

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Гибридная схема предсказания переходов, предложенная Макфарлингом [165], содержит два элементарных предиктора, отличающихся по своим характеристикам (размером таблиц предыстории и временем «разогрева») и работающих независимо друг от друга. Выбор предиктора, наиболее подходящего в данной ситуации, обеспечивается селектором, представляющим собой таблицу двухразрядных счетчиков, которые часто называют счетчиками выбора предиктора (рис.9.32).
Адресация конкретного счетчика в таблице (индексирование) осуществляет k младшими разрядами адреса команды условного перехода, для которой осуществляется предсказание. Обновление таблиц истории в каждом из предиктор производится обычным образом, как это происходит при их автономном использовании.
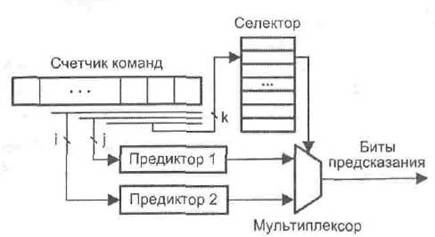
Рис. 9.32. Гибридный предиктор Макфарлинга
В свою очередь, изменение состояния счетчиков селектора выполняется по следующим правилам. Если оба предиктора одновременно дали одинаковое предсказание (верное или неверное), содержимое счетчика не изменяется. При правильном предсказании от первого предиктора и неверном от второго содержимое счетчика увеличивается, а в противоположном случае — уменьшается на единицу. Выбор предиктора, на основании которого делается результирующая оценка, реализуется с помощью мультиплексора, управляемого старшим разрядом соответствующего счетчика селектора.
В работе [95] идея гибридного механизма была обобщена на случай n предикторов. Общая структура такой схемы предсказания переходов показана на рис. 9.33. При выполнении команды УП предсказания формируются одновременно всеми предикторами, однако реальные действия осуществляются на основании только одного из них.
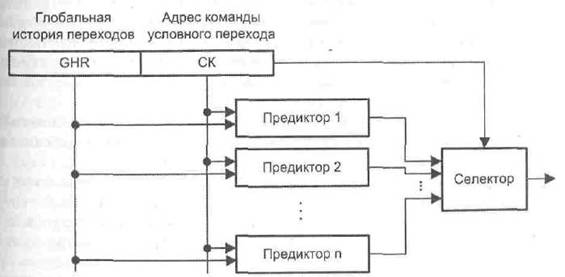
Рис. 9.33. Общая схема гибридного предиктора
Выбор подходящего предиктора обеспечивает механизм селекции (рис. 9.34). В схеме имеется буфер предыстории переходов (ВТВ), в котором каждая запись дополнена п двухразрядными счетчиками выбора предиктора, по числу используемых элементарных предикторов. Счетчики позволяют отследить самый предпочтительный элементарный предиктор для каждой команды УП, представленной в ВТВ.
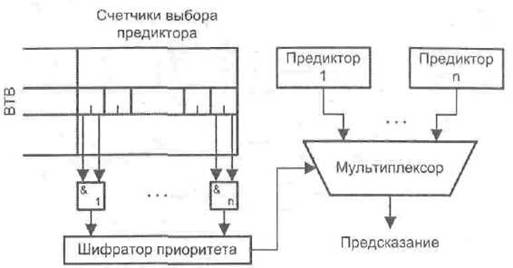
Рис. 9.34. Механизм выбора предиктора
При записи в ВТВ нового элемента во все ассоциированные с ним счетчики заносится число 3. Для каждой команды условного перехода предсказание генерируется всеми п предикторами, но во внимание принимаются только те из них, для которых соответствующий счетчик выбора предиктора содержит число 3. Если это число встретилось более чем в одном счетчике, выбор единственного предиктора, на основании которого и делается окончательное предсказание, обеспечивает шифратор приоритета. После выполнения команды условного перехода содержимое соответствующих ей счетчиков выбора обновляется, при этом действует следующий алгоритм. Если среди предикторов, счетчики которых равнялись 3, хотя бы один дал верное предсказание, то содержимое всех счетчиков, связанных с неверно сработавшими предикторами, уменьшается на единицу. В противном случае содержимое всех счетчиков, связанных с предикторами, прогноз которых подтвердился, увеличивается на единицу. Такая политика гарантирует, что по крайней J мере в одном из счетчиков будет число 3. Еще одно преимущество рассматриваемой схемы выбора состоит в том, что она позволяет, например, отличить предиктор-«оракул», давший правильное предсказание последние пять раз, от предиктора, верно определившего исход последние четыре раза. Стандартные счетчики с насыщением такую дифференциацию не обеспечивают.
