

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
2. КОНСПЕКТ ЛЕКЦИЙ
2.1. Общие вопросы изучения интеллектуальных информационных систем (ИИС)
Введение
Представление знаний — вопрос, возникающий в когнитологии (науке о мышлении), в информатике и в исследованиях искусственного интеллекта. В когнитологии он связан с тем, как люди хранят и обрабатывают информацию. В информатике — с подбором представления конкретных и обобщённых знаний, сведений и фактов для накопления и обработки информации в ЭВМ. Главная задача в искусственном интеллекте (ИИ) — научиться хранить знания таким образом, чтобы программы могли осмысленно обрабатывать их и достигнуть тем подобия человеческого интеллекта.
Под термином «представление знаний» чаще всего подразумеваются способы представления знаний, ориентированные на автоматическую обработку современными компьютерами, и, в частности, представления, состоящие из явных объектов. Например, Клайд — слон, все слоны серые. Представление знаний в подобной явной форме позволяет компьютерам делать дедуктивные выводы из ранее сохранённого знания, для нашего примера вывод будет такой: Клайд серый.
Исследователи ИИ используют теории представления знаний из когнитологии.
Правила вывода и семантические сети пришли в ИИ из теорий обработки информации человеком. Поскольку знание используется для достижения разумного поведения, фундаментальной целью дисциплины представления знаний является поиск таких способов представления, которые делают возможным процесс логического вывода, то есть создание знания из знаний.
Некоторые вопросы, которые возникают в представлении знаний с точки зрения ИИ:
· Как люди представляют знания?
· Какова природа знаний?
· Должна ли схема представления связываться с частной областью знаний или она должна быть общецелевой?
· Насколько выразительна данная схема представления?
· Должна ли быть схема декларативной или процедурной?
Есть хорошо известные проблемы, такие как «spreading activation» (задача навигации в сети узлов), категоризация, что связано с выборочным наследованием, например, вездеход можно считать специализацией автомобиля, но он наследует только некоторые характеристики.
Решение сложных задач часто может быть упрощено правильным выбором метода представления знаний. Опредёленный метод может сделать какую-либо область знаний легко представимой. Неправильный выбор метода представления затрудняет обработку. Не существует такого способа представления, который можно было бы использовать во всех задачах или сделать все задачи одинаково простыми.
Для структурирования информации, а также организации баз знаний и экспертных систем были предложены несколько способов представления знаний. Одно из них — представление данных и сведений в рамках логической модели баз знаний.
В 1970-х и начале 1980-х были предложены многочисленные методы представления знаний: эвристические вопросно-ответные системы, нейросети, экспертные системы и др. Главными областями их применения в то время были медицинская диагностика (MYCIN) и игры (например, шахматы).
В 1980-х годах появились формальные компьютерные языки представления знаний. Основные проекты того времени пытались закодировать (занести в свои базы знаний) огромные массивы общечеловеческого знания. Например, в проекте «Cyc» была обработана большая энциклопедия и кодировалась не сама хранящаяся в ней информация, а знания, которые потребуются читателю, чтобы понять эту энциклопедию: простейшая физика, понятия времени, причинности и мотивации, типовые объекты и их классы.
Данная работа привела к более точной оценке сложности задачи представления знаний. Глубокое представление знаний вместе с огромным приростом скорости и объёмов памяти компьютеров сделало представление знаний более реальным.
Было также разработано несколько языков программирования, ориентированных на представление знаний. Пролог (разработанный в 1972 году, но получивший популярность значительно позже) описывает высказывания и основную логику, он может производить выводы из известных посылок.
В области электронных документов были разработаны языки, явно выражающие структуру хранимых документов, такие как SGML (а впоследствии — XML). Они облегчили задачи поиска и извлечения информации, которые в последнее время всё больше связаны с задачей представления знаний. Большой интерес проявляется к технологии семантической паутины, в которой основанные на XML языки представления знаний, используются для увеличения доступности к компьютерным системам информации, хранящейся в сети.
