
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
СХЕМА СЖАТИЯ ЦВЕТНЫХ ИЗОБРАЖЕНИЙ С ПРИМЕНЕНИЕМ адаптивного двоичного арифметического кодирования
, студент кафедры безопасности информационных систем ГУАП, *****@***com
, студент кафедры безопасности информационных систем ГУАП, sokolovskiy. *****@***com.
Аннотация
В работе была предложена схема кодирования изображений без потерь на основе бинаризации и контекстного моделирования с использованием двоичного арифметического кодирования. Приведены результаты экспериментов, подтверждающие эффективность вносимых улучшений. Представлено сравнение улучшенной схемы с существующими решениями.
Введение
В современном мире во многих областях деятельности требуется работать с изображениями в высоком разрешении. В частности такие изображения используются в медицине. Данные изображения, как правило, занимают значительное место на жестком диске и требуют сжатия. При этом операция сжатия должна быть полностью обратимой, т. е. мы должны иметь возможность восстановления исходного изображения без потерь.
При сжатии изображений без потерь приходится сталкиваться с двумя основными проблемами:
1. наличие избыточности, обусловленной статистической зависимостью кодируемых данных. В цветных изображениях будем выделять пространственную (между пикселями одной компоненты) и межкомпонентную избыточность;
2. нестационарность потоков данных, обусловленная изменением статистических свойств.
В рамках данной работы будут рассмотрены типовое решение и ряд улучшений для уже существующей схемы сжатия без потерь, учитывающих статистические особенности медицинских цветных изображений.
2. Обзор существующих подходов к кодированию цветных изображений без потерь
В качестве типового решения рассмотрим схему кодирования, представленную на Рис. 1.
 Рисунок 1: Типовая схема кодирования изображений без потерь.
Рисунок 1: Типовая схема кодирования изображений без потерь.
Схема предсказания отвечает за решение проблемы избыточности данных. В результате кодироваться будет не само значение кодируемой величины, а разность между ним и предсказанным значением.
Схема кодирования решает проблемы избыточности и нестационарности данных. Для решения описанных проблем в схеме кодирования используется процедура контекстного моделирования с последующей адаптацией к нестационарности потоков данных. Под контекстной моделью на этапе энтропийного кодирования понимается правило присвоения вероятности текущему символу на основе некоторой предыстории.
Среди существующих решений можно выделить двух лидеров:
· JPEG-LS [1] – кодек для сжатия изображений. Показал высокую эффективность при сжатии медицинских изображений. Время работы кодека существенно меньше, чем у альтернативных решений.
· PAQ [2] – универсальный кодек для сжатия данных. Показал наивысшие результаты при сжатии медицинских изображений. Время работы на порядок больше, чем у конкурентов.
В рамках предыдущей работы [3] была доказана эффективность использования декоррелирующих цветовых преобразований совместно с JPEG-LS кодеком. В данной работе за основу берется схема с альтернативным предсказанием Inter Component Prediction (ICP) [4] и схема кодирования JPEG-LS кодека с отключенным пространственным предсказанием. Данная схема представлена на Рис. 2.
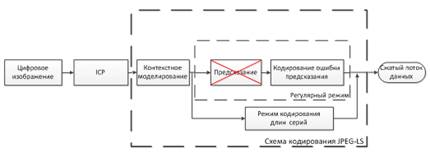 Рисунок 2: Базовая схема кодирования.
Рисунок 2: Базовая схема кодирования.
3. Улучшения схемы кодирования изображений без потерь
В качестве улучшений к существующей схеме кодирования было предложено:
1. добавление процедуры двоичного адаптивного арифметического кодирования;
2. изменение существующей процедуры определения контекста;
3. изменение режима кодирования длин серий.
2.1. Добавление процедуры двоичного арифметического адаптивного кодирования
Для работы арифметического кодирования необходима оценка вероятностей для каждого кодируемого символа. Способ получения оценок вероятностей не регламентирован и может быть выбран с учетом нестационарности потока данных и отличительных статистических особенностей кодируемого источника. Оценка вероятности появления кодируемого символа производится по формуле (1) Кричевского-Трофимова [5], где ni – это счётчик попадания i-го символа в контекст. Для учёта нестационарности статистических характеристик обрабатываемого потока используется схема с экспоненциальным забыванием [6]. В рамках этой схемы при достижении порогового значения производится уменьшение счётчиков попадания символов в контекст в несколько раз. Подобная схема уменьшает влияние предыдущей статистики по экспоненциальному закону, что позволяет энтропийному кодеку приспосабливаться к изменениям статистики в потоке.
| (1) |
Двоичное арифметическое кодирование используется в виду вычислительной простоты по сравнению с недвоичным арифметическим кодированием. Также существуют уже описанные эффективные реализации двоичного арифметического кодирования [7]. Но при переходе к использованию двоичного арифметического кодера для кодирования символов недвоичного источника данных необходимо вводить процедуру бинаризации – представления кодируемых символов в виде строки двоичных символов.
