

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Алгоритмы выделения разделителей в задаче сегментации графического образа документа.
,
Одной из важных задач, стоящих в области распознавания документов, является задача сегментации. В данной статье представлены алгоритмы по выделению и классификации разделителей фрагментов изображения документа, которые предлагается использовать для решения задачи сегментации. Анализируются свободные от информации области бинаризованных изображений документов. Выделяются горизонтальные полосы и вертикальные ручьи. Решены две задачи. Первая, это определение является ли заданная область документа строчной, то есть текстовой и строки в ней не сбиваются. Вторая, это определение является ли колонкой текста заданная строчная область документа.
1 Введение
Распознавание документов – это обширная область для исследований с большим многообразием перспективных разработок. Многие ученые работают на этой областью десятилетиями, существует большое количество литературы на эту тему.
Под распознаванием документов обычно подразумевают процесс преобразования информативного содержания документа из бумажного варианта в электронный вариант с сохранением логического содержания и, по возможности, форматирования [3]. Сегментация (zoning) – это процесс идентификации текстовых областей, картинок, таблиц, математических формул, а также определение порядка их следования или взаимного расположения. Под сегментацией понимается взаимодействие геометрической и логической сегментации (geometric and logical segmentation analysis). Геометрическая сегментация занимается выделением геометрической структуры документа. Этот этап включает в себя следующие шаги: предобработка (preprocessing step) и разбиение (page decomposition). Последний шаг – это разбиение образа документа на максимальные области, которые относятся по содержанию к различным типам. К предобработке обычно относят бинаризацию и нахождение угла наклона (skew) страницы. Под логической сегментацией понимается поиск различных логических интерпретаций для найденных областей (заголовок, параграф, подпись и т. п.) и отношений между областями (подпись к картинке, колонки, фреймы и т. п.).
В данной статье нас интересуют базовые алгоритмы в задаче сегментации.
2 Выделение разделителей
2.1 Проблемная область
Рассмотрим алгоритмы сегментации, основанные на анализе свободных от информации областей изображения документа. В данной статье нас будут интересовать бинаризованные образы документов, в которых информационное заполнение черное, а фон белый. Для алгоритма разбиения требуется структурированная информация о свободных областях. Существуют разные способы их представления и анализа. В статье [5] описывается алгоритм, основанный на представлении заранее сглаженных белых областей квадратами и восьмиугольниками. Бройль (Breuel) [1] для своего анализа покрывает белые области максимальными прямоугольниками. В статье [2] он использует максимальные прямоугольники произвольной ориентации. В виде цепочек белые области представлены в статье [4], они образуют циклы и тем самым ограничивают блоки. Задача сегментация основана на классификации цепочек и их последующем удалении. Оставшиеся цепочки образуют циклы, которые и делят документ на блоки.
В данной статье белые области представляются в виде пересекающихся горизонтальных полос и вертикальных ручьев, так называемых разделителей. Будем считать, что распознаваемый документ уже прошел процесс предобработки, а именно была выполнена бинаризация, сняты линии, выделены коробки компонент связности и найден угол наклона.
2.2 Горизонтальные полосы
Под горизонтальной полосой будем понимать прямоугольник. У нее могут быть уточняющие от одной вертикали до другой вертикали прямоугольники, которые расположены по оси Y на расстоянии, не превышающем заданную константу y, как изображено на рисунке 1. В дальнейшем горизонтальные полосы будем также называть сокращенно горизонталями.
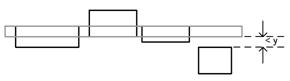
Рисунок 1. Горизонтальная полоса
2.2.1 Выделение горизонтальных полос
Для выделения горизонталей используется алгоритм выделения горизонтальных линий от края до края. На вход алгоритму подается набор компонент и интересующая область. На выходе горизонтальные линии, которые определяются прямоугольниками.
Для выделения полос используется проекция уменьшенных компонент на вертикальную ось Y. Найденные разреженные области на проекции считаются белыми линиями. Далее между соседними линиями предполагается строка текста, и ищутся ее базовые линии. Если подтверждается наличие строки текста, то линии уточняются.
