

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Библиографические ссылки
1. В. Д. Янушевич, М. Н. Жижин, А. А. Пойда, А. М. Новиков Разработка алгоритмов многомасштабной визуализации гигапиксельных видеопотоков. Вычислительные методы и программирование: новые вычислительные технологииТ.13, с. 153-159, ISSN /
2. Multiapplication, Intertile Synchronization on Ultra-High-Resolution Display Walls; Sungwon Nam, Sachin Deshpande, Venkatram Vishwanath, Byungil Jeong, Luc Renambot, Jason Leigh, Proceedings of the first annual ACM SIGMM conference on Multimedia systems, February 22-23, 2010.
3. А. Боровский Qt 4.7+ Практическое программирование на C++. – СПб.: «БХВ-Петербург», 2012. – С. 496. – ISBN 0757-8
УДК 004.051, 532.546
© , , 2013
ИССЛЕДОВАНИЕ ВАРИАНТОВ РАСПАРАЛЛЕЛИВАНИЯ АЛГОРИТМА РАСЧЕТА ДИНАМИЧЕСКИХ ПРОЦЕССОВ
В ПОРИСТЫХ СРЕДАХ
Гырник К. А. – ст. каф. «Прикладной математики и информатики» (ДВФУ);
e-mail: *****@***ru; Леонтьев Д. В. – ст. каф. «Прикладной математики и информатики» (ДВФУ), e-mail: *****@***ru – науч. сотр. (ИАПУ ДВО РАН), e-mail: *****@***ru
В работе обсуждается процесс нахождения оптимального варианта распараллеливания алгоритма по моделированию динамических процессов в пористых средах с использованием технологии OpenMP. Кратко представлен исходный последовательный алгоритм и описаны блоки коды, которые могут быть распараллелены. Получены данные ускорений различных вариантов программы с учетом параллельного выполнения каждого из отобранных блоков, а также их комбинаций. Выбран наиболее оптимальный вариант распараллеливания.
Введение
Опасным последствием многих техногенных и природных катастроф являются очаги горения и иного энерговыделения, часто возникающие в пористых средах. Например, пожары в грунтовых породах при взрывных работах в горнодобывающей отрасли, пожары под завалами промышленных и гражданских объектов, образовавшиеся в результате взрыва или иного воздействия. Актуальной задачей является своевременное выявление и локализация подобных очагов, а также выработка мер по их устранению. Исследования в этой области [1] показали, что эффективной мерой по охлаждению очагов тепловыделения является пропускание газа через пористую среду.
Математические модели движения газа через пористую среду, как правило, строятся на общих подходах механики сплошных многокомпонентных сред. В работах [2-4] предложен оригинальный численный метод исследования двумерных нестационарных течений газа через пористые объекты, основанный на комбинации явных и неявных конечно-разностных схем, и исследованы процессы охлаждения очагов тепловыделения в пористых объектах различной конфигурации (ступенчатые, плавно сужающиеся и др.). Численный метод реализован в виде последовательной программы моделирования динамических процессов в пористых средах.
В данной работе описывается метод распараллеливания последовательного алгоритма и реализация параллельной программы моделирования источников тепловыделения в пористых средах с использованием технологии OpenMP. В начале работы кратко представлен последовательный алгоритм и описан его потенциал параллелизма. Далее проведен сравнительный анализ нескольких версий программы с учетом параллельного исполнения отдельных участков ее кода. На основе анализа выбран оптимальный вариант распараллеливания программы. В заключении приведены результаты производительности параллельной версии.
Последовательный алгоритм расчета
Рассмотрим следующую конфигурацию пористого объекта (рис. 1,а). Объект имеет открытую границу в нижней части, закрытые (непроницаемые) границы слева и справа и наполовину прикрытую верхнюю границу. Последовательный алгоритм решения задачи показан на рис. 1,б.
