

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Глава 9
Основные направления в архитектуре процессоров
Ранее уже были рассмотрены основные составляющие центрального процессора. В данном разделе основное внимание уделено вопросам общей архитектуры процессоров как единого устройства и способам повышения их производительности.
Конвейеризация вычислений
Совершенствование элементной базы уже не приводит к кардинальному росту производительности ВМ. Более перспективными в этом плане представляются архитектурные приемы, среди которых один из наиболее значимых — конвейеризация.
Для пояснения идеи конвейера сначала обратимся к рис. 9.1, а, где показан отдельный функциональный блок (ФБ). Исходные данные помещаются во входной регистр Ргвх, обрабатываются в функциональном блоке, а результат обработки фиксируется в выходном регистре Ргвых. Если максимальное время обработки в ФБ равно Тmax то новые данные могут быть занесены во входной регистр Pвх не ранее, чем спустя Тmax.
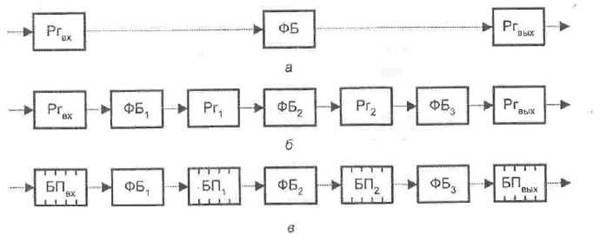
Рис. 9.1. Обработка информации: а — в одиночном блоке; б — в конвейере с регистрами; в — в конвейере с буферной памятью.
Теперь распределим функции, выполняемые в функциональном блоке ФБ (см рис. 9.1, а), между тремя последовательными независимыми блоками: ФБ1, ФБ2 и ФБ3, причем так, чтобы максимальное время обработки в каждом ФБi, было одинаковым и равнялось Тmax /3. Между блоками разместим буферные регистры Рг (рис. 9.1, б), предназначенные для хранения результата обработки в ФБi, на случай, если следующий за ним функциональный блок еще не готов использовать этот результат. В рассмотренной схеме данные на вход конвейера могут подаваться с интервалом Тmax /3 (втрое чаще), и хотя задержка от момента поступления первой единицы данных в Ргвх до момента появления результата ее обработки па выходе Ргвых по-прежнему составляет Тmax, последующие результаты появляются на выходе Ргвых уже с интервалом Тmax /3.
На практике редко удается добиться того, чтобы задержки в каждом ФБi были одинаковыми. Как следствие, производительность конвейера снижается, поскольку период поступления входных данных определяется максимальным временем их обработки в каждом функциональном блоке. Для устранения этого недостатка или, по крайней мере, частичной его компенсации каждый буферный регистр Ргi, следует заменить буферной памятью БПi, способной хранить множество данных и организованной по принципу FIFO — «первым вошел — первым вышел» (рис. 9.1, в). Обработав элемент данных, ФБi, заносит результат в БПi, извлекает из БПi-1 новый элемент данных и приступает к очередному циклу обработки, причем эта последовательность осуществляется каждым функциональным блоком независимо от других блоков. Обработка в каждом блоке может продолжаться до тех пор, пока не ликвидируется предыдущая очередь или пока не переполнится следующая очередь. Если емкость буферной памяти достаточно велика, различия во времени обработки не сказываются на производительности, тем не менее желательно, чтобы средняя длительность обработки во всех ФБ, была одинаковой.
В архитектуре вычислительных машин можно найти множество объектов, где конвейеризация обеспечивает ощутимый прирост производительности ВМ. Ранее уже рассматривались два таких объекта — операционные устройства и память, однако наиболее ощутимый эффект достигается при конвейеризации этапов машинного цикла.
По способу синхронизации работы ступеней конвейеры могут быть синхронными и асинхронными. Для традиционных ВМ характерны синхронные конвейеры. Связано это, прежде всего, с синхронным характером работы процессоров. Ступени конвейеров в процессоре обычно располагаются близко друг от друга, благодаря чему тракты распространения сигналов синхронизации получаются достаточно короткими и фактор «перекоса» сигналов становится не столь существенным. Асинхронные конвейеры оказываются полезными, если связь между ступенями не столь сильна, а длина сигнальных трактов между разными ступенями сильно рознится. Примером асинхронных конвейеров могут служить систолические массивы (систолическая обработка будет рассмотрена в последующих разделах).
