

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
|
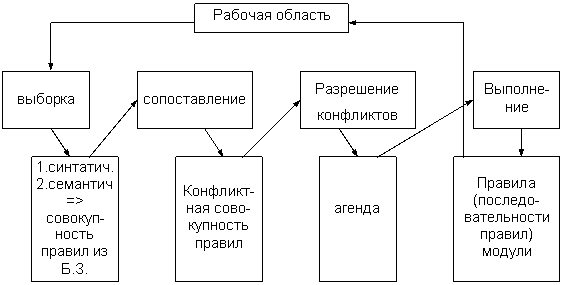
Этап выполнения интерпретации заключается в выполнении следующих действий: выборка, сопоставление, разрешение конфликтов, выполнение.
Выборка осуществляется двумя фазами:
· синтаксическая фаза выборки;
· семантическая фаза выборки.
Результат выборки - совокупность активных правил из базы знаний.
Синтаксическая выборка - это грубое определение правила по состоянию рабочей области памяти и переход к семантической выборке, то есть к конкретизации правил.
Семантическая выборка определяет соответствие выбранных правил, текущей цели или подцели для заданной предметной области. Отобранные правила переходят на стадию сопоставления, результатом которой является конфликтная совокупность правил. На этапе сопоставления выполняется заполнение выбранных правил текущими данными, при этом возможны конфликты.
Разрешение конфликтов - это этап интерпретации, который в зависимости от принятой стратегии используемого метода или цепочки логического вывода (прямой/обратной) формирует адженту (агенду) - список активных правил. После выбора агенды начинается ее выполнение. Выполнение предполагает реализацию правил в последовательности правил или модуля при сопоставлении с образцом. Результатом выполнения является изменение состояния рабочей области, выполнения операций ввода/вывода, изменение памяти системы (рис.6).
 |
|
Память системы (рис.5) содержит сведения о всех сеансах интерпретации при поиске решения.
Данная последовательность шагов (рис.6) может быть реализована в экспертных системах, представляемых двумя архитектурами:
n первая архитектура основана на управлении правилами; в ней рабочая область - это рабочая область(текущее состояние памяти), источник знаний - данные, агенда - совокупность конфликтующих в текущей ситуации правил, правила - все активные правила;
n вторая архитектура: правила - модули, источник знаний - классная доска, агенда - список конфликтующих правил, политические правила - правила для выполнения.
В системах с архитектурой второго состояния рабочей области памяти сравнивается:
1) с данными, представленными на классной доске( в базе данных или информационной базе);
2) с сопоставленными образцами, представленными также в базе данных.
В архитектуре второго состояния кроме правил, которые определяют принятие решений, используются общие правила (метоправила), которые позволяют увеличить эффективность функционирования системы в десятки раз. Если в первой архитектуре сформулированные правила могут быть прочитаны экспертом, даже не являющимся программистом, то во второй архитектуре метоправила могут быть прочитаны и использованы только программистом. Метоправила - это правила работы с правилами. Выбранный механизм обработки и структура метоправил являются наиболее общими и позволяют охватить при обработке больший объем данных, а последовательное применение частных правил в первой архитектуре может привести к росту базы знаний и из-за путаницы в частных правилах увеличивается база знаний, что приведет к неадекватным решениям.
В традиционных языках программирования при вызове модуля или процедуры используется имя процедуры. При разработке экспертных систем выбор модуля (образца или правила) осуществляется на основе текущих правил.
Приведем классификацию стратегий принятия решений:
1. Локальная и глобальная классификации.
Локальная стратегия используется для частных правил, глобальная стратегия - для общих правил;
2. Скрытая и открыта.;
Открытая стратегия позволяет вмешиваться в процесс поиска принятия решения, стратегия закрытая является жестко заданной для предметной области;
3. По форме принятия решения:
стратегия поиска принятия решения вглубь и поиска принятия решения вширь:
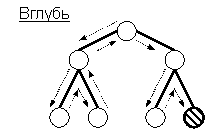 |  |
| |
Методы поиска, реализованные в экспертных системах
Методы поиска различаются:
· по определению предметной области;
· по представлению результатов.
