

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Размер области PGA/UGA определяют параметры уровня сеанса в файле init. ora:
SORT_AREA_SIZE и SORT_AREA_RETAINED_SIZE.
Эти два параметра управляют объемом пространства, используемым сервером Oracle для сортировки данных перед сбросом на диск, и определяют объем сегмента памяти, который не будет освобожден по завершении сортировки.
SORT_AREA_SIZE обычно выделяется в области PGA, a SORT_AREA_RETAINED_SIZE - в UGA.
Область SGA
Каждый экземпляр Oracle имеет одну большую область памяти, которая называется SGA, System Global Area - глобальная область системы. Это большая разделяемая структура, к которой обращаются все процессы Oracle.
Область SGA разбита на несколько пулов.
· Java-пул представляет собой фиксированный пул памяти, выделенный виртуальной машине JVM, которая работает в составе сервера.
· Большой пул (large pool) используется сервером в режиме разделяемого сервера для размещения памяти сеанса.
· Разделяемый пул (shared pool) содержит разделяемые курсоры, хранимые процедуры, объекты состояния, кэш словаря данных и десятки других компонентов данных.
· Буферный пул - память, выделенная под буферы блоков (кэш блоков базы данных, буферный кэш), буфер журнала повторного выполнения.
На общий размер SGA наиболее существенно влияют следующие параметры init. ora.
· JAVA_POOL_SIZE. - управляет размером Java-пула.
· SHARED_POOL_SIZE - управляет (до некоторой степени) размером разделяемого пула.
· LARGE_POOL_SIZE.- управляет размером большого пула.
· DB_CACHE _SIZE.- управляет размером буферного кэша.
· LOG_BUFFER.- управляет размером буфера журнала повторного выполнения.
Буферный кэш
В буферном кэше сервер Oracle хранит блоки базы данных перед их записью на диск, а также после считывания с диска. Это принципиально важный компонент SGA. Если сделать его слишком маленьким, запросы будут выполняться годами. Если же он будет чрезмерно большим, пострадают другие процессы (например, выделенному серверу не хватит пространства для создания области PGA, и он просто не запустится).
Блоки в буферном кэше контролируются двумя списками. Это список "грязных" блоков, которые должны быть записаны процессом записи блоков базы данных (это DBWn). Есть еще список "чистых" блоков, где вместо физического упорядочения списка блоков, сервер Oracle с помощью счетчика, связанного с блоком, подсчитывает количество обращений ("touch count) при каждом обращении (hit) к этому блоку в буферном КЭШе. Таблица X$BH содержит информацию о блоках в буферном кэше. В ней можно увидеть, как "счетчик обращений" увеличивается при каждом обращении к блоку. Использованный буфер не переносится в начало списка. Он остается на месте, а его "счетчик обращений" увеличивается. Блоки со временем перемешаются по списку естественным путем, поскольку измененные блоки переносятся в список "грязных" (для записи на диск процессом DBWn). Кроме того, если, несмотря на повторное использование блоков, буферный кэш заполнился, и блок с небольшим значением "счетчика обращений" удаляется из списка, он возвращается с новыми данными примерно в середину списка..
В буферном кэше выделено два буферных пула:
· KEEP
· RECYCLE
Если блок используется часто, он остается в пуле KEEP. Если к блоку некоторое время не обращались и в буферном пуле не осталось места, этот блок выбрасывается из пула как устаревший.
В пуле RECYCLE блоки выбрасываются иначе. Пул KEEP предназначен для продолжительного кэширования "горячих" блоков. Из пула RECYCLE блок выбрасывается сразу после использования. Это эффективно в случае "больших"таблиц, которые читаются случайным образом. (Понятие "большая таблица" очень относительно; нет эталона для определения того, что считать "большим".) Если в течение разумного времени вероятность повторного считывания блока мала, нет смысла долго держать такой блок в кэше. Поэтому в пуле RECYCLE блоки регулярно перечитываются.
Разделяемый пул
Разделяемый пул - один из наиболее важных фрагментов памяти в области SGA, особенно для обеспечения производительности и масштабируемости. Слишком маленький разделяемый пул может снизить производительность настолько, что система будет казаться зависшей. Слишком большой разделяемый пул может привести к такому же результату. Неправильное использование разделяемого пула грозит катастрофой.