Синхронные линейные конвейеры
Эффективность синхронного конвейера во многом зависит от правильного выбора длительности тактового периода Тк. Минимально допустимую Тк можно определить как сумму наибольшего из времен обработки на отдельной ступени конвейера ТСМАХ и времени записи результатов обработки в буферные регистры между ступенями конвейера ТБР:
![]()
Из-за вероятного «перекоса» в поступлении тактирующего сигнала в разные ступени конвейера предыдущую формулу следует дополнить еще одним элементом — максимальной величиной «перекоса» ТПК:
![]()
Каждая ступень может содержать множество логических трактов обработки. Тк определяется наиболее длинными трактами во всех ступенях конвейера. При разработке конвейера необходимо учитывать, что для двух последовательных элементов, обрабатываемых одной и той же ступенью, обработка первого элемента может проходить по тракту максимальной длины, а второго элемента - по минимальному тракту. В итоге результат обработки второго элемента может появиться на выходе ступени прежде, чем в выходном регистре ступени будет запомнен предыдущий результат. Чтобы избежать подобной ситуации, сумма ТБР + ТПК должна быть меньше минимального времени обработки в ступени ТСМIN, откуда
![]()
Выбор длительности тактового периода для конвейера должен осуществляться с соблюдением соотношения
![]()
Несмотря на очевидные преимущества выбора Тк равным нижнему пределу, проектировщики ВМ обычно ориентируются на среднее значение между нижним и верхним пределами.
Метрики эффективности конвейеров
Чтобы охарактеризовать эффект, достигаемый за счет конвейеризации вычислений, обычно используют три метрики: ускорение, эффективность и производительность.
Под ускорением понимается отношение времени обработки без конвейера и при его наличии. Теоретически наилучшее время обработки входного потока из N значений ТNK на конвейере с К ступенями и тактовым периодом ТК можно определить выражением
![]()
Формула отражает тот факт, что до появления на выходе конвейера результата обработки первого элемента должно пройти К тактов, а последующие результаты будут следовать в каждом такте.
В процессоре без конвейера общее время выполнения составляет NKTK. Таким образом, ускорение вычислений S за счет конвейеризации вычислений можно описать формулой
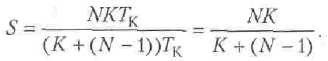
При N-->∞ ускорение стремится к величине, равной количеству ступеней в конвейере.
Еще одной метрикой, характеризующей конвейерный процессор, является эффективность Е — доля ускорения, приходящаяся на одну ступень конвейера:
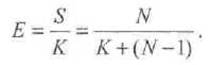
В качестве третьей метрики часто выступает пропускная способность или производительность Р — эффективность, деленная на длительность тактового периода:
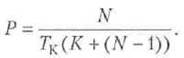
При N-->∞ эффективность стремится к единице, а производительность — к частоте тактирования конвейера:
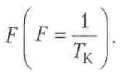
Нелинейные конвейеры
Конвейер не всегда представляет собой линейную цепочку этапов. В ряде ситуаций оказывается выгодным, когда функциональные блоки соединены между собой не последовательно, а в соответствии с логикой обработки, при этом один блоки в цепочке могут пропускаться, а другие — образовывать циклические структуры. Это позволяет с помощью одного и того же конвейера одновременно вычислять более одной функции, однако если эти функции конфликтуют между собой, то такой конвейер трудно загрузить полностью. Структура нелинейного конвейера, одновременно вычисляющего две функции X и Y, приведена на рис. 9.2. Там же показана последовательность, в которой функциями X и Y востребуются те или иные функциональные блоки.
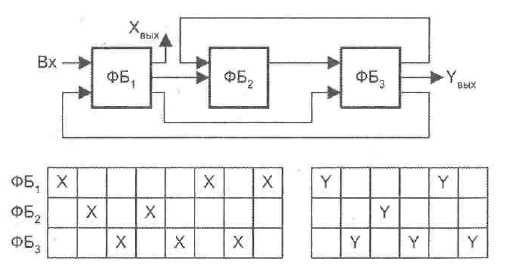
Рис. 9.2. Нелинейный конвейер
Чтобы определить, когда пора приступать к повторному вычислению той или иной функции, необходимо построить диаграмму однократной реализации этой функции и отследить по ней моменты, когда такой запуск не приведет к конфликту, связанному с одновременным обращением к одному и тому же функциональному блоку.
