


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Автор | Наименование | Год издания | Кол-во экземпляров | |
В библиотеке | На кафедре | |||
, | Практическая грамматика английского языка. | 2001 | 2 | - |
- | ||||
. | - | |||
. | - |
5.3. Методические разработки
Автор | Наименование, вид | Год издания | Кол-во экземпляров | |
В библиотеке | На кафедре | |||
Методические указания Для проверки самостоя- тельной работы по «Истории английского языка» | 2003 | 25 | 25 | |
Методические рекоменда Ции для проведения семинарских занятий по «Истории английского языка» | 2004 |
5.4. Технические и электронные средства обучения, иллюстрированные материалы (в т. ч. учебные фильмы).
Автор | Наименование | Год издания | Кол-во | Место хранения |
Hammond World Atlas | Статьи в энциклопедии на нужную тему. Компакт диск | 1998 | 1 | кафедра |
The 1995 World Almanac and Book of Facts | Статья в энциклопедии На нужную тему. Компакт диск | 1998 | 1 | кафедра |
Funk and Wagnalls. | Статья в энциклопедии на нужную тему. Компакт диск. | 1998 | 1 | Кафедра |
Программа утверждена Программа утверждена на
на заседании учебно-методической комиссии заседании кафедры
_________________________
протокол № протокол №
от «____» _______ от «_____» ___________
_______________ ____________________
1. Введение
Контролируемые учебные элементы
Студент должен знать об особенностях английского языка, ознакомиться с артикуляцией (+ артикуляционная гимнастика) и классификацией английских гласных и согласных.
Основное содержание лекций
1. Органы речи и их работа.
2. Гласные и согласные.
3. Основные принципы классификации согласных.
4. Основные принципы классификации гласных.
Параллельные компьютеры и суперЭВМ
К классу супер-ЭВМ принадлежат лишь те компьютеры, которые имеют максимальную производительность в настоящее время. Быстрое развитие компьютерной индустрии определяет относительность данного понятия - то, что десять лет назад можно было назвать суперкомпьютером, сегодня под это определение уже не попадает. Например, производительность персональных компьютеров, использующих Pentium-III/500MHz, сравнима с производительностью суперкомпьютеров начала 70-х годов, однако по сегодняшним меркам суперкомпьютерами не являются ни те, ни другие.
Супер-ЭВМ это компьютеры, имеющие в настоящее время не только максимальную производительность, но и максимальный объем оперативной и дисковой памяти (и специализированное ПО, с помощью которого можно эффективно всем этим воспользоваться).
Задачи, приводящие к использованию суперЭВМ
Список областей человеческой деятельности, где использование суперкомпьютеров действительно необходимо:
нефте - и газодобыча
прогноз погоды и моделирование изменения климата
сейсморазведка
проектирование электронных устройств
синтез новых материалов
и другие
Параллельная и конвейерная обработка данных
Параллельная обработка. Если некое устройство выполняет одну операцию за единицу времени, то для выполнения N операций потребуется N единиц времени. Если имеется система из P независимых устройств, то ту же работу она выполнит за N/P единиц времени.
Идея конвейерной обработки заключается в выделении отдельных этапов выполнения общей операции, причем каждый этап, выполнив свою работу, передает результат следующему, одновременно принимая новую порцию входных данных. Очевидный выигрыш в скорости обработки получается за счет совмещения разнесенных во времени операций.
2. Фонетика: Согласные [k], [g], [t], [d], [n], [s], [z], [²], [ð], [p], [b], [m]. Гласные [i], [e]. Палатализация. Словесное ударение. Основные классы параллельных компьютеров
Контролируемые учебные элементы
Студент должен знать основные классы суперкомпьютеров, их основные особенности, иметь представление о современных суперЭВМ, относящихся к данным классам.
Основное содержание лекций
Массивно-параллельные системы (MPP)
Система состоит из однородных вычислительных узлов, включающих:
один или несколько центральных процессоров (обычно RISC),
локальную память (прямой доступ к памяти других узлов невозможен),
коммуникационный процессор или сетевой адаптер
иногда - жесткие диски (как в SP) и/или другие устройства В/В
К системе могут быть добавлены специальные узлы ввода-вывода и управляющие узлы. Узлы связаны через некоторую коммуникационную среду (высокоскоростная сеть, коммутатор и т. п.)
