

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
К. О. ГОЛИКОВ
Национальный исследовательский ядерный университет «МИФИ»
Математические модели процессов обработки ДАННЫХ
в формах электронных документов
В работе представлен комплекс моделей, описывающих аспекты электронного документа, связанные с обработкой данных при редактировании. Для описания статической структуры данных предложена модель, основанная на теории типизированных деревьев. Также описаны принципы проверки целостности данных с помощью системы предикатов валидации и организации внутренних зависимостей документа, позволяющие формализовать динамические аспекты процесса обработки электронных документов.
Деятельность большинства организаций проходит в соответствии с заранее определенным регламентом бизнес-процессов, описанным чаще всего в виде набора официальных процедур. Передача данных в рамках этих процедур возможна благодаря использованию носителей данных – документов. Описывая совокупность всех формальных правил, регламентирующих движение документов на предприятии, говорят о документообороте организации.
Ключевыми понятиями документооборота являются документ и его маршрут. Согласно ГОСТ Р [1], под электронным документом понимают информацию с реквизитами, позволяющими ее идентифицировать, зафиксированную на носителе, обеспечивающем обработку данных электронно-вычислительной машиной. Маршрутом, или жизненным циклом документа называют последовательность состояний, проходимых документом с момента его создания или получения до завершения исполнения или обработки в организации. Для описания отдельного бизнес-процесса необходимо, с одной стороны, задать маршрут, на основании которого будет проходить утверждение, и, с другой стороны, определить структуру данных и правила заполнения документа, который будет использован в качестве носителя данных в данном процессе.
Управление электронными документами является сравнительно молодой отраслью информационных технологий, и на данный момент не устоялись общепринятая терминология и математическая модель описания соответствующих процессов. Проблема формального описания маршрутизации документов, тем не менее, стала темой ряда исследований, основывающихся на аппарате сетей Петри и пи-исчисления [2]. С другой стороны, вопросу моделирования процессов, происходящих с документом во время диалога с пользователем, уделено значительно меньше внимания. В данной работе рассмотрена эта задача и предложена модель описания процессов обработки данных документа, редактируемого участником документооборота.
Экземпляр электронного документа представляет собой структуру данных, которая в общем случае является иерархической. Иерархическая модель позволяет описать логические группы атрибутов, а также коллекции однотипных элементов, каждый из которых может иметь сложную внутреннюю структуру. В качестве отправной точки будем использовать теорию типизированных деревьев, предложенную в работе сотрудников технологического института Мельбурна Б. Лоуи, Дж. Зобеля и Р. Сакс-Дэвиса [3]. Модель основана на понятиях дерева данных и типа дерева.
Σ-дерево (дерево данных) определяется следующим образом. Пусть существует конечное множество базовых типов B = {b1, b2, …, bm} и для каждого из них определен домен допустимых значений, M(bi), а также зафиксирован алфавит Σ имен элементов. Множество Σ-деревьев (обозначаемое ΤΣ), определяется индуктивно следующим образом:
а) каждый элемент 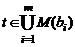 есть (элементарное) Σ-дерево;
есть (элементарное) Σ-дерево;
б) если σ Î Σ и t1,…, tn Î ΤΣ, где n ³ 1, то t = σ(t1,…, tn) есть Σ-дерево составного типа, а элемент σ называется в его контексте родительским.
Основной принцип типизации деревьев следующий. Пусть B – множество базовых типов, Т – множество всех доступных типов, T Ê B.
а) если тип τ Î B и t есть значение в домене типа τ, то t называют простым деревом типа τ, и обозначают t: τ;
б) рассмотрим деревья t1, t2,…, tn и типы τ1, τ2,… τn, где n ³1. Пусть для "i: 1 £ i £ n, каждый тип τi Î T и ti имеет тип τi. Пусть t = σ(t1: τ1, t2: τ2,…, tn: τn). Тогда t – дерево составного типа τ = σ(τ1, τ2, …, τn), обозначаемое t : τ.
