

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
I 7а + 22b = 710
22а + 80b = 2820
Решая ее, получим: а = - 5,79; b= 36,84.
Запишем уравнение регрессии:
ух = -5,79 + 36,84 x
Подставив в уравнение значения х, найдем теоретические значения у, (см. последнюю графу табл. 2.1)
В данном случае величина параметра а не имеет экономического смысла. В рассматриваемом примере имеем:
; sх =1,25;
. sy =46,29;
Оценку коэффициента регрессии можно получить проще, не обращаясь к методу наименьших квадратов. Альтернативную оценку параметра b можно найти исходя из содержания данного коэффициента: изменение результата
сопоставляют с изменением фактора
В нашем примере альтернативная оценка параметра b составит:
Эта величина является приближенной, ибо большая часть информации, имеющейся в данных, не используется при ее расчете. Она основана только на мини-максных значениях переменных.
Парная линейная регрессия используется в эконометрике нередко при изучении функции потребления:
C=Ky+L (2.25),
где С — потребление;
у - доход;
К и L - параметры функции.
Данное уравнение линейной регрессии используется обычно в увязке с балансовым равенством:
у = С+1-г, (2.26)
где I - размер инвестиций;
г — сбережения.
Для простоты предположим, что доход расходуется на потребление и инвестиции. Таким образом, рассматривается система уравнений
C=Ky+L
у=С+1 (2.27)
Наличие в данной системе балансового равенства накладывает ограничение на величину коэффициента регрессии, которая не может быть больше единицы, т. е. К£ 1. Предположим, что функция потребления составила:
C = 1,9 + 0,65у
Коэффициент регрессии характеризует склонность к потреблению. Он показывает, что из каждой тысячи дохода на потребление расходуется в среднем 650 руб., а 350 руб. инвестируются.
Если рассчитать регрессию размера инвестиций от дохода, т. е.
I=а + bу,
то уравнение регрессии составит:
I =1,9 + 0,35у.
Это уравнение можно и не определять, ибо оно выводится из функции потребления. Коэффициенты регрессии этих двух уравнений связаны равенством: 0,65 +0,35 =1.
Если коэффициент регрессии оказывается больше 1, то у <(С+1), т. е. на потребление расходуются не только доходы, но и сбережения.
Коэффициент регрессии в функции потребления используется для расчета мультипликатора:
(2.28)
где т — мультипликатор;
b - коэффициент регрессии в функции потребления.
В нашем примере
т = 1/(1— 0,65)=2,86.
Это означает, что дополнительные вложения в размере 1 тыс. руб. на длительный срок приведут при прочих равных условиях к дополнительному доходу в 2,86 тыс. руб.
Уравнение регрессии всегда дополняется показателем тесноты связи. При использовании линейной регрессии в качестве такого показателя выступает линейный коэффициент корреляции гп,. Существуют разные модификации формулы линейного коэффициента
корреляции. Некоторые из них приведены ниже:
(2.29)
Как известно, линейный коэффициент корреляции находится в границах: –1 < rxv < 1.
Если коэффициент регрессии b > 0, то 0 ≤ rxv ≤ 1, и, наоборот, при b < 0, –1 ≤ rrv ≤ 0. По данным табл. 2.1 величина линейного коэффициента корреляции составила 0,991, что достаточно близко к 1 и означает наличие очень тесной зависимости затрат на производство от величины объема выпущенной продукции.
Следует иметь в виду, что величина линейного коэффициента корреляции оценивает тесноту связи рассматриваемых признаков в ее линейной форме. Поэтому близость абсолютной величины линейного коэффициента корреляции к нулю еще не означает отсутствие связи между признаками. При иной спецификации модели связь между признаками может оказаться достаточно тесной. Для оценки качества подбора линейной функции рассчитывается квадрат линейного коэффициента корреляции ![]() , называемый коэффициентом детерминации. Коэффициент детерминации характеризует долю дисперсии результативного признака у, объясняемую регрессией, в общей дисперсии результативного признака:
, называемый коэффициентом детерминации. Коэффициент детерминации характеризует долю дисперсии результативного признака у, объясняемую регрессией, в общей дисперсии результативного признака:
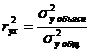 . (2.30)
. (2.30)
Соответственно величина 1 – r2 характеризует долю дисперсии у, вызванную влиянием остальных не учтенных в модели факторов.