Симметричные мультипроцессорные системы (SMP)
Система состоит из нескольких однородных процессоров и массива общей памяти (обычно из нескольких независимых блоков). Все процессоры имеют доступ к любой точке памяти с одинаковой скоростью. Процессоры подключены к памяти либо с помощью общей шины, либо с помощью коммутатора.
Системы с неоднородным доступом к памяти (NUMA)
Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т. е. к памяти других модулей. При этом доступ к локальной памяти в несколько раз быстрее, чем к удаленной.
Параллельные векторные системы (PVM)
Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах.
Кластерные системы
Набор рабочих станций (или даже ПК) общего назначения, используется в качестве дешевого варианта массивно-параллельного компьютера. Для связи узлов используется одна из стандартных сетевых технологий (Fast/Gigabit Ethernet, Myrinet) на базе шинной архитектуры или коммутатора.
Задания для самостоятельной работы
Подготовить сообщение о современных суперЭВМ различных классов. При подготовке сообщения выделить класс ЭВМ, среднюю и пиковую производительность, особенность программирования. Сообщение оформить в виде электронной презентации.
3. Классификация параллельных архитектур
Контролируемые учебные элементы
Студент должен знать основные принципы классификации суперкомпьютеров, предложенные Флинном, Фенгом, Хокни, Хендлером. Студент должен иметь представление о достоинствах и недостатках каждого типа классификации.
Основное содержание лекций
Классификация Флинна
Самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М. Флинном. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD, MISD, SIMD, MIMD.
Классификация Фенга
В 1972 году Т. Фенг предложил классифицировать вычислительные системы на основе двух простых характеристик. Первая - число бит n в машинном слове, обрабатываемых параллельно при выполнении машинных инструкций. Практически во всех современных компьютерах это число совпадает с длиной машинного слова. Вторая характеристика равна числу слов m, обрабатываемых одновременно данной вычислительной системой.
Достоинством является введение единой числовой метрики для всех типов компьютеров, которая вместе с описанием потенциала вычислительных возможностей конкретной архитектуры позволяет сравнить любые два компьютера между собой.
Классификация Хокни
Р. Хокни разработал свой подход к классификации, введенной им для систематизации компьютеров, попадающих в класс MIMD по систематике Флинна.
Основная идея классификации состоит в том, что множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством.
Классификация Хендлера
В основу классификации В. Хендлер закладывает явное описание возможностей параллельной и конвейерной обработки информации вычислительной системой. Предложенная классификация базируется на различии между тремя уровнями обработки данных в процессе выполнения программ:
уровень выполнения программы - опираясь на счетчик команд и некоторые другие регистры, устройство управления (УУ) производит выборку и дешифрацию команд программы;
уровень выполнения команд - арифметико-логическое устройство компьютера (АЛУ) исполняет команду, выданную ему устройством управления;
уровень битовой обработки - все элементарные логические схемы процессора (ЭЛС) разбиваются на группы, необходимые для выполнения операций над одним двоичным разрядом.
5. Основы интерфейса передачи сообщений (MPI)
5.1 Введение, состав инструментария, нотация записи, основные понятия
Контролируемые учебные элементы
Студент должен знать назначение библиотеки MPI, стиль программирования с использованием библиотеки MPI, основные понятия, используемые при программировании в MPI. Студент должен иметь навыки по созданию и запуску параллельных приложений в среде Visual C++ 6.0, с использованием MPICH 1.2.5
Основное содержание лекций
Введение
Создание параллельной программы включает в себя основные стадии:
последовательный алгоритм подвергается декомпозиции (распараллеливанию), т. е. разбивается на независимо работающие ветви;
для взаимодействия в ветви вводятся две дополнительных нематематических операции: прием и передача данных;
распараллеленный алгоритм записывается в виде программы, в которой операции приема и передачи записываются в терминах конкретной системы связи между ветвями.
Состав инструментария
MPI - это стандарт на программный инструментарий для обеспечения связи между ветвями параллельного приложения. MPI расшифровывается как "Message passing interface" ("Взаимодействие через передачу сообщений"). MPI предоставляет программисту единый механизм взаимодействия ветвей внутри параллельного приложения независимо от машинной архитектуры.
В его состав входят, как правило, два обязательных компонента:
библиотека программирования для языков Си, Си++;
загрузчик исполняемых файлов.
Основные понятия
Для MPI принято писать программу, содержащую код всех ветвей сразу. MPI-загрузчиком запускается указываемое количество экземпляров программы. Каждый экземпляр определяет свой порядковый номер в запущенном коллективе, и в зависимости от этого номера и размера коллектива выполняет ту или иную ветку алгоритма.
