


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
readln(k);
writeln(‘Введите ’,k:1,’ элементов массива‘);
for i:=1 to k do read(M[i]); readln;
…
{Вывод массива на экран}
writeln(‘Вот результат:’); {Заголовок вывода}
for i:=1 to k do write(‘M[‘,i:2,’]=’,M[i]:7:3); writeln;
…
end.
Шаблон 2. Ввод-вывод двумерного массива.
program …;
const NN=100; MM=100;{Максимальное число строк и столбцов}
…
type AA=array [1..NN,1..MM]of real;{Новый тип данных – двумерный массив}
…
var A:AA; n, m,i. j:integer;
…
begin
{Ввод двумерного массива}
writeln(‘Введите кол-во строк (не более ’,NN:1,’) и столбцов (не более ’,MM:1,’)');
readln(n, m);
for i:=1 to n do
begin
writeln(‘Введите ’,i:1,’-ю троку‘);
for j:=1 to m do read(M[i, j]);
readln
end;
…
{Вывод двумерного массива на экран}
writeln(‘Вот результат:’);{Заголовок вывода}
for i:=1 to n do
begin
for j:=1 to m do write(M[i, j]);
writeln
end;
…
end.
Лекция 7
7.1 Строки
Строковый тип данных (STRING) предназначен для обработки цепочек символов (литер, элементов типа CHAR). Переменные типа STRING могут быть объявлены следующим образом:
<имя переменной>:STRING[длина]
или
<имя переменной>:STRING
В стандарте Паскаля такого типа данных нет.
Параметр длина задает максимальную длину строки (максимальное число символов цепочки). Если максимальный размер строки не указан, то он автоматически принимается равным 255 – максимально возможной длине строки. Для переменной типа string резервируется участок памяти длиной длина+1 байт. Дополнительный байт используется для хранения значения текущей длины строки.
В языке Паскаль широко используются константы строкового типа. Они представляют собой цепочки произвольных символов используемой кодовой таблицы, заключенные в апострофы. Например: ‘ВОТ’ – цепочка из трех символов, ‘’ – пустая цепочка.
Строка обладает всеми свойствами массива литер, то есть, структуры данных, описанной описателем array[0..длина] of char. Если имеются описания s, s1:string[10], то, в отличие от массива, допустимы присваивания
s:=’BOT’
s1:=’’.
При этом текущая длина строки s будет равна 3, текущая строка s1 – 0. Текущая длина строки – целое положительное число в диапазоне от 0 до длина – хранится в нулевом элементе строки как данное типа char (s[0]=chr(3), s1[0]=chr(0)). В первом элементе строки s – s[1] – хранится символ ‘B’, во втором – ‘O’, в третьем – ‘T’, значение элемента s[4] неопределенно, обращение к нему является ошибкой, поскольку индекс превышает текущее значение длины строки.
Текущая длина строки не должна превышать максимальную длину.
К строкам применимы стандартные процедуры ввода и вывода. Если выдать на экран значения строк s и s1, то получим:
writeln(s) – на экране строка ‘ВОТ’,
writeln(s1) – на экране пустая строка.
Над строковыми данными определена бинарная операция конкатенации (+). Результатом конкатенации двух строк является строка, содержащая последовательно все символы левого операнда, а затем все символы правого операнда. Вот примеры использования конкатенации:
writeln(s) – на экране текст ВОТВОТ;
s1:=s+’ KOT’; writeln(s1) – на экране ВОТ КОТ.
