

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
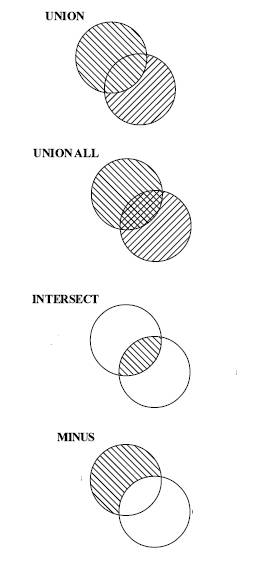
INTERSECT
SELECT employee_id, job_id
FROM job_history;
- MINUS – результатом выполнения являются все отличные строки, выбранные первой командой SELECT, которые не выбраны второй командой SELECT:
SELECT employee_id
FROM employees
MINUS
SELECT employee_id
FROM job_history;
Графически операторы SET представлены на Рис.5:
|
Операторы изменения данных в БД
Команды DML – это основа языка SQL. Они выполняются при следующих операциях:
- вставка новых строк в таблицу (INSERT).
- изменение существующих строк в таблице (UPDATE).
- удаление существующих строк из таблицы (DELETE).
- изменение или вставка строки при определенных условиях (MERGE).
Совокупность команд DML, образующих логическую единицу работы, является транзакция. Управление логикой транзакции осуществляется с помощью команд COMMIT, SAVEPOINT, ROLLBACK.
INSERT
Команда INSERT используется для вставки новых строк в таблицу. Синтаксис:
INSERT INTO table [(column [, column...])]
VALUES (value [, value...]);
Команда INSERT с предложением VALUES позволяет вставлять в таблицу только по одной строке.
INSERT INTO departments (department_id,
department_name, manager_id, location_id)
VALUES (70, 'Public Relations', 100, 1700);
Если вставляемая строка содержит значения для всех столбцов, то перечисление столбцов в предложении INSERT не обязательно:
INSERT INTO departments
VALUES (70, 'Public Relations', 100, 1700);
Следует помнить, что последовательность самих значений должна соответствовать последовательности столбцов в этой таблице. Лучше явно указывать список столбцов в команде INSERT. Символьные значения и даты обрамляются апострофами; числовые значения в апострофы не заключаются, так кА при этом будет выполняться неявное преобразование в тип данных NUMBER.
Для вставки неопределенных значений существует два метода.
- Неявный – неопределенные столбцы исключаются из списка вставляемых столбцов:
INSERT INTO departments (department_id, department_name)
VALUES (30, 'Purchasing');
- Явный – задается ключевое слово NULL в списке VALUES:
INSERT INTO departments
VALUES (100, 'Finance', NULL, NULL);
Задание пустой строки ‘’ в списке VALUES допускается только для символьных значений и дат. Для вставки специальных значений в таблицу можнл использовать функции. Пример использования функции SYSDATE для вставки в столбец hire_date текущей даты и времени:
INSERT INTO employees (employee_id,
first_name, last_name,
email, phone_number,
hire_date, job_id, salary,
commission_pct, manager_id,
department_id)
VALUES (113,
'Louis', 'Popp',
'LPOPP', '515.124.4567',
SYSDATE, 'AC_ACCOUNT', 6900,
NULL, 205, 110);
Для вставки конкретного значения даты используется функция TO_DATE:
INSERT INTO employees
VALUES (114,
'Den', 'Raphealy',
'DRAPHEAL', '515.127.4561',
TO_DATE ('ФЕВ 3, 2009', 'MON DD, YYYY'),
'SA_REP', 11000, 0.2, 100, 60);
Синтаксис многотабличного INSERT:
INSERT [ALL|FIRST]
[WHEN condition THEN] [insert_into_clause values_clause]
[ELSE] [insert_into_clause values_clause]
[insert_into_clause values_clause] (subquery)
Пример
INSERT ALL
INTO sal_history VALUES(EMPID, HIREDATE, SAL)
INTO mgr_history VALUES(EMPID, MGR, SAL)
SELECT employee_id EMPID, hire_date HIREDATE,
salary SAL, manager_id MGR
FROM employees
WHERE employee_id > 200;
INSERT ALL
WHEN HIREDATE < '01-ЯНВ-95' THEN
INTO emp_history VALUES(EMPID, HIREDATE, SAL)
WHEN COMM IS NOT NULL THEN
INTO emp_sales VALUES (EMPID, COMM, SAL)
SELECT employee_id EMPID, hire_date HIREDATE,
salary SAL, commission_pct COMM
FROM employees;
INSERT ALL
INTO sales_info VALUES (employee_id, week_id, sales_MON)
INTO sales_info VALUES (employee_id, week_id, sales_TUE)
INTO sales_info VALUES (employee_id, week_id, sales_WED)
INTO sales_info VALUES (employee_id, week_id, sales_THUR)
INTO sales_info VALUES (employee_id, week_id, sales_FRI)
SELECT EMPLOYEE_ID, week_id, sales_MON, sales_TUE,
sales_WED, sales_THUR, sales_FRI
FROM sales_source_data;
INSERT FIRST
WHEN salary < 5000 THEN
INTO sal_low VALUES (employee_id, last_name, salary)
WHEN salary between 5000 and 10000 THEN
INTO sal_mid VALUES (employee_id, last_name, salary)
ELSE
INTO sal_high VALUES (employee_id, last_name, salary)
SELECT employee_id, last_name, salary
FROM employees;
UPDATE
Для обновления существующих строк используется команда UPDATE. Синтаксис:
UPDATE table
SET column = value [, column = value, ...]
