

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Параметр формально является значением Y при X = 0. Он может не иметь экономического содержания. Интерпретировать можно лишь знак при параметре . Если > 0, то относительное изменение результата происходит медленнее, чем изменение фактора. Иными словами, вариация по фактору X выше вариации для результата Y. Также считают, что включает в себя неучтенные в модели факторы.
11. Пример
По итогам 2008 года были собраны данные по прибыли и оборачиваемости оборотных средств 500 торговых предприятий г. Челябинска. Результаты наблюдения сведены в таблицу.
№ | Годовая прибыль предприятия, млн. руб. | Годовая оборачиваемость оборотных средств, раз |
1 | 28,3 | 4,7 |
2 | 30,5 | 5,2 |
… | … | … |
… | … | … |
… | … | … |
499 | 35,6 | 6,1 |
500 | 37,4 | 6,3 |
Требуется построить зависимость прибыли предприятий от оборачиваемости оборотных средств и оценить качество полученного уравнения.
Пусть y – прибыль предприятия, x – оборачиваемость оборотных средств.
Y=a +b X +e.
На основе исходных данных были рассчитаны следующие показатели:
=5,82
=34,5
=0,35
cov(x, y)=2,05
Se=0,91
rxy=0,78
A=11%
Уровень доверия возьмем q=0,95 или 95%.

Следовательно, Y=0,39 +5,86 X.
Проверка качества:
1. Стандартные ошибки оценок , . намного больше =0,39, следовательно, низкая точность коэффициента . очень мала по сравнению с , следовательно, высокая точность коэффициента .
2. Интервальные оценки коэффициентов уравнения регрессии.
g = 1 – q =1 – 0,95 = 0,05;
n – 2 = 500 – 2 = 498;
tкр = 1,96;
α:  →
→  → очень низкая точность коэффициента;
→ очень низкая точность коэффициента;
β:  →
→  → высокая точность коэффициента.
→ высокая точность коэффициента.
3. Значимость коэффициентов регрессии.
 = >1,96 → коэффициент значим;
= >1,96 → коэффициент значим;
 = >1,96 → коэффициент значим.
= >1,96 → коэффициент значим.
4. Стандартная ошибка регрессии. Se=0,91, по сравнению со средним значением =34,5 ошибка невысокая, точность уравнения хорошая.
5. Коэффициент детерминации. R2 = rxy2=0,782=0,6084 не очень близко к 1, качество подгонки среднее.
6. Средняя ошибка аппроксимации. A=11%, качество подгонки уравнения среднее.
Экономическая интерпретация: при увеличении оборачиваемости оборотных средств предприятия на 1 раз в год средняя годовая прибыль увеличится на 5,86 млн. руб.
Тема 6. Нелинейная парная регрессия
Часто на практике между зависимой и независимыми переменными существует нелинейная форма взаимосвязи. В этом случае существует два выхода:
1) подобрать к анализируемым переменным преобразование, которое бы позволило представить существующую зависимость в виде линейной функции;
2) применить нелинейный метод наименьших квадратов.
Основные нелинейные регрессионные модели и приведение их к линейной форме
1. Экспоненциальное уравнение ![]() .
.
Если прологарифмировать левую и правую части данного уравнения, то получится
![]() .
.
Это уравнение является линейным, но вместо y в левой части стоит ln y.
В данном случае параметр β1 имеет следующий экономический смысл: при увеличении переменной x на единицу переменная y в среднем увеличится примерно на 100·β% (более точно: y увеличится в ![]() раз).
раз).
2. Логарифмическое уравнение ![]() .
.
Переход к линейному уравнению осуществляется заменой переменной x на X=lnx..
Параметр β1 имеет следующий экономический смысл: для увеличения y на единицу необходимо увеличить переменную x в ![]() раз, т. е. примерно на
раз, т. е. примерно на ![]() .
.
3. Гиперболическое уравнение ![]() .
.
В этом случае необходимо сделать замену переменных x на ![]() . Для гиперболической зависимости нет простой интерпретации коэффициента регрессии β1.
. Для гиперболической зависимости нет простой интерпретации коэффициента регрессии β1.
4. Степенное уравнение ![]() .
.
Прологарифмировав левую и правую части данного уравнения, получим
![]() .
.
Заменив соответствующие ряды их логарифмами, получится линейная регрессия.
Экономический смысл параметра β1: если значение переменной x увеличить на 1%, то y увеличится на β1%.