Методы по определению предметной области классифицируются следующим образом:
n по размерности пространства;
n по количеству пространств и определению места и времени;
n по модели, описывающих предметную область;
n по совокупности моделей;
n по определению неопределенности, то есть точности задания данных, размытости представления информации и так далее.
Методы по представлению результатов классифицируются следующим образом:
n количество представленных результатов(один, несколько, все);
n полнота представления информации и результат.
2.10. Методы поиска решений в пространстве задач
Общие стратегии поиска
1. Слепой поиск.
Используются следующие стратегии:
n стратегии поиска «вглубь»;
n стратегии поиска «вширь»,
в совокупности с прямой и обратной цепочкой логического вывода.
Пример.
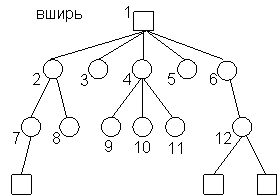 | 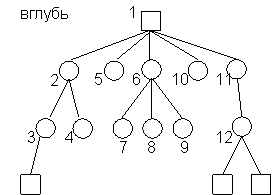 |
Конечные вершины графа - результат.
Метод редукции
Данный метод описывается с помощью графа «и/или». При реализации задачи она разбивается на совокупность подзадач. Каждая подзадача представляется веточкой графа (дугой графа). Каждая дуга графа имеет свое назначение.
Различают :
n дизъюнктивные ветви(или дуги ИЛИ);
n конъюнктивные дуги (И);
при выполнении подзадач с помощью дуги ИЛИ должна быть выполнена хотя бы одна из подзадач. При реализации дуги И должна быть выполнена вся совокупность последующих подзадач.
Конъюнктивные дуги на графе объединяются душкой. При поиске результата в «И/ ИЛИ» графе можно воспользоваться стратегией поиска «вширь» и стратегией поиска «вглубь».
Пример.
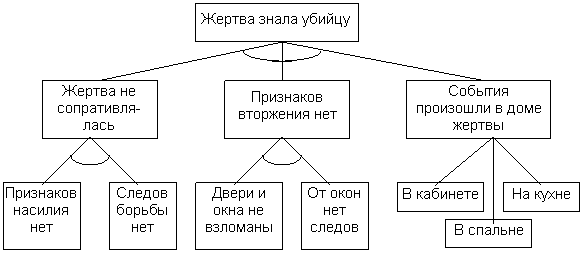 |
n Каким образом должен определен результат(обязательно),
n каждый раз он определен и один,
n ветви «И» предполагают наличие всех составляющих решения в правилах вывода, а ветви «ИЛИ» - наличие хотя бы одного решения.
Эвристический метод поиска
Данный метод предполагает использование доказательства частных эвристических характеристик, но таких, которые однозначно определяют результат. Все события, которые определяют результат разделяются на гипотезы и предположения. Гипотезы могут однозначно определять результат на основе двух понятий: логической необходимости и логической достаточности.
Метод поиска с помощью генерации и проверки
Генератором в данном методе поиска определяется совокупность решений, представленных неопределенно, то есть решения, которые могут привести или не привести к результату. Блок проверки на основе эвристических характеристик или характеристик заданных точно (по значениям данных) сокращает перебор всех возможных решений для получения результата, которые затем, после проверки, разворачиваются до полного решения. Решений может быть несколько.
Метод поиска в иерархических пространствах
В данном случае рассматривается не одно пространство поиска. Модель предметной области может представлять комбинацию моделей.
Пример. Получить все фазы естественного языка. При поиске в совокупности пространств каждое пространство определяет свой способ поиска. Для одного пространства используются вышеперечисленные способы, результатом которых является иерархия решений. Иерархия решений представляет собственную область, в которой на основе определения неопределенности получаем результат (или не получаем его).
2.11. Решение задач методом поиска в пространстве состояний
Методы поиска решений в пространстве состояний начнем рассматривать с простой задачи о миссионерах и людоедах. Три миссионера и три людоеда находятся на левом берегу реки и им нужно переправиться на правый берег, однако у них имеется только одна лодка, в которую могут сесть лишь 2 человека. Поэтому необходимо определить план, соблюдая который и курсируя несколько раз туда и обратно, можно переправить всех шестерых. Однако, если на любом берегу реки число миссионеров будет меньше, чем число людоедов, то миссионеры будут съедены. Решения принимают миссионеры, людоеды их выполняют.