Связи и структуры
Сегодня широко используются гиперссылки, однако близкое понятие семантической ссылки ещё не вошло в широкое употребление. Со времён Вавилона использовались математические таблицы. Позже эти таблицы использовались для представления результатов логических операций, например, таблицы истинности использовались для изучения и моделирования булевой логики. Табличные процессоры также являются примером табличного представления знаний. Другим методом представления знаний являются деревья, с помощью которых можно показать связи между фундаментальными концепциями и их производными.
Относительно новый подход к управлению знаниями — визуальные способы представления. Они дают пользователю способ визуализировать, как мысль или идея связана с другими идеями, позволяя перемещаться от одной мысли к другой для того, чтобы найти требующуюся информацию.
Хранение и обработка знаний
Одна из проблем в представлении знаний — как хранить и обрабатывать знания в информационных системах формальным способом так, чтобы машины могли использовать их для достижения поставленных задач. Примеры применения — экспертные системы, машинный перевод, системы извлечения и поиска информации (включая пользовательские интерфейсы баз данных).
Семантические сети. Фреймы
Для представления знаний можно использовать семантические сети. Каждый узел такой сети представляет концепцию, а дуги используются для определения отношений между концепциями.
Начиная с 1960-х годов, используется понятие фрейма знаний или просто фрейма.
Фрейм (англ. frame — кадр, рамка) — в самом общем случае данное слово обозначает структуру, содержащую некоторую информацию.
Фрейм — есть структура, содержащая описание объекта в виде атрибутов и их значений.
Каждый фрейм имеет своё собственное имя и набор атрибутов или слотов, которые содержат значения; например фрейм дом мог бы содержать слоты цвет, количество этажей и т. д.
Использование фреймов в экспертных системах является примером объектно-ориентированного программирования с наследованием свойств. Фреймовые структуры хорошо подходят для представления знаний, представленных в виде схем и когнитивных шаблонов.
Элементы подобных шаблонов обладают разными весами, причем большие веса назначаются тем элементам, которые соответствуют текущей когнитивной схеме. Паттерн (шаблон) активизируется при определённых условиях: если человек видит большую птицу, при условии что сейчас активна его «морская схема», а «земная схема» — нет, он классифицирует её скорее, как морского орлана, а не сухопутного беркута.
Фреймовые представления объектно - центрированы в том же смысле, что и семантическая сеть: все факты и свойства, связанные с одной концепцией, размещаются в одном месте, поэтому не требуется тратить ресурсы на поиск по базе данных.
Скрипт — это тип фреймов, который описывает последовательность событий во времени; типичный пример — описание похода в ресторан. События здесь включают ожидание встречи, выбор по меню, заказ музыки, цветов и др.
Язык и нотация
Некоторые люди считают, что лучше всего будет представлять знания так, как они представлены в человеческом разуме, который является единственным известным на сегодняшний день работающим разумом или же представлять знания в форме естественного языка.
, например, разработал «семантическую систему, базирующуюся на теории», которая не зависит от языка, которая выводит цель и рассуждает теми же концепциями и теориями что и люди. Формула, лежащая в основе этой семантики: Знание = Теория + Информация. Большинство распространенных приложений и систем баз данных основаны на языках.
Для представления знаний были предложены различные искусственные языки и нотации.
Нота́ция (от лат. notatio — записывание, обозначение) — система условных обозначений, принятая в какой-либо области знаний или деятельности.
Обычно искусственные языки основаны на логике и математике, и имеют легко читаемую грамматику для облегчения машинной обработки.
Последней модой в языках представления знаний является использование XML в качестве низкоуровневого синтаксиса. Это приводит к тому, что машины могут легко производить синтаксический анализ и вывод этих языков представления знаний за счёт удобочитаемости для человека.
XML (англ. eXtensible Markup Language) — расширяемый язык разметки, рекомендованный Консорциумом Всемирной паутины, как язык разметки, фактически представляющий собой свод общих синтаксических правил. XML — текстовый формат, предназначенный для хранения структурированных данных (взамен существующих файлов баз данных), для обмена информацией между программами, а также для создания на его основе более специализированных языков разметки (например, XHTML).