Так, в ходе реализации функции X запуск очередного ее вычисления возможен после 1,3 и 6 тактов. Запуск параллельного вычисления функции Y возможен после 2 и 4 тактов. При запуске функции Y очередной ее запуск позволен после тактов 1,3 и 5, а параллельный запуск функции X допустим после 2 и 4 тактов.
Конвейер команд
Идея конвейера команд была предложена в 1956 году академиком . Как известно, цикл команды представляет собой последовательность этапов. Возложив реализацию каждого из них на самостоятельное устройство и последовательно соединив такие устройства, мы получим классическую схему конвейера команд. Для иллюстрации воспользуемся примером, приведенным в [200]. Выделим в цикле команды шесть этапов:
1. Выборка команды (ВК). Чтение очередной команды из памяти и занесение ее в регистр команды.
2. Декодирование команды (ДК). Определение кода операции и способов адресации операндов,
3. Вычисление адресов операндов (ВА). Вычисление исполнительных адресов каждого из операндов в соответствии с указанным в команде способом их адресации.
4. Выборка операндов (ВО). Извлечение операндов из памяти. Эта операция не нужна для операндов, находящихся в регистрах.
5. Исполнение команды (ИК). Исполнение указанной операции.
6. Запись результата (ЗР). Занесение результата в память.

Рис. 9.3. Логика работы конвейера команд
На рис. 9.3 показан конвейер с шестью ступенями, соответствующими шести этапам цикла команды. В диаграмме предполагается, что каждая команда обязательно проходит все шесть ступеней, хотя этот случай не совсем типичен. Так, команда загрузки регистра не требует этапа ЗР. Кроме того, здесь принято, что все этапы могут выполняться одновременно. Без конвейеризации выполнение девяти команд заняло бы 9 х 6 = 54 единицы времени. Использование конвейера позволяет сократить время обработки до 14 единиц.
Конфликты в конвейере команд
Полученное в примере число 14 характеризует лишь потенциальную производительность конвейера команд. На практике в силу возникающих в конвейере конфликтных ситуаций достичь такой производительности не удается. Конфликтные ситуации в конвейере принято обозначать термином риск (hazard), а обусловлены они могут быть тремя причинами:
■ попыткой нескольких команд одновременно обратиться к одному и тому же ресурсу ВМ (структурный риск);
■ взаимосвязью команд по данным (риск по данным);
■ неоднозначностью при выборке следующей команды в случае команд перехода (риск по управлению).
Структурный риск (конфликт по ресурсам) имеет место, когда несколько команд, находящихся на разных ступенях конвейера, пытаются одновременно использовать один и тот же ресурс, чаще всего — память. Так, в типовом цикле команды сразу три этапа (ВК, ВО и ЗР) связаны с обращением к памяти. Диаграмма (см. рис. 9.3) показывает, что все три обращения могут производиться одновременно, однако на практике это не всегда возможно. Подобных конфликтов частично удается избежать за счет модульного построения памяти и использования кэш-памяти — имеется вероятность того, что команды будут обращаться либо к разным модулям ОП, либо одна из них станет обращаться к основной памяти, а другая к кэш-памяти. С этих позиций выгоднее разделять кэш-память команд и кэш-память данных. Конфликты из-за одновременного обращения к памяти могут и не возникать, поскольку для многих команд ступени выборки операнда и записи результата часто не требуются. В целом, влияние структурного риска на производительность конвейера по сравнению с другими видами рисков сравнительно невелико.
Риск по данным, в противоположность структурному риску — типичная и регулярно возникающая ситуация. Для пояснения сущности взаимосвязи команд по данным положим, что две команды в конвейере (i и j) предусматривают обращение к одной и той же переменной х, причем команда i предшествует команде j. В общем случае между i и j ожидаемы три типа конфликтов по данным (рис. 9.4):
■ «Чтение после записи» (ЧПЗ): команда j читаете до того, как команда i успела записать новое значение х, то есть j ошибочно получит старое значение х вместо нового.