Основой метода являются следующие этапы.
Определяется конечное число состояний, одно из состояний принимается за начальное и одно или несколько состояний определяются как искомое (конечное, или терминальное). Обозначим состояние S тройкой S = (x, y,z), где x - число миссионеров, y - число людоедов на левом берегу, z = {L, R}- положение лодки на левом (L ) или правом (R ) берегах. Итак, начальное состояние S0 = (3,3, L ) и конечное (терминальное) состояние Sk = (3,3, R ). Заданы правила перехода между группами состояний. Введем понятие действия M: [u: v] w, где u - число миссионеров в лодке, v - число людоедов в лодке, w - направление движения лодки (R или L ). Для каждого состояния заданы определенные условия допустимости (оценки) состояний: x >= y; 3 - x >= 3 - y; u + v <= 2. После этого из текущего (исходного) состояния строятся переходы в новые состояния, показанные на рис. 8. Два новых состояния следует сразу же вычеркнуть, так как они ведут к нарушению условий допустимости (миссионеры будут съедены). При каждом переходе в новое состояние производится оценка на допустимость состояний и, если при использовании правила перехода для текущего состояния получается недопустимое состояние, то производится возврат к тому предыдущему состоянию, из которого было достигнуто это текущее состояние. Эта процедура получила название бэктрекинг (bac tracing или BACKTRACK ).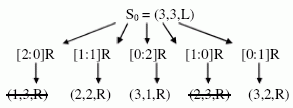
Рис. 7. Переходы из исходного состояния
Такой метод поиска S0 => Sk называется прямым методом поиска. Поиск Sk => S0 называют обратным поиском. Поиск в двух направлениях одновременно называют двунаправленным поиском.
2.12. Решение задач на основе продукций
Работа продукционной системы инициируется начальным описанием (состоянием) задачи. Из продукционного множества правил выбираются правила, пригодные для применения на очередном шаге. Эти правила создают так называемое конфликтное множество. Для выбора правил из конфликтного множества существуют стратегии разрешения конфликтов, которые могут быть и достаточно простыми, например, выбор первого правила, а могут быть и сложными эвристическими правилами. Продукционная модель в чистом виде не имеет механизма выхода из тупиковых состояний в процессе поиска. Она продолжает работать, пока не будут исчерпаны все допустимые продукции. Практические реализации продукционных систем содержат механизмы возврата в предыдущее состояние для управления алгоритмом поиска.
Рассмотрим пример использования продукционных систем для решения шахматной задачи хода конем в упрощенном варианте на доске размером 3 x 3.Требуется найти такую последовательность ходов конем, при которой он ставится на каждую клетку только один раз рис.8.
Записанные на рисунке предикаты move(x, y) составляют базу знаний (базу фактов) для задачи хода конем. Продукционные правила - это факты перемещений move, первый параметр которых определяет условие, а второй параметр определяет действие (сделать ход в поле, в которое конь может перейти). Продукционное множество правил для такой задачи приведено ниже.
P1: If (конь в поле 1) then (ход конем в поле 8)
P2: If (конь в поле 1) then (ход конем в поле 6)
P3: If (конь в поле 2) then (ход конем в поле 9)
P4: If (конь в поле 2) then (ход конем в поле 7)
P5: If (конь в поле 3) then (ход конем в поле 4)
P6: If (конь в поле 3) then (ход конем в поле 8)
P7: If (конь в поле 4) then (ход конем в поле 9)
P8: If (конь в поле 4) then (ход конем в поле 3)
P9: If (конь в поле 6) then (ход конем в поле 1)
P10: If (конь в поле 6) then (ход конем в поле 7)
P11: If (конь в поле 7) then (ход конем в поле 2)
P12: If (конь в поле 7) then (ход конем в поле 6)
P13: If (конь в поле 8) then (ход конем в поле 3)
P14: If (конь в поле 8) then (ход конем в поле 1)
P15: If (конь в поле 9) then (ход конем в поле 2)
P16: If (конь в поле 9) then (ход конем в поле 4)
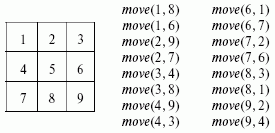
Рис. 8. Шахматная доска 3х3 для задачи хода конем
Допустим, необходимо из исходного состояния (поле 1) перейти в целевое состояние (поле 2). Итерации продукционной системы для этого случая игры показаны в таблице 4.