В нашем примере r2 = 0,982. Следовательно, уравнением регрессии объясняется 98,2% дисперсии результативного признака, а на долю прочих факторов приходится лишь 1,8% ее дисперсии (т. е. остаточная дисперсия). Величина коэффициента детерминации служит одним из критериев оценки качества линейной модели. Чем больше доля объясненной вариации, тем соответственно меньше роль прочих факторов, и, следовательно, линейная модель хорошо аппроксимирует исходные данные и ею можно воспользоваться для прогноза значений результативного признака. Так, полагая, что объем продукции предприятия может составить 5 тыс. ед., прогнозное значение для издержек производства окажется 178,4 тыс. руб.
2.3. Оценка существенности параметров линейной регрессии и корреляции
После того как найдено уравнение линейной регрессии, проводится оценка значимости как уравнения в целом, так и отдельных его параметров.
Оценка значимости уравнения регрессии в целом дается с помощью F-критерия Фишера. При этом выдвигается нулевая гипотеза, что коэффициент регрессии равен нулю, т. е. b = 0, и, следовательно, фактор х не оказывает влияния на результат у.
Непосредственному расчету F-критерия предшествует анализ дисперсии. Центральное место в нем занимает разложение общей суммы квадратов отклонений переменной у от среднего значения у на две части — «объясненную» и «необъясненную»:
| = |
| + |
|
Общая сумма квадратов отклонений | = | Сумма квадратов отклонений объясненная регрессией | + | Остаточная сумма квадратов отклонений |
Общая сумма квадратов отклонений индивидуальных значений результативного признака у от среднего значения ![]() вызвана влиянием множества причин. Условно разделим всю совокупность причин на две группы: изучаемый фактор х и прочие факторы. Если фактор не оказывает влияния на результат, то линия регрессии на графике параллельна оси Oх и
вызвана влиянием множества причин. Условно разделим всю совокупность причин на две группы: изучаемый фактор х и прочие факторы. Если фактор не оказывает влияния на результат, то линия регрессии на графике параллельна оси Oх и ![]() . Тогда вся дисперсия результативного признака обусловлена воздействием прочих факторов и общая сумма квадратов отклонений совпадет с остаточной. Если же прочие факторы не влияют на результат, то у связан с х функционально и остаточная сумма квадратов равна нулю. В этом случае сумма квадратов отклонений, объясненная регрессией, совпадает с общей суммой квадратов.
. Тогда вся дисперсия результативного признака обусловлена воздействием прочих факторов и общая сумма квадратов отклонений совпадет с остаточной. Если же прочие факторы не влияют на результат, то у связан с х функционально и остаточная сумма квадратов равна нулю. В этом случае сумма квадратов отклонений, объясненная регрессией, совпадает с общей суммой квадратов.
Поскольку не все точки поля корреляции лежат на линии регрессии, то всегда имеет место их разброс как обусловленный влиянием фактора х, т. е. регрессией у по х, так и вызванный действием прочих причин (необъясненная вариация). Пригодность линии регрессии для прогноза зависит от того, какая часть, общей вариации признака у приходится на объясненную вариацию. Очевидно, что если сумма квадратов отклонений, обусловленная регрессией, будет больше остаточной суммы квадратов, то уравнение регрессии статистически значимо и фактор х оказывает существенное воздействие на результат у. Это равносильно тому, что коэффициент детерминации ![]() будет приближаться к единице.
будет приближаться к единице.