■ «Запись после чтения» (ЗПЧ): команда j записывает новое значение х до того, как команда i успела прочитать х, то есть команда i ошибочно получит новое значение х вместо старого.
■ «Запись после записи» (ЗПЗ): команда; записывает новое значение х прежде чем команда i успела записать в качестве х свое значение, то есть х ошибочно содержит i-e значение х вместо j-го.
Возможен и четвертый случай, когда команда j читает x прежде команды i. Этот случай не вызывает никаких конфликтов, поскольку как i, так и j получат верное значение х.
Рис. 9.4. Конфликты поданным: а — «Чтение после записи»; б— «Запись после чтения»;
в — «Запись после записи»
Наиболее частый вид конфликтов по данным — ЧПЗ, поскольку операция чтения в цикле команды (этап ВО) предшествует операции записи (этап ЗР). По той же причине конфликты типа ЗПЧ большой проблемы не представляют. Сложности появляются, только если структура конвейера допускает запись прежде чтения или если команды в конвейере обрабатываются в последовательности, отличной от предписанной программой. Такое возможно, если командам в конвейере разрешается «догонять» предшествующие им команды, приостановленные из-за какого-то конфликта. Конфликт типа ЗПЗ также не вызывает особых проблем в конвейерах, где команды следуют в порядке, определенном программой, и могут производить запись только на этапе ЗР. В худшем случае, когда одна команда догоняет другую из-за приостановки последней, имеет место конфликт по ресурсу — попытка одновременного доступа к одной и той же ячейке.
В борьбе с конфликтами по данным выделяют два аспекта: своевременное обнаружение потенциального конфликта и его устранение. Признаком возникновения конфликта по данным между двумя командами i и j служит невыполнение хотя бы одного из трех условий Бернстейна (Bernstein's Conditions):

Где O(k) — множество ячеек, изменяемых командой k; I(1) — множество ячеек, читаемых командой l; Ø — пустое множество; ∩ — операция пересечения множеств.
Критерий может быть распространен и на большее число команд: для трех команд подобных уравнений будет 9, для четырех команд — 18 (по три на каждую пару). Соблюдение соотношений является достаточным, но не необходимым условием, поскольку в ряде случаев коллизий может и не быть.
Для борьбы с конфликтами но данным применяются как программные, так и аппаратные методы.
Программные методы ориентированы на устранение самой возможности конфликтов еще на стадии компиляции программы. Оптимизирующий компилятор пытается создать такой объектный код, чтобы между командами, склонными к конфликтам, находилось достаточное количество нейтральных в этом плане команд. Если такое не удается, то между конфликтующими командами компилятор вставляет необходимое количество команд типа «Нет операции». ^
Фактическое разрешение конфликтов возлагается на аппаратные методы. Наиболее очевидным решением является остановка команды j на несколько тактов с тем, чтобы команда i успела завершиться пли, по крайней мере, миновать ступень конвейера, вызвавшую конфликт. Соответственно задерживаются и команды, следующие в конвейере за j-й командой. Данную ситуацию называют «пузырьком» в конвейере. Иногда приостанавливают только команду j, не задерживая следующие за ней команды. Это более эффективный прием, но его реализация усложняет конвейер.
Попятно, что остановки конвейера снижают его эффективность но разработчики ВМ всячески стремятся сократить общее число остановок или хотя бы их длительность. Поскольку наиболее частые конфликты по данным — это ЧПЗ, основные усилия тратятся на противодействие именно этому типу конфликтов. Среди известных методов борьбы с ЧПЗ наибольшее распространение получил прием ускоренного продвижения информации (forwarding). Обычно между двумя соседними ступенями конвейера располагается буферный регистр, через который предшествующая ступень передает результат своей работы на последующую ступень, то есть передача информации возможна лишь между соседними ступенями конвейера. При ускоренном продвижении, когда для выполнения команды требуется операнд, уже вычисленный предыдущей командой, этот операнд может быть получен непосредственно из соответствующего буферного регистра, минуя вес промежуточные ступени конвейера. С данной целью в конвейере предусматриваются дополнительные тракты пересылки информации (тракты опережения, тракты обхода), снабженные средствами мультиплексирования.
