


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
· Специальные символы обозначают следующие элементы языка:
+ - * / - арифметические операции;
+ - * - операции над множествами;
= < > <= >= <> - отношения;
:= - присваивание;
. - конец программы, составной идентификатор, селектор поля записи;
, - разделитель элементов списка;
: - используется при описаниях;
; - разделитель операторов языка;
.. - диапазон;
[ ] илиселектор элемента массива;
{ } или (* *) - скобки для выделения комментариев;
+ - операция конкатенации строк
# - обозначение символа по его коду;
@ - обозначение адреса переменной;
$ - обозначение директивы компилятора или шестнадцатеричной константы;
^ - обозначение указателя.
· Комментарии { } (* *)
· Классификация типов данных:
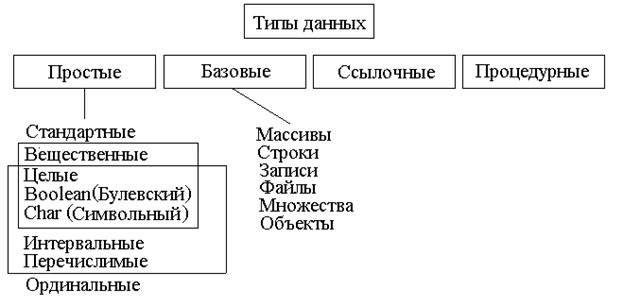
· О совместимости типов данных.
TP - язык со строгой типизацией данных. Это означает, что во время выполнения программы производится проверка справедливости (допустимости) выполняемых операций. Строгая типизация налагает определенные ограничения, которые объединены понятием совместимости типов данных. В основном программист должен сам предвидеть и обеспечивать явное преобразование типов данных там, где это необходимо. В TP явное преобразование типа данных осуществляется по схеме NewType(value), где значение value будет преобразовано к новому типу данных NewType.
Однако существуют ситуации, когда происходит неявное преобразование типов. Эти ситуации реализуются в операциях, при присваивании, при передаче параметров и регламентированы законами совместимости.
· В TP выделены три вида совместимости типов данных, и каждый вид предоставляет определенные возможности по совместному использованию данных. Два типа данных могут характеризоваться как одинаковые, совместимые по операциям (или просто совместимые) и совместимые по присваиванию.
· Две переменные относятся к одинаковым (эквивалентным) типам, если описания переменных:
а) ссылаются на одно и то же имя типа;
б) ссылаются на различные имена типов (пусть Т1 и Т2), которые в разделе описания типов объявлены идентичными (TYPE T1=T2);
· Бинарные операции могут быть выполнены над операндами, относящимися к совместимым (по операциям) типам данных. Два типа совместимы (по операциям), если:
а) типы одинаковы (эквивалентны);
б) оба типа целые или оба типа вещественные;
в) один тип есть диапазон другого, или оба есть диапазоны от третьего;
г) оба типа - строка (STRING);
д) один тип - строка, а другой - ARRAY[1..n] of CHAR, или просто CHAR;
е) оба типа - множества с совместимыми по операциям базовыми типами;
ж) один тип - ссылочный, другой безтиповый указатель;
з) оба типа - процедурные типы с одинаковым числом параметров, типы которых соответственно эквивалентны. Для функциональных типов необходима еще и эквивалентность типов результатов.
и) Считается, что каждый объект типа "множество" совместим с пустым множеством и каждый объект типа "указатель" совместим с константой NIL.
· Величина может быть присвоена переменной, если их типы совместимы по присваиванию. Выражение f типа F называется совместимым по присваиванию с переменной w типа W, если :
а) F и W - эквивалентные, не файловые типы (и не содержат файловые типы в качестве полей);
б) оба типа - совместимые ординарные типы и значения выражения f попадают в диапазон допустимых значений типа W;
в) оба вещественные типы и значение выражения f допустимо для типа W;
г) W - вещественный тип, F - целый;
д) W - строка, F - либо строка, либо символ, либо массив символов;
е) W и F - совместимые множественные типы, причем множество f целиком входит во множество W;
ж) W и F - совместимые ссылочные типы или совместимые процедурные типы;
з) W - процедурный тип, а f - имя процедуры или функции (параметры и типы должны быть согласованны);
и) W и F - объектные типы, причем тип F потомок типа W, либо оба типа ссылочные на совместимые объектные типы.
Хотя формулировки совместимости типов представляются довольно громоздкими, в их основе лежит простой здравый смысл. Разрешены действия, приводящие к естественному осмысленному результату без потери информации (или точности). Все операции округлений и усечений должны быть предусмотрены разработчиком программы и кодироваться явно.
Лекция 5
5.1 Простые типы данных
Элементы любого простого типа данных представляют собой упорядоченное множество. Следовательно, элементы простого типа могут быть связаны отношениями
=, <>, >, >=, <=, <.
Отношение между элементами простого типа является булевской величиной (относится к типу BOOLEAN).
Все простые типы данных, кроме вещественных, относятся к ординальным типам данных.
Для ординальных типов данных в языке TP определены операции, которые реализованы в функциях и процедурах:
PRED (predecessor - предшествующий),
SUCC (succeedent – последующий),
ORD (ordinal – порядковое числительное),
Dec (decrease – уменьшать),
Inc (increase – уменьшать),
SIZEOF (size of … - размер чего-либо)
Функции PRED и SUCC получают в качестве аргумента значение ординального типа и возвращают предыдущий или последующий элементы этого типа. Считается ошибкой применение функции PRED к первому элементу, а функции SUCC к последнему элементу множества значений данного ординального типа. Функция ORD возвращает порядковый номеp элемента данного ординального типа, пеpвый элемент имеет номер 0, втоpой - 1 и т. д. Исключение представляют данные целого типа, поскольку ORD с целочисленным аргументом возвращает сам аргумент. Функцию ORD можно считать функцией пpеобpазования типа, поскольку для любого ординального аргумента результат будет целочисленный.
Процедуры Dec (или Inc) позволяют увеличить (или уменьшить) аргумент на заданную величину. Например функция Dec(x, n) (или Inc (x, n)) увеличивает (или уменьшает) значение ординальной переменной x на n значений. Если параметр n опущен, то увеличение (уменьшение) происходит на 1.
Для любого типа данных (в том числе и для простого) определена функция SIZEOF(X), которая возвращает размер памяти под аргумент X в байтах. В этой функции в качестве аргумента можно использовать имя константы, имя переменной или типа данных.
5.1.1 Перечислимый тип
Перечислимый ординальный тип описывается прямым перечислением константных значений этого типа в скобках через запятую. В качестве константных значений используются идентификаторы. Например:
type week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday);
На множестве значений перечислимого типа определен естественный порядок Monday<Tuesday<Wednesday<…<Sunday. Если х и у – переменные var x, y:week_day; то можно переменным х и у присвоить значения, например: х:=Wednesday; y:=SUCC(x); применение функции ORD(Monday) – дает значение 0 целого типа, ORD(x) – 2 , ORD(y) – 3 ;
5.1.2 Интервальный тип
Интервальный ординальный тип (или тип – диапазон) является подмножеством последовательных величин ранее определенного (или предопределенного) перечислимого типа (базового типа).
Если тип week_day ранее определен, мы можем создать новый тип, например:
TYPE work_day=Monday..Friday;
На интервальном типе данных определены те же операции, что и на базовом. Однако программист должен гарантировать корректность операций на шаге выполнения. Если var D:work_day, то на шаге выполнения программы фрагмент D:=Friday; D:=SUCC(D) приведет к ошибке, поскольку для интервального типа work_day значение Friday является последним и не имеет последующего.
program datas;
type
week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday);
dat=1..31;
month=(January, Fabruary, March, April, May, June, July,
August, September, October, November, December);
year=1900..2100;
attr_of_day=record
w_d:week_day;
d:dat;
m:month;
y:year
end;
var
today:attr_of_day;
kol:integer;
function pred_week_day(w:week_day):week_day;
begin
if w=Monday then pred_week_day:=Sunday else pred_week_day:=pred(w)
end;
function pred_month(m:month):month;
begin
if m=January then pred_month:=December else pred_month:=pred(m)
end;
procedure pred_dat(var t:attr_of_day);
begin
if t. d=1 then
begin
t. m:=pred_month(t. m);
if t. m=December then t. y:=t. y-1;
case t. m of
January, March, May, July, August, October, December:t. d:=31;
Fabruary:if (t. y mod 4)=0 then t. d:=29 else t. d:=28;
April, June, September, November:t. d:=30
end
end else t. d:=t. d-1;
t. w_d:=pred_week_day(today. w_d);
end;
begin
today. w_d:=Monday;
today. d:=2;
today. m:=October;
today. y:=2006;
repeat
pred_dat(today);
if (today. y<=2000) and (today. w_d=Monday) and (today. d=13)
then kol:=kol+1;
until (today. y=1901) and (today. m=January) and (today. d=1);
writeln('Kol= ',kol:4)
end.
5.1.3 Целочисленные типы
К целочисленным типам в TP относятся следующие предопределенные типы:
Тип | Диапазон | Размер (байт) |
Shortint | -128..127 | 1 (со знаком) |
Integer | -32768..32767 | 2 (со знаком) |
Longint | -.. | 4 (со знаком) |
Byte | 0..255 | 1 (без знака) |
Word | 0..65535 | 2 (без знака) |
Для целочисленных типов применимы все функции, допустимые для ординальных типов – PRED, SUCC, DEC, INC. Определены унарные операции + и - ( сохранить знак числа, изменить знак числа), арифметические бинарные операции сложения (+), вычитания (-), умножения (*), деления нацело (div), взятия остатка при целочисленном делении (mod), деление (/), в результате последней операции получается вещественная величина. Кроме общих функций для ординальных типов данных, для целочисленных типов данных определены следующие:
CHR(X) – возвращает символ (значение типа CHAR), код которого есть целое положительное число X (0 <= X <= 255).
Логическая функция ODD(X) возвращает TRUE, если X – нечетно, в противном случае – FALSE.
ABS(X) - абсолютная величина X.
SQR(X) - квадрат величины X.
В TP для данных типа INTEGER (и совместимых с INTEGER) определены побитовые операции:
· n1 shl n2 - левый логический сдвиг двоичного кода числа n1 на n2 позиций. Слева двоичные разряды пропадают, справа добавляются нули.
· n1 shr n2 - правый логический сдвиг.
· not n – дополнение к двоичному коду целого числа n (цифра 0 заменяется на 1, 1 на 0).
· n1 or n2 – логическое "или".
· n1 and n2 – логическое "и".
· n1 xor n2 – логическое исключающее "или".
В побитовых операциях целые числа обрабатываются как строки двоичных цифр. Примеры использования побитовых операций приведены в таблицах.
Значение X | Операция | Результат |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Дес | Шестн | дес | шестн |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5 | $ | not X | $FFFFFFFA |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5 | $ | X shl 1 | 10 |
· Специальные символы обозначают следующие элементы языка: + - * / - арифметические операции; + - * - операции над множествами; = < > <= >= <> - отношения; := - присваивание; . - конец программы, составной идентификатор, селектор поля записи; , - разделитель элементов списка; : - используется при описаниях; ; - разделитель операторов языка; .. - диапазон; [ ] илиселектор элемента массива; { } или (* *) - скобки для выделения комментариев; + - операция конкатенации строк # - обозначение символа по его коду; @ - обозначение адреса переменной; $ - обозначение директивы компилятора или шестнадцатеричной константы; ^ - обозначение указателя. · Комментарии { } (* *) · Классификация типов данных:
· О совместимости типов данных. TP - язык со строгой типизацией данных. Это означает, что во время выполнения программы производится проверка справедливости (допустимости) выполняемых операций. Строгая типизация налагает определенные ограничения, которые объединены понятием совместимости типов данных. В основном программист должен сам предвидеть и обеспечивать явное преобразование типов данных там, где это необходимо. В TP явное преобразование типа данных осуществляется по схеме NewType(value), где значение value будет преобразовано к новому типу данных NewType. Однако существуют ситуации, когда происходит неявное преобразование типов. Эти ситуации реализуются в операциях, при присваивании, при передаче параметров и регламентированы законами совместимости. · В TP выделены три вида совместимости типов данных, и каждый вид предоставляет определенные возможности по совместному использованию данных. Два типа данных могут характеризоваться как одинаковые, совместимые по операциям (или просто совместимые) и совместимые по присваиванию. · Две переменные относятся к одинаковым (эквивалентным) типам, если описания переменных: а) ссылаются на одно и то же имя типа; б) ссылаются на различные имена типов (пусть Т1 и Т2), которые в разделе описания типов объявлены идентичными (TYPE T1=T2); · Бинарные операции могут быть выполнены над операндами, относящимися к совместимым (по операциям) типам данных. Два типа совместимы (по операциям), если: а) типы одинаковы (эквивалентны); б) оба типа целые или оба типа вещественные; в) один тип есть диапазон другого, или оба есть диапазоны от третьего; г) оба типа - строка (STRING); д) один тип - строка, а другой - ARRAY[1..n] of CHAR, или просто CHAR; е) оба типа - множества с совместимыми по операциям базовыми типами; ж) один тип - ссылочный, другой безтиповый указатель; з) оба типа - процедурные типы с одинаковым числом параметров, типы которых соответственно эквивалентны. Для функциональных типов необходима еще и эквивалентность типов результатов. и) Считается, что каждый объект типа "множество" совместим с пустым множеством и каждый объект типа "указатель" совместим с константой NIL. · Величина может быть присвоена переменной, если их типы совместимы по присваиванию. Выражение f типа F называется совместимым по присваиванию с переменной w типа W, если : а) F и W - эквивалентные, не файловые типы (и не содержат файловые типы в качестве полей); б) оба типа - совместимые ординарные типы и значения выражения f попадают в диапазон допустимых значений типа W; в) оба вещественные типы и значение выражения f допустимо для типа W; г) W - вещественный тип, F - целый; д) W - строка, F - либо строка, либо символ, либо массив символов; е) W и F - совместимые множественные типы, причем множество f целиком входит во множество W; ж) W и F - совместимые ссылочные типы или совместимые процедурные типы; з) W - процедурный тип, а f - имя процедуры или функции (параметры и типы должны быть согласованны); и) W и F - объектные типы, причем тип F потомок типа W, либо оба типа ссылочные на совместимые объектные типы. Хотя формулировки совместимости типов представляются довольно громоздкими, в их основе лежит простой здравый смысл. Разрешены действия, приводящие к естественному осмысленному результату без потери информации (или точности). Все операции округлений и усечений должны быть предусмотрены разработчиком программы и кодироваться явно. Лекция 55.1 Простые типы данныхЭлементы любого простого типа данных представляют собой упорядоченное множество. Следовательно, элементы простого типа могут быть связаны отношениями =, <>, >, >=, <=, <. Отношение между элементами простого типа является булевской величиной (относится к типу BOOLEAN). Все простые типы данных, кроме вещественных, относятся к ординальным типам данных. Для ординальных типов данных в языке TP определены операции, которые реализованы в функциях и процедурах: PRED (predecessor - предшествующий), SUCC (succeedent – последующий), ORD (ordinal – порядковое числительное), Dec (decrease – уменьшать),
НЕ нашли? Не то? Что вы ищете?
Inc (increase – уменьшать), SIZEOF (size of … - размер чего-либо) Функции PRED и SUCC получают в качестве аргумента значение ординального типа и возвращают предыдущий или последующий элементы этого типа. Считается ошибкой применение функции PRED к первому элементу, а функции SUCC к последнему элементу множества значений данного ординального типа. Функция ORD возвращает порядковый номеp элемента данного ординального типа, пеpвый элемент имеет номер 0, втоpой - 1 и т. д. Исключение представляют данные целого типа, поскольку ORD с целочисленным аргументом возвращает сам аргумент. Функцию ORD можно считать функцией пpеобpазования типа, поскольку для любого ординального аргумента результат будет целочисленный. Процедуры Dec (или Inc) позволяют увеличить (или уменьшить) аргумент на заданную величину. Например функция Dec(x, n) (или Inc (x, n)) увеличивает (или уменьшает) значение ординальной переменной x на n значений. Если параметр n опущен, то увеличение (уменьшение) происходит на 1. Для любого типа данных (в том числе и для простого) определена функция SIZEOF(X), которая возвращает размер памяти под аргумент X в байтах. В этой функции в качестве аргумента можно использовать имя константы, имя переменной или типа данных. 5.1.1 Перечислимый типПеречислимый ординальный тип описывается прямым перечислением константных значений этого типа в скобках через запятую. В качестве константных значений используются идентификаторы. Например: type week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); На множестве значений перечислимого типа определен естественный порядок Monday<Tuesday<Wednesday<…<Sunday. Если х и у – переменные var x, y:week_day; то можно переменным х и у присвоить значения, например: х:=Wednesday; y:=SUCC(x); применение функции ORD(Monday) – дает значение 0 целого типа, ORD(x) – 2 , ORD(y) – 3 ; 5.1.2 Интервальный типИнтервальный ординальный тип (или тип – диапазон) является подмножеством последовательных величин ранее определенного (или предопределенного) перечислимого типа (базового типа). Если тип week_day ранее определен, мы можем создать новый тип, например: TYPE work_day=Monday..Friday; На интервальном типе данных определены те же операции, что и на базовом. Однако программист должен гарантировать корректность операций на шаге выполнения. Если var D:work_day, то на шаге выполнения программы фрагмент D:=Friday; D:=SUCC(D) приведет к ошибке, поскольку для интервального типа work_day значение Friday является последним и не имеет последующего. program datas; type week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); dat=1..31; month=(January, Fabruary, March, April, May, June, July, August, September, October, November, December); year=1900..2100; attr_of_day=record w_d:week_day; d:dat; m:month; y:year end; var today:attr_of_day; kol:integer; function pred_week_day(w:week_day):week_day; begin if w=Monday then pred_week_day:=Sunday else pred_week_day:=pred(w) end; function pred_month(m:month):month; begin if m=January then pred_month:=December else pred_month:=pred(m) end; procedure pred_dat(var t:attr_of_day); begin if t. d=1 then begin t. m:=pred_month(t. m); if t. m=December then t. y:=t. y-1; case t. m of January, March, May, July, August, October, December:t. d:=31; Fabruary:if (t. y mod 4)=0 then t. d:=29 else t. d:=28; April, June, September, November:t. d:=30 end end else t. d:=t. d-1; t. w_d:=pred_week_day(today. w_d); end; begin today. w_d:=Monday; today. d:=2; today. m:=October; today. y:=2006; repeat pred_dat(today); if (today. y<=2000) and (today. w_d=Monday) and (today. d=13) then kol:=kol+1; until (today. y=1901) and (today. m=January) and (today. d=1); writeln('Kol= ',kol:4) end. 5.1.3 Целочисленные типыК целочисленным типам в TP относятся следующие предопределенные типы:
Для целочисленных типов применимы все функции, допустимые для ординальных типов – PRED, SUCC, DEC, INC. Определены унарные операции + и - ( сохранить знак числа, изменить знак числа), арифметические бинарные операции сложения (+), вычитания (-), умножения (*), деления нацело (div), взятия остатка при целочисленном делении (mod), деление (/), в результате последней операции получается вещественная величина. Кроме общих функций для ординальных типов данных, для целочисленных типов данных определены следующие: CHR(X) – возвращает символ (значение типа CHAR), код которого есть целое положительное число X (0 <= X <= 255). Логическая функция ODD(X) возвращает TRUE, если X – нечетно, в противном случае – FALSE. ABS(X) - абсолютная величина X. SQR(X) - квадрат величины X. В TP для данных типа INTEGER (и совместимых с INTEGER) определены побитовые операции: · n1 shl n2 - левый логический сдвиг двоичного кода числа n1 на n2 позиций. Слева двоичные разряды пропадают, справа добавляются нули. · n1 shr n2 - правый логический сдвиг. · not n – дополнение к двоичному коду целого числа n (цифра 0 заменяется на 1, 1 на 0). · n1 or n2 – логическое "или". · n1 and n2 – логическое "и". · n1 xor n2 – логическое исключающее "или". В побитовых операциях целые числа обрабатываются как строки двоичных цифр. Примеры использования побитовых операций приведены в таблицах.
