

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ЛЕКЦИИ ПО ДИСЦИПЛИНЕ «ЭКОНОМЕТРИКА»
(ЗАОЧНОЕ ОТДЕЛЕНИЕ)
Тема 1. Основные понятия, предмет, методы и задачи эконометрики
1. Определение эконометрики
Впервые название «эконометрика» было введено в 1926 г. норвежским экономистом и статистиком Рагнаром Фришем. В буквальном переводе этот термин означает «измерения в экономике». Существуют несколько подходов к пониманию эконометрики.
1. Эконометрика – это раздел экономики, занимающийся разработкой и применением статистических методов для измерений взаимосвязей между экономическими переменными (С. Фишер)
2. Основная задача эконометрики – наполнить эмпирическим содержанием априорные экономические рассуждения (Л. Клейн)
3. Эконометрика является не более чем набором инструментов, хотя и очень полезных. Она является одновременно нашим телескопом и нашим микроскопом для изучения окружающего экономического мира (Ц. Грилихес)
4. Цель эконометрики – эмпирический вывод экономических законов (Э. Маленво)
Таким образом, эконометрика – наука, позволяющая на базе экономической теории, статистики и методов математического моделирования придавать количественное выражение взаимосвязей экономических явлений и процессов.
2. Предметная область эконометрики
Экономистам требуется понять природу и функционирование экономических систем. Их интересуют глобальные или макровеличины (ВВП, занятость и др.), а также отрасли, регионы, домашние хозяйства.
На уровне мезо - и микроэкономики в теории и хозяйственной практике также встречаются задачи, требующие определения взаимосвязей экономических показателей (зависимость цены продукции от рыночных факторов, связь рентабельности предприятия с основными производственными и финансовыми показателями).
При этом нас интересует не только выявление объективно существующих (на качественном уровне) экономических законов и связей между экономическими показателями, но и подходы к их формализации, включающие в себя методы спецификации соответствующих моделей с учетом проблемы их идентифицируемости.
При рассмотрении статистики, как составной части эконометрики нас интересует лишь тот ее аспект, который непосредственно связан с информационным обеспечением анализируемой эконометрической модели, хотя в эконометрике зачастую приходится решать полный спектр соответствующих задач: выбор необходимых экономических показателей и обоснование способа их измерения, определение плана статистического обследования и т. п.
3. Задачи эконометрики
По конечным прикладным целям выделим три основные группы задач:
1. Прогноз социально-экономических показателей (переменных), характеризующих состояние и развитие анализируемой системы.
2. Имитация возможных сценариев развития.
3. Исследование текущего состояния анализируемой системы.
Одна из целей состоит в том, чтобы сделать условные прогнозы о поведении предметов и процессов. Условные прогнозы помогают фирмам, потребителям и правительствам принять решения и изменить результаты.
Другая важная цель состоит в том, чтобы проверить экономическую теорию – разработать базу понимания, адекватную реальной ситуации.
Эконометрические модели широко применяются в бизнесе, экономике, общественных науках, исследовании экономической активности и в исследовании политических процессов. Они полезны для более полного понимания сущности происходящих процессов, их анализа.
Модель, построенная и верифицированная на основе (уже имеющихся) наблюденных значений объясняющих переменных, может быть использована для прогноза состояния и развития исследуемых процессов в будущем или для объяснения поведения системы в зависимости от влияния различных факторов.
4. Понятие экономической системы
Система – это объективное единство закономерно связанных друг с другом предметов и явлений.
Элемент системы – простейшая неделимая часть системы. Элемент системы не способен к самостоятельному существованию и не может быть описан вне его функциональных характеристик.
Важным свойством системы является иерархичность – возможность представить каждую систему как подсистему или элемент системы более высокого уровня. В свою очередь, каждая подсистема может рассматриваться как самостоятельная система.
Основным свойством системы, выделяющим ее из простой совокупности элементов, является целостность. Целостность – принципиальная несводимость свойств системы к сумме свойств ее элементов, а также невыводимость свойств системы из свойств ее элементов.