Любая сумма квадратов отклонений связана с числом степеней свободы (df— degrees of freedom), т. е. с числом свободы независимого варьирования признака. Число степеней свободы связано с числом единиц совокупности n и с числом определяемых по ней констант. Применительно к исследуемой проблеме число степеней свободы должно показать, сколько независимых отклонений из п возможных 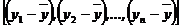 требуется для образования данной суммы квадратов. Так, для общей суммы квадратов
требуется для образования данной суммы квадратов. Так, для общей суммы квадратов 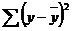 требуется (п – 1) независимых отклонений, ибо по совокупности из п единиц после расчета среднего уровня свободно варьируют лишь (п — 1) число отклонений. Например, имеем ряд значений у: 1, 2, 3, 4, 5. Среднее из них равно 3, и тогда п отклонений от среднего составят: –2; –1; 0; 1; 2. Так как
требуется (п – 1) независимых отклонений, ибо по совокупности из п единиц после расчета среднего уровня свободно варьируют лишь (п — 1) число отклонений. Например, имеем ряд значений у: 1, 2, 3, 4, 5. Среднее из них равно 3, и тогда п отклонений от среднего составят: –2; –1; 0; 1; 2. Так как 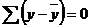 , то свободно варьируют лишь четыре отклонения, а пятое отклонение может быть определено, если предыдущие четыре известны.
, то свободно варьируют лишь четыре отклонения, а пятое отклонение может быть определено, если предыдущие четыре известны.
При расчете объясненной или факторной суммы квадратов ![]() используются теоретические (расчетные) значения результативного признака
используются теоретические (расчетные) значения результативного признака ![]() , найденные по линии регрессии:
, найденные по линии регрессии:
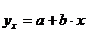 .
.
В линейной регрессии 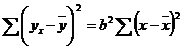 . В этом нетрудно убедиться, обратившись к формуле линейного коэффициента корреляции:
. В этом нетрудно убедиться, обратившись к формуле линейного коэффициента корреляции:
![]() или
или 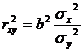
где ![]() — общая дисперсия признака у;
— общая дисперсия признака у;
 — дисперсия признака у, обусловленная фактором х.
— дисперсия признака у, обусловленная фактором х.
Соответственно сумма квадратов отклонений, обусловленных линейной регрессией, составит:
![]() . (2.31)
. (2.31)
Поскольку при заданном объеме наблюдений по х и у факторная сумма квадратов при линейной регрессии зависит только от одной константы коэффициента регрессии b, то данная сумма квадратов имеет одну степень свободы. К этому же выводу придем, если рассмотрим содержательную сторону расчетного значения признака у, т. е. ![]() . Величина
. Величина ![]() определяется по уравнению линейной регрессии:
определяется по уравнению линейной регрессии: ![]() . Параметр а можно определить как
. Параметр а можно определить как 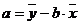 . Подставив выражение параметра а в линейную модель, получим:
. Подставив выражение параметра а в линейную модель, получим:
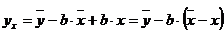 . (2.32)
. (2.32)
Отсюда видно, что при заданном наборе переменных у и х расчетное значение ![]() является в линейной регрессий функцией только одного параметра — коэффициента регрессии. Соответственно и факторная сумма квадратов отклонений имеет число степеней свободы, равное 1.
является в линейной регрессий функцией только одного параметра — коэффициента регрессии. Соответственно и факторная сумма квадратов отклонений имеет число степеней свободы, равное 1.
Существует равенство между числом степеней свободы общей, факторной и остаточной суммами квадратов. Число степеней свободы остаточной суммы квадратов при линейной регрессии составляет п – 2. Число степеней свободы для общей суммы квадратов определяется числом единиц, и поскольку мы используем среднюю вычисленную по данным выборки, то теряем одну степень свободы, т. е. dfобщ = п – 1.
Итак, имеем два равенства:
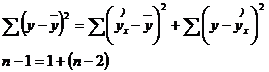 (2.33)
(2.33)
Разделив каждую сумму квадратов на соответствующее ей число степеней свободы, получим средний квадрат отклонений, или, что то же самое, дисперсию на одну степень свободы D.
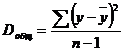 , (2.34)
, (2.34)
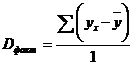 , (2.35)
, (2.35)
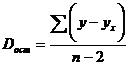 . (2.36)
. (2.36)
Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину F-отношения (F-критерий):
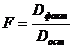 , (2.37)
, (2.37)
где F – критерий для проверки нулевой гипотезы H0: Dфакт = Dоcm.