5.1.4 Данные типа CHARДанные типа CHAR занимают один байт памяти. Константными значениями служат символы кодировки ASCII (Американский стандартный код обмена информации), содержащие, кроме латинских и русских (больших и малых) букв, цифр и используемых в TP специальных символов, различного рода служебные символы. Каждому символу соответствует некоторый код (целое число в диапазоне от 0 до 255), но не каждый символ имеет графическое представление (например, символы табуляции, символ возврата каретки и др.). Над данными типа CHAR можно производить операции, определенные для данных ординального типа. Функция ORD возвращает код аргумента. Если символ имеет графическое представление, например буква А, указать такой символ можно, заключив его изображение в апострофы – 'А'. Следующий оператор FOR C := 'A' TO 'Z' DO WRITELN('код символа', C, ' - ', ORD(C):3); позволяет получить коды всех символов таблицы ASCII в диапазоне от A до Z. Переменная C должна быть описана как CHAR. При использовании значений типа CHAR, не имеющих графического представления, можно применить форму записи символов по их коду с помощью префикса #, например #65 – то же самое, что 'A' (65 – код символа A). 5.1.5 Тип BOOLEANОрдинальный предопределенный тип BOOLEAN можно рассматривать как перечислимый тип с описанием TYPE BOOLEAN = (FALSE, TRUE); Переменные этого типа занимают один байт памяти. Операции AND, OR, XOR, NOT для операндов булевского типа понимаются компилятором как булевские операции умножения ("и"), сложения ("или"), "исключающего или" и "отрицания". Пусть A и B – выражения булевского типа, тогда булевские операции определяются следующим образом:
AND Логическое И OR Логическое ИЛИ XOR Логическое исключающее ИЛИ NOT Логическое НЕ Функция ORD дает значение 0, если аргумент имеет значение FALSE, и 1, если TRUE. 5.1.6 Вещественные типы данныхПростые типы вещественных данных не являются ординальными. С помощью этих типов данных в языке задается некоторое конечное подмножество рациональных чисел. Константы вещественного типа записываются в виде цепочки цифр с точкой, например: 0.0, 3.14, 17.4 (вещественная константа должна начинаться и заканчиваться цифрой). Константа может быть представлена в экспоненциальной форме, например, 1.0E+5, 0.01E-0, 3.14E. Кроме того, TP позволяет работать со следующими вещественными типами (табл.).
*Это форматы чисел, с которыми работает математический сопроцессор. Над данными вещественного типа в языке TP определены следующие операции и функции: 1. унарная операция + возвращает величину операнда; 2. унарная операция – меняет знак операнда; 3. бинарные операции +, - ,*, / возвращают результат выполнения соответствующих операций над вещественными числами; 4. отношения <, >, <=, >=, =, <> возвращают булевскую величину как результат сравнения операндов. 1. функция TRUNC(X) возвращает целую часть X; 2. функция ROUND(X) - округленное значение X до целого; 3. функция INT(X) - возвращает целую часть аргумента; 4. функция FRAC(X) - возвращает дробную часть аргумента; 5. функция PI - возвращает число 3.; 6. функция ABS(X) - абсолютную величину X; 7. функции SIN(X), COS(X), ARCTAN(X), LN(X), EXP(X), SQRT(X) и SQR(X) - возвращают значения синуса, косинуса, арктангенса, натурального логарифма, экспоненты, корня квадратного и квадрата аргумента X соответственно. Лекция 66.1 Структура программы на ПаскалеПрограмма на Паскале представляет собой обычный текст. Транслятор воспринимает этот текст как последовательность символов. На этапе лексического анализа текста выделяются слова (разделитель – пробел). Из слов составлены предложения (или операторы), разделителем служит символ «;» – «точка с запятой».
Начинается программа с необязательного оператора program <имя программы> – заголовка программы. Именем программы может быть любой уникальный в данной программе идентификатор. После заголовка следует секция описаний. Секция описаний состоит из разделов. Раздел описания имен модулей (в стандарте Паскаля этот раздел отсутствует). Раздел начинается заголовком uses, далее списком через запятую указываются имена используемых в программе модулей. Раздел описания меток. После заголовка раздела label записывается список используемых в программе меток. Раздел описания типов данных. После заголовка раздела type следуют операторы описания типов данных, созданных в программе пользователем. Операторы описания типа имеют следующий формат: <имя типа>=<описатель типа>. Имя типа – идентификатор, описатель типа – конструкция, определяющая данный тип. Раздел описания имен переменных начинается с заголовка var. Далее следуют операторы описания переменных, имеющие следующий формат: <список имен переменных через запятую>:<имя типа или описатель типа>. Раздел описания процедур и функций заголовка не имеет. Раздел содержит описания пользовательских процедур и функций. В стандарте Паскаля перечисленные разделы следуют в строго указанном порядке. В ТР разделы могут следовать в любом порядке и могут повторяться. Текст программы на Паскале завершает секция действий, представляющая собой составной оператор, – последовательность операторов, заключенная в логические скобки begin end. В секции действий описана последовательность действий, то есть алгоритм решения задачи. 6.2 Процедуры для стандартного ввода/выводаДля осуществления ввода и вывода данных стандартного типа используются предопределенные процедуры ввода и вывода READ, READLN, WRITE, WRITELN. Эти процедуры, кроме стандартных типов (целочисленные, вещественные, булевский, символьный), могут обслуживать диапазонные типы со стандартным базовым типом и данные типа string (строка). В качестве аргумента эти процедуры получают список элементов ввода или вывода. Список формируется как строка, в которой указываются через запятую имена элементов ввода или вывода, возможно со спецификацией (характеристикой). Спецификации служат для уточнения формата представления данных. Если спецификация не указана, используется формат, принятый по умолчанию для данного типа данных. Элемент ввода или вывода может принимать одну из следующих форм: E,{нет спецификации} E:LEN,{указана характеристика длины} E:LEN:ACCUR {указана характеристика длины и точности} Здесь Е – выражение одного из перечисленных выше типов, обслуживаемых процедурами ввода и вывода, LEN и ACCUR – выражения типа INTEGER. Характеристика точности (ACCUR) может применяться только для вывода данных вещественного типа. Использование характеристик при выдаче данных в текстовый файл (или на экран монитора) показано на примерах: VAR I:INTEGER; C:CHAR; PI:REAL; B:BOOLEAN; A, S:STRING; I:=1234; C:='a'; PI:=3.14159; B:=TRUE; S:='ABCD'; A:='ABCD'; Обращение к процедуре результат WRITE(I:6); ..1234 WRITE(I:1); 1234 WRITE(I); .......1234 WRITE(C:6); .....a WRITE(PI:10); .3.142E+00 WRITE(PI); .3.E+00 WRITE(PI:10:4); ....3.1416 WRITE(B:10); ......TRUE WRITE(B:2); .T WRITE(S:6); ..ABCD WRITE(S:2); AB WRITE(S); ABCD Процедура WRITELN, в отличие от WRITE, после записи данных в файл осуществляет переход на новую логическую запись (строку) текстового файла. Процедура READLN, в отличие от READ, после выполнения операции ввода данных для всего списка элементов ввода, осуществляет переход на следующую логическую запись (строку) текстового файла чтения. 6.3 Массивы. Регулярный типМассив – структура данных, задающая в памяти ЭВМ определенное количество однотипных записей. Тип данных массив в классификации типов данных языка Паскаль относят к базовым структурам и называют регулярным типом данных. Описатель массива ARRAY[<индексный тип>] OF <базовый тип> <индексный тип> - имя или описатель индексного типа, <базовый тип> - имя или описатель базового типа. В качестве базового типа можно использовать любой тип данных. Индексный тип – любой ординальный тип данных, кроме LONGINT. Индексный тип задает количество элементов массива (размер массива) и тип значений индексов. Вот примеры описателей массивов: ARRAY[1..10] OF REAL – массивы этого типа будут состоять из 10 элементов действительного типа, индексы – целые числа от 1 до 10. ARRAY[CHAR] OF INTEGER – массивы этого типа будут состоять из 256 целочисленных элементов, индексы – символы кодовой таблицы от #0 до #255. ARRAY[’A’..’Z’] OF INTEGER – массивы этого типа будут состоять из 26 целочисленных элементов, индексы – заглавные буквы латинского алфавита. В качестве описателя базового типа может быть использован описатель массива. Вот пример описаний: TYPE I1=<индексный тип 1>; I2=<индексный тип 2>; Ik=<индексный тип k>; BAZ=<базовый тип>; MASS=ARRAY[I1] OF ARRAY[I2] OF BAZ В Паскале предусмотрена более компактная запись последнего оператора: MASS=ARRAY[I1,I2] OF BAZ Переменная типа MASS будет представлять собой двумерный массив (массив массивов). В описании VAR M:ARRAY[I1,I2, …, Ik] OF BAZ массив М объявлен как многомерный (k – мерный) массив. Количество индексных типов в описании массива – размерность массива. Доступ к элементам массива осуществляется с помощью селектора [ ] – квадратные скобки. В квадратных скобках указывают значение (выражение) индексного типа. Если переменные x1,x2, …, xk описаны так: var x1:I1; x2:I2; …; xk:Ik, то M – массив ARRAY[I1,I2, …, Ik] OF BAZ, M[x1] – массив ARRAY[I2, …, Ik] OF BAZ, M[x1][x2] – массив ARRAY[ …, Ik] OF BAZ, … M[x1][x2] … [xk] – данное базового типа BAZ, Допустимы сокращенные формы записи: M[x1,x2],…, M[x1,x2, …, xk], соответственно. Приведем примеры описаний и использования массивов TYPE M10=ARRAY[1..10] OF REAL; IND=-5..5; MIND=ARRAY[IND] OF REAL; {тип - массив из 11 элементов} MINDM10=ARRAY[IND] OF M10; {тип - двумерный массив} week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); dat=1..31; month=(January, Fabruary, March, April, May, June, July, August, September, October, November, December); VAR X:M10;{массив} K:IND;{переменная} Y:ARRAY[1..10] OF REAL; V:MIND; MM:MINDM10;{двумерный массив} Mdat:ARRAY[month] OF dat; Mweek_day:ARRAY[month, dat] OF week_day; В этих условиях доступ к элементам иллюстрируется операторами: K:=0; V[K]:=17.0; X[1]:= 22.5; Y[5]:=X[1]; MM[-3, 1]:= 0;{то же самое, что MM[-3][1]:= 0;} Mdat[January]:=31; Mweek_day[October, 9]:= Monday; В TP можно выполнить такое присваивание MM[0]:=X, если все компоненты массива V инициализированы (одинаковые типы данных). Нельзя выполнить присваивание X:=Y, поскольку переменные относятся к несовместимым по присваиванию типам данных. 6.4 Для работы с массивами – шаблоныШаблон 1. Ввод-вывод одномерного массива. program …; const NN=100;{Максимальное число элементов} … type MM=array [1..NN]of real; {Новый тип данных - массив} … var M:MM; k, i:integer; … begin {Ввод массива} writeln(‘Введите кол-во элементов массива (не более ',NN:1,’)’);
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5 | $ | X shr 1 | 2 | $ |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Значение X | Значение Y | Операция | Результат | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Дес | Шестн | Дес | шестн. | дес. | шестн. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5 | $ | 15 |
· Специальные символы обозначают следующие элементы языка: + - * / - арифметические операции; + - * - операции над множествами; = < > <= >= <> - отношения; := - присваивание; . - конец программы, составной идентификатор, селектор поля записи; , - разделитель элементов списка; : - используется при описаниях; ; - разделитель операторов языка; .. - диапазон; [ ] илиселектор элемента массива; { } или (* *) - скобки для выделения комментариев; + - операция конкатенации строк # - обозначение символа по его коду; @ - обозначение адреса переменной; $ - обозначение директивы компилятора или шестнадцатеричной константы; ^ - обозначение указателя. · Комментарии { } (* *) · Классификация типов данных:
· О совместимости типов данных. TP - язык со строгой типизацией данных. Это означает, что во время выполнения программы производится проверка справедливости (допустимости) выполняемых операций. Строгая типизация налагает определенные ограничения, которые объединены понятием совместимости типов данных. В основном программист должен сам предвидеть и обеспечивать явное преобразование типов данных там, где это необходимо. В TP явное преобразование типа данных осуществляется по схеме NewType(value), где значение value будет преобразовано к новому типу данных NewType. Однако существуют ситуации, когда происходит неявное преобразование типов. Эти ситуации реализуются в операциях, при присваивании, при передаче параметров и регламентированы законами совместимости. · В TP выделены три вида совместимости типов данных, и каждый вид предоставляет определенные возможности по совместному использованию данных. Два типа данных могут характеризоваться как одинаковые, совместимые по операциям (или просто совместимые) и совместимые по присваиванию. · Две переменные относятся к одинаковым (эквивалентным) типам, если описания переменных: а) ссылаются на одно и то же имя типа; б) ссылаются на различные имена типов (пусть Т1 и Т2), которые в разделе описания типов объявлены идентичными (TYPE T1=T2); · Бинарные операции могут быть выполнены над операндами, относящимися к совместимым (по операциям) типам данных. Два типа совместимы (по операциям), если: а) типы одинаковы (эквивалентны); б) оба типа целые или оба типа вещественные; в) один тип есть диапазон другого, или оба есть диапазоны от третьего; г) оба типа - строка (STRING); д) один тип - строка, а другой - ARRAY[1..n] of CHAR, или просто CHAR; е) оба типа - множества с совместимыми по операциям базовыми типами; ж) один тип - ссылочный, другой безтиповый указатель; з) оба типа - процедурные типы с одинаковым числом параметров, типы которых соответственно эквивалентны. Для функциональных типов необходима еще и эквивалентность типов результатов. и) Считается, что каждый объект типа "множество" совместим с пустым множеством и каждый объект типа "указатель" совместим с константой NIL. · Величина может быть присвоена переменной, если их типы совместимы по присваиванию. Выражение f типа F называется совместимым по присваиванию с переменной w типа W, если : а) F и W - эквивалентные, не файловые типы (и не содержат файловые типы в качестве полей); б) оба типа - совместимые ординарные типы и значения выражения f попадают в диапазон допустимых значений типа W; в) оба вещественные типы и значение выражения f допустимо для типа W; г) W - вещественный тип, F - целый; д) W - строка, F - либо строка, либо символ, либо массив символов; е) W и F - совместимые множественные типы, причем множество f целиком входит во множество W; ж) W и F - совместимые ссылочные типы или совместимые процедурные типы; з) W - процедурный тип, а f - имя процедуры или функции (параметры и типы должны быть согласованны); и) W и F - объектные типы, причем тип F потомок типа W, либо оба типа ссылочные на совместимые объектные типы. Хотя формулировки совместимости типов представляются довольно громоздкими, в их основе лежит простой здравый смысл. Разрешены действия, приводящие к естественному осмысленному результату без потери информации (или точности). Все операции округлений и усечений должны быть предусмотрены разработчиком программы и кодироваться явно. Лекция 55.1 Простые типы данныхЭлементы любого простого типа данных представляют собой упорядоченное множество. Следовательно, элементы простого типа могут быть связаны отношениями =, <>, >, >=, <=, <. Отношение между элементами простого типа является булевской величиной (относится к типу BOOLEAN). Все простые типы данных, кроме вещественных, относятся к ординальным типам данных. Для ординальных типов данных в языке TP определены операции, которые реализованы в функциях и процедурах: PRED (predecessor - предшествующий), SUCC (succeedent – последующий), ORD (ordinal – порядковое числительное), Dec (decrease – уменьшать),
НЕ нашли? Не то? Что вы ищете?