Логика первого порядка и язык Пролог широко используется в качестве математической основы для этих систем, чтобы избежать избыточную сложность.
Языки делятся на искусственные и естественные.
Естественные языки формировались и формируются национальными или профессиональными сообществами людей. Знания передаются от одного человека к другому после их перевода на язык, который понимают человек - источник знания и человек - приемник знания.
Искусственные языки создавались и создаются для связи человека с ЭВМ. Примеры искусственных языков, которые используются преимущественно для представления знаний: Пролог, Лисп и др.
2.2. Интеллектуальные информационные системы (ИИС)
Рассмотрим функциональную структуру ИИС.
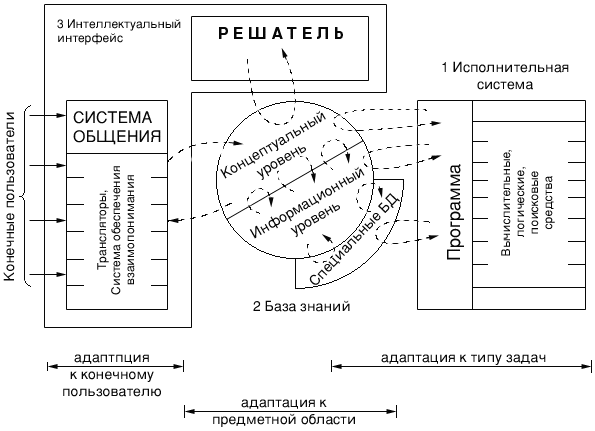
Рис. 1. Функциональная структура ИИС
Представленная структура состоит из трех комплексов вычислительных средств рис.2.1. Первый комплекс представляет собой совокупность средств, выполняющих программы (исполнительную систему), спроектированных с позиций эффективного решения задач, имеет в ряде случаев проблемную ориентацию. Второй комплекс - совокупность средств интеллектуального интерфейса, имеющих гибкую структуру, которая обеспечивает возможность адаптации в широком спектре интересов конечных пользователей. Третьим комплексом средств, с помощью которых организуется взаимодействие первых двух, является база знаний, обеспечивающая использование вычислительными средствами первых двух комплексов целостной и независимой от обрабатывающих программ системы знаний о проблемной среде. Исполнительная система объединяет всю совокупность средств, обеспечивающих выполнение сформированной программы. Интеллектуальный интерфейс - система программных и аппаратных средств, обеспечивающих для конечного пользователя использование компьютера для решения задач, которые возникают в среде его профессиональной деятельности либо без посредников либо с незначительной их помощью. База знаний (БЗ) - занимает центральное положение по отношению к остальным компонентам вычислительной системы в целом, через БЗ осуществляется интеграция вычислительных средств, участвующих в решении задач.
ИИС, на сегодняшний день, ориентированы на разработку двух классов систем:
· OLTP – системы обработки транзакций;
· OLAP – системы аналитической обработки запросов.
К реализующим их технологиям можно отнести:
1. Экспертные системы и системы обработки знаний; системы искусственного интеллекта, ориентированные на распознавание образов, речи и текста.
2. Нейросетевые технологии.
3. Нечеткое представление информации или нечеткие множества.
4. Генетические алгоритмы или алгоритмы реализации эволюции.
5. Системы раскопок данных (DATA MINING).
6. Системы и технологии дистанционного образования.
OLTP (Online Transaction Processing) — обработка транзакций в реальном времени. Она представляет собой способ организации БД, при котором система работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом клиенту требуется от системы минимальное время отклика.
Транза́кция (англ. transaction) — группа последовательных операций, которая представляет собой логическую единицу работы с данными. Транзакция может быть выполнена либо целиком и успешно, соблюдая целостность данных и независимо от параллельно идущих других транзакций, либо не выполнена вообще и тогда она не должна произвести никакого эффекта. Транзакции обрабатываются транзакционными системами, в процессе работы которых создаётся история транзакций.
