

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral

Рис. 9.43. Суперскалярный конвейер со специализированными исполнительными блока
По разным оценкам, применение суперскалярного подхода приводит к повышению производительности ВМ в пределах от 1,8 до 8 раз.
Для сравнения эффективности суперскалярного и суперконвейерного режима рис. 9.44 показан процесс выполнения восьми последовательных скалярных команд. Верхняя диаграмма иллюстрирует суперскалярный конвейер, обеспечивающий каждом тактовом периоде одновременную обработку двух команд. Отметим, что возможны суперскалярные конвейеры, где одновременно обрабатывается большее количество команд.
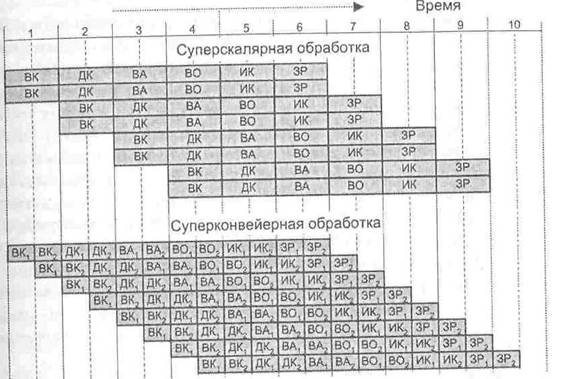
Рис. 9.44. Сравнение суперскалярного и суперконвейерного подходов

Рис. 9.45. Сравнение эффективности стандартной суперскалярной и совмещенной схем
суперскалярных вычислений
В процессорах некоторых ВМ реализованы как суперскалярность, так и суперконвейеризация (рис. 9.45). Такое совмещение имеет место в микропроцессора Athlon и Duron фирмы AMD, причем охватывает оно не только конвейер команд, но и блок обработки чисел в форме с плавающей запятой.
Особенности реализации суперскалярных процессоров
Поскольку в реальных суперскалярных процессорах множественность функциональных блоков сочетается с множественностью конвейеров команд, таким процессорам присущи все виды зависимостей, характерные для одинарных конвейеров, причем положение дел усугубляется тем, что конвейеров несколько. В суперскалярных процессорах одновременная работа нескольких конвейеров становится источником дополнительных неувязок, в частности проблемы последовательности поступления команд на исполнение и проблемы последовательности завершения команд.
Первая из упомянутых проблем возникает, когда очередность выдачи декодированных команд на исполнительные блоки отличается от последовательности предписанной программой. Подобная ситуация известна как неупорядоченная выдача команд (out-of-order issue). Термин упорядоченная выдача команд (in-order issue) применяют, когда команды покидают ступени, предшествующие ступени исполнения, в определенном программой порядке. В обоих случаях завершение команд обычно неупорядочено (неупорядоченное завершение команд — out-of-order completion), и это является второй проблемой. Упорядоченное завершение происходит реже. Например, в последовательности
MUL R1, R2, R3 {R1 <- R2xR3}
ADD R4, R5, R6 {R4<- R5 + R6},
даже если команда умножения MUL поступит в исполнительный блок до команды сложения ADD, умножение может потребовать много циклов, из-за чего команда MUL будет завершена позже, чем ADD. В современных микропроцессорах каждая команда разбивается на простейшие микрооперации, которые далее выполняются суперскалярным процессорным ядром в порядке, который удобен процессору.
В суперекалярных процессорах, с их множественными конвейерами и неупорядоченными выдачами/завершениями, взаимозависимость команд представляет серьезную проблему. Кроме того, существует еще один фактор, характерный только для суперскалярных процессоров, — конфликт по функциональному блоку, когда на него претендуют несколько команд, поступивших из разных конвейеров.
Пусть имеется последовательность
ADD R1,R2,R3 {R1<-R2 + R3}
SUB R4, R5, R6 {R4 <- R5 - R6}.
Зависимости между командами здесь нет, однако если в ЦП имеется только одно АЛУ, одновременное выполнение указанных операций невозможно.
Стратегии выдачи и завершения команд
В режиме параллельного выполнения нескольких команд процессор должен определить, в какой очередности ему следует:
■ выбирать команды из памяти;
■ выполнять эти команды;
■ позволять командам изменять содержимое регистров и ячеек памяти.
Для достижения максимальной загрузки всех ступеней своих конвейеров суперскалярный процессор должен варьировать все перечисленные виды последовательностей, но так, чтобы получаемый результат был идентичен результату при выполнении команд в порядке, определенном программой. Значит, процессор обязан учитывать все виды зависимостей и конфликтов.
В самом общем виде стратегии выдачи и завершения команд можно сгруппировать в такие категории:
■ упорядоченная выдача и упорядоченное завершение;
■ упорядоченная выдача и неупорядоченное завершение;
■ неупорядоченная выдача и неупорядоченное завершение.
Проанализируем каждый из этих вариантов на примере суперскалярного процессора с двумя конвейерами [200]. Процессор способен одновременно выбирать и декодировать две команды, причем передача обеих команд на декодирование должна также производиться одновременно. В состав процессора входят три отдельных функциональных блока (ФБ) и два устройства, обеспечивающие запись результата. В рассматриваемом примере предполагается существование следующих ограничений на выполнение программного кода из шести команд (I1-I6):
■ I1 требует для своего выполнения двух циклов процессора;
■ I13 и I14 имеют конфликт за обладание одним и тем же ФБ;
■ I15 зависит от значения, вычисляемого командой I4;
■ I5 и I6 конфликтуют за обладание одним и тем же ФБ.
