крамера.
– НОМД, т. к. результат вычисления дисперсии совпадает с нижней гранью из неравенства Рао-Крамера.
Пример 2.
Получим эту же оценку по критерию. X ~ B(m, θ); τ(θ) = θ.
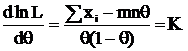 (см. вычисления в Примере 1).
(см. вычисления в Примере 1).
Приведем это выражение к виду (5): ![]()
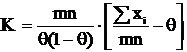 , тогда
, тогда 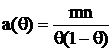 и
и 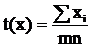 – НОМД, тогда учитывая что
– НОМД, тогда учитывая что ![]() , применим формулу (7) и получим, что
, применим формулу (7) и получим, что 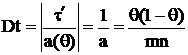 .
.
Критерий НОМД для экспоненциального семейства (э. с.).
Пусть 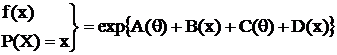 (8)
(8)
Тогда 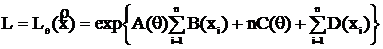 ;
;
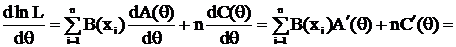
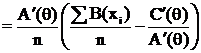
следовательно по критерию ![]() – НОМД для
– НОМД для
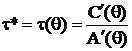 , (9)
, (9)
тогда по (7)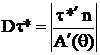 ,а значит НОМД существует и для любой линейной функции от τ.
,а значит НОМД существует и для любой линейной функции от τ.
Теорема 3.
Если НОМД для τ = τ(θ) существует, то распределение с. в. X относится к экспоненциальному семейству.
Доказательство. Пусть ![]() – НОМД для τ = τ(θ. Тогда
– НОМД для τ = τ(θ. Тогда ![]() . Проинтегрировав по θ обе части последнего равенства, получим:
. Проинтегрировав по θ обе части последнего равенства, получим:
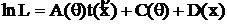 , что и доказывает утверждение.
, что и доказывает утверждение.
Примеры использования формулы (9).
Примеры функций τ = τ(θ), для которых существует НОМД для следующих распределений:
а) X ~ B(1,0);
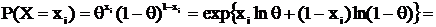
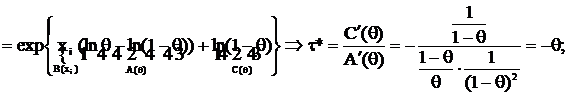
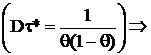 для τ = τ(θ) = Aθ + B, где A и B – любые const, существует НОМД
для τ = τ(θ) = Aθ + B, где A и B – любые const, существует НОМД
б) X ~ B(m,θ);
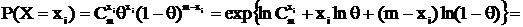
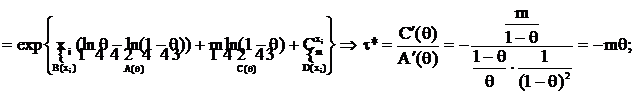
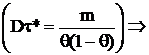 для τ = τ(θ) = Aθ + B, где A и B – любые const, существует НОМД
для τ = τ(θ) = Aθ + B, где A и B – любые const, существует НОМД
в) X ~ П(θ);
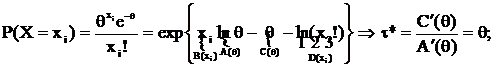
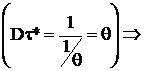 для τ = Aθ + B, где A и B – любые const, существует НОМД
для τ = Aθ + B, где A и B – любые const, существует НОМД
г) X ~ Г(θ);
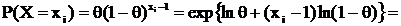
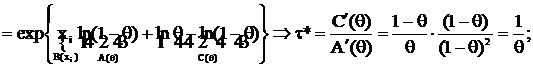
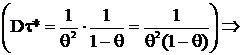 для
для 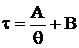 , где A и B – любые const, существует НОМД
, где A и B – любые const, существует НОМД
§5.Методы получения точечных оценок
Постановка задачи: Пусть имеется некоторая выборка X: x1, x2,…, xn, X~Fθ(x) θ![]() , где
, где ![]() - параметрическое пространство. Требуется постороить оценку для θ или τ(θ)
- параметрическое пространство. Требуется постороить оценку для θ или τ(θ)
Различаются два подхода к решению этой задачи в зависимости от понимания природы неизвестного параметра.
1 подход: реализуется в случае, когда θ является неизвестной постоянной, т. е. θ = const.
В данной ситуации используется метод подстановки.
Суть метода: Выбирается некоторая мера расхождения теоретического и эмпирического распределения и строится некоторый функционал от этой меры. Оценка для неизвестного параметра ищется таким образом, чтобы этот функционал принимал некоторое значение, соответствующее минимуму расхождения теоретических и практических результатов.
