

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
УДК 004.8
© , ёв, ,
, , 2013
ПЛАТФОРМА ДЛЯ РАЗРАБОТКИ ИНТЕЛЛЕКТУАЛЬНЫХ
МУЛЬТИ-АГЕНТНЫХ ИНТЕРНЕТ-СЕРВИСОВ
– д-р техн. наук, зав. лаб., e-mail: gribova@iacp.dvo.ru; С. – д-р физ.-мат. наук., гл. науч. сотр., e-mail: kleschev@iacp.dvo.ru; – вед. инж.-программист, e-mail: dmalkr@gmail.com; – канд. техн. наук., науч. сотр, e-mail: philipmm@iacp.dvo.ru; А. – канд. техн. наук, науч. сотр., e-mail: rakot2k@mail.ru; – канд. техн. наук, ст. науч. сотр. (ИАПУ ДВО РАН);, e-mail: shalf@iacp.dvo.ru В. – канд. техн. наук, зав. сектором суперкомпьютерных технологий (ИММ УрО РАН), e-mail: avs@imm.uran.ru
В работе описана концепция платформы облачных вычислений, предназначенная для разработки, управления и использования интеллектуальных мультиагентных интернет-сервисов. Основная цель создания платформы состоит в снижении за счет ее использования трудозатрат по сопровождению таких сервисов в течение их жизненного цикла.
Введение
Разработка и сопровождение интеллектуальных систем (состоящих, в общем случае, из решателя задач, пользовательского интерфейса, базы знаний) является чрезвычайно сложным и трудоемким процессом.
Можно выделить две ключевые технологии разработки таких систем. Первая технология состоит в использовании специализированных инструментальных оболочек интеллектуальных систем для прототипирования и реализации последних. В качестве способа представления знаний здесь используются базы правил. К недостаткам такого подхода следует отнести то, что базы знаний, основанные на правилах, исключительно сложно не только разрабатывать, но, прежде всего, сопровождать, поскольку эксперты не понимают такое представление. Разработанные подходы, стратегии, методы и процедуры работы с экспертами по извлечению знаний позволили упростить их создание, однако модификация, расширение знаний в процессе эксплуатации системы, осталась трудоемким процессом, так как такие системы не предназначены для этого, поскольку метод решения задачи частично содержится в базе знаний [1]. Помимо этого инструментальные оболочки, как правило, накладывают жесткие ограничения на характер диалога с пользователем, способ задания входной и представления выходной информации.
Вторая технология исходит от обратного принципа – при построении интеллектуальных систем наиболее сложным для создания и сопровождения компонентом является база знаний и любая другая сложно-структурированная информация. Поэтому она должна разрабатываться так, чтобы быть повторно-используемой в различных интеллектуальных системах. Этот подход предполагает сначала формирование метастуктуры или онтологии, по которой может быть создан класс различных баз знаний либо другой сложно-структурированной информации, ей соответствующий. Решатель задачи основан на онтологии обрабатываемой информации и, таким образом, может быть повторно использован для различных интеллектуальных систем, имеющих ту же онтологию обрабатываемой информации. Основные преимущества такой технологии – процедурные знания отделены от декларативных, решатель задач является повторно-используемым для класса задач с общей онтологией обрабатываемой информации. Данная технология, в основе которой лежит объектно-ориентированный подход к формированию онтологий поддерживается платформой Протеже (Protege) [2]. В онтологии определяется иерархия классов для представления основных ее объектов, множество слотов для описания их свойств и отношений между ними, а также множество экземпляров классов. В процессе проектирования онтологий сначала формируются метапонятия верхнего уровня, затем по ним порождаются метапонятия следующего уровня и т. д. Решатель задач состоит из трех основных компонентов: описания алгоритма, включающего все шаги решения задачи, описания так называемой онтологии метода, включающего спецификации форматов входных и выходных данных, а также непосредственно программного кода, реализующего метод. Пользовательский интерфейс не отделяется от метода решения задачи.