[WHERE condition];
Можно одновременно обновлять несколько строк. Предложение WHERE позволяет изменить конкретную строку или строки:
UPDATE employees
SET department_id = 50
WHERE employee_id = 113;
Если предложение WHERE отсутствует, обновляются все строки таблицы:
UPDATE copy_emp
SET department_id = 110;
DELETE
Удалять существующие строки модно с помощью команды DELETE. Синтаксис:
DELETE [FROM] table
[WHERE condition];
Удалить из таблицы конкретную строку или строки можно с помощью предложения WHERE. Если ни одна строка не была удалена, выдается сообщение “0 rows deleted”.
DELETE FROM departments
WHERE department_name = 'Finance';
Если предложение WHERE отсутствует, удаляются все строки таблицы:
DELETE FROM copy_emp;
Для удаления всех строк таблицы и освобождения памяти лучше использовать команду DDL TRUNCATE – усечение таблицы. Синтаксис команды:
TRUNCATE TABLE table_name;
Пример:
TRUNCATE TABLE copy_emp;
Откат команды невозможен. Команда DELETE удаляет строки из таблицы, но не освобождает место в табличном пространстве, занимаемое строками. Команда TRUNCATE выполняется быстрее.
MERGE
Изменять или вставлять новые строки при определенных условиях, можно, используя команду MERGE (слияние). Синтаксис:
MERGE INTO table_name table_alias
USING (table|view|sub_query) alias
ON (join condition)
WHEN MATCHED THEN
UPDATE SET
col1 = col1_val,
col2 = col2_val
WHEN NOT MATCHED THEN
INSERT (column_list)
VALUES (column_values);
Пример:
MERGE INTO copy_emp c
USING (SELECT * FROM EMPLOYEES ) e
ON (c. employee_id = e. employee_id)
WHEN MATCHED THEN
UPDATE SET
c. first_name = e. first_name,
c. last_name = e. last_name,
...
WHEN NOT MATCHED THEN
INSERT VALUES(e. employee_id, e. first_name, e. last_name,
e. email, e. phone_number, e. hire_date, e. job_id,
e. salary, mission_pct, e. manager_id,
e. department_id);
Обрабатывается условие (c. employee_id = e. employee_id). Taк как таблица copy_emp не заполнена, условие возвращает значение ложно (false) – нет соответствий. Выполняется условие WHEN NOT MATCHES и по команде MERGE вставляются строки из таблицы employees в таблицу copy_emp. Если строки в таблице copy_emp существуют и номер служащего (employee_id) совпадает в обеих таблицах, существующие строки таблицы copy_emp изменяются так, чтобы соответствовать строкам таблицы employees.
COMMIT, SAVEPOINT, ROLLBACK
Сервер Oracle обеспечивает согласованность данных на основе транзакций. Транзакции состоят из команд DMLб составляющих одно согласованное изменение данных. Транзакция начинается с первой исполняемой команды SQL и заканчивается, когда свершается одно из следующих событий:
- команда COMMIT или ROLLBACK;
- команда DDL, например, CREATE;
- команда DCL;
- пользователь выходит из программы iSQL*Plus;
- отказы системы;
Когда одна транзакция завершена, следующая исполняемая команда SQL автоматически начинает следующую транзакцию. Результаты выполнения команды DDL или DCL фиксируются автоматически. Следовательно, эти команды неявно завершают транзакцию.