Inc (increase – уменьшать), SIZEOF (size of … - размер чего-либо) Функции PRED и SUCC получают в качестве аргумента значение ординального типа и возвращают предыдущий или последующий элементы этого типа. Считается ошибкой применение функции PRED к первому элементу, а функции SUCC к последнему элементу множества значений данного ординального типа. Функция ORD возвращает порядковый номеp элемента данного ординального типа, пеpвый элемент имеет номер 0, втоpой - 1 и т. д. Исключение представляют данные целого типа, поскольку ORD с целочисленным аргументом возвращает сам аргумент. Функцию ORD можно считать функцией пpеобpазования типа, поскольку для любого ординального аргумента результат будет целочисленный. Процедуры Dec (или Inc) позволяют увеличить (или уменьшить) аргумент на заданную величину. Например функция Dec(x, n) (или Inc (x, n)) увеличивает (или уменьшает) значение ординальной переменной x на n значений. Если параметр n опущен, то увеличение (уменьшение) происходит на 1. Для любого типа данных (в том числе и для простого) определена функция SIZEOF(X), которая возвращает размер памяти под аргумент X в байтах. В этой функции в качестве аргумента можно использовать имя константы, имя переменной или типа данных. 5.1.1 Перечислимый типПеречислимый ординальный тип описывается прямым перечислением константных значений этого типа в скобках через запятую. В качестве константных значений используются идентификаторы. Например: type week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); На множестве значений перечислимого типа определен естественный порядок Monday<Tuesday<Wednesday<…<Sunday. Если х и у – переменные var x, y:week_day; то можно переменным х и у присвоить значения, например: х:=Wednesday; y:=SUCC(x); применение функции ORD(Monday) – дает значение 0 целого типа, ORD(x) – 2 , ORD(y) – 3 ; 5.1.2 Интервальный типИнтервальный ординальный тип (или тип – диапазон) является подмножеством последовательных величин ранее определенного (или предопределенного) перечислимого типа (базового типа). Если тип week_day ранее определен, мы можем создать новый тип, например: TYPE work_day=Monday..Friday; На интервальном типе данных определены те же операции, что и на базовом. Однако программист должен гарантировать корректность операций на шаге выполнения. Если var D:work_day, то на шаге выполнения программы фрагмент D:=Friday; D:=SUCC(D) приведет к ошибке, поскольку для интервального типа work_day значение Friday является последним и не имеет последующего. program datas; type week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); dat=1..31; month=(January, Fabruary, March, April, May, June, July, August, September, October, November, December); year=1900..2100; attr_of_day=record w_d:week_day; d:dat; m:month; y:year end; var today:attr_of_day; kol:integer; function pred_week_day(w:week_day):week_day; begin if w=Monday then pred_week_day:=Sunday else pred_week_day:=pred(w) end; function pred_month(m:month):month; begin if m=January then pred_month:=December else pred_month:=pred(m) end; procedure pred_dat(var t:attr_of_day); begin if t. d=1 then begin t. m:=pred_month(t. m); if t. m=December then t. y:=t. y-1; case t. m of January, March, May, July, August, October, December:t. d:=31; Fabruary:if (t. y mod 4)=0 then t. d:=29 else t. d:=28; April, June, September, November:t. d:=30 end end else t. d:=t. d-1; t. w_d:=pred_week_day(today. w_d); end; begin today. w_d:=Monday; today. d:=2; today. m:=October; today. y:=2006; repeat pred_dat(today); if (today. y<=2000) and (today. w_d=Monday) and (today. d=13) then kol:=kol+1; until (today. y=1901) and (today. m=January) and (today. d=1); writeln('Kol= ',kol:4) end. 5.1.3 Целочисленные типыК целочисленным типам в TP относятся следующие предопределенные типы:
Для целочисленных типов применимы все функции, допустимые для ординальных типов – PRED, SUCC, DEC, INC. Определены унарные операции + и - ( сохранить знак числа, изменить знак числа), арифметические бинарные операции сложения (+), вычитания (-), умножения (*), деления нацело (div), взятия остатка при целочисленном делении (mod), деление (/), в результате последней операции получается вещественная величина. Кроме общих функций для ординальных типов данных, для целочисленных типов данных определены следующие: CHR(X) – возвращает символ (значение типа CHAR), код которого есть целое положительное число X (0 <= X <= 255). Логическая функция ODD(X) возвращает TRUE, если X – нечетно, в противном случае – FALSE. ABS(X) - абсолютная величина X. SQR(X) - квадрат величины X. В TP для данных типа INTEGER (и совместимых с INTEGER) определены побитовые операции: · n1 shl n2 - левый логический сдвиг двоичного кода числа n1 на n2 позиций. Слева двоичные разряды пропадают, справа добавляются нули. · n1 shr n2 - правый логический сдвиг. · not n – дополнение к двоичному коду целого числа n (цифра 0 заменяется на 1, 1 на 0). · n1 or n2 – логическое "или". · n1 and n2 – логическое "и". · n1 xor n2 – логическое исключающее "или". В побитовых операциях целые числа обрабатываются как строки двоичных цифр. Примеры использования побитовых операций приведены в таблицах.
5.1.4 Данные типа CHARДанные типа CHAR занимают один байт памяти. Константными значениями служат символы кодировки ASCII (Американский стандартный код обмена информации), содержащие, кроме латинских и русских (больших и малых) букв, цифр и используемых в TP специальных символов, различного рода служебные символы. Каждому символу соответствует некоторый код (целое число в диапазоне от 0 до 255), но не каждый символ имеет графическое представление (например, символы табуляции, символ возврата каретки и др.). Над данными типа CHAR можно производить операции, определенные для данных ординального типа. Функция ORD возвращает код аргумента. Если символ имеет графическое представление, например буква А, указать такой символ можно, заключив его изображение в апострофы – 'А'. Следующий оператор FOR C := 'A' TO 'Z' DO WRITELN('код символа', C, ' - ', ORD(C):3); позволяет получить коды всех символов таблицы ASCII в диапазоне от A до Z. Переменная C должна быть описана как CHAR. При использовании значений типа CHAR, не имеющих графического представления, можно применить форму записи символов по их коду с помощью префикса #, например #65 – то же самое, что 'A' (65 – код символа A). 5.1.5 Тип BOOLEANОрдинальный предопределенный тип BOOLEAN можно рассматривать как перечислимый тип с описанием TYPE BOOLEAN = (FALSE, TRUE); Переменные этого типа занимают один байт памяти. Операции AND, OR, XOR, NOT для операндов булевского типа понимаются компилятором как булевские операции умножения ("и"), сложения ("или"), "исключающего или" и "отрицания". Пусть A и B – выражения булевского типа, тогда булевские операции определяются следующим образом:
AND Логическое И OR Логическое ИЛИ XOR Логическое исключающее ИЛИ NOT Логическое НЕ Функция ORD дает значение 0, если аргумент имеет значение FALSE, и 1, если TRUE. 5.1.6 Вещественные типы данныхПростые типы вещественных данных не являются ординальными. С помощью этих типов данных в языке задается некоторое конечное подмножество рациональных чисел. Константы вещественного типа записываются в виде цепочки цифр с точкой, например: 0.0, 3.14, 17.4 (вещественная константа должна начинаться и заканчиваться цифрой). Константа может быть представлена в экспоненциальной форме, например, 1.0E+5, 0.01E-0, 3.14E. Кроме того, TP позволяет работать со следующими вещественными типами (табл.).
*Это форматы чисел, с которыми работает математический сопроцессор. Над данными вещественного типа в языке TP определены следующие операции и функции: 1. унарная операция + возвращает величину операнда; 2. унарная операция – меняет знак операнда; 3. бинарные операции +, - ,*, / возвращают результат выполнения соответствующих операций над вещественными числами; 4. отношения <, >, <=, >=, =, <> возвращают булевскую величину как результат сравнения операндов. 1. функция TRUNC(X) возвращает целую часть X; 2. функция ROUND(X) - округленное значение X до целого; 3. функция INT(X) - возвращает целую часть аргумента; 4. функция FRAC(X) - возвращает дробную часть аргумента; 5. функция PI - возвращает число 3.; 6. функция ABS(X) - абсолютную величину X; 7. функции SIN(X), COS(X), ARCTAN(X), LN(X), EXP(X), SQRT(X) и SQR(X) - возвращают значения синуса, косинуса, арктангенса, натурального логарифма, экспоненты, корня квадратного и квадрата аргумента X соответственно. Лекция 66.1 Структура программы на ПаскалеПрограмма на Паскале представляет собой обычный текст. Транслятор воспринимает этот текст как последовательность символов. На этапе лексического анализа текста выделяются слова (разделитель – пробел). Из слов составлены предложения (или операторы), разделителем служит символ «;» – «точка с запятой».
Начинается программа с необязательного оператора program <имя программы> – заголовка программы. Именем программы может быть любой уникальный в данной программе идентификатор. После заголовка следует секция описаний. Секция описаний состоит из разделов. Раздел описания имен модулей (в стандарте Паскаля этот раздел отсутствует). Раздел начинается заголовком uses, далее списком через запятую указываются имена используемых в программе модулей. Раздел описания меток. После заголовка раздела label записывается список используемых в программе меток. Раздел описания типов данных. После заголовка раздела type следуют операторы описания типов данных, созданных в программе пользователем. Операторы описания типа имеют следующий формат: <имя типа>=<описатель типа>. Имя типа – идентификатор, описатель типа – конструкция, определяющая данный тип. Раздел описания имен переменных начинается с заголовка var. Далее следуют операторы описания переменных, имеющие следующий формат: <список имен переменных через запятую>:<имя типа или описатель типа>. Раздел описания процедур и функций заголовка не имеет. Раздел содержит описания пользовательских процедур и функций. В стандарте Паскаля перечисленные разделы следуют в строго указанном порядке. В ТР разделы могут следовать в любом порядке и могут повторяться. Текст программы на Паскале завершает секция действий, представляющая собой составной оператор, – последовательность операторов, заключенная в логические скобки begin end. В секции действий описана последовательность действий, то есть алгоритм решения задачи. 6.2 Процедуры для стандартного ввода/выводаДля осуществления ввода и вывода данных стандартного типа используются предопределенные процедуры ввода и вывода READ, READLN, WRITE, WRITELN. Эти процедуры, кроме стандартных типов (целочисленные, вещественные, булевский, символьный), могут обслуживать диапазонные типы со стандартным базовым типом и данные типа string (строка). В качестве аргумента эти процедуры получают список элементов ввода или вывода. Список формируется как строка, в которой указываются через запятую имена элементов ввода или вывода, возможно со спецификацией (характеристикой). Спецификации служат для уточнения формата представления данных. Если спецификация не указана, используется формат, принятый по умолчанию для данного типа данных. Элемент ввода или вывода может принимать одну из следующих форм: E,{нет спецификации} E:LEN,{указана характеристика длины} E:LEN:ACCUR {указана характеристика длины и точности} Здесь Е – выражение одного из перечисленных выше типов, обслуживаемых процедурами ввода и вывода, LEN и ACCUR – выражения типа INTEGER. Характеристика точности (ACCUR) может применяться только для вывода данных вещественного типа. Использование характеристик при выдаче данных в текстовый файл (или на экран монитора) показано на примерах: VAR I:INTEGER; C:CHAR; PI:REAL; B:BOOLEAN; A, S:STRING; I:=1234; C:='a'; PI:=3.14159; B:=TRUE; S:='ABCD'; A:='ABCD'; Обращение к процедуре результат WRITE(I:6); ..1234 WRITE(I:1); 1234 WRITE(I); .......1234 WRITE(C:6); .....a WRITE(PI:10); .3.142E+00 WRITE(PI); .3.E+00 WRITE(PI:10:4); ....3.1416 WRITE(B:10); ......TRUE WRITE(B:2); .T WRITE(S:6); ..ABCD WRITE(S:2); AB WRITE(S); ABCD Процедура WRITELN, в отличие от WRITE, после записи данных в файл осуществляет переход на новую логическую запись (строку) текстового файла. Процедура READLN, в отличие от READ, после выполнения операции ввода данных для всего списка элементов ввода, осуществляет переход на следующую логическую запись (строку) текстового файла чтения. 6.3 Массивы. Регулярный типМассив – структура данных, задающая в памяти ЭВМ определенное количество однотипных записей. Тип данных массив в классификации типов данных языка Паскаль относят к базовым структурам и называют регулярным типом данных. Описатель массива ARRAY[<индексный тип>] OF <базовый тип> <индексный тип> - имя или описатель индексного типа, <базовый тип> - имя или описатель базового типа. В качестве базового типа можно использовать любой тип данных. Индексный тип – любой ординальный тип данных, кроме LONGINT. Индексный тип задает количество элементов массива (размер массива) и тип значений индексов. Вот примеры описателей массивов: ARRAY[1..10] OF REAL – массивы этого типа будут состоять из 10 элементов действительного типа, индексы – целые числа от 1 до 10. ARRAY[CHAR] OF INTEGER – массивы этого типа будут состоять из 256 целочисленных элементов, индексы – символы кодовой таблицы от #0 до #255. ARRAY[’A’..’Z’] OF INTEGER – массивы этого типа будут состоять из 26 целочисленных элементов, индексы – заглавные буквы латинского алфавита. В качестве описателя базового типа может быть использован описатель массива. Вот пример описаний: TYPE I1=<индексный тип 1>; I2=<индексный тип 2>; Ik=<индексный тип k>; BAZ=<базовый тип>; MASS=ARRAY[I1] OF ARRAY[I2] OF BAZ В Паскале предусмотрена более компактная запись последнего оператора: MASS=ARRAY[I1,I2] OF BAZ Переменная типа MASS будет представлять собой двумерный массив (массив массивов). В описании VAR M:ARRAY[I1,I2, …, Ik] OF BAZ массив М объявлен как многомерный (k – мерный) массив. Количество индексных типов в описании массива – размерность массива. Доступ к элементам массива осуществляется с помощью селектора [ ] – квадратные скобки. В квадратных скобках указывают значение (выражение) индексного типа. Если переменные x1,x2, …, xk описаны так: var x1:I1; x2:I2; …; xk:Ik, то M – массив ARRAY[I1,I2, …, Ik] OF BAZ, M[x1] – массив ARRAY[I2, …, Ik] OF BAZ, M[x1][x2] – массив ARRAY[ …, Ik] OF BAZ, … M[x1][x2] … [xk] – данное базового типа BAZ, Допустимы сокращенные формы записи: M[x1,x2],…, M[x1,x2, …, xk], соответственно. Приведем примеры описаний и использования массивов TYPE M10=ARRAY[1..10] OF REAL; IND=-5..5; MIND=ARRAY[IND] OF REAL; {тип - массив из 11 элементов} MINDM10=ARRAY[IND] OF M10; {тип - двумерный массив} week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); dat=1..31; month=(January, Fabruary, March, April, May, June, July, August, September, October, November, December); VAR X:M10;{массив} K:IND;{переменная} Y:ARRAY[1..10] OF REAL; V:MIND; MM:MINDM10;{двумерный массив} Mdat:ARRAY[month] OF dat; Mweek_day:ARRAY[month, dat] OF week_day; В этих условиях доступ к элементам иллюстрируется операторами: K:=0; V[K]:=17.0; X[1]:= 22.5; Y[5]:=X[1]; MM[-3, 1]:= 0;{то же самое, что MM[-3][1]:= 0;} Mdat[January]:=31; Mweek_day[October, 9]:= Monday; В TP можно выполнить такое присваивание MM[0]:=X, если все компоненты массива V инициализированы (одинаковые типы данных). Нельзя выполнить присваивание X:=Y, поскольку переменные относятся к несовместимым по присваиванию типам данных. 6.4 Для работы с массивами – шаблоныШаблон 1. Ввод-вывод одномерного массива. program …; const NN=100;{Максимальное число элементов} … type MM=array [1..NN]of real; {Новый тип данных - массив} … var M:MM; k, i:integer; … begin {Ввод массива} writeln(‘Введите кол-во элементов массива (не более ',NN:1,’)’);
| X or Y | 15 |
· Специальные символы обозначают следующие элементы языка: + - * / - арифметические операции; + - * - операции над множествами; = < > <= >= <> - отношения; := - присваивание; . - конец программы, составной идентификатор, селектор поля записи; , - разделитель элементов списка; : - используется при описаниях; ; - разделитель операторов языка; .. - диапазон; [ ] илиселектор элемента массива; { } или (* *) - скобки для выделения комментариев; + - операция конкатенации строк # - обозначение символа по его коду; @ - обозначение адреса переменной; $ - обозначение директивы компилятора или шестнадцатеричной константы; ^ - обозначение указателя. · Комментарии { } (* *) · Классификация типов данных:
· О совместимости типов данных. TP - язык со строгой типизацией данных. Это означает, что во время выполнения программы производится проверка справедливости (допустимости) выполняемых операций. Строгая типизация налагает определенные ограничения, которые объединены понятием совместимости типов данных. В основном программист должен сам предвидеть и обеспечивать явное преобразование типов данных там, где это необходимо. В TP явное преобразование типа данных осуществляется по схеме NewType(value), где значение value будет преобразовано к новому типу данных NewType. Однако существуют ситуации, когда происходит неявное преобразование типов. Эти ситуации реализуются в операциях, при присваивании, при передаче параметров и регламентированы законами совместимости. · В TP выделены три вида совместимости типов данных, и каждый вид предоставляет определенные возможности по совместному использованию данных. Два типа данных могут характеризоваться как одинаковые, совместимые по операциям (или просто совместимые) и совместимые по присваиванию. · Две переменные относятся к одинаковым (эквивалентным) типам, если описания переменных: а) ссылаются на одно и то же имя типа; б) ссылаются на различные имена типов (пусть Т1 и Т2), которые в разделе описания типов объявлены идентичными (TYPE T1=T2); · Бинарные операции могут быть выполнены над операндами, относящимися к совместимым (по операциям) типам данных. Два типа совместимы (по операциям), если: а) типы одинаковы (эквивалентны); б) оба типа целые или оба типа вещественные; в) один тип есть диапазон другого, или оба есть диапазоны от третьего; г) оба типа - строка (STRING); д) один тип - строка, а другой - ARRAY[1..n] of CHAR, или просто CHAR; е) оба типа - множества с совместимыми по операциям базовыми типами; ж) один тип - ссылочный, другой безтиповый указатель; з) оба типа - процедурные типы с одинаковым числом параметров, типы которых соответственно эквивалентны. Для функциональных типов необходима еще и эквивалентность типов результатов. и) Считается, что каждый объект типа "множество" совместим с пустым множеством и каждый объект типа "указатель" совместим с константой NIL. · Величина может быть присвоена переменной, если их типы совместимы по присваиванию. Выражение f типа F называется совместимым по присваиванию с переменной w типа W, если : а) F и W - эквивалентные, не файловые типы (и не содержат файловые типы в качестве полей); б) оба типа - совместимые ординарные типы и значения выражения f попадают в диапазон допустимых значений типа W; в) оба вещественные типы и значение выражения f допустимо для типа W; г) W - вещественный тип, F - целый; д) W - строка, F - либо строка, либо символ, либо массив символов; е) W и F - совместимые множественные типы, причем множество f целиком входит во множество W; ж) W и F - совместимые ссылочные типы или совместимые процедурные типы; з) W - процедурный тип, а f - имя процедуры или функции (параметры и типы должны быть согласованны); и) W и F - объектные типы, причем тип F потомок типа W, либо оба типа ссылочные на совместимые объектные типы. Хотя формулировки совместимости типов представляются довольно громоздкими, в их основе лежит простой здравый смысл. Разрешены действия, приводящие к естественному осмысленному результату без потери информации (или точности). Все операции округлений и усечений должны быть предусмотрены разработчиком программы и кодироваться явно. Лекция 55.1 Простые типы данныхЭлементы любого простого типа данных представляют собой упорядоченное множество. Следовательно, элементы простого типа могут быть связаны отношениями =, <>, >, >=, <=, <. Отношение между элементами простого типа является булевской величиной (относится к типу BOOLEAN). Все простые типы данных, кроме вещественных, относятся к ординальным типам данных. Для ординальных типов данных в языке TP определены операции, которые реализованы в функциях и процедурах: PRED (predecessor - предшествующий), SUCC (succeedent – последующий), ORD (ordinal – порядковое числительное), Dec (decrease – уменьшать),
НЕ нашли? Не то? Что вы ищете?