Упорядоченная выдача и упорядоченное завершение. Наиболее простым в реализации вариантом является выдача декодированных команд на исполнение в том порядке, в котором они должны выполняться по программе (упорядоченная выдача), с сохранением той же последовательности записи результатов (упорядоченное завершение). Хотя такая стратегия и применялась в первых процессорах типа Pentium, сейчас она практически не встречается. Тем не менее, ее обычно берут в качестве точки отсчета при сравнении различных стратегий выдачи и завершения. Согласно данному принципу, все что затрудняет завершение команды в одном конвейере, останавливает и другой конвейер, так как команды должны покидать конвейеры, соответствуя порядку поступления па них. Пример использования подобных стратегии показан на рис. 9.46.
Здесь производятся одновременная выборка и декодирование двух команд, чтобы принять очередные команды, процессор должен ожидать, пока освободятся обе части ступени декодирования. Для упорядочивания завершения выдача команд приостанавливается, если возникает конфликт за общин функциональный блок или если функциональному блоку для формирования результата требуется более чем один такт процессора.
В рассматриваемом примере время задержки декодирования первой команды до записи последнего результата составляет 8 тактов.
Упорядоченная выдача и неупорядоченное завершение. Стратегии с неупорядоченным завершением дают возможность одному из конвейеров продолжать работать при «заторе» в
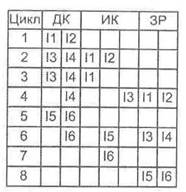
Рис. 9.46. Упорядоченная выдача и упорядоченное завершение
другом, при этом команды, стоящие в программе «позже» могут быть фактически выполнены раньше предыдущих, «застрявших» в другой конвейере. Естественно, процессор должен гарантировать, что результаты не будут записаны в память, а регистры не будут модифицироваться в неправильном последовательности, поскольку при этом могут получиться ошибочные результаты.
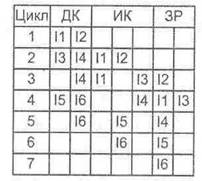
Рис. 9.47. Упорядоченная выдача и неупорядоченное завершение
Проиллюстрируем стратегию с упорядоченной выдачей и неупорядоченным
завершением (рис. 9.47). При заданных ей условиях допускается, что команда I2 может быть завершена еще до окончания исполнения команды I1. Это позволяет команде I3 завершиться на один такт раньше, вследствие чего результаты выполнения команд I1 и I3 записываются в одном и том же такте. При неупорядоченной выдаче в любой момент времени в стадии исполнения может находиться любое число команд, а степень параллелизма ограничена только числом функциональных блоков. По сравнению с предыдущей стратегией, возможность неупорядоченного завершения команд привела к сокращению времени выполнения шести команд на один цикл процессора.
Неупорядоченная выдача и неупорядоченное завершение. Неупорядоченная выдача развивает предыдущую концепцию, разрешая процессору нарушать предписанный программой порядок выдачи команд на исполнение, Чтобы обеспечить неупорядоченную выдачу команд, в конвейере необходимо максимально развязать ступени декодирования и исполнения. Это обеспечивается с помощью буферной памяти, называемой окнам команд. Каждая декодированная команда сначала помещается в окно команд. Процессор может продолжать выборку и декодирование новых команд вплоть до полного заполнения буфера. Выдача команд из буфера на исполнение определяется не последовательностью их поступления, а мерой готовности. Иными словами, любая команда, для которой уже известны значения всех операндов, при условии что функциональный блок, требуемый для ее исполнения, свободен, немедленно выдается из буфера на исполнение.
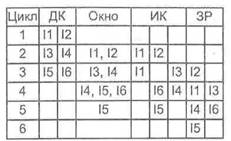
Рис. 9.48. Неупорядоченная выдача и неупорядоченное завершение
Стратегию иллюстрирует рис. 9.48. В каждом цикле процессора две команды из ступени декодирования пересылаются в окно команд (с учетом ограничения па размер буфера). Выдача команд из буфера производится по мере их готовности. Так, в рассматриваемом примере возможна выдача команды I6 до выдачи команды I5 (напомним, что I5 зависит от I4, а I6 — нет). Таким образом, сберегается один такт, как в ступени исполнения команды (ИК), так и в ступени записи результата (ЗР), и сквозная экономия по сравнению с рис. 9.47 составляет один цикл процессора. На рисунке изображено окно команд, но оно не является дополнительной ступенью конвейера.
Стратегии неупорядоченной выдачи и неупорядоченного завершения также свойственны ранее рассмотренные ограничения. Команда не может быть выдана, если она приводит к зависимости или конфликту. Разница заключается в том, что к выдаче готово больше команд, и это позволяет уменьшить вероятность приостановки конвейера.
Аппаратная поддержка суперскалярных операций
Из предыдущих рассуждении следует, что неупорядоченные выдача и завершение команд — это дополнительный потенциал повышения производительности суперскалярного процессора, для реализации которого, вместе с тем, необходимо решить. Две проблемы:
■ устранить зависимость команд по данным (речь идет о зависимостях типа ЧПЗ и. ЗПЗ), то есть исключить использование в качестве операнда «устаревшего» значения регистра и не допускать, чтобы очередная команда программы из-за нарушения последовательности выполнения команд занесла свои результат в регистр еще до того, как это сделала предшествующая команда;
■ сохранить такой порядок выполнения команд, чтобы общий итог вычислений остался идентичным результату, получаемому при строгом соблюдении программной последовательности.
