

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
С - ограничение на область определения переменной неопределенности.
Пример:
b - расстояние;
Х - далеко (близко, рядом);
С - те значения, которые не могут принимать переменные (где они не используются).
5. Лингвинстические переменные задаются следующем кортежом: Хл<b, a,Х, S,T>
b - имя переменной;
a - значение, которое может принимать лингвистическая переменная из области Х;
S - лингвистическая процедура использования переменной;
Т - семантическая процедура, определяющая использование лингвистической переменной.
2.16. Инструментальные средства проектирования экспертных систем
Инструментальные средства для разработки экспертных систем
Инструментальные средства для разработки экспертных систем делятся на три группы:
1) традиционные языки программирования, в том числе языки высокого уровня, объектно-ориентированные и функциональные;
2) пустые оболочки или среды для разработки экспертных систем. Каждая пустая оболочка включает встроенные языки или язык, определяющие взаимодействие с традиционными языками программирования. Каждая оболочка включает собственный язык организации и манипулирования знаний, таких средств внутри тоже может быть несколько.
3) специализированные системы искусственного интеллекта, содержащие программное ядро, которое позволяет менять ориентацию системы на область экспертных систем.
Экспертные системы по виду классифицируются:
· динамические экспертные системы - системы, предназначенные для решения задач анализа и синтеза в реальном времени; система принятия решений относится к экспертной системе данного вида.
· статические экспертные системы - системы, предназначенные для решения задач анализа в реальном времени и решения задач синтеза с разделением времени.
Типы экспертных систем:
· Экспериментальный прототип. Система ориентированна на правила общего вида релевантных решаемой задачи; количество правил должно быть меньше 50-ти (частный случай от 5 до 15). Система работает неустойчиво, время на разработку менее двух месяцев.
· Прмышленный образец. Среднее количество используемых правил в таких системах не более 50-ти (частный случай от 20 до 50). Правила общего вида и частные правила. Для доводки системы до экспертного образца требуется от 3 до 5 месяцев. Система работает стабильно на частных правилах.
· Прмышленная система. Стабильно работающая система, содержащая не менее 100 правил общего и частного вида; для разработки системы требуется от 10 до12 месяцев.
· Коммерческая система. Стабиль работающая система, использующая более 100 правил общего характера, используемая в конкретной области человеческой деятельности и предназначенная для продажи. На разработку, отладку и тестирование системы требуется не менее 1,5-2 лет.
Классификация по используемой технологии принятия решений:
1. Поверхностный подход.
Используемые правила общего характера, релевантные в предметной области. Правила получены только от эксперта в виде эвристик. Поиск решения индуктивным методом.
2. Структурный подход.
Технология использования правила общего и частного вида принятия решений на основе поиска по дереву решения или по специальному механизму (стратегия принятия решений).
3. Глубинный подход.
В данных технологиях проблемная область систематизированна с учетом модели представления знаний. Правила общего и частного вида формируются, исходя из используемой модели, состояния предметной области и рекомендации экспертов.
4. Совмещенные технологии.
Сочетание всех трех перечисленных выше.
Классификация оболочек экспертной системы
Тип 1. Статическая оболочка, то есть предназначена для решения статических задач.
n Используемая технология - поверхностная;
n типы использования правил - только общие;
n поиск решения от цели к данным;
n для приняти решений используется индуктивный подход на основе текущих данных;
n решаемые задачи - только задачи анализа.
Пример:
· Clas
· Элис
Решения получаются на основе правил, заданных по имеющемся в системе шаблону.
Тип 2. Статические оболочки, предназначенные для решения задач анализа и синтеза с разделением времени.
n Используемые технологии - поверхностный, глубинный, структурный подходы;
n поиск решений - на основе правил, представленных в среде оболочки. Для работы с правилами используются функции;
n поиск решений - от цели к данным, а так же от данных к цели; поиск решений вглубь и вширь.
o Пример: KAPPA;
· Nexpert;
· ADC.
Тип 3. Оболочки для пректирования динамических систем.
n Используемая технология - поверхностный подход. Отсутствие системы моделирования;
n принятие решения - на основе правил общего вида. Возможность использования для стстических задач.
Пример: Frame work;
Тип 4. Оболочки для разработки динамических систем.
n Решение задач анализа и синтеза в реальном времени;
n тип технологии - смешанный;
n используемые правила общего и частного вида; наличие системы моделирования, приближенной к имитационному моделированию.