Группа - это некое множество ветвей. Каждой группе соответствует идентификатор, называемый коммуникатором, который можно рассматривать как дескриптор коллектива. Он ограничивает область действия некоторой функции соответствующим коллективом. Программист вручную назначает тэги (идентификаторы) сообщениям, они служат для более точного распознавания сообщений.
Лабораторная работа № 2. Изучение загрузчика параллельных приложений MPIRun
Задания для самостоятельной работы
Изучить разделы «Введение», «Основные понятия» электронной информационно-справочной системы «Программирование в MPI».
Найти ответы на вопросы:
1. Каким образом могут передаваться данные в MPI?
2. Из чего состоит инструментарий MPI?
3. Для каких операционных систем разработан MPI?
4. Какова нотация записи функций в стандарте MPI?
5. Какая модель параллелизма используется при написании программ в MPI?
6. Что такое «область связи»?
5.2 Типы данных и константы. Обрамляющие функции стандарта MPI
Контролируемые учебные элементы
Студент должен знать особенности работы с типами данных в MPI, назначение и особенности использования обрамляющих функций, уметь использовать обрамляющие функции при разработке параллельных приложений.
Лабораторная работа № 3. Структура MPI программы
Задания для самостоятельной работы
Изучить раздел «Основные понятия» электронной информационно-справочной системы «Программирование в MPI».
Найти ответы на вопросы:
1. Для чего MPI необходимо знать тип пересылаемых данных?
2. Для чего в MPI используются описатели типов?
3. Для чего в MPI используются джокеры?
4. Как в MPI описывается начальная область связи?
5. Каково назначение обрамляющих функций MPI?
6. Как оформляется MPI программа?
4. Тематика
Темы сообщений по разделу «2. Основные классы параллельных компьютеров»
Соотношение популярности использования различных классов высокопроизводительных вычислительных систем
Современные SMP системы
Современные MPP системы
Современные NUMA системы
Современные PVP системы
Современные кластерные системы
Принципы построения кластерных систем
Компьютеры фирмы CRAY
Тематика и задания к лабораторным работам
Лабораторная работа №1. Разработка параллельных приложений в среде Visual C++ 6.0 на основе MPICH 1.2.5
Создать новое приложение в среде Visual C++ 6.0
File → New → Windows Console Application, указать месторасположение
тип приложения Simple Application, тогда будут созданы все необходимые файлы
Установить параметры приложения Project → Settings
Settings for : All Configurations;
- закладка С/С++; Category Preprocessor; в разделе Additional include directories вписать путь к заголовочным файлам C:\Program Files\MPICH\SDK\include
- закладка Link; Category Input; в разделе Additional library path вписать путь к библиотечным файлам C:\Program Files\MPICH\SDK\lib
Settings for : Win32Debug;
- закладка С/С++; Category Code Generation; в разделе Use run-time library выбрать Debug Multithreaded
- закладка Link; Category General; в разделе Object/Library modules вписать файлы ws2_32.lib mpichd. lib
Settings for : Win32Release;
- закладка С/С++; Category Code Generation; в разделе Use run-time library выбрать Multithreaded
- закладка Link; Category General; в разделе Object/Library modules вписать файлы ws2_32.lib mpich. lib
1. Написать параллельную программу «Hello world». Каждый процесс выводит приветствие с указанием своего номера. Для использования функций MPI подключить заголовочный файл mpi.h.
Лабораторная работа №2. Изучение загрузчика параллельных приложений MPIRun
Запустить загрузчик параллельных приложений MPIRun
Изучить параметры загрузчика
Загрузить параллельную программу «Hello world» из лабораторной работы №1
Запустить программу на выполнение в режиме эмуляции с использованием различного числа процессов, обратить внимание на способ вывода информации различными процессами
Запустить программу на выполнение на различных компьютерах, установив параметры загрузчика:
вывод в файл
без очистки окна вывода при каждом запуске
Лабораторная работа № 3. Структура MPI программы
Создать новый проект и настроить его для работы с MPI
Вставить обрамляющие функции
Определить количество процессов и номер текущего процесса в группе
Вывести все числа, кратные P в интервале [1, N], где N, P задаются в виде констант
Рекомендации
Разбить отрезок [1, N] равномерно между процессами и каждым процессом исследовать только свой отрезок.