Несмотря на то что обе задачи в принципе могут быть решены чисто программными средствами еще на этапе компиляции программы, в реальных суперскалярных процессорах для этих целей имеются соответствующие аппаратные средства. Каждая из перечисленных проблем решается своими методами и своими аппаратными средствами. Для устранения зависимости по данным используется прием известный как переименование регистров. Способ решения второй проблемы обобщенно называют переупорядочиванием команд или откладыванием исполнения команд.
Переименование регистров
Когда команды выдаются и завершаются упорядочение, каждый регистр в любой точке программы содержит именно то значение, которое диктуется программой. Применение стратегий с неупорядоченной выдачей и завершением команд ведет к тому, что запись в регистры может происходить также неупорядоченно и отдельные команды, обратившись к какому-то регистру, вместо нужного получат «устаревшее» или «опережающее» значение. Пусть имеется последовательность команд:
I1: MUL R2,R0, R1 {R2 <-R0x R1}
I2: ADD R0,R1,R2 {R0 <- R1 + R2}
I3: SUB R2,R0, R1 {R2 <- R0 – R1}
При неупорядоченных выдаче/завершении возможны ситуации, приводящие к неверному результату, например:
■ команда I2 была исполнена до того, как I1 успела записать в регистр R2 свой результат, то есть I2 использовала «старое» содержимое R2;
■ команда I3 исполнена раньше, чемI1, в результате чего неверный результат будет получен в I2, а по завершении цепочки из трех команд в R2 останется результат I1 вместо результата I3.
Ясно, что здесь нарушение порядка выполнения команд ведет к неправильному результату. Вводя новые регистры R0a и R2a, получим иную последовательность:
Il:MULR2,R0 R1{R2<-R0x R1}
I2: ADD R0, R1 R2{R0a <- R1 + R2}
I3: SUB R2a, R0, R1{R2a <- R0a – R1}
где возможность конфликта устранена. Такой метод известен как переименование регистров (register renaming).
Основная идея переименования регистров состоит в том, что каждый новый результат записывается в один из свободных в данный момент дополнительных регистров, при этом ссылки на заменяемый регистр во всех последующих командах соответственным образом корректируются. Программист, составляющий программу, имеет дело с именами логических регистров. Число физических регистров аппаратного регистрового файла (АРФ) обычно больше числа логических. «Лишние» регистры АРФ используются в процедуре переименования для временного хранения результатов до момента разрешения конфликтов по данным, после чего значение из регистра временного хранения переписывается на свое «штатное» место. В некоторых процессорах «лишние» регистры в АРФ отсутствуют, а для поддержки переименования предусмотрены специальные структуры, например рассматриваемый ниже буфер переименования.
На данном этапе будем считать, что дополнительные физические регистры входят в состав АРФ. Когда выполняется команда, предусматривающая запись результата в какой-то из логических регистров, например в Ri, для временного хранения выделяется один из свободных в данный момент физических регистров АРФ (Rj). Во всех последующих командах, где в качестве логического регистра операнда упоминается Rj, ссылка на него заменяется ссылкой на физический регистр R. Таким образом, различные команды, где указан один и тот же логический регистр, могут обращаться к различным физическим регистрам.
Номера логических регистров динамически отображаются на номера физических регистров посредством таблиц подстановки (lookup table), которые обновляются после декодирования каждой команды. Очередной результат записывается в новый физический регистр, но значение каждого логического регистра запоминается, благодаря чему легко восстанавливается в случае, если выполнение команды должно быть прервано из-за возникновения исключительной ситуации или неправильного предсказания направления условного перехода.
Переименование регистров может быть реализовано п по-другому — с помощью буфера переименования. Проиллюстрируем этот способ, вернувшись к ранее приведенной последовательности из трех команд. Схема содержит аппаратный регистровый файл (АРФ) на М регистров и буфер переименования (БП) на N входов (рис. 9.49). Будем считать, что число логических регистров также равно М, то есть в качестве временных регистров переименования используются только ячейки БП.

Рис. 9.49. Аппаратный регистровый файл и буфер переименования
Каждому регистру АРФ придан бит «Значение достоверно» (ЗД). Единичное значение ЗД свидетельствует о том, что в регистре содержится корректное значение, которое может быть взято в качестве операнда команды.
Буфер переименования представляет собой ассоциативное запоминающее устройство или набор регистров с ассоциативным доступом. Каждая ячейка пли регистр БП идентифицируется своим порядковым номером (0, 1, ...,N- 1). Информация, хранящаяся в ячейке или регистре БП (в каждом входе), представляется пятью полями:
■ Вход занят (ВЗ). Однобитовое поле, единичное значение которого говорит о том, что этот вход БП недоступен.
■ Номер переименованного регистра (Рг). В поле содержится номер логического регистра АРФ, для временной замены которого выделена данная ячейка БП.
■ Значение. В поле хранится текущее содержимое регистра, указанного в поле РГ.
■ Значение достоверно (ЗД), Однобитовое поде, единичное значение которог подтверждает достоверность содержимого поля «Значение» (если значение еще не вычислено, то ЗД = 0). ■ Последнее переименование (ПП). Если БП несколько ячеек через поле Рг ссылаются на один и тот же регистр, единица в однобитовом поле ПП будет только у той ячейки, где находится последняя ссылка на данный регистр.
Предположим, что в исходный момент (рис. 9.50, а) в буфере переименования заполнены три первых входа, то есть имеем единицы в их поле Б3. Текущее состояние БП свидетельствует о том, что в предшествующих командах для записи результатов использовались регистры R4, R0 и R1, и хотя результаты этих команд уже получены (в поле ЗД записана единица), вычисленные значения еще не переписаны в соответствующие регистры АРФ.