В разделяемом пуле сервер Oracle кэширует различные "программные" данные. Здесь кэшируются результаты разбора запроса. Перед повторным разбором запроса сервер Oracle просматривает разделяемый пул в поисках готового результата. Выполняемый сеансом PL/SQL-код тоже кэшируется здесь, так что при следующем выполнении не придется снова читать его с диска. PL/SQL-код в разделяемом пуле не просто кэшируется, - появляется возможность его совместного использования сеансами. Если 1000 сеансов выполняют один и тот же код, загружается и совместно используется всеми сеансами лишь одна копия этого кода. Сервер Oracle хранит в разделяемом пуле параметры системы. Здесь же хранится кэш словаря данных, содержащий информацию об объектах базы данных. Разделяемый пул состоит из множества маленьких (около 4 Кбайт) фрагментов памяти. Память в разделяемом пуле управляется по принципу давности использования (LRU). В этом отношении она похожа на буферный кэш: если фрагмент не используется, он теряется. Стандартный пакет DBMS_SHARED_POOL позволяет изменить это и принудительно закрепить объекты в разделяемом пуле. Это позволяет загрузить часто используемые процедуры и пакеты при запуске сервера и сделать так, чтобы они не выбрасывались из пула как устаревшие. Обычно, если в течение определенного периода времени фрагмент памяти в разделяемом пуле не использовался, он выбрасывается как устаревший. Даже PL/SQL-код, который может иметь весьма большой размер, управляется механизмом постраничного устаревания, так что при выполнении кода очень большого пакета необходимый код загружается в разделяемый пул небольшими фрагментами. Если в течение продолжительного времени он не используется, то в случае переполнения выбрасывается из разделяемого пула, а пространство выделяется для других объектов. Самый простой способ поломать механизм разделяемого пула Oracle - не использовать связываемые переменные. Отказавшись от использования связываемых переменных, можно "поставить на колени" любую систему, поскольку:
• система будет тратить много процессорного времени на разбор запросов;
• система будет тратить очень много ресурсов на управление объектами в разделяемом пуле, т. к. не предусмотрено повторное использование планов выполнения запросов.
Если каждый переданный серверу Oracle запрос специфичен, с жестко заданными константами, это вступает в противоречие с назначением разделяемого пула. Разделяемый пул создавался для того, чтобы хранящиеся в нем планы выполнения запросов использовались многократно. Если каждый запрос - абсолютно новый и никогда ранее не встречался, в результате кэширования только расходуются дополнительные ресурсы.
Разделяемый пул начинает снижать производительность. Обычно эту проблему пытаются решить, увеличивая разделяемый пул, но в результате становится еще хуже. Разделяемый пул снова неизбежно заполняется, и его поддержка требует больших ресурсов, чем поддержка маленького разделяемого пула, поскольку при управлении большим заполненным пулом приходится выполнять больше действий, чем при управлении маленьким заполненным пулом.
Единственным решением этой проблемы является применение разделяемых операторов SQL, которые используются повторно. Существует параметр инициализации CURSOR_SHARING, который можно использовать для частичного решения подобных проблем, но наиболее эффективное решение - применять повторно используемые SQL-операторы. Даже самые большие из крупных систем требуют от 10000 до 20000 уникальных SQL-операторов. В большинстве систем используется лишь несколько сотен уникальных запросов.
Большой пул
Большой пул назван так не потому, что это "большая" структура (хотя его размер вполне может быть большим), а потому, что используется для выделения больших фрагментов памяти - больших, чем те, для управления которыми создавался разделяемый пул.
Большой пул - это область памяти, управляемая по принципу пула RECYCLE. После освобождения фрагмента памяти он может использоваться другими процессами. Большой пул, в частности, используется:
• сервером в режиме MTS для размещения области UGA в SGA;
• при распараллеливании выполнения операторов - для буферов сообщений, которыми обмениваются процессы для координации работы серверов;
• в ходе резервного копирования для буферизации дискового ввода/вывода утилиты RMAN.