Метод подстановки объединяет ряд конкретных методов, которые различаются по мере различия теории и практики:
1. Метод моментов (ММ)
2. Метод максимального правдоподобия (ММП)
3. Метод минимального ![]()
4. Метод минимального расстояния.
Существуют и другие методы но мы рассмотрим только первые, т. к. они используются наиболее часто.
2 подход: реализуется в случае, когда θ является случайной величиной, т. е ![]() . В данной ситуации используются Байесовские оценки.
. В данной ситуации используются Байесовские оценки.
Методы подстановки.
1.Метод моментов (ММ)
Совокупность неизвестных параметров будем рассматривать как k-мерный вектор. 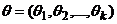 . Тогда оценки метода моментов (ОММ) являются решениями системы k уравнений, составленых путем приравнивания k теоретический моментов соответственно k эмпирическим.
. Тогда оценки метода моментов (ОММ) являются решениями системы k уравнений, составленых путем приравнивания k теоретический моментов соответственно k эмпирическим.
Достоинством ММ является простота его применения.
Недостатком ММ является то, что он не гарантирует качества оценок, хотя часто оценки, полученные этим методом являются «удачными».
Пример 1.
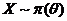 . Найти ОММ –
. Найти ОММ –![]() для неизвестного параметра θ.
для неизвестного параметра θ.
Решение.
![]() =MX=
=MX=![]()
Пример 2.
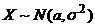 , тогда
, тогда 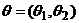 , где
, где 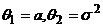 . Найти ОММ для θ.
. Найти ОММ для θ.
Решение.
![]()
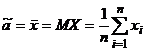
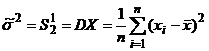 , отсюда
, отсюда 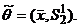
Пример 3.
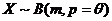 . Найти ОММ для θ (m-известно)
. Найти ОММ для θ (m-известно)
Решение.
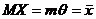 , следовательно,
, следовательно, 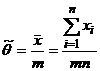
Пример 4.
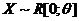 Найти ОММ для θ.
Найти ОММ для θ.
Решение.
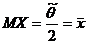 , тогда ОММ
, тогда ОММ 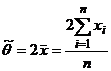
2.Метод максимального правдоподобия (ОМП)
Оценка максимального правдоподобия (ОМП)![]() выбирается таким образом, чтобы фунция прадоподобия
выбирается таким образом, чтобы фунция прадоподобия 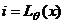 принимала наибольшее значение.
принимала наибольшее значение.
Различается два случая нахождения ОМП: регулярный и не регулярный.
Регулярный случай.
Имеем следующее условие регулярности:
1. дифференцируемость L по θ;
2. множество 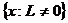 не зависит от неизвесного параметра θ.
не зависит от неизвесного параметра θ.
Условие регулярности обеспечивает достижение максимума функции L(x), поэтому в регулярном случае ОМП ищется из следующей системы кравнений (УМП):
![]()
![]()
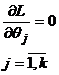 или из системы уравнений
или из системы уравнений 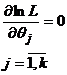 , т. к. L и lnL достигают максимума в тех же точках.
, т. к. L и lnL достигают максимума в тех же точках.
Пример 5.
Найти ОМП для θ.
Решение.
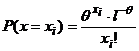 , тогда
, тогда 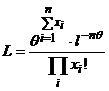 .
.
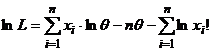
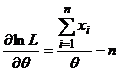 . Решим УМП и получим, что
. Решим УМП и получим, что 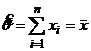 .
.
В данном случае получили, что ОМП совпадает с ОММ.
Очевидно, что вычисления ММП значительно сложнее, чем ММ, но ММП теоретически обосновывает гарантии качества оценок.
Теорема 1.
Если существует НОМД для ![]() , то в регулярном случае она является ОМП для
, то в регулярном случае она является ОМП для ![]() .
.
Доказательство: используем критерий НОМД: 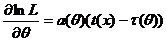 , где t(x) – НОМД для
, где t(x) – НОМД для ![]() . Тогда, если
. Тогда, если ![]() , то t(x) – ОМП для
, то t(x) – ОМП для ![]() .
.
Пример 6.
Для функции от неизвестного параметра θ, для которой не существует НОМД, а ОМП существует.
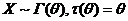 Найти.
Найти.