Поле ПП введено из-за того, что регистры могут переименовываться многократно на рис. 9.50, б показан случай последовательного переименования регистра R1. Единица в поле ПП входа 3 указывает, что последнему переименованию регистра R1 соответствует именно данный вход. У всех остальных входов, ссылающихся на «устаревшие» значения R1, в этом поле будет 0, Если очередной команде требуется значение из регистра R1, то из двух возможных чисел 10 и 15 будет взято 15, то есть значение того входа, где в поле ПП содержится единица.
Всякий раз, когда встречается команда, предполагающая запись результата в регистр, необходимо в буфере переименования выделить для этого регистра один из свободных входов (свободную ячейку) и правильно инициализировать его поля. Обычно буфер заполняется циклически, для чего имеются указатели первого и последнего свободного входов. Когда запрашивается очередной свободный вход, используется указатель «головы», и затем значение этого указателя соответствующим образом изменяется. Когда какой-то из входов освобождается, то корректируется значение указателя «хвоста». После выделения входа для регистра результата производится инициализация его полей: устанавливаются в единицу поля ВД и ПП, в поле Рг заносится номер регистра, а в поле ЗД помещается 0, означающий, что поле «Значение» еще не содержит достоверного значения. Рисунок 9.50, в иллюстрирует состояние буфера переименования после выделения входа для регистра R2 в команде MUL.
Теперь рассмотрим, каким образом из буфера извлекаются значения операндов (поиск операндов в БП производится, если они отсутствуют в АРФ). В нашем примере это соответствует выборке операндов для команды MUL (значений регистров R0 и R1). Так как рассматриваемый буфер ассоциативный, то для получения значений операндов нужно произвести ассоциативный поиск последних значений регистров R0 и R1, то есть тех входов, где в поле Рг указаны искомые регистры, а в ноле ПП содержится 1 (рис. 9.50, г).
Если передаваемой далее команде требуется значение регистра, которое еще не вычислено (недостоверно), вместо значения выдается идентификатор (номер) соответствующего входа буфера и ставится пометка, что это не значение, а номер входа. Рисунок 9.50, Э показывает такую ситуацию для команды ADD. Первое, что делается при переименовании этой команды, — выделение свободного входа для регистра R3, конкретно — входа 4. Далее должны быть извлечены значения регистров R1 и R2. Поскольку последнее переименование регистра Rl достоверно, выборКа содержащегося в регистре значения может быть произведена так, как это быд0 описано выше. Однако значение R2 еще не вычислено, поэтому вместо него в исполнительную часть процессора, где будет выполняться команда ADD, пересылается номер соответствующего входа буфера переименования (в нашем примере это 3).
Теперь в буфере переименования имеется несколько входов, ссылающихся на один и тот же регистр. Так, на рис. 9.50, е показана ситуация, когда команда SUB выдана до завершения команды MUL. В этом случае под регистр R2 выделен еще один вход (вход 5), в котором установлены соответствующие значения в полях ЗД и ПП. Одновременно содержимое поля ПП входа 3, где хранилось предыдущее описание регистра R2, изменено на 0. Таким образом, с данного момента все последующие команды, ссылающиеся на регистр R2 как источник операнда, будут переадресовываться на вход 5. Это будет продолжаться до появления повои команды, с регистром результата R2.
По завершении команды регистр результата должен быть модифицирован так, чтобы последующие команды могли получить доступ к вычисленному результату. Модификация базируется на идентификаторе входа буфера переименования, выделенного для запрошенного регистра результата. В нашем примере предположим, что завершилась команда MUL и результат 0 должен быть занесен во вход 3 (рисунок 9.50, ж). В поле ЗП этого входа помещается единица, показывающая, что значение регистра R2 уже доступно.
Последний момент — это освобождение входа буфера переименования (рисунок 9.50, з). Критерий освобождения входа будет рассмотрен позже.

Рис. 9.50. Иллюстрация процессов в буфере переименования
Переупорядочивание команд
После декодирования команд и переименования регистров команды передаются на исполнение. Как уже отмечалось, выдача команд в функциональные блоки может производиться неупорядоченно, по мере готовности. Поскольку порядок выполнения команд может отличаться от предписанного программой, необходимо обеспечить корректность их операндов (частично решается путем переименования регистров) и правильную последовательность занесения результатов в регистры АРФ. Одним из наиболее распространенных приемов решения этих проблем служит переупорядочивание команд. В его основе лежат использование окна команд — буферной памяти, куда помещаются все команды, прошедшие декодирование, и переименование регистров (последняя операция выполняется только с теми командами, которые записывают свои результат в регистры). Окно команд обеспечивает отсрочку передачи команд на исполнение до момента готовности операндов, а также нужную очередность завершения команд и загрузки их результатов в регистры АРФ. Эта техника известна также под названием шелвинг (shelving). Ниже рассматриваются дна варианта окна команд — централизованное и распределенное.
Централизованное окно команд. Данное окно реализуется в виде так называемого табло (score-board). Техника табло впервые была предложена в 1964 году фирмой Cray и реализована в ЭВМ CDC 6600.
Табло (иногда слово Scoreboard переводят как табельная доска) представляет собой буферное запоминающее устройство, в котором хранится некоторое количество последних извлеченных из памяти и декодированных команд, а также текущая информация о доступности ресурсов, привлекаемых для их исполнения. Функциями табло являются оперативное выявление команд, для исполнения которых уже доступны все необходимые операнды и ресурсы, и выдача таких команд на исполнение в соответствующие функциональные блоки. Табло можно рассматривать как систему предварительной диспетчеризации команд, однако оно осуществляет контроль выполнения команд и после их выдачи.
