

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
В групповом коде минимальное расстояние между кодовыми словами равно минимальному весу ненулевого кодового слова, так как d(b1,b2) = w(b1+b2), а b1+b2 – это тоже кодовое слово. Поэтому для кода с порождающей матрицей G1 для определения минимального расстояния между кодовыми словами не надо рассматривать 28 пар кодовых слов, а просто из семи весов для ненулевых кодовых слов выбрать минимальный. Это минимальное расстояние для этого кода равно 3. Веса кодов в таблице кодирования для кода с порождающей матрицей G1 приведены справа от самих кодов.
Коды Хемминга
Коды Хемминга тоже являются матричными, а значит и групповыми. Это (m, n)-коды, где m=2![]() -1-r, n=2
-1-r, n=2![]() -1 для r>1. Для r=2 это (1,3) код; для r=3 это (4,7) код; r=4 это (11,15) код и т. д. Эти коды исправляют однократную ошибку, поскольку минимальный вес кодового слова равен 3. В каждом кодовом слове b позиции, номера которых являются степенью двойки, - контрольные, а остальные позиции – это позиции исходного сообщения, расположенные в том же порядке. Например, для (4,7) кода Хемминга b
-1 для r>1. Для r=2 это (1,3) код; для r=3 это (4,7) код; r=4 это (11,15) код и т. д. Эти коды исправляют однократную ошибку, поскольку минимальный вес кодового слова равен 3. В каждом кодовом слове b позиции, номера которых являются степенью двойки, - контрольные, а остальные позиции – это позиции исходного сообщения, расположенные в том же порядке. Например, для (4,7) кода Хемминга b![]() = a
= a![]() , b
, b![]() = a
= a![]() , b
, b![]() = a
= a![]() , b
, b![]() = a
= a![]() , а b
, а b![]() , b
, b![]() и b
и b![]() - контрольные позиции, вычисляемые из значений позиций исходного слова.
- контрольные позиции, вычисляемые из значений позиций исходного слова.
Контрольные позиции определяются из системы уравнений: b![]() M
M![]() =0. M – матрица порядка r
=0. M – матрица порядка r![]() (2
(2![]() -1), в j-м столбце которой находятся символы двоичного разложения числа j. Для r=2, 3, 4 матрицы M имеют вид:
-1), в j-м столбце которой находятся символы двоичного разложения числа j. Для r=2, 3, 4 матрицы M имеют вид:
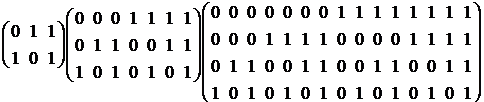
Система уравнений: b![]() M
M![]() =0 (матрица M транспонированная, в которой строки и столбцы матрицы M меняются местами) для r=3 ((4,7) кода Хемминга) имеет вид:
=0 (матрица M транспонированная, в которой строки и столбцы матрицы M меняются местами) для r=3 ((4,7) кода Хемминга) имеет вид:
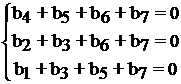 здесь «+» - сложение по модулю два. Отсюда b
здесь «+» - сложение по модулю два. Отсюда b![]() = b
= b![]() + b
+ b![]() + b
+ b![]() = a
= a![]() +a
+a![]() +a
+a![]() , b
, b![]() = b
= b![]() + b
+ b![]() + b
+ b![]() = a
= a![]() +a
+a![]() +a
+a![]() , b
, b![]() = b
= b![]() + b
+ b![]() + b
+ b![]() = a
= a![]() +a
+a![]() +a
+a![]() .
.
