
5. Строгие алгоритмы построения базиса, учитывающие зависимость строк
Излагаемый ниже алгоритм применялся (табл. 4) для построения собственно базиса, однако он может быть использован и для построения начального надбазиса в предыдущем методе. Алгоритм основан на учете зависимостей между строками. Нам уже приходилось касаться популярной в компьтерной лингвистике парадигмы «выбора наиболее частого» [4]. Приведенный здесь алгоритм можно считать своего рода иллюстрацией альтернативы этой парадигме.
Основа алгоритма состоит в том, что из возможных зависимостей строк вычленяются некоторые типы и каждый тип зависимости явным образом учитывается (или явно не учитывается).
Строки могут непосредственно зависеть друг от друга по вложенности и по пересечению. Тогда зная, например, частость надстроки w и частость вложенной в нее строки s, можно получить частость s для тех ее вхождений в слова, когда она не является подстрокой w. Возможна и опосредованная зависимость, которая в условиях нашей задачи может быть учтена только путем разложения (см. о матрицах согласованности и несогласованности в 4.2). Начнем с отношения непосредственной вложенности двух строк.
Пусть имеется строка s, которой приписана частость f(s) ее вхождений в слова. Если в (последовательно формируемом) базисе содержатся строки, для которых она является подстрокой, вычислим собственный вклад строки s — частость f*(s) тех ее вхождений в слова, которые не есть вхождения в составе надстрок. Выпишем, начиная с самой короткой, те надстроки, которые содержат вхождения s, непокрытые более короткими надстроками. Так формируется подбазис G = {gi}, предназначенный для коррекции частости строки s. Обозначив r(gi) число непокрытых другими компонентами G вхождений строки s в строку gi, запишем построенную по «включению–исключению» формулу для корректированной частости f*(s)
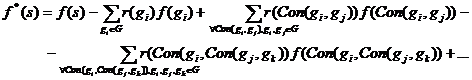 |
Не вдаваясь в детали, Con(a, b) — условное обозначение каждой из строк вида pqr, таких, что a = pq, b = qr или a = qr, b = pq (подстроки p, q и r непусты), r(w) — число непокрытых вхождений строки s в строку w.
В приведенной формуле можно пренебречь суммами, уже начиная со второй. В алгоритме вторая сумма еще используется, поэтому корректированная частость f*(s) чуть завышена. Перейдем к описанию алгоритма.
Пусть имеется список S — очередь на вхождение в базис. Очередь включает все подстроки слов словаря, и каждой подстроке приписаны частость ее вхождений в слова словаря, вычисленный одним из изложенных в 4.1 способов вес, а также некий вектор обоснования исключения. (Хотя частость назначается с учетом возможности самопересечения строки, на практике это излишне — частость реально встречающихся самопересечений несущественна относительно частости строки без учета самопересечений.) Список упорядочен по убыванию этих весов. Имеется также исходно пустой базис B, строки в котором будут упорядочиваться по убыванию длины. Кроме того, нам потребуется отдельный список F исходных частостей строк.
Начнем с процедуры включения в базис. Возьмем очередную строку s из очереди и выполним коррекцию ее частости, учитывая вложенность строки s в строки базиса.
Если базис не пуст, просмотрим включенные в него строки снизу–вверх, начиная с первой строки, длина которой больше строки s. Построим подбазис коррекции —множество G строк базиса, содержащих s. Именно, если очередная строка w базиса содержит s как подстроку, то подсчитываем число (несамопересекающихся) вхождений s в w. Просматриваем текущий G снизу–вверх (то есть по увеличению длин входящих в него строк) на предмет вхождения очередной строки gi в строку w. Если вхождение имеет место, вычеркиваем его из w. Если после какого-то шага прохода G в w не остается невычеркнутых вхождений s, то продолжим построение G, то есть, взяв в качестве w следующую строку базиса (т. е. стоящую выше текущей w), проверяем вхождение в нее s и если вхождения есть, проверяем w по подбазису G. Если же после прохода текущего подбазиса в w остались k невычеркнутых вхождений s, включаем w в подбазис G, выясняем по списку частостей строк частость f(w) и увеличиваем на kf(w) приписанную G величину коррекции, исходно (при пустом G) приравненную нулю.
Сформировав таким образом подбазис G, просмотрим нет ли попарных пересечений включенных в G строк. Для любой пары пересекающихся строк подбазиса, то есть строк, представимых в виде w1 = ab и w2 = bc (где a, b и c — непустые подстроки), смотрим по списку частостей частость строки w = abc и на f(w) уменьшаем величину коррекции. (Эта занимающая известное время операция в действительности дает уточнение того же порядка малости как и поправка частости строки по самопересечению.)
