

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ВВЕДЕНИЕ В МАТЕМАТИЧЕСКУЮ СТАТИСТИКУ
Информационный блок
Первоначально статистикой называлось изучение государственных дел. В 17 веке в Европе горстка математиков проводила небольшие частные исследования, которые впоследствии оформились в теорию вероятностей.
Начало статистической теории измерений положены Карлом Фридрихом Гауссом. В его основном труде по астрономии «Теория движения небесных тел» содержится способ определения орбит планет по наблюдениям, который опирается на развитую им же классическую теорию ошибок измерений.
Важной сферой применения методов математической статистики является массовое производство. Первые идеи в этой области принадлежат одному из директоров крупных пивоваренных заводов Гиннеса в Англии. В начале XX в. он прочитал книгу по теории вероятностей и подумал, что "из этого можно делать деньги". Позвав к себе Уильяма Госсета, младшего служащего завода, директор предложил ему поехать в единственный в то время центр статистических исследований в Лондоне для учебы под руководством крупнейшего статистика, биолога и философа Карла Пирсона, основателя журнала "Биометрика11. У. Госсет проявил инициативу и выдающиеся способности и вскоре приступил к самостоятельным исследованиям. Их результаты были весьма значительны: одни представляли несомненную ценность для пивоварения, другие - большой теоретический интерес. Естественно возникла проблема их публикации. Но устав пивоваренной компании Гиннеса запрещал работникам публикацию результатов исследований. Однако компания дала согласие на публикацию работ по теоретическим вопросам статистики (что было нарушением устава), о решила не связывать результаты с именем одного из служащих компании, дабы конкуренты не могли догадаться о пользе, которую несет статистика для пивоварения. В результате научный мир был изумлен рядом первоклассных статей в журнале "Биометрика", опубликованных начиная с 1908 г. под псевдонимом "Студент", но в нашей литературе принято писать "Стьюдент". Эти работы совершили переворот в статистике, так как они содержат неклассическую постановку задачи и точное ее решение.
Сейчас не только плодотворно развиваются области психологии, широко использующие математические методы, но даже на психологических факультетах и в ряде гуманитарных, биологических и медицинских вузов читается обязательный курс математики, включающий элементы математической статистики.
СТАТИСТИКА В ОБРАБОТКЕ МАТЕРИАЛОВ ПСИХОЛОГИЧЕСКИХ ИССЛЕДОВАНИЙ.
Математическая статистика - прикладная отрасль математики, основанная на теории вероятностей и предназначенная для систематизации и анализа эмпирических (опытных) данных, получаемых при изучении повторяющихся и варьирующихся явлений.
Математическая статистика как способ мышления
Для психологии - это способ преобразования полученных экспериментальных данных.
Цель статистики в гуманитарных науках
1. Синтез данных, полученных на различных группах
2. Сравнение данных с целью выявления сходства и различия
3. Выявление показателей изменяющихся в одном конкретном направлении
4. Предсказание определенных фактов на основании выводов к которым приводят полученные данные
Задача статистики - сделать знания о событии не интуитивным, а осмысленным, достоверным, переведенным на язык символов
Разделы математической статистики
1) Описательная статистика (первичная)
2) Индуктивная статистика
3) Многомерная (многофакторная) - корреляционный анализ
Описательная статистика включает в себя табулирование, представление и описание совокупностей данных. Эти данные могут быть либо количественными, как, например, измерения роста и веса, либо качественными, как, например, пол и тип личности. Огромные массивы данных, как правило, должны обобщаться или свертываться, прежде чем они будут интерпретироваться человеком.
ü Описание
ü Подытоживание
ü Представление материала в виде таблиц, графиков, построение распределения признаков.
ü Вычисление среднеарифметического для признаков, вычисление размаха конкретных признаков и дисперсий этих признаков.
