

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
 КАЗАНСКИЙ (ПРИВОЛЖСКИЙ) ФЕДЕРАЛЬНЫЙ
КАЗАНСКИЙ (ПРИВОЛЖСКИЙ) ФЕДЕРАЛЬНЫЙ
УНИВЕРСИТЕТ
Факультет вычислительной математики и кибернетики
Кафедра теоретической кибернетики
МЕТОДИЧЕСКОЕ ПОСОБИЕ
«Технологии баз данных (СУБД Oracle)»
Старший преподаватель кафедры теоретической кибернетики
Администратор СУБД Oracle лаборатории технологий баз данных
НИИММ им.
Казань-2010
Технологии баз данных (СУБД Oracle)
Гусенков Н. Г.
Методическое пособие представляет собой основную часть специального курса «СУБД Oracle» и предназначено для использования в качестве учебного и справочного материала студентами IV курса кафедры теоретической кибернетики.
В методическом пособии исследованы следующие вопросы:
· Структура и архитектура реляционной системы управления базами данных Oracle;
· Средства языка SQL;
· Способы создания и работы с объектами базы данных (таблицами, индексами, представлениями, ограничениями, триггерами и т. д.);
· Утилиты Oracle для импорта, экспорта, загрузки данных;
· Проведение настройки приложений;
· Применение основных стандартных пакетов;
Содержание
Введение. 6
Архитектура сервера Oracle. 7
Файлы базы данных. 8
Файлы параметров. 8
Файлы данных. 10
Файлы журнала повторного выполнения. 11
Активный журнал повторного выполнения. 12
Архивный журнал повторного выполнения. 14
Управляющие файлы.. 15
Временные файлы.. 15
Память. 15
Области PGA и UGA.. 16
Область SGA.. 16
Буферный кэш.. 17
Разделяемый пул. 17
Большой пул. 18
Буфер журнала повторного выполнения. 19
Java-пул. 19
Процессы.. 20
Серверные процессы.. 20
Фоновые процессы.. 23
Подчиненные процессы.. 25
Управление безопасностью БД.. 27
Механизм аутентификации. 27
Квоты табличных пространств. 28
Табличное пространство по умолчанию.. 28
Временное табличное пространство. 28
Блокирование входа пользователя в систему. 28
Ресурсные ограничения. 28
Привилегии. 28
Системные привилегии (system privileges) 29
Объектные привилегии (object privileges) 29
Роли. 29
Профиль. 29
Аудит. 30
Стандартный аудит. 30
Аудит по значениям.. 32
Дифференцированный аудит. 32
Создание объектов БД.. 33
Стандартные таблицы и поддержка целостности базы данных. 34
Ограничение целостности Foreign Key. 35
Состояния ограничений целостности. 35
Проверка ограничений. 36
Изменение режима выполнения откладываемых ограничений. 37
Создание ограничений. 37
Получение информации о таблицах и ограничениях целостности. 37
Временные таблицы.. 38
Внешние таблицы.. 38
Индексы на основе В*-дерева. 39
Индексы с обращенным ключом.. 40
Индексы на основе битовых карт. 40
Индексы по функции. 40
Таблицы, организованные по индексу. 41
Представления. 42
Триггера. 43
Табличные триггера. 43
Триггер INSTEAD OF. 46
Системные триггера. 47
Синонимы.. 49
Последовательности. 49
Импорт, экспорт и загрузка данных. 50
Утилиты IMP и EXP. 50
Утилиты Data Pump. 52
SQL*Loader 53
Описание метаданных. 57
SQL-запросы и подзапросы.. 59
Базовый оператор SELECT. 59
Работа с NULL.. 61
Соединение таблиц. 62
Подзапросы.. 65
Составные запросы (операторы SET) 68
Операторы изменения данных в БД.. 69
INSERT. 70
UPDATE.. 72
DELETE.. 72
MERGE.. 72
COMMIT, SAVEPOINT, ROLLBACK.. 73
Подзапросы в командах DML.. 74
Использование однострочных и групповых функций. 75
Однострочные функции. 75
Многострочные функции. 79
Аналитические функции. 84
Конструкция фрагментации. 86
Конструкция упорядочения. 86
Конструкция окна. 87
Окна диапазона. 88
Окна строк. 89
Задание окон. 90
Создание иерархических запросов. 91
Использование объектно-реляционных средств. 93
Применение основных стандартных пакетов. 102
DBMS_APPLICATION_INFO.. 102
DBMS_JOB.. 106
UTL_FILE.. 110
DBMS_LOB.. 111
DBMS_ALERT. 112
DBMS_PIPE.. 116
DBMS_UTILITY.. 117
Стратегии и средства настройки приложений. 119
EXPLAIN PLAN.. 120
SQL_TRACE, TIMED_STATISTICS и TKPROF. 122
Связываемые переменные. 128
Стабилизация плана оптимизатора. 134
Список литературы.. 143
Введение
СУБД Oracle - реляционная база данных, состоящая из множества таблиц, которые могут быть использованы независимо или взаимосвязано друг с другом.