Буфер журнала повторного выполнения
Буфер журнала повторного выполнения используется для временного кэширования данных активного журнала повторного выполнения перед записью на диск. Поскольку перенос данных из памяти в память намного быстрее, чем из памяти - на диск, использование буфера журнала повторного выполнения позволяет существенно ускорить работу сервера. Данные не задерживаются в буфере журнала повторного выполнения надолго. Содержимое этого буфера сбрасывается на диск:
· раз в три секунды;
· при фиксации транзакции;
· при заполнении буфера на треть или когда в нем оказывается 1 Мбайт данных журнала повторного выполнения.
Поэтому создание буфера журнала повторного выполнения размером в десятки Мбайт - напрасное расходование памяти. Чтобы использовать буферный кэш журнала повторного выполнения размером 6 Мбайт, например, надо выполнять продолжительные транзакции, генерирующие по 2 Мбайт информации повторного выполнения не более чем за три секунды. Если кто-либо в системе зафиксирует транзакцию в течение этих трех секунд, в буфере не будет использовано и 2 Мбайт, - содержимое буфера будет регулярно сбрасываться на диск. Лишь очень немногие приложения выиграют от использования буфера журнала повторного выполнения размером в несколько мегабайт.
Стандартный размер буфера журнала повторного выполнения, задаваемый параметром LOG_BUFFER в файле init. ora, определяется как максимальное из значений 512-ти (128 * количество процессоров) Кбайт. Минимальный размер этой области равен максимальному размеру блока базы данных для соответствующей платформы, умноженному на четыре.
Java-пул
Java-пул - создан для поддержки работы Java-машины в базе данных. Если поместить хранимую процедуру на языке Java или компонент EJB (Enterprise JavaBean) в базу данных, сервер Oracle будет использовать этот фрагмент памяти при обработке соответствующего кода. Java-пул виден в представлении V$SGASTAT, а также в результатах выполнения команды SHOW SGA. Параметр инициализации JAVA_POOL_SIZE используется для определения фиксированного объема памяти, отводящегося для Java-кода и данных сеансов.
Java-пул используется по-разному, в зависимости от режима работы сервера Oracle. В режиме выделенного сервера Java-пул включает разделяемую часть каждого Java-класса, использованного хоть в одном сеансе. Эти части только читаются (векторы выполнения, методы и т. д.) и имеют для типичных классов размер от 4 до 8 Кбайт.
Таким образом, в режиме выделенного сервера (который, как правило, и используется, если в приложениях применяются хранимые процедуры на языке Java) объем общей памяти для Java-пула весьма невелик; его можно определить исходя из количества используемых Java-классов. Информация о состоянии сеансов при работе в режиме разделяемого сервера в области SGA не сохраняется, поскольку эти данные находятся в области UGA, а она, в режиме разделяемого сервера является частью области PGA.
При работе в режиме MTS Java-пул включает:
• разделяемую часть каждого Java-класса и
• часть области UGA для каждого сеанса, используемую для хранения информации о состоянии сеансов.
Оставшаяся часть области UGA выделяется как обычно - из разделяемого пула или из большого пула, если он выделен.
Поскольку общий размер Java-пула фиксирован, разработчикам приложений необходимо оценить общий объем памяти для приложения и умножить на предполагаемое количество одновременно поддерживаемых сеансов. Полученное значение будет определять общий размер Java-пула. Каждая Java-часть области UGA будет увеличиваться и уменьшаться при необходимости, но помните, что размер пула должен быть таким, чтобы части всех областей UGA могли поместиться в нем одновременно.
В режиме MTS может потребоваться очень большой Java-пул. Его размер будет зависеть не от количества используемых классов, а от количества одновременно работающих пользователей. Как и большой пул, размеры которого становятся очень большими в режиме MTS, Java-пул тоже может разрастаться до огромных размеров.
Процессы
В экземпляре Oracle есть три класса процессов.
• Серверные процессы. Они выполняют запросы клиентов.
• Фоновые процессы. Это процессы, которые начинают выполняться при запуске экземпляра и решают различные задачи поддержки базы данных, такие как запись блоков на диск, поддержка активного журнала повторного выполнения, удаление прекративших работу процессов и т. д.