2.3 Определение строчности
Для определения строчности найдем горизонтали для всей исходной области. Далее поделим область на N частей по вертикали и для каждой части найдем горизонтали. Теперь остается проанализировать полученную информацию. Если горизонтали в частях области не противоречат горизонталям найденным во всей области, то будем считать, документ строчным. Например, как показано на рисунке 2, если были найдены новые горизонтали, то область документа не строчная.

Рисунок 2. Пример не строчного документа
2.4 Вертикальные ручьи
Под вертикальным ручьем будем понимать набор прямоугольников, расположенных друг над другом. Из определения следует, что для вертикального ручья можно задать кривую, которая будет для нее «центром тяжести». В дальнейшем вертикальные ручьи будем также называть сокращенно вертикалями. Пример вертикали приведен на рисунке 3.
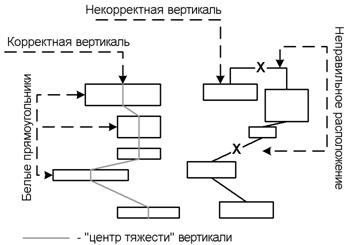
Рисунок 3. Пример корректного и некорректного вертикальных ручьев
2.4.1 Выделение вертикальных ручьев
После того как были найдены горизонтали от края до края, строим черно-белые полосы между горизонталями следующим образом. Берем коробки, которые пересекаются с черно-белой полосой, и размазываем их по полосе вдоль вертикали. Получается, что черно-белая полоса состоит из черных и белых прямоугольников, как показано на рисунке 4.
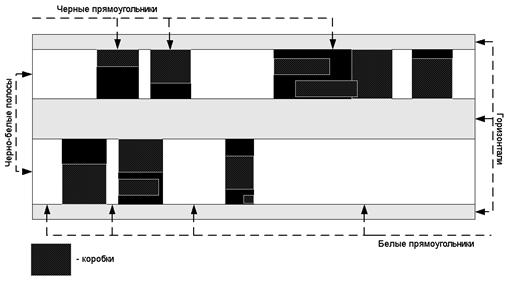
Рисунок 4. Черно-белые полосы и составляющие их прямоугольники
Далее из белых прямоугольников строим вертикали. Перебираем черно-белые полосы сверху вниз. При этом создаем и развиваем вертикальные ручьи, опираясь на их определение. Если возникает ситуация, что вертикаль можно продолжить несколькими разными белыми прямоугольниками, то, как показано на рисунке 5 для случая прямоугольника P3, выбираем прямоугольник с максимальной общей горизонтальной проекцией. Ниже приведен псевдокод построения вертикалей из белых прямоугольников:
while BlackWhiteLine exist:
if BlackWhileLinePrev not exist
then
while WhiteRect from BlackWhiteLine:
curves. add_new(WhiteRect)
next WhileRect
else
arrayWhiteAddToCurve. clear()
while WhitePrevRect from BlackWhiteLinePrev:
bestWhiteRect = BlackWhiteLine. getBest(WhitePrevRect)
if bestWhitePrevRect exist
then
curves. getByRect(WhitePrevRect).addRect(bestWhiteRect)
arrayWhiteAddToCurve. add(bestWhiteRect)
endif
next WhitePrevRect
while WhiteRect from BalckWhiteLine:
if WhiteRect not in arrayWhiteAddToCurve
then
curves. add_new(WhiteRect)
endif
next WhiteRect
endif
BlackWhiteLinePrev = BlackWhiteLine
next BlackWhiteLine
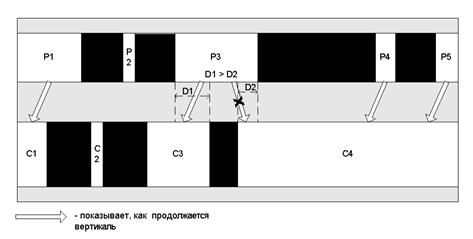
Рисунок 5. Построение вертикалей из белых прямоугольников
Из белых прямоугольников, изображенных на рисунке 5, получится 6 вертикалей.
Вертикаль V1 состоящая из: P1, C1; V2: P2; V3: P3, C3; V4: P4, C4; V5: P5, C4; V6: C2.Белый прямоугольник может принадлежать нескольким вертикалям. При этом самый верхний прямоугольник вертикали принадлежит только ей одной.