Однако в данном подходе отсутствует четкое разделение между двумя системами понятий. Такой подход, с одной стороны, позволяет быстро и относительно просто сконструировать небольшую предметную онтологию, однако, с другой стороны, отсутствует четкое разделение между базой знаний и онтологией и, таким образом, разделение труда между инженерами знаний (формируют онтологию через интерфейс, ориентированный на метаязык) и экспертами (формируют базу знаний через сгенерированный по онтологии интерфейс).
Помимо этого, обе технологии основаны на традиционном подходе к сопровождению программных средств, при котором версия системы передается конечному пользователю и который не предусматривает оперативное устранение возможных ошибок, централизованного хранения и обновления онтологий и баз знаний, модификацию алгоритма решения задачи, сводя эти процессы лишь к смене/обновлению версий системы.
В данной работе в качестве возможного решения указанных проблем предлагается облачная платформа, поддерживающая следующие технологические принципы разработки, сопровождения и использования интеллектуальных систем:
– все информационные ресурсы (онтологии, знания, данные) имеют единое унифицированное декларативное представление (семантическая сеть) [3, 4] и не включают метод решения задачи;
– формирование и сопровождение знаний осуществляется экспертами предметной области на основе онтологий;
– пользовательский интерфейс для эксперта генерируется по онтологии;
– метод решения задачи разбивается на подзадачи, где каждой подзадаче соответствует агент;
– для доступа агентов к информационным ресурсам, имеющим унифицированное представление, предусмотрены программные интерфейсы;
– интеллектуальная система предоставляется пользователю как интернет-сервис.
Платформа для разработки интернет-сервисов
Платформа для разработки интернет-сервисов представляет собой программно-информационный интернет-комплекс IACPaaS (Intelligence Application, Control and Platform as a Service) [5], предоставляющий контролируемый доступ и единую систему администрирования для создания и использования интеллектуальных сервисов и их компонентов, представленных семантическими сетями, поддержку функционирования агентов (через передачу и обработку сообщений, запуск методов).
Интернет-комплекс IACPaaS основан на технологии облачных вычислений и обеспечивает удаленный доступ конечным пользователям к интеллектуальным системам, а разработчикам и управляющим – к средствам создания интеллектуальных систем и управления ими.
Комплекс является развитием многоцелевого компьютерного банка знаний, разработанного ранее для создания и использования информационных ресурсов различных уровней общности (онтологий, знаний, данных), представленных семантическими сетями [6]. Основными архитектурными компонентами интернет-комплекса IACPaaS являются: фонд, административная система и виртуальная машина.
Фонд представляет собой совокупность единиц хранения – программных и информационных ресурсов различных типов; для удобства навигации он разделен на предметные области, а те, в свою очередь, на разделы; каждый раздел содержит относящиеся к нему единицы хранения: прикладные (в частности, интеллектуальные сервисы) и инструментальные средства (средства разработки и управления), их агенты, информационные ресурсы.
Административная система предназначена для всех пользователей проекта. С ее помощью они могут просматривать доступное им содержимое фонда; подавать заявки на регистрацию в предметных областях фонда, на регистрацию полномочий на использование системных и прикладных интернет-сервисов платформы, на модификацию фонда, а также реализовывать свои полномочия.
Виртуальная машина представляет собой совокупность трех процессоров (процессора информационных ресурсов, процессора решателей задач, процессора пользовательского интерфейса), а также ряда вспомогательных средств. Каждый процессор представляет собой набор функций для поддержки соответствующих компонентов интернет-сервиса.
Процессор информационных ресурсов представляет собой набор функций обработки информационных ресурсов фонда, доступный разработчикам и сопровождающим виртуальной машины, а также разработчикам и сопровождающим кода программных компонентов.
Процессор решателей задач состоит из инициализатора и коммуникационной системы. Инициализатор осуществляет запуск прикладных и системных сервисов. Коммуникационная система представляет собой набор функций, предназначенный для активизации агентов решателей задач, а также формирования и передачи сообщений между ними.