Система уравнений: b![]() M
M![]() =0 для r=4 ((11,15) кода Хемминга) имеет вид (в матрице M
=0 для r=4 ((11,15) кода Хемминга) имеет вид (в матрице M![]() порядка (2
порядка (2![]() -1)
-1)![]() r в j-ой строке находятся символы двоичного разложения числа j):
r в j-ой строке находятся символы двоичного разложения числа j):
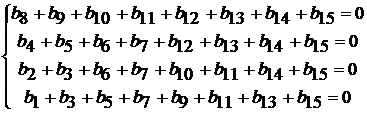 здесь «+» - сложение по модулю два. Отсюда b
здесь «+» - сложение по модулю два. Отсюда b![]() = b
= b![]() + b
+ b![]() + b
+ b![]() +b
+b![]() +b
+b![]() +b
+b![]() +b
+b![]() = a
= a![]() +a
+a![]() +a
+a![]() + a
+ a![]() +a
+a![]() + a
+ a![]() + a
+ a![]() , b
, b![]() = b
= b![]() + b
+ b![]() + b
+ b![]() +b
+b![]() +b
+b![]() +b
+b![]() +b
+b![]() = a
= a![]() +a
+a![]() +a
+a![]() + a
+ a![]() +a
+a![]() + a
+ a![]() + a
+ a![]() , b
, b![]() = b
= b![]() + b
+ b![]() + b
+ b![]() + b
+ b![]() + b
+ b![]() +b
+b![]() +b
+b![]() = a
= a![]() +a
+a![]() +a
+a![]() + a
+ a![]() +a
+a![]() + a
+ a![]() + a
+ a![]() , b
, b![]() = b
= b![]() + b
+ b![]() + b
+ b![]() + b
+ b![]() + b
+ b![]() +b
+b![]() +b
+b![]() = a
= a![]() +a
+a![]() +a
+a![]() + a
+ a![]() +a
+a![]() +a
+a![]() + a
+ a![]() .
.
Для (4,7)-кода Хемминга порождающая матрица G = .
.
(1,3) код Хемминга практически является кодом с тройным повторением: исходное слово a = (0) имеет кодовое слово b =, исходное слово a = (1) имеет кодовое слово b =Система уравнений: b![]() M
M![]() =0 для r=3 ((1,3) – кода Хемминга) имеет вид:
=0 для r=3 ((1,3) – кода Хемминга) имеет вид: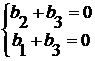 . Отсюда b
. Отсюда b![]() = b
= b![]() = a
= a![]() , b
, b![]() = b
= b![]() = a
= a![]() .
.
Схема декодирования кода Хемминга: считаем, что принято искажённое кодовое слово c = b + e, где «+» - сложение по модулю 2, e – это ошибка, двоичный вектор той же длины, что и векторы b и c. Если c кодовое слово, то тогда e = 0. (b+e) ![]() M
M![]() = e
= e ![]() M
M![]() , так как b
, так как b![]() M
M![]() =0. Если e
=0. Если e ![]() M
M![]() = 0, то считаем, что нет однократной ошибки.
= 0, то считаем, что нет однократной ошибки.
Если же существует одна ошибка в j-й позиции, то есть вектор e имеет единицу только в j – й позиции, то e ![]() M
M![]() - это вектор, равный j-му столбцу M (или j-й строке M транспонированное) и является двоичным разложением числа j. Отсюда для получения кодового слова b надо в искажённом кодовом слове c инвертировать j–ю позицию. Далее в кодовом слове b вычеркнуть контрольные позиции и получится исходное слово a – результат декодирования. Если ошибок более одной, то декодирование даёт неверный результат.
- это вектор, равный j-му столбцу M (или j-й строке M транспонированное) и является двоичным разложением числа j. Отсюда для получения кодового слова b надо в искажённом кодовом слове c инвертировать j–ю позицию. Далее в кодовом слове b вычеркнуть контрольные позиции и получится исходное слово a – результат декодирования. Если ошибок более одной, то декодирование даёт неверный результат.
Например, при r=3 (4,7) код c=0011111. c ![]() M
M![]() =(0011111)
=(0011111) ![]()
 = 011 = 3 = j (пять нижних столбцов матрицы M
= 011 = 3 = j (пять нижних столбцов матрицы M![]() поразрядно суммируем по модулю два). Инвертируем искажённое кодовое слово c в третьей позиции и получаем кодовое слово b = 0001111. Далее вычёркиваем из b контрольные позиции (b
поразрядно суммируем по модулю два). Инвертируем искажённое кодовое слово c в третьей позиции и получаем кодовое слово b = 0001111. Далее вычёркиваем из b контрольные позиции (b![]() , b
, b![]() и b
и b![]() ) и получаем исходное слово a = 0111.
) и получаем исходное слово a = 0111.