Наличие планировщика решений, который повышает эффективность работы системы за счет совокупности имеющихся на текущий момент известных решений.
Много включающих инструментальных средств.
Пример:
· G2;
· Rethink (на основе G2);
· RkWorks.
Системы нечеткой логики
Одной из задач определения неопределенности в системах искусственного интеллекта является использование нечетких переменных (элементов нечеткой логики) – fuzzy logic.
Алгоритмы нечеткой логики реализуют использование нечетких переменных в нечетких подмножествах нечетких множеств.
Если представить, что S - нечеткое множество, то P – нечеткое подмножество. P определяет степень вхождения значений нечетких переменых в нечеткое множество S.
Необходимо предусмотреть реализацию правила логического вывода. Любое правило состоит из двух частей:
если …, то …
1) если … - левая часть правила
2) то … - правая часть правила
В структуре логического вывода эти правила образуют цепочки. Степень вхождения нечеткой переменной в нечеткое множество определяется на основе суперпозиций степеней вхождения левой и правой частей правила. В дальнейшм происходит сколяризации данных до четкого реального значения. Т. о. алгоритм нечеткой логики реализует четыре основных задачи:
1) Определение степени вхождения заданного параметра в нечеткое подмножество по левой части правил логического вывода с использованием функции вхождения. Наиболее часто определение функций вхождения осуществляется с использованием трех интервалов – минимальное, среднее, высокое.
2) Определение функции вхождения при той же минимальной, средней, высокой градации функции вхождения для правых частей правил логического вывода.
3) Суперпозиция левых и правых частей правил. Задается определенная цена и модифицируется функция вхождения левой части правила.
Скаляризация – получение реальных значений.
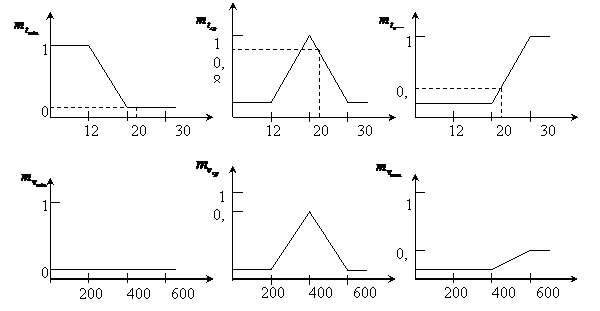
Пример - скорость вращения вентилятора. Если температура в помещении больше 20° С, то скорость вращения вентилятора – выше. Если температура в помещении меньше 20° С, то скорость вращения – ниже.
Нечеткое множество:
t - 12, 20, 30, 60.
U – 200, 400, 600, 1000.
1) Определение степени вхождения заданного параметра в нечеткое подмножество по левой части правил логического вывода с использованием функции вхождения.
Определим функцию вхождения ![]()
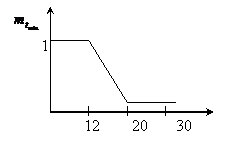 |
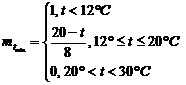
Определим функцию вхождения ![]()
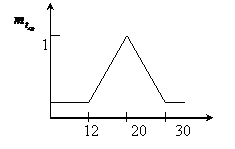
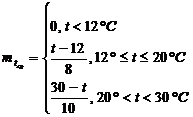
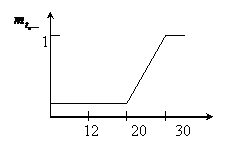 Определим функцию вхождения
Определим функцию вхождения ![]()
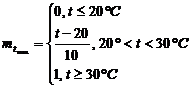
2) Определение степени вхождения заданного параметра в нечеткое подмножество по правой части правил логического вывода с использованием функции вхождения.
Определим функцию вхождения ![]()
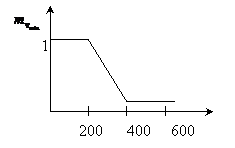 |
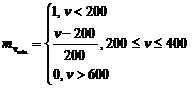
Определим функцию вхождения ![]()
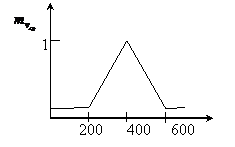
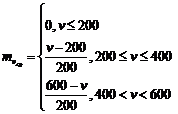
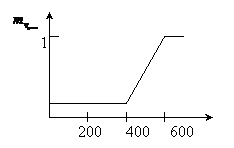 Определим функцию вхождения
Определим функцию вхождения ![]()
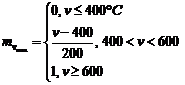
2) Суперпозиция левых и правых частей правил.