Процессор пользовательского интерфейса состоит из совокупности интерфейсных агентов и интерпретатора интерфейса. Интерфейсные агенты формируют описание абстрактного интерфейса пользователя в соответствии с моделью абстрактного интерфейса. Интерпретатор интерфейса выполняет построение конкретного пользовательского интерфейса на основе описания абстрактного интерфейса и модели конкретного интерфейса.
Информационные ресурсы
Информация имеет самостоятельную ценность и должна создаваться и использоваться как людьми независимо от средств их обработки, так и компьютерными программами, а также поддерживаться в актуальном состоянии длительное время.
Компьютерное представление любого типа информации (метаонтологии, онтологии, знания, данные) назовем информационным ресурсом. Наибольшее распространение в настоящее время получили декларативные модели представления информации. Для таких моделей можно выделить два основных подхода к их формированию: непосредственное формирование информации в соответствии с формализмом ее представления (языком) и на основе метаинформации (онтологии), которая является концептуальной системой, в терминах которой эта информация формируется. Способ формирования информации в терминах метаинформации получает все большее распространение.
К настоящему времени предложены три способа формирования информации на основе метаинформации [7]: на основе объектно-ориентированной метаинформации (объектные метамодели), на основе реляционной модели метаинформации, на основе метаинформации, представленной графовыми структурами, в частности, семантическими сетями.
Объектно-ориентированная метамодель основана на представлении информационных объектов предметной области как классов сущностей, имеющих множество атрибутов, с возможностью представления частных понятий через более общие с помощью is-a-иерархии вплоть до конкретных примеров этих понятий, причем количество таких уровней уточнения неограниченно.
Реляционная модель предметной области представляет собой алгебраическую систему, в которой выделяются подмножества объектов носителя информации (классы), отношения между классами (функциональные и нефункциональные) и связи между ними (кортежи этих отношений).
Порождение, основанное на метаинформации, представленной семантическими сетями, основано на двухуровневой модели: в терминах метаинформации формируется (объектная) информация – семантическая сеть.
В данной работе все информационные ресурсы имеют единое унифицированное декларативное представление – в виде семантической сети. Основной особенностью информационных ресурсов является их представление в виде пары информация – ссылка на метаинформацию. Метаинформация информационного ресурса является языком, в терминах которого формируется информация. Такой язык понятен экспертам предметной области, что позволяет им без посредников (инженеров знаний) создавать и сопровождать информационные ресурсы. Любая информация имеет ссылку на метаинформацию, по которой она порождается.
Информационные ресурсы имеют различный по продолжительности жизненный цикл: время жизни информационного ресурса может быть неограниченно (например, базы знаний), а может ограничиваться временем работы сервиса (в каждой программной системе в процессе функционирования создаются временные информационные ресурсы – промежуточные данные, которые необходимы для реализации удобного и эффективного алгоритма решения задачи). Временные информационные ресурсы имеют то же представление, что и информационные ресурсы с неограниченным временем жизни.
Каждый информационный ресурс с неограниченным временем жизни может иметь множество версий. Каждая версия информационного ресурса может иметь статус «публичная». Если версии присвоен такой статус, то она становится недоступной для модификации (например, окончательно утвержденная экспертами база знаний), и при этом к ней получают доступ все пользователи предметной области (а не только ее разработчики). Решение о присвоении версии информационного ресурса статуса «публичная» принимает администратор предметной области, после чего оно должно быть одобрено администратором проекта.
Программные интерфейсы информационных ресурсов
Основная задача данного компонента – обеспечить разработчика решателя задач набором программных интерфейсов для доступа к информационным ресурсам, скрывающим формат их внутреннего представления, что позволяет разработчикам использовать такой тип данных, не задумываясь о деталях внутренней организации информации. Этот концептуальный подход позволяет объединить тип данных с множеством операций, которые допустимо выполнять над ним. Таким образом, достигается разделение использования типа данных и операций над ним от деталей внутреннего представления данных и реализации операций.
Стандартный подход, реализуемый в решателях задач интеллектуальных систем, основан на фиксации формата внутреннего представления информационных ресурсов (баз знаний и данных), где большую часть метода решения «занимают» процедуры доступа к данным, представленным в этом формате.