Наибольшие проблемы при создании эффективного конвейера обусловлены командами, изменяющими естественный порядок вычислений1. Простейший конвейер ориентирован на линейные программы. В нем ступень выборки извлекает команды из последовательных ячеек памяти, используя для этого счетчик команд (СК). Адрес очередной команды в линейной программе формируется автомата чески, за счет прибавления к содержимому СК числа, равного длине текущей команды в байтах. Реальные программы практически никогда не бывают линейными. В них обязательно присутствуют команды управления, изменяющие последовательность вычислений: безусловный и условный переход, вызов процедуры» возврат из процедуры и т. п. Доля подобных команд в программе оценивается как 10-20% (по некоторым источникам она существенно больше). Выполнение команд, изменяющих последовательность вычислений (в дальнейшем будем их называть командами перехода), может приводить к приостановке конвейера на несколько тактов, из-за чего производительность процессора снижается. Приостановки конвейера при выполнении команд перехода обусловлены двумя факторами.
1В фон-неймановской ВМ команды размещаются и ячейках памяти и извлекаются для выполнения в том же порядке, в каком они следуют в программе. Такую последовательность выполнения команд программы называют естественной.
Первый фактор характерен для любой команды перехода и связан с выборкой команды из точки перехода (по адресу, указанному в команде перехода). То, что текущая команда относится к командам перехода, становится ясным только после декодирования (после прохождения ступени декодирования), то есть спустя два такта от момента поступления команды на конвейер. За это время на первые ступени конвейера уже поступят новые команды, извлеченные в предположении, что естественный порядок вычислений не будет нарушен. В случае, перехода эти ступени нужно очистить и загрузить в конвейер команду, расположенную по адресу перехода, для чего нужен исполнительный адрес последней. Поскольку в командах перехода обычно указаны лишь способ адресации и адресный код, исполнительный адрес предварительно должен быть вычислен, что и делается па третьей ступени конвейера. Таким образом, реализация перехода в конвейере требует определенных дополнительных операций, выполнение которых равносильно остановке конвейера как минимум на два такта.
Вторая причина нарушения ритмичности работы конвейера имеет отношение только к командам условного перехода. Для пояснения сути проблемы воспользуемся ранее приведенной условной программой (рис. 9.3), несколько изменив постановку задачи (рис. 9.5).
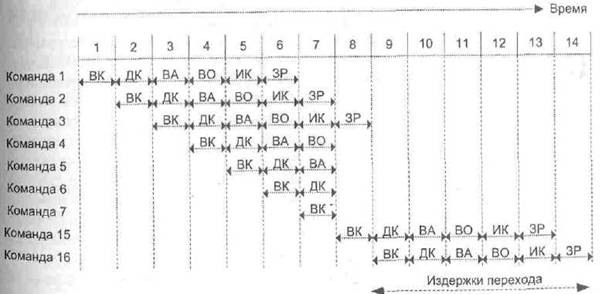
Рис. 9.5. Влияние условного перехода на работу конвейера команд
Пусть команда 3 — это условный переход к команде 15. До завершения команды 3 невозможно определить, какая из команд (4-я или 15-я) должна выполняться следующей, поэтому конвейер просто загружает следующую команду в последовательности (команду 4) и продолжает свою работу. В варианте, показанном на рис. 9.3, переход не произошел и получена максимально возможная производительность. На рис. 9.5 переход имеет место, о чем неизвестно до 7-го шага. В этой точке конвейер должен быть очищен от ненужных команд, выполнявшихся до данного момента. Лишь на шаге 8 на конвейер поступает нужная команда 15, из-за чего в течение тактов от 9 до 12 не будет завершена ни одна другая команда. Это и есть издержки из-за невозможности предвидения исхода команды условного перехода. Как видно, они либо существенно больше, чем для прочих кс перехода (если переход происходит), либо отсутствуют вовсе (если переход не происходит).
Для сокращения задержек, обусловленных выборкой команды из точки хода, применяются несколько подходов:
■ вычисление исполнительного адреса перехода на ступени декодирования команды;
■ использование буфера адресов перехода;
■ использование кэш-памяти для хранения команд, расположенных в точке перехода; ■ использование буфера цикла.