Индуктивная статистика. Теория статистического вывода - это формализованная система методов решения задач, характеризуется попытками вывести свойства большого массива данных путем обследования выборки. Задача статистического вывода состоит в том, чтобы предсказать свойства всей совокупности, зная свойства только выборки из этой совокупности.
ü Проверка того, можно ли распространить конкретные данные полученные на выборке, на всю популяцию из которой взята эта выборка. Позволяет проверять гипотезы исследования.
Многофакторная статистика
ü Позволяет узнать силу связи 2-х и более признаков, таким образом чтобы можно было предсказывать значение одного из них, зная величину другого
Термины и понятия
Вероятность - По Мизесу - это число, которое получается как предел частот при неограниченном увеличении количества наблюдений. Вероятность - это мера объективной возможности появления определенного события А в заданной совокупности условий, которое может произойти, а может и не произойти. Она обозначается обычно как Р(А). Мера вероятности - это мера случайности события, т. е. такого события, которое может произойти, а может и не произойти.
Популяция - в статистике это все существа или предметы образующие общую изучаемую совокупность
Выборка - это небольшое количество элементов отображаемых с помощью научных методов так, чтобы она была репрезентативной (от фр. (отражала популяцию в целом)
Частота f - число, показывающее, сколько раз встречается в выборке каждая варианта х„ так, что по определению сумма всех частот равна объему выборки
Частость - относительная частота, т. е. частота, деленная на количество испытаний. Частость - это доля каждой частоты f в общем объеме выборки N. Частость в гораздо меньшей степени зависит от количества испытаний, чем частота. Так, если ученик из пяти задач правильно решил четыре, из десяти - восемь, а из 20 только 16, то частость во всех трех случаях будет одинакова: 4/5.
Данные - основные элементы подлежащие анализу, это любая информация которая может быть классифицирована, преобразована в числовые значения и разбита на категории с целью обработки.
* не смешивать данные и значения
8, 13, 15, 8, 9, 9
6 данных
4 значения
Типы данных:
1) Количественные - получают при измерении (вес, рост, температура). Уровень у Количественные - получают при измерении (вес, рост, температура).ожет быть классифицированна, презентативной ная величину друг IQ, памяти.
2) Порядковые - соответствующие местам элементов в последовательности полученной при их расположении в возрастающем порядке (ранжирование)
3) Качественные - свойства элементов выборки или популяции, их нельзя измерить, их количественная оценка - частота встречаемости в популяции
Переменная - измеряемое психологическое явление, это может быть время решения задач, количество допущенных ошибок, уровень тревожности, интеллектуальное развитие. Являются случайными величинами, так как заранее неизвестно какое значение они примут.
Выделяют:
1) Независимая переменная - величина подлежащая изучению
2) Зависимая переменная - характеристика зависит от воздействия независимой переменной
3) Контролируемая переменная - величина поддерживающаяся на определенном уровне экспериментатором в течение всего эксперимента
Например: н\п - время роста
з\п - масса ребенка
Применяются для извлечения количественных данных. Различают статистические шкалы. С. Стивенс выделил 4:
· Шкалу наименований (номинальную) – классифицирует по названию, не измеряется количественно, материалы отличаются по качествам, можно размещать в любом порядке. Пример – дихотомическая шкала – с двумя вариантами – есть братья и сестры\нет братьев и сестер. Это альтернативный признак, может принимать два значения. Может быть три ячейки значений – кандидатура А, Б,В. Мы можем подсчитать частотность встречаемости наименований и работать с частотами.
· Шкалу порядка - объекты для рассмотрения принадлежат к одному или нескольким классам, но отличающиеся по параметрам выше-ниже, больше, меньше (места в соревнованиях). Располагаются от самого малого значения к самому большому, от самого низкого к самому высокому. Здесь должно быть не менее трех классов – низкий – средний – высокий. Каждому классу можно присвоить ранг. Ранжирование ценностей, личностных качеств.