Если нулевая гипотеза справедлива, то факторная и остаточная дисперсии не отличаются друг от друга. Для Н0 необходимо опровержение, чтобы факторная дисперсия превышала остаточную в несколько раз. Английским статистиком Снедекором разработаны таблицы критических значений F-отношений при разных уровнях существенности нулевой гипотезы и различном числе степеней свободы. Табличное значение F-критерия — это максимальная величина отношения дисперсий, которая может иметь место при случайном их расхождении для данного уровня вероятности наличия нулевой гипотезы. Вычисленное значение F-отношения признается достоверным (отличным от единицы), если оно больше табличного. В этом случае нулевая гипотеза об отсутствии связи признаков отклоняется и делается вывод о существенности этой связи: Fфакт > Fтабл — Н0 отклоняется.
Если же величина окажется меньше табличной Fфакт < Fтабл, то вероятность нулевой гипотезы выше заданного уровня (например, 0,05) и она не может быть отклонена без серьезного риска сделать неправильный вывод о наличии связи. В этом случае уравнение регрессии считается статистически незначимым. Н0 не отклоняется.
В рассматриваемом примере:
![]() – общая сумма квадратов;
– общая сумма квадратов;
![]() – факторная сумма квадратов;
– факторная сумма квадратов;
![]() – остаточная сумма квадратов;
– остаточная сумма квадратов;
Dфакт = 14735;
Docmam = 265/5 = 53;
F = 14735/53 = 278;
Fa=0,05 = 6,61; Fa=0,01 = 16,26.
Поскольку Fфакт > Fтабл как при 1%-ном, так и при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
Величина F-критерия связана с коэффициентом детерминации r2. Факторную сумму квадратов отклонений можно представить как
![]() , (2.38)
, (2.38)
а остаточную сумму квадратов — как
![]() . (2.39)
. (2.39)
Тогда значение F-критерия можно выразить как
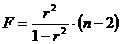 . (2.40)
. (2.40)
В нашем примере r = 0,982. Тогда ![]() (некоторое несовпадение с предыдущим результатом объясняется ошибками округления).
(некоторое несовпадение с предыдущим результатом объясняется ошибками округления).
Оценка значимости уравнения регрессии обычно дается в виде таблицы дисперсионного анализа (табл. 2.2).
Таблица 2.2
Дисперсионный анализ результатов регрессии
Источники вариации | Число степеней свободы | Сумма квадратов отклонений | Дисперсия на одну степень свободы | F-отношение | |
фактическое | табличное при а=0,05 | ||||
Общая | 6 | 15000 | — | — | — |
Объясненная | 1 | 14735 | 14735 | 278 | 6,61 |
Остаточная | 5 | 265 | 53 | 1 | — |
В линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных его параметров. С этой целью по каждому из параметров определяется его стандартная ошибка: тb и та.
Стандартная ошибка коэффициента регрессии определяется по формуле
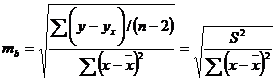 , (2.41)
, (2.41)
где S2 – остаточная дисперсия на одну степень свободы.
Для нашего примера величина стандартной ошибки коэффициента регрессии составила:
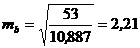 .
.
Величина стандартной ошибки совместно с t-распределением Стьюдента при (n – 2) степенях свободы применяется для проверки существенности коэффициента регрессии и для расчета его доверительных интервалов.
Для оценки существенности коэффициента регрессии его величина сравнивается с его стандартной ошибкой, т. е. определятся фактическое значение t-критерия Стьюдента: ![]() – которое затем сравнивается с табличным значением при определенном уровне значимости а и числе степеней свободы (n – 2).
– которое затем сравнивается с табличным значением при определенном уровне значимости а и числе степеней свободы (n – 2).
В рассматриваемом примере фактическое значение t-критерия для коэффициента регрессии составило:
![]() .
.
Этот же результат получим, извлекая квадратный корень из найденного ранее F-критерия, т. е.
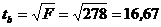
Покажем справедливость равенства tb = F :
При а = 0,05 (для двустороннего критерия) и числе степеней свободы 5 табличное значение tb = 2,57. Так как фактическое значение t-критерия превышает табличное, то, следовательно, гипотезу о несущественности коэффициента регрессии можно отклонить. Доверительный интервал для коэффициента регрессии определяется как ![]() . Для коэффициента регрессии b в примере 95 %-ные границы составят:
. Для коэффициента регрессии b в примере 95 %-ные границы составят:
36,84 ± 2,57 2,21 = 36,84 ± 5,68,
т. е.