Управление логикой транзакций осуществляется с помощью следующих команд:
COMMIT – завершает текущую транзакцию, делая все незафиксированные изменения постоянными,
SAVEPOINT имя – создает точку сохранения в текущей транзакции,
ROLLBACK – прекращает текущую транзакцию, отменяя все произведенные изменения в данных,
ROLLBACK TO SAVEPOINT имя – отменяет все произведенные изменения до точки сохранения.
Так как точки сохранения создаются логически, просмотреть список созданных точек сохранения нельзя. Пример:
UPDATE...
SAVEPOINT update_done;
INSERT...
ROLLBACK TO update_done;
DELETE FROM employees
WHERE employee_id = 99999;
INSERT INTO departments
VALUES (290, 'Corporate Tax', NULL, 1700);
COMMIT;
DELETE FROM copy_emp;
ROLLBACK;
Каждое изменение данных, выполненное в ходе транзакции, является временным до тех пор, пока транзакция не будет зафиксирована. Операции манипулирования данными изменяют только буфер базы данных, следовательно, предыдущее состояние данных может быть восстановлено. Текущий пользователь может проверить результаты своих операций манипулирования данными путем запросов к таблицам. Другие пользователи не могут видеть результаты манипулирования данными, выполняемых текущим пользователем. Сервер Oracle обеспечивает согласованность чтения, и каждый пользователь видит данные такими, какими они были зафиксированы последней командой COMMIT. Строки, с которыми в данный момент проводятся операции, блокируются: другие пользователи изменять их не могут. Все временные изменения становятся постоянными после из фиксации командой COMMIT. После выполнения команды COMMIT, измененные данные записываются в базу данных. Прежнее состояние данных безвозвратно теряется. Все пользователи могут, идет результаты транзакции. Блокировки с измененных строк снимаются, другие пользователи получают возможность изменять данные в этих строках. Все точки сохранения удаляются. Любые не зафиксированные изменения можно отменить командой ROLLBACK. После выполнения команды ROLLBACK изменения в данных отменяются. Восстанавливается прежнее состояние данных. Блокировка с соответствующих строк снимаются.
Подзапросы в командах DML
INSERT INTO
(SELECT employee_id, last_name, email, hire_date, job_id, salary, department_id
FROM employees
WHERE department_id = 50)
VALUES (99999, 'Taylor', 'DTAYLOR', TO_DATE ('07-JUN-99', 'DD-MON-RR'),
'ST_CLERK', 5000, 50);
UPDATE departments
SET (manager_id, location_id) =
(SELECT manager_id, location_id FROM departments WHERE department_id = 10)
WHERE department_id = 20;
UPDATE (SELECT salary, commission_pct FROM employees WHERE DEPARTMENT_ID = 80)
SET salary = salary * 1.1
WHERE commission_pct < .2;
DELETE FROM empl6 WHERE employee_id =
(SELECT employee_id
FROM emp_history
WHERE employee_id = E. employee_id);
DELETE FROM (SELECT * FROM job_history WHERE employee_id = 101);
Использование однострочных и групповых функций
Функции увеличивают мощность простого блока запроса и используются для манипулирования значениями данных. Рассмотрим однострочные функции для работы с числами, строками, датами, функции преобразования данных из одного типа в другой. А также групповые функции – функции для получения сводной информации по группам строк.
Однострочные функции
Однострочные функции работают только с одной строкой и возвращают по одному результату для каждой строки. Синтаксис однострочных функций:
function_name [(arg1, arg2,...)]
где
function_name – имя функции,
arg1, arg2,.. – аргументы, которые могут быть столбцами, выражениями, константами или значениями переменных.
· Символьные
Однострочные символьные функции принимают на входе символьные данные, а возвращают символьное или числовое значение. Символьные функции делятся на:
– функции преобразования регистра символов - LOWER, UPPER, INITCAP.
Примеры преобразований с помощью функций:
LOWER ('SQL Course') результат => sql course – преобразует алфавитные символы в нижний регистр,
UPPER ('SQL Course') => SQL COURSE – преобразует алфавитные символы в верхний регистр,
INITCAP ('SQL Course')=> Sql Course – преобразует алфавитные символы: первая буква каждого слова становится заглавной, остальные – строчные.