По имеющимся оценкам, точность предсказания переходов с помощью гибридных стратегий в среднем составляет 97,13%, что существенно выше по сравнению с прочими вариантами.
Асимметричная схема предсказания переходов. Асимметричная схема сочетает в себе черты гибридных и коррелированных схем предсказания. От гибридных схем она переняла одновременное срабатывание нескольких различных элементарных предикторов. В асимметричной схеме таких предикторов три, и каждый из них использует собственную таблицу РНТ. Для доступа к таблицам, аналогично коррелированным схемам, используется как адрес команды условного перехода, так и содержимое регистра глобальной истории (рис. 9.35).
Шаблон для обращения к каждой из трех РНТ формируется по-разному (применены различные функции кэширования). При выполнении команды условного перехода каждый из трех предикторов выдвигает свое предположение, но окончательное решение принимается по мажоритарной схеме. После завершения команды условного перехода содержимое всех трех таблиц обновляется.
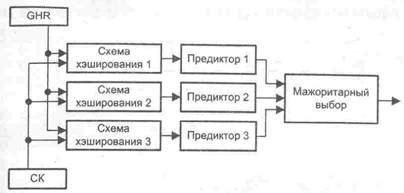
Рис. 9.35. Структура асимметричной схемы предсказания переходов
Правильный подбор алгоритмов кэширования позволяет практически исключить влияние на точность предсказания эффекта наложения. Средняя точность предсказания с помощью асимметричной схемы, полученная на тестовом пакете SPEC_95, составила 72,6%.
Суперконвейерные процессоры
Эффективность конвейера находится в прямой зависимости от того, с какой частотой на его вход подаются объекты обработки. Добиться n-кратного увеличения темпа работы конвейера можно двумя путями:
■ разбиением каждой ступени конвейера на п «подступеней» при одновременном повышении тактовой частоты внутри конвейера также в п раз;
■ включением в состав процессора п конвейеров, работающих с перекрытием.
В данном разделе рассматривается первый из этих подходов, известный как суперконвейеризация (термин впервые был применен в 1988 году). Иллюстрацией эффекта суперконвейеризации может служить диаграмма, приведенная на рис. 9.36, где рассмотрен ранее обсуждавшийся пример (см, рис. 9.3). Каждая из шести ступеней стандартного конвейера разбита па две более простые подступени, обозначенные индексами 1 и 2. Выполнение операции в подступенях занимает половину тактового периода. Тактирование операций внутри конвейера производится с частотой, вдвое превышающей частоту «внешнего» тактирования конвейера, благодаря чему на каждой ступени конвейера можно в пределах одного «внешнего» тактового периода выполнить две команды.
В сущности, суперконвейеризация сводится к увеличению количества ступеней конвейера, как за счет добавления новых ступеней, так и путем дробления имеющихся ступеней на несколько простых подступеней. Главное требование — возможность реализации операции в каждой подступени наиболее простыми техническими средствами, а значит, с минимальными затратами времени. Вторым, не менее важным, условием является одинаковость задержки во всех подступенях.
Критерием для причисления процессора к суперконвейерным служит число ступеней в конвейере команд. К суперконвейерным относят процессоры, где таких ступеней больше шести. Первым серийным суперконвейерным процессором считается MIPS R4000, конвейер команд которого включает в себя восемь ступеней.
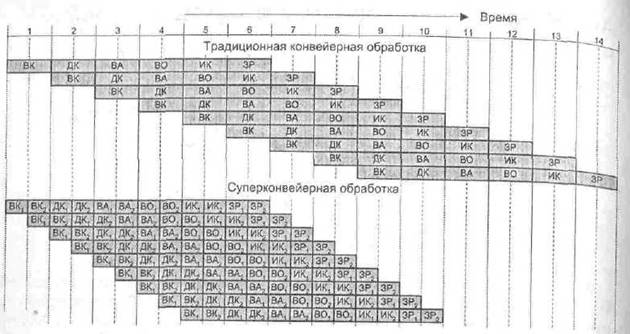
Рис. 9.36. Традиционная и суперконвейерная обработка команд
Суперконвейеризация здесь стала следствием разбиения этапов выборки команды и выборки операнда, а также введения в конвейер дополнительного этапа проверки тега, появление которой обусловлено архитектурой системы команд машины.