Пример использования строк для обеспечения защиты ввода целого числа от «дурака». Под «дураком» подразумевается пользователь программы, позволяющий себе, не взирая на настоятельные предупреждения разработчика о формате вводимой информации, вводить произвольную последовательность символов. При использовании стандартных средств ввода в таких случаях может возникнуть ошибка ввода, приводящая к прерыванию выполнения программы. Для обеспечения нормальной работы программы при вводе можно воспользоваться следующим средством:
program Enter_int;
type status=(beginning, znak, Ok, Err);
var s:string; zn, k,i:integer; c:char;
n:longint;
stat:status;
cifra:boolean;
begin
repeat
writeln(‘Введите целое по модулю меньшее ’,$7FFF:1);
readln(s);
k:=length(s);
zn:=1;
n:=0;
stat:=beginning;
for i:=1 to k do
begin
c:=s[i];
cifra:=(c>='0') and (c<='9');
case stat of
beginning: case c of
' ': ;
'+': stat:=znak;
'-': begin stat:=znak; zn:=-1 end;
'0'..'9': begin n:=n*10+ord(c)-ord('0');
stat:=Ok end;
else stat:=Err
end;
znak: if cifra then
begin
n:=n*10+ord(c)-ord('0'); stat:=Ok
end else stat:=Err;
Ok: if cifra then
begin
n:=n*10+ord(c)-ord('0'); stat:=Ok
end else stat:=Err;
end;
end;
n:=zn*n;
if abs(n)>=$7FFF then stat:=Err;
until stat=Ok;
writeln('rezult ',n)
end.
Переменную типа STRING можно сравнивать с другой переменной или константой типа STRING, используя отношения =, <, >, <=, >=, <>. Используется лексикографический порядок (как в каталогах библиотек).
В TP имеются следующие функции для обработки строк:
- CONCAT - функция имеет произвольное число параметров строкового типа, результат - строка, полученная последовательной склейкой параметров. Если длина полученной строки превышает 255 символов, то происходит усечение; COPY(S:string; ind, count:integer):string - возвращает подстроку S длиной count, начиная с литеры номер ind. При несоответствии с максимальной длиной используется усечение; DELETE(var S:string; ind, count:integer) - удаляет из S count символов, начиная с ind; INSERT(St:string; var S:string; ind:integer) - вставляет в S St, начиная с позиции ind; LENGTH(S:string) - функция, возвращает текущую длину строки S;
Две процедуры можно рассматривать как процедуры преобразования типа:
- VAL(S:string; var V; var code:integer) - где V - переменная целого или вещественного типа. Процедура выделяет из строки последовательность символов, преобразует к типу соответствующей переменной и присваивает полученное значение этой переменной. Процедура VAL является строковым аналогом процедуры READ. Если при чтении из строки встречается недопустимый символ, то в переменной code возвращается его номер. В противном случае этот параметр равен нулю; STR(X; var S:string) - преобразует численное значение целого или вещественного типа в его строковое представление. Эта процедура является строковым аналогом процедуры WRITE. После выражения X можно указать длину и точность представления данных.
Вот примеры использования процедур VAL и STR.
var X:real; S:string; i:integer;
begin
X:=3.1415926;
STR(X:8:4, S); S:='X=' + S;
Writeln(S); { на экране 'X= 3.1416'}
S:=DELETE(S,1,2); {удалили первые два символа}
VAL(S, X,i);
if i=0 then writeln(X:10:6) {на экране ' 3.141600'}
end.
В качестве упражнения перепишите программу Enter_int, используя функции и процедуры обработки строк.
7.2 Записи
Запись - структура данных, содержащая конечное число компонент различного типа. Компоненты называются полями. Как любой тип, определяемый программистом, тип "запись" должен быть объявлен в разделе TYPE. При описание типа запись указывает тип каждого поля и идентификатор, который именует поле. Тип данных RECORD предоставляет возможность объединить в одну связанную структуру различные по типу и смыслу поля, причем элементами записи могут быть и структурированные типы данных, например массивы и другие (подчиненные) записи. Для обработки доступна как вся запись целиком, так и отдельные поля.
Описатель записей:
RECORD <фиксированная часть> <вариантная часть> END
Здесь фиксированная часть записи состоит из списка имен полей с указанием типа данных, к которым эти поля относятся. В описании записи хотя бы одна из необязательных частей (фиксированная или вариантная) должна присутствовать.
Примеры записей, содержащих только фиксированную часть:
TYPE
REC = RECORD
A, B : INTEGER;
C : CHAR
END;
DATE = RECORD
DAY : 1..31;
MONTH : 1..12;
YEAR: 1900..2100
END;
Если VAR X:REC; Y, Z:DATE; то к полям записей X, Y и Z имеется доступ по имени поля. Например, X. A - поле A записи X, элемент типа INTEGER.