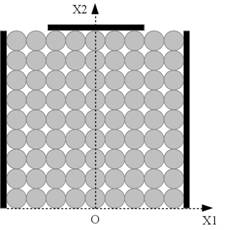
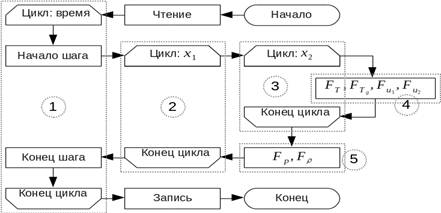
а) б)
Рис. 1. а) конфигурация пористого объекта;
б) блок-схема последовательного алгоритма задачи
Алгоритм включает три стадии: подготовительную, вычислительную и завершающую. Данные пористого объекта хранятся в основных шести трехмерных массивах: температура газа, температура твердой фазы, давление газа, плотность газа, вертикальная и горизонтальная скорости газа. Первые два измерения массивов отвечают за размерности сетки (координаты X1 и X2), а третье - за количество временных слоев, необходимых для организации вычислений. На подготовительной стадии осуществляется инициализация начального состояния пористого объекта, включая распределение давления, температур и остальных величин. Указанные начальные значения считываются из входных файлов, заранее подготовленных пользователем. Далее выполняется вычислительная стадия, реализующая цикл по времени, в котором значения текущего временного слоя рассчитываются с использованием значений предыдущего временного слоя (таким образом, величина третьей размерности всегда равна 2). Алгоритм нахождения указанных величин на каждом временном слое следующий: фиксируется индекс по координате X1; последовательно меняя индекс координаты X2, решается система из четырех уравнений, определяющая скорости фильтрации газа, его температуру и температуру твердой фазы; методом прогонки решается система уравнений, определяющая давление и плотность газа; после этого меняется индекс по координате X1 и процесс повторяется. Следует отметить, что для разных координат X1 может меняться алгоритм прогонки. Для тех координат, которые являются открытыми в верхней части, применяется обычная («прямая») прогонка, для закрытых - «обратная» прогонка (меняется направление вдоль оси OX2). После расчета всех параметров текущего слоя вычисляются краевые условия. Затем происходит переход либо к следующему временному слою, либо к заключительной фазе, в которой реализуется итоговая запись результатов в выходные файлы.
Разработанный алгоритм имеет ряд особенностей его применения. Первой важной особенностью является то, что интересуемый промежуток времени исследования состояния источников тепловыделения может измеряться часами и сутками модельного времени. Второй важной особенностью является квадратичная зависимость шага по времени от шага по пространству. Такое соотношение в сочетании с необходимостью рассматривать более точные сетки (уменьшение шага) и длительным модельным временем проведения вычислительного эксперимента приводит к весьма значительному росту количества итераций и значительному увеличению общего времени расчета. Грубая асимптотическая оценка последовательного алгоритма составляет O(n4). Например, для сетки с шагом 0,001 единиц, что соответствует области 1000x1000 ячеек, объем вычислений составляет триллионы (1012) операций, что выходит за рамки обычных настольных компьютеров и требует применения параллельных технологий для ускорения времени получения результата.
Анализ последовательного алгоритма
Для построения оптимального параллельного алгоритма моделирования состояния пористого объекта проведем анализ исходного последовательного алгоритма. Для начала аналитически определим те блоки кода, которые потенциально могут быть выполнены параллельно. Такие блоки показаны на рис. 1б пунктирными областями. Список включает все циклы алгоритма и его основные вычислительные блоки:
Блок (1) – главный цикл итераций по времени; очевидно, что он не может быть распараллелен, так как состояние пористого объекта на текущем шаге определяется его состоянием на предыдущем шаге;
Блок (2) – цикл по координате X1; пошаговый («ручной») анализ алгоритма показал, что все вычисления по каждой координате оси OX1 являются независимыми и могут быть свободно распараллелены;
Блок (3) – цикл по координате X2; «ручной» анализ также показал, что значения ряда физических величин могут быть вычислены также параллельно; таким образом, в рамках двух вложенных циклов значения температуры газа, температуры твердой фазы, горизонтальной и вертикальной скоростей фильтрации газа в каждой ячейке пористого объекта могут быть вычислены параллельно;
Блок (4) – последовательность вычислительных выражений для расчета значений температур и скоростей на текущем шаге по времени; в виду отсутствия взаимных зависимостей по данным между выражениями, вся последовательность может быть распараллелена по подблокам; каждому подблоку соответствует набор выражений, завершающийся оператором присваивания значения соответствующей физической величины ячейке массива;
Блок (5) – последовательность вычислительных выражений для расчета значений давления и плотности; данная последовательность не может быть распараллелена, так как, во-первых, присутствует взаимная зависимость по данным (плотность зависит от давления), во-вторых, для расчета используется алгоритм прогонки, в котором очередной шаг прогонки (в прямом или обратном направлении вдоль оси OX2) зависит от предыдущего.