5. Показательное уравнение ![]() (β1>0, β1≠1).
(β1>0, β1≠1).
Прологарифмировав левую и правую части уравнения, получим
![]() .
.
Проведя замены Y=ln y и B1=ln β1, получится линейная регрессия.
Экономический смысл параметра β1: при увеличении переменной x на единицу переменная y в среднем увеличится в β1 раз.
Тема 7. Множественная линейная регрессия: определение и оценка параметров
1. Понятие множественной линейной регрессии
Модель множественной линейной регрессии является обобщением парной линейной регрессии и представляет собой следующее выражение:
![]() , t=1...n,
, t=1...n,
где yt – значение зависимой переменной для наблюдения t,
xit – значение i-й независимой переменной для наблюдения t,
εt – значение случайной ошибки для наблюдения t,
n – число наблюдений,
m – число независимых переменных x.
2. Матричная форма записи множественной линейной регрессии
Уравнение множественной линейной регрессии можно записать в матричной форме:
 ,
,
где  ,
,  ,
,  ,
, ![]() .
.
3. Основные предположения
1. x1t...xkt – детерминированные величины, причем векторы xi=(xi1...xin)T – линейно независимы в Rn;
2. ![]() для всех наблюдений;
для всех наблюдений;
3. ![]() = const для всех наблюдений;
= const для всех наблюдений;
4. ![]() ;
;
5. et~N(0,s2).
В случае выполнения вышеперечисленных гипотез модель называется нормальной линейной регрессионной.
4. Метод наименьших квадратов
Параметры уравнения множественной регрессии оцениваются, как и в парной регрессии, методом наименьших квадратов (МНК):  .
.
Чтобы найти минимум этой функции необходимо вычислить производные по каждому из параметров и приравнять их к нулю, в результате получается система уравнений, решение которой в матричном виде следующее:
 →
→  .
.
 ,
,

5. Теорема Гаусса-Маркова
Если выполнены предположения 1-5 из пункта 3, то оценки , полученные методом наименьших квадратов, имеют наименьшую дисперсию в классе линейных несмещенных оценок, то есть являются несмещенными, состоятельными и эффективными.
Тема 8. Множественная линейная регрессия: оценка качества
1. Общая схема проверки качества парной регрессии
Адекватность модели – остатки должны удовлетворять условиям теоремы Гаусса-Маркова.
Основные показатели качества коэффициентов регрессии:
1. Стандартные ошибки оценок (анализ точности определения оценок).
2. Интервальные оценки коэффициентов уравнения регрессии (построение доверительных интервалов).
3. Значимость коэффициентов регрессии (проверка гипотез относительно коэффициентов регрессии).
Основные показатели качества уравнения регрессии в целом:
1. Стандартная ошибка регрессии Se (анализ точности уравнения регрессии).
2. Значимость уравнения регрессии в целом (проверка гипотезы относительно всех коэффициентов регрессии).
3. Коэффициент детерминации R2 (проверка качества подгонки уравнения к исходным данным).
4. Скорректированный коэффициент детерминации R2adj (проверка качества подгонки уравнения к исходным данным).
5. Средняя ошибка аппроксимации (проверка качества подгонки уравнения к эмпирическим данным).
2. Стандартные ошибки оценок
Стандартные ошибки коэффициентов регрессии – это средние квадратические отклонения коэффициентов регрессии от их истинных значений.
 ,
,
где ![]()
![]() - диагональные элементы матрицы
- диагональные элементы матрицы  ,
,
 .
.
Стандартная ошибка является оценкой среднего квадратического отклонения коэффициента регрессии от его истинного значения. Чем меньше стандартная ошибка тем точнее оценка.
3. Интервальные оценки коэффициентов множественной линейной регрессии
Доверительные интервалы для коэффициентов регрессии определяются следующим образом:
1. Выбирается уровень доверия q (0,9; 0,95 или 0,99).
2. Рассчитывается уровень значимости g = 1 – q.
3. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
4. Определяется критическое значение t-статистики (tкр) по таблицам распределения Стьюдента на основе g и n – m – 1.
5. Рассчитывается доверительный интервал для параметра ![]() :
:
 .
.
Доверительный интервал показывает, что истинное значение параметра с вероятностью q находится в данных пределах.
Чем меньше доверительный интервал относительно коэффициента, тем точнее полученная оценка.