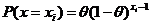 , тогда
, тогда 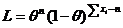
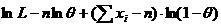
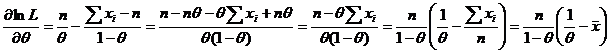
Найдем ОМП из УМП 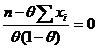 . Из этого уравнения следует, что
. Из этого уравнения следует, что ![]()
тогда ![]() - ОМП
- ОМП
Используем критерий НОМД:
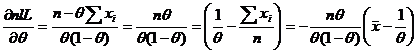 , следовательно, по критерию НОМД
, следовательно, по критерию НОМД ![]() - НОМД для
- НОМД для ![]() , тогда для
, тогда для ![]() НОМД не существует.
НОМД не существует.
По данной теореме, если НОМД для ![]() существует, то ОМП совпадает с ней. Это и является гарантией качества ОМП.
существует, то ОМП совпадает с ней. Это и является гарантией качества ОМП.
Теорема 2.
Все решения УМП (в регулярном случае), т. е. ОМП являются функциями достаточной статистики.
Доказательство: Пусть 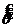 -достаточная статистика,
-достаточная статистика,  - плотность распределения
- плотность распределения 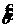 , а
, а 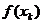 - плотность распределения исследуемой с. в. в точке
- плотность распределения исследуемой с. в. в точке 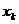 .
.
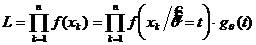 , тогда
, тогда 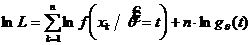 ,
,
следовательно, 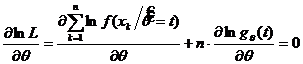 . Полученное УМП принимает вид:
. Полученное УМП принимает вид: ![]() , т. к.
, т. к. ![]() не зависит от
не зависит от ![]() в силу того, что
в силу того, что ![]() - достаточная статистика; следовательно,
- достаточная статистика; следовательно, 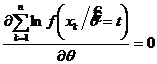 .
.
Решение уравнения 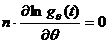 будет находится в терминах достаточной статистики, что и означает выполнение утверждения теоремы.
будет находится в терминах достаточной статистики, что и означает выполнение утверждения теоремы.
Теорема 3. Инвариантность ОМП.
Если параметры ![]() и
и ![]() связаны непрерывной взаимно-однозначной зависимостью
связаны непрерывной взаимно-однозначной зависимостью ![]() и
и ![]() - ОМП для
- ОМП для ![]() , то
, то ![]() - ОМП для
- ОМП для ![]()
Доказательство: Пусть ![]() - плотность распределения изучаемой с. в. Х. Тогда
- плотность распределения изучаемой с. в. Х. Тогда  в некоторой окрестности точки
в некоторой окрестности точки ![]() ; следовательно, т. к.
; следовательно, т. к. ![]() непрерывна,
непрерывна, ![]() . Это неравенство означает утверждение теоремы в силу характера зависимости
. Это неравенство означает утверждение теоремы в силу характера зависимости ![]() , т. е.
, т. е. ![]() в некоторой окрестности и
в некоторой окрестности и ![]() является ОМП для
является ОМП для ![]() .
.
Замечание 1. Если задача состоит в построении ОМП для некоторой ![]() , и
, и ![]() удовлетворяет условиям теоремы 3, то она сводится к более простой - нахождению
удовлетворяет условиям теоремы 3, то она сводится к более простой - нахождению ![]() - ОМП для
- ОМП для ![]() , тогда
, тогда ![]() .
.
Замечание 2. (без доказательства) При достаточно общих условиях ОМП состоятельны асимптотически нормальны и асимптотически эффективны при ![]() .
.
Особый интерес представляет нахождение ОМП в нерегулярном случае: ОМП находится из смысла метода (ММП), т. е. как значения, при которых функция правдоподобия принимает наибольшие значения.
Пример 7. ![]() Найти ОМП для
Найти ОМП для ![]() -
-![]() .
.
Решение:
Это нерегулярный случай.
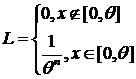
Наибольшее значение L, равное  , получается при наименьшем возможном значении
, получается при наименьшем возможном значении  , если наблюдались значения x:
, если наблюдались значения x: 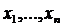 , т. е.
, т. е. 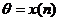 .
.
Пример 8. того, что ОМП бесконечно много.
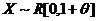
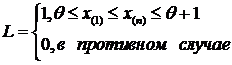
Очевидно, что Lmax=1, но
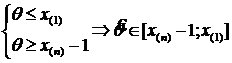
- ОМП для ![]()
Точек на отрезке для 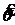 бесконечно много, следовательно, значений бесконечно много. Остается только один вопрос: существует ли такой отрезок?
бесконечно много, следовательно, значений бесконечно много. Остается только один вопрос: существует ли такой отрезок?