Таким образом, в алгоритме выделим три блока кода (2, 3 и 4), которые потенциально могут быть распараллелены при обязательном условии сохранения корректности конечного результата.
Результаты распараллеливания с использованием OpenMP
Для каждого из выделенных блоков определим набор выражений в терминах стандарта OpenMP [5], которые должны быть внесены в последовательный код программы. Отметим, что авторы не ставят своей целью получить максимально возможное ускорение при распараллеливании, что может быть связано с кардинальным преобразованием исходной программы. Наиболее приемлемым результатом будет получение достаточно высоких показателей ускорения при минимальных изменениях в исходном коде.
Блоки 2 и 3, определенные выше - это циклы, распараллеливание которых в терминах OpenMP представляет собой тривиальную задачу. Достаточно перед оператором цикла вставить следующее выражение (директиву компилятору):
#pragma omp parallel for shared(f1, f2, ...)
Блок 4 распараллеливаем с использованием понятия параллельной секции. Вся последовательность выражений, состоящая из подблоков и составляющая тело цикла по OX2, обрамляется директивой omp parallel sections. Каждый подблок представляется отдельной секцией и обрамляется директивой omp section. В результате получаем распараллеливание тела цикла по OX2 не только по отдельным итерациям, но и по содержимому тела цикла.
Таким образом, для выбора оптимального способа распараллеливания были сформированы три группы OpenMP-директив, которыми модифицируем исходный код последовательной программы. В результате получаем семь версий параллельной программы, каждая из которых содержит соответствующие параллельные директивы. В первой версии модифицируем только блок 2. Во второй версии — только блок 3. В третьей — только блок 4. В четвертой — только блоки 2 и 3. И так далее, до получения последней версии, где директивы компилятору присутствует во всех выделенных блоках.
Остается открытым вопрос количества параллельных потоков, которые должны быть созданы в процессе выполнения каждой из parallel-директив. В OpenMP количество потоков, создаваемых директивой parallel, может регулироваться тремя способами: определение переменной среды OMP_NUM_THREADS при запуске параллельной программы, использование библиотечной функции omp_set_num_threads непосредственно в коде программы и указание количества потоков непосредственно в директиве с помощью оператора num_threads. При тестировании различных версий будем придерживаться концепции неограниченного параллелизма, предполагая, что в вычислительной системе существует такое достаточное количество ядер (процессоров), чтобы каждый создаваемый поток в исследуемой параллельной программе монопольно занимал одно ядро процессора. Также будем активировать режим вложенного параллелизма в OpenMP, когда этого будет требовать соответствующая версия.
Результаты тестирования представлены в таблицах 1 и 2. Тестирование проводилось на вычислительном кластере ЦКП «Дальневосточный вычислительный ресурс» ДВО РАН. Использовались узлы с 48 ядрами (4 процессора AMD Opteron по 12 ядер каждый). Тестирование проводилось в два этапа. На первом этапе определялась версия программы, которая показывает максимальное значение ускорения. На втором этапе «максимальная» версия тестировалась для разных объем исходных данных. Для первого этапа размер шага по пространству пористого объекта выбран 0,025 единиц, что соответствует сетке 43x43 ячейки. Для второго этапа брался размер шага 0,01 и 0,0025, что соответствует сетке 103x103 и 403x403.
