
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Алгоритм формирования базиса воспроизводится и использовался нами нами в расчетах без изменений, за исключением 1) исправления той ошибки, что каждая основа, в скольких бы экземплярах она ни присутствовала в словаре, учивалась в исходном алгоритме только один раз; 2) сокращения алфавита с принятых авторами данного метода 45 символов до 33 используемого нами. Изменения были внесены, чтобы заранее не ставить метод наичастого в проигрышное положение. (45–символьный алфавит был принят по той причине, что словарь включал одну цифросодержащую словоформу — «16–разрядный». Тогда, основываясь на мощном корпусе слов типа «1,5–миллиметровый», «c–квадрат», «À–класс», «N–грамма» и «Windows–подобный», следовало бы пополнить алфавит за счет латинского, греческого и иврита, а также расширить словарь конструкциями типа «рипс лаовай», заметим, надежно удовлетворяющими «частотному критерию» словоупотребления.)
1. Формирование базиса. В базис вносится весь алфавит. Затем выписываются все l–подстроки всех основ (l ³ 2). Подсчитывается частость каждой подстроки — общее число ее вхождений в основы. Подстрокам присваиваются веса, равные произведению частости на длину подстроки. Подстроки упорядочиваются по убыванию весов. Первые N–A (где N — априори заданный допустимый размер базиса, а A — размер алфавита) самых весомых подстрок из этого списка вносятся в базис. Строки базиса упорядочиваются по убыванию длины.
2. Разложение основ по сформированному базису производится следующим образом. В первую позицию очередной основы ставится указатель. Затем производится просмотр базиса, начиная с самой длинной строки, на предмет поиска строки, совпадающей с основой с помеченного указателем места. Когда такая строка найдена, указатель смещается по основе на длину этой строки и процедура поиска в базисе повторяется.
Чтобы избежать неоднозначности, заметим, что на этапе формирования базиса подсчитываются все вхождения подстрок, включая самопересекающиеся, как, например, для подстроки «ере» в слове «перерешать». Подстроке «ере» в этом случае будет назначена частость 2. (Впрочем, частость самопересечений ничтожна относительно частости самих допускающих самопересечение строк.)
Нужно сказать, что процедура разложении по базису очень эффективна. Число компонент базиса, покрывающих основу, оказывается больше минимального для данного базиса не более чем в 3% случаев.
Что касается алгоритма формирования базиса, то представление о его качестве дает число используемых в разложениях компонент сформированного им 256–компонентного базиса (табл. 2). Поскольку базис, в принципе, допускает несколько разложений слова на одинаковое число компонент, нет оснований утверждать, что не существует еще меньшего подбазиса, обеспечивающего такой же тираж разложения.
Табл. 2. Число используемых в разложении компонент базиса, построенного методом наичастого
Первая буква основ | Число используемых среди 256 компонент базиса | Первая буква основ | Число используемых среди 256 компонент базиса | Первая буква основ | Число используемых среди 256 компонент базиса |
А | 228 | К | 249 | Ф | 214 |
Б | 238 | Л | 207 | Х | 174 |
В | 253 | М | 244 | Ц | 155 |
Г | 226 | Н | 246 | Ч | 169 |
Д | 248 | О | 254 | Ш | 209 |
Е | 119 | П | 253 | Щ | 114 |
Ж | 166 | Р | 247 | Э | 198 |
З | 252 | С | 248 | Ю | 85 |
И | 216 | Т | 229 | Я | 131 |
Й | 20 | У | 235 |
Как средство борьбы с зияющими пустотами можно предложить очевидный и не требующий повторного разложения словаря способ оптимизации выделенного базиса. Именно, по ходу построения минимальных разложений основ нужно подсчитывать не только тираж компонент, но и тираж их сочетаний в разложениях. Разложив все основы, упорядочим эти сочетания по убыванию тиража, после чего можно поступить совершенно в духе метода наичастого, перенеся в новый базис все компоненты базиса, имеющие ненулевой тираж (это, так сказать, «алфавит»), а в оставшиеся свободные места занеся наиболее частые — по тиражу — сочетания. Можно поступить и более разумно, в духе изложенного в главе 5 метода построения базиса с учетом зависимостей между строками; только на этапе оптимизации базиса это будет учет зависимостей между «строками», составленными не из букв, а из компонент исходно полученного базиса. При этом не требуется ни резервировать место под «алфавит», ведь при включении в базис построенных на нем «строк» тираж его компонент изменится (например, у некоторых обнулится), ни наличия в исходном базисе пустот.