1. Синхронизировать процессы
2. Выполнить замер времени работы программы
3. Запустить программу на нескольких компьютерах, сравнить результаты
Лабораторная работа № 4. Основы точечного взаимодействия
1. Реализовать задачу с использованием блокирующих и неблокирующих обменов
2. Провести численные эксперименты (замер времени работы) для 1, 2, ..., 8 компьютеров. Результаты занести в таблицу.
Задачи
1. Вычислить приближенное значение криволинейного интеграла на отрезке [a, b] методом трапеций с равномерным разбиением на n отрезков.
2. Для вычислимой функции f(x) найти точки максимума и минимума на отрезке [a; b] с точностью d=1/n.
3. Для вычислимой функции f(x) найти точку на отрезке [a; b] с точностью d=1/n, значение в которой наиболее близко к заданному Y.
4. Для вычислимой функции f(x) найти процентное соотношение положительных и отрицательных значений при равномерном разбиении отрезка [a; b] на n точек.
Рекомендации
Частичные отрезки или точки распределить равномерно между работающими процессами; тогда каждый процесс будет решать поставленную задачу на своих отрезках; результаты работы собрать и обработать в нулевом процессе.
При проведении экспериментов выполнить по 5 измерений общего времени работы программы и найти среднее арифметическое для n=100, 10000, 1 для каждого числа используемых компьютеров. Результаты занести в таблицу вида:
p | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
n=100 | tp | ||||||||
Ep | |||||||||
n=10000 | tp | ||||||||
Ep | |||||||||
n=100000 | tp | ||||||||
Ep | |||||||||
n=1000000 | tp | ||||||||
Ep |
Лабораторная работа № 5. Основы коллективного взаимодействия
Реализовать все точечные операции лабораторной работы № 4 с помощью коллективных функций.
Лабораторная работа № 6. Численные характеристики параллелизма
Построить графики зависимости времени работы программы лабораторной работы № 4от числа процессоров для всех значений n
Построить диаграммы эффективности работы программы, группировку провести по n
Проанализировать вид графиков и выяснить причины, влияющие на данную ситуацию
Лабораторная работа № 7. Разбиение процессов на группы
Написать программу разделения исходной группы процессов MPI_COMM_WORLD на два коммуникатора - четные и нечетные процессы с использованием и без использования групп.
5. Перечень вопросов промежуточной аттестации
Варианты контрольных работ
Контрольная работа по разделам
«Основные классы параллельных компьютеров», «Классификация параллельных архитектур»
ВАРИАНТ 1 Ф. И.О. _________________________________________________
1. Укажите класс параллельного компьютера, к которому относится следующее определение
«Однородные вычислительные узлы с локальной памятью, соединенные некоторой коммуникационной средой; прямой доступ к памяти других узлов невозможен »
1. массивно-параллельные (MPP) 3. кластерные системы
2. симметричные мультипроцессорные (SMP) 4. параллельные векторные (PVP)
5. системы с неоднородным доступом к памяти (NUMA)
2. К недостаткам SMP систем относится …
1. медленное взаимодействие между процессорами 3. плохая масштабируемость
2. небольшое число процессоров 4. сложность программирования
3. Среди перечисленных обозначений к классификации Флинна относятся …
1. SISD 3. переключаемые MIMD с общей памятью
2. t (C)=(k, d,w) 4. MISD
4. Класс MISD в настоящее время считается
1. переполненным 3. содержащим конвейерные машины
2. пустым 4. содержащим векторные машины
5. Запишите основные положения классификации Фенга
ВАРИАНТ 2 Ф. И.О. __________________________________________________
1. Укажите класс параллельного компьютера, к которому относится следующее определение
«Набор рабочих станций общего назначения, связанных между собой с использованием стандартной сетевой технологии »
1. массивно-параллельные (MPP) 3. кластерные системы
2. симметричные мультипроцессорные (SMP) 4. параллельные векторные (PVP)
5. системы с неоднородным доступом к памяти (NUMA)
2. К достоинствам SMP систем относится …
1. дешевизна 3. наличие средств автоматического распараллеливания
2. простота масштабирования 4. легкость программирования
3. Среди перечисленных обозначений к классификации Хокни относятся …
1. MIMD конвейерные 3. t(c)=(n, m)
2. t(C)=(k, d,w) 4. SIMD