Все извлеченные из памяти команды сразу же после их декодирования и, если это необходимо, переименования регистров заносятся в табло, причем с соблюдением порядка их следования в программе. Физически табло реализуется на основе ассоциативной памяти. Каждой команде выделяется одна ячейка, состоящая из нескольких полей:
■ поля операции, где хранится дешифрированный код операции;
■ двух полей операндов, размещающих значения операндов, если они известны, либо информацию о том, откуда эти операнды должны быть получены;
■ поля результата, указывающего регистру, куда должен быть помещен результат выполнения данной команды;
■ поля битов достоверности.
■ В табло также хранится текущая информация о доступности устройств обработки (функциональных блоков).
Функционирование табло тесно увязано с работой буфера переименования и может быть описано следующим образом. Каждая команда после декодирования и переименования регистров заносится в очередную свободную ячейку табло. Декодированный код операции помещается в поле операции. Если команда предполагает загрузку результата в регистр, то на этот регистр имеется ссылка в БП и в поле результата заносится номер входа БП, в котором хранится последняя ссылка па данный регистр. Далее делается попытка заполнить поля операндов значениями операндов. Сначала производится поиск нужного значения в аппаратном регистровом файле. Если бит ЗД регистра операнда в АРФ установлен в 0 (значение недостоверно), это означает, что операндом является результат предыдущей операции и дальше следует искать в БП. Выполняется ассоциативный поиск ссылки на регистр в буфере переименования. При удачном исходе (в найденной ячейке БП биты ЗД и ПП установлены в единицу) требуемое значение операнда берется из буфера переименования. В любом варианте при обнаружении достоверного значения операнда поле операнда ячейки табло заполняется найденным значением, а соответствующий этому полю бит достоверности (ЗД) устанавливается в единицу. Если же значение операнда еще не вычислено, то в поле операнда ячейки табло заносится идентификатор входа буфера переименования, где находится последняя ссылка на искомый регистр, при этом бит достоверности такого поля сбрасывается в 0.
Обновление информации о готовности операндов и доступности функциональных устройств выполняется в каждом цикле процессора.
Команда может быть считана из табло и выдана на исполнение лишь после того как будут занесены значения всех операндов, и лишь при условии, что нужный для исполнения этой команды ФБ свободен. После завершения команды в ФП производится запись полученного результата (если эта команда предполагает данное действие) в ту ячейку буфера переименования, на которую указывает поле результата. Одновременно производится ассоциативный доступ ко всем хранящимся в табло командам и в тех из них, где в полях операндов указан идентификатор обновленного входа БП, этот идентификатор заменяется занесенным в регистр новым значением, с соответствующей коррекцией битов достоверности. Далее завершенная команда покидает табло. Удаление команды из табло является основанием для перезаписи значения результата данной команды в регистр АРФ и удаления соответствующей записи из буфера переименования.
Отметим, что рассматриваемая технология предполагает схему распределения готовых команд по требуемым для их исполнения функциональным блокам, с одновременной проверкой их доступности. Эта функция названа диспетчеризацией.
В примере, приведенном на рис. 9.51, для команд П, 12,13 и 15 известны значения одного из операндов, и они вынуждены ожидать значения второго операнда. Команде 14 известны оба операнда, и при условии доступности ФБ, требуемого для ее исполнения, она вправе быть выдана из окна команд.
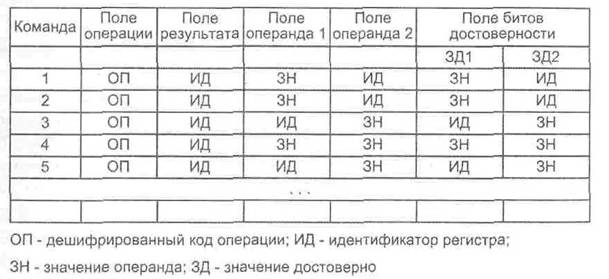
Рис. 9.51. Содержимое табло
В каждом такте работы процессора готовыми к выдаче могут оказаться сразу несколько команд, и все готовые команды должны быть направлены в соответствующие функциональные блоки. Если имеется несколько однотипных блоков обработки, то в процессоре должна быть предусмотрена логика выбора одного из них.
После выдачи команды из табло ее позиция освобождается и может быть использована для загрузки повой команды. Вместе с тем необходимо сохранить заданную программой последовательность команд. Эту задачу решают одним из двух методов. В первом из них, именуемом как стек диспетчеризации, после выдачи команд и освобождения позиций в окне последующие команды сдвигаются вниз, заполняя вновь доступные позиции и освобождая верхнюю часть табло. Новые команды всегда загружаются в верхнюю часть табло. В случае второго метода, с так называемым блоком обновления регистров, табло функционирует так же, как очередь типа FIFO, но производится общий сдвиг вниз, включая и освободившиеся позиции. Это упрощает логику работы централизованного окна.
Распределенное окно команд. В варианте распределенного окна команд на входе каждого функционального блока размещается буфер декодированных команд, называемый накопителем команд или схемой резервирования (reservation station). Метод резервирования был разработан в 1967 году и впервые воплощен в вычислительной системе IBM 360/91. После выборки и декодирования команды распределяются по схемам резервирования тех ФБ, где команда будет исполняться. В буфере команда запоминается и по готовности выдается в связанный с данным пунктом функциональный блок. Логика работы каждого накопителя аналогична централизованному окну команд. Выдача происходит только после того, как команда получит все необходимые операнды, и при условии, что ФБ свободен. При обновлении содержимого буфера переименования файла производится доступ ко всем накопителям команд, и в них идентификаторы обновленных входов заменяются хранящимися в этих входах значениями операндов.