При кодировании Хемминга можно использовать как порождающие матрицы, так и вышеприведённую схему кодирования. Для (11,15) кода Хемминга порождающая матрица имеет вид:
G = 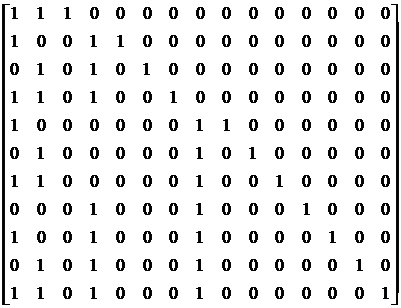
Коды Хаффмана
Код Хаффмана кодирует сообщения (слова), состоящие из символов алфавита. Этот код используется при архивировании данных. Символы независимы и появляются каждый со своей вероятностью, не зависящей от позиции в сообщении. Например, сообщения состоят из пяти символов (в алфавите 5 букв): a, b, c, d и e с вероятностями 0.12, 0.4, 0.15, 0.08 и 0.25 соответственно. Сумма вероятностей всех символов равна единице. Код Хаффмана на каждом этапе кодирования объединяет два символа (или дерево символов и символ или два дерева символов) с наименьшими вероятностями, одному из них приписывается ноль, другому – единица, а их вероятности суммируются для участия в следующих этапах.
Во всех следующих этапах эти символы участвуют только вместе с их суммарной вероятностью (в составе своего дерева символов). Количество этапов на единицу меньше числа символов в алфавите. На первом этапе образуется простое дерево из двух символов, на каждом последующем этапе к дереву (к деревьям) добавляется ровно один символ:
008 0.25
a b c d e
Первый этап (суммируем 0.12 и 0.08):
025
0 / \ 1
d a b c e
Второй этап (суммируем 0.15 и 0.20):
0
![]() 0 / \ 1
0 / \ 1
0 / \ 1
c d a b e
Третий этап (суммируем 0.35 и 0.25):
0
![]() 0 / \ 1
0 / \ 1
![]() 0 / \ 1
0 / \ 1
0 / \ 1
e c d a b
Четвёртый этап (суммируем 0.60 и 0.40):
1.00
![]() 0 / \ 1
0 / \ 1
![]() 0 / \ 1
0 / \ 1
![]() 0 / \ 1
0 / \ 1
0 / \ 1
b e c d a.
Символ a кодируется 1111, b – 0, c – 110, d – 1110 и символ e – 10, т. е. код символа получается при проходе от вершины (вероятность 1.00) к символу. Средняя длина кода Хаффмана минимальна (здесь 2.15), она равна сумме вероятностей символов, умноженных на их длины кодов. Символ с максимальной вероятностью получает самый короткий код, а символ с минимальной вероятностью – самый длинный.
Деревьев при кодировании может быть несколько, но на последнем этапе получается ровно одно итоговое дерево, вверху которого будет вероятность 1.00. В деревьях символов можно левому символу приписывать ноль, а правому единицу, а можно и наоборот.
Комбинаторика
Глава 8. Размещения и сочетания
Комбинаторика решает задачи перечисления и пересчёта. Перечисление состоит в нахождении всех элементов, а пересчёт только требует назвать их количество. Если взять для примера (1,3) код Хемминга, то перечисление его всех кодовых слов это: 000 и 111, а пересчёт всех его кодовых слов даёт цифру два.
Набор r элементов из n – называется (n, r)-выборкой. Выборка может производиться по различным правилам. В упорядоченной выборке (размещении) задан порядок следования в ней элементов. Неупорядоченная выборка называется сочетанием. Если в выборке допускаются повторения элементов, то она называется выборкой с повторениями (надчерк сверху). Выборка без повторений обычно называется просто выборкой. Выборки:
Размещения | Сочетания | |
С повторениями | _ A | _ C |
Без повторений | A r | C r |
В размещениях с повторениями у каждого из r элементов выборки есть ровно n возможностей быть выбранным. Возможности для всех элементов выборки перемножаются. Ограничений на соотношение чисел n и r между собой здесь нет.
В размещениях (без повторений) у первого из r элементов выборки есть ровно n возможностей быть выбранным, у второго – (n-1), … , у последнего r-го – (n – r + 1). Возможности для всех элементов выборки так же перемножаются. При n=r A![]() обозначается как P
обозначается как P![]() , т. е. P
, т. е. P![]() = A
= A![]() =n! - число всех перестановок n-элементного множества. Здесь n не может быть меньше r, иначе не из чего будет выбирать последние (r – n) элементов.