Таблица 9.1. Длина конвейера команд в популярных микропроцессорах
Тип микропроцессора | Количество ступеней в конвейере команд |
MIPSR4400 | 8 |
UltraSPARC I | 9 |
Pentium III | 10 |
Itanium | 10 |
UltraSPARC III | 14 |
Pentium 4 | 20 |
К сожалению, выигрыш, достигаемый за счет суперконвейеризации, на практике может оказаться лишь умозрительным. Удлинение конвейера ведет не только к усугублению проблем, характерных для любого конвейера, но и возникновению дополнительных сложностей. В длинном конвейере возрастает вероятность конфликтов. Дороже встает ошибка предсказания перехода — приходится очищать большее число ступеней конвейера, на что требуется больше времени. Усложняется логика взаимодействия ступеней конвейера. Тем не менее создателям ВМ удается успешно справляться с большинством из перечисленных проблем, свидетельством чего служит неуклонное возрастание числа ступеней в конвейерах команд современных процессоров (табл. 9.1).
Архитектуры с полным и сокращенным набором команд
Современная технология программирования ориентирована на языки высокого уровня (ЯВУ), главная задача которых —облегчить процесс написания программ. Более 90% всего процесса программирования осуществляют на ЯВУ. К сожалению, операции, характерные для ЯВУ, отличаются от операций, реализуемых машинными командами. Эта проблема получила название семантического разрыва и ведет она к недостаточно эффективному выполнению программ. Пытаясь преодолеть семантический разрыв, разработчики ВМ расширяют систему команд, дополняя ее командами, реализующими сложные операторы ЯВУ на аппаратурном уровне, вводят дополнительные виды адресации и т. п. Вычислительные машины, где реализованы эти средства, принято называть ВМ с полным набором команд (CISC — Complex Instruction Set Computer). К типу CISC можно отнести практически все ВМ, выпускавшиеся до середины 80-х годов и значительную часть из выпускаемых в настоящее время.
Характерные для CISC способы решения проблемы семантического разрыва, вместе с тем ведут к усложнению архитектуры ВМ, главным образом устройства управления, что, в свою очередь, негативно сказывается на производительности в целом. Кроме того, в CISC очень сложно организовать эффективный конвейер команд, который, как уже отмечалось, является одним из наиболее перспективных путей повышения производительности ВМ. Все это заставило более внимательно проанализировать программы, получаемые после компиляции с ЯВУ, Был предпринят комплекс исследований [128,158,177,178,209], в результате которых обнаружились интересные закономерности:
■ Реализация сложных команд, эквивалентных операторам ЯВУ, требует увеличения емкости управляющей памяти в микропрограммном УУ. Микропрограммы сложных команд могут занимать до 60% управляющей памяти, в то время как их доля в общем объеме программы зачастую не превышает 0,2%.
■ В откомпилированной программе операторы ЯВУ реализуются в виде процедур (подпрограмм), поэтому на операции вызова процедуры и возврата из нее приходится от 15 до 45% вычислительной нагрузки.
■ При вызове процедуры вызывающая программа передает этой процедуре некоторое количество аргументов. Согласно [209], в 98% случаев число передаваемых аргументов не превышает шести. Примерно такое же положение сложилось и с параметрами, которые процедура возвращает вызывающей программе. Более 80% переменных, используемых программой [177,178], являются локальными, то есть создаются при входе в процедуру и уничтожаются при выходе из нее. Количество локальных переменных, создаваемых отдельной процедурой, в 92% случаев не превышает шести [209].
■ Почти половину операций в ходе вычислений составляет операция присваивания, сводящаяся к пересылке данных между регистрами, ячейками памяти или регистрами и памятью.
Детальный анализ результатов исследований привел к серьезному пересмотру традиционных архитектурных решений, следствием чего стало появление «архитектуры с сокращенным набором команд (RISC — Reduced Instruction Set Computer) Термин «RISC» впервые был использован Паттерсоном и Дитцелем в 1980 году.