Inc (increase – уменьшать), SIZEOF (size of … - размер чего-либо) Функции PRED и SUCC получают в качестве аргумента значение ординального типа и возвращают предыдущий или последующий элементы этого типа. Считается ошибкой применение функции PRED к первому элементу, а функции SUCC к последнему элементу множества значений данного ординального типа. Функция ORD возвращает порядковый номеp элемента данного ординального типа, пеpвый элемент имеет номер 0, втоpой - 1 и т. д. Исключение представляют данные целого типа, поскольку ORD с целочисленным аргументом возвращает сам аргумент. Функцию ORD можно считать функцией пpеобpазования типа, поскольку для любого ординального аргумента результат будет целочисленный. Процедуры Dec (или Inc) позволяют увеличить (или уменьшить) аргумент на заданную величину. Например функция Dec(x, n) (или Inc (x, n)) увеличивает (или уменьшает) значение ординальной переменной x на n значений. Если параметр n опущен, то увеличение (уменьшение) происходит на 1. Для любого типа данных (в том числе и для простого) определена функция SIZEOF(X), которая возвращает размер памяти под аргумент X в байтах. В этой функции в качестве аргумента можно использовать имя константы, имя переменной или типа данных. 5.1.1 Перечислимый типПеречислимый ординальный тип описывается прямым перечислением константных значений этого типа в скобках через запятую. В качестве константных значений используются идентификаторы. Например: type week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); На множестве значений перечислимого типа определен естественный порядок Monday<Tuesday<Wednesday<…<Sunday. Если х и у – переменные var x, y:week_day; то можно переменным х и у присвоить значения, например: х:=Wednesday; y:=SUCC(x); применение функции ORD(Monday) – дает значение 0 целого типа, ORD(x) – 2 , ORD(y) – 3 ; 5.1.2 Интервальный типИнтервальный ординальный тип (или тип – диапазон) является подмножеством последовательных величин ранее определенного (или предопределенного) перечислимого типа (базового типа). Если тип week_day ранее определен, мы можем создать новый тип, например: TYPE work_day=Monday..Friday; На интервальном типе данных определены те же операции, что и на базовом. Однако программист должен гарантировать корректность операций на шаге выполнения. Если var D:work_day, то на шаге выполнения программы фрагмент D:=Friday; D:=SUCC(D) приведет к ошибке, поскольку для интервального типа work_day значение Friday является последним и не имеет последующего. program datas; type week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); dat=1..31; month=(January, Fabruary, March, April, May, June, July, August, September, October, November, December); year=1900..2100; attr_of_day=record w_d:week_day; d:dat; m:month; y:year end; var today:attr_of_day; kol:integer; function pred_week_day(w:week_day):week_day; begin if w=Monday then pred_week_day:=Sunday else pred_week_day:=pred(w) end; function pred_month(m:month):month; begin if m=January then pred_month:=December else pred_month:=pred(m) end; procedure pred_dat(var t:attr_of_day); begin if t. d=1 then begin t. m:=pred_month(t. m); if t. m=December then t. y:=t. y-1; case t. m of January, March, May, July, August, October, December:t. d:=31; Fabruary:if (t. y mod 4)=0 then t. d:=29 else t. d:=28; April, June, September, November:t. d:=30 end end else t. d:=t. d-1; t. w_d:=pred_week_day(today. w_d); end; begin today. w_d:=Monday; today. d:=2; today. m:=October; today. y:=2006; repeat pred_dat(today); if (today. y<=2000) and (today. w_d=Monday) and (today. d=13) then kol:=kol+1; until (today. y=1901) and (today. m=January) and (today. d=1); writeln('Kol= ',kol:4) end. 5.1.3 Целочисленные типыК целочисленным типам в TP относятся следующие предопределенные типы:
Для целочисленных типов применимы все функции, допустимые для ординальных типов – PRED, SUCC, DEC, INC. Определены унарные операции + и - ( сохранить знак числа, изменить знак числа), арифметические бинарные операции сложения (+), вычитания (-), умножения (*), деления нацело (div), взятия остатка при целочисленном делении (mod), деление (/), в результате последней операции получается вещественная величина. Кроме общих функций для ординальных типов данных, для целочисленных типов данных определены следующие: CHR(X) – возвращает символ (значение типа CHAR), код которого есть целое положительное число X (0 <= X <= 255). Логическая функция ODD(X) возвращает TRUE, если X – нечетно, в противном случае – FALSE. ABS(X) - абсолютная величина X. SQR(X) - квадрат величины X. В TP для данных типа INTEGER (и совместимых с INTEGER) определены побитовые операции: · n1 shl n2 - левый логический сдвиг двоичного кода числа n1 на n2 позиций. Слева двоичные разряды пропадают, справа добавляются нули. · n1 shr n2 - правый логический сдвиг. · not n – дополнение к двоичному коду целого числа n (цифра 0 заменяется на 1, 1 на 0). · n1 or n2 – логическое "или". · n1 and n2 – логическое "и". · n1 xor n2 – логическое исключающее "или". В побитовых операциях целые числа обрабатываются как строки двоичных цифр. Примеры использования побитовых операций приведены в таблицах.
5.1.4 Данные типа CHARДанные типа CHAR занимают один байт памяти. Константными значениями служат символы кодировки ASCII (Американский стандартный код обмена информации), содержащие, кроме латинских и русских (больших и малых) букв, цифр и используемых в TP специальных символов, различного рода служебные символы. Каждому символу соответствует некоторый код (целое число в диапазоне от 0 до 255), но не каждый символ имеет графическое представление (например, символы табуляции, символ возврата каретки и др.). Над данными типа CHAR можно производить операции, определенные для данных ординального типа. Функция ORD возвращает код аргумента. Если символ имеет графическое представление, например буква А, указать такой символ можно, заключив его изображение в апострофы – 'А'. Следующий оператор FOR C := 'A' TO 'Z' DO WRITELN('код символа', C, ' - ', ORD(C):3); позволяет получить коды всех символов таблицы ASCII в диапазоне от A до Z. Переменная C должна быть описана как CHAR. При использовании значений типа CHAR, не имеющих графического представления, можно применить форму записи символов по их коду с помощью префикса #, например #65 – то же самое, что 'A' (65 – код символа A). 5.1.5 Тип BOOLEANОрдинальный предопределенный тип BOOLEAN можно рассматривать как перечислимый тип с описанием TYPE BOOLEAN = (FALSE, TRUE); Переменные этого типа занимают один байт памяти. Операции AND, OR, XOR, NOT для операндов булевского типа понимаются компилятором как булевские операции умножения ("и"), сложения ("или"), "исключающего или" и "отрицания". Пусть A и B – выражения булевского типа, тогда булевские операции определяются следующим образом:
AND Логическое И OR Логическое ИЛИ XOR Логическое исключающее ИЛИ NOT Логическое НЕ Функция ORD дает значение 0, если аргумент имеет значение FALSE, и 1, если TRUE. 5.1.6 Вещественные типы данныхПростые типы вещественных данных не являются ординальными. С помощью этих типов данных в языке задается некоторое конечное подмножество рациональных чисел. Константы вещественного типа записываются в виде цепочки цифр с точкой, например: 0.0, 3.14, 17.4 (вещественная константа должна начинаться и заканчиваться цифрой). Константа может быть представлена в экспоненциальной форме, например, 1.0E+5, 0.01E-0, 3.14E. Кроме того, TP позволяет работать со следующими вещественными типами (табл.).
*Это форматы чисел, с которыми работает математический сопроцессор. Над данными вещественного типа в языке TP определены следующие операции и функции: 1. унарная операция + возвращает величину операнда; 2. унарная операция – меняет знак операнда; 3. бинарные операции +, - ,*, / возвращают результат выполнения соответствующих операций над вещественными числами; 4. отношения <, >, <=, >=, =, <> возвращают булевскую величину как результат сравнения операндов. 1. функция TRUNC(X) возвращает целую часть X; 2. функция ROUND(X) - округленное значение X до целого; 3. функция INT(X) - возвращает целую часть аргумента; 4. функция FRAC(X) - возвращает дробную часть аргумента; 5. функция PI - возвращает число 3.; 6. функция ABS(X) - абсолютную величину X; 7. функции SIN(X), COS(X), ARCTAN(X), LN(X), EXP(X), SQRT(X) и SQR(X) - возвращают значения синуса, косинуса, арктангенса, натурального логарифма, экспоненты, корня квадратного и квадрата аргумента X соответственно. Лекция 66.1 Структура программы на ПаскалеПрограмма на Паскале представляет собой обычный текст. Транслятор воспринимает этот текст как последовательность символов. На этапе лексического анализа текста выделяются слова (разделитель – пробел). Из слов составлены предложения (или операторы), разделителем служит символ «;» – «точка с запятой».
Начинается программа с необязательного оператора program <имя программы> – заголовка программы. Именем программы может быть любой уникальный в данной программе идентификатор. После заголовка следует секция описаний. Секция описаний состоит из разделов. Раздел описания имен модулей (в стандарте Паскаля этот раздел отсутствует). Раздел начинается заголовком uses, далее списком через запятую указываются имена используемых в программе модулей. Раздел описания меток. После заголовка раздела label записывается список используемых в программе меток. Раздел описания типов данных. После заголовка раздела type следуют операторы описания типов данных, созданных в программе пользователем. Операторы описания типа имеют следующий формат: <имя типа>=<описатель типа>. Имя типа – идентификатор, описатель типа – конструкция, определяющая данный тип. Раздел описания имен переменных начинается с заголовка var. Далее следуют операторы описания переменных, имеющие следующий формат: <список имен переменных через запятую>:<имя типа или описатель типа>. Раздел описания процедур и функций заголовка не имеет. Раздел содержит описания пользовательских процедур и функций. В стандарте Паскаля перечисленные разделы следуют в строго указанном порядке. В ТР разделы могут следовать в любом порядке и могут повторяться. Текст программы на Паскале завершает секция действий, представляющая собой составной оператор, – последовательность операторов, заключенная в логические скобки begin end. В секции действий описана последовательность действий, то есть алгоритм решения задачи. 6.2 Процедуры для стандартного ввода/выводаДля осуществления ввода и вывода данных стандартного типа используются предопределенные процедуры ввода и вывода READ, READLN, WRITE, WRITELN. Эти процедуры, кроме стандартных типов (целочисленные, вещественные, булевский, символьный), могут обслуживать диапазонные типы со стандартным базовым типом и данные типа string (строка). В качестве аргумента эти процедуры получают список элементов ввода или вывода. Список формируется как строка, в которой указываются через запятую имена элементов ввода или вывода, возможно со спецификацией (характеристикой). Спецификации служат для уточнения формата представления данных. Если спецификация не указана, используется формат, принятый по умолчанию для данного типа данных. Элемент ввода или вывода может принимать одну из следующих форм: E,{нет спецификации} E:LEN,{указана характеристика длины} E:LEN:ACCUR {указана характеристика длины и точности} Здесь Е – выражение одного из перечисленных выше типов, обслуживаемых процедурами ввода и вывода, LEN и ACCUR – выражения типа INTEGER. Характеристика точности (ACCUR) может применяться только для вывода данных вещественного типа. Использование характеристик при выдаче данных в текстовый файл (или на экран монитора) показано на примерах: VAR I:INTEGER; C:CHAR; PI:REAL; B:BOOLEAN; A, S:STRING; I:=1234; C:='a'; PI:=3.14159; B:=TRUE; S:='ABCD'; A:='ABCD'; Обращение к процедуре результат WRITE(I:6); ..1234 WRITE(I:1); 1234 WRITE(I); .......1234 WRITE(C:6); .....a WRITE(PI:10); .3.142E+00 WRITE(PI); .3.E+00 WRITE(PI:10:4); ....3.1416 WRITE(B:10); ......TRUE WRITE(B:2); .T WRITE(S:6); ..ABCD WRITE(S:2); AB WRITE(S); ABCD Процедура WRITELN, в отличие от WRITE, после записи данных в файл осуществляет переход на новую логическую запись (строку) текстового файла. Процедура READLN, в отличие от READ, после выполнения операции ввода данных для всего списка элементов ввода, осуществляет переход на следующую логическую запись (строку) текстового файла чтения. 6.3 Массивы. Регулярный типМассив – структура данных, задающая в памяти ЭВМ определенное количество однотипных записей. Тип данных массив в классификации типов данных языка Паскаль относят к базовым структурам и называют регулярным типом данных. Описатель массива ARRAY[<индексный тип>] OF <базовый тип> <индексный тип> - имя или описатель индексного типа, <базовый тип> - имя или описатель базового типа. В качестве базового типа можно использовать любой тип данных. Индексный тип – любой ординальный тип данных, кроме LONGINT. Индексный тип задает количество элементов массива (размер массива) и тип значений индексов. Вот примеры описателей массивов: ARRAY[1..10] OF REAL – массивы этого типа будут состоять из 10 элементов действительного типа, индексы – целые числа от 1 до 10. ARRAY[CHAR] OF INTEGER – массивы этого типа будут состоять из 256 целочисленных элементов, индексы – символы кодовой таблицы от #0 до #255. ARRAY[’A’..’Z’] OF INTEGER – массивы этого типа будут состоять из 26 целочисленных элементов, индексы – заглавные буквы латинского алфавита. В качестве описателя базового типа может быть использован описатель массива. Вот пример описаний: TYPE I1=<индексный тип 1>; I2=<индексный тип 2>; Ik=<индексный тип k>; BAZ=<базовый тип>; MASS=ARRAY[I1] OF ARRAY[I2] OF BAZ В Паскале предусмотрена более компактная запись последнего оператора: MASS=ARRAY[I1,I2] OF BAZ Переменная типа MASS будет представлять собой двумерный массив (массив массивов). В описании VAR M:ARRAY[I1,I2, …, Ik] OF BAZ массив М объявлен как многомерный (k – мерный) массив. Количество индексных типов в описании массива – размерность массива. Доступ к элементам массива осуществляется с помощью селектора [ ] – квадратные скобки. В квадратных скобках указывают значение (выражение) индексного типа. Если переменные x1,x2, …, xk описаны так: var x1:I1; x2:I2; …; xk:Ik, то M – массив ARRAY[I1,I2, …, Ik] OF BAZ, M[x1] – массив ARRAY[I2, …, Ik] OF BAZ, M[x1][x2] – массив ARRAY[ …, Ik] OF BAZ, … M[x1][x2] … [xk] – данное базового типа BAZ, Допустимы сокращенные формы записи: M[x1,x2],…, M[x1,x2, …, xk], соответственно. Приведем примеры описаний и использования массивов TYPE M10=ARRAY[1..10] OF REAL; IND=-5..5; MIND=ARRAY[IND] OF REAL; {тип - массив из 11 элементов} MINDM10=ARRAY[IND] OF M10; {тип - двумерный массив} week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); dat=1..31; month=(January, Fabruary, March, April, May, June, July, August, September, October, November, December); VAR X:M10;{массив} K:IND;{переменная} Y:ARRAY[1..10] OF REAL; V:MIND; MM:MINDM10;{двумерный массив} Mdat:ARRAY[month] OF dat; Mweek_day:ARRAY[month, dat] OF week_day; В этих условиях доступ к элементам иллюстрируется операторами: K:=0; V[K]:=17.0; X[1]:= 22.5; Y[5]:=X[1]; MM[-3, 1]:= 0;{то же самое, что MM[-3][1]:= 0;} Mdat[January]:=31; Mweek_day[October, 9]:= Monday; В TP можно выполнить такое присваивание MM[0]:=X, если все компоненты массива V инициализированы (одинаковые типы данных). Нельзя выполнить присваивание X:=Y, поскольку переменные относятся к несовместимым по присваиванию типам данных. 6.4 Для работы с массивами – шаблоныШаблон 1. Ввод-вывод одномерного массива. program …; const NN=100;{Максимальное число элементов} … type MM=array [1..NN]of real; {Новый тип данных - массив} … var M:MM; k, i:integer; … begin {Ввод массива} writeln(‘Введите кол-во элементов массива (не более ',NN:1,’)’);
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5 | $ | 15 |
· Специальные символы обозначают следующие элементы языка: + - * / - арифметические операции; + - * - операции над множествами; = < > <= >= <> - отношения; := - присваивание; . - конец программы, составной идентификатор, селектор поля записи; , - разделитель элементов списка; : - используется при описаниях; ; - разделитель операторов языка; .. - диапазон; [ ] илиселектор элемента массива; { } или (* *) - скобки для выделения комментариев; + - операция конкатенации строк # - обозначение символа по его коду; @ - обозначение адреса переменной; $ - обозначение директивы компилятора или шестнадцатеричной константы; ^ - обозначение указателя. · Комментарии { } (* *) · Классификация типов данных:
· О совместимости типов данных. TP - язык со строгой типизацией данных. Это означает, что во время выполнения программы производится проверка справедливости (допустимости) выполняемых операций. Строгая типизация налагает определенные ограничения, которые объединены понятием совместимости типов данных. В основном программист должен сам предвидеть и обеспечивать явное преобразование типов данных там, где это необходимо. В TP явное преобразование типа данных осуществляется по схеме NewType(value), где значение value будет преобразовано к новому типу данных NewType. Однако существуют ситуации, когда происходит неявное преобразование типов. Эти ситуации реализуются в операциях, при присваивании, при передаче параметров и регламентированы законами совместимости. · В TP выделены три вида совместимости типов данных, и каждый вид предоставляет определенные возможности по совместному использованию данных. Два типа данных могут характеризоваться как одинаковые, совместимые по операциям (или просто совместимые) и совместимые по присваиванию. · Две переменные относятся к одинаковым (эквивалентным) типам, если описания переменных: а) ссылаются на одно и то же имя типа; б) ссылаются на различные имена типов (пусть Т1 и Т2), которые в разделе описания типов объявлены идентичными (TYPE T1=T2); · Бинарные операции могут быть выполнены над операндами, относящимися к совместимым (по операциям) типам данных. Два типа совместимы (по операциям), если: а) типы одинаковы (эквивалентны); б) оба типа целые или оба типа вещественные; в) один тип есть диапазон другого, или оба есть диапазоны от третьего; г) оба типа - строка (STRING); д) один тип - строка, а другой - ARRAY[1..n] of CHAR, или просто CHAR; е) оба типа - множества с совместимыми по операциям базовыми типами; ж) один тип - ссылочный, другой безтиповый указатель; з) оба типа - процедурные типы с одинаковым числом параметров, типы которых соответственно эквивалентны. Для функциональных типов необходима еще и эквивалентность типов результатов. и) Считается, что каждый объект типа "множество" совместим с пустым множеством и каждый объект типа "указатель" совместим с константой NIL. · Величина может быть присвоена переменной, если их типы совместимы по присваиванию. Выражение f типа F называется совместимым по присваиванию с переменной w типа W, если : а) F и W - эквивалентные, не файловые типы (и не содержат файловые типы в качестве полей); б) оба типа - совместимые ординарные типы и значения выражения f попадают в диапазон допустимых значений типа W; в) оба вещественные типы и значение выражения f допустимо для типа W; г) W - вещественный тип, F - целый; д) W - строка, F - либо строка, либо символ, либо массив символов; е) W и F - совместимые множественные типы, причем множество f целиком входит во множество W; ж) W и F - совместимые ссылочные типы или совместимые процедурные типы; з) W - процедурный тип, а f - имя процедуры или функции (параметры и типы должны быть согласованны); и) W и F - объектные типы, причем тип F потомок типа W, либо оба типа ссылочные на совместимые объектные типы. Хотя формулировки совместимости типов представляются довольно громоздкими, в их основе лежит простой здравый смысл. Разрешены действия, приводящие к естественному осмысленному результату без потери информации (или точности). Все операции округлений и усечений должны быть предусмотрены разработчиком программы и кодироваться явно. Лекция 55.1 Простые типы данныхЭлементы любого простого типа данных представляют собой упорядоченное множество. Следовательно, элементы простого типа могут быть связаны отношениями =, <>, >, >=, <=, <. Отношение между элементами простого типа является булевской величиной (относится к типу BOOLEAN). Все простые типы данных, кроме вещественных, относятся к ординальным типам данных. Для ординальных типов данных в языке TP определены операции, которые реализованы в функциях и процедурах: PRED (predecessor - предшествующий), SUCC (succeedent – последующий), ORD (ordinal – порядковое числительное), Dec (decrease – уменьшать),
НЕ нашли? Не то? Что вы ищете?