• Подчиненные процессы. Они подобны фоновым процессам, но выполняют, корме того, действия от имени фонового или серверного процесса.
Серверные процессы
Серверные процессы решают задачу: обрабатывают передаваемые им SQL-операторы. При получении запроса именно серверный процесс Oracle будет разбирать его и помещать в разделяемый пул (или находить соответствующий запрос в разделяемом пуле). Именно этот процесс создает план выполнения запроса. Этот процесс реализует план запроса, находя необходимые данные в буферном кэше или считывая данные в буферный кэш с диска. Такие серверные процессы можно назвать "рабочими лошадками" СУБД. Часто именно они потребляют основную часть процессорного времени в системе, поскольку выполняют сортировку, суммирование, соединения - в общем, почти все.
В режиме выделенного сервера (dedicated) имеется однозначное соответствие между клиентскими сеансами и серверными процессами (или потоками). Если имеется 100 сеансов на UNIX-машине, будет 100 процессов, работающих от их имени.
Другой тип серверных процессов - разделяемый серверный процесс (shared) или режим многопотокового сервера (MTS - multi-threaded server). Для подключения к серверному процессу этого типа обязательно используется протокол Net, даже если клиент и сервер работают на одной машине. Клиентское приложение подключается к процессу прослушивания Net и перенаправляется на процесс-диспетчер. Диспетчер играет роль канала передачи информации между клиентским приложением и разделяемым серверным процессом. Клиентские приложения со скомпонованными в них библиотеками Oracle физически подключаются к диспетчеру MTS. Диспетчеров MTS для любого экземпляра можно сгенерировать несколько, но часто для сотен и даже тысяч пользователей используется один диспетчер. Диспетчер отвечает за получение входящих запросов от клиентских приложений и их размещение в очереди запросов в области SGA. Первый свободный разделяемый серверный процесс, по сути, ничем не отличающийся от выделенного серверного процесса, выберет запрос из очереди и подключится к области UGA соответствующего сеанса. Разделяемый сервер обработает запрос и поместит полученный при его выполнении результат в очередь ответов. Диспетчер постоянно следит за появлением результатов в очереди и передает их клиентскому приложению. С точки зрения клиента нет никакой разницы между подключением к выделенному серверу и подключением в режиме MTS, - они работают одинаково. Различие возникает только на уровне экземпляра.
Режим выделенного сервера проще настроить и он обеспечивает самый простой способ подключения. При этом требуется минимальное конфигурирование. Настройка и конфигурирование режима MTS, хотя и несложный, но дополнительный шаг. Основное различие между этими режимами, однако, не в настройке. Оно связано с особенностями работы. При использовании выделенного сервера имеется соответствие один к одному между клиентским сеансом и серверным процессом. В режиме MTS соответствие - многие к одному (много клиентов и один разделяемый сервер). Как следует из названия, разделяемый сервер - общий ресурс, а выделенный - нет. При использовании общего ресурса необходимо стараться не монополизировать его надолго.
Правило номер один для режима MTS: убедитесь, что транзакции выполняются быстро. Они могут выполняться часто, но должны быть короткими. В противном случае будут наблюдаться все признаки замедления работы системы из-за монополизации общих ресурсов несколькими процессами. В экстремальных случаях, если все разделяемые серверы заняты, система "зависает". Режим MTS не подходит, однако, для хранилища данных. В такой системе выполняются запросы продолжительностью одна, две, пять и более минут. Для режима MTS это "смертельно". В системе, где 90 процентов задач относятся к классу ООТ (системы оперативной обработки транзакций).а 10 процентов - "не совсем ООТ", можно поддерживать одновременно выделенные и разделяемые серверы в одном экземпляре.
В этом случае существенно сокращается количество процессов для пользователей ООТ, а "не совсем ООТ"-задачи не монополизируют надолго разделяемые серверы.
Итак, какие же преимущества дает режим MTS, если учитывать, для какого типа транзакций он предназначен? Режим MTS позволяет добиться следующего.