Основные черты RISC-архитектуры
Главные усилия в архитектуре RISC направлены на построение максимально эффективного конвейера команд, то есть такого, где все команды извлекаются из памяти и поступают в ЦП на обработку в виде равномерного потока, причем ни одна команда не должна находиться в состоянии ожидания, а ЦП должен оставаться загруженным на протяжении всего времени. Кроме того, идеальным будет вариант когда любой этап цикла команды выполняется в течение одного тактового периода.
Последнее условие относительно просто можно реализовать для этапа выборки Необходимо лишь, чтобы все команды имели стандартную длину, равную ширине шины данных, соединяющей ЦП и память. Унификация времени исполнения для различных команд — значительно более сложная задача, поскольку наряду с регистровыми существуют также команды с обращением к памяти.
Помимо одинаковой длины команд, важно иметь относительно простую подсистему декодирования и управления: сложное устройство управления (УУ) будет вносить дополнительные задержки в формирование сигналов управления. Очевидный путь существенного упрощения УУ — сокращение числа выполняемых команд, форматов команд и данных, а также видов адресации.
Излишне напоминать, что в сокращенном списке команд должны оставаться те, которые используются наиболее часто. Исследования показали, что 80-90% времени выполнения типовых программ приходится на относительно малую часть команд (10-20%). К наиболее часто востребуемым действиям относятся пересылка данных, арифметические и логические операции. Основная причина, препятствующая сведению всех этапов цикла команды к одному тактовому периоду, — потенциальная необходимость доступа к памяти для выборки операндов п/или записи результатов. Следует максимально сократить число команд, имеющих доступ к памяти. Это соображение добавляет к ранее упомянутым принципам RISC еще два:
■ доступ к памяти во время исполнения осуществляется только командами «Чтение» и «Запись»; ■ все операции, кроме «Чтение» и «Запись», имеют тип «регистр-регистр».
Для упрощения выполнения большинства команд и приведения их к типу «регистр-регистр» требуется снабдить ЦП значительным числом регистров общего назначения. Большое число регистров в регистровом файле ЦП позволяет обеспечить временное хранение промежуточных результатов, используемых как операнды в последующих операциях, и ведет к уменьшению числа обращений к памяти» ускоряя выполнение операций. Минимальное число регистров, равное 32, прнято как стандарт де-факто большинством производителей RISC-компьютеров.
Суммируя сказанное, концепцию RISC-компьютера можно свести к следующим положениям:
■ выполнение всех (или, по крайней мере, 75% команд) за один цикл;
■ стандартная однословная длина всех команд, равная естественной длине слова и ширине шины данных и допускающая унифицированную поточную обработку всех команд;
■ малое число команд (не более 128);
■ малое количество форматов команд (не более 4);
■ малое число способов адресации (не более 4);
■ доступ к памяти только посредством команд «Чтение» п «Запись»;
■ все команды, за исключением «Чтения» и «Записи», используют внутрипроцессорные межрегистровые пересылки;
■ устройство управления «жесткой» логикой;
■ относительно большой (не менее 32) процессорный файл регистров общего назначения (согласно [210] число РОН в современных RISC-микропроцессорах может превышать 500).
Регистры в RISC-процессорах
Отличительная черта RISC-архитектуры — большое число регистров общего назначения, что объясняется стремлением свести все пересылки к типу «регистр-регистр». Но увеличение числа РОН способно дать эффект лишь при разумном их использовании. Оптимизация использования регистров в RISC-процессорах обеспечивается как программными, так и аппаратными средствами.
Программная оптимизация выполняется на этапе компиляции программы, написанной на ЯВУ. Компилятор стремится так распределить регистры процессора, чтобы разместить и них те переменные, которые в течение заданного периода времени будут использоваться наиболее интенсивно.
На начальном этапе компилятор выделяет каждой переменной виртуальный регистр. Число виртуальных регистров в принципе не ограничено. Затем компилятор отображает виртуальные регистры па ограниченное количество физических регистров. Виртуальные регистры, использование которых не перекрывается, отображаются на один и тот же физический регистр. Если в определенном фрагменте программы физических регистров не хватает, то их роль для оставшихся виртуальных регистров выполняют ячейки памяти. В ходе вычислений содержимое каждой такой ячейки с помощью команды «Чтение» временно засылается в регистр, после чего командой «Запись» вновь возвращается в ячейку памяти.