Инициализация записи - инициализация всех полей записи Y. DAY := 17; Y. MONTH := 3; Y. YEAR := 1992;
Если запись Y инициализирована, то можно ее использовать в правой части оператора присваивания Z := Y ; Z и Y совместимы по присваиванию, поскольку относятся к одному и тому же типу данных.
Посмотрите, как используется запись в программе Datas лекции 5.
Вариантная часть всегда следует за фиксированной, если она есть.
CASE <тег:> тип of <список описаний вариантов>
Описание варианта - это константное значение или диапазон константных значений, относящихся к типу «тип» описания вариантной части. Далее ставится двоеточие, и в скобках - описание полей варианта. Описание полей варианта осуществляется по тем же правилам, что и полей фиксированной части. Имена всех полей должны быть уникальными идентификаторами внутри записи.
Следующий пример показывают способ задания поля тега.
TYPE SHAPE = (TRIANGLE, RECTANGLE, SQUARE, CIRCLE);
COORDINATES = RECORD { фиксированная часть }
X, Y, AREA : REAL;
CASE S : SHAPE OF { вариантная часть }
TRIANGLE : (SIDE : REAL; BASE : REAL);
RECTANGLE: (SIDEA, SIDEB : REAL);
SQUARE : (EDGE : REAL);
CIRCLE : (RADIUS : REAL)
END;
В памяти поля разместятся как показано на рисунке
фиксированная часть | вариантная часть | ||||
X | Y | AREA | S | SIDE | BASE |
X | Y | AREA | S | SIDEA | SIDEB |
X | Y | AREA | S | EDGE | - |
X | Y | AREA | S | RADIUS | - |
Если S = RECTANGLE, то доступны поля SIDEA и SIDEB. Например, при инициализации записи:
X : COORDINATES;
X. S := RECTANGLE;
X. SIDEA := 17.5;
X. SIDEB := 20.4;
В стандартном языке Pascal (и в TP) можно вообще не указывать поле тега:
COORDINATES RECORD
X, Y : REAL; { фиксированная часть }
AREA : REAL;
CASE SHAPE OF { вариантная часть }
END
В этом случае можно обращаться к любым полям вариантной части по имени, однако ответственность за правильность трактовки данных возложена на программиста.
Проанализируйте самостоятельно следующий пример:
program record_;
type
T_education=(begining, medium, higher);
T_profession=(teacher, driver, woker);
T_category=(A, B,C, D);
T_anketa=
record
name :string[20];
case profession:T_profession of
teacher:(education:T_education;
pedagogical_length_of_service:byte);
driver :(licence:record
case drivers_licence:boolean of
true :(category:T_category;
drivers_length_of_servie:byte);
false:(drivers_school:string[20])
end);
woker :(specialization:string[20];
class:string[20])
end;
var a1,a2,a3:T_anketa;
begin
writeln(sizeof(T_profession)); {1}
writeln(sizeof(T_anketa)); {64}
a1.name:='Ivan';
a1.profession:=teacher;
a1.education:=higher;
a1.pedagogical_length_of_service:=1;
a2.name:='Vlad';
a2.profession:=driver;
a2.licence. drivers_licence:=true;
a2.licence. category:=B;
a3.name:='Mike';
a3.profession:=woker;
a3.specialization:='shoe-maker';
a3.class:='master';
end.
Оператор присоединения WITH позволяет один раз указать имя записи и обращаться непосредственно к полям записи. Синтаксис оператора WITH:
WITH <список переменных> DO <оператор>,
где в списке «список переменных» указываются имена записей.