Inc (increase – уменьшать), SIZEOF (size of … - размер чего-либо) Функции PRED и SUCC получают в качестве аргумента значение ординального типа и возвращают предыдущий или последующий элементы этого типа. Считается ошибкой применение функции PRED к первому элементу, а функции SUCC к последнему элементу множества значений данного ординального типа. Функция ORD возвращает порядковый номеp элемента данного ординального типа, пеpвый элемент имеет номер 0, втоpой - 1 и т. д. Исключение представляют данные целого типа, поскольку ORD с целочисленным аргументом возвращает сам аргумент. Функцию ORD можно считать функцией пpеобpазования типа, поскольку для любого ординального аргумента результат будет целочисленный. Процедуры Dec (или Inc) позволяют увеличить (или уменьшить) аргумент на заданную величину. Например функция Dec(x, n) (или Inc (x, n)) увеличивает (или уменьшает) значение ординальной переменной x на n значений. Если параметр n опущен, то увеличение (уменьшение) происходит на 1. Для любого типа данных (в том числе и для простого) определена функция SIZEOF(X), которая возвращает размер памяти под аргумент X в байтах. В этой функции в качестве аргумента можно использовать имя константы, имя переменной или типа данных. 5.1.1 Перечислимый типПеречислимый ординальный тип описывается прямым перечислением константных значений этого типа в скобках через запятую. В качестве константных значений используются идентификаторы. Например: type week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); На множестве значений перечислимого типа определен естественный порядок Monday<Tuesday<Wednesday<…<Sunday. Если х и у – переменные var x, y:week_day; то можно переменным х и у присвоить значения, например: х:=Wednesday; y:=SUCC(x); применение функции ORD(Monday) – дает значение 0 целого типа, ORD(x) – 2 , ORD(y) – 3 ; 5.1.2 Интервальный типИнтервальный ординальный тип (или тип – диапазон) является подмножеством последовательных величин ранее определенного (или предопределенного) перечислимого типа (базового типа). Если тип week_day ранее определен, мы можем создать новый тип, например: TYPE work_day=Monday..Friday; На интервальном типе данных определены те же операции, что и на базовом. Однако программист должен гарантировать корректность операций на шаге выполнения. Если var D:work_day, то на шаге выполнения программы фрагмент D:=Friday; D:=SUCC(D) приведет к ошибке, поскольку для интервального типа work_day значение Friday является последним и не имеет последующего. program datas; type week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); dat=1..31; month=(January, Fabruary, March, April, May, June, July, August, September, October, November, December); year=1900..2100; attr_of_day=record w_d:week_day; d:dat; m:month; y:year end; var today:attr_of_day; kol:integer; function pred_week_day(w:week_day):week_day; begin if w=Monday then pred_week_day:=Sunday else pred_week_day:=pred(w) end; function pred_month(m:month):month; begin if m=January then pred_month:=December else pred_month:=pred(m) end; procedure pred_dat(var t:attr_of_day); begin if t. d=1 then begin t. m:=pred_month(t. m); if t. m=December then t. y:=t. y-1; case t. m of January, March, May, July, August, October, December:t. d:=31; Fabruary:if (t. y mod 4)=0 then t. d:=29 else t. d:=28; April, June, September, November:t. d:=30 end end else t. d:=t. d-1; t. w_d:=pred_week_day(today. w_d); end; begin today. w_d:=Monday; today. d:=2; today. m:=October; today. y:=2006; repeat pred_dat(today); if (today. y<=2000) and (today. w_d=Monday) and (today. d=13) then kol:=kol+1; until (today. y=1901) and (today. m=January) and (today. d=1); writeln('Kol= ',kol:4) end. 5.1.3 Целочисленные типыК целочисленным типам в TP относятся следующие предопределенные типы:
Для целочисленных типов применимы все функции, допустимые для ординальных типов – PRED, SUCC, DEC, INC. Определены унарные операции + и - ( сохранить знак числа, изменить знак числа), арифметические бинарные операции сложения (+), вычитания (-), умножения (*), деления нацело (div), взятия остатка при целочисленном делении (mod), деление (/), в результате последней операции получается вещественная величина. Кроме общих функций для ординальных типов данных, для целочисленных типов данных определены следующие: CHR(X) – возвращает символ (значение типа CHAR), код которого есть целое положительное число X (0 <= X <= 255). Логическая функция ODD(X) возвращает TRUE, если X – нечетно, в противном случае – FALSE. ABS(X) - абсолютная величина X. SQR(X) - квадрат величины X. В TP для данных типа INTEGER (и совместимых с INTEGER) определены побитовые операции: · n1 shl n2 - левый логический сдвиг двоичного кода числа n1 на n2 позиций. Слева двоичные разряды пропадают, справа добавляются нули. · n1 shr n2 - правый логический сдвиг. · not n – дополнение к двоичному коду целого числа n (цифра 0 заменяется на 1, 1 на 0). · n1 or n2 – логическое "или". · n1 and n2 – логическое "и". · n1 xor n2 – логическое исключающее "или". В побитовых операциях целые числа обрабатываются как строки двоичных цифр. Примеры использования побитовых операций приведены в таблицах.
5.1.4 Данные типа CHARДанные типа CHAR занимают один байт памяти. Константными значениями служат символы кодировки ASCII (Американский стандартный код обмена информации), содержащие, кроме латинских и русских (больших и малых) букв, цифр и используемых в TP специальных символов, различного рода служебные символы. Каждому символу соответствует некоторый код (целое число в диапазоне от 0 до 255), но не каждый символ имеет графическое представление (например, символы табуляции, символ возврата каретки и др.). Над данными типа CHAR можно производить операции, определенные для данных ординального типа. Функция ORD возвращает код аргумента. Если символ имеет графическое представление, например буква А, указать такой символ можно, заключив его изображение в апострофы – 'А'. Следующий оператор FOR C := 'A' TO 'Z' DO WRITELN('код символа', C, ' - ', ORD(C):3); позволяет получить коды всех символов таблицы ASCII в диапазоне от A до Z. Переменная C должна быть описана как CHAR. При использовании значений типа CHAR, не имеющих графического представления, можно применить форму записи символов по их коду с помощью префикса #, например #65 – то же самое, что 'A' (65 – код символа A). 5.1.5 Тип BOOLEANОрдинальный предопределенный тип BOOLEAN можно рассматривать как перечислимый тип с описанием TYPE BOOLEAN = (FALSE, TRUE); Переменные этого типа занимают один байт памяти. Операции AND, OR, XOR, NOT для операндов булевского типа понимаются компилятором как булевские операции умножения ("и"), сложения ("или"), "исключающего или" и "отрицания". Пусть A и B – выражения булевского типа, тогда булевские операции определяются следующим образом:
AND Логическое И OR Логическое ИЛИ XOR Логическое исключающее ИЛИ NOT Логическое НЕ Функция ORD дает значение 0, если аргумент имеет значение FALSE, и 1, если TRUE. 5.1.6 Вещественные типы данныхПростые типы вещественных данных не являются ординальными. С помощью этих типов данных в языке задается некоторое конечное подмножество рациональных чисел. Константы вещественного типа записываются в виде цепочки цифр с точкой, например: 0.0, 3.14, 17.4 (вещественная константа должна начинаться и заканчиваться цифрой). Константа может быть представлена в экспоненциальной форме, например, 1.0E+5, 0.01E-0, 3.14E. Кроме того, TP позволяет работать со следующими вещественными типами (табл.).
*Это форматы чисел, с которыми работает математический сопроцессор. Над данными вещественного типа в языке TP определены следующие операции и функции: 1. унарная операция + возвращает величину операнда; 2. унарная операция – меняет знак операнда; 3. бинарные операции +, - ,*, / возвращают результат выполнения соответствующих операций над вещественными числами; 4. отношения <, >, <=, >=, =, <> возвращают булевскую величину как результат сравнения операндов. 1. функция TRUNC(X) возвращает целую часть X; 2. функция ROUND(X) - округленное значение X до целого; 3. функция INT(X) - возвращает целую часть аргумента; 4. функция FRAC(X) - возвращает дробную часть аргумента; 5. функция PI - возвращает число 3.; 6. функция ABS(X) - абсолютную величину X; 7. функции SIN(X), COS(X), ARCTAN(X), LN(X), EXP(X), SQRT(X) и SQR(X) - возвращают значения синуса, косинуса, арктангенса, натурального логарифма, экспоненты, корня квадратного и квадрата аргумента X соответственно. Лекция 66.1 Структура программы на ПаскалеПрограмма на Паскале представляет собой обычный текст. Транслятор воспринимает этот текст как последовательность символов. На этапе лексического анализа текста выделяются слова (разделитель – пробел). Из слов составлены предложения (или операторы), разделителем служит символ «;» – «точка с запятой».
Начинается программа с необязательного оператора program <имя программы> – заголовка программы. Именем программы может быть любой уникальный в данной программе идентификатор. После заголовка следует секция описаний. Секция описаний состоит из разделов. Раздел описания имен модулей (в стандарте Паскаля этот раздел отсутствует). Раздел начинается заголовком uses, далее списком через запятую указываются имена используемых в программе модулей. Раздел описания меток. После заголовка раздела label записывается список используемых в программе меток. Раздел описания типов данных. После заголовка раздела type следуют операторы описания типов данных, созданных в программе пользователем. Операторы описания типа имеют следующий формат: <имя типа>=<описатель типа>. Имя типа – идентификатор, описатель типа – конструкция, определяющая данный тип. Раздел описания имен переменных начинается с заголовка var. Далее следуют операторы описания переменных, имеющие следующий формат: <список имен переменных через запятую>:<имя типа или описатель типа>. Раздел описания процедур и функций заголовка не имеет. Раздел содержит описания пользовательских процедур и функций. В стандарте Паскаля перечисленные разделы следуют в строго указанном порядке. В ТР разделы могут следовать в любом порядке и могут повторяться. Текст программы на Паскале завершает секция действий, представляющая собой составной оператор, – последовательность операторов, заключенная в логические скобки begin end. В секции действий описана последовательность действий, то есть алгоритм решения задачи. 6.2 Процедуры для стандартного ввода/выводаДля осуществления ввода и вывода данных стандартного типа используются предопределенные процедуры ввода и вывода READ, READLN, WRITE, WRITELN. Эти процедуры, кроме стандартных типов (целочисленные, вещественные, булевский, символьный), могут обслуживать диапазонные типы со стандартным базовым типом и данные типа string (строка). В качестве аргумента эти процедуры получают список элементов ввода или вывода. Список формируется как строка, в которой указываются через запятую имена элементов ввода или вывода, возможно со спецификацией (характеристикой). Спецификации служат для уточнения формата представления данных. Если спецификация не указана, используется формат, принятый по умолчанию для данного типа данных. Элемент ввода или вывода может принимать одну из следующих форм: E,{нет спецификации} E:LEN,{указана характеристика длины} E:LEN:ACCUR {указана характеристика длины и точности} Здесь Е – выражение одного из перечисленных выше типов, обслуживаемых процедурами ввода и вывода, LEN и ACCUR – выражения типа INTEGER. Характеристика точности (ACCUR) может применяться только для вывода данных вещественного типа. Использование характеристик при выдаче данных в текстовый файл (или на экран монитора) показано на примерах: VAR I:INTEGER; C:CHAR; PI:REAL; B:BOOLEAN; A, S:STRING; I:=1234; C:='a'; PI:=3.14159; B:=TRUE; S:='ABCD'; A:='ABCD'; Обращение к процедуре результат WRITE(I:6); ..1234 WRITE(I:1); 1234 WRITE(I); .......1234 WRITE(C:6); .....a WRITE(PI:10); .3.142E+00 WRITE(PI); .3.E+00 WRITE(PI:10:4); ....3.1416 WRITE(B:10); ......TRUE WRITE(B:2); .T WRITE(S:6); ..ABCD WRITE(S:2); AB WRITE(S); ABCD Процедура WRITELN, в отличие от WRITE, после записи данных в файл осуществляет переход на новую логическую запись (строку) текстового файла. Процедура READLN, в отличие от READ, после выполнения операции ввода данных для всего списка элементов ввода, осуществляет переход на следующую логическую запись (строку) текстового файла чтения. 6.3 Массивы. Регулярный типМассив – структура данных, задающая в памяти ЭВМ определенное количество однотипных записей. Тип данных массив в классификации типов данных языка Паскаль относят к базовым структурам и называют регулярным типом данных. Описатель массива ARRAY[<индексный тип>] OF <базовый тип> <индексный тип> - имя или описатель индексного типа, <базовый тип> - имя или описатель базового типа. В качестве базового типа можно использовать любой тип данных. Индексный тип – любой ординальный тип данных, кроме LONGINT. Индексный тип задает количество элементов массива (размер массива) и тип значений индексов. Вот примеры описателей массивов: ARRAY[1..10] OF REAL – массивы этого типа будут состоять из 10 элементов действительного типа, индексы – целые числа от 1 до 10. ARRAY[CHAR] OF INTEGER – массивы этого типа будут состоять из 256 целочисленных элементов, индексы – символы кодовой таблицы от #0 до #255. ARRAY[’A’..’Z’] OF INTEGER – массивы этого типа будут состоять из 26 целочисленных элементов, индексы – заглавные буквы латинского алфавита. В качестве описателя базового типа может быть использован описатель массива. Вот пример описаний: TYPE I1=<индексный тип 1>; I2=<индексный тип 2>; Ik=<индексный тип k>; BAZ=<базовый тип>; MASS=ARRAY[I1] OF ARRAY[I2] OF BAZ В Паскале предусмотрена более компактная запись последнего оператора: MASS=ARRAY[I1,I2] OF BAZ Переменная типа MASS будет представлять собой двумерный массив (массив массивов). В описании VAR M:ARRAY[I1,I2, …, Ik] OF BAZ массив М объявлен как многомерный (k – мерный) массив. Количество индексных типов в описании массива – размерность массива. Доступ к элементам массива осуществляется с помощью селектора [ ] – квадратные скобки. В квадратных скобках указывают значение (выражение) индексного типа. Если переменные x1,x2, …, xk описаны так: var x1:I1; x2:I2; …; xk:Ik, то M – массив ARRAY[I1,I2, …, Ik] OF BAZ, M[x1] – массив ARRAY[I2, …, Ik] OF BAZ, M[x1][x2] – массив ARRAY[ …, Ik] OF BAZ, … M[x1][x2] … [xk] – данное базового типа BAZ, Допустимы сокращенные формы записи: M[x1,x2],…, M[x1,x2, …, xk], соответственно. Приведем примеры описаний и использования массивов TYPE M10=ARRAY[1..10] OF REAL; IND=-5..5; MIND=ARRAY[IND] OF REAL; {тип - массив из 11 элементов} MINDM10=ARRAY[IND] OF M10; {тип - двумерный массив} week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); dat=1..31; month=(January, Fabruary, March, April, May, June, July, August, September, October, November, December); VAR X:M10;{массив} K:IND;{переменная} Y:ARRAY[1..10] OF REAL; V:MIND; MM:MINDM10;{двумерный массив} Mdat:ARRAY[month] OF dat; Mweek_day:ARRAY[month, dat] OF week_day; В этих условиях доступ к элементам иллюстрируется операторами: K:=0; V[K]:=17.0; X[1]:= 22.5; Y[5]:=X[1]; MM[-3, 1]:= 0;{то же самое, что MM[-3][1]:= 0;} Mdat[January]:=31; Mweek_day[October, 9]:= Monday; В TP можно выполнить такое присваивание MM[0]:=X, если все компоненты массива V инициализированы (одинаковые типы данных). Нельзя выполнить присваивание X:=Y, поскольку переменные относятся к несовместимым по присваиванию типам данных. 6.4 Для работы с массивами – шаблоныШаблон 1. Ввод-вывод одномерного массива. program …; const NN=100;{Максимальное число элементов} … type MM=array [1..NN]of real; {Новый тип данных - массив} … var M:MM; k, i:integer; … begin {Ввод массива} writeln(‘Введите кол-во элементов массива (не более ',NN:1,’)’);