Задача оптимизации состоит в определении того, каким переменным в данной точке программы выгоднее всего выделить физические регистры. Наиболее распространенный метод, применяемый для этой цели, известен как раскраска графа. В общем случае метод формулируется следующим образом. Имеется граф, состояний из узлов и ребер. Необходимо раскрасить узлы так, чтобы соседние узлы имели разный цвет и чтобы при этом общее количество привлеченных цветов было минимальным. В нашем случае роль узлов выполняют виртуальные регистры. Если два виртуальных регистра одновременно присутствуют в одном и том же фрагменте программы, они соединяются ребром. Делается попытка раскрасить граф в n цветов, где п — число физических регистров. Если такая попытка не увенчалась успехом, то узлам, которые не удалось раскрасить, вместо физических регистров выделяются ячейки в памяти.
На рис. 9.37 приведен пример раскраски графа [36], и котором шесть виртуальных регистров отображаются на три физических. Доказаны временная последовательность активного вовлечения в выполнение каждого виртуального регистр (рис. 9.37, а) и раскрашенный граф (рис. 9.37,б).
Как видно, не удалось раскрасить только виртуальный регистр F, его придете отображать на ячейку памяти.
Аппаратная оптимизация использования регистров в RISC-процессорах орн ентирована па сокращение затрат времени при работе с процедурами. Наибольшее время в программах, написанных па ЯВУ, расходуется на вызовы процедуп и возврат из пик. Связано это с созданием и обработкой большого числа локальных переменных и констант. Одним из механизмов для борьбы с этим эффектом являются так называемые регистровые окна. Главная их задача — упростить и ус_ копить передачу параметров от вызывающей процедуры к вызываемой и обратно
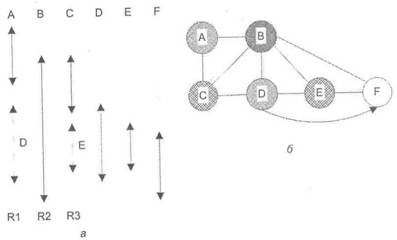
Рис. 9.37. Иллюстрация метода раскраски графа: а — временная последовательность
активного использования виртуальных регистров; б — граф взаимного использования регистров
Регистровый файл разбивается на группы регистров, называемые окнами. Отдельное окно назначается глобальным переменным. Глобальные регистры доступны всем процедурам, выполняемым в системе в любое время. С другой стороны, каждой процедуре выделяется отдельное окно в регистровом файле. Все окна имеют одинаковый размер (обычно по 32 регистра) и состоят из трех полей. Левое поле каждого регистрового окна одновременно является и правым полем предшествующего ему окна (рис. 9.38). Среднее поле служит для храпения локальных переменных и констант процедуры. |
База окна (первый в последовательности регистров окна) указывается полем, называемым указателем текущего окна (CWP, Current Window Pointer), обычно расположенным в регистре (слоне) состояния ЦП. Если текущей процедуре назначено регистровое окно j, CWP содержит значение j.
Каждой вновь вызванной процедуре выделяется регистровое окно, непосредственно следующее за окном вызвавшей ее процедуры. Последние k регистров окна j одновременно являются первыми k регистрами окна j + 1. Если процедура, занимающая окно j, обращается к процедуре, которой в данной архитектуре должно быть назначено окно j + 1, она может передать в процессе вызова k аргументов.
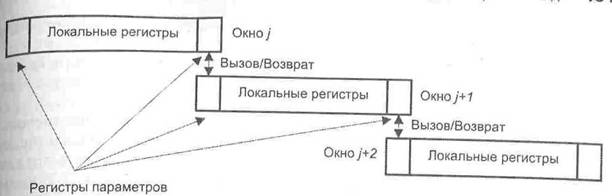
Рис. 9.38. Перекрытие регистровых окон
Упомянутые k регистров сразу же будут доступны вызванной процедуре без всяких пересылок. Естественно, вызов приведет к увеличению содержимого поля CPW на единицу.