Экономическая система – система, элементами которой являются экономические категории – ресурсы, индивидуумы и социальные группы, производительные силы, производственные отношения, средства и предметы труда, факторы производства связанные между собой взаимосвязями, определенными в предметной области экономики – денежными, инвестиционными, информационными потоками.
5. Понятие модели экономической системы
Модель – это упрощенное, идеализированное представление процессов реального мира. Модель должна быть простой, чтобы её легко было обработать, но достаточно общей, чтобы быть полезной.
Модели упрощают реальность и имеют целью сбор только фундаментальных признаков системы. Однако, тезис о том, что спрос на апельсины зависит только от цены, является слишком упрощенным, а также нереалистичным утверждением.
Поэтому необходимо подбирать такое число параметров модели, которые адекватно описывают существующую экономическую систему и в то же время не включают в себя избыточных составляющих. Задача построения модели спроса на апельсины с учетом влияния химического состава, цвета, размера, наличия косточек и т. п. факторов так же является нереальной.
6. Типы данных
Данные, с которыми приходится работать эконометристам, делятся на три типа:
1. Пространственные данные (cross-section data).
Тип данных во многом определяет методику их оценки. Примерами пространственных данных являются финансовые отчеты предприятий за определенный квартал или год, результаты обследования домашних хозяйств за период, данные о ВВП различных стран в каком-либо конкретном году, и т. п., - то есть это данные об однородных объектах за один и тот же период времени.
2. Временные ряды (time series).
Примерами временных рядов являются ежедневные значения курса доллара по отношению к рублю за период с 1 января 1992 г. до 22 сентября 2002 г., значения ВВП России за год в период с 1992 до 2002 г., и т. п., - то есть последовательные значения одной экономической переменной в различные периоды времени.
3. Панельные данные (panel data).
Панельные данные – это до некоторой степени обобщение временных рядов и пространственных данных. Например, если с одних и те же предприятий каждый год собираются одни и те же показатели их хозяйственной деятельности, получится массив данных, в котором содержатся и данные об однородных объектах за один и тот же период времени, и последовательные значения одной экономической переменной в различные периоды времени.
7. Основные эконометрические модели
Можно выделить три основных класса моделей, которые чаще всего применяются в эконометрике:
1. Модели временных рядов.
К классу моделей временных рядов относятся модели, общей чертой которых является то, что они объясняют поведение временного ряда, исходя только из его предыдущих значений. Такие модели могут применяться, например, для прогнозирования объемов продаж, спроса, изменения курса акций и т. п.
2. Регрессионные модели с одним уравнением.
В регрессионных моделях с одним уравнением зависимая переменная у представляется в виде функции f(x, b) = f(x1…xk, b1…bp), где x1…xk – независимые переменные, b1…bp –параметры. В зависимости от вида функции f(x, b) модели делятся на линейные и нелинейные.
3. Системы регрессионных уравнений.
Системы уравнений состоят из совокупности тождеств, регрессионных уравнений и ограничений на функционирование описываемой экономической системы, представленных в виде неравенств.
В большинстве случаев экономические законы выражаются в относительно простой математической форме.
8. Этапы эконометрического моделирования
В общем виде последовательность построения эконометрических моделей можно представить в виде следующей схемы (рис.1).


Рис.1. Схема эконометрического исследования
Вообще построение эконометрической модели подразделяется на шесть основных этапов:
1. Постановка задачи – определение конечных целей моделирования, набора участвующих в модели факторов и показателей, их роли.
2. Анализ предметной области – предмодельный анализ экономической сущности изучаемого явления, формирование и формализация априорной информации.
3. Формулировка модели (спецификация) – выбор общего вида модели, и состава входящих в нее переменных.
4. Сбор данных – сбор необходимой статистической информации, т. е. регистрация значений участвующих в модели факторов и показателей на различных временных или пространственных тактах функционирования изучаемого явления.
5. Оценка параметров модели – статистическое оценивание неизвестных параметров модели и статистический анализ модели.
6. Оценка качества модели – сопоставление реальных и модельных данных, проверка адекватности модели, оценка точности модельных данных.
7. Интерпретация результатов – формулирование экономических выводов об изучаемом объекте и сопоставление их с теоретическими результатами и результатами других исследований.