| X and Y | 5 | $ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5 | $ | 15 |
· Специальные символы обозначают следующие элементы языка: + - * / - арифметические операции; + - * - операции над множествами; = < > <= >= <> - отношения; := - присваивание; . - конец программы, составной идентификатор, селектор поля записи; , - разделитель элементов списка; : - используется при описаниях; ; - разделитель операторов языка; .. - диапазон; [ ] илиселектор элемента массива; { } или (* *) - скобки для выделения комментариев; + - операция конкатенации строк # - обозначение символа по его коду; @ - обозначение адреса переменной; $ - обозначение директивы компилятора или шестнадцатеричной константы; ^ - обозначение указателя. · Комментарии { } (* *) · Классификация типов данных:
· О совместимости типов данных. TP - язык со строгой типизацией данных. Это означает, что во время выполнения программы производится проверка справедливости (допустимости) выполняемых операций. Строгая типизация налагает определенные ограничения, которые объединены понятием совместимости типов данных. В основном программист должен сам предвидеть и обеспечивать явное преобразование типов данных там, где это необходимо. В TP явное преобразование типа данных осуществляется по схеме NewType(value), где значение value будет преобразовано к новому типу данных NewType. Однако существуют ситуации, когда происходит неявное преобразование типов. Эти ситуации реализуются в операциях, при присваивании, при передаче параметров и регламентированы законами совместимости. · В TP выделены три вида совместимости типов данных, и каждый вид предоставляет определенные возможности по совместному использованию данных. Два типа данных могут характеризоваться как одинаковые, совместимые по операциям (или просто совместимые) и совместимые по присваиванию. · Две переменные относятся к одинаковым (эквивалентным) типам, если описания переменных: а) ссылаются на одно и то же имя типа; б) ссылаются на различные имена типов (пусть Т1 и Т2), которые в разделе описания типов объявлены идентичными (TYPE T1=T2); · Бинарные операции могут быть выполнены над операндами, относящимися к совместимым (по операциям) типам данных. Два типа совместимы (по операциям), если: а) типы одинаковы (эквивалентны); б) оба типа целые или оба типа вещественные; в) один тип есть диапазон другого, или оба есть диапазоны от третьего; г) оба типа - строка (STRING); д) один тип - строка, а другой - ARRAY[1..n] of CHAR, или просто CHAR; е) оба типа - множества с совместимыми по операциям базовыми типами; ж) один тип - ссылочный, другой безтиповый указатель; з) оба типа - процедурные типы с одинаковым числом параметров, типы которых соответственно эквивалентны. Для функциональных типов необходима еще и эквивалентность типов результатов. и) Считается, что каждый объект типа "множество" совместим с пустым множеством и каждый объект типа "указатель" совместим с константой NIL. · Величина может быть присвоена переменной, если их типы совместимы по присваиванию. Выражение f типа F называется совместимым по присваиванию с переменной w типа W, если : а) F и W - эквивалентные, не файловые типы (и не содержат файловые типы в качестве полей); б) оба типа - совместимые ординарные типы и значения выражения f попадают в диапазон допустимых значений типа W; в) оба вещественные типы и значение выражения f допустимо для типа W; г) W - вещественный тип, F - целый; д) W - строка, F - либо строка, либо символ, либо массив символов; е) W и F - совместимые множественные типы, причем множество f целиком входит во множество W; ж) W и F - совместимые ссылочные типы или совместимые процедурные типы; з) W - процедурный тип, а f - имя процедуры или функции (параметры и типы должны быть согласованны); и) W и F - объектные типы, причем тип F потомок типа W, либо оба типа ссылочные на совместимые объектные типы. Хотя формулировки совместимости типов представляются довольно громоздкими, в их основе лежит простой здравый смысл. Разрешены действия, приводящие к естественному осмысленному результату без потери информации (или точности). Все операции округлений и усечений должны быть предусмотрены разработчиком программы и кодироваться явно. Лекция 55.1 Простые типы данныхЭлементы любого простого типа данных представляют собой упорядоченное множество. Следовательно, элементы простого типа могут быть связаны отношениями =, <>, >, >=, <=, <. Отношение между элементами простого типа является булевской величиной (относится к типу BOOLEAN). Все простые типы данных, кроме вещественных, относятся к ординальным типам данных. Для ординальных типов данных в языке TP определены операции, которые реализованы в функциях и процедурах: PRED (predecessor - предшествующий), SUCC (succeedent – последующий), ORD (ordinal – порядковое числительное), Dec (decrease – уменьшать),
НЕ нашли? Не то? Что вы ищете?
Inc (increase – уменьшать), SIZEOF (size of … - размер чего-либо) Функции PRED и SUCC получают в качестве аргумента значение ординального типа и возвращают предыдущий или последующий элементы этого типа. Считается ошибкой применение функции PRED к первому элементу, а функции SUCC к последнему элементу множества значений данного ординального типа. Функция ORD возвращает порядковый номеp элемента данного ординального типа, пеpвый элемент имеет номер 0, втоpой - 1 и т. д. Исключение представляют данные целого типа, поскольку ORD с целочисленным аргументом возвращает сам аргумент. Функцию ORD можно считать функцией пpеобpазования типа, поскольку для любого ординального аргумента результат будет целочисленный. Процедуры Dec (или Inc) позволяют увеличить (или уменьшить) аргумент на заданную величину. Например функция Dec(x, n) (или Inc (x, n)) увеличивает (или уменьшает) значение ординальной переменной x на n значений. Если параметр n опущен, то увеличение (уменьшение) происходит на 1. Для любого типа данных (в том числе и для простого) определена функция SIZEOF(X), которая возвращает размер памяти под аргумент X в байтах. В этой функции в качестве аргумента можно использовать имя константы, имя переменной или типа данных. 5.1.1 Перечислимый типПеречислимый ординальный тип описывается прямым перечислением константных значений этого типа в скобках через запятую. В качестве константных значений используются идентификаторы. Например: type week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); На множестве значений перечислимого типа определен естественный порядок Monday<Tuesday<Wednesday<…<Sunday. Если х и у – переменные var x, y:week_day; то можно переменным х и у присвоить значения, например: х:=Wednesday; y:=SUCC(x); применение функции ORD(Monday) – дает значение 0 целого типа, ORD(x) – 2 , ORD(y) – 3 ; 5.1.2 Интервальный типИнтервальный ординальный тип (или тип – диапазон) является подмножеством последовательных величин ранее определенного (или предопределенного) перечислимого типа (базового типа). Если тип week_day ранее определен, мы можем создать новый тип, например: TYPE work_day=Monday..Friday; На интервальном типе данных определены те же операции, что и на базовом. Однако программист должен гарантировать корректность операций на шаге выполнения. Если var D:work_day, то на шаге выполнения программы фрагмент D:=Friday; D:=SUCC(D) приведет к ошибке, поскольку для интервального типа work_day значение Friday является последним и не имеет последующего. program datas; type week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); dat=1..31; month=(January, Fabruary, March, April, May, June, July, August, September, October, November, December); year=1900..2100; attr_of_day=record w_d:week_day; d:dat; m:month; y:year end; var today:attr_of_day; kol:integer; function pred_week_day(w:week_day):week_day; begin if w=Monday then pred_week_day:=Sunday else pred_week_day:=pred(w) end; function pred_month(m:month):month; begin if m=January then pred_month:=December else pred_month:=pred(m) end; procedure pred_dat(var t:attr_of_day); begin if t. d=1 then begin t. m:=pred_month(t. m); if t. m=December then t. y:=t. y-1; case t. m of January, March, May, July, August, October, December:t. d:=31; Fabruary:if (t. y mod 4)=0 then t. d:=29 else t. d:=28; April, June, September, November:t. d:=30 end end else t. d:=t. d-1; t. w_d:=pred_week_day(today. w_d); end; begin today. w_d:=Monday; today. d:=2; today. m:=October; today. y:=2006; repeat pred_dat(today); if (today. y<=2000) and (today. w_d=Monday) and (today. d=13) then kol:=kol+1; until (today. y=1901) and (today. m=January) and (today. d=1); writeln('Kol= ',kol:4) end. 5.1.3 Целочисленные типыК целочисленным типам в TP относятся следующие предопределенные типы:
Для целочисленных типов применимы все функции, допустимые для ординальных типов – PRED, SUCC, DEC, INC. Определены унарные операции + и - ( сохранить знак числа, изменить знак числа), арифметические бинарные операции сложения (+), вычитания (-), умножения (*), деления нацело (div), взятия остатка при целочисленном делении (mod), деление (/), в результате последней операции получается вещественная величина. Кроме общих функций для ординальных типов данных, для целочисленных типов данных определены следующие: CHR(X) – возвращает символ (значение типа CHAR), код которого есть целое положительное число X (0 <= X <= 255). Логическая функция ODD(X) возвращает TRUE, если X – нечетно, в противном случае – FALSE. ABS(X) - абсолютная величина X. SQR(X) - квадрат величины X. В TP для данных типа INTEGER (и совместимых с INTEGER) определены побитовые операции: · n1 shl n2 - левый логический сдвиг двоичного кода числа n1 на n2 позиций. Слева двоичные разряды пропадают, справа добавляются нули. · n1 shr n2 - правый логический сдвиг. · not n – дополнение к двоичному коду целого числа n (цифра 0 заменяется на 1, 1 на 0). · n1 or n2 – логическое "или". · n1 and n2 – логическое "и". · n1 xor n2 – логическое исключающее "или". В побитовых операциях целые числа обрабатываются как строки двоичных цифр. Примеры использования побитовых операций приведены в таблицах.
5.1.4 Данные типа CHARДанные типа CHAR занимают один байт памяти. Константными значениями служат символы кодировки ASCII (Американский стандартный код обмена информации), содержащие, кроме латинских и русских (больших и малых) букв, цифр и используемых в TP специальных символов, различного рода служебные символы. Каждому символу соответствует некоторый код (целое число в диапазоне от 0 до 255), но не каждый символ имеет графическое представление (например, символы табуляции, символ возврата каретки и др.). Над данными типа CHAR можно производить операции, определенные для данных ординального типа. Функция ORD возвращает код аргумента. Если символ имеет графическое представление, например буква А, указать такой символ можно, заключив его изображение в апострофы – 'А'. Следующий оператор FOR C := 'A' TO 'Z' DO WRITELN('код символа', C, ' - ', ORD(C):3); позволяет получить коды всех символов таблицы ASCII в диапазоне от A до Z. Переменная C должна быть описана как CHAR. При использовании значений типа CHAR, не имеющих графического представления, можно применить форму записи символов по их коду с помощью префикса #, например #65 – то же самое, что 'A' (65 – код символа A). 5.1.5 Тип BOOLEANОрдинальный предопределенный тип BOOLEAN можно рассматривать как перечислимый тип с описанием TYPE BOOLEAN = (FALSE, TRUE); Переменные этого типа занимают один байт памяти. Операции AND, OR, XOR, NOT для операндов булевского типа понимаются компилятором как булевские операции умножения ("и"), сложения ("или"), "исключающего или" и "отрицания". Пусть A и B – выражения булевского типа, тогда булевские операции определяются следующим образом:
AND Логическое И OR Логическое ИЛИ XOR Логическое исключающее ИЛИ NOT Логическое НЕ Функция ORD дает значение 0, если аргумент имеет значение FALSE, и 1, если TRUE. 5.1.6 Вещественные типы данныхПростые типы вещественных данных не являются ординальными. С помощью этих типов данных в языке задается некоторое конечное подмножество рациональных чисел. Константы вещественного типа записываются в виде цепочки цифр с точкой, например: 0.0, 3.14, 17.4 (вещественная константа должна начинаться и заканчиваться цифрой). Константа может быть представлена в экспоненциальной форме, например, 1.0E+5, 0.01E-0, 3.14E. Кроме того, TP позволяет работать со следующими вещественными типами (табл.).
*Это форматы чисел, с которыми работает математический сопроцессор. Над данными вещественного типа в языке TP определены следующие операции и функции: 1. унарная операция + возвращает величину операнда; 2. унарная операция – меняет знак операнда; 3. бинарные операции +, - ,*, / возвращают результат выполнения соответствующих операций над вещественными числами; 4. отношения <, >, <=, >=, =, <> возвращают булевскую величину как результат сравнения операндов. 1. функция TRUNC(X) возвращает целую часть X; 2. функция ROUND(X) - округленное значение X до целого; 3. функция INT(X) - возвращает целую часть аргумента; 4. функция FRAC(X) - возвращает дробную часть аргумента; 5. функция PI - возвращает число 3.; 6. функция ABS(X) - абсолютную величину X; 7. функции SIN(X), COS(X), ARCTAN(X), LN(X), EXP(X), SQRT(X) и SQR(X) - возвращают значения синуса, косинуса, арктангенса, натурального логарифма, экспоненты, корня квадратного и квадрата аргумента X соответственно. Лекция 66.1 Структура программы на ПаскалеПрограмма на Паскале представляет собой обычный текст. Транслятор воспринимает этот текст как последовательность символов. На этапе лексического анализа текста выделяются слова (разделитель – пробел). Из слов составлены предложения (или операторы), разделителем служит символ «;» – «точка с запятой».