Глубина вложения процедур одна в другую может быть весьма велика, и желательно, чтобы количество регистровых окон не было сдерживающим фактором. Это достигается за счет организации окон в виде циклического буфера.

Рис. 9.39. Циклический буфер из пересекающихся регистровых окон
На рис. 9.39 показан циклический буфер из шести окон, заполненный на глубину 4 (процедура А вызвала В, В вызвала С, С вызвала D). Указатель текущего окна (CWP) идентифицирует окно активной на данный момент процедуры — D, то есть окно 03. При выполнении процедуры все ссылки на регистры в командах преобразуются в смещение относительно CWP. Указатель сохраненного окна (SWP, Saved Window Pointer) содержит номер последнего из окон, сохраненных в памяти ь причине переполнения циклического буфера. Если процедура D теперь вызовет процедуру Е, аргументы для нее она поместит в общее для обеих полей регистров, окон (пересечение окон 03 и 04), а значение CWP увеличится на единицу, то есть CWP будет показывать на окно 04.
Если далее процедура Е вызовет процедуру F, то этот вызов при существующем состоянии буфера не может быть выполнен, поскольку окно для F (05) перекрывается с окном процедуры А(00). Следовательно, при попытке F начать загружа-п. правое поле своего окна будут потеряны параметры процедуры А (АрИ). Поэтому когда CWP увеличивается на единицу (операция выполняется по модулю 6) и оказывается равным SWP, возникает прерывание и окно процедуры А сохраняется, в памяти (запоминаются только поля Ан1 и А_лок). Далее значение CWP мнкремсн-тируется и производится вызов процедуры F. Аналогичное прерывание происходит и при возврате, например когда выполнится возврат из В в A. CWP уменьшается па единицу (по модулю 6) и совпадет со значением SWP. Обработка прерывания приведет к восстановлению содержимого окна процедуры А из памяти.
Как видно из примера, регистровый файл из п окон способен поддерживать п-1 вызов процедуры. Число п не должно быть большим. В [208] показано, что при 8 регистровых окнах сохранение и восстановление окон в памяти требуется лишь для 1% операций вызова процедур. В ВМ Pyramid, например, используется 16 окон по 32 регистра в каждом.
Теоретически такой прием не исключен и в CISC. Однако устройство управления CISC-процессора оккупирует на кристалле более 50% площади, оставляя мало места для других подсистем, в частности для большого файла регистров. УУ RISC занимает порядка 10% поверхности кристалла, предоставляя возможность иметь большой регистровый файл.
Другая часто встречаемая техника аппаратной оптимизации использования регистром — придание некоторым из них специального качества: такие регистру в состоянии принимать на себя имя любого РОН. Набор регистров, обладающий подобным свойством, называют буфером переименования. Прием оказывается очень удобным при конвейеризации команд и позволяет предотвратить конфликты, когда одна команда хочет воспользоваться регистром, в данный момент запятым другой командой.
Преимущества и недостатки RISC
Сравнивая достоинства и недостатки CISC и RISC, невозможно сделать однозначный вывод о неоспоримом преимуществе одной архитектуры над другой. Для отдельных сфер использования ВМ лучшей оказывается та или иная. Тем не менее, ниже приводится основная аргументация «за» и «против» RISC-архитектуры.
Для технологии RISC характерна сравнительно простая структура устройств управления. Площадь, выделяемая на кристалле микросхемы для реализации УУ, существенно меньше. Так, в RISC I она составляет 6%, а в RISC II - 10%. Как следствие, появляется возможность разместить на кристалле большое число регистров ЦП (138 в RISC II). Кроме того, остается больше места для других узлов ЦП и для дополнительных устройств: кэш-памяти, блока арифметики с плавающей запятой, части основной памяти, блока управления памятью, портов ввода/вывода.
Унификация набора команд, ориентация на потоковую конвейерную обработку, унификация размера команд и длительности их выполнения, устранение периодов ожидания в конвейере — все эти факторы положительно сказываются на общем быстродействии. Простое устройство управления имеет немного вентилей и, следовательно, короткие линии связи для прохождения сигналов управления. Малое число команд, форматов и режимов приводит к упрощению схемы декодирования, и оно происходит быстрее. Применяемое в RISC УУ с «жесткой» логиком быстрее микропрограммного. Высокой производительности способствует и упрощение передачи параметров между процедурами. Таким образом, применение RISC ведет к сокращению времени выполнения программы или увеличению скорости, за счет сокращения чист циклов на команду.