Отметим одну особенность рассматриваемой схемы: не требуется, чтобы операнд был обязательно занесен в отведенный для него регистр — он может быть ускоренно передан прямо в накопитель команд для немедленного использования или буферизирован там для последующего использования.
Число независимых команд, которые могут выполняться одновременно, варьируется от программы к программе, а также в пределах каждой программы. В среднем число таких команд равно 1 -3, временами возрастая до 5-6. Механизм резервирования ориентирован на одновременную выдачу нескольких команд, что, как правило, легче реализовать с распределенным, а не централизованным окном команд, поскольку темп загрузки распределенных буферов обычно меньше, чем потенциальный темп выдачи команд. Пропускная способность линии связи между централизованным окном команд и функциональными блоками должна быть выше, чем в случае распределенного окна. Однако для централизованного окна характерно более эффективное задействование емкости буфера.
Емкость накопителя команд в каждом функциональном блоке зависит от ожидаемого числа команд для этого блока. Типичный накопитель рассчитан на 1 -3 команды. Если в одной из них одновременно готовы несколько команд, выдача их в ФБ производится в порядке занесения этих команд в накопитель.
Для более детального пояснения процессов, происходящих в технологии накопителей, рассмотрим следующий пример. На рис 9.52 показана схема передачи декодированных команд с переименованными регистрами в накопитель команд. Предполагается, что в рамках одного цикла в накопитель могут быть выданы до двух команд. Буфер переименования представлен регистровым файлом (РгФ). Из РгФ позволено одповрсмен но выбрать по два операнда (RS1, RS2) для каждой из двух команд. Каждый регистр РгФ имеет дополнительный бит достоверности (V), единичное состояние которого свидетельствует о корректности содержимого регистра. Доступные операнды (OSl, OS2) переписываются в соответствующие поля ячеек накопителя (OS1/IS1, Оs2/Is2), при этом биты достоверности этих полей (VS1, VS2) устанавливаются в единицу. Если значение операнда в РгФ недоступно, то в поля (OS1/IS1, Os2/Is2) заносится порядковый номер того регистра, откуда операнд должен быть получен (обозначаются как IS1 и IS2), а в соответствующий бит (VS1 или VS2), записывается 0. Если выдаваемая в регистр команда предполагает запись результата в регистр Ro, то бит достоверности этого регистра в РгФ сбрасывается, тем самым запрещается последующим командам использовать содержимое данного регистра.
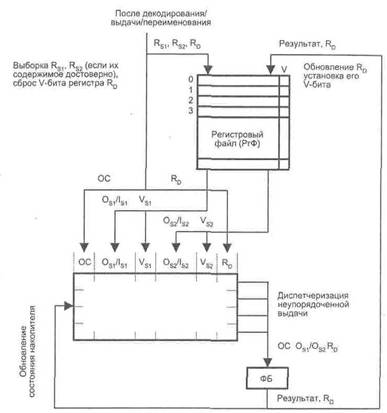
Рис. 9.52. Общая схема шелвинга к примеру
После передачи команд в накопитель там производится проверка на наличие команд, для исполнения которых есть все необходимые операнды. Поиск таких команд выполняется путем анализа битов VSl и VS2. Если у команды оба бита в единичном состоянии, то она готова к выдаче в ФБ. При наличии в накопителе только одной команды она сразу выдается в ФБ. Если готовых команд несколько, из них в ФБ пересылается наиболее «старая», то есть поступившая в накопитель первой. После завершения команды ее результат совместно с идентификатором регистра результата (RD) выдается в РгФ и в накопитель для обновления их содержимого. В ходе обновления РгФ вычисленное значение заносится в RD, а бит достоверности регистра результата устанавливается в единицу. С этого момента значение RD доступно в качестве операнда для последующих команд. В накопителе производятся поиск идентификатора RD в полях (OS1/IS1, ОS2/IS2) всех команд и их замена на вычисленное значение. Одновременно состояние бита VS1 (VS2) изменяется на еденицу. Далее выполняются очередной поиск готовых к исполнению команд и nN выдача в ФБ.
Теперь рассмотрим технику переупорядочивания команд с использованием накопителей на примере следующей последовательности команд:
MUL R3, R1, R2 {R3 <- R1xR2}
ADD R5, R2, R3 {R5 <- R2+R3}
ADD R6, R3, R4 {R6 <- R3 + R4}.
После декодирования и переименования регистров команда MUL в цикле i выдается в накопитель (рис. 9.53, а). Одновременно с этим из РгФ выбираются операнды этой команды (R1 и R2). Поскольку биты достоверности регистров операндов (V-биты) показывают, что значения операндов доступны (R1 = 10, R2 = 20), то эти значения будут переданы в накопитель, а биты наличия операндов в накопителе (VS1 и VS2) будут установлены в единицу. Бит достоверности регистра назначения R3 в РгФ сбрасывается с тем, чтобы не допустить доступ к этому регистру последующих команд до тех пор, пока в него не будет помещен результат операции MUL.