· Шкалу интервалов - материалы с количественной оценкой в фиксированных единицах, есть единица измерения (грамм, метр, возраст). Больше на определенное количество единиц, либо меньше. Равное расстояние между значениями.
· Шкалу отношений - материалы с фиксированными единицами и отношением суммарных итогов (в психологии не применяется). Выраженность свойства в их отношениях. Например 2 относится к 4 как 4 к 8. Для постороения такой шкалы нужно определить абсолютный нуль, в психологии это невозможно.
Материалы из книги по параметрическим и непараметрическим методам. Решение задач - критерий Стьюдента, Манна-Уитни, Попарное сравнение. Психологическая диагностика. \ Под ред. , , СПб, Питер, 2005
Конструирование методик
Реализация требований к методикам, к их надежности и валидности осуществляется с помощью математической статистики.
Надежность. Необходимо получить коэффициент надежности, характеризующий внутреннюю согласованность методики. Метод расщепление методики. Эксперимент проводится с выборкой 50-100 испытуемых. Полученные ответы на вопросы делятся на четные и нечетные по нумерации. Выписывается число правильных ответов по каждой части (четной и нечетной). Итого два числа для одного испытуемого. Выписывается ряд по количеству испытуемых. Два ряда коррелируются между собой методом либо ранговой корреляции, либо методом Пирсона.
Четный верный - нечетный верный
Надежность может проверятся приемом параллельных форм. Создается две формы одной методики, где задания содержательно отличаются. Две группы испытуемых. Одна получает методики в порядке АБ, другая БА. Результаты коррелируются.
Если мы проверяем стабильность данных, то проводится корреляция между данными первого испытания и данными повторного испытания (не менее 6 недель).
Валидность - проверяется методом хи-квадрата, либо корреляцией.
Составление протоколов исследования
Лабораторная работа в текстовом редакторе
Построение распределения для доказательства гипотез
Информационный блок
Задача статистики - выявление различий между 2мя выборками - это подразумевает наличие гипотезы. В статистике может быть 2 гипотезы:
1) Но - Нулевая гипотеза - разница между двумя выборками отсутствует. Предполагается, что выявленные различия не достоверные, не значимы - обе выборки относятся к одной популяции. То, что нам надо опровергнуть, если стоит задача показать значимость различий.
2) Н1 - альтернативная гипотеза - рабочая гипотеза. Различия между обоими распределениями, выборками достаточно значимы и обусловлены влиянием независимой переменной. Это то, что мы хотим доказать. Иногда называется экспериментальной.
Основной принцип метода проверки гипотез это выдвижение Но, чтобы попытаться ее опровергнуть и подтвердить Н1.
Для проверки гипотез:
Построение распределения
Группировка по классам, состоит в объединении данных с близким значением в кластеры (группы) с одинаковой частотой единиц для каждого кластера. Разбиение на кластеры не имеет жестких правил. Существует только два правила:
1. Число единиц внутри класса зависит от протяженности шкалы. Чем длиннее шкала, тем больше единиц можно объединить в один класс.
0-5 - кластер
2. От численности выборки зависит число единиц. Чем больше выборка, тем больше число единиц объединяется в один класс.
Примерные способы объединения
Для количественных данных с наполнением шкалы 50 ед. Группировка с интервалами в 3 ед. или 5 Наполненность 100 ед. 10 или 20 (более 20 не используется)Группировка позволяет получить обобщенную и упрощенную картину распределения.
Пример построения распределения
30 ед.
11,20,14,9,12,15,16,20,14,9,5,10,15,10,13,9,11,12,16,3,10,7,11,11,11,10,11,10,10,5
Построить гистограмму.