На Рис.1 представлена диаграмма отношений сущностей (erd – entity relationship diagram) для приложения “Трудовые ресурсы”(HR – Human Resources). В ней отражены таблицы и отношения между ними, которые используются в практических примерах данного пособия.
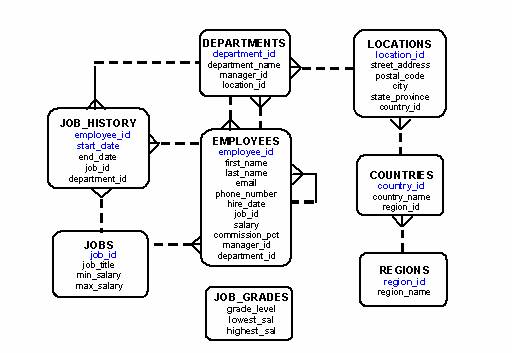
|
Архитектура сервера Oracle
Oracle проектировалась как максимально переносимая СУБД, - она доступна на всех распространенных платформах. Хотя физические средства реализации СУБД Oracle на разных платформах могут отличаться, архитектура системы - достаточно общая, чтобы можно было понять, как СУБД Oracle работает на всех платформах. Сервер Oracle включает процессы, структуры памяти и файлы. Сервер Oracle состоит из экземпляра Oracle и базы данных Oracle. Экземпляр Oracle это совокупность фоновых процессов и структур памяти. Экземпляр должен быть запущен для обеспечения доступа к информации базы данных. Каждый раз, когда запускается экземпляр, выделяется память для системной глобальной области (SGA) и стартуют фоновые процессы. Фоновые процессы экземпляра выполняют стандартные функции, необходимые для обслуживания запросов нескольких пользователей одновременно. Фоновые процессы выполняют операции ввода-вывода и контролируют другие процессы Oracle, обеспечивая параллельную обработку, повышение производительности и надежности. База данных состоит из файлов операционной системы (файлов базы данных), в которых на физическом уровне хранится информация в базе данных. Использование файлов базы данных гарантирует целостность хранимой информации и восстановление в случае сбоя экземпляра Oracle.
|
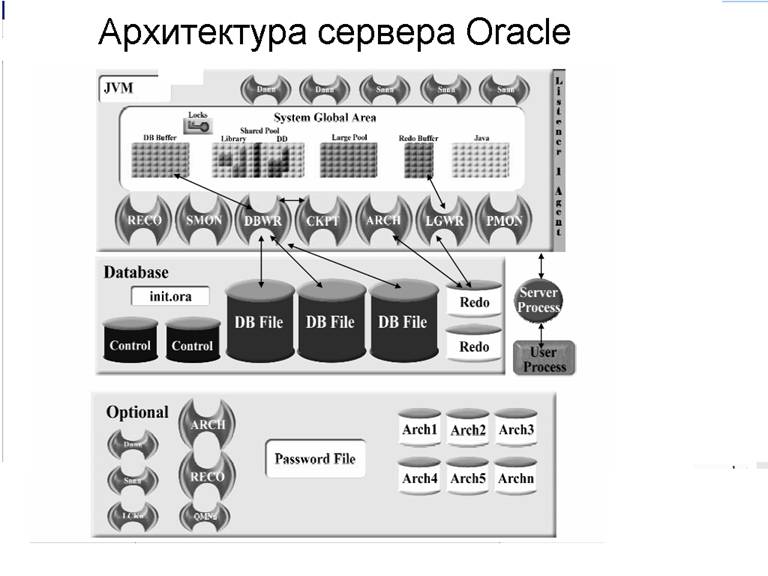
На Рис.2 представлены три основных компонента архитектуры сервера Oracle:
· Файлы - образуют базу данных и поддерживают экземпляр. Это файлы параметров, управляющие файлы, данных, временных данных и журналов повторного выполнения.