Пример использования функций в операторе SELECT:
SELECT employee_id, last_name, department_id FROM employees
WHERE last_name = 'higgins'; - данные не найдены.
SELECT employee_id, last_name, department_id FROM employees
WHERE LOWER(last_name) = 'higgins'; - выборка успешна.
– функции манипулирования символами - CONCAT, SUBSTR, LENGTH, INSTR, LPAD, RPAD, TRIM, REPLACE.
Примеры преобразований с помощью функций:
CONCAT ('Hello', 'World')=> HelloWorld – присоединяет первое символьное значение ко второму, эквивалентно оператору конкатенации (||),
SUBSTR ('HelloWorld',1,5) => Hello – возвращает 5 символов символьного выражения, начиная с символа 1. Если на месте второго аргумента стоит отрицательное число, отсчет начинается с конца символьной строки. Если третий аргумент отсутствует, возвращаются все символы до конца строки.
LENGTH ('HelloWorld') => 10 – возвращает количество символов в аргументе.
INSTR ('HelloWorld', 'W') => 6 – возвращает номер позиции строки второго аргумента в символьном значении первого аргумента. Дополнительно можно задать позицию начала поиска (третий аргумент) и число обнаружений (четвертый аргумент). По умолчанию третий и четвертый аргументы равны 1, что означает выполнение поиска в первом аргументе, начиная с первой позиции до первого обнаружения.
LPAD (salary,10,'*') => *****24000 – дополняет символьное значение первого аргумента слева до длины второго аргумента (10) символами третьего аргумента ('*').
RPAD (salary, 10, '*') => 24000***** 24000 – дополняет символьное значение первого аргумента справа до длины второго аргумента (10) символами третьего аргумента ('*').
REPLACE ('JACK and JUE','J','BL') => BLACK and BLUE – выполняет поиск строки второго аргумента ('J') по текстовому значению первого аргумента и в случае обнаружения производится ее замена на строку третьего аргумента ('BL').
TRIM (LEADING 'H' FROM 'HelloWorld') – elloWorld – позволяет вырезать из исходной строки ('HelloWorld') начальные (LEADING) или конечные (TRAILING) символы или и те, и другие (BOTH).
Пример использования функций в операторе SELECT:
SELECT employee_id, CONCAT (first_name, last_name) NAME,
job_id, LENGTH (last_name),
INSTR (last_name, 'a') "Contains 'a'?"
FROM employees WHERE SUBSTR(job_id, 4) = 'REP';
· Числовые - ROUND, TRUNC, MOD
Числовые функции принимают на входе числовые данные и возвращают числовые значения.
ROUND (45.926, 2) => 45.93 - округляет значение первого аргумента до десятичных разрядов, определяемых вторым аргументом. Если второй аргумент опущен, то до целого. Если второй аргумент отрицательный, округляются разряды слева от десятичной точки.
TRUNC (45.926, 2) => 45.92 - усекается значение первого аргумента до десятичных разрядов, определяемых вторым аргументом. Если второй аргумент опущен, то до целого. Если второй аргумент отрицательный, округляются разряды слева от десятичной точки.
MOD (1600, 300) => 100 – возвращает остаток от деления значения первого аргумента на значение второго аргумента.
· Для работы с датами - SYSDATE, MONTHS_BETWEEN, ADD_MONTHS, NEXT_DAY, LAST_DAY, ROUND, TRUNC
Oracle хранит даты во внутреннем числовом формате, представляющем столетие, год, месяц, число, часы, минуты и секунды.
SYSDATE – это функция, возвращающая текущую дату и время сервера базы данных. Можно использовать SYSDATE также, как любое другое имя столбца. Обычно для получения текущей даты используют запрос из фиктивной таблицы DUAL:
SELECT sysdate FROM dual;
С датами можно выполнять арифметические действия сложения и вычитания. Прибавлять и вычитать можно числовые константы и даты. При вычитании даты из даты в результате получается количество дней:
SELECT last_name, (SYSDATE-hire_date)/7 AS WEEKS
FROM employees
WHERE department_id = 90;
Примеры функций для работы с датами:
MONTHS_BETWEEN ('01-СЕН-95','11-ЯНВ-94') => 19.6774194 – число месяцев разделяющих две даты.
ADD_MONTHS (‘31-ЯНВ-96',1) => '29-ФЕВ-96' – добавление календарных месяцев к дате.