Для семантических сетей в работе [6] предложен набор программных интерфейсов для обеспечения доступа к семантическим сетям, их создания, редактирования, контроля непротиворечивости, как со стороны программной системы, так и со стороны редактора [8]. Его использование упростило разработку и манипулирование знаниями, представленными семантическими сетями, однако предложенные программные интерфейсы не поддерживали логическую семантику: поддержка соответствия между метаинформацией и информацией полностью возлагалась на разработчика решателя задач.
В данной работе набор программных интерфейсов обеспечивает доступ к информационным ресурсам, а также поддерживает соответствие между метаинформацией и информацией. Основными группами функций программного интерфейса являются: функции получения значений атрибутов вершин и дуг сети, функции порождения вершин и дуг сети, функции редактирования значений атрибутов вершин и дуг сети, функции проверки различных условий, функции навигации по семантической сети и др.
Мультиагентные интернет-сервисы
Интеллектуальный мультиагентный интернет-сервис представлен своим декларативным описанием, которое включает в себя, в общем случае: (1) входные, выходные и собственные информационные ресурсы различного уровня общности (содержательно это могут быть онтологии, базы знаний, базы данных и т. д.), (2) решатель задач, представленный описанием множества агентов и, возможно, управляющим графом, и (3) пользовательский интерфейс.
Входные, выходные, собственные информационные ресурсы
Входные и выходные информационные ресурсы сервиса являются его входными и выходными формальными параметрами (определяющими классы обрабатываемых информационных ресурсов). Значениями этих параметров являются информационные ресурсы, для которых ресурсы-параметры являются онтологиями. Информационные ресурсы, являющиеся значениями входных параметров интернет-сервиса, являются не изменяемыми, а информационные ресурсы, являющиеся значениями выходных параметров интернет-сервиса, могут изменяться при их обработке агентами сервиса. Собственные информационные ресурсы используются для хранения собственных данных, настроек сервиса, управляющих логикой его работы. Следует отметить, что в силу специфики решаемой сервисом задачи каждый из перечисленных типов информационных ресурсов может отсутствовать.
Решатель задач
Решатель задач интеллектуального интернет-сервиса представлен множеством агентов и может включать управляющий граф. Среди множества агентов должен быть выделен единственный инициализирующий агент, посылая инициализирующее сообщение которому, платформа инициирует работу всего сервиса.
Агенты
Агент – повторно используемый программный компонент, взаимодействующий с другими агентами посредством приема и передачи сообщений [9, 10]. Повторная используемость означает, что агент может быть составной частью различных сервисов. В общем случае агент состоит из двух частей – декларативной и процедурной. Декларативная часть представляет собой спецификацию агента – информационный ресурс, в котором описана структура агента и которая должно использоваться средствами облачной платформы для автоматической генерации шаблона его исходного кода, а также для его внедрения в общую инфраструктуру платформы. Процедурная часть (код агента) – есть код консеквентов всех его продукций.
Декларативная часть включает:
– название и описание агента (они будут доступны всем авторизованным пользователям проекта при просмотре содержимого фонда);
– внутреннее имя агента, которое будет использовано при формировании имени класса агента на этапе генерации класса-заготовки исходного кода агента;
– описание структуры (онтологии) информации, доступной из любого блока продукций агента и используемой для хранения собственных данных, настроек агента, управляющих логикой его работы и т. п.– локальной структуры данных (может отсутствовать, если не требуется хранить такого рода информацию (все нужные данные доступны через сообщения));
– описание множества блоков продукций агента.
Описание каждого блока продукций включает:
– описание назначения блока продукций;
– описание шаблона входных сообщений – сообщений, инициирующих выполнение данного блока продукций агента;
– описание шаблонов выходных сообщений – сообщений, создаваемых в процессе выполнения данного блока продукций агента и рассылаемых адресатам после завершения выполнения данного блока (может отсутствовать, если при выполнении данного блока продукций агента не должны создаваться и посылаться какие-либо сообщения).