Таблица 4. Итерации для задачи хода конем | ||||
№ итерации | Текущее поле | Целевое поле | Конфликтное множество | Активация правила |
1 | 1 | 2 | 1, 2 | 2 |
2 | 6 | 2 | 1, 7 | 10 |
3 | 7 | 2 | Выход | |
Продукционные системы могут порождать бесконечные циклы при поиске решения. В продукционной системе эти циклы особенно трудно определить, потому что правила могут активизироваться в любом порядке. Самая простая стратегия разрешения конфликтов сводится к тому, чтобы выбирать первое соответствующее перемещение, которое ведет в еще не посещаемое состояние. Следует также отметить, что конфликтное множество это простейшая база целей.
Перечислим основные преимущества продукционных систем:
- простота и гибкость выделения знаний; отделение знаний от программы поиска; модульность продукционных правил (правила не могут "вызывать" другие правила); возможность эвристического управления поиском; возможность трассировки "цепочки рассуждений"; независимость от выбора языка программирования; продукционные правила являются правдоподобной моделью решения задачи человеком.
2.13. Решение задач на основе семантических сетей
Алгоритм наискорейшего спуска по дереву решений
Пример построения более узкого дерева рассмотрим на примере задачи о коммивояжере. Торговец должен побывать в каждом из 5 городов, обозначенных на карте рис. 9.
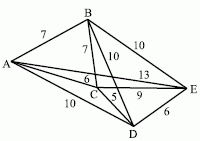
Рис. 9. Граф переходов
Задача состоит в том, чтобы, начиная с города А, найти минимальный путь, проходящий через все остальные города только один раз и приводящий обратно в А. Идея метода исключительно проста - из каждого города идем в ближайший, где мы еще не были. Решение задачи показано на рис. 10.
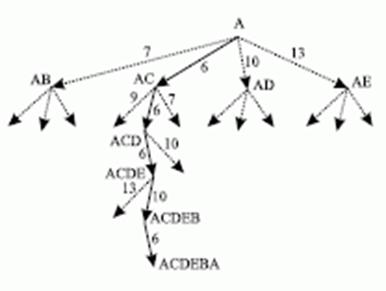
Рис. 10. Поиск минимального пути на графе
Такой алгоритм поиска решения получил название алгоритма наискорейшего спуска.
Алгоритм минимакса
В 1945 году Оскар Моргенштерн и Джон фон Нейман предложили метод минимакса, нашедший широкое применение в теории игр. Предположим, что противник использует оценочную функцию (ОФ), совпадающую с нашей ОФ. Выбор хода с нашей стороны определяется максимальным значением ОФ для текущей позиции. Противник стремится сделать ход, который минимизирует ОФ. Поэтому этот метод и получил название минимакса. На рис. 11 приведен пример анализа дерева ходов с помощью метода минимакса (выбранный путь решения отмечен жирной линией).
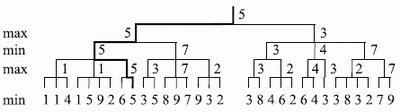
Рис. 11. Дерево ходов
Даже такой простой подход позволит нам избежать части тупиковых состояний в процессе поиска и сократить время по сравнению с полным перебором. Кстати, этот подход достаточно распространен в экспертных продукционных системах.
Алгори́тм Де́йкстры — алгоритм на графах, изобретенный Э. Дейкстрой. Находит кратчайшее расстояние от одной из вершин графа до всех остальных. Алгоритм работает только для графов без рёбер отрицательного веса. Алгоритм широко применяется в программировании и технологиях, например, его использует протокол OSPF для устранения кольцевых маршрутов. Известен также под названием кратчайший путь — первый.