NEXT_DAY ('01-СЕН-95','ПЯТНИЦА') => '08-СЕН-95' – ближайшая дата, когда наступит заданный день недели.
LAST_DAY ('01-ФЕВ-95') => '28-ФЕВ-95' – последняя дата текущего месяца.
ROUND (SYSDATE,'MONTH') => 01-АВГ-03 – возвращает дату, округленную до месяца.
ROUND (SYSDATE,'YEAR') => 01-ЯНВ-04 - возвращает дату, округленную до года.
TRUNC (SYSDATE,'MONTH') => 01-ИЮЛ-03 - возвращает дату, усеченную до месяца.
TRUNC (SYSDATE,'YEAR') => 01-ЯНВ-03 - возвращает дату, усеченную до года.
· Функции преобразования типов данных - TO_CHAR, TO_DATE, TO_NUMBER.
В некоторых случаях сервер Oracle допускает данные какого-то типа там, где он ожидает данные другого типа. Это допускается, если сервер Oracle может автоматически привести данные к определенному типу. Такое преобразование типов данных может производиться неявно сервером Oracle или явно пользователем.
Синтаксис функции TO_CHAR:
TO_CHAR(число|дата, {формат}, {nlsparams}) – преобразует число или дату в строку символов в соответствии с форматом. Nlsparams определяет при преобразовании чисел знак отделения десятичных разрядов, знак отделения групп символов, знак обозначения валюты. При преобразовании дат nlsparams устанавливает язык, на котором будут отображаться наименования месяцев и дней. Если nlsparams или формат опущены, то функция использует параметры по умолчанию, установленные для данной сессии.
Пример применения функции TO_CHAR:
SELECT last_name, TO_CHAR(hire_date, 'fmDD Month YYYY') AS HIREDATE
FROM employees;
Элементы формата даты:
YYYY – полный год цифрами.
YEAR – год прописью.
MM – двузначное цифровое обозначение месяца.
MONTH – полное название месяца.
DY – трехзначное алфавитное сокращенное название дня недели.
DAY – полное название дня недели.
DD – номер дня месяца.
Элемент fm (fill mode) используется для удаления конечных пробелов и ведущих нулей.
Синтаксис функции TO_NUMBER:
TO_NUMBER(строка, {формат}, {nlsparams}) – преобразует символьную строку, содержащую цифры, в число в соответствии с форматом.
Синтаксис функции TO_DATE:
TO_DATE(строка, {формат}, {nlsparams}) – преобразует символьную строку, содержащую дату, в дату в соответствии с форматом.
· Общие функции - NVL, NVL2, NULLIF, COALEASCE.
Эти функции работают с любыми типами данных и используются для обработки неопределенных значений списка выражений.
Пример использования функции NVL для преобразования неопределенного значения (NULL) в действительное:
SELECT last_name, salary, NVL(commission_pct, 0), (salary*12) + (salary*12*NVL(commission_pct, 0)) AN_SAL FROM employees;
В примере функция NVL используется для преобразования неопределенных значений в ноль, чтобы вычислить годовой доход служащих.
Пример использования функции NVL2:
SELECT last_name, salary, commission_pct,
NVL2 (commission_pct, 'SAL+COMM', 'SAL') income FROM employees
WHERE department_id IN (50, 80);
Функция NVL2 проверяет значение первый аргумент. Если он определен, тогда функция NVL2 возвращает значение второго аргумента. Если значение первого аргумента не определено, результатом работы функции будет значение третьего аргумента.
Пример использования функции NULLIF:
SELECT first_name, LENGTH (first_name) "expr1", last_name, LENGTH (last_name) "expr2",
NULLIF (LENGTH (first_name), LENGTH (last_name)) result FROM employees;
Функция NULLIF сравнивает значения двух аргументов. Если они равны, функция возвращает неопределенное значение, если нет – значение первого аргумента.
Пример использования функции COALESCE:
SELECT last_name, employee_id, COALESCE (TO_CHAR (commission_pct), TO_CHAR (manager_id), 'No commission and no manager') FROM employees;
Функция COALESCE возвращает значение первого определенного аргумента в списке.
· Функции условной обработки – CASE, DECODE.
Пример использования выражения CASE:
SELECT last_name, job_id, salary,
CASE job_id WHEN 'IT_PROG’ THEN 1.10*salary
WHEN 'ST_CLERK' THEN 1.15*salary
WHEN 'SA_REP' THEN 1.20*salary
ELSE salary END "REVISED_SALARY"
FROM employees;
Выражение CASE позволяет производить логическую обработку оператора IF-THEN-ELSE в командах SQL, не вызывая процедуру.
