

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Для нашего примера ![]() составит:
составит:
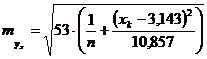 .
.
При ![]()
![]() .
.
При xk = 4
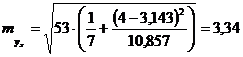 .
.
Соответственно ![]() составит эту же величину и при хk = 2,286. Для прогнозируемого значения
составит эту же величину и при хk = 2,286. Для прогнозируемого значения ![]() 95%-ные доверительные интервалы при заданном хk определяются выражением
95%-ные доверительные интервалы при заданном хk определяются выражением
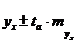 (2.57)
(2.57)
т. е. ![]() или
или ![]() .
.
При хk. = 4, прогнозное значение у составит:
![]() ,
,
которое представляет собой точечный прогноз. Прогноз линии регрессии в интервале составит:
132,99 ≤ ![]() ≤ 150,15.
≤ 150,15.
На графике доверительные границы для ![]() представляют собой гиперболы, расположенные по обе стороны от линии регрессии (рис. 2.3).
представляют собой гиперболы, расположенные по обе стороны от линии регрессии (рис. 2.3).
Рис. 2.3 показывает, как изменяются пределы в зависимости от изменения хk: две гиперболы по обе стороны от линии регрессии определяют 95 %-ные доверительные интервалы для среднего значения у при заданном значении х.
Однако фактические значения у варьируют около среднего значения ![]() . Индивидуальные значения у могут отклоняться от
. Индивидуальные значения у могут отклоняться от ![]() на величину случайной ошибки ε, дисперсия которой оценивается как остаточная дисперсия на одну степень свободы S2. Поэтому ошибка предсказываемого индивидуального значения у должна включать не только стандартную ошибку
на величину случайной ошибки ε, дисперсия которой оценивается как остаточная дисперсия на одну степень свободы S2. Поэтому ошибка предсказываемого индивидуального значения у должна включать не только стандартную ошибку ![]() , но и случайную ошибку S.
, но и случайную ошибку S.
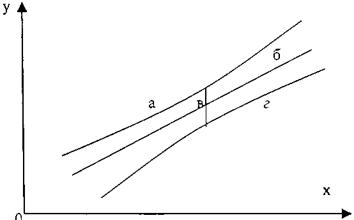
Рис. 2.3. Доверительный интервал линии регрессии:
а - верхняя доверительная граница; б - линия регрессии;
в - доверительный интервал для ![]() при хk;
при хk;
г — нижняя доверительная граница
Средняя ошибка прогнозируемого индивидуального значения у - ![]() составит:
составит:
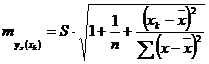 . (2.57)
. (2.57)
По данным рассматриваемого примера получим:
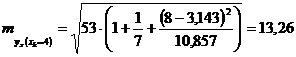 .
.
Доверительные интервалы прогноза индивидуальных значений у при xk = 4 с вероятностью 0,95 составят: 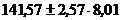 , или 141,57 ±20,59, это означает, что 120,98 ≤ yр ≤ 162,1б.
, или 141,57 ±20,59, это означает, что 120,98 ≤ yр ≤ 162,1б.
Интервал достаточно широк, прежде всего, за счет малого объема наблюдений.
При прогнозировании на основе уравнения регрессии следует помнить, что величина прогноза зависит не только от стандартной ошибки индивидуального значения у, но и от точности прогноза значения фактора х. Его величина может задаваться на основе анализа других моделей исходя из конкретной ситуации, а также из анализа динамики данного фактора.
Рассмотренная формула средней ошибки индивидуального значения признака у(![]() ) может быть использована также для оценки существенности различия предсказываемого значения исходя из регрессионной модели и выдвинутой гипотезы развития событий.
) может быть использована также для оценки существенности различия предсказываемого значения исходя из регрессионной модели и выдвинутой гипотезы развития событий.
Предположим, что в нашем примере с функцией издержек выдвигается предположение, что в предстоящем году в связи со стабилизацией экономики при выпуске продукции в 8 тыс. ед. затраты на производство не превысят 250 млн. руб. Означает ли это действительно изменение найденной закономерности или же данная величина затрат соответствует регрессионной модели?