При использовании арифметического кодирования ключевым параметром эффективности бинаризации будет сумма энтропий кодируемых двоичных источников, а не средняя длина двоичной последовательности бинаризированного источника В качестве бинаризации возможно использование унарного кода, так как для данного способа доказана справедливость равенства из формулы (2).
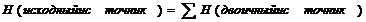 (2)
(2)
Унарный код - двоичный префиксный код переменной длины для представления натуральных чисел. Операция кодирования унарным кодом некоторого числа показана на Рис. 3.

Рисунок 3: Кодирование унарным кодом.
2.2. Изменение существующей процедуры контекстного моделирования
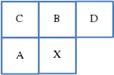
Рисунок 4: Контекст рассматриваемого значения Х.
В кодеке JPEG-LS контекстное моделирование производится на основе квантованных значений локальных градиентов (3) соседних пикселей, представленных на Рисунке 4. Квантованные градиенты формируют 365 контекстов. Моделирование выполняется на этапе предсказания и является его частью.
| (3) |
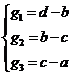
При переходе к новой схеме предсказания ICP исчезла необходимость в коррекции ошибок предсказания: гистограмма ошибок имеет чётко выраженную концентрацию в нуле. Значение ошибки предсказания кодируется в следующем контексте:
| (4) |
где BC(x) – это индекс старшего значащего бита числа 'x', который будем называть битовой категорией. Битовая категория для ошибок предсказания может принимать девять различных значений, поэтому для кодирования ошибок предсказания используется девять контекстных потоков.
2.3. Изменение режима кодирования длин серий
Режим кодирования длин серий используется для эффективного кодирования повторяющихся значений. При использовании этого режима в битовый поток укладывается информация о значении текущего символа и о количестве его повторений.
Благодаря эффективной работе схемы предсказания в кодируемом потоке данных наблюдается группировка множественных нулевых значений. Режим кодирования длин серий был скорректирован для обработки таких последовательностей.
Был также изменён блок принятия решений относительно использования режима кодирования длин серий: для каждой компоненты решение принимается на основе её статистических свойств. Кодирование длин серий используется в случае, если диспепрсия значений ошибок внутри компоненты оказывается ниже некоторого порога.
4. Результаты проведенных экспериментов
Предлагаемая схема кодирования представлена на Рис. 5.
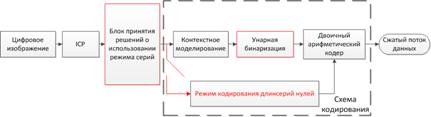
Рисунок 5: Предлагаемая схема кодирования.
Представленная схема проходила проверку на тестовом множестве, состоящем из 332 изображений:
• 95 оригинальных медицинских изображений (кардиограммы, МРТ, рентгеновские снимки);
• 95 уменьшенных и 95 увеличенных в несколько раз копий медицинских изображений;
• 41 цветных фотореалистичных изображений.
Результаты проведенных экспериментов приведены в таблице 1.
Дополнения к схеме кодирования | Размер сжатого тестового множества (байт) | TG (Х, JPEG-LS), % | Время обработки тестового множества |
JPEG-LS + цветовое преобразование | 38,7 | 6 мин | |
JPEG-LS + ICP | 41,4 | 13 мин | |
Предлагаемая схема | 45,4 | 14 мин | |
PAQ | 54,5 | 5ч. 35мин. |
Таблица 1: Результаты сжатия опробованных схем кодирования.
Оценка выигрыша по сжатию рассматриваемого кодека производилась согласно формуле (5).
![]() (5)
(5)
где Total Gain(TG) – величина, отражающая выигрыш кодека X по сжатию в процентах относительно кодека JPEG-LS.
Заключение
В данной работе были представлены методы улучшения схемы кодирования, связанные с применением процедуры адаптивного двоичного арифметического кодирования и изменением контекстного моделирования. Как видно из результатов экспериментов, эффективность сжатия предлагаемой схемы приблизилась к результатам PAQ, но при этом сохраняет существенное преимущество в скорости.
Литература
1. ITU-T Recommendation T.87/ISO 14495-1 “Information technology – Lossless and near-lossless compression of continuous-tone still images – Baseline”,
2. Matthew V. Mahoney, “The PAQ1 Data Compression Program”, Draft, Jan. 20, 2002, revised Mar. 19.
3. “Анализ обратимых преобразований компонент цветных изображений”, ГУАП, СНК 2012
4. “Метод сжатия цветных изображений без потерь”, ГУАП, СНК 2012.
5. R. E. Krichevski and V. E. Trofimov, “The performance of universal encoding” IEEE Trans. Inform. Theory, vol. IT-27, pp 199-207, Mar. 1981.
6. Eado Meron, Meir Feder, Fellow, “Finite-Memory Universal Prediction of Individual Sequences”, IEEE Transactions on Information Theory, vol. 50, NO.7, JULY 2004, pp
7. Detlev Marpe, Heiko Schwarz, and Thomas Wiegand “Context-Based Adaptive Binary Arithmetic Coding in the H.264/AVC Video Compression Standard”, IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 13, NO. 7, JULY 2003