В данном случае определяем значения функции вхождения на графиках в левой части правил для конкретного значения:
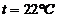
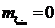
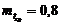
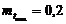
Суперпозиция заключается в изменении границы функции вхождения на графиках правых и левых частей правила.
 |
3) Сколяризация – определение суммарной величины функции вхождения путем объединения полученных на 3-м этапе графиков и нахождение центра тяжести графика.
 |
Центр тяжести графика будет определять скорость вращения вентилятора при температуре 22°С.
Получаем суммарный график.
2.17. Нейросетевые технологии
Искусственный нейрон
Основной моделью нейросетевой технологии является искусственный нейрон. Простой искусственный нейрон характеризуется совокупностью входов и выходов. Моделирование различных ситуаций на основе ярусов или ступеней искусственных нейронов приводит к идентификации на выходе данного явления.
Искусственный нейрон представлен на логическом уровне в бинарном виде в совокупности используемых пространств с помощью серых и белых шаров. Подобное моделирование используется в задачах обработки естественного языка, распознавания образов, аппроксимации функций, решение задач прогнозирования, планирования, в аналитической обработки запросов к хранилищам баз данных.
Искусственный нейрон j определяется теорией нейросетей, количеством входов ![]() {i=1,2}, весом входов
{i=1,2}, весом входов ![]() функцией состояния нейронов сети
функцией состояния нейронов сети ![]() и функцией активации нейронов при решении задачи f(
и функцией активации нейронов при решении задачи f(![]() ) = y.
) = y.
Различают 5 основных функций активации:
1. Пороговая линейная функция:
у = 0, при a<1, где a-порог функции
y = 1, при a³1 с учетом функции состояния нейронов сети ![]() .
.
2. Ступенчатая линейная функция:
у = 0, при S<a,
y = aS + b, при ![]() £ S £
£ S £![]() ,
,
у = 1, при S ³![]() .
.
3. Линейная функция:
y = kS + b, где k-множитель.
4. Функция Гауссиана:
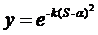
5. Сигмоидальная функция:
![]()
Парадигма нейронной сети определяется структурой нейронной сети (НС) и алгоритмом обучения сети. НС могут быть обучаемые и конструируемые. Для конструируемой сети в парадигму входит набор (или библиотека) образцов функционирования сети. А если сеть обучаемая, то строятся алгоритмы.
Различают одно-, двух - и n-уровневые нейронные сети.
Для решения поставленной задачи вводятся ассоциации НС с разделением в различных пространствах белых и серых шаров. Простой персептрон, т. е. одноуровневая двухвходная сеть не может решить поставленной задачи. Поэтому для решения задач используются 2-х и многоуровневые нейронные сети.
 |
Пакеты для использования НС технологий
На практике реально нет смысла использовать НС технологии, они применяются только в научных целях. Реализовывать нейросетевые алгоритмы на языках высокого уровня тоже не целесообразно. Гораздо эффективнее использовать существующие пакеты, которые включают решения всех реализуемых сетью задач.
Например: BrainMaker и AITM, включающий 3 технологии-
- Neuro Shell II
- Neuro Windows
- Hyper Logic.
Для решения задачи на основе использования нейросетевых технологий необходимо:
· хорошо знать предметную область,
· иметь представление о функциях НС,
· хорошо изучить пакет, использующий нейросетевую технологию.
Последовательность обработки информации с помощью нейронных сетей:
· Сбор исходных данных.
· Создание упорядоченных последовательностей на основе выделенных исходных данных.
· Определение закономерностей в изменении совокупности параметров:
- для текущих значений;
- для текущих значений со сдвигом на один шаг;
- определение периодичности повторяющихся событий.