Пример. Необходимо перевести с банковского счёта номер 5 на счёт номер 7 сумму в 10 денежных единиц. Этого можно достичь, к примеру, приведённой последовательностью действий:
· начать транзакцию;
· прочесть баланс на счету номер 5;
· уменьшить баланс на 10 денежных единиц;
· сохранить новый баланс счёта номер 5;
· прочесть баланс на счету номер 7;
· увеличить баланс на 10 денежных единиц;
· сохранить новый баланс счёта номер 7;
· окончить транзакцию.
Эти действия представляют собой логическую единицу работы «перевод суммы между счетами», и таким образом, являются транзакцией. Если прервать данную транзакцию, к примеру, в середине, и не аннулировать все изменения, легко оставить владельца счёта номер 5 без 10 единиц, тогда как владелец счета номер 7 их не получит.
OLTP-приложения охватывается широкий спектр задач во многих отраслях: банковские и биржевые операции
, в промышленности — регистрация прохождения детали на конвейере, фиксация в статистике посещений очередного посетителя веб-сайта, автоматизация бухгалтерского, складского учёта и учёта документов и т. п.
Приложения OLTP, как правило, автоматизируют структурированные, повторяющиеся задачи обработки данных, такие как ввод заказов и банковские транзакции. OLTP-системы проектируются, настраиваются и оптимизируются для выполнения максимального количества транзакций за короткие промежутки времени. Как правило, большой гибкости здесь не требуется, и чаще всего используется фиксированный набор надёжных и безопасных методов ввода, модификации, удаления данных и выпуска оперативной отчётности. Показателем эффективности является количество транзакций, выполняемых за секунду. Обычно аналитические возможности OLTP-систем сильно ограничены (либо вообще отсутствуют).
Требования:
· сильно нормализованные модели данных;
· при возникновении ошибки транзакция должна целиком откатиться и вернуть систему к состоянию, которое было до начала транзакции;
· обработка данных в реальном времени.
OLTP-системы оптимизированы для небольших дискретных транзакций. А вот запросы на некую комплексную информацию (к примеру, поквартальную динамику объемов продаж по определённой модели товара в определённом филиале), характерные для аналитических приложений (OLAP), породят сложные соединения таблиц и просмотр таблиц целиком. На один такой запрос уйдет масса времени и компьютерных ресурсов, что затормозит обработку текущих транзакций.

OLTP База данных (БД) - основа системы OLTP.

OLAP - Хранилище данных - основа системы OLAP.
OLAP (англ. online analytical processing, аналитическая обработка в реальном времени) — технология обработки данных, заключающаяся в подготовке суммарной (агрегированной) информации на основе больших массивов данных, структурированных по многомерному принципу. Реализации технологии OLAP являются компонентами программных решений класса Business Intelligence.
Причина использования OLAP для обработки запросов — это скорость. Реляционные БД хранят сущности в отдельных таблицах, которые обычно хорошо нормализованы. Эта структура удобна для операционных БД (системы OLTP), но сложные многотабличные запросы в ней выполняются относительно медленно.
OLAP-структура, созданная из рабочих данных, называется OLAP-куб.
Куб создаётся из соединения таблиц с применением схемы звезды или схемы снежинки. В центре схемы звезды находится таблица фактов, которая содержит ключевые факты, по которым делаются запросы. Множественные таблицы с измерениями присоединены к таблице фактов. Эти таблицы показывают, как могут анализироваться агрегированные реляционные данные. Количество возможных агрегирований определяется количеством способов, которыми первоначальные данные могут быть иерархически отображены.
Особое место при разработке систем OLTP и OLAP занимают используемые инструментальные средства: СУБД, системы быстрой разработки приложений, оболочки для создания экспертных и образовательных приложений, которые классифицируются также в зависимости от используемой системы.