· Структуры памяти - системная глобальная область (SGA - System Global Area ), глобальная область процесса (PGA - Process Global Area), глобальная область пользователя (UGA - User Global Area).
· Физические процессы или потоки - серверные процессы, фоновые процессы и подчиненные процессы.
Файлы базы данных.
Базу данных образуют следующие файлы.
· Файлы параметров. По этим файлам экземпляр при запуске определяет свои характеристики, например, размер структур в памяти и местонахождение управляющих файлов.
· Файлы данных. Собственно данные (в этих файлах хранятся таблицы, индексы и все остальные сегменты).
· Файлы журнала повторного выполнения. Журналы транзакций.
· Управляющие файлы. Определяют местонахождение файлов данных и содержат
· другую необходимую информацию о состоянии базы данных.
· Временные файлы. Используются при сортировке больших объемов данных и для хранения временных объектов.
· Файлы паролей. Используются для аутентификации пользователей, выполняющих
· администрирование удаленно, по сети.
Файлы параметров
С базой данных Oracle связано много файлов параметров: от файла TNSNAMES. ORA на клиентской рабочей станции (используемого для поиска сервера) и файла LISTENER. ORA на сервере (для запуска процесса прослушивания) до файлов SQLNET. ORA, PROTOCOL. ORA, NAMES. ORA, CMAN. ORA и LDAP. ORA. Наиболее важным является файл параметров инициализации экземпляра, потому что без него не удастся запустить экземпляр. Файл параметров инициализации экземпляра обычно называют файлом init или файлом init. ora. Это название происходит от стандартного имени этого файла, init<ORACLE_SID>.ora. Например, экземпляр со значением SID, равным kurs, обычно имеет файл инициализации initkurs. ora. Без файла параметров инициализации нельзя запустить экземпляр Oracle. Поэтому файл этот достаточно важен. Однако, поскольку это обычный текстовый файл, который можно создать в любом текстовом редакторе, сохранять его ценой собственной жизни не стоит. ORACLE_SID (или SID) - это идентификатор экземпляра. Если значение ORACLE_SID задано неправильно, выдается сообщение об ошибке ORACLE NOT AVAILABLE. В одном и том же базовом каталоге ORACLE_HOME может быть несколько баз данных, так что необходимо иметь возможность уникально идентифицировать их и соответствующие конфигурационные файлы.
В Oracle файл init. ora имеет очень простую конструкцию. Он представляет собой набор пар имя параметра/значение. Файл init. ora может иметь такой вид:
db_name = "kurs"
db_block_size = 8192
control_files = ("C:\oradata\control01.ctl", "C:\oradata\control02.ctl")
Фактически это почти минимальный файл init. ora, с которым уже можно работать. В нем указан размер блока, стандартный для платформы OC. Файл параметров инициализации используется для получения имени базы данных и местонахождения управляющих файлов. Управляющие файлы содержат информацию о местонахождении всех остальных файлов, так что они нужны в процессе начальной загрузки при запуске экземпляра.
Начиная с версии Oracle 9i, существуют два типа файлов параметров инициализации:
- файл статических параметров, PFILE или init<ORACLE_SID>.ora; файл постоянных параметров, SPFILE или :sp<ORACLE_SID>.ora;
В файле параметров содержатся:
· перечень параметров экземпляра,
· имя базы данных, которую обслуживает экземпляр,
· распределение памяти для структур системной глобальной области (SGA),
· имена и расположение управляющих файлов,
· информация о сегментах отката,
· режим журналирования (ARCHJVELOG или NOARCHIVELOG).
PFILE – это текстовый файл, который может быть отредактирован с помощью стандартного редактора ОС. Экземпляр читает файл параметров только при запуске. Если файл был модифицирован, то для того, чтобы изменения вступили в силу, необходимо перезапустить экземпляр. Некоторые из параметров могут быть динамически изменены во время работы экземпляра. Изменения динамических параметров не отражаются на содержимом файла PFILE.