9. Примеры
Функция потребления:
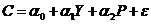
где С – потребление некоторого пищевого продукта на душу населения в некотором году, Y – реальный доход на душу населения в этом году, а Р – индекс цен на этот продукт, скорректированный (дефлированный) на общий индекс стоимости жизни; a0, a1, a2 — константы.
Производственная функция Кобба-Дугласа:
Q=A×Ka×Lb,
где А, a, b - параметры модели. Величина А зависит от единиц измерения Q, К и L, а также от эффективности производственного процесса.
Параметры a и b называют коэффициентами эластичности. Они показывают, на сколько процентов в среднем изменится Q, если a или b увеличить соответственно на один процент.
Кривая Филипса описывает связь темпа роста зарплаты и уровня безработицы:
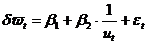 ,
,
где ![]() - уровень заработной платы;
- уровень заработной платы; ![]() - темп роста зарплаты (в %);
- темп роста зарплаты (в %); ![]() - процент безработных в год t.
- процент безработных в год t.
Тема 2. Элементарные понятия и определения теории вероятностей и математической статистики
Случайная величина X – числовая функция, заданная на некотором вероятностном пространстве.
Функция распределения случайной величины X – числовая функция числового аргумента, определяемая равенством f(x)=P(X£x), xÎR
Случайные величины могут быть дискретными и непрерывными.
Дискретная случайная величина – если множество ее значений конечно или счетно.
Непрерывная случайная величина – если функция ее распределения дифференцируема, то есть существует производная p(x)=f’(x), называемая плотностью случайной величины X.
В эконометрике используются дискретные случайные величины, значения которых, как правило, задаются выборочными значениями.
Пусть X1,...,Хn, Y1,...,Yn,– случайные выборки:
- выборочное среднее ;
- выборочная дисперсия ;
- выборочная ковариация ;
- парный коэффициент корреляции ![]() .
.
Парный коэффициент корреляции характеризует тесноту линейной зависимости между двумя случайными величинами.
-1≤rxy≤1,
чем ближе rxy к границам отрезка, тем сильнее связь X и Y;
чем ближе rxy к 0, тем слабее связь X и Y.
Если rxy>0, то между рассматриваемыми случайными величинами существует положительная связь (увеличение одного показателя приводит к увеличению другого);
если rxy <0, то связь отрицательная.
Коэффициент корреляции позволяет выявлять только линейные зависимости между случайными величинами
Распределение непрерывной случайной величины x называют нормальным ( ), если соответствующая ей плотность распределения равна
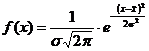 .
.
Случайная величина x распределена по стандартному нормальному закону распределения, если
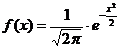 .
.
Тема 3. Общий вид регрессионной модели
1. Понятие регрессии
Регрессионный анализ занимает центральное место во всем математико-статистическом инструментарии эконометрики.
Регрессия – функциональная зависимость между объясняющими переменными и средним значением зависимой переменной, которая строится с целью прогнозирования этого среднего значения при фиксированных значениях объясняющих переменных.
Регрессионное уравнение представляет собой зависимость вида:
.
2. Зависимая переменная
Переменная Y называется зависимой, она характеризует результат или эффективность функционирования анализируемой экономической системы. Ее значения формируются в процессе функционирования этой системы под воздействием ряда других переменных и факторов, часть из которых поддается регистрации и, в определенной степени, управлению и планированию.
В регрессионном анализе результирующая переменная выступает в роли функции, значения которой определяются значениями независимых переменных с некоторой случайной погрешностью, выступающих в роли аргументов. Поэтому по природе своей результирующая переменная Y всегда стохастична (случайна).
Пример:
Изучается зависимость Y – объема продаж холодильников от X1 цены реализации, X2 объема вложений, направленных на улучшение потребительских свойств продукции (энергосбережение, дизайн, дополнительные функции) и X3 вложений в сервисное обслуживание покупателей (открытие и оборудование сервис-центров, организация бесплатной доставки, затраты на гарантийное обслуживание).