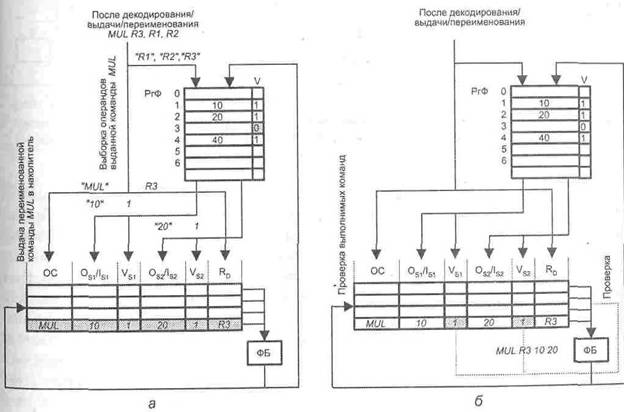
Рис. 9.53. К примеру техники переупорядочивания команд с использованием накопителей:
а — выдача команды MUL в накопитель в цикле i и выборка соответствующих операндов;
б — поиск выполнимых команд и диспетчеризация команды MUL в цикле i + 1
В следующем (i + 1)-м цикле происходит передача команды из накопителя (этот этап принято называть диспетчеризацией) в функциональный блок (ФБ) и выдача в накопитель двух очередных команд ADD. Сначала делается проверка битов наличия операндов (VSl и VS2) у всех находящихся в накопителе команд (в нашем примере здесь только одна команда MUL). Поскольку оба операнда доступны (VS1 = 1 и VS2 = 1), команда MUL пересылается в ФБ на исполнение. Это иллюстрирует рис. 9.5.3, б.

Рис. 9.54. К примеру техники переупорядочивания команд с использованием накопителей;
а — выдача двух последующих команд ADD в накопитель в цикле i + 1; 6 — проверка
на наличие исполнимых команд в цикле i + 2
В том же (i + 1)-м цикле в накопитель передаются две последующие команды ADD (pис. 9.54, а), при этом имеют место два действия. Во-первых, в РгФ сбрасываются биты достоверности выходных регистров этих команд (R5 и R6). Во-вторых, делается попытка выбрать из РгФ значения операндов команд ADD. В пашем случае биты достоверности в РгФ показывают, что доступны значения регистров R2 и R4, поэтому в накопитель будут отправлены значения данных регистров, а соответствующие им биты VS1 и VS2 будут установлены в единицу. В то же время значение R3 пока недоступно, так как бит достоверности этого регистра содержит 0. Как следствие, вместо значения регистра R3 в накопитель будет передан порядковый номер этого регистра в регистровом файле, а биты VSl и VS2, относящиеся к регистру R3, будут сброшены в 0.
В цикле i + 2 в накопителе снова происходит поиск готовых к исполнению команд с целью их диспетчеризации в ФБ. Поскольку значение R3 еще не вычислено, новые команды в ФБ не выдаются (рис. 9.54, 6).
В цикле i + 3 выполнение команды MUL завершается. На выходе ФБ появляется результат операции (200), а из накопителя поступает идентификатор регистра, куда этот результат должен быть занесен (рис 9.55 а). Теперь настало время обновления состояния регистрового файла и накопителя. В регистр R3 регистрового файла заносится значение 200, а бит достоверности этого регистра устанавливается в 1. С данного момента содержимое R3 может использоваться последующими командами. В накопителе производится ассоциативный и поиск ссылок на регистр R3 во всех полях операндов (OSI/IS1, OS2/IS2) и замена ссылок назначение операнда(200). Одновременно соответствующие биты наличия (VS1, VS2) устанавливаются в единицу. Далее в том же цикле выполняется поиск в накопителе готовых к исполнению команд (рис, 9.55, б). К его началу к диспетчеризации готовы обе команды ADD, то есть более одной команды, и выбор обуславливается правилом арбитража, согласно которому на исполнение в ФБ выдается наиболее «старая» из команд — та, которая поступила в накопитель раньше.
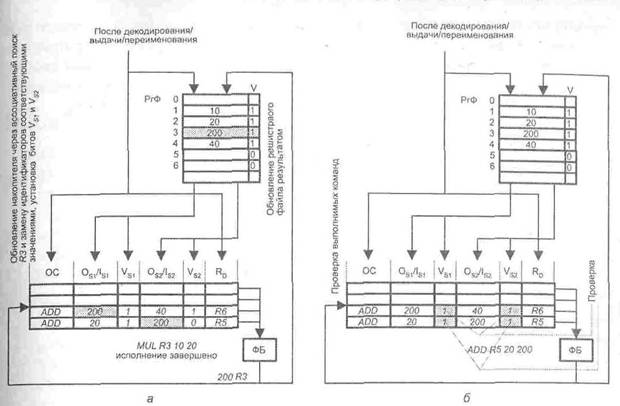
Рис. 9.55. К примеру техники переупорядочивания команд с использованием накопителей:
а — обновление состояния регистрового файла и накопителя результатом команды MUL
в цикле i + 2; б — проверка на наличие исполнимых команд в цикле i + 3 и диспетчеризация
более «старой» из команд ADD
Буфер восстановления последовательности. Стратегия буфера восстановления последовательности (БВП) впервые была описана Смитом и Плескуном (Smith and Pleszkun) в 1988 году. Хотя первоначально она предназначалась для решения проблемы прерывании, в наши дни — это универсальный инструмент для поддержания правильной последовательности исполнения команд в случае нескольких параллельно работающих функциональных блоков.