Электронный документ может быть представлен как частный случай типизированного дерева, причем тип дерева находится в прямом соответствии с моделируемой официальной процедурой. Предметная область электронных документов накладывает дополнительные условия на допустимые структуры данных. Так, важным свойством электронного документа должна являться однозначная адресуемость всех данных. Например, структуры, смешивающие базовые и составные типы или ставящие в соответствие одному составному элементу несколько атомарных, являются корректными с точки зрения базовой модели, но не могут быть использованы при описании электронных документов. Во избежание подобных проблем необходимо дополнительно ограничить множество составных типов так, чтобы множественность значений допускалась только в случае, когда все поддеревья сами имеют составной тип, как указано в условии (1):
![]() (1)
(1)
Заметим, что тип дерева накладывает жесткие ограничения на структуру экземпляра дерева (имена элементов, количество вершин-потомков и их типы строго определены), однако данные в листовых вершинах ограничены лишь доменом допустимых значений. Другими словами, данному типу дерева может отвечать множество различных экземпляров деревьев, хранящих различные данные, однако имеющих одинаковую структуру. Поскольку каждый из простых типов описывает строго определенный домен значений, то и составной тип будет однозначно определять множество своих экземпляров. По аналогии с доменом значений простого типа обозначим множество допустимых экземпляров составного типа τ как M(τ).
Имея определение некоторого типа дерева, всегда можно провести верификацию отдельного экземпляра дерева на принадлежность к данному типу. Взаимоотношение между экземпляром и типами деревьев проиллюстрировано на рис. 1.
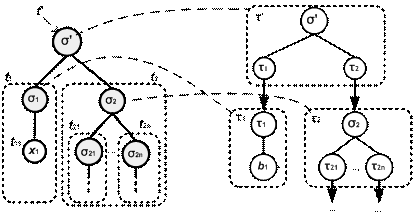
Рис. 1. Графическое представление типизированного дерева ![]() и его типа τ
и его типа τ
Для проверки корректности структуры документа целесообразно выделить подмножество D таких типов деревьев, которые могут быть использованы для описания документа. Исходя из логики предметной области, документ не может быть представлен атомарным значением, поэтому для типизации документов могут быть использованы только составные типы из множества E = T \ B. Итак, D Í E – множество типов документов. Поскольку множество D определяет все допустимые типы документов, можно провести верификацию корректности структуры документа на основе следующего условия:  .
.
Задача проверки целостности данных документа не исчерпывается корректностью его структуры. Не менее важной является проверка значений полей на соответствие правилам предметной области. Расширим модель типизированных деревьев, определив условия проверки целостности данных. Рассмотрим дерево t: τ. Назовем ограничением предикат V(x), определенный на множестве деревьев, соответствующих типу τ. Значение истинности предиката V(t) определяет состояние ограничения: если это «истина», то ограничение выполнено, если «ложь», то ограничение нарушено.
Заметим, что условие V(t) является необходимым, но не достаточным для корректности дерева. Поскольку ограничения могут быть определены на разных уровнях вложенности, необходимо проверить также их выполнение для всех поддеревьев, входящих в данное. Поэтому определим предикат ![]() для дерева (t : τ) следующим образом:
для дерева (t : τ) следующим образом:
а) если ![]() (простой тип), то
(простой тип), то ![]() ;
;
б) если 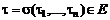 (составной тип) и
(составной тип) и ![]() , то:
, то:
![]() . (2)
. (2)
Таким образом, полная проверка корректности данных документа подразумевает рекурсивный спуск от корневой вершины к листовым с вычислением значений предикатов валидации на каждом уровне.
Поскольку ограничения имеют непосредственное отношение к валидации данных дерева, имеет смысл расширить понятие типа, включив в него множество присущих типу ограничений. Определим расширенный тип ![]() на типе τ как пару:
на типе τ как пару:
а) если ![]() (простой тип), то
(простой тип), то ![]() ;
;
б) если  (составной тип), то
(составной тип), то ![]() .
.
Здесь V – предикат, соответствующий ограничениям, присущим данному типу, ![]() – расширенные варианты типов
– расширенные варианты типов ![]() . По аналогии с множествами типов T, B, E, D множества расширенных типов будем обозначать
. По аналогии с множествами типов T, B, E, D множества расширенных типов будем обозначать 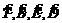 .
.
Введенные понятия позволяют свести верификацию корректности данных в дереве к проверке на соответствие расширенному типу. Действительно, если положить, что 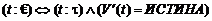 , то для корректности дерева t с точки зрения расширенного типа
, то для корректности дерева t с точки зрения расширенного типа ![]() достаточно потребовать, чтобы
достаточно потребовать, чтобы ![]() , при этом данное условие будет включать проверку структуры дерева и проверку ограничений на всех уровнях вложенности.
, при этом данное условие будет включать проверку структуры дерева и проверку ограничений на всех уровнях вложенности.
Расширенный тип документа дополнительно ограничивает значения, которые могут быть использованы в корректном экземпляре документа. Поэтому домен допустимых значений будет являться подмножеством домена для соответствующего нерасширенного типа: 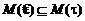 .
.
Рассмотрим теперь процесс работы пользователя с документом. Можно выделить три основных этапа этого процесса: открытие документа, модификация данных и завершение работы, которое обычно связано с процедурой подписания документа (рис. 2).