Системы OLTP и OLAP классифицируются по способу разработки информационного приложения (или архитектуре): OLTP реализуются в локальной архитектуре и в архитектуре «файл-сервер»; системы OLAP только в архитектуре «клиент-сервер». Причем, если при разработке OLTP ресурсными показателями системы являются память и время, то в OLAP они не имеют значения. Ресурсными показателями в OLAP являются точность приближения к требуемому запросу пользователя и трафик вычислительной сети (требуется максимально разгрузить).
Если в OLTP время выступает ресурсным показателем, то в OLAP время является указателем информации в хранилище.
Хранилища данных
Совокупность систем обработки данных ориентирована на использование двух основных сред: OLTP и OLAP. Соответственно каждая из сред ориентирована на собственную обработку данных. Для OLTP (обработка транзакций) – это базы данных, а для OLAP (обработка сложных аналитических запросов) – это хранилища данных.
 Обработка данных в хранилищах данных предполагает получение их из различных источников, которыми являются архивы данных; информационные приложения; внешние источники поступления данных, не связанные с какой-либо системой.
Обработка данных в хранилищах данных предполагает получение их из различных источников, которыми являются архивы данных; информационные приложения; внешние источники поступления данных, не связанные с какой-либо системой.
На выходе хранилища данных (или постпроцессора) расположены клиентские приложения, включающие киоск данных (необязательно) и предметно-ориентированный интерфейс пользователя.
Хранилища данных начали широко использоваться с 1990-х годов. Основное назначение хранилища данных – это функционирование в среде систем поддержки принятия управленческих решений.
Хранилище данных – это предметно-ориентированная упорядоченная в хронологическом порядке интегрированная и неизменная единица информации, используемая для систем поддержки принятия решения в сфере управления.
Данная информационная единица на сегодняшний день является качественно новым информационным продуктом.
Таблица 1. Отличие OLTP и OLAP
для OLTP | для OLAP | |
1 | работа с транзакциями в оперативном режиме, несложные запросы | аналитическая обработка данных, прогнозирование и моделирование |
2 | отсутствие необходимости упорядочивания данных | упорядочивание данных в хронологическом порядке |
3 | простые запросы | сложные запросы |
4 | детализация данных | агрегирование или агрегатирование (объединение данных) |
5 | частое обновление данных небольшими порциями | редкое обновление данных большими порциями; в частном случае – обновление отсутствует, есть только накопление |
Таким образом, хранилища данных ориентированы на предметную область (для выполнения запросов о поставках и заказах следует иметь хранилища о клиентах и поставщиках).
Интегрированность предполагает объединение данных в хранилища данных из различных источников с приведением их к единому формату. Соблюдение хронологического порядка предполагает упорядоченность по времени поступления информации.
Встает задача представления хранилища данных в памяти ЭВМ: если в традиционных системах обработки транзакций OLTP реляционное представление является наиболее признанным из-за наличия нормализации отношений и ограничения блокировок обработки информации, используемых для уменьшения времени выполнения запроса, то при организации хранилищ они выполняют отрицательную роль. Следовательно, нормализация и блокировка запросов в хранилищах данных отсутствуют.
В хранилищах данных обязательно наличие упорядоченности данных, т. е. среди показателей представления информации должен быть показатель времени, соответствующий глубине залегания информации в хранилище данных.
Для хранилищ данных характерным является достаточно большой объем информации (порядка 500-600Гб).
Способы представления информации в хранилище данных
Существует два способа представления информации в хранилище данных:
·
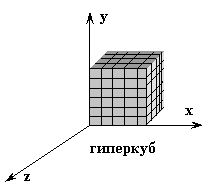 |
представление информации в виде трехмерных массивов;
(в частном случае измерений может быть гораздо больше).
· использование многих размерностей - гипершар.
Измерениями гиперкуба являются:
- время (ось z);
- параметры (ось х);
- объекты (ось у).
Пример: экономическая ситуация в РФ:
- по оси z – года;
- по оси x – добыча полезных ископаемых, ….
- по оси у – субъекты РФ.