Простота УУ, сопровождаемая снижением стоимости и повышением надежности, также говорит и пользу RISC. Разработка УУ занимает меньше времени. Простое УУ будет содержать меньше конструктивных ошибок и поэтому более надежно.
Многие современные CISC-машины, такие как VAX 11/780, VAX-8600, имеют много средств для прямой поддержки функций ЯВУ, наиболее частых в этих языках (управление процедурами, операции с массивами, проверка индексов массивов защита информации, управление памятью и т. д.). RISC также обладает рядом средств для непосредственной поддержки ЯВУ и упрощения разработки компиляторов ЯВУ, благодаря чему эта архитектура в плане поддержки ЯВУ ни в чем не уступает CISC.
Недостатки RISC прямо связаны с некоторыми преимуществами этой архитектуры. Принципиальный недостаток — сокращенное число команд: на выполнение ряда функций приходится тратить несколько команд вместо одной в CISC. Это удлиняет код программы, увеличивает загрузку памяти и трафик команд между памятью и ЦП. Недавние исследования показали, что RISC-программа в среднем на 30% длиннее CISC-программы, реализующей те же функции.
Хотя большое число регистров дает существенные преимущества, само по себе оно усложняет схему декодирования номера регистра, тем самым увеличивается время доступа к регистрам.
УУ с «жесткой» логикой, реализованное в большинстве RISC-систем, менее гибко, более склонно к ошибкам, затрудняет поиск и исправление ошибок, уступает при выполнении сложных команд.
Однословная команда исключает прямую адресацию для полного 32-битового адреса. Поэтому ряд производителей допускают небольшую часть команд двойной длины, например в Intel 80960.
Суперскалярные процессоры
Поскольку возможности по совершенствованию элементной базы уже практически исчерпаны, дальнейшее повышение производительности ВМ лежит в плоскости архитектурных решении. Как уже отмечалось, одни из наиболее эффективных подходов в этом плане — введение в вычислительный процесс различных уровней параллелизма. Ранее рассмотренный конвейер команд — типичный пример такого подхода. Тем же целям служат и арифметические конвейеры, где конвейеризации подвергается процесс выполнения арифметических операций. Дополнительный уровень параллелизма реализуется в векторных и матричных процессорах, но только при обработке многокомпонентных операндов типа векторов и массивов. Здесь высокое быстродействие достигается за счет одновременной обработки всех компонентов вектора или массива, однако подобные операнды характерны лишь для достаточно узкого круга решаемых задач. Основной объем вычислительной нагрузки обычно приходится на скалярные вычисления, то есть на обработку одиночных операндов, таких, например, как целые числа. Для подобных вычислений дополнительный параллелизм реализуется значительно сложнее, но тем не менее возможен и примером могут служить суперскалярные процессоры.
Суперскалярным (этот термин впервые был использован в 1987 году [45]) называется центральный процессор (ЦП), который одновременно выполняет более чем одну скалярную команду. Это достигается за счет включения в состав ЦП нескольких самостоятельных функциональных (исполнительных) блоков, каждый из которых отвечает за свой класс операций и может присутствовать в процессоре в нескольких экземплярах. Так, в микропроцессоре Pentium III блоки целочисленной арифметики и операций с плавающей точкой дублированы, а в микропроцессорах Pentium 4 и Athlon — троированы. Структура типичного суперскалярного процессора [234] показана на рис. 9.40. Процессор включает в себя шесть блоков: выборки команд, декодирования команд, диспетчеризации команд, распределения команд пф функциональным блокам, блок исполнения и блок обновления состояния.

Рис. 9.40. Архитектура суперскалярного процессора
Блок выборки команд извлекает команды из основной памяти через кэш-память команд. Этот блок хранит несколько значений счетчика команд и обрабатывает команды условного перехода.
Блок декодирования расшифровывает код операции, содержащийся в извлеченных из кэш-памяти командах. В некоторых суперскалярных, процессорах, например в микропроцессорах фирмы Intel, блоки выборки и декодирования совмещены.