Совокупность выделенных закономерностей является примерами, на которых обучается сеть. Тестирование сети предусматривает задание исходных параметров, проведения их по сети (по совокупности скрытых слоев) и получения на выходе правильных и неправильных результатов. Если неправильных ответов > 50 % от общего числа полученных ответов, то сеть обучена плохо. В этом случае следует переобучить или переконструировать сеть.
Если сеть обучена хорошо (т. е. правильных ответов>50 %) подавать на входы исходные данные по решаемой проблеме с учетом корректировки результата на указанный процент.
Пример: Совокупность подсистем Brain Maker включает подсистему Net Maker, работающую с нейросетевыми технологиями. Поставлена задача: требуется получить прогноз о среднегодовой температуре в Москве на 2002 год.
Необходимо:
1. в любом текстовом редакторе подготовить исходные данные, включающие год, среднегодовую температуру в данном году и совокупность сопутствующих факторов (влажность, атмосферное давление и т. д.). Данные в текстовом файле формируются по столбцам.
2. Организовать считывание текстового файла с расширением *.dat в Net Maker. Файл считывается по столбцам и формируются графики закономерностей появления событий в указанных годах по совокупности данных и сопутствующих им факторам. По оси Y откладывается мощность события, по оси X – конкретное значение.
3. Организовать сдвиг параметров среднегодовой температуры в столбцах на 1 шаг вверх или вниз, чтобы получить новое значение температуры. Построить графики закономерности для данных со сдвигом. Выполнить поиск закономерностей на основе указанных входных значений. Это и является обучением сети на совокупности примеров.
4. Выполнить тестирование сети: задав заведомо правильные значения по годам, на выходе сети получаем процент правильных и неправильных значений.
5. Получить результаты: ввод реальных значений по годам.
2.18. Генетические алгоритмы
Технология, используемая для получения вероятностной или локально-оптимальной характеристики целевой функции. При реализации генетических алгоритмов моделируются эволюция происхождения событий, подобно живой природе. Алгоритмы данной группы не дают оптимального результата, однако имеют удовлетворительную сходимость.
Основные понятия теории генетических алгоритмов
Фенотип – формат кодирования информации по решаемой проблеме.
Генотип – единица информации кода (особь).
Операции генетического алгоритма:
· селекция – создание родительской популяции;
· операция скрещивания (операция Кроссенговера) – модификация кода особей
родителей;
· операция мутации – внесение случайным образом или на основе заданного закона изменение в один из разрядов на заданную долю величины от единицы и в сторону уменьшения;
· получение потомков – значение функции оптимизации, для которых является
приближенной к оптимальному значению.
Вероятность мутации. Определяется как частное от деления вероятности значения целевой функции для i-ой особи на сумму вероятностей всей популяции.
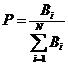
Целевая функция для особи резервируется в зависимости от решаемой задачи.
Популяция – совокупность родительских особей, участвующих в селекции.
Элитизм – передача родительских особей в фонд скрещивания с потомками.
Пример:
1 | 2 | 3 | 4 | 5 | |
1 | 0 | 4 | 6 | 2 | 9 |
2 | 4 | 0 | 3 | 2 | 9 |
3 | 6 | 3 | 0 | 5 | 9 |
4 | 2 | 2 | 5 | 0 | 8 |
5 | 9 | 9 | 9 | 8 | 0 |
Кодирование информации осуществляется только на начальном этапе (операция эволюции выполняется только с кодом). Предположим, что этап селекции был выполнен, соответственно выполнение этапа определяется генотипом особей:
№ | Генотип |
| Р | ||||
1 | 1 | 2 | 3 | 4 | 5 | 20 | 20/93 |
2 | 2 | 1 | 3 | 4 | 5 | 23 | 23/93 |
3 | 3 | 4 | 5 | 1 | 2 | 26 | 26/93 |
4 | 4 | 5 | 1 | 2 | 3 | 24 | 24/93 |
Р – вероятность скрещивания. Генотип определяет последовательность обхода узлов графа, в соответствии с заданным законом.