=n! - число всех перестановок n-элементного множества. Здесь n не может быть меньше r, иначе не из чего будет выбирать последние (r – n) элементов.
Примеры размещений: имеем разделённый на четыре равные части квадрат и пять различных красок. Каждая из частей квадрата красится одной краской. Если разные части можно окрасить в один цвет, то число способов раскрасить квадрат равно числу (5,4) – размещений с повторениями (![]() =
=![]() = 5
= 5![]() ). Если нельзя, то число таких способов равно числу (5,4) – размещений (A
). Если нельзя, то число таких способов равно числу (5,4) – размещений (A![]() = A
= A![]() =5!/1! = 5!).
=5!/1! = 5!).
Число перестановок множества {1, 2, 3} равно шести (3!):,,,,иПоказом всех перестановок решена задача перечисления.
Каждое (n, r) – сочетание можно упорядочить r! способами и получим все (n, r) – размещения, отсюда C![]()
![]() r! = C
r! = C![]()
![]() P
P![]() = A
= A![]() . Возьмём для примера все (2,3) – сочетания из множества {1, 2, 3}: (1 2),иИх всего три. Каждое из сочетаний можно упорядочить двумя (2!) способами: первое –и (2 1), второе –ии третье –иОтсюда C
. Возьмём для примера все (2,3) – сочетания из множества {1, 2, 3}: (1 2),иИх всего три. Каждое из сочетаний можно упорядочить двумя (2!) способами: первое –и (2 1), второе –ии третье –иОтсюда C![]()
![]() r! = A
r! = A![]() и C
и C![]() = A
= A![]() / r!. Здесь n не может быть меньше r. Осталось определить число сочетаний с повторениями.
/ r!. Здесь n не может быть меньше r. Осталось определить число сочетаний с повторениями.
Каждому (n, r) – сочетанию с повторениями, полученному из множества X = {x1, x2, … , xn}, поставим в соответствие двоичный вектор длины (n + r –1), состоящий из r нулей и (n – 1) единиц так, что число нулей между (j – 1)–й единицей и j-й единицей равно количеству элементов xj в сочетании. Число нулей перед первой единицей равно количеству элементов x1 в этом сочетании, а число нулей после последней единицы – количеству элементов xn в (n, r) – сочетании.
Пусть для примера X={2, 3, 4, 5} и возьмём (4,6) – сочетание с повторениями:Соответствующий этой выборке двоичный вектор (двоичное число) равен 0, так как элементов 2 в выборке нет, то и в двоичном числе перед первой единицей нет нулей. Элементов 3 в выборке два, поэтому в двоичном коде два нуля между первой и второй единицами. Элементов 4 в выборке три, поэтому в двоичном коде три нуля между второй и третьей единицами. Элемент 5 в выборке один, поэтому в двоичном числе после последней, третьей единицы стоит один нуль.
Получили взаимно однозначное соответствие между (n, r) – сочетанием с повторениями и двоичными числами, состоящими из r нулей и (n – 1) единиц. Есть выборка – получим число, есть число – получим выборку.
В двоичном векторе длиной (n + r – 1) имеется C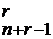 возможностей установить r нулей (остальные единицы), так как порядок установки нулей не имеет значения (например, сначала ноль на первую позицию, а затем на пятую, всё равно, что сначала на пятую, а затем на первую) и повторений нет (на одну позицию двоичного вектора несколько нулей не установишь). Пусть множество X = {3, 4, 5, 6}, и (4,6) – сочетание с повторениями равно {3, 3, 3, 5, 5, 5}. Тогда соответствующий этому сочетанию двоичный вектор имеет вид: 1.
возможностей установить r нулей (остальные единицы), так как порядок установки нулей не имеет значения (например, сначала ноль на первую позицию, а затем на пятую, всё равно, что сначала на пятую, а затем на первую) и повторений нет (на одну позицию двоичного вектора несколько нулей не установишь). Пусть множество X = {3, 4, 5, 6}, и (4,6) – сочетание с повторениями равно {3, 3, 3, 5, 5, 5}. Тогда соответствующий этому сочетанию двоичный вектор имеет вид: 1.