Надо заметить, что получается несимметричная картина, так как если бы мы строили вертикали снизу вверх, то получили бы в некоторых случаях другой результат. Данный недостаток не сильно влияет на описание метода и на результат, поэтому оставим решение этой проблемы без внимания, тем более что построение симметричной картины усложнит описание всего алгоритма выделения разделителей.
2.4.2 Классификация вертикальных ручьев
Теперь у нас есть множество вертикалей и нужно уметь их классифицировать. Для того, чтобы отбросить явный мусор, вводим оценочную функцию для вертикалей номер 1:
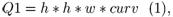
где

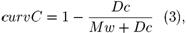
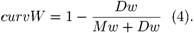
Здесь h – высота, которая задается количеством составляющих вертикаль прямоугольников. Ширина w вычисляется как
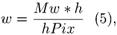
где hPix – высота в пикселях. curv – кривизна, curvC – кривизна середины, curvW – непостоянство ширины. Dс и Dw – это корни из дисперсий соответственно середины и ширины в пикселях, Mw – математическое ожидание ширины в пикселях.
Упорядочиваем оценки вертикалей по возрастанию и берем производную. Потом ищем скачок значения производной больше константы DERV_MIN. Считаем что все вертикали, оценки которых левее этого скачка, являются межбуквенными вертикалями. Для большей точности можно дополнительно требовать еще и скачок производной сглаженной гистограммы оценок вертикалей. Запоминаем граничное значение оценки QBorder.
Далее для оставшихся вертикалей ищем максимальные прямоугольники [1]. При этом накладываем условие, что для любой координаты Y всегда есть единственный максимальный прямоугольник.
Теперь введем более точную оценку вертикали - оценочную функцию для вертикалей номер 2:
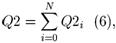
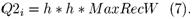
N – количество максимальных прямоугольников. Кривизна не учитывается, так как ее нет у максимального прямоугольника. MaxRecW – вычисляется, как и w в формуле (5), только подставляются ширина и высота максимального прямоугольника вместо ширины и высоты вертикального ручья.
Введем Q3 – более жесткую оценочную функцию для вертикалей номер 3, которая учитывает кривизну вертикали. Q3 отличается от Q2 только тем, что суммирование оценок ![]() идет мере их убывания, при этом если следующая оценка в Q3_THRESHOLD раз меньше предыдущей, то суммирование останавливается. Отбросим вертикали, оценка Q3 которых < QBorder.
идет мере их убывания, при этом если следующая оценка в Q3_THRESHOLD раз меньше предыдущей, то суммирование останавливается. Отбросим вертикали, оценка Q3 которых < QBorder.
Далее мы постараемся уменьшить количество вертикальных ручьев за счет их разрезания на части. Дело в том, что, так как вертикалям разрешено иметь общие белые прямоугольники, часто встречается ситуация, когда есть общая большая белая область, за счет которой несколько вертикалей пытаются выделиться. Сделаем так, чтобы большие области учитывались только в одной вертикали.
Упорядочим оставшиеся вертикали по убыванию Q2. Будем их перебирать и запоминать составляющие их белые прямоугольники. У каждой вертикали есть максимальный прямоугольник с лучшей оценкой. Рассмотрим все белые прямоугольники, составляющие вертикаль, и пересекающиеся с выбранным максимальным прямоугольником. Если среди этих белых прямоугольников есть хоть один, который еще не был запомнен, то запомним его и перейдем к следующей вертикали. Иначе разрежем на части данную вертикаль максимальным прямоугольником и получившиеся части добавим в наше множество вертикалей упорядоченных по Q2. При этом не забудем отбросить вертикали, у которых Q3 < QBorder. Оставшиеся вертикали объявляем кандидатами на разрезание.
На рисунках 6,7,8 показаны примеры соответственно всех найденных вертикалей, результат их классификации и максимальные прямоугольники для вертикалей-кандидатов на разрезание.