Найдем значение критерия качества для минимальной суммы длин соединения:
![]() =4+3+5+8=20
=4+3+5+8=20
![]() =4+6+5+8=23
=4+6+5+8=23
![]() =5+8+9+4=26
=5+8+9+4=26
![]() =8+9+4+3=24
=8+9+4+3=24
Этап скрещивания: выбираем 2 наиболее оптимальные особи. Для выполнения операции Крассенговера разделим код на разряды:
№ | Генотип | |||
1 | 1 | 23 | 45 |
|
2 | 2 | 13 | 45 |
|
№ | Генотип |
| ||
3 | 3 | 451 | 2 |
|
4 | 4 | 512 | 3 |
|
Родители
Меняем местами соответствующие разряды в строках:
Потомки
№ | Генотип | |||
1 | 2 | 23 | 45 | 16 |
2 | 1 | 23 | 45 | 20 |
Мутация
№ | Генотип | |||
3 | 4 | 451 | 2 | 21 |
4 | 3 | 512 | 3 | 25 |
2.19. Технология Data Mining
KDD – Knowledge of discovery in database. Данная технология предназначена для работы с хранилищами данных в распределенном пространстве.
Технология Data Mining заключается в определении закономерностей, фактов или событий, встречающихся в хранилищах данных, с целью получения максимальной прибыли или оптимизации работы деятельности компании. Data Mining отличается от технологий разработчиков систем типа OLAP наличием статической (динамической) количественной оценки взаимосвязанных факторов. Аналитическая система OLAP только описывает факты, так как они есть.
Всю совокупную информацию в хранилищах данных можно представить в трех слоях:
1. Оперативная обработка данных (обработка транзакций)
2. и 3. Недоступны для использования в аналитической системе. Т. о. для слоя 2, недоступной для оперативной обработки и для исследования данных, в используется интеграция методов OLAP, аналитическая обработка и технология Data Mining (может быть реализована только для второго слоя).
Технология Data Mining осуществляет поиск закономерности в обозримом пространстве данных с помощью следующих моделей:
· Классификация – использование единственной переменной, определяющей класс совершающихся событий.
· Регрессионный анализ – классификация событий в обозримом пространстве данных по нескольким переменным.
Регрессионный анализ в пространстве – изменение классификационных характеристик обозримого пространства данных, с учетом показателя времени.
Кластеризация – определение кластеров параметров по значению метаданных в обозримом пространстве данных.
Ассоциации – исследование структур имеющихся событий в обозримом пространстве данных.
Последовательность – извлечение закономерности из совокупности событий следующих друг за другом.
Методы поиска закономерностей технологии Data Mining:
· Нейронные сети.
· Бинарные и деревья (tree).
· Нечеткие множества.
· Выделение ассоциаций, последовательностей.
· Интеллектуальная обработка данных.
· Синтаксический, семантический анализ.
· Генетические алгоритмы.
· Эволюционное программирование.
· Сравнение с образцами предшествующих данных.
Последовательность реализации задачи раскопок данных:
Изучение предметной области для Data Mining.
Подготовка информации в хранилище данных для выполнения Data Mining, т. е. выделение в многомерном пространстве данных N-мерные структур, которые предназначены для передачи данных на уровень Data Mining.
Исследование данных в обозримом пространстве данных, исключение ”мусора”.
Моделирование ситуаций, приводящих к выгоде на основе использования моделей и методов.
Тестирование созданных моделей на основе новых закономерностей, определение работоспособности моделей.
Работа аналитика с разработанным программным средством (конкретной фирмы или корпорации).
Инструменты:
Inter Prass Prainer, SQL.
2.20. Геоинформационные системы
Все технологии, связанные с обработкой, визуализацией и манипулированием данными называется информационными технологиями. Технология функционирования геоинформационных систем является новейшей технологией обработки и манипулированием данными. Технология разработки таких систем предполагает интеграцию значений данных, имеющих текстовый или фактографический характер с данными, представленных в виде топологического представления. Такая интеграция позволяет выполнить естественную визуализацию и анализ данных, относящихся как к каждому топологическому элементу представления, так и к общему представлению информации о ситуации или объекте.
Геоинформационные системы нельзя смешивать или путать с системами картографии, визуального зондирования местности или с системами топологического проектирования, хотя характер обработки информации может совпадать.
Информация в геоинформационных системах носит информативный характер и
представлена в нескольких тематических слоях. Интеграция слоев позволяет выполнить анализ.
В свою очередь, универсальные ГИС могут быть профессиональными и настольными. Отдельная область – это открытые геоинформационные системы, которые определяют особую область современных исследований – интранетика. Последние версии систем имеют возможность организации работы в сети.