Такая заключительная внутренняя оптимизация базиса применима к базисам, полученным любым из описанных в статье методов, однако именно результаты метода наичастого дают больше всего оснований для ее применения.
4. Метод надбазиса
С не меньшим успехом, как убедится читатель, излагаемый ниже метод можно было бы назвать методом частотного шаманизма, поскольку схема метода, допуская, но не требуя явного учета взаимной зависимости строк, в одной из реализаций полагается на возможность некоей «самооптимизации». Суть метода состоит в том, чтобы как-то сформировать базис большего размера, чем требуется, построить разложения по этому надбазису, а по результатам разложения выделить из надбазиса базис допустимого размера. Обоснования для тех или иных решений в этом методе носят характер правдоподобных (не более того) рассуждений.
Метод основан на том, что если процедура формирования надбазиса не слишком противоестественна, надбазис будет содержать строки, построенный из которых базис даст лучшее среднее покрытие, чем базис, сразу сформированный той же процедурой. При этом мы не ожидаем, что в надбазис войдут все компоненты хотя бы одного из оптимальных базисов словаря и не надеемся выделить из надбазиса лучший из неявно содержащихся в нем базисов. Если требуемый размер базиса N составляет порядка двух сотен, а размер надбазиса P — не менее трех сотен, то число вариантов выбора базиса из надбазиса CPN, оказывается не меньшим
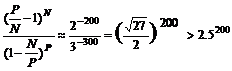
Прямой перебор компонент такого надбазиса не годится (из чего, в частности, следует, что включение компонент в надбазис должно быть все–таки по возможности разумным). Если попытаться для выделения базиса воспользоваться тиражом компонент надбазиса, подобно частостям в методе наичастого, то нужно иметь в виду, что чем больше размер надбазиса, тем вероятнее, что компоненты лучшего из содержащихся в нем CPN базисов войдут не (только) в минимальные разложения по надбазису, но в разложения, которые содержат на 1, 2 и т. д. компоненты больше минимальных.
Второе. Пусть мы решили, разложения в каком радиусе от минимальных должны рассматриваться. Например, это будет 0–радиус, то есть учитываются тиражи компонент надбазиса только в минимальных разложениях. Но тогда каким типом процедуры разложения воспользоваться — дающей первое встреченное минимальное разложение или процедурой, дающей все минимальные разложения.
Если воспользоваться первым типом разложения, то мы тем самым неявно допускаем, что процедура «оказывает предпочтение» компонентам какого–то одного из содержащихся в надбазисе эффективных базисов. Действительно, если минимальными разложениями основы w1 являются ab и cd, а основы w2 — be и fg, то первыми найденными процедурой разложениями могут оказаться не (использующие только 3 разных компоненты) ab и be, а любая другая пара, «размазывающая тираж» по 4 разным компонентам. Единственное основание для допущения — регулярный характер детерминированной процедуры разложения и самих основ.
Поиск минимального разложения слова состоит в том, что, не найдя разложения на меньшее число компонент, мы увеличиваем число искомых компонент m на единицу, и перебираем все разбиения слова на m частей пока очередное разбиение не окажется разложением на компоненты надбазиса. Пусть процедура выглядит так: перед каждым из последних m – 1 символов слова выставляется разделитель, эти разделители постепенно перемещаться к началу слова, задавая очередное разбиение. Это означает, что первым из всех минимальных разложений будет найдено то, у которого первая компонента самая длинная, вторая — самая длинная из минимальных разложений, начинающихся с первой компоненты, и т. д.. В этой процедуре разбиения справа–налево (она же — разложения слева–направо) регулярность ограничивается тем, что если w1 представима как ab и cd, а w2 — как ae и fg, то при условии, что c и f короче a, процедура выдаст в качестве первых минимальных разложений ab и ae, то есть разложения увеличивающие тираж не у 4, а у 3 компонент. Более оптимистичная формулировка могла бы звучать так: чем длиннее совпадение начала слов, тем ближе их разложения. Аналогично, при построении разложения справа–налево, сказанное относилось бы к концам слов.