SPFILE – это двоичный файл. Этот файл не предназначен для внесения изменений вручную и должен всегда располагаться на сервере. После создания этот файл сопровождается сервером Oracle. SPFILE позволяет вносить изменения в параметры, которые становятся постоянными и действуют после перезапуска базы данных. Команда ALTER SYSTEM применяется для изменения значений параметров. Ключевой параметр SCOPE в этой команде определяет границы внесения изменений.
SCOPE=MEMORY – изменения действуют только до остановки запущенного в настоящее время экземпляра.
SCOPE=SPFILE - значение параметра изменяется только в файлу SPFILE.
SCOPE=BOTH - изменяется значение параметра для выполняемого экземпляра и в файле SPFOLE.
Пример: ALTER SYSTEM SET shared_pool_size = SCOPE=SPFILE
Файл SPFILE может быть создан на основе файла init<ORACLE_SID>.ora с помощью команды CREATE SPFILE, которая может быть выполнена до или после открытия базы данных.
CREATE SPFILE [=’полный путь SPFILE’] FROM PFILE [=’полный путь PFILE’ ]
На основе SPFILE можно получить PFILE.
CREATE PFILE [=’полный путь PFILE’] FROM SPFILE [=’полный путь SPFILE’ ]
Выгрузка SPFILE в PFILE полезна для сохранения содержимого файла инициализации на случай его потери.
Чтобы посмотреть информацию из SPFILE можно использовать представление V$SPARAMETER
При запуске экземпляра можно явно указать файл параметров.
STARTUP PFILE = ’полный путь PFILE’
В файл PFILE можно вставить параметр, указывающий на то, что нужно пользоваться SPFILE. Это единственный способ, чтобы указать путь к файлу SPFILE, если он не назван и не находится в директории по умолчанию (опции STARTUP SPFILE нет).
Файлы данных
Файлы данных вместе с файлами журнала повторного выполнения являются наиболее важными в базе данных. Именно в них хранятся все данные.
Рассмотрим организацию файлов данных в Oracle и способы хранения данных в этих файлах. Но прежде надо разобраться, что такое табличное пространство, сегмент, экстент и блок. Все это - единицы выделения пространства под объекты в базе данных Oracle.
Сегменты - это области на диске, выделяемые под объекты - таблицы, индексы, сегменты отката и т. д. При создании таблицы создается сегмент таблицы. При создании фрагментированной таблицы создается по сегменту для каждого фрагмента. При создании индекса создается сегмент индекса и т. д. Каждый объект, занимающий место на диске, хранится в одном сегменте. Есть сегменты отката, временные сегменты, сегменты индексов и т. д. Сегменты, в свою очередь, состоят из одного или нескольких экстентов. Экстент - это непрерывный фрагмент пространства в файле. Каждый сегмент первоначально состоит хотя бы из одного экстента, причем для некоторых объектов требуется минимум два экстента (в качестве примера можно назвать сегменты отката). Чтобы объект мог вырасти за пределы исходного экстента, ему необходимо выделить следующий экстент. Этот экстент не обязательно должен выделяться рядом с первым; он может находиться достаточно далеко от первого, но в пределах экстента в файле пространство всегда непрерывно. Экстенты состоят из блоков.
Блок - наименьшая единица выделения пространства в Oracle. В блоках и хранятся строки данных, индексов или промежуточные результаты сортировок. Именно блоками сервер Oracle обычно выполняет чтение и запись на диск.
Блоки в Oracle бывают размером 2 Кбайт, 4 Кбайт или 8 Кбайт (хотя допустимы также блоки размером 16 Кбайт и 32 Кбайт). Размер блока в базе данных с момента ее создания - величина постоянная, поэтому все блоки в базе данных одного размера.
Формат блока:
- Заголовок блока содержит информацию о типе блока (блок таблицы, блок индекса и т. д.), информацию о текущих и прежних транзакциях, затронувших блок, а также адрес (местонахождение) блока на диске.
- Каталог таблиц содержит информацию о таблицах, строки которых хранятся в этом блоке (в блоке могут храниться данные нескольких таблиц).
- Каталог строк содержит описание хранящихся в блоке строк. Это массив указателей на строки, хранящиеся в области данных блока.