Из выражения для L имеем: 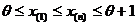 , значит
, значит 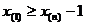 , т. е. отрезок существует.
, т. е. отрезок существует.
Далее предлагаются к рассмотрению примеры на построение ОМП и ОММ как с объяснениями, так и для самостоятельного решения.
Примеры нахождения ОММ и ОМП.
Пример 9.
, где 
Найти ОММ для  и
и  .
.
Решение:
| (1) | |
(2) |
Поделим (2) на (1)2: 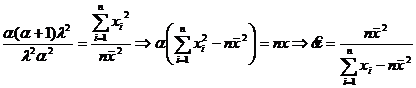
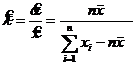
Пример 10.
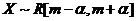 , - известно, m – не известно. Найти ОМП для параметра m.
, - известно, m – не известно. Найти ОМП для параметра m.
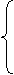 Решение: Вычислим функцию правдоподобия:
Решение: Вычислим функцию правдоподобия:
L= | |
максимального значения L=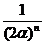 достигает при всех
достигает при всех 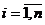 . Отсюда следует, что множество ОМП для m есть пересечение всех отрезков [xi-α, xi+α], , т. е. это любое значение отрезка [x(n)-α, x(1)+α]=
. Отсюда следует, что множество ОМП для m есть пересечение всех отрезков [xi-α, xi+α], , т. е. это любое значение отрезка [x(n)-α, x(1)+α]=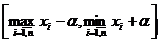 , при этом
, при этом 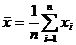 может не принадлежать этому отрезку.
может не принадлежать этому отрезку.
Пример 11.
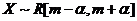 , где параметры m и α оба неизвестны. Найти ОМП для параметров m и α.
, где параметры m и α оба неизвестны. Найти ОМП для параметров m и α.
Решение. По 10 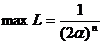 достигается при возможном минимальном значении α, совместном с выборкой, т. е. когда
достигается при возможном минимальном значении α, совместном с выборкой, т. е. когда 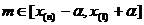 (по 10), т. е.
(по 10), т. е. 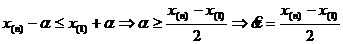 - ОМП для α,
- ОМП для α,
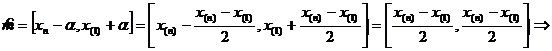 ОМП для параметра m:
ОМП для параметра m: 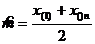
Пример 12.
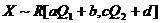 , где a, b, c, d – известные константы. Q=(Q1,Q2) – неизвестный параметр распределения. Найти ОМП и ОММ для θ=(θ1,θ2)
, где a, b, c, d – известные константы. Q=(Q1,Q2) – неизвестный параметр распределения. Найти ОМП и ОММ для θ=(θ1,θ2)
![]() Решение:
Решение:
L= | |
0, в противном случае |
ф. м.п. L принимает наибольшее значение при минимальном значении Q2 и максимальном значении Q1, а т. к. 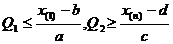 , то
, то
ОМП= |
|
|
ОММ: |
|
|
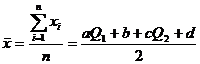
Байесовские оценки (решения)
Решающей функцией 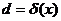 называется правило (функция), ставящее в соответствие каждому результату наблюдения некоторое решение d. Областью определения величины
называется правило (функция), ставящее в соответствие каждому результату наблюдения некоторое решение d. Областью определения величины 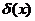 является множество значений наблюдаемой случайной величины (с. в.) Х, областью значений - множество решений D.
является множество значений наблюдаемой случайной величины (с. в.) Х, областью значений - множество решений D.
Чтобы функцию ![]() выбрать наилучшим образом, нужно сравнить последствия использования различных функций
выбрать наилучшим образом, нужно сравнить последствия использования различных функций ![]() . Для этого задается функция потерь
. Для этого задается функция потерь 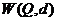 , значение которой определяется выбранным решением, если с. в. X имеет функцию распределения
, значение которой определяется выбранным решением, если с. в. X имеет функцию распределения ![]() с неизвестным параметром Q. Тогда при многократном применении
с неизвестным параметром Q. Тогда при многократном применении ![]() (при повторении опыта) определяются средние потери
(при повторении опыта) определяются средние потери 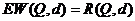 , называемые функцией риска.
, называемые функцией риска.
Цель состоит в выборе решающей функции ![]() , минимизирующей функцию риска
, минимизирующей функцию риска ![]() .
.
Байесовский подход отличается от небайесовского тем, что неизвестный параметр Q считается не фиксированной постоянной, а с. в. с известным распределением ![]() - априорным распределением.
- априорным распределением.