Сообщение – это временный информационный ресурс, жизненный цикл которого начинается с его создания некоторым агентом по его шаблону, затем следует посылка этого сообщения другому агенту, который его получает и обрабатывает. После этого сообщение прекращает свое существование. Онтология сообщения определяет язык взаимодействия агентов, т. е. агент, посылающий сообщение другому агенту, должен знать шаблон этого сообщения. Таким образом, агенты взаимодействуют друг с другом на языках, задаваемых онтологией сообщений (каждая онтология сообщений – информационный ресурс, имеющий унифицированный способ представления (семантическая сеть)).
Агент включает блоки продукции (методы), выполняющие обработку принимаемых им сообщений с целью решения связанной с агентом подзадачи. Для каждого блока продукций определен свой шаблон сообщения. Результатом работы метода может быть формирование и посылка сообщения конкретному агенту, либо множеству агентов, а также формирование или модификация некоторого информационного ресурса.
Продукция состоит из условия (антецедента) и действия (консеквента). Антецедент такой продукции используется для анализа сообщения, выбора применимого метода и передачи ему информации из сообщения; консеквент, по сути, является вызовом метода.
Все онтологии (шаблоны) сообщений содержатся в фонде IACPaaS. Для передачи сообщения некоторому агенту приложения используется готовый шаблон или проектируется новый шаблон (который может стать повторно используемым), задающий структуру передаваемой информации.
Агенты могут быть различных типов: управляющие, обрабатывающие и интерфейсные. Они могут быть как проблемно-ориентированными, так и проблемно-независимыми.
Агент может послать сообщение:
– по обратному адресу (агенту, от которого он получил сообщение, инициировавшее работу блока продукций);
– агенту, указанному в шаблоне сообщения;
– агенту, указанному в управляющем графе;
– заданному разработчиком в коде блока продукций агенту.
Управляющий граф
Управляющий граф применяется, когда в состав решателя задач включаются проблемно-независимые агенты, которые, в отличие от проблемно-ориентированных, не должны отправлять сообщения друг другу напрямую. В этом случае для решателя задач интернет-сервиса формируется свой управляющий граф, который используется процессором решателей задач при обработке блока продукций некоторого агента для выбора того агента, которому предназначено передаваемое сообщение. Управляющий граф состоит из вершин, соответствующих блокам продукций агентов, и дуг, соответствующих посылкам сообщений другим агентам. Вершина управляющего графа имеет уникальное имя и содержит ссылку на агента решателя задач, в который входит блок продукций, представляемый этой вершиной управляющего графа. Дуги управляющего графа соответствуют передачам сообщений между блоками продукций агентов. Дуга управляющего графа имеет уникальную метку и содержит ссылку на шаблон передаваемого сообщения, а также ссылки на адресата и отправителя сообщения.
Пользовательский интерфейс
Для упрощения разработки пользовательского интерфейса в состав агентной платформы входит системный агент «Вид». Агент «Вид» взаимодействует с Web-сервером, обрабатывающими агентами (а те – с интерфейсными агентами) и интерпретатором интерфейса следующим образом:
– через клиентское программное обеспечение (браузер) формируется запрос к Web-серверу;
– Web-сервер обрабатывает информацию о наступившем событии и передает ее агенту «Вид»;
– агент «Вид» формирует сообщение, в которое помещает полученные от Web-сервера данные, и посылает его обрабатывающему агенту решателя задач – интерфейсному контроллеру;
– интерфейсный контроллер принимает сообщение и выполняет необходимые действия, взаимодействуя, возможно, при этом с другими агентами решателя задач.
Далее при необходимости отобразить результаты обработки события в интерфейсе:
– обрабатывающий агент, обращаясь к интерфейсным агентам, формирует описание абстрактного интерфейса (в соответствии с моделью абстрактного интерфейса[1]), после чего создает и посылает агенту «Вид» сообщение, в которое инкапсулирует это описание;
– агент «Вид» принимает сообщение, по описанию абстрактного интерфейса и модели конкретного интерфейса формирует описание фрагмента конкретного интерфейса (обращаюсь к интерпретатору интерфейса) и отправляет его Web-серверу;
– Web-сервер формирует ответ браузеру, который визуализирует фрагмент пользовательского интерфейса.