Вместе эти три части блока называются служебным пространством блока. Это пространство недоступно для данных и используется сервером Oracle для управления блоком.
Остальные две части блока вполне понятны: в блоке имеется:
- Занятое пространство, в котором хранятся данные.
- Свободное пространство.
Таким образом, сегменты состоят из экстентов, которые, в свою очередь, состоят из блоков.
Следующее понятие:
Табличное пространство (tablespace) - это контейнер с сегментами. Каждый сегмент принадлежит к одному табличному пространству. В табличном пространстве может быть много сегментов. Все экстенты сегмента находятся в табличном пространстве, где создан сегмент. Сегменты никогда не переходят границ табличного пространства. С табличным пространством, в свою очередь, связан один или несколько файлов данных. Экстент любого сегмента табличного пространства целиком помещается в одном файле данных. Однако экстенты сегмента могут находиться в нескольких различных файлах данных.
Табличные пространства в Oracle - это логические структуры хранения данных.
Разработчики создают сегменты в табличных пространствах. Они никогда не переходят на уровень файлов. Объекты создаются в табличных пространствах, а об остальном заботится сервер Oracle. Если в дальнейшем администратор базы данных решит перенести файлы данных на другой диск для более равномерного распределения операций ввода/вывода по дискам, никаких проблем для приложения это не создаст. На работе приложения это никак не отразится.
Итак, иерархия объектов, обеспечивающих хранение данных в Oracle, выглядит так.
1. База данных, состоящая из одного или нескольких табличных пространств.
2. Табличное пространство, состоящее из одного или нескольких файлов данных. Табличное пространство содержит сегменты.
3. Сегмент (TABLE, INDEX и т. д.), состоящий из одного и более экстентов. Сегмент привязан к табличному пространству, но его данные могут находиться в разных файлах данных, образующих это табличное пространство.
4. Экстент - набор расположенных рядом на диске блоков. Экстент целиком находится в одном табличном пространстве и, более того, в одном файле данных этого табличного пространства.
5. Блок - наименьшая единица управления пространством в базе данных. Блок - наименьшая единица ввода/вывода, используемая сервером.
Файлы журнала повторного выполнения
Файлы журнала повторного выполнения(redo log) принципиально важны для базы данных Oracle. Это журналы транзакций базы данных. Они используются только для восстановления при сбое экземпляра или носителя или при поддержке резервной базы данных на случай сбоев. Если на сервере, где работает СУБД, отключится питание и вследствие этого произойдет сбой экземпляра, для восстановления системы в состояние, непосредственно предшествующее отключению питания, сервер Oracle при повторном запуске будет использовать активные журналы повторного выполнения. Если диск, содержащий файлы данных, полностью выйдет из строя, для восстановления резервной копии этого диска на соответствующий момент времени сервер Oracle, помимо активных журналов повторного выполнения, будет использовать также архивные. Кроме того, при случайном удалении таблицы или какой-то принципиально важной информации, если эта операция зафиксирована, с помощью активных и заархивированных журналов повторного выполнения можно восстановить данные из резервной копии на момент времени, непосредственно предшествующий удалению.
Практически каждое действие, выполняемое в СУБД Oracle, генерирует определенные данные повторного выполнения, которые надо записать в активные файлы журнала повторного выполнения. При вставке строки в таблицу конечный результат этой операции записывается в журналы повторного выполнения. При удалении строки записывается факт удаления. При удалении таблицы в журнал повторного выполнения записываются последствия этого удаления. Данные из удаленной таблицы не записываются, но рекурсивные SQL-операторы, выполняемые сервером Oracle при удалении таблицы, генерируют определенные данные повторного выполнения. Например, при этом сервер Oracle удалит строку из таблицы SYS. OBJ$, и это удаление будет отражено в журнале.
Некоторые операции могут выполняться в режиме с минимальной генерацией информации повторного выполнения. Например, можно создать индекс с атрибутом NOLOGGING. Это означает, что первоначальное создание этого индекса не будет записываться в журнал, но любые инициированные при этом рекурсивные SQL-операторы, выполняемые сервером Oracle, - будут. Например, вставка в таблицу SYS. OBJ$ строки, соответствующей индексу, в журнал записываться не будет. Однако последующие изменения индекса при выполнении SQL-операторов INSERT, UPDATE и DELETE, будут записываться в журнал.