Примеры сочетаний: число способов выбрать пять номеров из 36 равно числу (36,5) – сочетаний. Из колоды с 52 картами выбирается 10 карт, в скольких случаях из выбранных 10 карт окажутся все 4 туза? Из 10 карт четыре уже есть (4 туза), оставшиеся 6 карт надо набрать из 48 карт (52 – 4 туза). Отсюда число таких наборов с 4 тузами равно числу (48,6) – сочетаний. Число наборов из трёх типов монет достоинством 1, 5 и 10 копеек и общим количеством 30 монет в каждом наборе равно числу (3,30) сочетаний с повторениями.
Для примера определим количество целочисленных решений системы: x
= C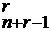 . Каждому решению <x
. Каждому решению <x![]() , x
, x![]() , …, x
, …, x![]() > этого уравнения можно поставить в соответствие (n, r)-сочетание с повторениями, такое, что в нём содержится x
> этого уравнения можно поставить в соответствие (n, r)-сочетание с повторениями, такое, что в нём содержится x![]() элементов первого типа из n-элементного множества, x
элементов первого типа из n-элементного множества, x![]() элементов второго типа из n-элементного множества, и т. д. Сделаем замену переменных u
элементов второго типа из n-элементного множества, и т. д. Сделаем замену переменных u![]() =x
=x![]() -a
-a![]() . Тогда u
. Тогда u![]() +u
+u![]() + … +u
+ … +u![]() =r-
=r-![]() a
a![]() =r’ . При r’
=r’ . При r’![]() 0 количество целочисленных решений равно C
0 количество целочисленных решений равно C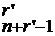 .
.
Разбиения
Число разбиений конечного n-элементного множества на k подмножеств таких, что i-е подмножество содержит n![]() элементов, подмножества не имеют общих элементов и каждый элемент множества попадает в одно и ровно в одно подмножество разбиения, равно C
элементов, подмножества не имеют общих элементов и каждый элемент множества попадает в одно и ровно в одно подмножество разбиения, равно C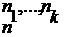 =n!/(n
=n!/(n![]() !
!![]() n
n![]() !
!![]() …
…![]() n
n![]() !). C
!). C![]() является количеством разбиений множества мощности n на два подмножества: мощности k и мощности (n – k).
является количеством разбиений множества мощности n на два подмножества: мощности k и мощности (n – k).
Первое подмножество мощности n![]() можно выбрать C
можно выбрать C![]() способами. Второе подмножество мощности n
способами. Второе подмножество мощности n![]() набирается из оставшихся (n - n
набирается из оставшихся (n - n ) элементов и его можно выбрать C
) элементов и его можно выбрать C![]() способами. И так далее. Итого: C
способами. И так далее. Итого: C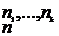 = (n!/(n
= (n!/(n![]() !
!![]() (n - n
(n - n![]() )!))
)!))![]() ((n - n
((n - n![]() )!/ (n
)!/ (n![]() !
!![]() (n - n
(n - n![]() - n
- n![]() )!))
)!))![]() … = n!/(n
… = n!/(n![]() !
!![]() n
n![]() !
!![]() …
…![]() n
n![]() !). Выделенные жирным шрифтом скобки с разностями все сокращаются.
!). Выделенные жирным шрифтом скобки с разностями все сокращаются.
Набор подмножеств в разбиении является упорядоченным, а сами подмножества разбиения - нет. Например, число способов расселить 12 студентов в три комнаты, в которых имеется 2, 4 и 6 мест соответственно, равно C![]() = 12!/(2!
= 12!/(2! ![]() 4!
4! ![]() 6!).
6!).
Полиномиальная формула
Полиномиальная формула: (x![]() +x
+x![]() + … +x
+ … +x![]() )
)![]() =
=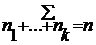 C
C![]() x
x![]()
![]() …
… ![]() x
x![]() , где суммирование производится по всем решениям уравнения n
, где суммирование производится по всем решениям уравнения n![]() +n
+n![]() + … +n
+ … +n![]() = n в целых неотрицательных числах. Рассмотрим все скобки (x
= n в целых неотрицательных числах. Рассмотрим все скобки (x![]() +x
+x![]() + … +x
+ … +x![]() ). Их n штук и все они одинаковые, а в множестве не может быть одинаковых элементов. Чтобы сделать из скобок множество мощности n пронумеруем их.
). Их n штук и все они одинаковые, а в множестве не может быть одинаковых элементов. Чтобы сделать из скобок множество мощности n пронумеруем их.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 |