Этапы построения
1. Выбрать размер кластера (например, 5 единиц). Обратить внимание, что 0 тоже является числом, входящим в кластер. Если кластер имеет диапазон 5 единиц, то первый кластер будет от 0 до 4, то есть будет включать такие числа, как 0,1,2,3,4. Подсчитывается количество чисел из ряда, входящих в каждый кластер
кластер | количество чисел в кластере |
от 0 до 4 | 1 |
от 5 до 9 | 6 |
от 10 до 14 | 17 |
от 15 до 19 | 4 |
от 20 до 24 | 2 |
2. 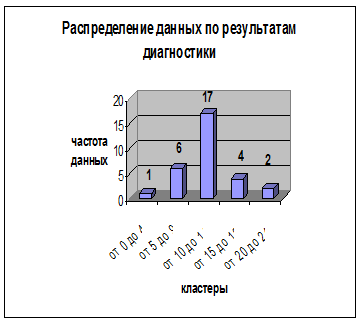 На оси Х и У отмечаются столбцы, высота которых соответствует частоте встречаемости каждого числа из кластера. По результатам подсчета получается следующая диаграмма (см. рисунок 1). Выделяют центральные точки каждого столбика и обводят кривой (см. рисунок 2). По кривой смотрят нормальное распределение или нет. Если выборка соответствует популяции (ее части), то это нормальное распределение, где кривая имеет колоколообразную форму, есть пик, и части с права и лево более-менее симметричны.
На оси Х и У отмечаются столбцы, высота которых соответствует частоте встречаемости каждого числа из кластера. По результатам подсчета получается следующая диаграмма (см. рисунок 1). Выделяют центральные точки каждого столбика и обводят кривой (см. рисунок 2). По кривой смотрят нормальное распределение или нет. Если выборка соответствует популяции (ее части), то это нормальное распределение, где кривая имеет колоколообразную форму, есть пик, и части с права и лево более-менее симметричны.
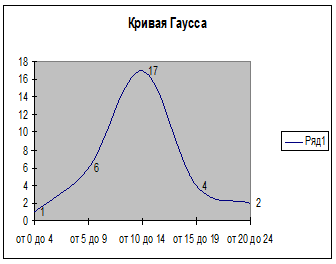
Рис. 1 Рис. 2
Распределение может отсутствовать. Бывает на патологических выборках и это свидетельствует о том, что группа предельно негомогенная (разнородная) по какому-либо признаку.
Задание:
Построить распределение, определить однородность группы, тип распределения (нормальное или нет), ответить на вопрос - можно ли считать выборку правильно подобранной.
86,48,0,56,57,77,0,68,56,59,30,87,87,96,0,19,68,83,17,19,24,88,26,49,79,39,89,63,82,5,15,88,69, 78,0,19,6,58,23,17,48,0,70
Придумать и рассчитать нормальное распределение
Информационный блок
Оценка центральной тенденции
На основании выявления центральной тенденции, можно говорить о том, как меняются показатели у большинства испытуемых выборки, после воздействия на группу. Об этом можно судить по смещению распределения в сторону уменьшения или увеличения.
Чтобы выразить тенденции количественно, используют три вида показателей.
Мода Мо Медиана Ме Среднеарифметическое М~ ИЛИ х с чертойМода - соответствие наиболее частому значению.
Берется кластер с большим количество значений (самый высокий столбик). Ряд значений от 101-183
101,108,120,126,132,144,162,168
Мо=126+132=129
2
Мода как показатель используется редко и для того, чтобы дать общее представление о распределении. Бывают распределения с 2мя модами (бимодальные)
Когда есть 2 относительно самостоятельные выборки по признаку.
Соглашение об использовании моды:
1. В том случае, когда все значения в группе встречаются одинаково часто, принято считать, что группа оценок не имеет моды.
Пример: 0,5; 0,5; 1,6; 1,6; 2,9; 2,9. Моды нет. Мо = 0.
2. Когда два соседних значения имеют одинаковую частоту и они больше частоты любого другого значения, мода есть среднее этих двух значений.
Пример: 1, 1, 2, 2, 2, 3, 3, 3,4. М0=2,5.