4. Кластерные системы можно отнести к классу …
1. SISD 3. SIMD
2. MIMD 4. MISD
5. Запишите основные положения классификации Хендлера
ВАРИАНТ 3 Ф. И.О. __________________________________________________
1. Укажите класс параллельного компьютера, к которому относится следующее определение
«Однородные базовые модули из нескольких процессоров и блока памяти, объединенные с помощью высокоскоростного коммутатора; поддерживается единое адресное пространство»
1. массивно-параллельные (MPP) 3. кластерные системы
2. симметричные мультипроцессорные (SMP) 4. параллельные векторные (PVP)
5. системы с неоднородным доступом к памяти (NUMA)
2. К достоинствам кластерных систем относится …
1. простота взаимодействия процессоров 3. дешевизна
2. простота масштабирования 4. легкость программирования
3. Среди перечисленных обозначений к классификации Фенга относятся …
1. t(C)=(k, d,w) × (k1,d1,w1) 3. MIMD с переключателем
2. t(C)=(k, d,w) 4. MISD
4. Системы с векторной обработкой данных можно отнести к классу …
1. SISD 3. SIMD
2. MIMD 4. MISD
5. Запишите основные положения классификации Хокни
ВАРИАНТ 4 Ф. И.О. __________________________________________________
1. Укажите класс параллельного компьютера, к которому относится следующее определение
«Система из однородных процессоров и массива общей памяти »
1. массивно-параллельные (MPP) 3. кластерные системы
2. симметричные мультипроцессорные (SMP) 4. параллельные векторные (PVP)
5. системы с неоднородным доступом к памяти (NUMA)
2. К достоинствам MPP систем относится …
1. высокая скорость взаимодействия процессоров 3. широкий класс решаемых задач
2. простота масштабирования 4. легкость программирования
3. Среди перечисленных обозначений к классификации Хендлера относится…
1. SISD 3. t(С)=(n, m)
2. t(C)=(k, d,w) 4. t(C)=(k, d,w) × (k1,d1,w1)
4. Впервые ввел единую числовую характеристику для описания параллельных машин …
1. Хендлер 3. Хокни
2. Флинн 4. Фенг
5. Запишите основные положения классификации Флинна
Контрольная работа по разделам
«Модели параллельного программирования», «Численные характеристики параллелизма», «Этапы разработки параллельных алгоритмов», «Параллельные алгоритмы обработки матриц»
ВАРИАНТ 1 Ф. И.О. __________________________________________________
1. Запишите понятие эффективности алгоритма
2. Параллельный алгоритм средних произведений умножения матриц ( A – m´ n , B – n´ q) отражает формула …
1. 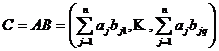 2.
2. 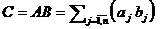 3.
3. 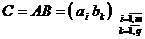
3. Для программирования в модели параллелизма данных наиболее характерно …
1. простота программирования 3. сложность программирования
2. планирование коммуникаций 4. глобальное пространство имен
4. При разработке параллельного алгоритма на этапе планирования вычислений выполняется …
1. выделение параллельных подзадач 3. выбор способа связи между подзадачами
2. проверка масштабируемости алгоритма 4. определение процессоров для подзадач
5. Для связи подзадач НЕ существует тип коммуникаций …
1. локальные 3. серверные
2. глобальные 4. синхронные
ВАРИАНТ 2 Ф. И.О. __________________________________________________
1. Запишите понятие задачи отображения
2. Параллельный алгоритм внешних произведений при умножении матриц ( A – m´ n , B – n´ q) отражает формула …
1. 2. 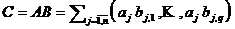 3.
3. 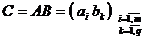
3. Для программирования в модели параллелизма задач наиболее характерно …
1. выделение параллельных подзадач 3. сложность программирования
2. планирование коммуникаций 4. четкая синхронизация вычислений
4. На этапе декомпозиции при разработке параллельного алгоритма выполняется …
1. выделение параллельных подзадач 3. выбор способа связи между подзадачами
2. разбиение массивов данных на фрагменты 4. определение процессоров для выполнения подзадач
5. Основными критериями при укрупнении являются …
1. упрощение масштабирования 3. упрощение программирования
2. уменьшение коммуникаций 4. синхронизация коммуникаций
ВАРИАНТ 3 Ф. И.О.__________________________________________________
1 Запишите понятие ускорения алгоритма
2. Параллельный алгоритм скалярных произведений умножения матриц ( A – m´ n , B – n´ q) отражает формула …
1. 2. 3.