Обработка информации в хранилище для данного способа представления информации осуществляется на основе следующих операций:
· сечение – заключается в выборе значения времени и по выбранному значению происходит разрезание гиперкуба, в результате чего получаем двумерные реляционные таблицы или плоские файлы.
· кручение (агрегирование) – при выполнении данной операции измерения меняются местами (ось х – время…).
· дополнение – данная операция предполагает включение в агрегат данных. Агрегат может представлять собой слой данных, относящихся к одному коду. В данном случае необходимо выполнить сечение и агрегатирование информации.
· детализация.
Основные единицы, характеризующие гиперкуб – это измерение и ячейка.
Если рассматривать реляционную модель данных, то в данном представлении отсутствуют нормализация и блокировка данных.
Нормальная форма данных — формальное свойство отношения, которое характеризует степень избыточности хранимых данных и возможные проблемы.
Блокировка (англ. lock) в СУБД — это отметка о захвате объекта транзакцией в ограниченный или исключительный доступ с целью предотвращения коллизий и поддержания целостности данных.
При представлении информации в виде реляционной модели формируется фактологический файл, содержащий измерения в соответствие с гиперкубом.
Фактологический файл связан со справочными файлами на основе идентификации параметров и его характеристик. Привязывание справочных файлов к фактологическому файлу выполняется в двух структурах, называемых звезда и снежинка.
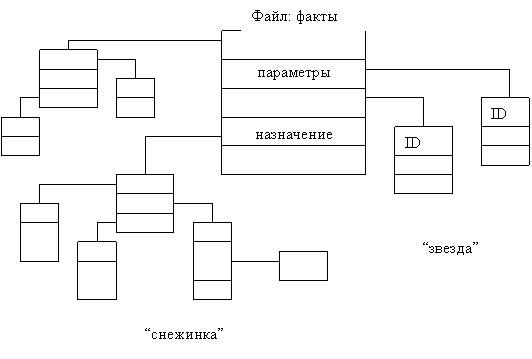 |
Рис. 2. Структуры фактологического файла
Структура “звезда” предполагает наличие фактологического файла и одного файла связующего в общей структуре хранилища данных. “Снежинка” предполагает наличие второго, третьего и т. д. уровней.
Операции, используемые для обработки данных при представлении информации в хранилище в виде реляционной модели данных – это операции реляционной алгебры (проекция и т. п.).
В структуре данных в виде реляционной модели обработка информации осуществляется дольше, но эффективнее используется память. В среде гиперкуба память используется не эффективно, но обработка информации выполняется быстро.
Перечислим задачи, для которых используются хранилища данных, работающие в системе принятия решения:
· прогнозирование;
· выявление аномалий;
· аппроксимация функций;
· кластеризация;
· классификация.
Необходимо различать характер запросов к хранилищам данных. Запросы всегда направлены на анализ имеющихся данных.
Например, если в традиционной системе OLTP мы реализуем запрос - получить значение счета клиента в конкретном банке, то в аналитической системе с хранилищами данных запросы для данной предметной области выглядят иначе. А именно: получить среднее время оплаты счета клиента после выставления его фирмой за указанный промежуток времени или выявить махинации с кредитными карточками на основе нестандартных ситуаций, возникающих при использовании кредитной карточки конкретным клиентом.
Предметная ориентированность данных в хранилищах данных конкретизируется в хранилищах типа – киоск данных. Разделение данных предполагает выделение из хранилища данных информации с более узкой спецификацией (киоски данных для подразделений предприятия). С понятием “киоск данных” связаны понятия – метаданные. Метаданные определяют в современных СУБД депозитарий данных, т. е. конкретный профиль указанного подразделения в общей структуре организации.
2.3. Экспертные системы
Экспертные системы (ЭС) относятся к задачам, которые претендуют на NP-полноту. NP-полнота систем характеризуется заданной сложностью. Сложность задачи характеризуется количеством шагов поиска решения.
1. Если задача сходится за экспоненциальное количество шагов, т. е. алгоритм решения задачи можно представить в виде экспоненты exp(2, 4, 8, …), то сложность задачи определяется классом Е.