31,16 ≤ b ≤ 42,52.
Поскольку коэффициент регрессии в эконометрических исследованиях имеет четкую экономическую интерпретацию, то доверительные границы интервала для коэффициента регрессии не должны содержать противоречивых результатов, например, –10 ≤ b ≤ 40. Такого рода запись указывает, что истинное значение коэффициента регрессии одновременно содержит положительные и отрицательные величины и даже ноль, чего не может быть.
Стандартная ошибка параметра а определяется по формуле:
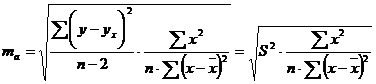 . (2.42)
. (2.42)
Процедура оценивания существенности данного параметра не отличается от рассмотренной выше для коэффициента регрессии; вычисляется t-критерий:
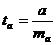 , (2.43)
, (2.43)
его величина сравнивается с табличным значением при df = п – 2 степенях свободы.
Значимость линейного коэффициента корреляции проверяется на основе величины ошибки коэффициента корреляции тr:
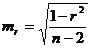 . (2.44)
. (2.44)
Фактическое значение t-критерия Стьюдента определяется как
![]() . (2.45)
. (2.45)
Данная формула свидетельствует, что в парной линейной регрессии ![]() , ибо, как уже указывалось, . Кроме того,
, ибо, как уже указывалось, . Кроме того, ![]() . Следовательно,
. Следовательно, ![]() .
.
Таким образом, проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
В рассматриваемом примере tr не совпало с tb в результате ошибок округлений. Величина ![]() значительно превышает табличное значение 2,57 при а = 0,05. Следовательно, коэффициент корреляции существенно отличен от нуля и зависимость является достоверной.
значительно превышает табличное значение 2,57 при а = 0,05. Следовательно, коэффициент корреляции существенно отличен от нуля и зависимость является достоверной.
Рассмотренная формула оценки коэффициента корреляции рекомендуется к применению при большом числе наблюдений и если r не близко к +1 или -1. Если же величина коэффициента корреляции близка к +1, то распределение его оценок отличается от нормального или распределения Стьюдента, так как величина коэффициента корреляции ограничена значениями от -1 до +1. Чтобы обойти это затруднение, Р. Фишером было предложено для оценки существенности r ввести вспомогательную величину z, связанную с коэффициентом корреляции следующим отношением:
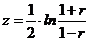 . (2.46)
. (2.46)
При изменении r от –1 до +1 величина z изменяется от –∞ до +∞, что соответствует нормальному распределению. Математический анализ доказывает, что распределение величины z мало отличается от нормального даже при близких к единице значениях коэффициента корреляции. Стандартная ошибка величины z определяется по формуле:
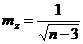 , (2.47)
, (2.47)
где п — число наблюдений.
При r = 0,991, 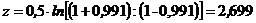 , а
, а 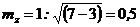 . Величину z можно не рассчитывать, а воспользоваться готовыми таблицами z-преобразования. в которых приведены значения величины z для соответствующих значений r.
. Величину z можно не рассчитывать, а воспользоваться готовыми таблицами z-преобразования. в которых приведены значения величины z для соответствующих значений r.
Далее выдвигаем нулевую гипотезу Н0, которая состоит в том, что корреляция отсутствует, т. е. теоретическое значение коэффициента корреляции равно нулю. Коэффициент корреляции z значимо отличен от нуля, если
![]() (2.48)
(2.48)
т. е. если фактическое значение tz превышает его табличное значение на уровне значимости а = 0,05 или а = 0,01.
Иными словами, если ![]() , то коэффициент корреляции значимо отличен от нуля, что имеет место в рассмотренном примере:
, то коэффициент корреляции значимо отличен от нуля, что имеет место в рассмотренном примере:
при ta=0,05 = 2,57.
Ввиду того, что r и z связаны между собой приведенным выше соотношением, можно вычислить критические значения r, соответствующие каждому из значений z. Таблицы критических значений r разработаны для уровней значимости 0,05 и 0,01 и соответствующего числа степеней свободы. Критические значения r предполагают справедливость нулевой гипотезы, т. е. r мало отлично от нуля. Если фактическое значение коэффициента корреляции по абсолютной величине превышает табличное, то данное значение r считается существенным. Если же r оказывается меньше табличного, то фактическое значение r несущественно.