Начинается программа с необязательного оператора program <имя программы> – заголовка программы. Именем программы может быть любой уникальный в данной программе идентификатор. После заголовка следует секция описаний. Секция описаний состоит из разделов. Раздел описания имен модулей (в стандарте Паскаля этот раздел отсутствует). Раздел начинается заголовком uses, далее списком через запятую указываются имена используемых в программе модулей. Раздел описания меток. После заголовка раздела label записывается список используемых в программе меток. Раздел описания типов данных. После заголовка раздела type следуют операторы описания типов данных, созданных в программе пользователем. Операторы описания типа имеют следующий формат: <имя типа>=<описатель типа>. Имя типа – идентификатор, описатель типа – конструкция, определяющая данный тип. Раздел описания имен переменных начинается с заголовка var. Далее следуют операторы описания переменных, имеющие следующий формат: <список имен переменных через запятую>:<имя типа или описатель типа>. Раздел описания процедур и функций заголовка не имеет. Раздел содержит описания пользовательских процедур и функций. В стандарте Паскаля перечисленные разделы следуют в строго указанном порядке. В ТР разделы могут следовать в любом порядке и могут повторяться. Текст программы на Паскале завершает секция действий, представляющая собой составной оператор, – последовательность операторов, заключенная в логические скобки begin end. В секции действий описана последовательность действий, то есть алгоритм решения задачи. 6.2 Процедуры для стандартного ввода/выводаДля осуществления ввода и вывода данных стандартного типа используются предопределенные процедуры ввода и вывода READ, READLN, WRITE, WRITELN. Эти процедуры, кроме стандартных типов (целочисленные, вещественные, булевский, символьный), могут обслуживать диапазонные типы со стандартным базовым типом и данные типа string (строка). В качестве аргумента эти процедуры получают список элементов ввода или вывода. Список формируется как строка, в которой указываются через запятую имена элементов ввода или вывода, возможно со спецификацией (характеристикой). Спецификации служат для уточнения формата представления данных. Если спецификация не указана, используется формат, принятый по умолчанию для данного типа данных. Элемент ввода или вывода может принимать одну из следующих форм: E,{нет спецификации} E:LEN,{указана характеристика длины} E:LEN:ACCUR {указана характеристика длины и точности} Здесь Е – выражение одного из перечисленных выше типов, обслуживаемых процедурами ввода и вывода, LEN и ACCUR – выражения типа INTEGER. Характеристика точности (ACCUR) может применяться только для вывода данных вещественного типа. Использование характеристик при выдаче данных в текстовый файл (или на экран монитора) показано на примерах: VAR I:INTEGER; C:CHAR; PI:REAL; B:BOOLEAN; A, S:STRING; I:=1234; C:='a'; PI:=3.14159; B:=TRUE; S:='ABCD'; A:='ABCD'; Обращение к процедуре результат WRITE(I:6); ..1234 WRITE(I:1); 1234 WRITE(I); .......1234 WRITE(C:6); .....a WRITE(PI:10); .3.142E+00 WRITE(PI); .3.E+00 WRITE(PI:10:4); ....3.1416 WRITE(B:10); ......TRUE WRITE(B:2); .T WRITE(S:6); ..ABCD WRITE(S:2); AB WRITE(S); ABCD Процедура WRITELN, в отличие от WRITE, после записи данных в файл осуществляет переход на новую логическую запись (строку) текстового файла. Процедура READLN, в отличие от READ, после выполнения операции ввода данных для всего списка элементов ввода, осуществляет переход на следующую логическую запись (строку) текстового файла чтения. 6.3 Массивы. Регулярный типМассив – структура данных, задающая в памяти ЭВМ определенное количество однотипных записей. Тип данных массив в классификации типов данных языка Паскаль относят к базовым структурам и называют регулярным типом данных. Описатель массива ARRAY[<индексный тип>] OF <базовый тип> <индексный тип> - имя или описатель индексного типа, <базовый тип> - имя или описатель базового типа. В качестве базового типа можно использовать любой тип данных. Индексный тип – любой ординальный тип данных, кроме LONGINT. Индексный тип задает количество элементов массива (размер массива) и тип значений индексов. Вот примеры описателей массивов: ARRAY[1..10] OF REAL – массивы этого типа будут состоять из 10 элементов действительного типа, индексы – целые числа от 1 до 10. ARRAY[CHAR] OF INTEGER – массивы этого типа будут состоять из 256 целочисленных элементов, индексы – символы кодовой таблицы от #0 до #255. ARRAY[’A’..’Z’] OF INTEGER – массивы этого типа будут состоять из 26 целочисленных элементов, индексы – заглавные буквы латинского алфавита. В качестве описателя базового типа может быть использован описатель массива. Вот пример описаний: TYPE I1=<индексный тип 1>; I2=<индексный тип 2>; Ik=<индексный тип k>; BAZ=<базовый тип>; MASS=ARRAY[I1] OF ARRAY[I2] OF BAZ В Паскале предусмотрена более компактная запись последнего оператора: MASS=ARRAY[I1,I2] OF BAZ Переменная типа MASS будет представлять собой двумерный массив (массив массивов). В описании VAR M:ARRAY[I1,I2, …, Ik] OF BAZ массив М объявлен как многомерный (k – мерный) массив. Количество индексных типов в описании массива – размерность массива. Доступ к элементам массива осуществляется с помощью селектора [ ] – квадратные скобки. В квадратных скобках указывают значение (выражение) индексного типа. Если переменные x1,x2, …, xk описаны так: var x1:I1; x2:I2; …; xk:Ik, то M – массив ARRAY[I1,I2, …, Ik] OF BAZ, M[x1] – массив ARRAY[I2, …, Ik] OF BAZ, M[x1][x2] – массив ARRAY[ …, Ik] OF BAZ, … M[x1][x2] … [xk] – данное базового типа BAZ, Допустимы сокращенные формы записи: M[x1,x2],…, M[x1,x2, …, xk], соответственно. Приведем примеры описаний и использования массивов TYPE M10=ARRAY[1..10] OF REAL; IND=-5..5; MIND=ARRAY[IND] OF REAL; {тип - массив из 11 элементов} MINDM10=ARRAY[IND] OF M10; {тип - двумерный массив} week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); dat=1..31; month=(January, Fabruary, March, April, May, June, July, August, September, October, November, December); VAR X:M10;{массив} K:IND;{переменная} Y:ARRAY[1..10] OF REAL; V:MIND; MM:MINDM10;{двумерный массив} Mdat:ARRAY[month] OF dat; Mweek_day:ARRAY[month, dat] OF week_day; В этих условиях доступ к элементам иллюстрируется операторами: K:=0; V[K]:=17.0; X[1]:= 22.5; Y[5]:=X[1]; MM[-3, 1]:= 0;{то же самое, что MM[-3][1]:= 0;} Mdat[January]:=31; Mweek_day[October, 9]:= Monday; В TP можно выполнить такое присваивание MM[0]:=X, если все компоненты массива V инициализированы (одинаковые типы данных). Нельзя выполнить присваивание X:=Y, поскольку переменные относятся к несовместимым по присваиванию типам данных. 6.4 Для работы с массивами – шаблоныШаблон 1. Ввод-вывод одномерного массива. program …; const NN=100;{Максимальное число элементов} … type MM=array [1..NN]of real; {Новый тип данных - массив} … var M:MM; k, i:integer; … begin {Ввод массива} writeln(‘Введите кол-во элементов массива (не более ',NN:1,’)’);
| X xor Y | 10 |
· Специальные символы обозначают следующие элементы языка: + - * / - арифметические операции; + - * - операции над множествами; = < > <= >= <> - отношения; := - присваивание; . - конец программы, составной идентификатор, селектор поля записи; , - разделитель элементов списка; : - используется при описаниях; ; - разделитель операторов языка; .. - диапазон; [ ] илиселектор элемента массива; { } или (* *) - скобки для выделения комментариев; + - операция конкатенации строк # - обозначение символа по его коду; @ - обозначение адреса переменной; $ - обозначение директивы компилятора или шестнадцатеричной константы; ^ - обозначение указателя. · Комментарии { } (* *) · Классификация типов данных:
· О совместимости типов данных. TP - язык со строгой типизацией данных. Это означает, что во время выполнения программы производится проверка справедливости (допустимости) выполняемых операций. Строгая типизация налагает определенные ограничения, которые объединены понятием совместимости типов данных. В основном программист должен сам предвидеть и обеспечивать явное преобразование типов данных там, где это необходимо. В TP явное преобразование типа данных осуществляется по схеме NewType(value), где значение value будет преобразовано к новому типу данных NewType. Однако существуют ситуации, когда происходит неявное преобразование типов. Эти ситуации реализуются в операциях, при присваивании, при передаче параметров и регламентированы законами совместимости. · В TP выделены три вида совместимости типов данных, и каждый вид предоставляет определенные возможности по совместному использованию данных. Два типа данных могут характеризоваться как одинаковые, совместимые по операциям (или просто совместимые) и совместимые по присваиванию. · Две переменные относятся к одинаковым (эквивалентным) типам, если описания переменных: а) ссылаются на одно и то же имя типа; б) ссылаются на различные имена типов (пусть Т1 и Т2), которые в разделе описания типов объявлены идентичными (TYPE T1=T2); · Бинарные операции могут быть выполнены над операндами, относящимися к совместимым (по операциям) типам данных. Два типа совместимы (по операциям), если: а) типы одинаковы (эквивалентны); б) оба типа целые или оба типа вещественные; в) один тип есть диапазон другого, или оба есть диапазоны от третьего; г) оба типа - строка (STRING); д) один тип - строка, а другой - ARRAY[1..n] of CHAR, или просто CHAR; е) оба типа - множества с совместимыми по операциям базовыми типами; ж) один тип - ссылочный, другой безтиповый указатель; з) оба типа - процедурные типы с одинаковым числом параметров, типы которых соответственно эквивалентны. Для функциональных типов необходима еще и эквивалентность типов результатов. и) Считается, что каждый объект типа "множество" совместим с пустым множеством и каждый объект типа "указатель" совместим с константой NIL. · Величина может быть присвоена переменной, если их типы совместимы по присваиванию. Выражение f типа F называется совместимым по присваиванию с переменной w типа W, если : а) F и W - эквивалентные, не файловые типы (и не содержат файловые типы в качестве полей); б) оба типа - совместимые ординарные типы и значения выражения f попадают в диапазон допустимых значений типа W; в) оба вещественные типы и значение выражения f допустимо для типа W; г) W - вещественный тип, F - целый; д) W - строка, F - либо строка, либо символ, либо массив символов; е) W и F - совместимые множественные типы, причем множество f целиком входит во множество W; ж) W и F - совместимые ссылочные типы или совместимые процедурные типы; з) W - процедурный тип, а f - имя процедуры или функции (параметры и типы должны быть согласованны); и) W и F - объектные типы, причем тип F потомок типа W, либо оба типа ссылочные на совместимые объектные типы. Хотя формулировки совместимости типов представляются довольно громоздкими, в их основе лежит простой здравый смысл. Разрешены действия, приводящие к естественному осмысленному результату без потери информации (или точности). Все операции округлений и усечений должны быть предусмотрены разработчиком программы и кодироваться явно. Лекция 55.1 Простые типы данныхЭлементы любого простого типа данных представляют собой упорядоченное множество. Следовательно, элементы простого типа могут быть связаны отношениями =, <>, >, >=, <=, <. Отношение между элементами простого типа является булевской величиной (относится к типу BOOLEAN). Все простые типы данных, кроме вещественных, относятся к ординальным типам данных. Для ординальных типов данных в языке TP определены операции, которые реализованы в функциях и процедурах: PRED (predecessor - предшествующий), SUCC (succeedent – последующий), ORD (ordinal – порядковое числительное), Dec (decrease – уменьшать),
НЕ нашли? Не то? Что вы ищете?
Inc (increase – уменьшать), SIZEOF (size of … - размер чего-либо) Функции PRED и SUCC получают в качестве аргумента значение ординального типа и возвращают предыдущий или последующий элементы этого типа. Считается ошибкой применение функции PRED к первому элементу, а функции SUCC к последнему элементу множества значений данного ординального типа. Функция ORD возвращает порядковый номеp элемента данного ординального типа, пеpвый элемент имеет номер 0, втоpой - 1 и т. д. Исключение представляют данные целого типа, поскольку ORD с целочисленным аргументом возвращает сам аргумент. Функцию ORD можно считать функцией пpеобpазования типа, поскольку для любого ординального аргумента результат будет целочисленный. Процедуры Dec (или Inc) позволяют увеличить (или уменьшить) аргумент на заданную величину. Например функция Dec(x, n) (или Inc (x, n)) увеличивает (или уменьшает) значение ординальной переменной x на n значений. Если параметр n опущен, то увеличение (уменьшение) происходит на 1. Для любого типа данных (в том числе и для простого) определена функция SIZEOF(X), которая возвращает размер памяти под аргумент X в байтах. В этой функции в качестве аргумента можно использовать имя константы, имя переменной или типа данных. 5.1.1 Перечислимый типПеречислимый ординальный тип описывается прямым перечислением константных значений этого типа в скобках через запятую. В качестве константных значений используются идентификаторы. Например: type week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); На множестве значений перечислимого типа определен естественный порядок Monday<Tuesday<Wednesday<…<Sunday. Если х и у – переменные var x, y:week_day; то можно переменным х и у присвоить значения, например: х:=Wednesday; y:=SUCC(x); применение функции ORD(Monday) – дает значение 0 целого типа, ORD(x) – 2 , ORD(y) – 3 ; 5.1.2 Интервальный типИнтервальный ординальный тип (или тип – диапазон) является подмножеством последовательных величин ранее определенного (или предопределенного) перечислимого типа (базового типа). Если тип week_day ранее определен, мы можем создать новый тип, например: TYPE work_day=Monday..Friday; На интервальном типе данных определены те же операции, что и на базовом. Однако программист должен гарантировать корректность операций на шаге выполнения. Если var D:work_day, то на шаге выполнения программы фрагмент D:=Friday; D:=SUCC(D) приведет к ошибке, поскольку для интервального типа work_day значение Friday является последним и не имеет последующего. program datas; type week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); dat=1..31; month=(January, Fabruary, March, April, May, June, July, August, September, October, November, December); year=1900..2100; attr_of_day=record w_d:week_day; d:dat; m:month; y:year end; var today:attr_of_day; kol:integer; function pred_week_day(w:week_day):week_day; begin if w=Monday then pred_week_day:=Sunday else pred_week_day:=pred(w) end; function pred_month(m:month):month; begin if m=January then pred_month:=December else pred_month:=pred(m) end; procedure pred_dat(var t:attr_of_day); begin if t. d=1 then begin t. m:=pred_month(t. m); if t. m=December then t. y:=t. y-1; case t. m of January, March, May, July, August, October, December:t. d:=31; Fabruary:if (t. y mod 4)=0 then t. d:=29 else t. d:=28; April, June, September, November:t. d:=30 end end else t. d:=t. d-1; t. w_d:=pred_week_day(today. w_d); end; begin today. w_d:=Monday; today. d:=2; today. m:=October; today. y:=2006; repeat pred_dat(today); if (today. y<=2000) and (today. w_d=Monday) and (today. d=13) then kol:=kol+1; until (today. y=1901) and (today. m=January) and (today. d=1); writeln('Kol= ',kol:4) end. 5.1.3 Целочисленные типыК целочисленным типам в TP относятся следующие предопределенные типы:
Для целочисленных типов применимы все функции, допустимые для ординальных типов – PRED, SUCC, DEC, INC. Определены унарные операции + и - ( сохранить знак числа, изменить знак числа), арифметические бинарные операции сложения (+), вычитания (-), умножения (*), деления нацело (div), взятия остатка при целочисленном делении (mod), деление (/), в результате последней операции получается вещественная величина. Кроме общих функций для ординальных типов данных, для целочисленных типов данных определены следующие: CHR(X) – возвращает символ (значение типа CHAR), код которого есть целое положительное число X (0 <= X <= 255). Логическая функция ODD(X) возвращает TRUE, если X – нечетно, в противном случае – FALSE. ABS(X) - абсолютная величина X. SQR(X) - квадрат величины X. В TP для данных типа INTEGER (и совместимых с INTEGER) определены побитовые операции: · n1 shl n2 - левый логический сдвиг двоичного кода числа n1 на n2 позиций. Слева двоичные разряды пропадают, справа добавляются нули. · n1 shr n2 - правый логический сдвиг. · not n – дополнение к двоичному коду целого числа n (цифра 0 заменяется на 1, 1 на 0). · n1 or n2 – логическое "или". · n1 and n2 – логическое "и". · n1 xor n2 – логическое исключающее "или". В побитовых операциях целые числа обрабатываются как строки двоичных цифр. Примеры использования побитовых операций приведены в таблицах.
5.1.4 Данные типа CHARДанные типа CHAR занимают один байт памяти. Константными значениями служат символы кодировки ASCII (Американский стандартный код обмена информации), содержащие, кроме латинских и русских (больших и малых) букв, цифр и используемых в TP специальных символов, различного рода служебные символы. Каждому символу соответствует некоторый код (целое число в диапазоне от 0 до 255), но не каждый символ имеет графическое представление (например, символы табуляции, символ возврата каретки и др.). Над данными типа CHAR можно производить операции, определенные для данных ординального типа. Функция ORD возвращает код аргумента. Если символ имеет графическое представление, например буква А, указать такой символ можно, заключив его изображение в апострофы – 'А'. Следующий оператор FOR C := 'A' TO 'Z' DO WRITELN('код символа', C, ' - ', ORD(C):3); позволяет получить коды всех символов таблицы ASCII в диапазоне от A до Z. Переменная C должна быть описана как CHAR. При использовании значений типа CHAR, не имеющих графического представления, можно применить форму записи символов по их коду с помощью префикса #, например #65 – то же самое, что 'A' (65 – код символа A). 5.1.5 Тип BOOLEANОрдинальный предопределенный тип BOOLEAN можно рассматривать как перечислимый тип с описанием TYPE BOOLEAN = (FALSE, TRUE); Переменные этого типа занимают один байт памяти. Операции AND, OR, XOR, NOT для операндов булевского типа понимаются компилятором как булевские операции умножения ("и"), сложения ("или"), "исключающего или" и "отрицания". Пусть A и B – выражения булевского типа, тогда булевские операции определяются следующим образом:
AND Логическое И OR Логическое ИЛИ XOR Логическое исключающее ИЛИ NOT Логическое НЕ Функция ORD дает значение 0, если аргумент имеет значение FALSE, и 1, если TRUE. 5.1.6 Вещественные типы данныхПростые типы вещественных данных не являются ординальными. С помощью этих типов данных в языке задается некоторое конечное подмножество рациональных чисел. Константы вещественного типа записываются в виде цепочки цифр с точкой, например: 0.0, 3.14, 17.4 (вещественная константа должна начинаться и заканчиваться цифрой). Константа может быть представлена в экспоненциальной форме, например, 1.0E+5, 0.01E-0, 3.14E. Кроме того, TP позволяет работать со следующими вещественными типами (табл.).
*Это форматы чисел, с которыми работает математический сопроцессор. Над данными вещественного типа в языке TP определены следующие операции и функции: 1. унарная операция + возвращает величину операнда; 2. унарная операция – меняет знак операнда; 3. бинарные операции +, - ,*, / возвращают результат выполнения соответствующих операций над вещественными числами; 4. отношения <, >, <=, >=, =, <> возвращают булевскую величину как результат сравнения операндов. 1. функция TRUNC(X) возвращает целую часть X; 2. функция ROUND(X) - округленное значение X до целого; 3. функция INT(X) - возвращает целую часть аргумента; 4. функция FRAC(X) - возвращает дробную часть аргумента; 5. функция PI - возвращает число 3.; 6. функция ABS(X) - абсолютную величину X; 7. функции SIN(X), COS(X), ARCTAN(X), LN(X), EXP(X), SQRT(X) и SQR(X) - возвращают значения синуса, косинуса, арктангенса, натурального логарифма, экспоненты, корня квадратного и квадрата аргумента X соответственно. Лекция 66.1 Структура программы на ПаскалеПрограмма на Паскале представляет собой обычный текст. Транслятор воспринимает этот текст как последовательность символов. На этапе лексического анализа текста выделяются слова (разделитель – пробел). Из слов составлены предложения (или операторы), разделителем служит символ «;» – «точка с запятой».