Есть два типа файлов журнала повторного выполнения: активные и архивные.
Активный журнал повторного выполнения
В каждой базе данных Oracle есть как минимум два активных файла журнала повторного выполнения. Эти активные файлы журнала повторного выполнения имеют фиксированный размер и используются циклически. Сервер Oracle выполняет запись в файл журнала 1, а когда доходит до конца этого файла, - переключается на файл журнала 2 и переписывает его содержимое от начала до конца. Когда заполнен файл журнала 2, сервер переключается снова на файл журнала 1 (если имеется всего два файла журнала повторного выполнения; если их три, сервер, разумеется, переключится на третий файл): Переход с одного файла журнала на другой называется переключением журнала. Важно отметить, что переключение журнала может вызвать временное "зависание" плохо настроенной базы данных. Поскольку журналы повторного выполнения используются для восстановления транзакций в случае сбоя, перед повторным использованием файла журнала необходимо убедиться, что его содержимое не понадобится в случае сбоя. Если сервер Oracle "не уверен", что содержимое файла журнала не понадобится, он приостанавливает на время изменения в базе данных и убеждается, что данные, "защищаемые" этой информацией повторного выполнения, записаны на диск. После этого обработка возобновляется, и файл журнала переписывается.
Ключевое понятие баз данных - обработка контрольной точки. Чтобы понять, как используются активные журналы повторного выполнения, надо разобраться с обработкой контрольной точки, использованием буферного кэша базы данных и рассмотреть функции процесса записи блоков базы данных (Database Block Writer - DBWn). В буферном кэше базы данных временно хранятся блоки базы данных. Это структура в области SGA разделяемой памяти экземпляра Oracle. При чтении блоки запоминаются в этом кэше (предполагается, что в дальнейшем их не придется читать с диска).
Буферный кэш - первое и основное средство настройки производительности сервера. Он существует исключительно для ускорения очень медленного процесса ввода/вывода. При изменении блока путем обновления одной из его строк изменения выполняются в памяти, в блоках буферного кэша. Информация, достаточная для повторного выполнения этого изменения, записывается в буфер журнала повторного выполнения - еще одну структуру данных в области SGA. При фиксации изменений с помощью оператора COMMIT сервер Oracle не записывает на диск все измененные блоки в области SGA. Он только записывает в активные журналы повторного выполнения содержимое буфера журнала повторного выполнения. Пока измененный блок находится в кэше, а не на диске, содержимое соответствующего активного журнала может быть использовано в случае сбоя экземпляра. Если сразу после фиксации изменения отключится питание, содержимое буферного кэша пропадет.
Если это произойдет, единственная запись о выполненном изменении останется в файле журнала повторного выполнения. После перезапуска экземпляра сервер Oracle будет по сути повторно выполнять транзакцию, изменяя блок точно так же, как он это делал ранее, и фиксируя это изменение автоматически. Итак, если измененный блок находится в кэше и не записан на диск, мы не можем повторно записывать соответствующий файл журнала повторного выполнения. Тут и вступает в игру процесс DBWn. Это фоновый процесс сервера Oracle, отвечающий за освобождение буферного кэша при заполнении и обработку контрольных точек. Обработка контрольной точки состоит в сбросе грязных (измененных) блоков из буферного кэша на диск. Сервер Oracle делает это автоматически, в фоновом режиме. Обработка контрольной точки может быть вызвана многими событиями, но чаще всего - переключением журнала повторного выполнения. При заполнении файла журнала 1, перед переходом на файл журнала 2, сервер Oracle инициирует обработку контрольной точки. В этот момент процесс DBWn начинает сбрасывать на диск все грязные блоки, защищенные файлом журнала I. Пока процесс DBWn не сбросит все блоки, защищаемые этим файлом, сервер Oracle не сможет его повторно использовать. Если попытаться использовать его прежде, чем процесс DBWn завершит обработку контрольной точки, в журнал сообщений (alert log) будет выдано следующее сообщение:
Thread 1 cannot allocate new log, sequence 66
Checkpoint not complete
Current log# 2 seq# 65 mem# 0: C:\ORACLE\ORADATA\TKYTE816\REDO02.LOG
Журнал сообщений - это файл на сервере, содержащий информационные сообщения сервера, например, о запуске и останове, а также уведомления об исключительных ситуациях, вроде незавершенной обработки контрольной точки. Итак, в момент выдачи этого сообщения обработка изменений была приостановлена до завершения процессом DBWn обработки контрольной точки. Для ускорения обработки сервер Oracle отдал все вычислительные мощности процессу DBWn. При соответствующей настройке сервера это сообщение в журнале появляться не должно. Если оно все же есть, значит, имеют место искусственные, ненужные ожидания, которых можно избежать. Цель (в большей степени администратора базы данных, чем разработчика) - иметь достаточно активных файлов журнала повторного выполнения. Это предотвратит попытки сервера использовать файл журнала, прежде чем будет закончена обработка контрольной точки. Если это сообщение выдается часто, значит, администратор базы данных не выделил для приложения достаточного количества активных журналов повторного выполнения или процесс DBWn не настроен, как следует.