Функция DECODE действует аналогичным образом. Синтаксис:
DECODE (столбец|выражение, вариант1, результат1
[, вариант2, результат2,...,]
[, результат по умолчанию])
Функция DECODE расшифровывает столбец или выражение после сравнения его с каждым искомым значением варианта. Если выражение равно искомому значению, функция возвращает соответствующий результат. Если выражение не совпадает ни с одним из искомых значений, а результат по умолчанию не задан, функция возвращает неопределенное значение. Пример использования функции DECODE:
SELECT last_name, job_id, salary,
DECODE (job_id, 'IT_PROG', 1.10*salary,
'ST_CLERK', 1.15*salary,
'SA_REP', 1.20*salary,
salary) REVISED_SALARY FROM employees;
Многострочные функции
Многострочные функции работают с группой строк и выдают по одному результату для каждой группы. Их часто называют групповыми функциями. Это:
AVG – среднее значение;
COUNT - количество строк;
MAX – максимальное значение;
MIN – минимальное значение;
STDDEV - стандартное отклонение значений;
SUM – суммирование значений;
VARIANCE – дисперсия значений.
Синтаксис применения групповых функций:
SELECT group_function (column), ...
FROM table
[WHERE condition]
[ORDER BY column];
Пример использования групповых функций:
SELECT AVG (salary), MAX (salary),
MIN (salary), SUM(salary)
FROM employees
WHERE job_id LIKE '%REP%';
Запрос вычисляет средний, самый высокий, самый низкий оклад и сумму окладов всех торговых представителей.
Для функции COUNT имеется три формата:
- COUNT(*) – возвращает количество строк в таблице, которые удовлетворяют ограничениям, заданным в команде SELECT. При этом учитываются и строки дубликаты и строки с неопределенными значениями.
Пример:
SELECT COUNT(*) FROM employees WHERE department_id = 50;
- COUNT(выражение) – возвращает количество строк с определенными значениями, заданными выражением:
SELECT COUNT(commission_pct) FROM employees WHERE department_id = 80;
- COUNT(DISTINCT выражение) – возвращает количество уникальных, определенных значений в столбце, заданном выражением:
SELECT COUNT(DISTINCT department_id) FROM employees;
C помощью предложения GROUP BY можно разделить строки таблицы на группы. Затем можно использовать групповые функции для получения сводной информации по каждой группе. Синтаксис:
SELECT column, group_function (column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];
Пример:
SELECT department_id, AVG (salary)
FROM employees
GROUP BY department_id;
Если используется предложение GROUP BY, все столбцы из списка SELECT, к которым не применяются групповые функции, должны быть включены в предложение GROUP BY. В примере выдаются номера отделов и средний оклад по каждому отделу.
Столбец, указанный в GROUP BY, может отсутствовать в списке SELECT:
SELECT AVG (salary)
FROM employees
GROUP BY department_id;
Чтобы получить результаты по группам и подгруппам, следует указать несколько столбцов в предложении GROUP BY. Синтаксис:
SELECT column, group_function (column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];
Пример:
SELECT department_id, job_id, SUM (salary)
FROM employees
WHERE department_id > 40
GROUP BY department_id, job_id
ORDER BY department_id;
Предложение GROUP BY указывает, как должны быть сгруппированы строки: сначала по номерам отделов, затем по должностям внутри отделов. Таким образом, функция SUM применяется к столбцу окладов по каждой должности внутри каждого отдела.
Если в одной о той же команде SELECT указываются отдельные элементы и групповые функции, предложение GROUP BY со списком отдельных элементов обязательно. При выполнении следующего запроса будет выдаваться сообщение об ошибке:
SELECT department_id, COUNT (last_name)
FROM employees;
Предложение WHERE для исключения групп не используется. Следующая команда SELECT вызовет ошибку:
SELECT department_id, AVG (salary)
FROM employees
WHERE AVG (salary) > 8000
GROUP BY department_id;
Для исключения групп следует использовать предложение HAVING. Синтаксис:
SELECT column, group_function
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[HAVING group_condition]
[ORDER BY column];
Пример применения предложение HAVING:
SELECT department_id, MAX (salary)
FROM employees
GROUP BY department_id
HAVING MAX (salary)>10000;
Выводятся только те номера отделов и максимальный оклад только тех отделов, где он превышает 10000.