В данном случае Y – является результатом функционирования экономической системы производства и сбыта продукции. Y не поддается детерминированному планированию и управлению, поскольку частично определяется внешними факторами: уровнем спроса и наличием конкуренции. По этой же причине, а также в связи с возможностью возникновения ошибок Y является случайной.
3. Независимые переменные
Переменные X=(x1,…,xn) называются независимыми (объясняющими, регрессорами). Они поддаются регистрации, описывают условия функционирования изучаемой реальной экономической системы и в существенной мере определяют процесс формирования значений результирующих переменных. Как правило, часть из них поддается хотя бы частичному регулированию и управлению.
В регрессионном анализе они играют роль аргументов той функции, в качестве которой рассматривается анализируемый результирующий показатель Y. Объясняющие переменные могут быть как случайными, так и неслучайными.
Пример:
В современных западных теориях менеджмента и маркетинга определяется модель рассматриваемой системы, в которой в качестве основных ее элементов, влияющих на объем сбыта продукции выделяются цена, качество, сервис. При этом одновременно поддаются управлению только два любых фактора из трех.
4. Параметры регрессии
Величины a=(a1,…,an) называют параметрами или коэффициентами регрессии. Они характеризуют веса факторов X в регрессионной модели.
Пример:
Переменные влияют на результат не одинаково в зависимости от региональных условий сбыта. Коэффициенты a1, a2, a3 показывают уровень влияния каждого из факторов на результат.
5. Функция регрессии
Функция f(X) называется функцией регрессии Y по Х (или просто – регрессией Y по X), если она описывает изменение условного среднего значения результирующей переменной Y в зависимости от изменения значений объясняющих переменных X.
6. Случайная ошибка
Присутствие случайной «остаточной» составляющей («регрессионных остатков») e(Х) может быть обусловлено различными причинами:
1) отсутствие в регрессии факторов X влияющих на формирование значений Y;
2) присутствие в регрессии факторов X не влияющих на формирование значений Y;
3) неправильный выбор функциональной формы модели (если мы предположили линейную форму модели, а между переменными существует более сложная связь, то ошибка увеличится);
4) агрегирование переменных (факторы представляют собой комбинацию других переменных);
5) ошибки измерений (описки при сборе и записи данных или округление данных также увеличит ошибку);
6) ограниченность статистических данных (зачастую компании не имеют возможности отслеживать данные по всем филиалам, кроме того, если компания функционирует непродолжительное время, наблюдений может оказаться недостаточно);
7) влияние человеческого фактора (могут проявиться субъективные пристрастия как потребителей при покупке холодильников, так и исследователя при описании модели и сборе данных).
7. Типы ошибок
Ошибки классификации возникают, когда в состав генеральной совокупности не включены объекты, которые на самом деле к ней относятся.
Ошибки спецификации имеют место при неправильном отборе объектов (включении в генеральную совокупность таких объектов, которые на самом деле к ней не относятся) или факторов, влияющих на исследуемую характеристику (объясняющих переменных). Такие ошибки часто обусловлены недостатками в теоретическом анализе рассматриваемых явлений.
Ошибки модели проявляются в неправильном выборе вида искомой зависимости (например, отыскивается линейная зависимость между характеристиками в то время, как на самом деле они связаны степенной зависимостью).
8. Виды регрессионных уравнений
Наиболее часто используются следующие виды уравнений:
1. Парная линейная регрессия ![]()
2. Множественная линейная регрессия ![]()
3. Полиномиальное уравнение ![]()
4. Степенное уравнение ![]() .
.
5. Показательное уравнение ![]() (βi>0, βi≠1)
(βi>0, βi≠1)
6. Экспоненциальное уравнение ![]() .
.
7. Логарифмическое уравнение ![]() .
.
8. Гиперболическое уравнение 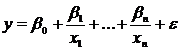 .
.
Тема 4. Парная линейная регрессия: оценка параметров
1. Понятие парной линейной регрессии
Парная линейная регрессия – регрессия между двумя случайными переменными, связанными линейным соотношением: Y=a +b X +e, при этом предполагается, что e~N(0,s).
2. Графическое представление парной линейной регрессии
Парная регрессия легко определяется по графическому изображению реальных статистических данных в виде точек (корреляционное поле или диаграмма рассеивания).