БВП представляет собой кольцевой буфер (рис. 9.56) с указателями головной и хвостовой части. Указатель головной части содержит адрес, следующего свободного входа. Команды заносятся в БВП в порядке, определяемом программой. Каждая выданная команда помещается в следующую свободную ячейку буфера (говорят, что команде выделен очередной свободным вход БВП.), причем выделение ячеек идет с соблюдением последовательности выдачи команд. Каждый занятый вход содержит также информацию о состоянии хранимой в нем команды: команда только выдана (i), находится в стадии исполнения (х) или уже завершена (f). Указатель хвостовой части показывает па команду, подлежащую удалению из БВП прежде других. Удаление команды разрешено, только если она завершена и предшествующие ей команды уже удалены из буфера. Этот механизм гарантирует что команды покидают БВП строго по порядку. Очередность выполнения команд программы сохраняется благодаря тому, что заносить свои результаты в память или регистры разрешается лишь тем командам, которые покинули БВП.
Число входов в БВП в разных процессорах составляет от 5 (PowerPC 603) до 64(SPAKC64).
Название буфера подчеркивает его основную задачу — поддержание строгой последовательности завершения команд путем переупорядочивания тех из них, которые исполнялись с нарушением этой последовательности. Однако БВП более универсален - с равным успехом он годится и для переименования регистров, и для распределения декодированных команд по накопителям (схемам резервирования). Так, по своему основному назначению БВП применен в микропроцессорах PowerPC 603, PowerPC 604, R10000. В микропроцессорах Am29000, AMD K5, Pentium Pro буфер используется также для переименования регистров. Наконец, в системе Lighining БВП реализует все три из вышеперечисленных функций.
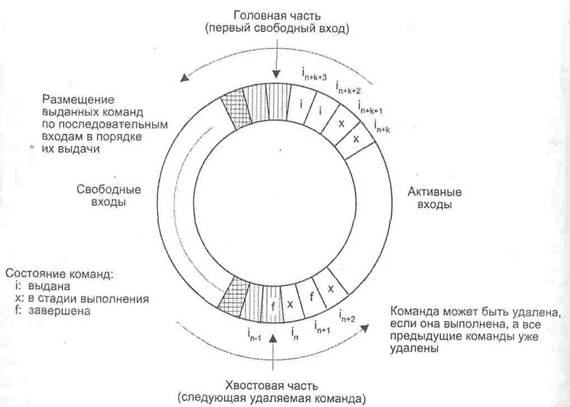
Рис. 9.56. Принципы организации буфера восстановления последовательности
Контрольные вопросы
1. В чем суть идеи конвейеризации? В каких случаях в конвейер следует вводить буферные регистры? В каких случаях буферные регистры нужно заменять буферной памятью? Ответы обоснуйте.
2. Определите синхронный конвейер из 8 функциональных блоков, из которых половина блоков работает в полтора раза медленнее других. Задайте конкретные временные параметры элементов конвейера. Рассчитайте значения трех метрик эффективности конвейера.
3. Пусть алгоритм вычисления программного разворота летательного аппарата (ЛА) имеет вид: tetai = (a × vi + b) × vi+ с, vi = vi-1+ ∆vi„ где tetai — программное значение угла тангажа; vi - текущее значение скорости ЛА; vi-1 — предыдущее значение скорости ЛА; ∆vi - текущее приращение скорости ЛА; а, Ь, с — константы. Запрограммируйте этот алгоритм с помощью системы команд семейства Pentium. Составьте диаграмму выполнения своей программы на конвейере с шестью ступенями. Определите случаи структурного риска и объясните возможные пути их разрешения. Зафиксируйте случаи риска по данным и поясните, как они распознаются. Предложите пути их устранения.
4. Модифицируем предыдущий алгоритм следующим образом; tetai = (a × vi + b) × vi+ с, если ∆vi > d, тогда vi = vi-1+ ∆vi,иначе vi = vi-1. Для соответствующей программы опишите случай нарушения ритмичности работы конвейера с шестью ступенями. Охарактеризуйте возможные способы уменьшения задержки конвейера и выберите один из них. Выбор обоснуйте.
5. В чем суть статического предсказания переходов? Сформулируйте достоинства и недостатки известных способов статического предсказания переходов.
6. В чем заключается смысл динамического предсказания переходов? Дайте развернутую характеристику достоинств к недостатков известных способов динамического предсказания переходов. Из каких соображений следует выбирать конкретную схему динамического предсказания? От чего зависит выбор?
7. Поясните идею суперконвейера. В чем заключаются достоинства и недостатки суперконвейеризации?
8. Поясните достоинства и недостатки ВМ с полным набором команд. Какие исторические причины привели к их возникновению?
9. Какие исторические причины способствовали появлению ВМ с сокращенным набором команд?
10. Перечислите основные характеристики ВМ с сокращенным набором команд. Опишите возможности совместного использования в одной ВМ CISC-архитектуры и RISC-архитектуры.
12. Для чего вводится механизм регистровых окон? Поясните структуру окна. Ради какой цели окна организуются в виде. циклического буфера?
13. Обоснуйте основные недостатки ВМ с сокращенным набором команд.
14. Дайте развернутую характеристику назначения и структурной организации суперскалярного процессора. Какие уровни параллелизма здесь используются?
15. На конкретных примерах поясните суть проблемы неупорядоченности команд в суперскалярных процессорах.
16. Разработайте структуру конкретного суперскалярного процессора. Задайте несколько программных фрагментов и составьте диаграммы их выполнения для трех методик выдачи и завершения команд.
17. На примере конкретного программного фрагмента поясните суть метода переименования регистров. В чем состоят недостатки этого метода? Как их смягчить?
18. На примере конкретного программного фрагмента поясните смысл метода переупорядочивания команд. В чем заключается разница между централизованным и распределенным окном команд? Проведите сравнительный анализ организации этих окон.
19. Опишите назначение, организацию и порядок работы буфера восстановления последовательности. Для решения каких задач он применяется в современных процессорах?

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