Строя разложения слева–направо и справа–налево, мы, безусловно, получим разложения одного размера, но это будут, вообще говоря, разные разложения на разные компоненты. Соответственно, хотя разные процедуры обхода слова дадут одинаковые суммарный тираж компонент надбазиса и среднее покрытие надбазиса, но распределения тиражей компонент надбазиса окажутся разными, а тем самым из надбазиса будут выделены разные базисы с разными величинами среднего покрытия. Например, для В–словаря лучшими при замащивании основ слева–направо будут общий тираж 31119 и среднее покрытие 1.84, достигаемые на базисе, выделенном из полученного взвешиванием F(f, l) = fl0.5 надбазиса размером 388. При замащивании справа–налево значения, порождаемые этим надбазисом равны 31009 и 1.85, а лучшими будут 30, достигаемые при 404–компонентном надбазисе, полученном взвешиванием F(f, l) = fl0.75. Оказывается, различие результатов при разных направлениях замащивания достаточно невелико.
Однако можно попытаться, не полагаясь на (как мы убедились, достаточно ограниченную) чудодейственную способность регулярных процедур разложения, попытаться целенаправленно выделить базис по всем разложениям в выбранном радиусе. Проще всего в 0–радиусе, то есть по всем минимальным. Совокупность таких разложения есть смесь разложений, построенных на компонентах, принадлежащих разным, причем неизвестным нам базисам, обеспечивающим лучшее (для данного надбазиса) качество разложения. И соответственно использованные в разложениях компоненты — смесь компонент разных, частично пересекающихся, эффективных базисов. А задача состоит в том, чтобы правильно расщепить смесь, отнеся каждое из разложений одной основы к соответствующему эффективному базису, либо выделить хотя бы один такой базис. Подробнее об этом в 4.2. (Заметим, что названные задачи не совпадают с задачей выделения из надбазиса его подбазисов минимального, но априори не ограниченного размера, дающих то же среднее покрытие, что надбазис, то есть таких подбазисов, для которых хотя бы одно из разложений каждого слова было построено на компонентах подбазиса.)
Рассмотрим последовательно выполняемые в методе надбазиса действия:
1) каким-то образом формируется надбазис, размер которого либо не больше априорной величины, либо таков, что на надбазисах большего размера качество базисов, выделяемых из надбазиса по тиражам использования компонент в минимальных разложениях, только ухудшается;
2) выполняем цикл по размерам надбазиса, начиная с выбранного до какого-то минимального (но заведомо не меньшего допустимого размера базиса) с достаточно большим шагом уменьшения размера надбазиса. (Это значит, что только для самого первого надбазиса размер определяется в процессе его формирования, для всех остальных размер следующего меньше предыдущего на величину шага.) По сформированному надбазису строятся минимальные разложения всех слов словаря или, если словарь достаточно большой, выборки из него. По этим разложениям получаем тираж компонент надбазиса. По тиражу и, возможно, с учетом зависимостей между компонентами из надбазиса выделяется базис требуемого размера. После чего по этому базису строятся минимальные разложения для словаря или выборки и вычисляется величина среднего покрытия;
3) выясняется интервал размеров надбазисов, в котором средние покрытия выделяемых из них базисов оказались выше;
4) на выделенном интервале повторяется описанная процедура построения надбазисов и выделения из них базисов, только с относительно небольшим шагом изменения размера доуточняющих надбазисов. Базис, на котором достигается максимум среднего покрытия, объявляется лучшим.
Практически каждое действие требует пояснения и обоснования.
4.1. Выбор надбазиса
Здесь есть два связанных вопроса — как выбирать надбазис и каким должен быть его размер, чтобы можно было воспользоваться результатами разложения по надбазису для выделения из него базиса.
При выборе строк в базис в методе наичастого использует процедура взвешивания. Что можно сказать о двух строках–кандидатах в базис, ничего не зная или осознанно игнорируя их возможную зависимость друг от друга и от строк, уже (и особенно еще не) включенных в базис? Если строки одной длины, но разной частости, то первой в базис следует включить более частую. Если строки разной длины, но одинаковой частости, первым кандидатом на включение в базис будет более длинная строка. И, разумеется, предпочтительным кандидатом является та строка, которая одновременно длиннее и чаще. В этих ситуациях для построения отношения порядка включения в базис не требуется взвешивание, то есть чтобы расположить две сравниваемые строки в порядковой шкале претендентов достаточно интерпретировать шкалу длин l и шкалу частостей f как порядковые. Если же одна строка длиннее другой, но имеет меньшую частость, возникает потребность в функции от l и f, отображающей строки на порядковую шкалу претендентов.