Начинается программа с необязательного оператора program <имя программы> – заголовка программы. Именем программы может быть любой уникальный в данной программе идентификатор. После заголовка следует секция описаний. Секция описаний состоит из разделов. Раздел описания имен модулей (в стандарте Паскаля этот раздел отсутствует). Раздел начинается заголовком uses, далее списком через запятую указываются имена используемых в программе модулей. Раздел описания меток. После заголовка раздела label записывается список используемых в программе меток. Раздел описания типов данных. После заголовка раздела type следуют операторы описания типов данных, созданных в программе пользователем. Операторы описания типа имеют следующий формат: <имя типа>=<описатель типа>. Имя типа – идентификатор, описатель типа – конструкция, определяющая данный тип. Раздел описания имен переменных начинается с заголовка var. Далее следуют операторы описания переменных, имеющие следующий формат: <список имен переменных через запятую>:<имя типа или описатель типа>. Раздел описания процедур и функций заголовка не имеет. Раздел содержит описания пользовательских процедур и функций. В стандарте Паскаля перечисленные разделы следуют в строго указанном порядке. В ТР разделы могут следовать в любом порядке и могут повторяться. Текст программы на Паскале завершает секция действий, представляющая собой составной оператор, – последовательность операторов, заключенная в логические скобки begin end. В секции действий описана последовательность действий, то есть алгоритм решения задачи. 6.2 Процедуры для стандартного ввода/выводаДля осуществления ввода и вывода данных стандартного типа используются предопределенные процедуры ввода и вывода READ, READLN, WRITE, WRITELN. Эти процедуры, кроме стандартных типов (целочисленные, вещественные, булевский, символьный), могут обслуживать диапазонные типы со стандартным базовым типом и данные типа string (строка). В качестве аргумента эти процедуры получают список элементов ввода или вывода. Список формируется как строка, в которой указываются через запятую имена элементов ввода или вывода, возможно со спецификацией (характеристикой). Спецификации служат для уточнения формата представления данных. Если спецификация не указана, используется формат, принятый по умолчанию для данного типа данных. Элемент ввода или вывода может принимать одну из следующих форм: E,{нет спецификации} E:LEN,{указана характеристика длины} E:LEN:ACCUR {указана характеристика длины и точности} Здесь Е – выражение одного из перечисленных выше типов, обслуживаемых процедурами ввода и вывода, LEN и ACCUR – выражения типа INTEGER. Характеристика точности (ACCUR) может применяться только для вывода данных вещественного типа. Использование характеристик при выдаче данных в текстовый файл (или на экран монитора) показано на примерах: VAR I:INTEGER; C:CHAR; PI:REAL; B:BOOLEAN; A, S:STRING; I:=1234; C:='a'; PI:=3.14159; B:=TRUE; S:='ABCD'; A:='ABCD'; Обращение к процедуре результат WRITE(I:6); ..1234 WRITE(I:1); 1234 WRITE(I); .......1234 WRITE(C:6); .....a WRITE(PI:10); .3.142E+00 WRITE(PI); .3.E+00 WRITE(PI:10:4); ....3.1416 WRITE(B:10); ......TRUE WRITE(B:2); .T WRITE(S:6); ..ABCD WRITE(S:2); AB WRITE(S); ABCD Процедура WRITELN, в отличие от WRITE, после записи данных в файл осуществляет переход на новую логическую запись (строку) текстового файла. Процедура READLN, в отличие от READ, после выполнения операции ввода данных для всего списка элементов ввода, осуществляет переход на следующую логическую запись (строку) текстового файла чтения. 6.3 Массивы. Регулярный типМассив – структура данных, задающая в памяти ЭВМ определенное количество однотипных записей. Тип данных массив в классификации типов данных языка Паскаль относят к базовым структурам и называют регулярным типом данных. Описатель массива ARRAY[<индексный тип>] OF <базовый тип> <индексный тип> - имя или описатель индексного типа, <базовый тип> - имя или описатель базового типа. В качестве базового типа можно использовать любой тип данных. Индексный тип – любой ординальный тип данных, кроме LONGINT. Индексный тип задает количество элементов массива (размер массива) и тип значений индексов. Вот примеры описателей массивов: ARRAY[1..10] OF REAL – массивы этого типа будут состоять из 10 элементов действительного типа, индексы – целые числа от 1 до 10. ARRAY[CHAR] OF INTEGER – массивы этого типа будут состоять из 256 целочисленных элементов, индексы – символы кодовой таблицы от #0 до #255. ARRAY[’A’..’Z’] OF INTEGER – массивы этого типа будут состоять из 26 целочисленных элементов, индексы – заглавные буквы латинского алфавита. В качестве описателя базового типа может быть использован описатель массива. Вот пример описаний: TYPE I1=<индексный тип 1>; I2=<индексный тип 2>; Ik=<индексный тип k>; BAZ=<базовый тип>; MASS=ARRAY[I1] OF ARRAY[I2] OF BAZ В Паскале предусмотрена более компактная запись последнего оператора: MASS=ARRAY[I1,I2] OF BAZ Переменная типа MASS будет представлять собой двумерный массив (массив массивов). В описании VAR M:ARRAY[I1,I2, …, Ik] OF BAZ массив М объявлен как многомерный (k – мерный) массив. Количество индексных типов в описании массива – размерность массива. Доступ к элементам массива осуществляется с помощью селектора [ ] – квадратные скобки. В квадратных скобках указывают значение (выражение) индексного типа. Если переменные x1,x2, …, xk описаны так: var x1:I1; x2:I2; …; xk:Ik, то M – массив ARRAY[I1,I2, …, Ik] OF BAZ, M[x1] – массив ARRAY[I2, …, Ik] OF BAZ, M[x1][x2] – массив ARRAY[ …, Ik] OF BAZ, … M[x1][x2] … [xk] – данное базового типа BAZ, Допустимы сокращенные формы записи: M[x1,x2],…, M[x1,x2, …, xk], соответственно. Приведем примеры описаний и использования массивов TYPE M10=ARRAY[1..10] OF REAL; IND=-5..5; MIND=ARRAY[IND] OF REAL; {тип - массив из 11 элементов} MINDM10=ARRAY[IND] OF M10; {тип - двумерный массив} week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday); dat=1..31; month=(January, Fabruary, March, April, May, June, July, August, September, October, November, December); VAR X:M10;{массив} K:IND;{переменная} Y:ARRAY[1..10] OF REAL; V:MIND; MM:MINDM10;{двумерный массив} Mdat:ARRAY[month] OF dat; Mweek_day:ARRAY[month, dat] OF week_day; В этих условиях доступ к элементам иллюстрируется операторами: K:=0; V[K]:=17.0; X[1]:= 22.5; Y[5]:=X[1]; MM[-3, 1]:= 0;{то же самое, что MM[-3][1]:= 0;} Mdat[January]:=31; Mweek_day[October, 9]:= Monday; В TP можно выполнить такое присваивание MM[0]:=X, если все компоненты массива V инициализированы (одинаковые типы данных). Нельзя выполнить присваивание X:=Y, поскольку переменные относятся к несовместимым по присваиванию типам данных. 6.4 Для работы с массивами – шаблоныШаблон 1. Ввод-вывод одномерного массива. program …; const NN=100;{Максимальное число элементов} … type MM=array [1..NN]of real; {Новый тип данных - массив} … var M:MM; k, i:integer; … begin {Ввод массива} writeln(‘Введите кол-во элементов массива (не более ',NN:1,’)’);
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5.1.4 Данные типа CHAR
Данные типа CHAR занимают один байт памяти. Константными значениями служат символы кодировки ASCII (Американский стандартный код обмена информации), содержащие, кроме латинских и русских (больших и малых) букв, цифр и используемых в TP специальных символов, различного рода служебные символы. Каждому символу соответствует некоторый код (целое число в диапазоне от 0 до 255), но не каждый символ имеет графическое представление (например, символы табуляции, символ возврата каретки и др.). Над данными типа CHAR можно производить операции, определенные для данных ординального типа. Функция ORD возвращает код аргумента. Если символ имеет графическое представление, например буква А, указать такой символ можно, заключив его изображение в апострофы – 'А'. Следующий оператор
FOR C := 'A' TO 'Z' DO
WRITELN('код символа', C, ' - ', ORD(C):3);
позволяет получить коды всех символов таблицы ASCII в диапазоне от A до Z.
Переменная C должна быть описана как CHAR.
При использовании значений типа CHAR, не имеющих графического представления, можно применить форму записи символов по их коду с помощью префикса #, например #65 – то же самое, что 'A' (65 – код символа A).
5.1.5 Тип BOOLEAN
Ординальный предопределенный тип BOOLEAN можно рассматривать как перечислимый тип с описанием
TYPE BOOLEAN = (FALSE, TRUE);
Переменные этого типа занимают один байт памяти. Операции AND, OR, XOR, NOT для операндов булевского типа понимаются компилятором как булевские операции умножения ("и"), сложения ("или"), "исключающего или" и "отрицания". Пусть A и B – выражения булевского типа, тогда булевские операции определяются следующим образом:
A | B | not A | A and B | A OR B | A xor B |
T | T | F | T | T | F |
T | F | F | F | T | T |
F | T | T | F | T | T |
F | F | T | F | F | F |
AND Логическое И
OR Логическое ИЛИ
XOR Логическое исключающее ИЛИ
NOT Логическое НЕ
Функция ORD дает значение 0, если аргумент имеет значение FALSE, и 1, если TRUE.
5.1.6 Вещественные типы данных
Простые типы вещественных данных не являются ординальными. С помощью этих типов данных в языке задается некоторое конечное подмножество рациональных чисел. Константы вещественного типа записываются в виде цепочки цифр с точкой, например: 0.0, 3.14, 17.4 (вещественная константа должна начинаться и заканчиваться цифрой). Константа может быть представлена в экспоненциальной форме, например, 1.0E+5, 0.01E-0, 3.14E.
Кроме того, TP позволяет работать со следующими вещественными типами (табл.).
Тип | Диапазон | Цифры | Байты |
real | 2.9e-39..1.7e38 | 11-12 | 6 |
Single* | 1.5e-45..3.4e38 | 7-8 | 4 |
Double* | 5.0e-324..1.7e308 | 15-16 | 8 |
Extended* | 3.4e-4932..1.1e4932 | 19-20 | 10 |
comp | -9.2e18..9.2e18 | 19-20 | 8 |
*Это форматы чисел, с которыми работает математический сопроцессор.
Над данными вещественного типа в языке TP определены следующие операции и функции:
1. унарная операция + возвращает величину операнда;
2. унарная операция – меняет знак операнда;
3. бинарные операции +, - ,*, / возвращают результат выполнения соответствующих операций над вещественными числами;
4. отношения <, >, <=, >=, =, <> возвращают булевскую величину как результат сравнения операндов.
1. функция TRUNC(X) возвращает целую часть X;
2. функция ROUND(X) - округленное значение X до целого;
3. функция INT(X) - возвращает целую часть аргумента;
4. функция FRAC(X) - возвращает дробную часть аргумента;
5. функция PI - возвращает число 3.;
6. функция ABS(X) - абсолютную величину X;
7. функции SIN(X), COS(X), ARCTAN(X), LN(X), EXP(X), SQRT(X) и SQR(X) - возвращают значения синуса, косинуса, арктангенса, натурального логарифма, экспоненты, корня квадратного и квадрата аргумента X соответственно.
Лекция 6
6.1 Структура программы на Паскале
Программа на Паскале представляет собой обычный текст. Транслятор воспринимает этот текст как последовательность символов. На этапе лексического анализа текста выделяются слова (разделитель – пробел). Из слов составлены предложения (или операторы), разделителем служит символ «;» – «точка с запятой».

Начинается программа с необязательного оператора program <имя программы> – заголовка программы. Именем программы может быть любой уникальный в данной программе идентификатор.
После заголовка следует секция описаний. Секция описаний состоит из разделов.
Раздел описания имен модулей (в стандарте Паскаля этот раздел отсутствует). Раздел начинается заголовком uses, далее списком через запятую указываются имена используемых в программе модулей.
Раздел описания меток. После заголовка раздела label записывается список используемых в программе меток.
Раздел описания типов данных. После заголовка раздела type следуют операторы описания типов данных, созданных в программе пользователем. Операторы описания типа имеют следующий формат: <имя типа>=<описатель типа>. Имя типа – идентификатор, описатель типа – конструкция, определяющая данный тип.
Раздел описания имен переменных начинается с заголовка var. Далее следуют операторы описания переменных, имеющие следующий формат: <список имен переменных через запятую>:<имя типа или описатель типа>.
Раздел описания процедур и функций заголовка не имеет. Раздел содержит описания пользовательских процедур и функций.
В стандарте Паскаля перечисленные разделы следуют в строго указанном порядке. В ТР разделы могут следовать в любом порядке и могут повторяться.
Текст программы на Паскале завершает секция действий, представляющая собой составной оператор, – последовательность операторов, заключенная в логические скобки begin end. В секции действий описана последовательность действий, то есть алгоритм решения задачи.
6.2 Процедуры для стандартного ввода/вывода
Для осуществления ввода и вывода данных стандартного типа используются предопределенные процедуры ввода и вывода READ, READLN, WRITE, WRITELN. Эти процедуры, кроме стандартных типов (целочисленные, вещественные, булевский, символьный), могут обслуживать диапазонные типы со стандартным базовым типом и данные типа string (строка). В качестве аргумента эти процедуры получают список элементов ввода или вывода. Список формируется как строка, в которой указываются через запятую имена элементов ввода или вывода, возможно со спецификацией (характеристикой). Спецификации служат для уточнения формата представления данных. Если спецификация не указана, используется формат, принятый по умолчанию для данного типа данных.
Элемент ввода или вывода может принимать одну из следующих форм:
E,{нет спецификации}
E:LEN,{указана характеристика длины}
E:LEN:ACCUR {указана характеристика длины и точности}
Здесь Е – выражение одного из перечисленных выше типов, обслуживаемых процедурами ввода и вывода, LEN и ACCUR – выражения типа INTEGER. Характеристика точности (ACCUR) может применяться только для вывода данных вещественного типа. Использование характеристик при выдаче данных в текстовый файл (или на экран монитора) показано на примерах:
VAR I:INTEGER; C:CHAR; PI:REAL; B:BOOLEAN; A, S:STRING;
I:=1234;
C:='a';
PI:=3.14159;
B:=TRUE;
S:='ABCD';
A:='ABCD';
Обращение к процедуре результат
WRITE(I:6); ..1234
WRITE(I:1); 1234
WRITE(I); .......1234
WRITE(C:6); .....a
WRITE(PI:10); .3.142E+00
WRITE(PI); .3.E+00
WRITE(PI:10:4); ....3.1416
WRITE(B:10); ......TRUE
WRITE(B:2); .T
WRITE(S:6); ..ABCD
WRITE(S:2); AB
WRITE(S); ABCD
Процедура WRITELN, в отличие от WRITE, после записи данных в файл осуществляет переход на новую логическую запись (строку) текстового файла.
Процедура READLN, в отличие от READ, после выполнения операции ввода данных для всего списка элементов ввода, осуществляет переход на следующую логическую запись (строку) текстового файла чтения.
6.3 Массивы. Регулярный тип
Массив – структура данных, задающая в памяти ЭВМ определенное количество однотипных записей. Тип данных массив в классификации типов данных языка Паскаль относят к базовым структурам и называют регулярным типом данных.
Описатель массива ARRAY[<индексный тип>] OF <базовый тип>
<индексный тип> - имя или описатель индексного типа,
<базовый тип> - имя или описатель базового типа.
В качестве базового типа можно использовать любой тип данных. Индексный тип – любой ординальный тип данных, кроме LONGINT. Индексный тип задает количество элементов массива (размер массива) и тип значений индексов.
Вот примеры описателей массивов:
ARRAY[1..10] OF REAL – массивы этого типа будут состоять из 10 элементов действительного типа, индексы – целые числа от 1 до 10.
ARRAY[CHAR] OF INTEGER – массивы этого типа будут состоять из 256 целочисленных элементов, индексы – символы кодовой таблицы от #0 до #255.
ARRAY[’A’..’Z’] OF INTEGER – массивы этого типа будут состоять из 26 целочисленных элементов, индексы – заглавные буквы латинского алфавита.
В качестве описателя базового типа может быть использован описатель массива. Вот пример описаний:
TYPE
I1=<индексный тип 1>;
I2=<индексный тип 2>;
Ik=<индексный тип k>;
BAZ=<базовый тип>;
MASS=ARRAY[I1] OF ARRAY[I2] OF BAZ
В Паскале предусмотрена более компактная запись последнего оператора:
MASS=ARRAY[I1,I2] OF BAZ
Переменная типа MASS будет представлять собой двумерный массив (массив массивов). В описании VAR M:ARRAY[I1,I2, …, Ik] OF BAZ массив М объявлен как многомерный (k – мерный) массив. Количество индексных типов в описании массива – размерность массива.
Доступ к элементам массива осуществляется с помощью селектора [ ] – квадратные скобки. В квадратных скобках указывают значение (выражение) индексного типа. Если переменные x1,x2, …, xk описаны так: var x1:I1; x2:I2; …; xk:Ik, то
M – массив ARRAY[I1,I2, …, Ik] OF BAZ,
M[x1] – массив ARRAY[I2, …, Ik] OF BAZ,
M[x1][x2] – массив ARRAY[ …, Ik] OF BAZ,
…
M[x1][x2] … [xk] – данное базового типа BAZ,
Допустимы сокращенные формы записи: M[x1,x2],…, M[x1,x2, …, xk], соответственно.
Приведем примеры описаний и использования массивов
TYPE M10=ARRAY[1..10] OF REAL;
IND=-5..5;
MIND=ARRAY[IND] OF REAL; {тип - массив из 11 элементов}
MINDM10=ARRAY[IND] OF M10; {тип - двумерный массив}
week_day=(Monday, Tuesday, Wednesday, Thursday,
Friday, Saturday, Sunday);
dat=1..31;
month=(January, Fabruary, March, April, May, June, July,
August, September, October, November, December);
VAR X:M10;{массив}
K:IND;{переменная}
Y:ARRAY[1..10] OF REAL;
V:MIND;
MM:MINDM10;{двумерный массив}
Mdat:ARRAY[month] OF dat;
Mweek_day:ARRAY[month, dat] OF week_day;
В этих условиях доступ к элементам иллюстрируется операторами:
K:=0;
V[K]:=17.0;
X[1]:= 22.5;
Y[5]:=X[1];
MM[-3, 1]:= 0;{то же самое, что MM[-3][1]:= 0;}
Mdat[January]:=31;
Mweek_day[October, 9]:= Monday;
В TP можно выполнить такое присваивание MM[0]:=X, если все компоненты массива V инициализированы (одинаковые типы данных). Нельзя выполнить присваивание X:=Y, поскольку переменные относятся к несовместимым по присваиванию типам данных.
6.4 Для работы с массивами – шаблоны
Шаблон 1. Ввод-вывод одномерного массива.
program …;
const NN=100;{Максимальное число элементов}
…
type MM=array [1..NN]of real; {Новый тип данных - массив}
…
var M:MM; k, i:integer;
…
begin
{Ввод массива}
writeln(‘Введите кол-во элементов массива (не более ',NN:1,’)’);

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