Разные приложения генерируют различные объемы информации повторного выполнения. Системы класса СППР (системы поддержки принятия решений, выполняющие только запросы), естественно, будут генерировать намного меньше информации повторного выполнения, чем системы ООТ (системы оперативной обработки транзакций). Система, манипулирующая изображениями в больших двоичных объектах базы данных, может генерировать во много раз больше данных повторного выполнения, чем простая система ввода заказов. В системе ввода заказов со 100 пользователями генерируется в десять раз меньше данных повторного выполнения, чем в системе с 1000 пользователей. "Правильного" размера для журналов повторного выполнения нет, - он просто должен быть достаточным.
При определении размера и количества активных журналов повторного выполнения необходимо учитывать много факторов. Некоторые из них:
• Резервная база данных. Когда заполненные журналы повторного выполнения посылаются на другую машину и там применяются к копии текущей базы данных, необходимо много небольших файлов журнала. Это поможет уменьшить рассинхронизацию резервной базы данных с основной.
• Множество пользователей, изменяющих одни и те же блоки. Здесь могут понадобиться большие файлы журнала повторного выполнения. Поскольку все изменяют одни и те же блоки, желательно, чтобы до того как блоки будут сброшены на диск, было выполнено как можно больше изменений. Каждое переключение журнала инициирует обработку контрольной точки, так что желательно переключать журналы как можно реже. Это, однако, может замедлить восстановление.
• Среднее время восстановления. Если необходимо обеспечить максимально быстрое восстановление, придется использовать файлы журнала меньшего размера, даже если одни и те же блоки изменяются множеством пользователей. Один или два небольших файла журнала повторного выполнения будут обработаны при восстановлении намного быстрее, чем один гигантский. Система в целом будет работать медленнее, чем могла бы (из-за слишком частой обработки контрольных точек), но восстановление будет выполняться быстрее.
Архивный журнал повторного выполнения
База данных Oracle может работать в двух режимах - NOARCHIVELOG и ARCHIVELOG. Если база данных не работает в режиме ARCHIVELOG, данные рано или поздно будут потеряны. Работать в режиме NOARCHIVELOG можно только в среде разработки или тестирования. Эти режимы отличаются тем, что происходит с файлом журнала повторного выполнения до того как сервер Oracle его перепишет. Сохранять ли копию данных повторного выполнения или разрешить серверу Oracle переписать ее, потеряв при этом навсегда? - очень важный вопрос. Если не сохранить этот файл, мы не сможем восстановить данные с резервной копии до текущего момента. Предположим, резервное копирование выполняется раз в неделю, по субботам. В пятницу вечером, после того как за неделю было сгенерировано несколько сотен журналов повторного выполнения, происходит сбой диска. Если база данных не работала в режиме ARCHIVELOG, остается только два варианта дальнейших действий.
• Удалить табличное пространство/пространства, связанные со сбойным диском. Любое табличное пространство, имеющее файлы данных на этом диске, должно быть удалено, включая его содержимое. Если затронуто табличное пространство SYSTEM (словарь данных Oracle), этого сделать нельзя.
• Восстановить данные за субботу и потерять все изменения за неделю.