- Сократить количество процессов/потоков операционной системы. В системе с тысячами пользователей ОС может быстро оказаться перегруженной при попытке управлять тысячами процессов. В обычной системе одновременно активна лишь небольшая часть этих тысяч пользователей.
- Искусственно ограничить степень параллелизма.
.
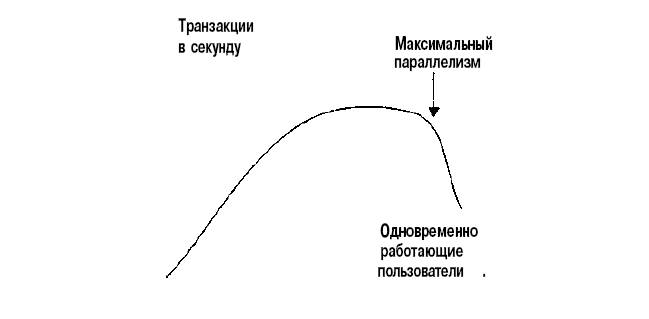
|
На рис.3 представлена диаграмма, показывающая зависимость количества транзакций от количества одновременно работающих пользователей: Сначала при добавлении одновременно работающих пользователей количество транзакций растет. С какого-то момента, однако, добавление новых пользователей не увеличивает количества выполняемых в секунду транзакций: оно стабилизируется. Пропускная способность достигла максимума, и время ожидания ответа начинает расти (каждую секунду выполняется то же количество транзакций, но пользователи получают результаты со все возрастающей задержкой. При дальнейшем добавлении пользователей пропускная способность начинает падать. Количество одновременно работающих пользователей перед началом этого падения и является максимально допустимой степенью параллелизма в системе.
Дальше система переполняется запросами, и образуются очереди. С этого момента система не справляется с нагрузкой. Не только существенно увеличивается время ответа, но и начинает падать пропускная способность системы. Если ограничить количество одновременно работающих пользователей до числа, непосредственно предшествующего падению, можно обеспечить максимальную пропускную способность и приемлемое время ответа для большинства пользователей. Режим MTS позволяет ограничить максимальную степень параллелизма в системе до этого количества одновременно работающих пользователей.
- Сократить объем памяти, необходимый системе. Это одна из наиболее часто упоминаемых причин использования режима MTS: сокращается объем памяти, необходимой для поддержки определенного количества пользователей. При использовании режима MTS область UGA помещается в SGA. Это означает, что при переходе на режим MTS необходимо точно оценить суммарный объем областей UGA и выделить место в области SGA с помощью параметра инициализации LARGE_POOL Поэтому размер области SGA при использовании режима MTS обычно очень большой. Эта память выделяется заранее и поэтому может использоваться только СУБД. Сравните это с режимом разделяемого сервера, когда процессы могут использовать любую область памяти, не выделенную под SGA. Итак, если область SGA становится намного больше вследствие размещения в ней областей UGA, каким же образом экономится память? Экономия связана с уменьшением количества выделяемых областей PGA. Каждый выделенный/разделяемый сервер имеет область PGA. В ней хранится информация процесса. В ней располагаются области сортировки, области хешей и другие структуры процесса. Именно этой памяти для системы надо меньше, если используется режим MTS. При переходе с 5000 выделенных серверов на 100 разделяемых освобождается 4900 областей PGA - именно такой объем памяти и экономится в режиме MTS.
Фоновые процессы
Монитор процессов (PMON).Этот процесс отвечает за очистку после нештатного прекращения подключений. Например, если выделенный сервер "падает" или, получив сигнал, прекращает работу, именно процесс PMON освобождает ресурсы. Процесс PMON откатит незафиксированные изменения, снимет блокировки и освободит ресурсы в области SGA, выделенные прекратившему работу процессу. Помимо очистки после прерванных подключений, процесс PMON контролирует другие фоновые процессы сервера Oracle и перезапускает их при необходимости (если это возможно). Если разделяемый сервер или диспетчер сбоит (прекращает работу), процесс PMON запускает новый процесс (после очистки структур сбойного процесса). Процесс PMON следит за всеми процессами Oracle и либо перезапускает их, либо прекращает работу экземпляра, в зависимости от ситуации. Например, в случае сбоя процесса записи журнала повторного выполнения (LGWR) экземпляр надо перезапускать. Это серьезная ошибка и самое безопасное - немедленно прекратить работу экземпляра, предоставив исправление данных штатному процессу восстановления.