3. Если два несмежных значения в группе имеют равные частоты и они больше частоты любого другого значения, то имеем две моды. Говорят: группа оценок является бимодальной.
Пример: 10, 11, 11,11,12, 13, 14, 14, 14, 15. Мо=11 и 14.
Необходимо отметить, что среди распределений встречаются "унимодальные", у которых мода отсутствует и полимодалъные, у которых две и более мод.
Задание:
Найдите моду на примере распределения в первом задании. Отметьте ее на распределении.
Информационный блок
Медиана - соответствует центральному значению в последовательном ряду всех полученных значений.
10,11,12,13,14,14,15,15,15,15,17,17,19,20,21
15 - медиана для нечетного ряда
значения необходимо расположить в возрастающем порядке
четный ряд - 7,8,9,11,12,13,14,16
Если число данных четное, то медиана равна среднеарифметической м\у 2мя центральными значениями в последовательном ряду всех полученных значений.
(11+12)/2=11,5 - медиана для четного ряда
Задание:
Найдите медиану на примере распределения в первом задании. Отметьте ее на распределении.
Информационный блок
Средняя арифметическая.
Оценка математического ожидания. Вычисляют, разделив сумму всех значений данных на число этих данных.
В бимодальном распределении среднеарифметическое это числовое значение, которое отсутствует или редко представлено.
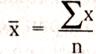
Задание:
Найдите среднеарифметическое на примере распределения в первом задании. Отметьте ее на распределении.
Информационный блок
При совпадении моды, медианы и среднеарифметического - это нормальное распределение.
Оценка разброса данных
Позволяет определить насколько полученные данные в выборке однородны (гомогенны), какова вариативность выполнения испытуемыми конкретного задания.
Способы оценки
Оценка размаха вариаций10,11,13,15,16,18,20
20-10=10 размах вариации для данного признака
Стандартное отклонение (среднее квадратичное отклонение)Мера разнообразия входящих в группу объектов. Обозначается буквой сигма σ
Показывает насколько отклоняется каждое значение от среднеарифметического.
Расчет - А. Определение среднеарифметического признака х с чертой
Б. Отклонение каждого значения в последовательном ряду данных от высчитанного среднеарифметического
3,5,6,9,11,14
Ср. арифметическое =8
шесть значений
((3-8)2 + (5-8)2 + (6-8)2 + (9-8)2 + (14-8)2)/6 = 14
√14 = 3,74 - сигма, характеризует вариативность выборки
х с чертой=8+\-3,74
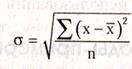
Под корнем
n - число данных, обследуемых
И сумма разности в квадрате. От каждого значения отнимают среднеарифметическое, разность возводят в квадрат и все складывают
Статистики показали, что при нормальном распределении результаты располагаются в пределах одного стандартного отклонения по обе стороны от средней, в % отношении всегда одинаковы и не зависят от величины стандартного отклонения. В пределах одного стандартного отклонения они соответствуют 68 % популяции. Слева и справа от среднеарифметической лежит 50 % вариант.
Коэффициент асимметрии - показатель скошенности распределения в левую или правую сторону по оси абсцисс. Если правая ветвь кривой длиннее левой - это положительная ассиметрия, если наоборот - отрицательная. У нормального распределения редко бывает коэффициент ассиметрии близкий к единице и более единицы (-1 и +1). Эксцесс - показатель островершинности. Кривые высокие в средней части, островершинные - называются эксцессивными. При уменьшении величины эксцесса кривая становится более плоской, приобретает вид плато, а затем седловины - с прогибом в средней части. Очень большая величина эксцессы говорит о наличие ошибок при введение или подсчете данных.Задание:
Найдите размах вариации и сигму на примере распределения в первом задании. Определите скошеность (положительная или отрицательная) кривой. Ответить на вопрос - является кривая эксцессивной.