К универсальным профессиональным средствам разработки систем относятся две системы: Inter Graph + Inter Geo, Info Arc, реализованные на main frame.
Универсальные настольные средства создания приложений: Map Info, Auto Desk, Geo Draw, CADdy и система Панорама. Панорама и CADdy являются системами для планирования и топологического проектирования только картографической информации. Система CADdy является только кадастровой системой.
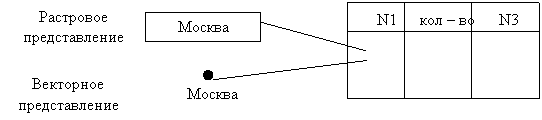
Каждая геоинформационная система или приложение оперирует векторной или растровой информацией. Векторная информация связана с координатным представлением точек на поверхности топологической основы. Растровая информация определена фрагментом или ячейкой на топологической основе. Каждая ячейка при этом характеризуется совокупностью непрерывных свойств (изменение одного и того же понятия в пределах одной ячейки). Совокупность ячеек (растров) образует кадастр, следовательно, любое представление информации ориентировано на работу в кадастровой геоинформационной системе. Кроме того, кадастр (реестр) может определять совокупность ячеек, принадлежащих к одному и тому же типу данных (единица информации).
Представление данных в любой ГИС осуществляется в 3 этапа:
задание топологической основы решаемой задачи. Это может быть выполнено:
а) простым сканированием информации;
б) в настольных универсальных инструментах имеются свойства создания топологической основы, реализованные в виде графических редакторов, работающих с картографической информацией;
в) использование интерфейса ГИС другого уровня (т. е. организация преемственности между форматами данных).
формирование фактологической базы данных или создание атрибутивных полей. Атрибутивные поля (АП) – поля базы данных, которые будут интегрированы с точками или ячейками топологической основы. В реляционной базе данных атрибутивные поля будут представлены таблицами. В объектно-ориентированных системах управления данными это будет иерархия классов.
интеграция атрибутивных данных (полей) и картографического представления информации. Интеграция осуществляется по нескольким тематическим слоям.
 |
Основные операции ГИС:
1. сбор и подготовка данных;
2. визуализация представления;
3. манипулирование данными (актуализация информации).
4. запросы и анализ информации;
5. наличие удобного интерфейса.
Новые информационные технологии классифицируются следующим образом:
1. Системы документооборота и фактологической базы данных
В основе таких систем лежат:
· информационно-поисковые системы;
· системы искусственного интеллекта или системы, основанные на знаниях;
· технологии организации хранилищ данных.
2. Распределенные и параллельные базы данных.
В их основе лежат:
· системы обработки транзакций;
· нейросетевые технологии;
· системы искусственного интеллекта,
· системы, основанные на знаниях.
3.Бизнес - процесс реинжениринг (BPR).
Системы реинжениринга бизнеса предназначены для кардинального, резкого, эффективного улучшения деятельности работы предприятия или компании на основе перепланирования ее деятельности. Если традиционно процесс производства или оказания услуги разбивается на задания, составляющие его, то система реинжениринга предполагает разбиение решаемой задачи на процессы. Выход каждого процесса является входом следующего процесса. При описании модели компании модель, на которой описываются процессы называется прецедентной, т. к. каждый процесс является прецедентом, т. е. он связан с работой (или функционированием) подразделения предприятия. 1-й этап реинжениринга – создание прецедентной модели. 2-й этап реинжениринга – построение имитационной не прецедентной модели. Результат второго этапа будет представлять внутреннюю модель компании, пригодную для использования.
4.Технологии: имитационное моделирование, неиросетевые технологии, системы, основанные на знаниях, экспертные системы (технология G2: Re think).
5. Дистанционное обучение.
Дистанционное обучение – самая новая технология. В нее входят:
· системы аналитической обработки и представления хранилищ данных olap;
· экспертные системы;
· технологии мультимедиа, гипермедиа, экстрамедиа.
Литература
1. Люгер Дж. Ф. Искусственные интеллектуальные стратегии и методы
решения сложных проблем. М. : Вильямс, 2005. – 864 с.
2. Искусственный интеллект: современный подход. М. : Вильямс,
2006. – 1408 с.
3. Попов и динамические экспертные системы. М.:Финансы и
статистика. 1998.
4. , Базы знаний интеллектуальных систем.2001.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