Функция взвешивания вида F(f, l) = fl неявно апеллирует к тому, сколько символов словаря могла бы покрыть строка с характеристиками f и l. (Обсуждая величину покрытия, можно пренебречь тем фактом, что в русском языке существуют самопересекающиеся 3–строки «ала», «ана», «ара», «ере», «иги», «ого», «око», «опо», «ото», «охо», «юлю» и 4–строка «снос», которые в случае самопересечения встречаются в слове дважды, но будучи использованы в разложении, покроют не 6 и 8, а 3 и 4 символа.) Однако такая апелляция выглядит достаточно безосновательной. Действительно, когда строка не включается в базис, важно не то, сколько символов могла бы покрыть она, а то, сколько компонент базиса потребуется на покрытие ее вхождения (причем эти компоненты могут заодно захватывать и символы слева и справа от вхождения строки). Взвешивание F(f, l) = fl имеет смысл только в случае l = 2, когда единственный способ разбиения строки — это разбиение нм отдельные символы. При l > 2 дело обстоит иначе. И не ясно, почему из 2l–1–1 вариантов разбиения l–строки нужно считать единственно возможным тот, при котором строка рассыпается на отдельные символы, либо, как минимум, предполагать, что число покрывающих строку компонент должно быть пропорционально ее длине?
С другой стороны, из сказанного следует лишь то, что функция взвешивания F(f, l) должна расти по l медленнее, чем линейно. В табл. 3 упоминаются три использованные нами схемы взвешивания, все степенные по l. Первая — линейная F(f, l) = fl, вторая — fl0.75 и третья — fl0.5. При обсчете В–словаря одним из начальных размеров надбазиса оказался как раз требуемый размер базиса (256). В таком случае использованный вариант метода надбазиса вырождался в метод наичастого, то есть приведенные в табл. 3 результаты для надбазиса размером 256 — это результаты, которые бы показал метод наичастого при замене в нем схемы взвешивания. Нелинейные схемы дали лучшие результаты.
Однако более принципиальным при выборе надбазиса является определение его размера. Действительно, выделение компонент из надбазиса основано на их использовании в минимальных разложениях по надбазису. Рассмотрим два крайних случая — размер надбазиса близок или совпадает с допустимым размером базиса и размер надбазиса, как и число различных основ в словаре, гораздо больше требуемого размера базиса. В первом случае состав и качество (величина среднего покрытия) базиса окажутся практически теми же, что и у надбазиса. Во втором случае качество как угодно выделенного базиса окажется хуже, чем даже в методе наичастого. Действительно, в базис могут попасть только те компоненты надбазиса, которые используются в минимальных для этого надбазиса разложениях. Но очень большой надбазис заведомо содержит многие основы и их длинные подстроки. Минимальными разложениями тех основ, которые являются компонентами надбазиса, будут они сами, а минимальные разложения остальных будут содержать «слишком крупные компоненты» надбазиса. Любая из компонент очень большого надбазиса сама покрывает очень небольшую часть словаря. Но базис формируется — по тиражу — из небольшого подмножества этих компонент. Таким образом, с увеличением размера надбазиса обеспечиваемое им среднее покрытие будет стремиться к средней длине слова, а среднее покрытие для базиса, состоящего из любого (256–элементного) подмножества надбазиса будет, напротив, стремиться к 1.
Мы исходим из предположения, что среднее покрытие базиса, выделенного на основе тиража в минимальных разложениях, вне зависимости от деталей процедуры выделения, является «в большом» унимодальной функцией размера надбазиса. То есть предполагается, что есть некий тренд среднего покрытия базиса как функции размера надбазиса, который с увеличением последнего сначала возрастает, а затем убывает, сходясь к 1. Но при этом мы не знаем, сколь велики могут быть колебания этой функции вокруг унимодального тренда.
В качестве правила для динамического выбора порогового размера надбазиса, начиная с которого эффект от роста надбазиса предполагается отрицательным, мы использовали следующее, более напоминающее шаманизм, хотя и имеющее прозрачную мотивировку. Именно, выполняемое каким-то образом включение строк в надбазис (из которого базис выделяется по тиражам в минимальных разложениях) продолжается до тех пор, пока число независимых друг от друга строк в нем не окажется близким к требуемому размеру базиса. Набор таких независимых компонент — это своего рода ортобазис, содержащийся внутри надбазиса.