Например, если Y запись типа DATE (см. пример выше), то значения полям этой записи можно присвоить так:
WITH Y DO BEGIN
DAY :=17; MONTH := 3; YER := 1992
END;
Оператор WITH V1, V2,...,Vn DO S;
эквивалентен последовательности операторов присоединения
WITH V1 DO WITH V2 DO... WITH Vn DO S;
Вот как массив строк может помочь распечатать (выдать на экран) данное перечислимого типа (день недели 1 января 1901 года):
program datas;
type
week_day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday);
dat=1..31;
month=(January, Fabruary, March, April, May, June, July,
August, September, October, November, December);
year=1900..2100;
attr_of_day=record
w_d:week_day;
d:dat;
m:month;
y:year
end;
var
today:attr_of_day;
kol:integer;
prn_week_day:array[week_day] of string[9]
function pred_week_day(w:week_day):week_day;
begin
if w=Monday then pred_week_day:=Sunday else pred_week_day:=pred(w)
end;
function pred_month(m:month):month;
begin
if m=January then pred_month:=December else pred_month:=pred(m)
end;
procedure pred_dat(var t:attr_of_day);
begin
if t. d=1 then
begin
t. m:=pred_month(t. m);
if t. m=December then t. y:=t. y-1;
case t. m of
January, March, May, July, August, October, December:t. d:=31;
Fabruary:if (t. y mod 4)=0 then t. d:=29 else t. d:=28;
April, June, September, November:t. d:=30
end
end else t. d:=t. d-1;
t. w_d:=pred_week_day(today. w_d);
end;
begin
prn_week_day[Monday]:=’Monday’
prn_week_day[Tuesday]:=‘Tuesday’
prn_week_day[Wednesday]:=‘Wednesday’
prn_week_day[Thursday]:=‘Thursday’
prn_week_day[Friday]:=‘Friday’
prn_week_day[Saturday]:=‘Saturday’
prn_week_day[Sunday]:=‘Sunday’
today. w_d:=Monday;
today. d:=2;
today. m:=October;
today. y:=2006;
repeat
pred_dat(today);
if (today. y<=2000) and (today. w_d=Monday) and (today. d=13)
then kol:=kol+1;
until (today. y=1901) and (today. m=January) and (today. d=1);
writeln('Kol= ',kol:4);
writeln(prn_week_day[today. w_d])
end.
Лекция 8
8.1 Множества
Переменная, относящаяся к типу множество, может содержать любую комбинацию величин, взятых из базового ординального типа. Каждая величина базового типа может принадлежать и не принадлежать этому множеству. Описатель множества выглядит так:
SET OF базовый тип
Базовым типом может являться любой ординальный тип, содержащий не более 255 элементов. Например: VAR set1,set2,even, anyset: SET OF 0..100;
Конструктором множества является заключенный в квадратные скобки список (через запятую) элементов множества (элементов базового типа). Элементы могут задаваться в виде выражения базового типа, либо в виде диапазона между двумя значениями, заданными выражениями. Например:
set1:=[1..20];
even:=[2,4,6,8,10,12,14,16,18,20];
set2:=[15..25];
anyset:=[3,3+2,11..15,17..4*5];
Над данными типа множество определены следующие операции:
- set1=set2 - сравнение (результат операции - FALSE); set1<>set2 - сравнение на несовпадение (TRUE); set2<=set1- входит ли set2 как подмножество в set1? (FALSE); set1>=even - содержит ли set1 как подмножество even? (TRUE); 5 in set1 - является ли 5 элементом множества set1? (TRUE). set1+set2 - объединение множеств - множество [1..25], set1*set2 - пересечение множеств - множество [15..20], set1-even - разность множеств - множество нечетных чисел меньших 20.
Вместо оператора cifra:=(c>='0') and (c<='9') в программе Enter_int (см. лекцию 7) можно использовать более ясную и лаконичную конструкцию
cifra:=c in ['0'..'9'].
В TP множество реализуется как последовательность бит, с помощью которой устанавливается, принадлежит (1) или нет (0) элемент, номер которого совпадает с порядковым номером бита, данному множеству. Таким образом, для базового типа из K элементов каждое множество задается строкой из K бит.
8.2 Файлы
Файл, с точки зрения программы на языке Паскаль, - это именованная структура данных, представляющая собой последовательность элементов одного типа. Количество элементов файла практически не ограничено. В первом приближении файл можно рассматривать как массив переменной длины неограниченного размера.