После завершения наблюдений над с. в. X из априорного распределения неизвестного параметра можно получить его апостериорные распределение 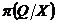 , и выбор байесовского решения естественно связывать с ожидаемыми потерями при этом апостериорном распределении
, и выбор байесовского решения естественно связывать с ожидаемыми потерями при этом апостериорном распределении ![]() .
.
Доказано, что при байесовском подходе минимальные средние потери (риск) по всем возможным значениям параметра Q и всем реализациям с. в. X достигается при той же решающей функции ![]() , при которой получаются минимальные средние потери при апостериорном распределении параметра Q.
, при которой получаются минимальные средние потери при апостериорном распределении параметра Q.
Апостериорный риск вычисляется по формуле:
|
| (1) |
| ||
![]()
![]() . (2)
. (2)
Здесь ![]() =
=![]() ;
; 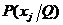 =
=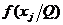 - плотность распределения с. в. Х в непрерывном случае при Х=хj
- плотность распределения с. в. Х в непрерывном случае при Х=хj
|
| (3) |
|
Формула (2) – формула Байеса, а (3) – формула полной вероятности.
Формулы (1) – (3) даны для нахождения байесовского решения минимизацией апострериорного риска по одному наблюдению. Если же ставиться задача сделать это по выборке, то в формулах (2) и (3) следует заменить вероятности 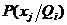 и на соответствующие функции правдоподобия
и на соответствующие функции правдоподобия 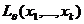 .
.
Разберем подробно две задачи оценивания неизвестного параметра Q путем нахождения байесовского решения в дискретном и непрерывном случаях с использованием формул (1), (2), (3).
Задача 1.
Пусть с. в. Х имеет бернуллиевское распределение B(1,Q), априорное распределение 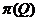 задано рядом распределения:
задано рядом распределения:
Q | 1/4 | 1/2 |
З | 1/3 | 2/3 |
а функция потерь 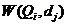 задается таблицей:
задается таблицей:
d1 | d2 | |
Q1=1/4 | 1 | 4 |
Q2=1/2 | 3 | 2 |
Где D=(d1,d2) – множество решений состоит из двух точек: d1:(Q=1/4) и d2=(Q=1/2)
Найти байесовскую оценку для неизвестного параметра Q.
Решение.
По (1) 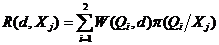 , где j=1,2 (т. к. с. в. Х принимает два значения: Х=0, Х=1).
, где j=1,2 (т. к. с. в. Х принимает два значения: Х=0, Х=1).
По (2) 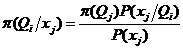
По (3) 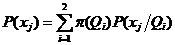 , а
, а 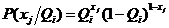 по условию задачи, откуда получаем
по условию задачи, откуда получаем 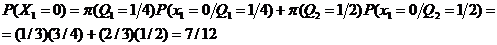
Аналогично
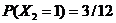
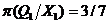
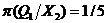
Таким образом, найдено апостриорное распределение параметра Q.
Вычислим и сравним теперь апостериорные риски при каждом наблюдаемом значении с. в. Х (Х1=0 и Х2=1) для всех решений и в качестве байесовского выберем то из них, при котором получается меньший риск.
а) Пусть Х=х1=0, тогда по (1)
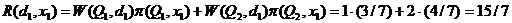
Аналогично получаем, что 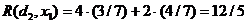
При Х=х1=0 меньший апостериорный риск при решении d1, а при Х=х2=1 – при d2, таким образом получаем байесовское правило:
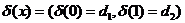
2. Пусть с. в. Х имеет экспоненциальное распределение с неизвестным параметром Q, априорное распределение которого есть гамма распределение с плотностью 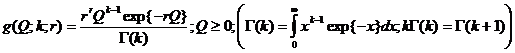
А функция потерь W(d, Q)=(Q-t)2, где решение d: t= - оценка для Q.
- оценка для Q.
Найти байесовскую оценку для параметра Q по
а) одному наблюдению Х,
б) по выборке х1,…,хn
Решение.
а) Найдем апостериорное распределение
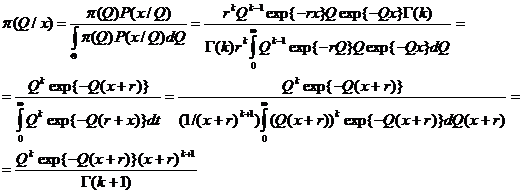
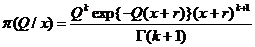 есть гамма-распределение с плотностью
есть гамма-распределение с плотностью 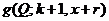 .
.
Байесовскую оценку для Q находим, минимизируя апостерионый риск R(d, x) по t.
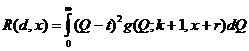 .