Монитор системы (SMON). Это процесс, занимающийся всем тем, от чего "отказываются" остальные процессы. Это своего рода "сборщик мусора" для базы данных.
Вот некоторые из решаемых им задач.
- Очистка временного пространства. Например, при построении индекса выделяемые ему в ходе создания экстенты помечаются как временные (TEMPORARY). Если выполнение оператора CREATE INDEX прекращено досрочно по какой-либо причине, процесс SMON должен эти экстенты освободить. Есть и другие операции, создающие временные экстенты, за очистку которых также отвечает процесс SMON.
- Восстановление после сбоев. Процесс SMON после сбоя восстанавливает экземпляр при перезапуске.
- Восстановление транзакций, затрагивающих недоступные файлы. Эта задача аналогична той, которая возникает при запуске базы данных. Процесс SMON восстанавливает сбойные транзакции, пропущенные при восстановлении экземпляра после сбоя по причине недоступности файлов для восстановления. Например, файл мог быть на недоступном или на не смонтированном диске. Когда файл будет доступен, процесс SMON восстановит его.
- Очистка таблицы OBJ$. OBJ$ - низкоуровневая таблица словаря данных, содержащая записи практически для каждого объекта (таблицы, индекса, триггера, представления и т. д.) базы данных. Часто там встречаются записи, представляющие удаленные или отсутствующие" объекты, используемые механизмом поддержки зависимостей Oracle. Процесс SMON удаляет эти ненужные строки.
- Сжатие сегментов отката. Процесс SMON автоматически сжимает сегмент отката до заданного размера.
- "Отключение"сегментов отката. Администратор базы данных может "отключить" или сделать недоступным сегмент отката с активными транзакциями. Активные транзакции могут продолжать использование такого отключенного сегмента отката. В этом случае сегмент отката фактически не отключается: он помечается для "отложенного отключения". Процесс SMON периодически пытается "действительно" отключить его, пока это не получится.
- Процесс контрольной точки (CKPT). Процесс CKPT передает сигнал процессу DRWn о контрольной точке, обновляя информацию о контрольной точке в заголовках файлов данных и управляющих файлах. Он запускается всегда.
- Запись блоков базы данных (DBWn). Процесс записи блоков базы данных (Database Block Writer - DBWn) - фоновый процесс, отвечающий за запись измененных блоков на диск. В кэше буферов серверный процесс собирает изменения, внесенные в блоки отмены и в блоки данных. Процесс записи в базу данных (DBWn) записывает модифицированные буфера из кэша буферов базы данных в файлы данных. Он обеспечивает наличие в кэше буферов базы данных достаточного числа свободных буферов – буферов, которые могут быть переписаны, когда серверный процесс должен считать блоки из файлов данных. Это улучшает производительность базы данных, так как серверные процессы вносят изменения только в кэш буферов, а DBWn откладывает запись в файлы базы данных до возникновения одного из следующих событий:
- контрольная точка; число модифицированных буферов достигает порогового значения; какой либо процесс не находит свободных буферов; истекло время ожидания; перевод постоянного или временного табличного пространства в автономный режим; перевод табличного пространства в режим “только чтение”; удаление или усечение таблицы; начало горячего резервирования табличного пространства по команде
ALTER TABLESPACE … BEGIN BACKUP.
В большинстве систем работает только один процесс записи блоков базы данных, но в больших, многопроцессорных системах имеет смысл использовать несколько. Если сконфигурировано более одного процесса DBWn, не забудьте также увеличить значение параметра инициализации DB_BLOCK_LRU_LATCHES. Он определяет количество защелок списков по давности использования, touch lists. Каждый процесс DBWn должен иметь собственный список. Если несколько процессов DBWn совместно используют один список блоков для записи на диск, они будут конфликтовать друг с другом при доступе к списку.