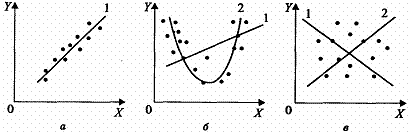
Рис 1. Диаграммы рассеивания статистических наблюдений
а) Взаимосвязь между Y и X близка к линейной: Y = a + bX
б) Взаимосвязь близка к квадратической: Y = a + bX + gX2
в) Взаимосвязь между Y и X отсутствует. Какую бы мы ни выбрали форму связи, результаты проверки ее качества будут неудачными.
На рис. 1а) показано облако наблюдений, соответствующее парной линейной регрессии.
3. Проблема оценки коэффициентов регрессии
По выборке ограниченного объема нельзя точно определить теоретические значения a и b. Можно лишь построить эмпирическое уравнение регрессии:
,
где ![]() ,
, ![]() - оценки параметров.
- оценки параметров.
В результате имеем:
где e – оценка теоретического случайного отклонения e .
Оценки ![]() ,
, ![]() отличаются от истинных значений a и b, что приводит к несовпадению эмпирической и теоретической линий регрессии. По различным выборкам из одной и той же генеральной совокупности получают разные значения оценок коэффициентов регрессии.
отличаются от истинных значений a и b, что приводит к несовпадению эмпирической и теоретической линий регрессии. По различным выборкам из одной и той же генеральной совокупности получают разные значения оценок коэффициентов регрессии.
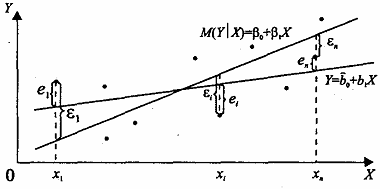
Рис. 2. Эмпирическая и теоретическая линии регрессии
Задача состоит в нахождении по выборке данных оценок a и b так, чтобы построенная линия регрессии была наилучшей в определенном смысле среди всех других прямых.
4. Метод наименьших квадратов
Мы хотим найти уравнение вида , то есть, получить теоретические значения результативного признака Y, подставляя в него фактические значения X. Оценки параметров линейной регрессии могут быть найдены разными методами.
Классический подход к оцениванию параметров линейной регрессии основан на методе наименьших квадратов (МНК). МНК позволяет получить такие оценки параметров a и b, при которых сумма квадратов отклонений фактических значений зависимой переменной X от расчетных (теоретических) минимальна:
.
Фактически, метод наименьших квадратов позволяет минимизировать ошибки: .
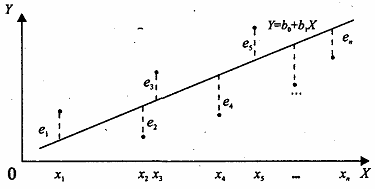
Рис. 3. Графическое представление линии регрессии с МНК-параметрами
5. Вычисление МНК-оценок для парной линейной регрессии
Решим задачу минимизации: 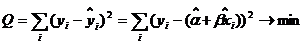 .
.
Чтобы найти минимум этой функции необходимо вычислить производные по каждому из параметров и приравнять их к нулю:
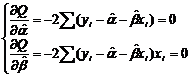 Þ
Þ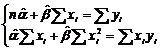 Þ
Þ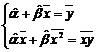
Решая эту систему, найдем искомые значения оценок :
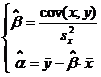
6. Свойства МНК-оценок
Оценки принято обозначать символом параметра с крышечкой: ![]() .
.
Оценки коэффициентов уравнения регрессии, полученные методом наименьших квадратов могут обладать следующими свойствами:
1. Несмещенность - .
2. Состоятельность - .
3. Эффективность - , , где a’, b’ – любые другие оценки для a и b.
Содержательно несмещенность оценки означает, что при ее использовании мы не получаем систематической ошибки; состоятельность оценки гарантирует приближение оценки к истинному значению параметра при увеличении объема выборки, а эффективная оценка является наилучшей в смысле минимума среднеквадратичного отклонения. В классе несмещенных оценок эффективность означает минимальность дисперсии.