.
Берем производную по t и приравниваем ее к нулю. Получаем
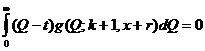 , откуда
, откуда 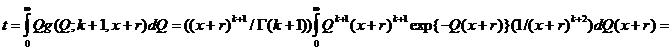
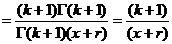 то есть
то есть 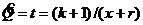 байесовская оценка для неизвестного параметра Q по наблюденному значению х.
байесовская оценка для неизвестного параметра Q по наблюденному значению х.
Апостериорный байесовский риск тогда вычисляется по формуле:
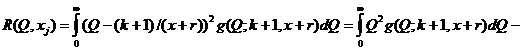
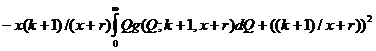
где интегралы 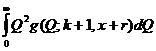 и
и 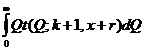 аналогично преобразуются, как было показано выше выражаются через гамма-функцию, и может быть досчитан самостоятельно.
аналогично преобразуются, как было показано выше выражаются через гамма-функцию, и может быть досчитан самостоятельно.
б) Дана выборка х1,…,хn. Найдем сначала апостериорное распределение 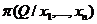 .
.
Аналогично случаю а) получаем байесовскую оценку в виде:
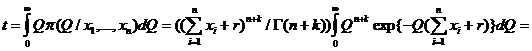
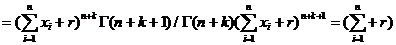 , то есть
, то есть 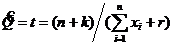 - байесовская оценка для параметра в случае б).
- байесовская оценка для параметра в случае б).
Апостериорный риск тогда в этом случае б) есть
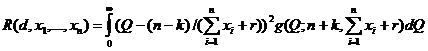 и вычисляется аналогично случаю а) и может быть получено самостоятельно.
и вычисляется аналогично случаю а) и может быть получено самостоятельно.
§6.Доверительное оценивание.
Постановка задачи.
![]() =(х1,…,хn) - выборка объёма n наблюдений над случайной величиной Х, распределение которой относится к параметрическому семейству Fθ(х), где θ=(θ1,…, θк) и θ
=(х1,…,хn) - выборка объёма n наблюдений над случайной величиной Х, распределение которой относится к параметрическому семейству Fθ(х), где θ=(θ1,…, θк) и θ![]() Θ (Θ - параметрическое множество ). Требуется оценить некоторую функцию τ=τ(θ). Доверительное оценивание τ означает нахождение κ-мерной области, заключающей неизвестное значение функции τ с заданной доверительной вероятностью γ. Подробнее остановимся на рассмотрении случая κ=1 и τ(θ)=θ. Тогда искомое доверительное множество становится доверительным интервалом, и задача состоит в построении двух статистик t1=t1(
Θ (Θ - параметрическое множество ). Требуется оценить некоторую функцию τ=τ(θ). Доверительное оценивание τ означает нахождение κ-мерной области, заключающей неизвестное значение функции τ с заданной доверительной вероятностью γ. Подробнее остановимся на рассмотрении случая κ=1 и τ(θ)=θ. Тогда искомое доверительное множество становится доверительным интервалом, и задача состоит в построении двух статистик t1=t1(![]() ) и t2=t2(
) и t2=t2(![]() )(концов доверительного интервала J=(t1,t2) заключающего в себе неизвестное значение параметра θ с заданной доверительной вероятностью γ: γ=p(t1<θ<t2)).
)(концов доверительного интервала J=(t1,t2) заключающего в себе неизвестное значение параметра θ с заданной доверительной вероятностью γ: γ=p(t1<θ<t2)).
При доверительном оценивании заданное значение γ(обычно близкое к единице) означает надёжность оценивания τ(θ) с точностью, определяемую размером доверительной области. При построении доверительного интервала для параметра θ его длина - точность оценивания, а γ - заданная надежность. Поэтому желательно строить кратчайший доверительный интервал, соответствующий наибольшей точности при данном γ.
Общий приём при нахождении доверительного интервала состоит в построении центральной статистики (ц. с.) Z=Z(θ), т. е. такой статистики, распределение которой не зависит от неизвестного параметра θ. Если Z(θ) непрерывна и монотонна по θ, то это обеспечивает однозначную эквивалентность событий {t1*<Z<t2*} и {t1<θ<t2}. Тогда, если удалось найти t1*=t1*(θ) и t2*=t2*(θ) - нижнюю и верхнюю доверительные границы, то решая неравенство t1*<Z<t2* относительно θ находим значения t1 и t2 - искомые границы доверительного интервала для неизвестного параметра θ.