В рассматриваемом примере при числе степеней свободы п – 2 = 5 критическое значение r при а = 0,05 составляет 0,754, а при а= 0,01 составляет 0,874, что ниже фактической величины rху = 0,991. Следовательно, как было уже доказано, полученное значение r существенно отлично от нуля.
2.4. Интервалы прогноза по линейному уравнению регрессии
В прогнозных расчетах по уравнению регрессии определяется предсказываемое (ур) значение как точечный прогноз ![]() при xp = xk, т. е. путем подстановки в уравнение регрессии соответствующего значения х. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки ух т. е.
при xp = xk, т. е. путем подстановки в уравнение регрессии соответствующего значения х. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки ух т. е. ![]() , и соответственно интервальной оценкой прогнозного значения (у*)
, и соответственно интервальной оценкой прогнозного значения (у*)
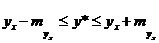 (2.49)
(2.49)
Чтобы понять, как строится формула для определения величин стандартной ошибки ![]() обратимся к уравнению линейной регрессии:
обратимся к уравнению линейной регрессии: ![]() . Подставим в это уравнение выражение параметра а:
. Подставим в это уравнение выражение параметра а:
, (2.50)
тогда уравнение регрессии примет вид
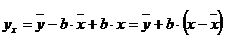 . (2.51)
. (2.51)
Отсюда вытекает, что стандартная ошибка ![]() зависит от ошибки
зависит от ошибки ![]() и ошибки коэффициента регрессии b, т. е.
и ошибки коэффициента регрессии b, т. е.
![]() . (2.52)
. (2.52)
Из теории выборки известно, что 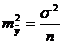 . Используя в качестве оценки
. Используя в качестве оценки ![]() остаточную дисперсию на одну степень свободы S2, получим формулу расчета ошибки среднего значения переменной у.
остаточную дисперсию на одну степень свободы S2, получим формулу расчета ошибки среднего значения переменной у.
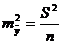 (2.53)
(2.53)
Ошибка коэффициента регрессии, как уже было показано, определяется формулой
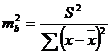 . (2.54)
. (2.54)
Считая, что прогнозное значение фактора хр = xk, получим следующую формулу расчета стандартной ошибки предсказываемого по линии регрессии значения, т. е. ![]() :
:
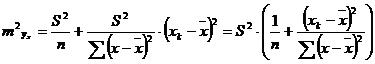 (2.55)
(2.55)
Соответственно ![]() имеет выражение:
имеет выражение:
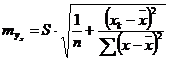 . (2.56)
. (2.56)
Рассмотренная формула стандартной ошибки предсказываемого среднего значения у при заданном значении хk характеризует ошибку положения линии регрессии. Величина стандартной ошибки ![]() , как видно из формулы, достигает минимума при
, как видно из формулы, достигает минимума при ![]() , и возрастает по мере того, как «удаляется» от
, и возрастает по мере того, как «удаляется» от ![]() в любом направлении. Иными словами, чем больше разность между xk и х, тем больше ошибка
в любом направлении. Иными словами, чем больше разность между xk и х, тем больше ошибка ![]() , с которой предсказывается среднее значение у для заданного значения xk. Можно ожидать наилучшие результаты прогноза, если признак-фактор х находится в центре области наблюдений х и нельзя ожидать хороших результатов прогноза при удалении xk от
, с которой предсказывается среднее значение у для заданного значения xk. Можно ожидать наилучшие результаты прогноза, если признак-фактор х находится в центре области наблюдений х и нельзя ожидать хороших результатов прогноза при удалении xk от ![]() . Если же значение xk оказывается за пределами наблюдаемых значений х, используемых при построении линейной регрессии, то результаты прогноза ухудшаются в зависимости от того, насколько xk отклоняется от области наблюдаемых значений фактора х.
. Если же значение xk оказывается за пределами наблюдаемых значений х, используемых при построении линейной регрессии, то результаты прогноза ухудшаются в зависимости от того, насколько xk отклоняется от области наблюдаемых значений фактора х.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