В результате декодирования команды выясняется не только ее принадлежность к командам перехода, но также способ адресации и адресный код точки перехода. Это позволяет сразу же приступить к вычислению исполнительного адреса перехода, не дожидаясь передачи команды на третью ступень конвейера, и тем самым сократить время остановки конвейера с двух тактов до одного. Для реализации этой идеи в состав ступени декодирования вводятся дополнительные сумматоры, с помощью которых и вычисляется исполнительный адрес точки перехода.
Буфер адресов перехода (ВТВ, Branch Target Buffer) представляет собой кэш-память небольшой емкости, в которой хранятся исполнительные адреса точек перехода нескольких последних команд, для которых переход имел место. В роли тегов выступают адреса соответствующих команд. Перед выборкой очередной команды ее адрес (содержимое счетчика команд) сравнивается с адресами команд, представленных в ВТВ. Для команды, найденной в буфере адресов перехода, исполнительный адрес точки перехода не вычисляется, а берется из ВТВ, благодаря чему выборка команды из точки перехода может быть начата на один такт раньше. Команда, ссылка на которую в ВТВ отсутствует, обрабатывается стандартным образом. Если это команда перехода, то полученный при ее выполнении исполнительный адрес точки перехода заносится в ВТВ, при условны, что команда завершилась переходом. При замещении информации в ВТВ обычно применяется алгоритм LRU.
Применение ВТВ дает наибольший эффект, когда отдельные команды перехода в программе выполняются многократно, что типично для циклов. Обычно ВТВ используется не самостоятельно, а в составе других, более сложных схем компенсации конфликтов по управлению.
Кэш-память команд, расположенных в точке перехода (BTIC, Branch Target Instruction Cache),— это усовершенствованный вариант ВТВ, где в кэш-память помимо исполнительного адреса команды в точке перехода записывается также и код этой команды. За счет увеличения емкости кэш-памяти BTIC позволяет при повторном выполнении команды перехода исключить не только этап вычисления исполнительного адреса точки перехода, но и этап выборки расположенной там команды. Преимущества данного подхода в наибольшей степени проявляются при многократном исполнении одних и тех же команд перехода, главным образом при реализации программных циклов.
Буфер цикла представляет собой маленькую быстродействующую память, входящую в состав первой ступени конвейера, где производится выборка команд. В буфере сохраняются коды п последних команд в той последовательности, в которой они выбирались. Когда имеет место переход, аппаратура сначала проверяет, нет ли нужной команды в буфере, и если это так, то команда извлекается из буфера. Стратегия наиболее эффективна при реализации циклов и итераций, чем и объясняется название буфера. Если буфер достаточно велик, чтобы охватить все тело цикла, выборку команд из памяти достаточно выполнить только одни раз в первой итерации, поскольку необходимые для последующих итераций команды уже находятся в буфере.
По принципу использования буфер цикла похож на BTIC, с той разницей, что в нем сохраняется последовательность выполнения команд, а сам буфер меньше по емкости и дешевле.
Среди ВМ, где реализован буфер цикла, можно упомянуть некоторые вычислительные машины фирмы CDC (Star 100,6600,7600) и суперЭВМ CRAY-1. Специализированная версия буфера цикла имеется и в микропроцессоре Motorola 68010, где он используется для особых циклов, включающих в себя команду «Уменьшение и переход по условию».
Методы решения проблемы условного перехода
Несмотря на важность аспекта вычисления исполнительного адреса точки перехода, основные усилия проектировщиков ВМ направлены на решение проблемы условных переходов, поскольку именно последние приводят к наибольшим издержкам в работе конвейера. Для устранения или частичного сокращения этих издержек были предложены различные способы, которые условно можно разделить на четыре группы;
■ буферы предвыборки;
■ множественные потоки;
■ задержанный переход;
■ предсказание перехода.