3. Для программирования в модели параллелизма задач НЕ характерно …
1. единое пространство памяти 3. простота программирования
2. планирование коммуникаций 4. четкая синхронизация вычислений
4. На этапе проектирования коммуникаций при разработке параллельного алгоритма НЕ выполняется …
1. выделение параллельных подзадач 3. выбор способа связи между подзадачами
2. выбор способа управления подзадачами 4. определение процессоров для выполнения подзадач
5. При выделении параллельных подзадач желательно, что бы их количество …
1. зависело от размерности задачи 3. не менялось при изменении параметров задачи
2. строго соответствовало числу процессоров 4. на порядок превосходило число процессоров
ВАРИАНТ 4 Ф. И.О.__________________________________________________
1. Запишите понятие средней степени параллелизма
2. К параллельному алгоритму средних произведений умножения матриц ( A – m´ n , B – n´ q) НЕ относятся формулы …
1. 2. 3.
3. Для программирования в модели параллелизма данных НЕ характерно …
1. простота программирования 3. сложность программирования
2. планирование коммуникаций 4. выделение крупных параллельных подзадач
4. При разработке параллельного алгоритма вопрос о возможности распараллеливания решается на этапе …
1. проектирования коммуникаций 3. укрупнения
2. декомпозиции 4. планирования вычислений
5. При планировании вычислений основными критериями при распределении подзадач по процессорам являются …
1. уменьшение времени работы программы 3. уменьшение обменов
2. синхронизация обменов 4. выравнивание нагрузки
Контрольная работа по теме «Коллективный обмен данными»
ВАРИАНТ 1 Ф. И.О. __________________________________________________
1. Зарисуйте схему работы коллективной функции MPI_Bcast(…)
2. Используя функции точечных коммуникаций, напишите аналог коллективной операции MPI_Allgather(…)
ВАРИАНТ 2 Ф. И.О. __________________________________________________
1. Зарисуйте схему работы коллективной функции MPI_Gather(…)
2. Используя функции точечных коммуникаций, напишите аналог коллективной операции MPI_Bcast(…)
ВАРИАНТ 3 Ф. И.О. __________________________________________________
1. Зарисуйте схему работы коллективной функции MPI_Scatter(…)
2. Используя функции точечных коммуникаций, напишите аналог коллективной операции MPI_Gather(…)
ВАРИАНТ 4 Ф. И.О. __________________________________________________
1. Зарисуйте схему работы коллективной функции MPI_Allgather(…)
2. Используя функции точечных коммуникаций, напишите аналог коллективной операции MPI_Scatter(…)
Вопросы к зачету
Классы параллельных компьютеров.
Классификация параллельных архитектур Флинна.
Классификация параллельных архитектур Фенга.
Классификация параллельных архитектур Хендлера.
Основные характеристики параллельных алгоритмов: степень параллелизма, ускорение, эффективность; понятие задачи отображения.
Модель программирования «параллелизм данных», достоинства и недостатки.
Модель программирования «параллелизм задач», достоинства и недостатки.
Этапы разработки параллельного алгоритма. Декомпозиция.
Этапы разработки параллельного алгоритма. Проектирование коммуникаций.
Параллельные алгоритмы умножения матрицы на вектор.
Параллельный алгоритм средних произведений умножения матриц.
Параллельный алгоритм внешних произведений умножения матриц.
Интерфейс передачи сообщений (MPI). Почему MPI нужно знать тип пересылаемых данных?
Коммуникации точка-точка. Отличия блокирующих и неблокирующих обменов.
Идентификатор сообщений, его использование. Назначение переменной статуса (status).
Группы процессов: способы создания, использование.
Область взаимодействия процессов. Назначение коммуникаторов.
Отличия коммуникаций точка-точка от коллективных. Выход из коллективной функции для каждого процесса.
Особенности векторных вариантов коллективных операций.
6. Учебно-методическое обеспечение программы
Дж. Ортега Введение в параллельные вычислительные системы. 1994
С. Немнюгин, О. Стесик Параллельное программирование для многопроцессорных вычислительных систем, 2002
http://fmf. *****/uchmater. htm
Информационно-справочная система «Программирование в MPI»
http://*****
Параллельные вычисления в России
http://*****
Курс лекций «Параллельная обработка данных», Лаборатория Параллельных Информационных Технологий, НИВЦ МГУ

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