Чтобы ответить на этот вопрос, найдем точечный прогноз при х = 8, т. е.
![]() .
.
Предполагаемое же значение затрат, исходя из экономической ситуации, – 250,0. Для оценки существенности различия этих величин определим среднюю ошибку прогнозируемого индивидуального значения:
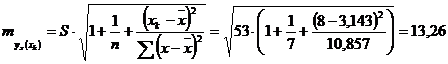 .
.
Сравним ее с величиной предполагаемого снижения издержек производства, т. е. 38,93:
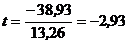 .
.
Поскольку оценивается значимость только уменьшения затрат, то используется односторонний t-критерий Стьюдента. При ошибке в 5% с пятью степенями свободы tтабл=2,015. Следовательно, предполагаемое уменьшение затрат значимо отличается от прогнозируемого по модели при 95%-ном уровне доверия. Однако если увеличить вероятность до 99%, при ошибке в 1% фактическое значение t-критерия оказывается ниже табличного 3,365, и рассматриваемое различие в величине затрат статистически не значимо.
3. СРЕДНЯЯ ОШИБКА АППРОКСИМАЦИИ
Фактические значения результативного признака отличаются от теоретических, рассчитанных по уравнению регрессии, т. е. у и ![]() . Чем меньше это отличие, тем ближе теоретические значения подходят к эмпирическим данным, лучше качество модели. Величина отклонений фактических и расчетных значений результативного признака (у -
. Чем меньше это отличие, тем ближе теоретические значения подходят к эмпирическим данным, лучше качество модели. Величина отклонений фактических и расчетных значений результативного признака (у - ![]() ) по каждому наблюдению представляет собой ошибку аппроксимации. Их число соответствует объему совокупности. В отдельных случаях ошибка аппроксимации может оказаться равной нулю. Отклонения (у –
) по каждому наблюдению представляет собой ошибку аппроксимации. Их число соответствует объему совокупности. В отдельных случаях ошибка аппроксимации может оказаться равной нулю. Отклонения (у – ![]() ) несравнимы между собой, исключая величину, равную нулю. Так, если для одного наблюдения (у –
) несравнимы между собой, исключая величину, равную нулю. Так, если для одного наблюдения (у – ![]() ) = 5, а для другого она равна 10, то это не означает, что во втором случае модель дает вдвое худший результат. Для сравнения используются величины отклонений, выраженные в процентах к фактическим значениям. Так, если для первого наблюдения у = 20, а для второго у = 50, ошибка аппроксимации составит 25% для первого наблюдения и 20% — для второго.
) = 5, а для другого она равна 10, то это не означает, что во втором случае модель дает вдвое худший результат. Для сравнения используются величины отклонений, выраженные в процентах к фактическим значениям. Так, если для первого наблюдения у = 20, а для второго у = 50, ошибка аппроксимации составит 25% для первого наблюдения и 20% — для второго.
Поскольку (у – ![]() ) может быть как величиной положительной, так и отрицательной, то ошибки аппроксимации для каждого наблюдения принято определять в процентах по модулю.
) может быть как величиной положительной, так и отрицательной, то ошибки аппроксимации для каждого наблюдения принято определять в процентах по модулю.
Отклонения (у – ![]() ) можно рассматривать как абсолютную ошибку аппроксимации, а
) можно рассматривать как абсолютную ошибку аппроксимации, а
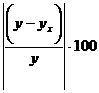
— как относительную ошибку аппроксимации. Чтобы иметь общее суждение о качестве модели из относительных отклонений по каждому наблюдению, определяют среднюю ошибку аппроксимации как среднюю арифметическую простую:
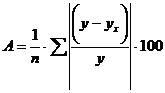 . (3.1)
. (3.1)
Представим расчет средней ошибки аппроксимации для уравнения 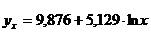 в табл. 2.7.
в табл. 2.7. ![]() , что говорит о хорошем качестве уравнения регрессии, ибо ошибка аппроксимации в пределах 5-7% свидетельствует о хорошем подборе модели к исходным данным.