Рассмотрим два примера применения алгоритма Дейкстры на практике.
Вариант 1. Дана сеть автомобильных дорог, соединяющих города Новосибирской области. Найти кратчайшие пути от Новосибирска до каждого города области (если двигаться можно только по дорогам).
Вариант 2. Имеется некоторое количество авиарейсов между городами мира, для каждого известна стоимость. Найти маршрут минимальной стоимости (возможно, с пересадками) от Копенгагена до Барнаула.
Определение алгоритма
Дан простой взвешенный граф G(V,E) без петель и дуг отрицательного веса. Найти кратчайшие пути от некоторой вершины a графа G до всех остальных вершин этого графа.
1. Каждой вершине из V сопоставим метку — минимальное известное расстояние от этой вершины до a. Алгоритм работает пошагово — на каждом шаге он «посещает» одну вершину и пытается уменьшать метки. Работа алгоритма завершается, когда все вершины посещены.
2. Инициализация. Метка самой вершины a полагается равной 0, метки остальных вершин — бесконечности. Это отражает то, что расстояния от a до других вершин пока неизвестны. Все вершины графа помечаются как не посещенные.
3. Шаг алгоритма. Если все вершины посещены, алгоритм завершается. В противном случае из еще не посещенных вершин выбирается вершина u, имеющая минимальную метку. Мы рассматриваем всевозможные маршруты, в которых u является предпоследним пунктом. Вершины, соединенные с вершиной u ребрами, назовем соседями этой вершины. Для каждого соседа рассмотрим новую длину пути, равную сумме текущей метки u и длины ребра, соединяющего u с этим соседом. Если полученная длина меньше метки соседа, заменим метку этой длиной. Рассмотрев всех соседей, пометим вершину u как посещенную и повторим шаг.
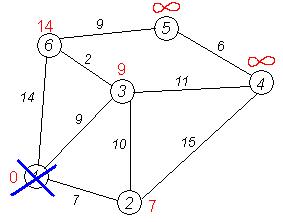
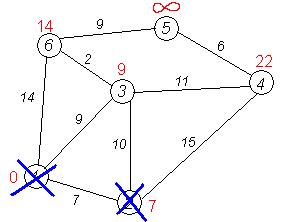
Рассмотрим выполнение алгоритма на примере графа, показанного на рисунке. Пусть требуется найти расстояния от 1-й вершины до всех остальных.
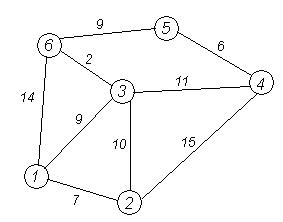
Кружками обозначены вершины, линиями — пути между ними (ребра графа). В кружках обозначены номера вершин, над ребрами обозначена их «цена» — длина пути. Рядом с каждой вершиной красным обозначена метка — длина кратчайшего пути в эту вершину из вершины 1.
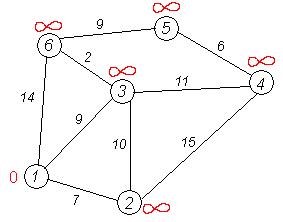
Первый шаг. Рассмотрим шаг алгоритма Дейкстры для нашего примера. Минимальную метку имеет вершина 1. Ее соседями являются вершины 2, 3 и 6.
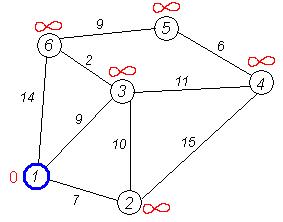
Первый по очереди сосед вершины 1 — вершина 2, потому что длина пути до нее минимальна. Длина пути в нее через вершину 1 равна кратчайшему расстоянию до вершины 1 + длина ребра, идущего из 1 в 2, то есть 0 + 7 = 7. Это меньше текущей метки вершины 2, поэтому новая метка 2-й вершины равна 7. На графике изначально рассмотрена вершина №3.
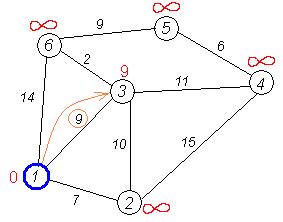
Аналогичную операцию проделываем с двумя другими соседями 1-й вершины — 3-й и 6-й.