Пример применения предложения WHERE для ограничения по столбцу совместно с ограничением по групповой функцией:
SELECT job_id, SUM (salary) PAYROLL
FROM employees
WHERE job_id NOT LIKE '%REP%'
GROUP BY job_id
HAVING SUM (salary) > 13000
ORDER BY SUM (salary);
Выводятся должности и общая сумма окладов за месяц по каждой должности, если эта общая сумма превышает 13000. Из выходных данных исключаются данные о торговых представителях. Список сортируется по возрастанию общей суммы окладов.
В команде запроса в предложении GROUP BY можно задавать операторы ROLLUP и CUBE. Операция ROLLUP выдает результат группировки, содержащий обычные сгруппированные строки и строки промежуточных итогов. При использовании операции CUBE выбранные строки группируются на основе значений всех возможных комбинаций заданных выражений. В результате возвращается по одной строке итоговой информации для каждой группы. Оператор CUBE можно использовать для получения строк сводных перекрестных отчетов. Для использования операторов ROLLUP и CUBE необходимо, чтобы столбцы, указанные в предложении GROUP BY, были связаны значимыми и реальными отношениями друг с другом, иначе операторы вернут не относящуюся к делу информацию.
Пример использования ROLLUP:
SELECT department_id, job_id, SUM (salary) FROM employees
WHERE department_id<60
GROUP BY ROLLUP (department_id, job_id);
В примере общая сумма окладов по каждой должности внутри отделов, номера которых меньше 60, выводится на основе предложения GROUP BY. Оператор ROLLUP выдает:
- общую сумму окладов сотрудников отделов, номера которых меньше 60.
- общую сумму окладов сотрудников всех отделов, номера которых меньше 60, независимо от должности.
Оператор ROLLUP вырабатывает промежуточные итоговые данные, которые сворачиваются (roll up) с наименьшего уровня до самого высокого уровня в порядке, заданном списком группируемых столбцов в предложении GROUP BY.
Пример использования CUBE:
SELECT department_id, job_id, SUM (salary) FROM employees
WHERE department_id<60
GROUP BY CUBE (department_id, job_id);
В примере общая сумма окладов по каждой должности внутри отделов, номера которых меньше 60, выводится на основе предложения GROUP BY. Оператор CUBE выдает:
- общие суммы окладов сотрудников по каждому отделу, номер которого меньше 60.
- общие суммы окладов сотрудников по всем должностям независимо от отдела, полученных на основе данных, в которых номер отдела меньше 60.
- общие суммы окладов сотрудников всех отделов, номера которых меньше 60, независимо от должности.
Оператор CUBE выполняет операцию ROLLUP для выработки промежуточных итогов по отделам, номера которых меньше 60, независимо от наименования должности. Дополнительно оператор CUBE выводит общий оклад по каждой должности независимо от отделов.
Вместе с оператором CUBE или оператором ROLLUP может быть использована функция GROUPING. Она помогает понять, как были получены итоговые значения. Функция GROUPING использует единственный столбец в качестве аргумента. Значение этого аргумента должно соответствовать одному из выражений в предложении GROUP BY. Функция GROUPING возвращает 0 или 1. Значения, возвращаемые функцией GROUPING, полезны для:
- определения уровня агрегирования данного промежуточного итога, т. е. для нахождения группы или групп, на которых основывается промежуточная итоговая сумма;
- определения того, неопределенное значение (NULL) в выражении столбца – это результат который отражает факт, что:
- значение NULL получено из базовой таблицы, хранящей значение NULL;
- значение NULL создано ROLLUP/CUBE, как результат групповой функции, примененной к этому выражению.
Значение 0, возвращенное функцией GROUPING, отражает одну из следующих ситуаций:
- выражение использовалось для подсчета агрегированного значения;
- значение NULL в выражении – это хранимое значение NULL.
Значение 1, возвращенное функцией GROUPING, отражает одну из следующих ситуаций:
- выражение не использовалось для подсчета агрегированного значения.
- Значение NULL в выражении столбца создано функциями ROLLUP или CUBE как результат группировки.
Пример использования функции GROUPING:
SELECT department_id deptid, job_id job, SUM(salary),
GROUPING (department_id) grp_dept,
GROUPING (job_id) grp_job
FROM employees WHERE department_id<50
GROUP BY ROLLUP (department_id, job_id);
Дальнейшее расширение предложения GROUP BY – это GROPING SETS, которое позволяет задавать несколько группировок данных. Такие действия повышают эффективность агрегирования, а также помогают анализировать данные в зависимости от многих размерностей.