Заключение
В работе описана платформа для разработки интеллектуальных интернет-сервисов. Основная цель создания платформы состоит в снижение за счет ее использования трудоемкости разработки и, прежде всего, сопровождения интернет-сервисов.
Для достижения этой цели все информационные ресурсы интеллектуального сервиса представляются (в отличие от используемых в настоящее время подходов к разработке интеллектуальных систем) в едином унифицированном виде – в форме семантических сетей. При этом поддерживается единый для всех компонентов набор программных интерфейсов для доступа к ним и модификации. Представление решателя задач как совокупности агентов, а также единый формат представления баз знаний и данных позволяет повторно использовать эти компоненты для создания различных интеллектуальных интернет-сервисов. База знаний формируется на основе онтологий, что позволяет их создавать и сопровождать экспертам предметной области.
Использование облачной платформы IACPaaS для разработки интернет-сервисов соответствует современным требованиям к проектированию и реализации программных систем и обеспечивает ее жизнеспособность (адаптируемость и управляемость) за счет того, что все компоненты сервиса доступны разработчикам для поддержания их в актуальном состоянии. Разработка агента сводится к описанию компонентов его декларативной составляющей, а также написанию процедурного кода консеквентов множества продукций. Разработка сервиса сводится к написанию его декларативной спецификации, а его сопровождение – к их изменению.
Работа выполнена при финансовой поддержке РФФИ (проект ) и ДВО РАН (проект 12-II-УО-01И-001).
Библиографические ссылки
1. С. Знание, организованное в виде прототипов, для экспертных систем // Кибернетический сборник. – М.: Мир, 1985. – №22. – С. 221-277.
2. Protege. [Electronic resource]. URL: http://protege. stanford. edu/ (дата обращения 31.05.2013).
3. П. Расширенные семантические сети для представления и обработки знаний // Системы и средства информатики. – Ин-т проблем информатики РАН. – М. – 1993. – №. 4. – С.70-83.
4. Lehmann F. W. Semantic Networks // Computers & Mathematics with Applications. – vol.23. – 1992. – №2-5.
5. В., С., А., М., В., А., Б., А. Проект IACPaaS. Комплекс для интеллектуальных систем на основе облачных вычислений // Искусственный интеллект и принятие решений. – 2011. – №1. – С.27-35.
6. А., С. Компьютерные банки знаний. Многоцелевой банк знаний // Информационные технологии. – 2006. – №2. – С. 2-8.
7. В., С., А., М., , Агентный подход к разработке интеллектуальных Интернет-сервисов // Труды конгресса по интеллектуальным системам и информационным технологиям "IS&IT'12" (2-9 сентября 2012 г., Россия, Дивноморское). – М.: Физматлит. – 2012. – Т.1. – С. 218-223.
8. А., С. Компьютерные банки знаний. Универсальный подход к решению проблемы редактирования информации. – Информационные технологии. – 2006. – №5 – С. 25-31.
9. И. Многоагентные системы: современное состояние исследований и перспективы применения // Новости искусственного интеллекта. – 1996. – №1. – С.44-59.
10. Б. Агенты, многоагентные системы, виртуальные сообщества: стратегическое направление в информатике и искусственном интеллекте // Новости искусственного интеллекта. – 1998. – №2. – С.5-63.
УДК 004.422.8
© , ,
, 2013
СИНХРОНИЗАЦИЯ ГИГАПИКСЕЛЬНЫХ ВИДЕОПОТОКОВ
НА ВИДЕОСТЕНАХ
– канд. техн. наук, науч. сотр, e-mail: magsend@gmail.com; Н. – канд. техн. наук, зав. лаб., e-mail: andrew@kiae.ru; – канд. физ-мат. наук, зав. лаб., e-mail: poyda@wdcb.ru; – мл. науч. сотр., e-mail: novikov@wdcb.ru; – лаборант-исследователь, e-mail: argentum_no3@ ***** (НИЦ «Курчатовский институт»)
Рассматривается метод визуализации видеопотоков высокого разрешения, организованных по принципу видеопирамид, на многодисплейных видеостенах. Основное внимание уделяется проблемам синхронизации видеотайлов и интерактивного взаимодействия пользователей с многоузловой системой.