7. Теорема Гаусса-Маркова:
Если выполнены следующие условия
1) ![]() для всех наблюдений;
для всех наблюдений;
2) ![]() = const для всех наблюдений;
= const для всех наблюдений;
3) ![]() ;
;
4) et~N(0,s2), то оценки ![]() , полученные методом наименьших квадратов, имеют наименьшую дисперсию в классе всех линейных несмещенных оценок, то есть являются несмещенными, состоятельными и эффективными.
, полученные методом наименьших квадратов, имеют наименьшую дисперсию в классе всех линейных несмещенных оценок, то есть являются несмещенными, состоятельными и эффективными.
Привести картинки, показывающие нарушение условий Гаусса-Маркова.
Наряду с перечисленными условиями обычно также предполагается:
- число наблюдений существенно больше числа объясняющих переменных;
- отсутствуют ошибки спецификации;
- случайное отклонение независимо от объясняющей переменной.
Тема 5. Парная линейная регрессия: проверка качества
1. Проблемы использования уравнения регрессии
После определения оценок возникают вопросы:
- насколько точны и надежны найденные оценки;
- насколько точно эмпирическое уравнение регрессии соответствует уравнению для всей генеральной совокупности;
- насколько близки оценки к своим теоретическим значениям a и b.
Для ответа на эти вопросы рассчитываются и проверяются ряд показателей и гипотез.
2. Общая схема проверки качества парной регрессии
Адекватность модели – остатки должны удовлетворять условиям теоремы Гаусса-Маркова.
Основные показатели качества коэффициентов регрессии:
1. Стандартные ошибки оценок (анализ точности определения оценок).
2. Интервальные оценки коэффициентов уравнения регрессии (построение доверительных интервалов).
3. Значимость коэффициентов регрессии (проверка гипотез относительно коэффициентов регрессии).
Основные показатели качества уравнения регрессии в целом:
1. Стандартная ошибка регрессии Se (анализ точности уравнения регрессии).
2. Коэффициент детерминации R2 (проверка качества подгонки уравнения к эмпирическим данным).
3. Средняя ошибка аппроксимации (проверка качества подгонки уравнения к эмпирическим данным).
3. Стандартные ошибки коэффициентов
Оценки являются случайными величинами. Отсюда следует, что стандартные ошибки коэффициентов регрессии – это средние квадратические отклонения коэффициентов регрессии от их истинных значений.
Стандартные ошибки коэффициентов регрессии:
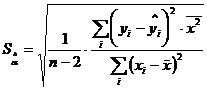 ,
,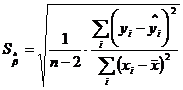
Стандартная ошибка является оценкой среднего квадратического отклонения коэффициента регрессии от его истинного значения. Чем меньше стандартная ошибка тем точнее оценка.
4. Интервальные оценки коэффициентов
На практике часто важно знать возможные значения параметров . Так как истинные значения параметров не известны, то о них можно судить приближенно. Для это рассчитываются доверительные интервалы.
Доверительные интервалы для коэффициентов регрессии определяются следующим образом:
1. Выбирается уровень доверия q. Обычно он близок к 1, например, 0,9; 0,95 или 0,99.
2. Рассчитывается уровень значимости g = 1 – q.
3. Рассчитывается число степеней свободы n – 2, где n – число наблюдений.
4. Определяется критическое значение t-статистики (tкр) по таблицам распределения Стьюдента на основе g и n – 2.
5. Рассчитываются доверительные интервалы для параметров .
α: 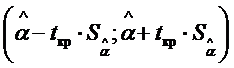 ,
,
β: 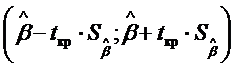 .
.
Доверительный интервал показывает, что истинное значение параметра с вероятностью q находится в данных пределах.
Чем меньше доверительный интервал относительно коэффициента, тем точнее полученная оценка.
5. Значимость коэффициентов регрессии
Коэффициент значим, если есть достаточно высокая вероятность того, что его истинное значение отлично от нуля.
Имеются альтернативные гипотезы: H0: b=0 и H1: b≠0.