Все соседи вершины 1 проверены. Текущее минимальное расстояние до вершины 1 считается окончательным и пересмотру не подлежит (то, что это действительно так, впервые доказал Дейкстра). Вычеркнем её из графа, чтобы отметить, что эта вершина посещена.
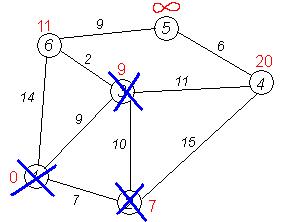
Второй шаг'. Шаг алгоритма повторяется. Снова находим «ближайшую» из непосещенных вершин. Это вершина 2 с меткой 7.
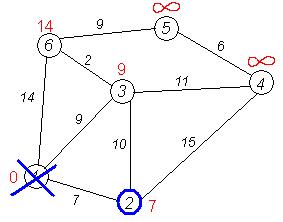
Снова пытаемся уменьшить метки соседей выбранной вершины, пытаясь пройти в них через 2-ю. Соседями вершины 2 являются 1, 3, 4.
Первый (по порядку) сосед вершины 2 — вершина 1. Но она уже посещена, поэтому с 1-й вершиной ничего не делаем.
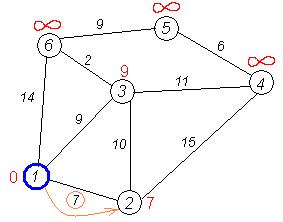
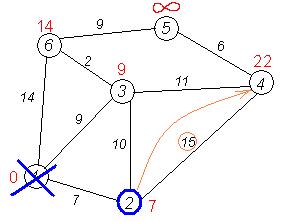
Следующий сосед вершины 2 — вершина 4/*3*/. Если идти в неё через 2-ю, то длина такого пути будет = кратчайшее расстояние до 2 + расстояние между вершинами 2 и 4 = 7 + 15 = 22. Поскольку 22<![]() , устанавливаем метку вершины 4 равной 22.
, устанавливаем метку вершины 4 равной 22.
Ещё один сосед вершины 2 — вершина 3. Если идти в неё через 2, то длина такого пути будет = 7 + 10 = 17. Но текущая метка третьей вершины равна 9<17, поэтому метка не меняется.
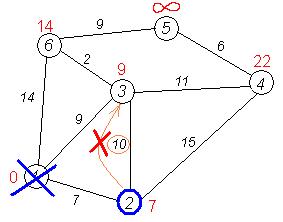
Все соседи вершины 2 просмотрены, замораживаем расстояние до неё и помечаем ее как посещенную.
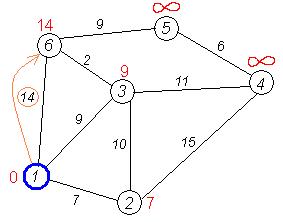
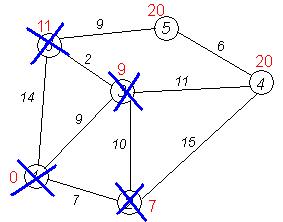
Третий шаг. Повторяем шаг алгоритма, выбрав вершину 3. После ее «обработки» получим такие результаты:
Дальнейшие шаги. Повторяем шаг алгоритма для оставшихся вершин (Это будут по порядку 6, 4 и 5).
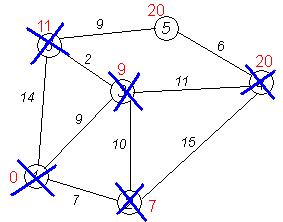
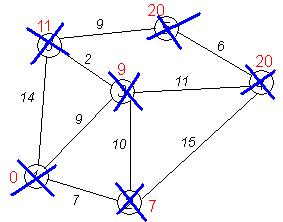
Завершение выполнения алгоритма. Алгоритм заканчивает работу, когда вычеркнуты все вершины. Результат его работы виден на последнем рисунке: кратчайший путь от вершины 1 до 2-й составляет 7, до 3-й — 9, до 4-й — 20, до 5-й — 20, до 6-й — 11.