Оба варианта непривлекательны, поскольку приводят к потере данных. Работая же в режиме ARCHIVELOG, достаточно найти другой диск и восстановить на него соответствующие файлы с субботней резервной копии. Затем применить к ним архивные журналы повторного выполнения и, наконец, - активные журналы повторного выполнения (то есть повторить все накопленные за неделю транзакции в режиме быстрого наката). При этом ничего не теряется. Данные восстанавливаются на момент сбоя.
Управляющие файлы
Управляющий файл (control) - это сравнительно небольшой файл (в редких случаях он может увеличиваться до 64 Мбайт), содержащий информацию обо всех файлах, необходимых серверу Oracle. Из файла параметров инициализации (init. ora) экземпляр может узнать, где находятся управляющие файлы, а в управляющем файле описано местонахождение файлов данных и файлов журнала повторного выполнения. В управляющих файлах хранятся и другие необходимые серверу Oracle сведения, в частности время обработки контрольных точек, имя базы данных (которое должно совпадать со значением параметра инициализации db_name), дата и время создания базы данных, хронология архивирования журналов повторного выполнения (именно она приводит к увеличению размера управляющего файла в некоторых случаях) и т. д. Управляющие файлы надо мультиплексировать. Необходимо поддерживать несколько копий этих файлов, желательно на разных дисках, чтобы предотвратить потерю управляющих файлов в случае сбоя диска. Потеря управляющих файлов - не фатальное событие, она только существенно усложнит восстановление.
Временные файлы
Временные файлы данных в Oracle (temporary) - это специальный тип файлов данных. Сервер Oracle использует временные файлы для хранения промежуточных результатов сортировки большого объема данных или результирующих множеств, если для них не хватает оперативной памяти. Постоянные объекты данных, такие как таблицы или индексы, во временных файлах никогда не хранятся, в отличие от содержимого временных таблиц и построенных по ним индексов. Так что создать таблицы приложения во временном файле данных нельзя, а вот хранить в нем данные можно, если использовать временную таблицу.
Сервер Oracle обрабатывает временные файлы специальным образом. Обычно все изменения объектов записываются в журналы повторного выполнения. Эти журналы транзакций в дальнейшем можно использовать для повторного выполнения транзакций Это делается, например, при восстановлении после сбоя. Временные файлы в этом процессе не участвуют. Для них не генерируются данные повторного выполнения, хотя и генерируются данные отмены (UNDO) при работе с глобальными временными таблицами, чтобы можно было откатить изменения, сделанные в ходе сеанса. Создавать резервные копии временных файлов данных нет необходимости, а если кто-то это делает, то напрасно теряет время, поскольку данные во временном файле данных восстановить все равно нельзя.
Память
Основные структуры памяти сервера Oracle. Их три:
• SGA, System Global Area - глобальная область системы. Это большой совместно используемый сегмент памяти, к которому обращаются все процессы Oracle.
• PGA, Process Global Area - глобальная область процесса. Это приватная область памяти процесса или потока, недоступная другим процессам/потокам.
• UGA, User Global Area - глобальная область пользователя. Это область памяти, связанная с сеансом. Глобальная область памяти может находиться в SGA либо в PGA. Если сервер работает в режиме разделяемого сервера, она располагается в области SGA, если в режиме выделенного сервера, - в области PGA.
Области PGA и UGA
PGA - область памяти процесса. Эта область памяти используется одним процессом или одним потоком. Она недоступна ни одному из остальных процессов/потоков в системе. Область PGA никогда не входит в состав области SGA - она всегда локально выделяется процессом или потоком.
Область памяти UGA хранит состояние сеанса, поэтому всегда должна быть ему доступна. Местонахождение области UGA зависит исключительно от конфигурации сервера Oracle. Если сконфигурирован режим MTS, область UGA должна находиться в структуре памяти, доступной всем процессам, следовательно, в SGA. В этом случае сеанс сможет использовать любой разделяемый сервер, так как каждый из них сможет прочитать и записать данные сеанса. При подключении к выделенному серверу это требование общего доступа к информации о состоянии сеанса снимается, и область UGA становится почти синонимом PGA, - именно там информация о состоянии сеанса и будет располагаться. Просматривая статистическую информацию о системе, можно обнаружить, что при работе в режиме выделенного сервера область UGA входит в PGA (размер области PGA будет больше или равен размеру используемой памяти UGA - размер UGA будет учитываться при определении размера области PGA).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