4. Значимость коэффициентов регрессии
Процедура оценки значимости коэффициентов осуществляется аналогичной парной регрессии следующим образом:
1. Рассчитывается значение t-статистики для коэффициента регрессии по формуле  .
.
2. Выбирается уровень доверия q ( 0,9; 0,95 или 0,99).
3. Рассчитывается уровень значимости g = 1 – q.
4. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
5. Определяется критическое значение t-статистики (tкр) по таблицам распределения Стьюдента на основе g и n – m – 1.
6. Если  , то коэффициент является значимым на уровне значимости g. В противном случае коэффициент не значим (на данном уровне g).
, то коэффициент является значимым на уровне значимости g. В противном случае коэффициент не значим (на данном уровне g).
t-тесты обеспечивают проверку значимости предельного вклада каждой переменной при допущении, что все остальные переменные уже включены в модель.
5. Стандартная ошибка регрессии
Стандартная ошибка регрессии Se показывает, насколько в среднем фактические значения зависимой переменной y отличаются от ее расчетных значений
 .
.
Используется как основная величина для измерения качества модели (чем она меньше, тем лучше).
Значения Se в однотипных моделях с разным числом наблюдений и (или) переменных сравнимы.
6. Оценка значимости уравнения регрессии в целом
Уравнение значимо, если есть достаточно высокая вероятность того, что существует хотя бы один коэффициент, отличный от нуля.
Имеются альтернативные гипотезы:
H0: b1=b2=…=bm=0 и
H1: b1≠0Úb2≠0Ú…Úbm≠0.
Если принимается гипотеза H0, то уравнение статистически незначимо. В противном случае говорят, что уравнение статистически значимо.
Значимость уравнения регрессии в целом осуществляется с помощью F-статистики.
Оценка значимости уравнения регрессии в целом основана на тождестве дисперсионного анализа:
![]() Þ
Þ
TSS – общая сумма квадратов отклонений
ESS – объясненная сумма квадратов отклонений
RSS – необъясненная сумма квадратов отклонений
F-статистика представляет собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную) к остаточной сумме квадратов (в расчете на одну степень свободы)

n – число выборочных наблюдений, m – число независимых переменных.
При отсутствии линейной зависимости между зависимой и независимой переменными F-статистика имеет F-распределение Фишера-Снедекора со степенями свободы k1 = m, k2 = n – m –1.
Процедура оценки значимости уравнения осуществляется следующим образом:
7. Рассчитывается значение F-статистики по формуле ![]() .
.
8. Выбирается уровень доверия q ( 0,9; 0,95 или 0,99).
9. Рассчитывается уровень значимости g = 1 – q.
10. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
11. Определяется критическое значение F-статистики (Fкр) по таблицам распределения Фишера на основе g и n – m – 1.
12. Если  , то уравнение является значимым на уровне значимости g. В противном случае уравнение не значимо (на данном уровне g).
, то уравнение является значимым на уровне значимости g. В противном случае уравнение не значимо (на данном уровне g).
В парной регрессии F-статистика равна квадрату t-статистики: ![]() , а значимость коэффициента регрессии и значимость уравнения в целом эквивалентны.
, а значимость коэффициента регрессии и значимость уравнения в целом эквивалентны.
7. Коэффициент детерминации R2
Качество оценки уравнения можно проверить путем расчета коэффициента детерминации R2, который показывает степень соответствия найденного уравнения экспериментальным данным.
 .
.
Коэффициент R2 показывает долю дисперсии переменной y, объясненную регрессией, в общей дисперсии y.
Коэффициент детерминации лежит в пределах 0 £ R2 £ 1.
Чем ближе R2 к 1, тем выше качество подгонки уравнения к статистическим данным.
Чем ближе R2 к 0, тем ниже качество подгонки уравнения к статистическим данным.
Коэффициенты R2 в разных моделях с разным числом наблюдений и переменных несравнимы.
8. Скорректированный коэффициент детерминации R2adj
Низкое значение R2 не свидетельствует о плохом качестве модели, и может объясняться наличием существенных факторов, не включенных в модель
R2 всегда увеличивается с включением новой переменной. Поэтому его необходимо корректировать, и рассчитывают скорректированный коэффициент детерминации
![]()
Если R2adj выходит за пределы интервала [0;1], то его использовать нельзя.
Если при добавлении новой переменной в модель увеличивается не только R2, но и R2adj, то можно считать, что вклад этой переменной в повышение качества модели существенен.