Информационный блок
Правила выбраковки данных (выскакивающих значений)
В статистике правомерно изъять из расчетов данные, которые не укладываются в 3 сигма, так как считается, что значения не укладывающиеся в 3 сигма данной выбрки относятся в другой, принципиально иной выборке.
Слуховая память. 3,4,4,5,5,5,5, 6,6,7
Среднеарифм.= 5
((3-5)2 + (4-5)2 + (4-5)2 + (5-5)2 +(5-5)2 + (5-5)2 + (5-5)2 + (6-5)2 + (6-5)2 + (7-5)2)/10=√1,2=1,09
σ = 1,09
х с чертой = 5 +\- 1,09
3σ 5+\- 3,27 (все что больше лежит в другой выборке)
Оценка достоверности отличий
В исследовании часто встречается задача оценить достоверность отличий между двумя и более рядами значений. Например, значения двух экспериментов до и после коррекции. Чаще всего подобные подсчеты проводятся с использованием статистических программ. Но возможен и ручной подсчет.
Достоверность различий среднеарифметических можно оценить по критерию Стьюдента. Расчет имеет две формулы. Одна без вычисления сигмы. Вторая с вычислением. Второй тип вычисляется по формуле.
Ta = (M1 - M2)\ (√m12 + m22)
M1 M2 - значение сравниваемых средних арифметических
m12 m22 - величины статистических ошибок средних арифметических.
Знак не учитывается.
Величина статистических ошибок вычисляется по формуле
M = +\-сигма\ √n
M - ошибка средней
N - число значений признака
Значение критерия для трех уровней значимости р приведены в таблице. Число степеней свободы определяется по формуле d = n1+n2 - 2, где n1 n2 - объемы сравниваемых выборок.
Решение о достоверности различий принимается, если вычисленная величина Т а превышает табличное значение для данного числа степеней свободы. Если значения превышают (0.05, 0.01) нет в таблице, то оцениваемые различия случайны. Если превышены значения и по 0.001, то различия абсолютно случайны. Т. е. различия не могут распространятся на всю совокупность.
Задание:
Определите достоверность отличий для двух выборок.
А - 2,2,2,3,5,7,8,7,8,10
Б - 7,7,9,10,10,12,15,15,20,20
Информационная часть
Корреляционный анализ
Дает возможность точной количественной оценки степени согласованности изменений (варьирования) двух и более признаков. Теснота связи характеризуется коэффициентом корреляции.
Если зависимость прямо пропорциональна - коэффициент равен 1 (-1 и +1)
- 1 - разная направленность варьирования признаков (рост одного ведет к падению другого)
если коэффициент равен 0 - то взаимосвязи нет
Коэффициент корреляции по Пирсону.
Есть два ряда значений. Вопрос есть ли взаимосвязь между выполнением теста 1 и теста 2.
Обозначим тест1 - х
Обозначим тест 2 - у
Выборка 15 человек.
Основная формула
R = (∑(x - x~) x ∑(y - y~))
√ ∑(x-x~)2 x √∑(y - y~)2
Тождества помогают в рассчетах
∑(x-x~)2 = ∑x2 - (∑(x)2 \ n)
∑(y-у~)2 = ∑у2 - (∑(у)2 \ n)
∑(x-x~) Х (y-у~) = ∑ху - ((∑х) Х ∑(у)) \ n
обязательно вычислить число степеней свободы fd = n - 2, чтобы сравнить результаты R с табличными. В примере число степеней свободы 13.
Существует еще вычисление коэффициента корреляции по Спирмену, так называемая ранговая корреляция. Где используется разность рангов данных.
Задание:
Определить существует ли взаимосвязь между методикой Векслера и тестом Амтхауэра, если результаты диагностики были следующими:
По тесту Векслера обобщенные показатели -
5,5,10,10,10,14,14,14,14,10,10,10,5,5,5,5,5,5,10,20,20,10
По тесту Амтхауэра -
5,5,5,5,10,10,10,10,15,15,15,20,20,20,20,20,5,5,5,5,5,5