Алгоритмы поиска пути на графе различаются также направлением поиска. Существуют прямые, обратные и двунаправленные методы поиска. Двунаправленный поиск требует удовлетворительного решения двух проблем: смены направления поиска и оптимизации "точки встречи". Одним из критериев для решения первой проблемы является сравнение "ширины" поиска в обоих направлениях - выбирается то направление, которое сужает поиск. Вторая проблема вызвана тем, что прямой и обратный пути могут разойтись и, чем уже поиск, тем это более вероятно.
2.14. Решение задач на основе нечеткого планирования
Недостатком большинства известных в настоящее время систем планирования является их жесткая привязка к схеме планирования. Любая из них всегда ищет решение либо SS - проблемы, либо PR - проблемы. Связано это с фиксацией формы представления информации для планирования. Для классических моделей SS - и PR - проблем эти формы различны. Человек в своей деятельности успешно комбинирует шаги планирования из решения SS и PR - проблем. Вторым недостатком является детерминированность систем планирования. В реальных СИИ детерминированность планирования, как правило, не имеет места. Обобщение нечетких SS - и PR - проблем заключается в допущении нечетких состояний и нечетких операторов перехода из состояния в состояние. Разбиение задачи на подзадачи имеет весовые коэффициенты на дугах со значениями из множества [0, 1], которые интерпретируются как достоверности решения соответствующих подпроблем. Достоверность решения PR-проблемы определяется как минимум достоверностей решения ее подпроблем.
Схемой SS - проблемы называется пара M = (S, G), где S - множество состояний, G - множество отображений g: S->S, называемых операторами. SS - проблема - это четверка Р = (S, G, i, f ), где (S, G) - схема SS - проблемы, i, f - соответственно начальное и заключительное состояние. Путь х, ведущий из i в f, есть решение Р, а множество всех подобных путей составляет множество решений.
Приведем формальное определение семантики сведения задачи к подзадачам.
Импликата проблемы Р есть пара (p, y ), где p =P1 P2... Pk - цепочка проблем, y - отображение из {Хр1, Хр2, ... , Хрk} в Хр. Хрi обозначает множество решений Рi. Импликативная схема есть тройка L =(Р, p, y ), такая, что Р - проблема, (p, y ) - импликата Р. Проблема Р решена тогда и только тогда, когда Хp - непустое множество.
Рассмотрим головоломку "Ханойская башня" . Имеются три стержня 1, 2 и 3 и три диска различных размеров А, В, С с отверстием в центре, которые могут одеваться на стержни. В исходной позиции диски находятся на стержне 1; самый большой диск С - внизу, самый маленький диск А - наверху. Требуется перенести все диски на стержень 3, перемещая за один раз только один диск. Брать можно только самый верхний диск на стержне, причем его нельзя класть на диск, меньший по размерам. Используем для записи состояний и операторов классическую формализацию.
Выражение ijk обозначает конфигурацию, при которой диск С находится на стержне i, диск В - на стержне j и диск А-на стержне k.
Выражение xij обозначает действие, при котором диск х перемещается со стержня i на стержень j.
С помощью этого формализма можно просто записать все состояния и переходы головоломки в виде треугольного графа, где вершины соответствуют расположению дисков на стержнях, а дуги соответствуют возможным перекладываниям дисков (рис.1). На этой головоломке легко проиллюстрировать все основные понятия обобщенной стратегии проблем.
Рассмотрим решение проблемы с использованием формализма xij :
А13, В12, А32,С13,А21, В23, А13.
Очевидно, что это решение не единственно и имеется конечное множество решений обозначенной проблемы.
Представим головоломку в виде модели проблемы R = (B, G, P0, T), где B={Р0, P1,..., P9}; G={g}; T={L1,L2,L3}. SS - проблемы Р0,P1...,P9 определяются следующим образом:
P0=(S, G, 111, 333), P1=(S, G, 111, 122), P2=(S, G, 122, 322),
Р3=(S, G, 322, 333), P4=(S, G, 111, 113), P5 =(S, G, 113, 123),
P6==(S, G, 123, 122), P7=(S, G, 322, 321), P8=(S, G, 321, 331),
P9=(S G, 331,333).