Равномерность поступления команд на вход конвейера часто нарушается, например из-за занятости памяти или при выборке команд, состоящих из нескольких слов. Чтобы добиться ритмичности подачи команд на вход конвейера, между ступенью выборки команды и остальной частью конвейера часто размещают буферную память, организованную по принципу очереди (FIFO) и называемую буфером предвыборки. Буфер предвыборки можно рассматривать как несколько дополнительных ступеней конвейера. Подобное удлинение конвейера не сказывается на его производительности (при заданной тактовой частоте); оно лишь приводит к увеличению времени прохождения команды через конвейер. Типичные буферы предвыборки в известных процессорах рассчитаны на 2-8 команд.
Чтобы одновременно с обеспечением ритмичной работы конвейера решить 11 Проблему условных переходов, в конвейер включают два таких буфера (рис. 9.6).
Каждая извлеченная из памяти и помещенная в основной буфер команда анализируется блоком перехода. При обнаружении команды условного перехода (УП)
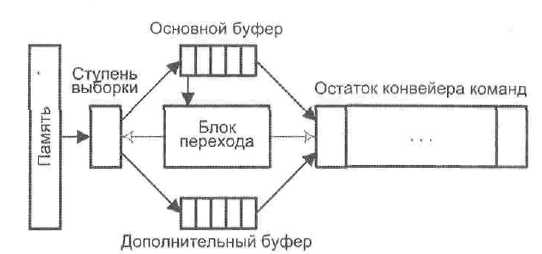
Рис. 9.6. Конвейер с буферами предвыборки команд
блок перехода вычисляет исполнительный адрес точки перехода и параллельно с продолжением последовательной выборки в основной буфер организует выборку в дополнительный буфер команд, начиная с точки УП. Далее блок перехода определяет исход команды УП, в зависимости от которого подключает к остатку конвейера нужный буфер, при этом содержимое другого буфера сбрасывается. Упрощенный вариант подобного подхода применен в IBM 360/91, где дополнительный буфер рассчитан на одну команду, то есть выигрыш достигается за счет исключения времени на выборку команды из точки перехода.
Помимо необходимости дублирования части оборудования, у метода имеется еще один недостаток. Так, если в потоке команд несколько команд УП следуют одна за другой или находятся достаточно близко, количество возможных ветвлений увеличивается и, соответственно, должно быть увеличено и число буферов предвыборки.
Другим решением проблемы переходов служит дублирование начальных ступеней конвейера и создание тем самым двух параллельных потоков команд (рис. 9.7).
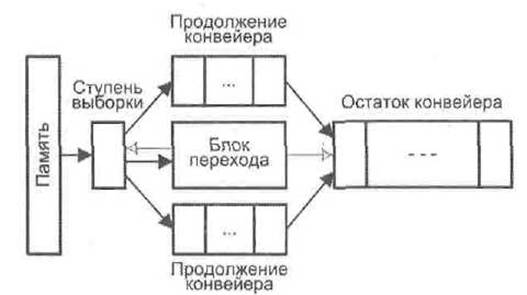
Рис. 9.7. Конвейер с множественными Потоками
В одной из ветвей такого «раздвоенного» конвейера последовательность выборки и выполнения команд соответствует случаю, когда условие перехода не вы полнилось, во второй ветви — случаю выполнения этого условия. Для ранее рассмотренного примера (см. рис. 9.5) в одном из потоков может обрабатывать последовательность команд 4-6, а в другом - 15-17. Оба потока сходятся в точке, где итог проверки условия перехода становится очевидным. Дальнейшее продвижение по конвейеру продолжает только «правильный» поток. Основной недостаток метода состоит в том, что на конвейер или в поток может поступить новая команда УП до того, как будет принято окончательное решение по текущей команде перехода. Каждая такая команда требует дополнительного потока. Несмотря на это, стратегия позволяет улучшить производительность конвейера. Примерами ВМ, где используются два или более конвейерных потоков, служат IBM 370/168 и IBM 3033.
Стратегия задержанного перехода предполагает продолжение выполнения команд, следующих за командой УП, вне зависимости от ее исхода. Естественно, что, то имеет смысл, лишь когда последующие команды являются «полезными», то есть такими, которые все равно должны быть когда-то выполнены, независимо от того, происходит переход или нет, и если команда перехода никак не влияет на результат их выполнения.