Обычно процесс DBWn использует асинхронный ввод/вывод для записи блоков на диск. При использовании асинхронного ввода/вывода процесс DBWn собирает пакет блоков для записи и передает его операционной системе. Процесс DBWn не ждет, пока ОС запишет блоки, - он собирает следующий пакет для записи. Завершив асинхронную запись, ОС уведомляет об этом процесс DBWn. Это позволяет процессу DBWn работать намного быстрее, чем при последовательном выполнении действий
- Запись журнала (LGWR). Процесс LGWR отвечает за сброс на диск содержимого буфера журнала повторного выполнения, находящегося в области SGA. Он делает это:
• раз в три секунды;
• при фиксации транзакции;
• при заполнении буфера журнала повторного выполнения на треть или при записи в него 1 Мбайт данных.
Поэтому создание слишком большого буфера журнала повторного выполнения не имеет смысла: сервер Oracle никогда не сможет использовать его целиком. Все журналы записываются последовательно, а не вразброс, как вынужден выполнять ввод/вывод процесс DBWn. Запись большими пакетами, как в этом случае, намного эффективнее, чем запись множества отдельных блоков в разные части файла. Это одна из главных причин выделения процесса LGWR и журнала повторного выполнения.
Эффективность последовательной записи измененных байтов перевешивает расход ресурсов на дополнительный ввод/вывод. Сервер Oracle мог бы записывать блоки данных непосредственно на диск при фиксации, но это потребовало бы записи множества разбросанных блоков, а это существенно медленнее, чем последовательная запись изменений процессом LGWR.
- Архивирование (ARCn). Это не обязательный фоновый процесс, запускается, если база данных сконфигурирована в режиме ARCHIVELOG. Задача процесса ARCn - копировать в другое место активный файл журнала повторного выполнения, когда он заполняется процессом LGWR. Эти архивные файлы журнала повторного выполнения затем можно использовать для восстановления носителя. Тогда как активный журнал повторного выполнения используется для "исправления" файлов данных в случае сбоя питания (когда прекращается работа экземпляра), архивные журналы повторного выполнения используются для восстановления файлов данных в случае сбоя диска. Если будет потерян диск, содержащий файл данных, можно взять резервные копии за прошлую неделю, восстановить из них старую копию файла и попросить сервер применить активный журнал повторного выполнения и все архивные журналы, сгенерированные с момента создания этой резервной копии. Это "подтянет" файл по времени к остальным файлам в базе данных, и можно будет продолжить работу без потери данных.
Процесс ARCn обычно копирует активный журнал повторного выполнения в несколько мест (избыточность - гарантия сохранности данных!). Это могут быть диски на локальной машине или, что лучше, на другой машине, на случай катастрофического сбоя.
Они также могут отправляться на другую машину для применения к резервной базе данных (это одно из средств защиты от сбоев, предлагаемое Oracle).
Подчиненные процессы
В сервере Oracle есть два типа подчиненных процессов - ввода/вывода (I/O slaves) и параллельных запросов (Parallel Query slaves).
Подчиненные процессы ввода/вывода
Подчиненные процессы ввода/вывода используются для эмуляции асинхронного ввода/вывода в системах или на устройствах, которые его не поддерживают. Например, ленточные устройства (чрезвычайно медленно работающие) не поддерживают асинхронный ввод/вывод. Используя подчиненные процессы ввода/вывода, можно сымитировать для ленточных устройств такой способ работы, который операционная система обычно обеспечивает для дисков. Как и в случае действительно асинхронного ввода/вывода, процесс, записывающий на устройство, накапливает большой объем данных в виде пакета и отправляет их на запись. Об их успешной записи процесс (на этот раз - подчиненный процесс ввода/вывода, а не ОС) сигнализирует исходному вызвавшему процессу, который удаляет этот пакет из списка данных, ожидающих записи.
Таким образом, можно существенно повысить производительность, поскольку именно подчиненные процессы ввода/вывода ожидают завершения работы медленно работающего устройства, а вызвавший их процесс продолжает выполнять другие важные действия, собирая данные для следующей операции записи.