Выпонив эти операции, наконец уменьшаем на величину коррекции исходное значение частости строки s и вычисляем вес s для откорректированной по G частости. Если вес окажется больше веса строки, стоящей в очереди следом за s, то s вносится в базис и переходим к рассмотрению следующей строки из очереди. Иначе s вместе с исходной частостью, откорректированным весом и заполняемым при отвержении s вектором обоснования исключения (см. ниже) перемещается в очереди на место, соответствующее новому весу.
Мы описали процедуру включения в базис, в которой строка из списка рассматривалась как подстрока строк базиса. Теперь естественно построить основанную на тех же представлениях о зависимости строк процедуру исключения строк из базиса, а точнее их вытеснения включаемой строкой.
Включаемая в базис строка из списка может оказаться надстрокой для каких-то строк базиса. Приняв решение включить строку из очереди в базис, проверим, нет ли в базисе строк, являющихся подстроками включаемой. Обходя базис теперь сверху–вниз (от более длинных строк к коротким), выпишем все удовлетворяющие этому условию строки базиса. Сформировав такой список SB, проделаем с каждой попавшей в него строкой точно те же действия, что со строкой s из очереди S при выяснении возможности включить ее в базис. Когда вес, вычисленный по корректированной частости очередной строки sB из списка SB оказывается меньше веса очередной строки из S, строка sB исключается из базиса и вносится в список S согласно вычисленному весу. Обход списка SB от самых длинных к самым коротким строкам гарантирует нас от ситуации, когда строка из SB сначала используется для принятия решения об исключении какой-то другой строки из SB, а затем оказывается объектом для такого же решения.
Когда строка вытесняется из базиса в список S (как и в случае отвержения строки–претендента из S — см. выше), будем заполнять вектор обоснования исключения идентификаторами тех строк базиса, по которым и было принято решение об ее исключении. Но тогда при исключении строки из базиса нужно пересчитать веса тех строк, в исключении которых эта строка сама участвовала ранее. С этой целью просматриваются вектора обоснования исключения у строк списка S, расположенных ниже текущей. Если исключаемая строка входит в такой вектор строки s, то вес строки s должен быть пересчитан. Все удовлетворяющие этому условию строки s перемещаются в списке S под текущую строку, то есть становятся в начало текущей очереди на попадание в базис. Тем из них, которые имеют нулевой вес, назначается вес, равный 1. Это нужно для корректного выполнения останова, который производится либо в случае, когда текущий размер базиса окажется не меньше требуемого уже после включения очередной строки и вызванной этим попытки выталкивания из него недостаточно весомых компонент, либо же в случае, когда вес очередной строки из очереди равен 0.
Мы описали процедуру включения/исключения строк, основанную на отношении непосредственной вложенности двух строк. Кроме того, было рассмотрено отношение вложенности строки в конкатенацию пары строк, то есть случай, когда возможно представление строки s = cd, и строк базиса b1 = ec, b2 = df (где подстроки e, c, d, f не пусты). Другие варианты отношения пересечения включаемой/исключаемой строки и строк базиса не рассматривались.
Отношение вложенности в конкатенацию, как и отношение непосредственной вложенности, может использоваться при решении вопроса о включении в базис и вопроса об исключении из базиса. В первом случае это означает, что когда про очередную строку из очереди не было решено вернуть ее (на новое место) в очередь, пересчитанная частость f*(s) корректируется дальше — по включенности s в конкатенации строк базиса. Это как бы дополнительный фильтр, оберегающий базис от включения в него строк с небольшим собственным вкладом.
В случае же использования покрытия конкатенациями для исключения строк из базиса возникает необходимость в значительном переборе (действительно, для любой 2– и почти любой 3–строки всегда найдется сколько-то покрывающих ее конкатенаций). По этой причине строгий алгоритм формирования базиса использовался в двух вариантах — «полном» (включение/исключение с учетом вложенности в обеих ее формах) и быстром (включение с учетом вложенности строки s из очереди непосредственно в строки из базиса и вложенности s в конкатенации пар строк базиса, а исключение только по непосредственной вложенности). Так как с расширением учитываемых зависимостей требуется все больший перебор, мы ограничились только вложенностью. Быстрый вариант алгоритма требует немного времени и играет роль эффективного фильтра, только в последнюю очередь пропускающего в базис строки, плохо совместимые с уже имеющимися в базисе строками.
При том, что, как видно из табл. 4, строгий алгоритм построения базиса дал не лучшие результаты, только о нем можно точно сказать, что именно и с какой целью в нем делается, а какие типы зависимостей — сознательно и явно — игнорируются. Собственно, данный алгоритм является логически строгим, но заведомо не является точным, поскольку игнорируемые (чтобы избежать объемного перебора) зависимости весьма существенны.