Таблица 1
Результаты тестирования на сетке 43x43
Последовательная версия | 0,501396 | ||||
Параллельная версия (кол-во потоков) | 2 | 3 | 4 | 6 | 8 |
Версия 1 (блок 2) | 0,436435 | 0,439977 | 0,423541 | 0,409995 | 0,386292 |
Версия 2 (блок 3) | 0,883134 | 0,882022 | 0,982007 | 1,022048 | 1,051134 |
Версия 3 (блок 4) | 6,298855 | 7,244954 | 9,05906 | 11,047954 | 14,976852 |
Версия 4 (блоки 2 и 3) | 2,31069 | 11,027065 | 32,775138 | X | X |
Версия 5 (блоки 2 и 4) | 58,091256 | X | X | X | X |
Версия 6 (блоки 3 и 4) | 58,508218 | X | X | X | X |
Версия 7 (блоки 2, 3 и 4) | 178,0348 | X | X | X | X |
Как видно из таблицы наиболее оптимальным способом является распараллеливание в исходном алгоритме цикла по координате OX1. Распараллеливание остальных блоков кода приводит только к увеличению накладных расходов на создание и синхронизацию потоков. Знаком «X» отмечены тесты, которые не проводились по понятной причине — получить эффект ускорения для этой версии не удастся.
Таблица 2
Тестирование задачи на разных объемах данных
Размер сетки | 103x103 | 403x403 |
Последовательна версия | 9,148628 | 835,185364 |
Версия 1 (блок 2), 2 потока | 6,694661 (S=1,37) | 485,410744 (S=1,72) |
Версия 1 (блок 2), 3 потока | 5,566655 (S=1,64) | 399,350094 (S=2,09) |
Версия 1 (блок 2), 4 потока | 4,979433 (S=1,84) | 355,536221 (S=2,35) |
Версия 1 (блок 2), 6 потоков | 4,370389 (S=2,09) | 312,981125 (S=2,67) |
Версия 1 (блок 2), 8 потоков | 4,377882 (S=2,09) | 285,901529 (S=2,92) |
В таблице 2 представлено время работы последовательной и параллельной версии программы для разных объемом данных и разного количества параллельных потоков. Значение времени обозначает среднее количество секунд реального времени для расчета одной секунды модельного времени. Все тесты проводились для 100 секунд модельного времени.
Заключение
Таким образом, в работе построена параллельная программа моделирования динамических процессов в пористых средах. Исследована производительность этой программы. В целом следует сказать, что получены удовлетворительные результаты. Достигнуто ускорение почти в 3 раза. Однако, следует признать, что задача, а также выбранный способ и технология распараллеливания, имеют слабую масштабируемость и эффективность. Так, насыщение задачи размерностью 103x103 уже наступает при 6 потоках, а эффективность не превышает 30%. Слабые результаты можно компенсировать простотой перехода от последовательной к параллельной программе. Однако надо сказать, что для получения максимально возможного ускорение требуется существенная перестройка алгоритма исходной программы, а также глубокий анализ потока данных задачи.
Библиографические ссылки
1. , , Математическое моделирование аварийного блока Чернобыльской АЭС. М.: Наука, 19с.
2. Левин В. А., Луценко Н. А. Численное моделирование двумерных нестационарных течений газа через пористые тепловыделяющие элементы // Вычислительные технологии. 2006. Т. 11. №6. С. 44-58.
3. Левин В. А., Луценко Н. А. Движение газа через пористые объекты с неравномерным локальным распределением источников тепловыделения // Теплофизика и аэромеханика. 2008. Т. 15. №3. С. 407-417.
4. Левин В. А., Луценко Н. А. Нестационарные течения газа через осесимметричные пористые тепловыделяющие объекты // Математическое моделирование. 2010. Т. 22. №3. С. 26-44.