Если принимается гипотеза H0, то считают, что величина Y не зависит от X. В этом случае говорят, что коэффициент b статистически незначим (т. к. слишком близок к нулю). В противном случае говорят, что коэффициент b статистически значим, что указывает на наличие линейной зависимости между Y и X.
Для определения уровня значимости коэффициента используется t-статистика, которая соизмеряет значение коэффициента с его стандартной ошибкой.
Процедура оценки значимости коэффициентов осуществляется следующим образом:
1. Рассчитывается значение t-статистики для коэффициента регрессии по формуле  или
или  .
.
2. Выбирается уровень доверия q. Обычно он близок к 1, например, 0,9; 0,95 или 0,99.
3. Рассчитывается уровень значимости g = 1 – q.
4. Рассчитывается число степеней свободы n – 2, где n – число наблюдений.
5. Определяется критическое значение t-статистики (tкр) по таблицам распределения Стьюдента на основе g и n – 2.
6. Если 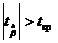 , то коэффициент является значимым на уровне значимости g. В противном случае коэффициент не значим (на данном уровне g).
, то коэффициент является значимым на уровне значимости g. В противном случае коэффициент не значим (на данном уровне g).
6. Стандартная ошибка регрессии
Стандартная ошибка регрессии Se показывает, насколько в среднем фактические значения зависимой переменной y отличаются от ее расчетных значений
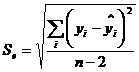 .
.
Используется как основная величина для измерения качества модели (чем она меньше, тем лучше).
7. Оценка значимости уравнения регрессии в целом
Уравнение значимо, если есть достаточно высокая вероятность того, что существует хотя бы один коэффициент, отличный от нуля.
Имеются альтернативные гипотезы:
H0: α=b=0 и
H1: α≠0Úb≠0≠0.
Если принимается гипотеза H0, то уравнение статистически незначимо. В противном случае говорят, что уравнение статистически значимо.
Процедура оценки значимости уравнения парной регрессии осуществляется следующим образом:
1. Рассчитывается значение F-статистики по формуле ![]() .
.
2. Выбирается уровень доверия q (0,9; 0,95 или 0,99).
3. Рассчитывается уровень значимости g = 1 – q.
4. Рассчитывается число степеней свободы n – 2, где n – число наблюдений.
5. Определяется критическое значение F-статистики (Fкр) по таблицам распределения Фишера на основе g и n – 2.
6. Если  , то уравнение является значимым на уровне значимости g. В противном случае уравнение не значимо (на данном уровне g).
, то уравнение является значимым на уровне значимости g. В противном случае уравнение не значимо (на данном уровне g).
В парной регрессии значимость коэффициента регрессии β и значимость уравнения в целом эквивалентны.
8. Коэффициент детерминации R2
Для проверки качества подгонки уравнения к исходным данным значений y, то есть насколько хорошо уравнение регрессии согласуется со статистическими данными, используется коэффициент детерминации R2
 .
.
Коэффициент R2 показывает долю дисперсии переменной y, объясненную регрессией, в общей дисперсии y.
Коэффициент детерминации лежит в пределах 0 £ R2 £ 1.
Чем ближе R2 к 1, тем выше качество подгонки уравнения к статистическим данным.
Если R2 = 1, то статистические данные лежат на линии регрессии, т. е. между зависимой и объясняющими переменными имеется функциональная зависимость.
Чем ближе R2 к 0, тем ниже качество подгонки уравнения к статистическим данным.
В случае парной регрессии R2 = rxy2.
Например, если R2 =0,85, то говорят, что на 85% изменение y описывается полученным уравнением и влиянием переменной x, а 15% изменения y – следствие влияния неучтенных в уравнении регрессии факторов.
9. Средняя ошибка аппроксимации
Оценку качества модели дает также средняя ошибка аппроксимации (средняя абсолютная процентная ошибка) – показывает в процентах среднее отклонение расчетных значений зависимой переменной от фактических значений yi

Если A ≤ 10%, то качество подгонки уравнения считается хорошим. Чем меньше значение A, тем лучше.
10. Интерпретация парной линейной регрессии
Параметр показывает, насколько изменится среднее значение Y при увеличении X на единицу.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