Подчиненные процессы ввода/вывода используются в нескольких компонентах сервера - процессы DBWn и LGWR используют их для имитации асинхронного ввода/вывода, а утилита RMAN (Recovery MANager - диспетчер восстановления) использует их при записи на ленту. Использование подчиненных процессов ввода/вывода управляется двумя параметрами инициализации.
· BACKUP_TAPE_IO_SLAVES. Этот параметр указывает, используются ли подчиненные процессы вода/вывода утилитой RMAN для резервного копирования или восстановления данных с ленты. Поскольку этот параметр предназначен для ленточных устройств, а к ленточным устройствам в каждый момент времени может обращаться только один процесс, он - булева типа, а не задает количество используемых подчиненных процессов, как можно было ожидать. Утилита RMAN запускает необходимое количество подчиненных процессов, в соответствии с количеством используемых физических устройств. Если параметр BACKUP_TAPE_IO_SLAVES имеет значение TRUE, то для записи или чтения с ленточного устройства используется подчиненный процесс ввода/вывода. Если этот параметр имеет (стандартное) значение FALSE, подчиненные процессы ввода/вывода не используются при резервном копировании. К ленточному устройству тогда обращается фоновый процесс, выполняющий резервное копирование.
· DBWn_IO_SLAVES. Задает количество подчиненных процессов ввода/вывода, используемых процессом DBWn. Процесс DBWn и его подчиненные процессы всегда записывают на диск измененные буфера буферного кэша. По умолчанию этот параметр имеет значение 0, и подчиненные процессы ввода/вывода не используются.
Подчиненные процессы параллельных запросов
В Oracle есть средства распараллеливания запросов к базе данных. Речь идет о возможности создавать для SQL-операторов типа SELECT, CREATE TABLE, CREATE INDEX, UPDATE и т. д. план выполнения, состоящий из нескольких планов, которые можно выполнять одновременно. Результаты выполнения этих планов объединяются. Это позволяет выполнить операцию за меньшее время, чем при последовательном выполнении. Например, если имеется большая таблица, разбросанная по десяти различным файлам данных, 16-процессорный сервер, и необходимо выполнить к этой таблице запрос, имеет смысл разбить план выполнения этого запроса на 16 небольших частей и полностью использовать возможности сервера. Это принципиально отличается от использования одного процесса для последовательного чтения и обработки всех данных.
Управление безопасностью БД
Чтобы получить доступ к базе данных, необходимо указать правильное имя пользователя и успешно пройти процедуру аутентификации. Администратор базы данных определяет имена пользователей, которым разрешен доступ к базе данных. В некоторых системах для каждого пользователя имеется своя собственная учетная запись, в других системах многие пользователи совместно используют общую учетную запись. На Рис.4 приведены способы управления безопасностью базы данных.
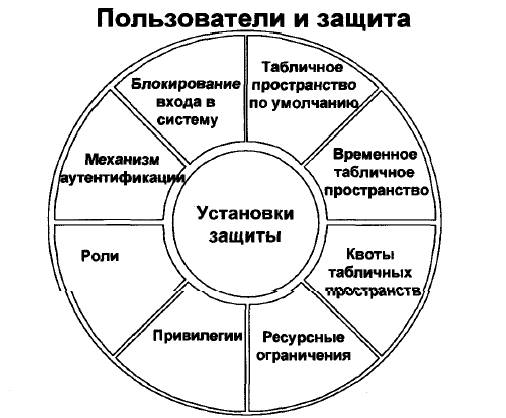
|
Механизм аутентификации
Аутентификация означает проверку кого-то или чего-то (пользователя, устройства или других объектов), кто хочет использовать данные, ресурсы или приложения. Она производится для установления доверительного отношения перед дальнейшим взаимодействием. Кроме того аутентификация предоставляет возможность вести учет доступа к ресурсам и объектам базы данных. После аутентификации процесс авторизации может предоставить или ограничить привилегии на доступ или на действия, разрешенные данному пользователю. Наиболее общий метод аутентификации – это использование пароля, когда пользователь создается вместе с паролем. Этот пароль должен указываться пользователем при попытке установить соединение. Когда администратор назначает пароль, он должен сразу же установить для него истечение срока годности (expire). Это заставит пользователя изменить пароль при первом соединении.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