Поскольку возможны разные интерпретации зависимости, изложенное правило останова выглядит еще более шаманским. Однако заметим, что если в надбазисе содержится ортобазис, то слова, включающие в качестве подстрок компоненты последнего будут всегда или как правило (в зависимости от выбранной формы независимости) разлагаться на них. Помимо ортобазиса в надбазисе могут быть еще какие-то компоненты, также используемые в минимальных разложениях, причем пока разложение по надбазису не выполнено, число таких компонент остается неизвестным. Тогда если продолжить пополнение надбазиса, число различных используемых в минимальных разложениях компонент будет все больше превосходить требуемый размер базиса. Тем самым, когда мы как-то выделим из надбазиса базис, в минимальных разложениях по надбазису окажется много строк, не представленных в базисе. Результат переразложения в базис слов, содержащих в своих разложениях компоненты надбазиса, не вошедшие в базис, будет тем хуже, чем больше таких компонент.
В реализации метода надбазиса, которая использовалась для расчетов (табл. 3 и 4), для прекращения пополнения надбазиса отслеживалась независимость по не самому строгому критерию — непосредственной вложенности строк, то есть подсчитывалось число строк надбазиса, не вложенных в другие.
4.2. Выделение базиса из надбазиса
После того как надбазис сформирован, по нему строятся минимальные разложения либо всех слов словаря, либо, если словарь большой, выборки из него (в расчетах ее размер равнялся 4000 основ). Каждой компоненте надбазиса присваивается ее тираж в минимальных разложениях. Затем строки надбазиса взвешиваются по тиражу и длине (как на начальном этапе отбора в они взвешивались по частости и длине) и строки с лучшими весами объявляются базисом.
Приведенные в табл. 3 и 4 результаты относятся к варианту рассмотрения для каждой основы ровно одного минимального разложения (получаемого ее замащиванием слева–направо). Другой вариант состоит в том, чтобы, когда это возможно (то есть когда основа не слишком длинна), выписать для каждой основы все ее минимальные разложения. Компоненты, входящие в одно разложение, объявляются совместимыми. В разных вариантах, относящихся к одной основе могут быть общие компоненты, стоящие на одних и тех же местах. Сравнивая попарно минимальные разложения одной основы, отбрасываем такие компоненты, а каждую оставшуюся компоненту одного разложения объявляем несовместимой с каждой оставшейся компонентой другого разложения. Так можно построить две матрицы — совместимости и несовместимости компонент, а также тиражи компонент по числу слов, в разложении которых они используются хотя бы один раз.
Табл. 3. Результаты применения метода надбазиса для разных схем взвешивания
Первая буква основы | Схема взвешивания | Размеры исходных и уточняющих(*) надбазисов | Тираж разложения на усеченном базисе (лучшее разложение помечено ***) | Среднее покрытие |
А | 1 | 800 720 640 560 480 400 320 | 11805 11849 11814 11871 11988 12136 12480 | 2.11 2.10 2.10 2.09 2.07 2.05 1.99 |
800* 780* 760* 740* 720* | 11805 11813 11796 11789*** 11849 | 2.11 2.10 2.11 2.11*** 2.10 | ||
2 | 800 720 | 12069 11873 | 2.06 2.09 | |
800* 780* 760* 740* 720* 700* 680* | 12069 11929 11965 11937 11873 11829 11829 | 2.06 2.08 2.08 2.08 2.09 2.10 2.10 | ||