Остаётся обсудить две проблемы: построение центральной статистики Z=Z(θ) и нахождение значений t1* и t2* из уравнения: γ=p(t1*<Z<t2*). (1)
Начнём с первой проблемы. Идеями построения ц. с. могут быть следующие:
1) замена исходной с. в. на новую, зависящую от неизвестного параметра θ, распределение которой не зависит от θ;
2) стандартизация имеющейся точечной оценки;
3) использование результатов ЦПТ или асимптотической нормальности ОМП (для построения асимптотических доверительных интервалов).
Вторая проблема состоит в нахождении значений t1* и t2* из уравнения (1). Требуется сформулировать дополнительное ограничение на t1* и t2*, чтобы это было возможно, т. е. чтобы уменьшить число неизвестных в уравнении (1) с двух до одной.
При решении этой проблемы различают, обычно, два случая: регулярный и нерегулярный (раньше определён регулярный случай требованиями дифференцируемости функции правдоподобия L и независимости области, в которой L![]() 0, от неизвестного параметра θ).
0, от неизвестного параметра θ).
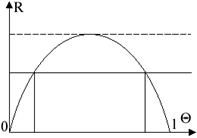
Регулярный случай: строят центральный доверительный интервал (ц. д.и.). Определим ц. д.и. Пусть ![]() - кривая распределения неизвестного параметра θ:
- кривая распределения неизвестного параметра θ:
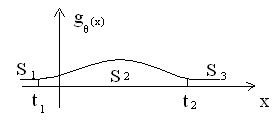
Тогда J=(t1,t2) - ц. д.и., если площади S1 и S3 одинаковы.
Определим хр - p-квантиль распределения F(x) если хр - корень уравнения F(x)=p.
Теперь выразим значения t1 и t2 в терминах квантилит распределения параметра θ с функцией распределения G(θ): S1+S2+S3=1. Пусть S2=γ, тогда
S1=S3=![]() , откуда следует, что t1-
, откуда следует, что t1-![]() - квантиль, а t2=(
- квантиль, а t2=(![]() +γ)=
+γ)=![]() - квантиль распределения. Значит ц. д.с. - интервал между
- квантиль распределения. Значит ц. д.с. - интервал между ![]() и
и ![]() - квантилями распределения G(θ). Таким образом, требование построения ц. д.и. и есть необходимое дополнительное требование в уравнении (1).
- квантилями распределения G(θ). Таким образом, требование построения ц. д.и. и есть необходимое дополнительное требование в уравнении (1).
Нерегулярный случай: в качестве искомого доверительного интервала в уравнении (1) выбирают крайнюю зону значений неизвестного параметра. Тогда число неизвестных в уравнении (1) уменьшается до одного.
Построение доверительных интервалов (Д. И.).
Примеры:
1. X~R[2Q-1,3Q+4]. Построить д. и. с уровнем доверия ![]() для неизвестного параметра Q.
для неизвестного параметра Q.
Решение. Введем новую случайную величину (с. в.) Y=X-2Q+1, тогда Y~R[0,Q+5]=R[0,Q*], где Q=Q+5. Построим д. и. с доверительным уровнем ![]() для параметра Q.
для параметра Q.
Обозначим Z=Y(n)/Q*, тогда Fz (Y)=P{Y(n)< Q*y}=y![]() - это функция распределения максимума выборки n равномерно распределенных на [0,1] значений y1,…,yn.
- это функция распределения максимума выборки n равномерно распределенных на [0,1] значений y1,…,yn.
P{![]() < Y(n) / Q* < 1}=
< Y(n) / Q* < 1}= ![]() = P{
= P{![]() <Z < 1}=Fz(1)-Fz(
<Z < 1}=Fz(1)-Fz(![]() )= 1-
)= 1-![]() , откуда
, откуда
![]() =P{Y(n)<Q*=Q+5<Y(n)
=P{Y(n)<Q*=Q+5<Y(n)![]()
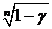 }=P{
}=P{![]() -2Q-4<Q<
-2Q-4<Q<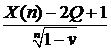 -5}.
-5}.
или с вероятностью ![]() выполнены неравенства:
выполнены неравенства:
или 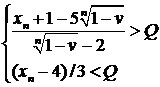
то есть 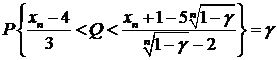
2. X ~ E(aQ+b). Построить д. и. для неизвестного параметра Q с уровнем доверия ![]() .
.
Решение. Обозначим Q*=aQ+b и построим сначала д. и. для параметра Q с уровнем доверия ![]() .
.