Рис. 2. Диаграмма состояний (конечный автомат): обработка документа пользователем
Модификация документа, представленная на диаграмме композитным состоянием «Изменен», является в общем случае итеративным процессом. На каждом шаге пользователь изменяет одно или несколько полей документа, после чего производится валидация данных. В случае если часть данных нарушает ограничения целостности, пользователь получает сообщения об ошибках, и весь документ переводится в состояние «Некорректен». Для того чтобы отправить документ далее по маршруту, сотрудник должен, прежде всего, исправить все ошибки в данных, то есть вернуть документ в корректное состояние. Редактирование документа сводится к последовательной замене значений атрибутов в дереве документа, при этом состояние на каждом шаге редактирования может быть описано отдельным экземпляром дерева 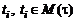 . При этом корректными с точки зрения предметной области являются лишь те из деревьев, которые принадлежат домену значений расширенного типа:
. При этом корректными с точки зрения предметной области являются лишь те из деревьев, которые принадлежат домену значений расширенного типа: 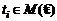 . Процесс заполнения документа как последовательность переходов между элементами множества
. Процесс заполнения документа как последовательность переходов между элементами множества ![]() приведен на рис. 3.
приведен на рис. 3.
 Изменение данных в документе может быть как инициировано пользователем, так и происходить автоматически на основе заранее определенных правил – зависимостей между полями документа. Для принятия решения о срабатывании зависимости недостаточно информации о состоянии дерева после изменений пользователя; необходимы также данные о характере самого изменения. Таким образом, зависимость d на дереве типа τ можно определить следующим образом как функцию (3), определенную на паре типизированных деревьев («до изменения» и «после изменения»):
Изменение данных в документе может быть как инициировано пользователем, так и происходить автоматически на основе заранее определенных правил – зависимостей между полями документа. Для принятия решения о срабатывании зависимости недостаточно информации о состоянии дерева после изменений пользователя; необходимы также данные о характере самого изменения. Таким образом, зависимость d на дереве типа τ можно определить следующим образом как функцию (3), определенную на паре типизированных деревьев («до изменения» и «после изменения»):
![]() (3)
(3)
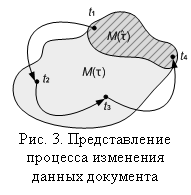
С практической точки зрения, для описания большинства зависимостей, встречающихся в реальных документах, достаточно более узкого класса функций, для определения которого используем понятие пути адресации [3]. Путь адресации p указывает на конкретную вершину типизированного дерева, а операция проекции ![]() позволяет получить данные, находящиеся в этой вершине. В качестве примера зависимости можно рассмотреть следующее правило: при изменении данных по пути адресации src, установить значение по пути адресации dest в f(t), где путь адресации dest указывает на поле простого типа bdest, и f : M(τ) ® M(bdest) – это функция, вычисляющая новое значение поля в соответствии с данными документа. Тогда класс зависимостей
позволяет получить данные, находящиеся в этой вершине. В качестве примера зависимости можно рассмотреть следующее правило: при изменении данных по пути адресации src, установить значение по пути адресации dest в f(t), где путь адресации dest указывает на поле простого типа bdest, и f : M(τ) ® M(bdest) – это функция, вычисляющая новое значение поля в соответствии с данными документа. Тогда класс зависимостей ![]() можно определить так:
можно определить так:
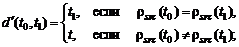 (4)
(4)
![]() (5)
(5)
На практике при определении документа имеет смысл задать набор зависимостей, которые могут быть организованы в цепь, так, что результат каждой из них становится входным аргументом для следующей. В этом случае можно говорить о суперпозиции зависимостей:
![]() . (6)
. (6)
В общем случае зависимости не являются коммутативными, то есть их порядок может повлиять на конечный результат. Поэтому при реализации системы зависимостей необходимо, чтобы последовательность их выполнения была определена явно и недвусмысленно.
Предложенные модели в комплексе описывают процесс обработки данных электронного документа, заполняемого участником документооборота. Данный набор моделей может быть использован при проектировании систем документооборота для формализации правил валидации данных и организации зависимостей между полями электронных документов.
Список литературы
1. Государственный стандарт РФ. ГОСТ Р . Делопроизводство и архивное дело. Термины и определения. М.: Федеральное агентство по техническому регулированию и метрологии, 1998.
2. Van der Aalst W. // The Journal of Circuits, Systems and Computers. 1998. V. 1. P. 21.
3. Lowe B., Zobel J., Sacks-Davis R. // Journal of Systems Integration. 1997. V. 7. P. 31.