Введение
В современной научной среде гигантские объемы данных порождаются различного рода сенсорами, научными приборами, системами управления бизнесом, социальными сетями и другими источниками. Для их продуктивного использования необходимы соответствующие технологии, в том числе - удобное визуальное представление данных. При этом для многих научных и технических задач требуется интерактивная визуализация изменяющихся динамических сцен в гигапиксельных разрешениях. К таким задачам можно отнести визуализацию развития вселенной во времени на всех уровнях детализации, взаимодействия группы белков с точностью до атомов, наблюдение за процессами, проходящими внутри клетки, демонстрация карты погодных явлений в реальном времени с высокой точностью.
Для визуализации высокого разрешения требуется не только программное обеспечение, но и соответствующие технические платформы. Все чаще в научных исследованиях используются видеостены сверхвысокого разрешения, состоящие из десятков дисплеев, управляемых кластером визуализации. Каждый компьютер такого кластера обычно используется для вывода изображения на 2-4 дисплея.
Для решения задачи интерактивной визуализации изменяющихся динамических сцен на видеостенах высокого разрешения можно использовать видеопирамиды [1].
Видеопирамиды – это видеопоток, предварительно нарезанный на смежные участки стандартного формата. При этом нарезается не только оригинальный видеопоток, но и его уменьшенные по масштабу копии, образуя так называемую «пирамиду». В зависимости от требуемого для визуализации масштаба и области видео, на экран выводится только часть нарезанных участков, аналогично тому, как Google Maps позволяет просматривать многомасштабные пирамиды изображений.
Основной недостаток использования видеопирамид состоит в том, что каждый фрамгент видеопотока представляет собой отдельный видеофайл и должен быть декодирован независимо от остальных. При демонстрации видеопотока необходима синхронизация всех видеофайлов. Для визуализации видеопирамиды на одном компьютере, эта проблема решается средствами HTML5 и ECMAScript, но данный метод не может быть использован для видеостены, так как требуется синхронизация не на одном компьютере, а на нескольких.
Архитектура многодисплейных видеостен
Архитектура многодисплейных видеостен детально представлена на рисунке 1 на примере технологии SAGE [2]. SAGE состоит из Free Space Manager, SAGE Application Interface Library (SAIL), SAGE Receiver (приемника) и пользовательского интерфейса. Free Space Manager является центральным блоком управления, который обрабатывает пользовательские команды, полученные через графический интерфейс (например, перемещение окна, изменение его размера) и управляет потоками пикселей между SAIL и SAGE приемниками. SAIL перенаправляет выходные пиксельные потоки от приложений к соответствующим SAGE приемникам. Когда выполнение заданных функций завершено, SAIL и SAGE ресиверы информируют Free Space Manager, обновляется статус SAGE.
Задача о синхронизации видеопотоков
Задача о синхронизации независимых видеопотоков на компьютерах, соединённых локальной сетью, решена в некоторых реализациях проекта MPlayer. Однако для воспроизведения видеопирамиды на одном компьютере должна быть возможность запуска как минимум четырёх полностью (с точностью до десятых секунды) синхронизованных плееров, чтобы они покрывали экран полностью, даже при передвижении видео или изменении масштаба просмотра.
Архитектура разработанной системы визуализации
В разработанной системе визуализации на каждом мониторе видеостены запущено несколько копий видеоплеера MPlayer, вплотную состыкованных друг с другом без промежуточных панелей, и полностью покрывающих всю площадь экрана видеостены (рисунок 2). Дополнительные модули позиционирования плееров (Video Positioning System), запускаемые на каждом узле видеостены, распределяют каждому плееру видеотайлы, которые плеер должен проигрывать. Синхронизация между узлами и модулями позиционирования осуществляются общим контроллером (Server State Cast).