9. Средняя ошибка аппроксимации
Средняя ошибка аппроксимации (средняя абсолютная процентная ошибка) – показывает в процентах среднее отклонение расчетных значений зависимой переменной от фактических значений yi

Если A ≤ 10%, то качество подгонки уравнения считается хорошим. Чем меньше значение A, тем лучше.
10. Использование показателей качества коэффициентов и уравнения регрессии для интерпретации и корректировки модели
В случае незначимости уравнения, необходимо устранить ошибки модели. Наиболее распространенными являются следующие ошибки:
- неправильно выбран вид функции регрессии;
- в модель включены незначимые регрессоры;
- в модели отсутствуют значимые регрессоры.
После устранения ошибок требуется заново оценить параметры уравнения и его качество, продолжая этот процесс до тех пор, пока качество уравнения не станет удовлетворительным. Если после поделанных процедур, мы не достигли требуемого уровня значимости, то необходимо устранять другие ошибки (спецификации, классификации, наблюдения и т. д., см. тему 3, п. 6).
11. Интерпретация множественной линейной регрессии
Коэффициент регрессии ![]() при переменной xi показывает, на сколько увеличится среднее значение зависимой переменной y при увеличении xi на 1, при условии постоянства других переменных.
при переменной xi показывает, на сколько увеличится среднее значение зависимой переменной y при увеличении xi на 1, при условии постоянства других переменных.
12. Пример
В апреле 2006 года были собраны данные по стоимости 200 двухкомнатных квартир в Металлургическом районе г. Челябинска, их жилой площади, площади кухни и расстоянии до центра города (пл. Революции). Результаты наблюдения сведены в таблицу.
№ | Стоимость квартиры, тыс. руб. | Жилая площадь, м2 | Площадь кухни, м2 | Расстояние до центра, км |
1 | 1200 | 29 | 6 | 10,1 |
2 | 1220 | 30 | 8 | 10,1 |
3 | 1270 | 30 | 9 | 10,3 |
… | … | … | ||
198 | 1000 | 30 | 9 | 14,8 |
199 | 1020 | 30 | 7,5 | 14,8 |
200 | 1100 | 32 | 11 | 14,9 |
Требуется построить зависимость стоимости квартиры от трех факторов и оценить качество полученного уравнения.
Пусть y – стоимость квартиры, x1 – жилая площадь, x2 – площадь кухни, x3 – расстояние до центра.
y= b0+b1 x1 +b2 x2+b3 x3+e.
На основе исходных данных были рассчитаны следующие показатели:
=1160 тыс. р.
=30,7 м2
=7,7 м2
=12,7 км
b0=399
b1=16,5
b2=58,5
b3=–15,6
R2=0,54
![]()
Уровень доверия возьмем q=0,95 или 95%.
Следовательно, уравнение регрессии будет следующее
y= 399+16,5 x1 +58,5 x2–15,6 x3+e.
Проверка качества:
1. Стандартные ошибки оценок ![]() ,
, ![]() ,
, 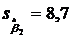 ,
, 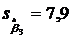 . Для b0 и b3 достаточно большие по сравнению с самими коэффициентами, следовательно, невысокая точность этих коэффициентов. Наиболее точным является b2, так как у него самая маленькая стандартная ошибка
. Для b0 и b3 достаточно большие по сравнению с самими коэффициентами, следовательно, невысокая точность этих коэффициентов. Наиболее точным является b2, так как у него самая маленькая стандартная ошибка 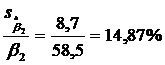 .
.
2. Интервальные оценки коэффициентов уравнения регрессии.
g = 1 – q =1 – 0,95 = 0,05;
n – 2 = 200 – 2 = 198;
tкр = 1,96;
b0: ![]() →
→ ![]() ;
;
b1: ![]() →
→ ![]() ;
;
b2: ![]() →
→ ![]() ;
;
b3: ![]() →
→ ![]() .
.
Таким образом, точность всех коэффициентов кроме b2 низкая.
3. Значимость коэффициентов регрессии.
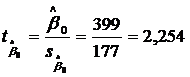 ;
; 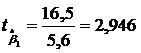 ;
; 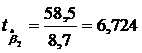 ;
; 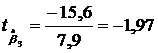 . Все |t| >1,96 → коэффициенты значимы.
. Все |t| >1,96 → коэффициенты значимы.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