Б | 1 | 800 720 640 560 480 400 320 | 12766 12764 12830 12895 12966 13122 13346 | 2.06 2.06 2.05 2.04 2.03 2.00 1.97 |
800* 780* 760* 740* 720* 700* 680* | 12766 12781 12800 12753 12764 12810 12800 | 2.06 2.06 2.05 2.06 2.06 2.05 2.05 | ||
2 | 800 720 640 | 12756 12765 12799 | 2.06 2.06 2.05 | |
800* 780* 760* 740* 720* | 12756 12759 12727 12725*** 12765 | 2.06 2.06 2.06 2.06*** 2.06 | ||
В | 1 | 472 392 312 256 | 31315 31176 31176 31916 | 1.83 1.84 1.84 1.79 |
472* 452* 432* 412* 392* 372* 352* | 31315 31318 31188 31221 31176 31233 31207 | 1.83 1.83 1.83 1.83 1.84 1.83 1.83 | ||
2 | 424 344 264 256 | 31196 31182 31699 31836 | 1.83 1.84 1.81 1.80 | |
424* 404* 384* 364* 344* 324* 304* | 31196 31158 31194 31216 31182 31197 31195 | 1.83 1.84 1.83 1.83 1.84 1.83 1.83 | ||
3 | 388 308 256 | 31119 31207 31665 | 1.84 1.83 1.81 | |
388* 368* 348* 328* 308* | 31119*** 31160 31126 31159 31207 | 1.84*** 1.84 1.84 1.84 1.83 | ||
Г | 1 | 800 720 640 560 480 400 320 | 10779 10805 10806 10772 10781 10946 11128 | 2.08 2.08 2.08 2.09 2.08 2.05 2.02 |
640* 620* 600* 580* 560* 540* 520* | 10806 10794 10794 10774 10772 10783 10805 | 2.08 2.08 2.08 2.09 2.09 2.08 2.08 | ||
2 | 640 560 480 | 10743 10810 10753 | 2.09 2.08 2.09 | |
660* 640* 620* 600* 580* 560* | 10786 10743 10739*** 10780 10829 10810 | 2.08 2.09 2.09*** 2.08 2.08 2.08 | ||
3 | 660 580 500 420 340 260 | 10750 10764 10775 10844 11010 11562 | 2.09 2.09 2.09 2.07 2.04 1.94 | |
680* 660* 640* 620* 600* 580* | 10764 10750 10785 10801 10790 10764 | 2.09 2.09 2.08 2.08 2.08 2.09 | ||
Д | 1 | 800 720 640 560 480 400 320 | 18590 18561 18608 18534 18563 18585 18876 | 1.97 1.98 1.97 1.98 1.98 1.97 1.94 |
640* 620* 600* 580* 560* 540* 520* | 18608 18632 18602 18557 18534 18516*** 18538 | 1.97 1.97 1.97 1.98 1.98 1.98*** 1.98 | ||
2 | 640 560 480 | 18579 18519 18702 | 1.97 1.98 1.96 | |
640* 620* 600* 580* 560* 540* 520* | 18579 18607 18579 18542 18519 18533 18576 | 1.97 1.97 1.97 1.98 1.98 1.98 1.98 | ||
Е | 1 | 800 | 774 | 3.16 |
2 | 800 | 761*** | 3.21*** | |
3 | 800 | 771 | 3.17 | |
Ж | 1 | 800 720 640 560 480 | 1764 1800 1847 1885 1976 | 2.61 2.56 2.49 2.44 2.33 |
800* 780* 760* 740* 720* | 1764 1790 1790 1797 1800 | 2.61 2.57 2.57 2.56 2.56 | ||
2 | 800 720 | 1762 1787 | 2.62 2.58 | |
800* 780* 760* 740* 720* | 1762*** 1765 1766 1774 1787 | 2.62*** 2.61 2.61 2.60 2.58 | ||
3 | 800 720 | 1769 1778 | 2.60 2.59 | |
800* 780* 760* 740* | 1769 1771 1772 1773 | 2.60 2.60 2.60 2.60 | ||
…………………………………………………………………………………………………………… | ||||
П | 1 | 458 378 298 | 100756 100274 101051 | 1.95 1.96 1.95 |
458* 438* 418* 398* 378* 358* 338* 318* 298* | 100756 100259 100642 100337 100274 100464 100345 100596 101051 | 1.95 1.96 1.96 1.96 1.96 1.96 1.96 1.96 1.95 | ||
2 | 437 357 277 | 100075 99935 101450 | 1.97 1.97 1.94 | |
437* 417* 397* 377* 357* 337* 317* 297* 277* | 100075 100067 99911 99903*** 99935 100185 100449 100666 101450 | 1.97 1.97 1.97 1.97*** 1.97 1.97 1.96 1.96 1.94 | ||
………………………………………………………………………………………………… | ||||
Примечание. На размер надбазиса было наложено техническое ограничение — не более 800. | ||||
В завершение, надо сказать, что мы склонны рассматривать метод надбазиса не столько как метод, сколько как схему, в которую можно вкладывать разные технические решения, в том числе «скрещивать» со строгими методами.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