2. Если задача сходится за полиномиальное количество шагов, т. е. формулу нахождения решения можно свести к полиному, то данная задача характеризуется сложностью Р.
3. Если для задачи отсутствует формула нахождения решения, отсутствует алгоритм получения результата или получить алгоритм достаточно сложно и трудоемко, но возможно, то сложность такой задачи характеризуется, как неопределенное полиномиальное (NP).
Назначение и особенности экспертных систем
Экспертные системы, или системы, основанные на знаниях, предназначены для решения неформулизуемых или слабо формулизуемых задач. Там, где используется враждебная человеку среда, отсутствует алгоритм решения задачи, или для решения задачи требуется достаточно много времени (машинного) и имеется недостаток в числе экспертов для решения поставленной задачи. Данные задачи решают проблемы в условиях неполной, нечеткой, размытой и, возможно, ошибочной информации.
Эксперт - это человек, который является профессионалом высокой квалификации в данной проблемной области, для которой предназначена разработка системы.
Экспертная система разрабатывается в том случае, если ее разработка, во-первых, необходима, во-вторых, оправдана и неоценима.
Этапы разработки экспертных систем:
1. Приобретение знаний. Приобретение знаний для системы представления знаний осуществляется от эксперта в заданной прикладной области, когнитологом (инженером по знаниям). Существует три способа приобретения знаний:
· наблюдение за работой эксперта;
· опрос эксперта;
· интервьюирование.
2. Представление знаний. Описание проблемной информации. Оно осуществляется с помощью:
· таксономической классификационной схемой (объекты, их свойства, отношения);
· выделение фактов, правил, отношений для заданной проблемной области;
· факты есть описание значений данных;
· правила есть интеграция фактов в каузальной форме (если... то...) для получения решения;
· отношения есть совокупность семантических отношений для интерпретации правил в стратегиях поиска решений;
· идентификация знаний.
Факты и правила составляют знания. Факты, правила и отношения составляют стратегию поиска решения. Знания и стратегия поиска решения составляют декларативные и процедурные знания (для констатирования фактов и для выполнения действий соответственно).
2.4. Разработка моделей представления знаний
Существуют следующие модели представления знаний:
· фрейм;
· семантическая сеть;
· исчисление предикатов первого порядка;
· комбинированная модель (правила продукций);
Лингвистическая обработка проблемной информации состоит из предложения (совокупность фактов) и утверждения (совокупность предложений).
Определение неопределенности:
· использование коэффициентов неопределенности;
· использование вероятностных характеристик событий;
· использование логической необходимости и логической достаточности для события;
· использование формулы Байеса для вероятности происхождения событий;
· использование лингвистической переменной;
· использование переменной неопределенности.
Стратегии поиска решения:
· цепочки логических рассуждений (интерпретация фактов предметной области); существует прямая цепочка и обратная цепочка логического рассуждения;
· стратегия поиска решения на основе логических цепочек вглубь и вширь;
· результат использования стратегий и логических рассуждений есть реализация логического вывода.
3. Реализация.
Для реализации используются:
· традиционные языки программирования (С++, CU и др.);
· языки обработки списков (Lisp, Ada и др.);
· языки логического программирования (Prolog и др.);
· пустые оболочки для создания экспертных систем (GURU и др.);
· экспертные системы для разработки экспертных систем и систем приобретения знаний.
При этом используются следующие технологии:
· объектно-ориентированная технология разработки экспертных систем;
· распределенная архитектура системы, то есть технология клиент-сервер;
· технология риинжиниринга бизнеса или моделирование бизнес-процесса.
2.5. Разработка экспертной системы (ЭС)
Структура экспертной системы должна быть прозрачна для конечного пользователя. Конечным пользователем экспертной системы является и необученный пользователь, и эксперт в заданной предметной области, и прикладной программист и когнитолог.
Ядром экспертной системы является естественный язык и объектно-ориентированное представление информации.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