Все файлы можно разделить на типизированные, нетипизированные и текстовые.
Пример описаний файлов, в котором определены размеры буферов файлов различного типа:
program files;
var f1:file of real; {В стандарте f1^ - переменная типа real - типизированный файл}
f2:file; {нетипизированный файл}
f3:text; {текстовой файл}
begin
writeln(sizeof(f1),sizeof(f2),sizeof(f3))
end.
Результат: 128 128 256
Работа с файлами обеспечивается набором процедур и функций, обслуживающих файлы.
Описатель для типизированного файла выглядит так:
<имя>: file of <базовый тип>;
<имя> - файловая переменная. В стандарте файловая переменная является указателем на буфер файла. В ТР, как видно из примера, это не так.
<базовый тип> - любой, кроме файлового и записи, содержащей файловый тип.
Объявление файловой переменной задает только тип компонентов файла. Чтобы программа могла выводить данные в файл или читать данные из файла, необходимо указать конкретный файл файловой системы, т. е. задать имя файла. Имя файла задается вызовом процедуры ASSIGN, связывающей файловую переменную с конкретным файлом.
assign (var f:text; <ИмяФайла>:string);
Имя файла задается согласно принятым в MS-DOS правилам. Оно может быть полным, т. е. состоять не только непосредственно из имени файла, но и включать путь к файлу. Существуют определенные договоренности при записи имени файла, например:
assign ( f, 'a:\result. txt');{Полное имя файла}
assign (f,'\students\ivanov\korni. txt'); {Указан путь относительно текущей директории}
Имя файла может быть задано строкой:
fname:='otchet. txt';
assign(f, fname);
8.3 Процедуры открытия и закрытия файлов:
RESET(F) - открытие существующего файла F на чтение (файловая переменная F связана с существующим файлом MS DOS процедурой ASSIGN). В стандартном Паскале при открытии файла на чтение в динамической памяти создается буфер файла, в который помещается первая запись файла. Для нетипизированных файлов размер записи может быть указан вторым параметром. В ТР буфером является сама файловая переменная, размер буфера в примере пункта 8.3. Если открываемый на чтение файл не существует в файловой системе, возникает ошибка этапа выполнения программы.
REWRITE(F) – создает и открывает на запись новый файл. Если файловая переменная F связана с существующим файлом, то данные этого файла уничтожаются. В стандартном Паскале при открытии файла на запись в динамической памяти создается буфер файла для промежуточного хранения записей. Для нетипизированных файлов размеры записей могут задаваться вторым параметром. В ТР буфером является сама файловая переменная, размер буфера в примере пункта 8.3.
CLOSE(F) - закрытие файла F. При закрытии файла записи содержимое буфера выталкивается в файл. В стандарте Паскаля процедура закрытия файла разрывает связь файловой переменной (указателя) с буфером и уничтожает буфер в динамической памяти.
8.4 Процедуры ввода/вывода:
WRITE(F, E) - запись значения выражения E базового типа в файл; (не применима к нетипизированным файлам)
READ(F, V) - чтение из файла записи в переменную; (не применима к нетипизированным файлам)
BLOCKREAD; BLOCKWRITE - только для нетипизированных файлов.
SEEK(F, n) - делает доступной для обработки запись n файла F (эта процедура не применима к текстовым файлам);
EOF(F) - функция, возвращает TRUE, если достигнут конец файла F.
При работе с файлами в TP очень полезна функция IORESULT, которая возвращает значение кода ошибки выполнения последней операции ввода/вывода. Следующий фрагмент является шаблоном для открытия файла на чтение. Он позволяет избежать прерывания программы при попытке открытия на чтение не существующего файла
repeat
writeln('введите имя файла'); readln(s);
assign(f, s);
{$I-} {отключение проверки ошибок в/в}
reset(f);
{$I+} {включение проверки ошибок в/в}
i:=IORESULT;
if i<>0 then begin
writeln('Ошибка',i:3);
writeln('Попробуйте еще');
end;
until i = 0;
Здесь i – переменная типа integer, s – строка. {$I-} – псевдокомментарий – директива компилятору при выполнении дальнейших действий снять контроль проверки правильности выполнения операции ввода/вывода. Если открытие файла F прошло успешно, то IORESULT возвращает значение 0, в противном случае IORESULT возвращает код ошибки, отличный от нуля.
