
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
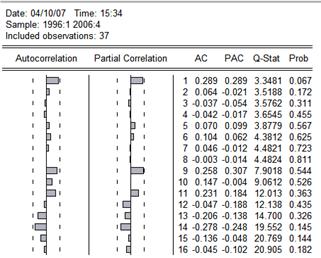
По данной кореллограмме видно, что функция ACF(k)=0 и РACF(k)=0 при любых k. Следовательно, это белый шум МА(0) - случайный процесс и моделировать его бесполезно.
Ряд 5й. Нарастающим итогом к соответств. периоду предыдущего года. В 1й лабораторной было выяснено, что этот ряд – интегрирован нулевого порядка – TS ряд. Причем тренд не является значимым, а значима константа.
ADF Test Statistic | -3.286397 | 1% Critical Value* | -3.6228 | |
5% Critical Value | -2.9446 | |||
10% Critical Value | -2.6105 | |||
*MacKinnon critical values for rejection of hypothesis of a unit root. | ||||
Augmented Dickey-Fuller Test Equation | ||||
Dependent Variable: D(SER05) | ||||
Method: Least Squares | ||||
Date: 04/09/07 Time: 20:56 | ||||
Sample(adjusted): 1997:2 2006:1 | ||||
Included observations: 36 after adjusting endpoints | ||||
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
SER05(-1) | -0.479451 | 0.145890 | -3.286397 | 0.0024 |
C | 0.560100 | 0.180383 | 3.105060 | 0.0038 |
R-squared | 0.241078 | Mean dependent var | 0.006555 | |
Adjusted R-squared | 0.218757 | S. D. dependent var | 0.438226 | |
S. E. of regression | 0.387339 | Akaike info criterion | 0.994921 | |
Sum squared resid | 5.101077 | Schwarz criterion | 1.082894 | |
Log likelihood | -15.90858 | F-statistic | 10.80041 | |
Durbin-Watson stat | 2.037501 | Prob(F-statistic) | 0.002361 |
Строим коррелограмму.
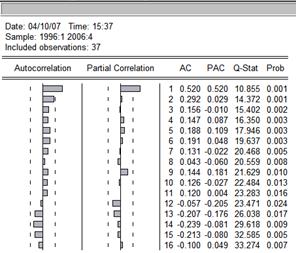
По данной кореллограмме видно, что функция Р(1)![]() 0, а далее при всех остальных k>1 P(k) экспоненциально убывает, а Рpart(1)=Р(1) и далее при любых k>1 экспоненциально убывает. Следовательно, скорее всего это соответствует модели ARMA (1,1).
0, а далее при всех остальных k>1 P(k) экспоненциально убывает, а Рpart(1)=Р(1) и далее при любых k>1 экспоненциально убывает. Следовательно, скорее всего это соответствует модели ARMA (1,1).
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
C | 0.019480 | 0.011115 | 1.752570 | 0.0893 |
AR(1) | 0.359052 | 0.171202 | 2.097246 | 0.0440 |
MA(1) | -0.957839 | 0.040022 | -23.93303 | 0.0000 |
R-squared | 0.280425 | Mean dependent var | 0.010490 | |
Adjusted R-squared | 0.235451 | S. D. dependent var | 0.443978 | |
S. E. of regression | 0.388208 | Akaike info criterion | 1.027264 | |
Sum squared resid | 4.822567 | Schwarz criterion | 1.160579 | |
Log likelihood | -14.97712 | F-statistic | 6.235341 | |
Durbin-Watson stat | 1.910735 | Prob(F-statistic) | 0.005167 | |
Inverted AR Roots | .36 | |||
Inverted MA Roots | .96 |
По полученным результатам делаем вывод о том, что константа не значима (Prob >0.05). Следовательно, данную переменную из модели необходимо удалить. Новая модель выглядит следующим образом:
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
AR(1) | 0.489783 | 0.191505 | 2.557552 | 0.0153 |
MA(1) | -0.965416 | 0.080679 | -11.96615 | 0.0000 |
R-squared | 0.225216 | Mean dependent var | 0.010490 | |
Adjusted R-squared | 0.201737 | S. D. dependent var | 0.443978 | |
S. E. of regression | 0.396675 | Akaike info criterion | 1.044045 | |
Sum squared resid | 5.192576 | Schwarz criterion | 1.132922 | |
Log likelihood | -16.27078 | Durbin-Watson stat | 2.001014 | |
Inverted AR Roots | .49 | |||
Inverted MA Roots | .97 |
№ 2.
Построим прогноз исходного показателя на два года вперед и сравним данный прогноз с прогнозом, полученным в Лабораторной работе №2.
Период / прогнозы | Лабораторная 2 | Лабораторная 3 | |
2006 | II кв | -63,30304 | -69,01155 |
III кв | -65,87462 | -70,12310 | |
IV кв | -69,03021 | -71,23465 | |
2007 | I кв | -72,96321 | -72,34620 |
II кв | -73,64877 | -73,45775 | |
III кв | -77,85774 | -74,56931 | |
IV кв | -80,03215 | -75,68086 | |
2008 | I кв | -81,36445 | -76,79241 |
II кв | -86,21544 | -77,90396 | |
III кв | -89,31654 | -79,01551 | |
IV кв | -92,31544 | -80,12706 |
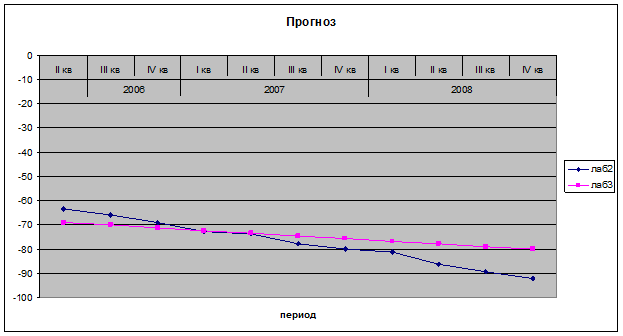
Итак, построены два прогноза на период 2006 г. 2 квартал – 2008 г. 4 квартал. Как видно из графиков и числовых представлений прогноза значения существенно отличаются. Такое различие прогнозов можно объяснить отличием построения моделей и учетом в них разных факторов. Так, в лабораторной работе 2 были учтены изменения тренда, выбросы (введены соответствующие фиктивные переменные). В данной лабораторной работе строена модель MA(1) с учетом исключения незначимых тренда и константы. Установить, какой прогноз является более точным сложно. Пожалуй, наиболее правильным было построить объединенную модель, учитывающую все данные факторы.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