Использование GROUPING SETS позволяет написать только одну команду SELECT и определить в ней различные группировки (которые могут также включать операторы ROLLUP или CUBE). Без такой возможности необходимо определять несколько команд SELECT, объединенных операторами UNION ALL. Например, можно написать команду:
SELECT department_id, job_id, manager_id, AVG (salary)
FROM employees
GROUP BY GROUPING SETS
((department_id, job_id, manager_id),
(department_id, manager_id), (job_id, manager_id));
По этой команде подсчитываются итоговые значения для трех группировок;
(department_id, job_id, manager_id), (department_id, manager_id) и (job_id, manager_id).
Без этой дополнительной возможности потребовалось бы объединение с помощью UNION ALL нескольких запросов для получения такого же результата. Многозапросный подход неэффективен, так как требует многократного сканирования одних и тех же данных.
Аналитические функции
Некоторые вопросы об информации в базе данных задают часто, но реализующие их запросы сложно написать на обычном языке SQL (кроме того, такие запросы не всегда быстро работают). Эти проблемы часто можно решить с помощью аналитических функций, которые добавляют расширения языка SQL, упрощающие создание запросов и существенно повышающие производительность по сравнению с обычным SQL-запросом. Ряд запросов, которые сложно сформулировать на обычном языке SQL, весьма типичны:
- Подсчет промежуточной суммы. Показать суммарную зарплату сотрудников отдела построчно, чтобы в каждой строке выдавалась сумма зарплат всех сотрудников вплоть до указанного.
- Подсчет процентов в группе. Показать, какой процент от общей зарплаты по отделу составляет зарплата каждого сотрудника. Берем его зарплату и делим на сумму зарплат по отделу.
- Запросы первых N. Найти N сотрудников с наибольшими зарплатами или N наиболее продаваемых товаров по регионам.
- Подсчет скользящего среднего. Получить среднее значение по текущей и предыдущим N строкам.
- Выполнение ранжирующих запросов. Показать относительный ранг зарплаты сотрудника среди других сотрудников того же отдела.
Сервер Oracle предлагает 26 аналитических функций. Они разбиваются на четыре основных класса по возможностям.
Первый класс образуют различные функции ранжирования, позволяющие строить запросы типа "первых N".
Второй класс образуют оконные функции, позволяющие вычислять разнообразные агрегаты. В качестве функции агрегирования можно использовать SUM, COUNT, AVG, MIN, МАХ и т. д.
К третьему классу относятся различные итоговые функции. Они очень похожи на оконные, поэтому имеют те же имена: SUM, MIN, MAX и т. д. Тогда как оконные функции используются для работы с окнами данных, итоговые функции работают со всеми строками фрагмента или группы.
Есть также функции LAG и LEAD, позволяющие получать значения из предыдущих или следующих строк результирующего множества. Это помогает избежать самосоединения данных. Например, если в таблице записаны даты визитов пациентов к врачу и необходимо вычислить время между визитами для каждого их них, очень пригодится функция LAG. Можно просто фрагментировать данные по пациентам и отсортировать их по дате. После этого функция LAG легко сможет вернуть данные предыдущей записи для пациента. Останется вычесть из одной даты другую. До появления аналитических функций для получения этих данных приходилось организовывать сложное соединение таблицы с ней же самой.
Пример применения аналитических функций для подсчета промежуточной суммы зарплат по отделам:
SELECT last_name, department_id, salary,
SUM (salary) OVER (ORDER BY department_id, last_name) running_total,
SUM (salary) OVER (PARTITION BY department_id ORDER BY last_name) department_total,
ROW_NUMBER () OVER (PARTITION BY department_id ORDER BY last_name) seq
FROM employees ORDER BY department_id, last_name
Запрос выдал следующие значения:
running_total – сумма зарплат в целом. Это было сделано по всему упорядоченному результирующему множеству с помощью конструкции SUM (SAL) OVER (ORDER BY department_id, last_name).
department_total – подсчет промежуточных сумм по отделам, сбрасывая их в ноль при переходе к следующему отделу. Этого удалось добиться благодаря конструкции PARTITION BY department_id - в запросе была указана конструкция, задающая условие разбиения данных на группы.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