Блоки диспетчеризации и распределения взаимодействуют между собой и в совокупности играют в суперскалярном процессоре роль контроллера трафика. Оба блока хранят очереди декодированных команд. Очередь блока распределения часто рассредоточивается по несколько самостоятельным буферам — накопителям команд или схемам резервирования (reservation station),- предназначенным для хранения команд, которые уже декодированы, но еще не выполнены. Каждый накопитель команд связан со своим функциональным блоком (ФБ), поэтому число накопителей обычно равно числу ФБ, но если в процессоре используется несколько однотипных ФБ, то им придается общий накопитель. По отношению к блоку диспетчеризации накопители команд выступают в роли виртуальных функциональных устройств. Оба вида очередей показаны на рис. 9.41 [234]. В некоторых суперскалярных процессорах они объединены в единую очередь.
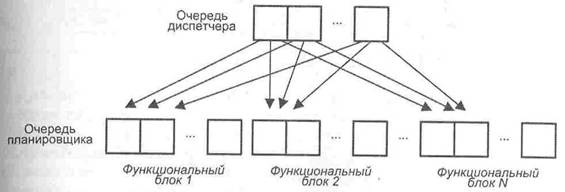
Рис. 9.41. Очереди диспетчеризации и распределения
В дополнение к очереди, блок диспетчеризации хранит также список свободных функциональных блоков, называемый табло (Scoreboard). Табло используется для отслеживания состояния очереди распределения. Один раз за цикл блок диспетчеризации извлекает команды из своей очереди, считывает из памяти или регистров операнды этих команд, после чего, в зависимости от состояния табло, помещает команды и значения операндов в очередь распределения. Эта операция называется выдачей команд. Блок распределения в каждом цикле проверяет каждую команду в своих очередях на наличие всех необходимых для ее выполнения операндов и при положительном ответе начинает выполнение таких команд в соответствующем функциональном блоке.
Блок исполнения состоит из набора функциональных блоков. Примерами ФБ могут служить целочисленные операционные блоки, блоки умножения и сложения с плавающей запятой, блок доступа к памяти. Когда исполнение команды завершается, ее результат записывается и анализируется блоком обновления состояния, который обеспечивает учет полученного результата теми командами в очередях распределения, где этот результат выступает в качестве одного из операндов.
Как было отмечено ранее, суперскалярность предполагает параллельную работу максимального числа исполнительных блоков, что возможно лишь при односменном выполнении нескольких скалярных команд. Последнее условие хорошо сочетается с конвейерной обработкой, при этом желательно, чтобы в суперскалярном процессоре было несколько конвейеров, например два или три.
Подобный подход реализован в микропроцессоре Intel Pentium, где имеются два конвейера, каждый со своим АЛУ (рис. 9.42). Отметим, что здесь, в отличие от стандартного конвейера, в каждом цикле необходимо производить выборку более чем одной команды. Соответственно, память ВМ должна допускать одповременное считывание нескольких команд и операндов, что чаще всего обеспечивается за счет ее модульного построения.
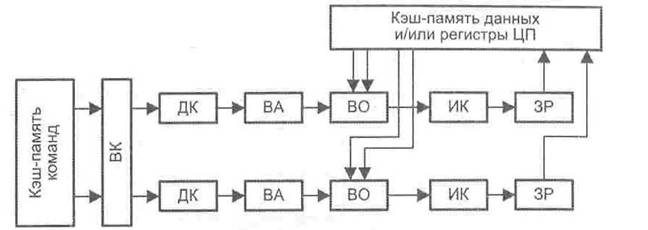
Рис. 9.42. Суперскалярный процессор с двумя конвейерами
Более интегрированный подход к построению суперскалярного конвейера показан на рис. 9.43. Здесь блок выборки (ВК) извлекает из памяти более одной команды и передает их через ступени декодирования команды и вычисления адресов операндов в блок выборки операндов (ВО). Когда операнды становятся доступными, команды распределяются по соответствующим исполнительным блокам. Обратим внимание, что операции «Чтение», «Запись» и «Переход» реализуются самостоятельными исполнительными блоками. Подобная форма суперскалярного процессора используется в микропроцессорах Pentium II и Pentium III фирмы Intel, а форма с тремя конвейерами — в микропроцессоре Athlon фирмы AMD.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