, что говорит о хорошем качестве уравнения регрессии, ибо ошибка аппроксимации в пределах 5-7% свидетельствует о хорошем подборе модели к исходным данным.
Таблица 3.1
Расчет средней ошибки аппроксимации
y |
| у – |
|
10,0 | 9,9 | 0,1 | 1,0 |
13,4 | 13,4 | 0,0 | 0,0 |
15,4 | 15,5 | –0,1 | 0,6 |
16,5 | 17,0 | –0,5 | 3,0 |
18,6 | 18,1 | 0,5 | 2,7 |
19,1 | 19,1 | 0,0 | 0,0 |
Итого 93,0 | 93,0 | 0 | 7,3 |
Возможно и иное определение средней ошибки аппроксимации:
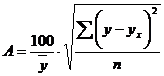 . (3.2)
. (3.2)
Для нашего примера эта величина составит
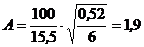 .
.
В стандартных программах чаще используется первая формула для расчета средней ошибки аппроксимации.
4. ПРИМЕР ВЫБОРА СПЕЦИФИКАЦИИ ЭКОНОМЕТРИЧЕСКОЙ МОДЕЛИ (МЕТОД ПАРНОЙ РЕГРЕССИИ, И ОЦЕНКА ЕЕ ПАРАМЕТРОВ)
По некоторым территориям районов Приморского края известны значения средней суточного душевого дохода в у. е. (фактор X) и процент от общего дохода, расходуемого на покупку продовольственных товаров (фактор Y), табл. 4.1. Требуется для характеристики зависимости У от X рассчитать параметры линейной, степенной, показательной функции и выбрать оптимальную модель (провести оценку моделей через среднюю ошибку аппроксимации (А) и F - критерий Фишера.
Таблица 4.1.
Район | фактор Y | фактор X |
Пожарский (1) | 68,8 | 45,1 |
Кавалеровский (2) | 61,2 | 59,0 |
Дальнегорский (3) | 59,9 | 57,2 |
Хасанский (4) | 56,7 | 61,8 |
Лесозаводский (5) | 55,0 | 58,8 |
Хорольский (6) | 54,3 | 47,2 |
Анучинский (7) | 49,3 | 55,2 |
Решение.
1а. Для расчета параметров а и b линейной регрессии ![]() [1] решаем систему нормальных уравнений относительно а и b:
[1] решаем систему нормальных уравнений относительно а и b:
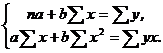
По исходным данным рассчитываем ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() :
:
Таблица 4.2.
y | х | ух | х2 | у2 |
| у – | Аi | |
1 | 68,8 | 45,1 | 3102,88 | 2034,01 | 4733,44 | 61,3 | 7,5 | 10.9 |
2 | 61,2 | 59,0 | 3610,80 | 3481,00 | 3745,44 | 56,5 | 4,7 | 7,7 |
3 | 59,9 | 57,2 | 3426,28 | 3271,84 | 3588,01 | 57,1 | 2,8 | 4,7 |
4 | 56,7 | 61,8 | 3504,06 | 3819,24 | 3214,89 | 55,5 | 1,2 | 2,1 |
5 | 55,0 | 58,8 | 3234,00 | 3457,44 | 3025,00 | 56,5 | -1,5 | 2,7 |
6 | 54,3 | 47,2 | 2562,96 | 2227,84 | 2948,49 | 60,5 | -6,2 | 11,4 |
7 | 49,3 | 55,2 | 2721,36 | 3047,04 | 2430,49 | 57,8 | -8,5 | 17,2 |
Итого | 405,2 | 384,3 | 22162,34 | 21338,41 | 23685,76 | 405,2 | 0,0 | 56,7 |
Ср. знач. (Итого/n) | 57,89
| 54,90
| 3166,05
| 3048,34
| 3383,68
| X | X | 8,1 |
| 5,74 | 5,86 | X | X | Х | X | X | X |
| 32,92 | 34,34 | X | X | Х | X | X | X |
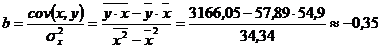 ,
,

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