Задача о позиционировании нескольких плееров в пространстве, их передвижении, масштабировании, так же как и задача выбора нужного фрагмента, по отдельности решены во многих приложениях, но ни в одном программном продукте они не объединены вместе. Для того чтобы исправить все недостатки, был переписан код MPlayer2 и созданы управляющие программные компоненты, автоматизирующие положение плееров, их запуск и синхронизацию.

Рис. 1. Архитектура кластера визуализации для многодисплейной видеостены
Для разработки программного модуля управления запуском плееров, их положением и размером был выбран язык C++ и библиотека Qt [3] версии 4. В качестве протокола синхронизации выбран протокол UDP, который обеспечил автономность и независимость программ друг от друга.
Из кода MPlayer в код одной из стабильных версий MPlayer2 был внедрён UDP-протокол синхронизации двух плееров. После изменений в коде, MPlayer2, запущенный с параметром «-udp-master», посылает UDP пакеты сразу на несколько портов, следующих друг за другом, заданных парой параметров: «-udp-port» и «-udp-port-range», задающих первый порт и количество портов соответственно. Если плеер будет запущен с параметром «-udp-slave», то он выбирает первый свободный порт из диапазона, заданного теми же параметрами, резервирует его под себя и использует в качестве порта для синхронизации. Таким образом, плееры сами выбирают открытые окна для синхронизации. Предоставлены так же параметры для выбора адресов вещания и захвата. Изменённый код MPlayer2 опубликован в Интернете по адресу
https:///complynx/mplayer2/
Для запуска плееров, их синхронизации, выбора нужных фрагментов для воспроизведения из файлового хранилища, был разработан оконно-графический интерфейс. Текущая версия программы опубликована в Интернете по адресу https://bitbucket. org/complynx/tiledvideos.
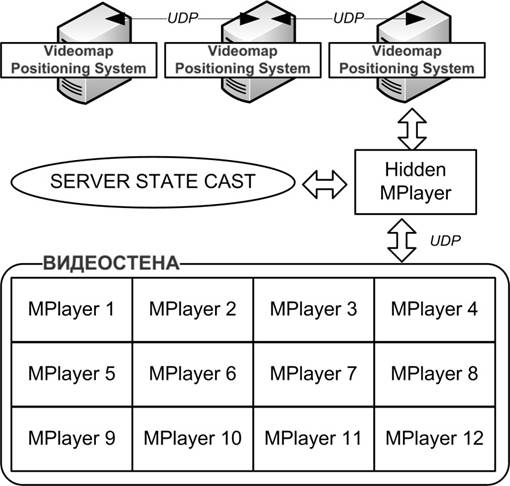
Рис. 2. Архитектура разработанной системы визуализации
На этапе реализации системы был выявлен ряд проблем и ограничений, часть из которых следует описать и указать их последствия и возможные решения.
1. Задержки декодера. При получении сообщения о позиции видео на серверном плеере (компонента «Server state cast»), клиентский плеер не успевает быстро перейти на требуемый кадр, в связи с чем в следующий момент от него снова потребуется перестроение кадров.
2. Недостаточная для Full-HD видео скорость чтения с диска.
3. Проблема неполных кадров. Все плееры на экране должны полностью покрывать его пространство. В результате могут появиться плееры, которые помещаются на экран только частично, однако данные эти плееры требуют в полном объеме.
4. Количество одновременно воспроизводимых видеотайлов на одном узле. Опытным путём было получено, что число одновременно воспроизводимых видеотайлов не может превышать шестнадцати. При превышении этого количества плееры не будут отображать видео, или будет перезагружен графический сервер X. org.
Выводы
Разработанный метод визуализации видеопирамиды на видеостене может быть использован для визуализации сверхбольших наборов данных в фундаментальных приложениях, таких как астрономия, климатология, газо - и гидродинамика, механика сплошных сред, геофизика, так и в чисто практических целях, например для экологического мониторинга или дистанционного зондирования.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