Лекция 9
9.1 Текстовые файлы.
Текстовый файл (описатель text в отличие от типизированного файла file of char) представляет собой файл символов, сгруппированных в строки. Разбиение на строки обеспечивается признаком (комбинаций символов) конца строки. Для текстовых файлов существует специальный вид операций чтения и записи (read, write, readln, writeln), который позволяют считывать и записывать значения, тип которых отличается от символьного типа (это действительные, целочисленные типы и строки, выводить можно также и данные булевского типа). Такие значения автоматически переводятся в символьное представление и обратно. Например, Read(f, i), где i - переменная целого типа, приведет к считыванию последовательности цифр, интерпретации этой последовательности как десятичного числа, и сохранению его в i. Предопределены две стандартные переменные типа text – это Input и Оutput. Стандартная файловая переменная Input – это доступный только для чтения файл, связанный со стандартным файлом ввода операционной системы (обычно это клавиатура), а стандартная файловая переменная Оutput – это доступный только для записи файл, связанный со стандартным файлом вывода операционной системы (обычно это дисплей). Перед началом выполнения программы файлы Input и Оutput автоматически открываются, как если бы были выполнены следующие операторы:
Assign(Input,'con'); Reset(Input);
Assign(Output,'con'); Rewrite(Output);
После завершения работы программы эти файлы автоматически закрываются.
Обращение к процедурам ввода и вывода для текстовых файлов организуется так:
Read(f,<список элементов ввода>),
write(f,<список элементов вывода>),
readln(f,<список элементов ввода>),
writeln(f,<список элементов вывода>)
f – имя файловой переменной. Список элементов ввода представляет собой список имен переменных символьного, целочисленного, действительного или строкового типа через запятую. Данные в строке читаемого текстового файла трактуются как символьное представление данных соответствующего типа.
· Данные целого типа читаются с текущего символа, пропуская лидирующие пробелы, до первого символа, синтаксически не совместимого с представлением целого числа, либо до конца строки файла.
· Переменная типа CHAR принимает значение текущего символа.
· Переменная-строка принимает символы, пока не будет достигнута ее максимальная длина, либо конец строки файла.
· Данные вещественного типа читаются последовательно из строки файла, пока не будет достигнут символ, синтаксически не совместимый с представлением вещественного числа, либо конец строки файла.
Пример:
VAR I, J : INTEGER; S :STRING[100]; CH : CHAR;
...
READ(f, I, J, CH, S);
Пусть читаемые данные:ABCDEFGHIJKLMNOPQRSTUVWXYZ.
После выполнения процедуры READ:
I =36, J = 24, CH = ' ', S = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'.
При завершении операции ввода данных во все переменные списка элементов ввода процедура readln осуществляет переход на новую строку текстового файла. В ТР, начиная с седьмой версии, при достижении конца строки чтение данных из текстового файла продолжается со следующей строки, если список ввода не исчерпан. Однако, с целью сохранения мобильности и читабельности программы, не следует пользоваться этим при проектировании ввода данных. Рекомендуется осуществлять переход на другую строку явным образом. Вот два примера:
program ReadEoln {Плохое решение};
var c:char; f:text;
begin
assign(f,'text. txt');
reset(f); {Нужно использовать шаблон безопасного открытия}
while not(eof(f)) do
begin
read(f, c);
write(c);
end;
close(f);
writeln;
readln;
end.
program Copy {хорошее решение, шаблон!};
var c:char; f:text;
begin
assign(f,'text. txt');
reset(f){Нужно использовать шаблон безопасного открытия};
while not(eof(f)) do
begin while not(eoln(f)) do
begin
read(f, c);
write(c);
end;
readln(f);
writeln;
end;
close(f);
writeln;
readln;
end.