Для реализации этой идеи на этапе компиляции программы после каждой команды перехода вставляется команда «Нет операции». Затем на стадии оптимизации программы производятся попытки «перемешать» команды таким образом, чтобы по возможности большее количество команд «Нет операции» заменить «полезными» командами программы. Разумеется, замещать команду «Нет операции» можно лишь на такую, которая не влияет на условие выполняемого перехода, иначе полученная последовательность команд не будет функционально эквивалентной исходной. В оптимизированной программе удается заменить более 20% команд «Нет операции» [120].
Предсказание переходов
Предсказание переходов на сегодняшний день рассматривается как один из наиболее эффективных способов борьбы с конфликтами по управлению. Идея заключается в том, что еще до момента выполнения команды условного перехода или сразу же после ее поступления па конвейер делается предположение о наиболее вероятном исходе такой команды (переход произойдет или не произойдет). Последующие команды подаются на конвейер в соответствии с предсказанием. Для иллюстрации вернемся к примеру (см. рис. 9.5), где команда 3 является командой УП. Пусть для команды 3 предсказано, что переход не произойдет. Тогда вслед за командой 3 на конвейер будут поданы команды 4-6 и т. д. Если предсказан переход, то после команды 3 на конвейер подаются команды 15-17, ... При ошибочном предсказании конвейер необходимо вернуть к состоянию, с которого началась выборка «ненужных» команд (очистить начальные ступени конвейера), и приступить к загрузке, начиная с «правильной» точки, что по эффекту эквивалентно приостановке конвейера. Цена ошибки может оказаться достаточно высокой, но при правильных предсказаниях крупен и выигрыш — конвейер функционирует ритмично без остановок и задержек, причем выигрыш тем больше, чем выше точность предсказания. Термин «точность предсказания» в дальнейшем будем трактовать как процентное отношение числа правильных предсказаний к их общему количеству. В работе [70] дается следующая оценка: чтобы снижение производительности конвейера из-за его остановок по причине конфликтом по управлению не превысило 10%, точность предсказания переходов должна быть выше 97,7%.
К настоящему моменту известно более двух десятков различных способов реализации идеи предсказания переходов [165,230-232], отличающихся друг от друга исходной информацией, на основании которой делается прогноз, сложностью реализации и, главное, точностью предсказания. При классификации схем предсказания переходов обычно выделяют два подхода: статический и динамический, в зависимости от того, когда и на базе какой информации делается предсказание.
Эффективность большинства из приводимых в учебнике методов предсказания переходов иллюстрируется результатами исследований, опубликованными в [68,95,107,197,207,228]. Все эксперименты проводились по примерно одинаковой методике: численные показатели получены путем имитации методов предсказания переходов при выполнении наборов стандартных тестовых программ. Главное различие заключалось в выборе тестовых программ, что и нашло отражение в существенном расхождении полученных оценок.
Так, в работе Смита [197] использовались шесть тестовых программ, написанных на языке Фортран:
■ ADVAN: решение системы из трех дифференциальных уравнений в частных производных;
■ GIBSON: искусственная программа компиляции набора команд, примерно удовлетворяющего так называемой смеси Гибсона № 5;
■ SCI2: обращение матрицы;
■ SINCOS: преобразование массива координат из полярной системы отсчета в прямоугольную;
■ SORTST: сортировка массива изцелых чисел;
■ TBLINK: работа со связанным списком.
В прочих исследованиях участвовали программы, входящие в различные версии тестовых пакетов SPEC, в частности пакетов SPEC_92, SPEC_95 и CPU2000.
Последующий материал раздела посвящен рассмотрению различных механизмов предсказания переходов.
Статическое предсказание переходов
Статическое предсказание переходов осуществляется на основе некоторой априорной информации о подлежащей выполнению программе. Предсказание делается на этапе компиляции программы и в процессе вычислений уже не меняется. Главное различие между известными механизмами статического прогнозирования заключается в виде информации, используемой для предсказания, и ее трактовки. Исходная информация может быть получена двумя путями: на основе анализа кода программы или в результате ее профилирования (термин «профилирование» поясняется ниже).
Известные стратегии статического предсказания для команд УП можно классифицировать следующим образом:
■ переход происходит всегда (ПВ);
■ переход не происходит никогда (ПН);
■ предсказание определяется по результатам профилирования;

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