5. OpenMP Application Program Interface. Version 2.5 May 2005. [Электронный ресурс] // OpenMP Architecture Review Board : [сайт] / Режим доступа: http://www. openmp. org/mp-documents/spec25.pdf (28.04.203).
УДК 681.3
© , 2013
Оценка функциональной надежности
иерархических вычислительных структур
– канд. техн. наук, завкафедрой «Прикладная математика» (С-ПБ ГУ ГА), е-mail: *****@***ru
Представлены результаты исследования функциональной надежности иерархической структуры. Обсуждаются возможности оптимизации структуры.
Введение
Иерархические структуры достаточно часто применяются при создании распределенных систем обработки информации. Однако серьезным недостатком таких структур является их малая, по сравнению с многими другими структурами, функциональная надежность, так как при выходе из строя серверов верхнего уровня, выходит из строя вся система [1, 2].
Здесь приводятся результаты исследования логической иерархической вычислительной структуры, построенной на базе вычислительной сети, состоящей из R уровней, на каждом из которых работают серверы, образующие эту структуру. На уровне r работает ![]() серверов (r = 1,2,…,R). Для каждого уровня r задано минимальное количество работающих серверов
серверов (r = 1,2,…,R). Для каждого уровня r задано минимальное количество работающих серверов ![]() (
(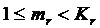 ), при котором уровень обеспечивает требуемые характеристики обработки информации. Таким образом структура задается параметрами {R, K, m}, где
), при котором уровень обеспечивает требуемые характеристики обработки информации. Таким образом структура задается параметрами {R, K, m}, где ![]() и
и 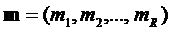 .
.
Иерархическая структура выходит из строя (отказывает), если вышел из строя (отказал) хотя бы один ее уровень.
Анализ работы уровня r
Рассматривается система, состоящая из ![]() устройств. Для обеспечения нужных характеристик функционирования системы в каждый момент времени должно работать
устройств. Для обеспечения нужных характеристик функционирования системы в каждый момент времени должно работать ![]() устройств. При выходе из строя любого из работающих устройств, его заменяет любое из работающих до тех пор, пока не останется
устройств. При выходе из строя любого из работающих устройств, его заменяет любое из работающих до тех пор, пока не останется ![]() работающих устройств. При выходе из строя любого из них уровень считается отказавшим.
работающих устройств. При выходе из строя любого из них уровень считается отказавшим.
Считается, что система работает в течение заданного интервала времени T (0< T < ∞), по истечении которого она останавливается и восстанавливаются все отказавшие устройства. После восстановления система опять функционирует в течение интервала длительностью T. Все устройства в системе имеют одинаковую функцию распределения длительности интервала до отказа – ![]() такую, что
такую, что ![]() ,
, ![]() .
.
Существует функция ![]() .
.
Вероятность отказа системы в момент T вычисляется по формуле:
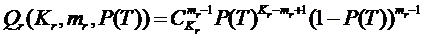 .
.
Вероятность того, что число устройств, превышающих m в момент T больше 0 равна:
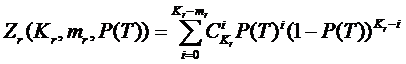 .
.
Вероятность отказа всей иерархической структуры вычисляется по формуле:
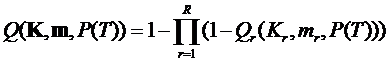 .
.
Применяя полученные формулы можно определить оптимальные значения векторов K, m и длительности работы структуры T. Для этого предлагается ввести штрафы за отказ системы ранее установленной длительности работы T и штраф за наличие избытка работающих устройств к моменту T.
Следует отметить, что рассматривается именно логическая иерархическая структура, поскольку при ее создании на базе компьютерной возможно установление связей между любыми узлами сети (устройствами структуры). Введение для каждого слоя минимального числа работающих устройств обусловлено тем, что в данном случае возможна передача функций обработки между компьютерами (узлами, устройствами) внутри одного слоя, но при числе работающих устройств меньше установленного, характеристики системы ухудшаются до неприемлемого уровня.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