Список элементов вывода представляет собой список выражений (в частности, переменных и констант) символьного, строкового, целочисленного действительного и булевского типа. После каждого выражения может указываться через двоеточие характеристика длины, а для выражений действительного типа еще и характеристика точности. При завершении операции вывода данных процедура writeln осуществляет переход на новую строку текстового файла.
Вот два примера работы с текстовыми файлами (предложены Путинцевым А).
{Добавление записей в файл данных о дневной температуре воздуха}
program aprec;
var
DayTemp:record {дневная темперарура}
day:integer; {число}
month:integer; {месяц}
temper:integer; {температура}
end;
f:text;{ файл дневной температуры}
begin
assign(f,'a:\temperat. txt');
append(f); {открываем файл для добавления записи}
{Нужно использовать шаблон безопасного открытия}
write('Введите в одной строке, разделяя пробелами');
writeln(' число, номер месяца и температуру');
write('->');
with DayTemp do
begin
readln(day, month, temper);
writeln(f, day,' ',month,' ',temper);
{Следовало бы указать характеристики длины}
end;
close(f);
writeln('Данные добавлены');
end.
{Чтение записей из файла}
program readrec;
var
DayTemp:record {дневная температура}
day:integer; {число}
month:integer; {месяц}
temper:integer; {температура}
end;
f:text; {файл дневной температуры}
mes:integer;{номер месяца}
n:integer;{кол-во дней месяца, о которых есть данные в файле}
summ:integer; {сумма температур месяца}
sredn:real; {средняя температура}
begin
n:=0;
summ:=0;
writeln('Вычисление среднемесячной температуры.');
write('Месяц->');
readln(mes);
assign(f,'a:\temperat. txt');
reset(f);{Нужно использовать шаблон безопасного открытия}
while NOT EOF(f) do begin
with DayTemp do readln(f, day, month, temper);
{Область действия оператора with}
if DayTemp. month=mes
then begin
n:=n+1;
summ:=summ+DayTemp. temper;
end;
end;
close(f);
if n<>0 then begin
sredn:=summ/n;
writeln('Средняя температура:',sredn:6:3);
end
else writeln('Данных о температуре за',mes:3,' месяц нет.');
end.
9.2 Проект программы:
- Точная формулировка задачи Типы данных Структуры данных Процедуры и функции Алгоритм
9.3 Простейший сканер.
Формулировка задачи: Программа читает текстовый файл, выделяет слова и распознает идентификаторы. Имя текстового файла запрашивается. На экран выдается список слов по одному слову в строку, идентификаторы помечаются символом *. Разделителем не является признак конца строки.
Спецификации (типы данных и структуры данных):
Определяются три состояния чтения текста:
· ident – подозрение на идентификатор,
· news – начало чтения нового слова,
· ordin – читаемое слово не идентификатор.
Состояния объединены в перечислимый тип status.
chars – множество всех символов, letter, digit и separ - подмножества букв, цифр и разделителей слов, соответственно.
Процедуры и функции - нет.
Алгоритм: Чтение (из файла) посимвольно. Определяется изменение состояния в зависимости от состояния s и вновь прочитанного символа c. Начальное состояние - news.
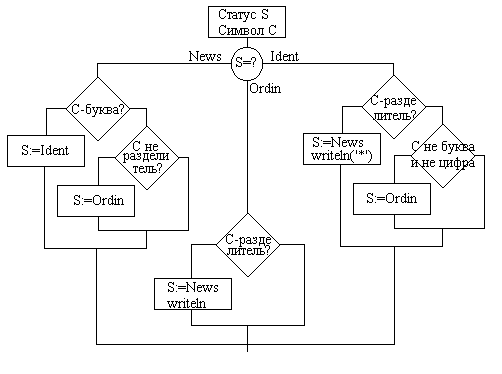
Входной алфавит V – буква, цифра, разделитель, символ.
Алфавит состояний Q – News, Ident, Ordin.
Функция переходов f:Q´V®Q:
буква | цифра | разделитель | символ | |
News | Ident | Ordin | News | Ordin |
Ident | Ident | Ident | News | Ordin |
Ordin | Ordin | Ordin | News | Ordin |
Начальное состояние – News

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