X~E(Q*), F(![]() )=1-exp{-Q*
)=1-exp{-Q*![]() }, x ≥ 0, F(1)(x)=1-
}, x ≥ 0, F(1)(x)=1-![]() =1-exp{-Q*nx}.
=1-exp{-Q*nx}.
Введем новую с. в. Y=Q*![]() .
.
FY(x)=P{x(1)<x/Q*}=F(1)(x/Q*)=1-exp{-nx} - это функция распределения минимума выборки экспоненциально распределенных значений Y1,…,Yn с. в. Y~E(1), поэтому
![]() =P
=P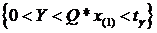 =P
=P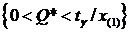 =FY(
=FY(![]() )-FY(0)=1-exp{-n
)-FY(0)=1-exp{-n![]() }, откуда
}, откуда
![]() =-(ln(1-
=-(ln(1-![]() ))/n. Тогда
))/n. Тогда
P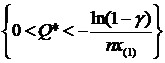 =P
=P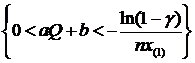 = =P
= =P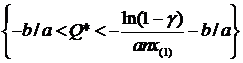 ,
,
То есть требуемый интервал для Q построен.
Рассмотрим приведенные выше идеи построения центральной статистики на примерах, и с их помощью нахождения доверительных интервалов для ![]() параметра θ.
параметра θ.
Примеры (на применение идеи 1).
1. Построить доверительный интервал Y(t1,t2) для параметра θ: X~R[aθ+b, cθ +d], (равномерное распределение), где а, Ь, с, d -const, а θ-неизвестный параметр.
Решение: проведем стандартизацию данного распределения. Введем новую случайную величину Y= Х - аθ- b, тогда Y~R[0, θ*], где θ*=(с-а)θ + d-b.
Построим сначала доверительный интервал для параметра θ* с уровнем
доверия γ. Для этого рассмотрим случайную величину Z=![]() и найдем ее распределение: F
и найдем ее распределение: F![]() (y)=P{Z<y} = P
(y)=P{Z<y} = P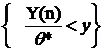 =P{Y(n)<y} = =FY(n)(θ *у) =
=P{Y(n)<y} = =FY(n)(θ *у) = ![]() (θ*y)=yn при θ*у
(θ*y)=yn при θ*у![]() [0; θ*], следовательно, случайная величина как W(n) , где случайная величина W(n) ~R[0, 1] и распределение не зависит от неизвестного параметра θ*, следовательно, Z - центральная статистика. Очевидно, что наш кратчайший доверительный интервал для случайной величины Z с заданным уровнем доверия находится в области наиболее вероятных ее значений, т. е. имеет вид (tγ,l): γn=P{tγ<Z<1}=P
[0; θ*], следовательно, случайная величина как W(n) , где случайная величина W(n) ~R[0, 1] и распределение не зависит от неизвестного параметра θ*, следовательно, Z - центральная статистика. Очевидно, что наш кратчайший доверительный интервал для случайной величины Z с заданным уровнем доверия находится в области наиболее вероятных ее значений, т. е. имеет вид (tγ,l): γn=P{tγ<Z<1}=P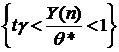 , значит tγ находим из уравнения 1-
, значит tγ находим из уравнения 1-![]() =γ, следовательно,
=γ, следовательно, ![]() =
=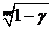 и доверительный интервал с уровнем доверия для Z есть (
и доверительный интервал с уровнем доверия для Z есть (![]() ,1) , значит γ=
,1) , значит γ=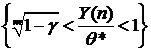 = =
= =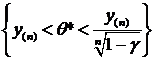 =P
=P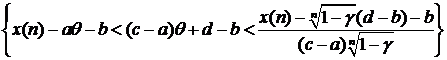 , следовательно,
, следовательно, 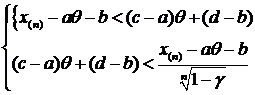
![]()
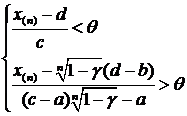
![]()
![]() γ=P
γ=P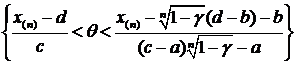 =Y=(t1,t
=Y=(t1,t
Искомый интервал Y для параметра θ построен.
2.X~E(θ*)
F(X)=1-exp{- θ *}, x ≥ 0, F(1)(x)=1-![]() =1-exp{- θ *nx}.
=1-exp{- θ *nx}.
Введем новую с. в. Y= θ *x(1).
![]() (x)=P{x(1)<x/ θ *}=F(1)(x
(x)=P{x(1)<x/ θ *}=F(1)(x