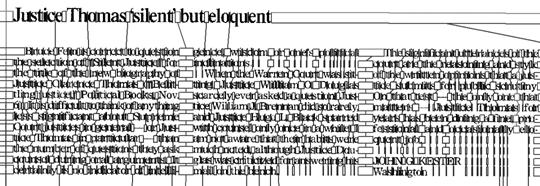
Рисунок 6. Все найденные вертикали

Рисунок 7. Вертикали - кандидаты на разрезание

Рисунок 8. Максимальные прямоугольники вертикалей-кандидатов на разрезание
2.5 Определение простоты текстовой области документа
Под простой текстовой областью будем понимать колонку текста. Для этого сначала определим, что область графического документа строчная. Потом найдем вертикали, и если среди них нет кандидатов на разрезание, то объявляем область текстовой и простой.
3 Результаты
При выделении сырья можно выделить два промежуточных результата: определение строчности и простоты. Данные по работе этих алгоритмов представлены ниже в таблицах.
Таблица 1. Характеристики стенда
Индекс стенда | Название стенда | количество документов | количество строчных документов | количество не строчных документов | |
простых | не простых | ||||
RusEng | Документы с русско-английским текстом | 108 | 108 | 0 | 0 |
Eng | Документы с английским текстом | 161 | 160 | 1 | 0 |
Rus | Документы с русским текстом | 229 | 229 | 0 | 0 |
Mix | Разные документы, в том числе и со сложной структурой (газеты, журналы, ...) | 110 | 7 | 49 | 54 |
Таблица 2. Результаты алгоритма определения строчности. N=3
Индекс стенда | определились как строчные | не знаю | Точность | Информативность | ||
строчные на самом деле | не строчные на самом деле | строчные на самом деле | не строчные на самом деле | |||
RusEng | 105 | 0 | 3 | 0 | 100% | 97,22% |
Eng | 156 | 0 | 5 | 0 | 100% | 96,89% |
Rus | 220 | 0 | 9 | 0 | 100% | 96,07% |
Mix | 34 | 0 | 22 | 54 | 100% | 60,71% |
Таблица 3. Результаты алгоритма определения простоты. DERV_MIN=30, Q3_THRESHOLD=2
Индекс стенда | определились как простые | определились как не простые | Точность | ||
сложная структура на самом деле | безразличные[1] на самом деле | ошибка из-за грязи | |||
RusEng | 102 | 0 | 2 | 1 | 99,05% |
Eng | 141 | 1 | 14 | 0 | 100% |
Rus | 212 | 0 | 7 | 1 | 99,55% |
Mix | 7 | 27 | 0 | 0 | 100% |
4 Заключение
В статье были описаны алгоритмы по выделению и классификации белых областей распознаваемого документа. Получены промежуточные результаты, которые можно использовать в виде отдельных алгоритмов при решении общей задачи сегментации.
Многие методы сегментации опираются на области информативного заполнения документа. В случае бинаризованого изображения – это, как правило, черные области. Предлагаемые в данной статье алгоритмы для сегментации оперируют свободными от информации областями, представляя их в виде пересекающихся горизонталей и вертикалей.
Алгоритмы, оперирующие свободными от заполнения областями, обеспечивают лучшие результаты при обработке изображений сложно структурированных документов плотного заполнения. Описанные в данной статье алгоритмы вносят заметный вклад в развитие этого направления.
5 Литература
[1] T. M. Breuel. Two algorithms for geometric layout analysis. In Proceedings of the Workshop on Document Analysis Systems, Princeton, NJ, USA, 2002.
[2] T. M. Breuel. High Performance Document Layout Analysis. PARC, Palo Alto, CA, USA, 2003.
[3] R. Cattoni, T. Coianiz, S. Messelodi, and C. M. Modena. Geometric layout analysis techniques for document image understanding: a review. Technical report, IRST, Trento, Italy, 1998.
[4] K. Kise, O. Yanagida and S. Takamatsu. Page Segmentation Base on Thinning of Background. In Proc. of the 13th International Conference on Pattern Recognition, page 788-792, Vienna, Austria, August 1996. IEEE Press.
[5] N. Norman, C. Viard-Gaudin. A Background Based Adaptive Page Segmentation Algorithm. In Proc. of the 3th International Conference on Document Analysis and Recognition, page 138-141, Montreal, Canada, August 1995.
[1] списки и вырожденные таблицы