Проблемы Р2 и P4 - P9 решаются перекладыванием одного диска и являются элементарными. Проблемы P1 и Р3 решаются с помощью манипуляций только с дисками В и А и являются более простыми, чем Р0. Проблемы P1 и Р3 решаются, а проблема Р0 сводится к P1, P2 и Р3 аналогичной манипуляцией с дисками, синтаксис которой выражен оператором g, а семантика - отображением Y.
Приведенные определения обобщаются на нечеткий случай, когда состояние системы, для которой строится модель решения проблемы, не является точно заданным, а результаты действий системы неоднозначны.
Например, у робототехнической системы это может быть связано с несовершенством рецепторов, с ограниченными размерами внутренней модели, не отражающей сложности окружающего мира.
Построить решение нечеткой PR - проблемы по a - решениям ее нечетких подпроблем можно лишь в частных случаях и при наложении дополнительных условий.
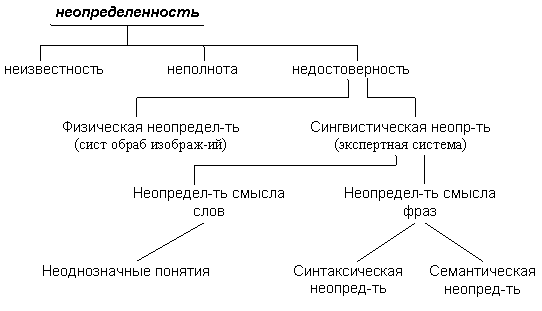
2.15. Определение неопределенности в экспертных системах
 | |
|
В экспертных системах используются следующие способы определения неопределенности, заданной на схеме 4:
· с помощью вероятностных характеристик;
· с помощью понятий логической необходимости и логической достаточности, которые связываются с вероятностными характеристиками;
· определение неопределенности на основе мощности правил, которая определяется с помощью коэффициентов уверенности;
· использование переменных неопределенности;
· использование лингвистических переменных.
Рассмотрим подробнее.
1. Для каждого утверждения, которая участвует в правиле логического вывода, задается вероятность подтверждения факта, которая лежит в пределе от 0 до 1. Например (для факта):
металлург (Х, 0.5) & мужчина (Х, 0.75)
учитель (Х, 0.5) & женщина (Х, 0.5)
2. Логическая достаточность LS и логическая необходимость LS определяют мощность правила на основе вероятностных характеристик суждения и гипотезы. Например (правило):
если идет снег, то холодно
суждение гипотеза
Е Н
Р(снег)=СХ (вероятность того, что идет снег - это будет Снег и Холодно)
Р(холод)=СНХ (Снег, но не Холодно)
Р(холод/снег)=НХС (не Холодно, Снег)
Р(снег/холод)=НСНХ (не Снег, не Холодно)
СХ + СНХ + НХС + НСНХ = 1
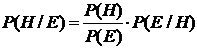 - формула Байеса
- формула Байеса
Таким образом, логическая достаточность
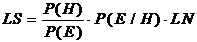
|
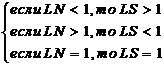
3. Коэфициент уверенности присваивается каждому факту в правиле для определения мощности правила в целом. Если факты в правиле связаны союзом И, то мощность правила будет определяться мощностью самого слабого звена правила, умноженного на мощность фактов данного уровня. Если факты в правиле связаны союзом ИЛИ, то мощность правила определяется на основе произведения мощности самого важного факта цепочки на коэфициент уверенности уровня. Например:
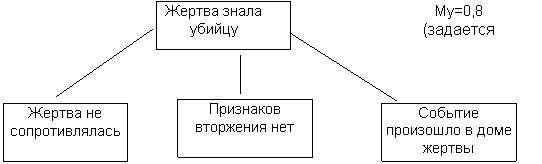 |
Мп=0,7 * Мур=0,7*0,8+0,56 - мощность всего правила.
4. Переменные неопределенности задаются следующим котрежом: Хн<b, Х,С>
b - имя переменной неопределенности;
Х - область определения переменной неопределенности;

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