6. Сравнение методов
Чтобы поставить методы в равные условия, ни в один из них не была включена проверка того, нельзя ли целиком занести словарь в базис заданного размера. С другой стороны, с этой же целью во всех методах, включая метод наичастого, использовалась процедура построения минимального покрытия. Из табл. 4 видно, что лучшие результаты дал метод надбазиса, худшие — метод наичастого. И если к последнему применимы слова Марка Блока об «эмпиризме в обличье здравого смысла» [2], то первый тяготеет к шаманизму, несмотря на подспудное желание авторов узреть в нем «здравый смысл в обличье эмпиризма». Логически прозрачный алгоритм построения базиса, учитывающий зависимость строк, дал промежуточные результаты на всех словарях кроме небольших. На последних он оказался лучшим. В случае Й–словаря, содержащего 24 основы, из которых 20 несовпадающих, результаты всех трех методов оказались одинаковы. Что следует признать большим везением. Действительно, рассмотрим словарь всего из двух основ — одна длиной 24 и вторая длиной 2, не входящая в первую. Первая основа содержит 231 почти наверняка попарно различную подстроку не короче 4 и сколько-то, возможно совпадающих, подстрок меньшей длины. В таком случае базис будет заполнен исключительно подстроками длинной основы плюс алфавитом. Для второй основы, согласно методу наичастого, в 256–компонентном базисе места не найдется.
Что касается скорости методов, то метод надбазиса очевидно самый медленный, не сильно от него отличается «полный» строгий алгоритм построения базиса.. Самый быстрый метод — наичастого, очень близок к нему по скорости быстрый строгий алгоритм построения базиса, отслеживающий непосредственную вложенность и вложенность в конкатенацию при принятии решения о включении в базис и непосредственную вложенность при принятии решения об исключении из базиса. Наконец, надо заметить, что затраты времени для метода надбазиса определяются размером словаря (выборки), а для строгого алгоритма — наличием вложенностей у рассматриваемых строк.
Табл. 4. Результаты применения трех методов нахождения базиса
Общий минимальный тираж | Среднее покрытие | ||||||
Метод наичастого | Метод надбазиса | Строгий алгоритм построения базиса* | Метод наичастого | Метод надбазиса | Строгий алгоритм построения базиса* | Верхняя оценка на 4–, 3– и 2–строках | |
А | 13238 | 11789 | 12104 (11924) | 1.88 | 2.11 | 2.05 (2.09) | 2.40 |
Б | 13934 | 12725 | 13069 | 1.89 | 2.06 | 2.01 | 2.18 |
В | 31936 | 31119 | 31444 (31347) | 1.79 | 1.84 | 1.82 (1.83) | 1.98 |
Г | 11899 | 10739 | 10947 | 1.89 | 2.09 | 2.05 | 2.35 |
Д | 19403 | 18516 | 18894 | 1.89 | 1.98 | 1.94 | 2.24 |
Е | 1259 | 761 | 630 (614) | 1.94 | 3.21 | 3.88 (3.98) | |
Ж | 2258 | 1762 | 1753 | 2.04 | 2.62 | 2.63 | |
З | 25074 | 24129 | 24468 | 1.91 | 1.99 | 1.96 | 2.27 |
И | 14825 | 13008 | 13382 | 1.83 | 2.09 | 2.03 | 2.39 |
Й | 24 | 24 | 24 | 5.17 | 5.17 | 5.17 | |
К | 25551 | 24088 | 24674 | 1.88 | 1.99 | 1.94 | 2.14 |
Л | 7269 | 6211 | 6337 | 1.78 | 2.08 | 2.04 | 2.58 |
М | 17596 | 16404 | 16800 | 1.89 | 2.03 | 1.98 | 2.22 |
Н | 36112 | 34314 | 34701 | 1.85 | 1.95 | 1.93 | 2.11 |
О | 37489 | 36272 | 36735 | 1.77 | 1.83 | 1.80 | 2.05 |
П | 102894 | 99903 | 100961 (100840) | 1.91 | 1.97 | 1.95 (1.95) | 2.14 |
Р | 27166 | 25526 | 25822 | 1.96 | 2.09 | 2.06 | 2.42 |
С | 43582 | 41918 | 42482 | 1.83 | 1.90 | 1.87 | 2.02 |
Т | 13394 | 12215 | 12521 | 1.87 | 2.05 | 2.00 | 2.29 |
У | 12058 | 10679 | 11419 | 1.81 | 2.04 | 1.91 | 2.65 |
Ф | 6237 | 5263 | 5461 | 2.00 | 2.37 | 2.29 | 2.68 |
Х | 4301 | 3442 | 3513 | 1.96 | 2.44 | 2.40 | 3.00 |
Ц | 1682 | 1220 | 1189 | 2.18 | 3.00 | 3.08 | |
Ч | 3365 | 2664 | 2766 | 1.99 | 2.51 | 2.42 | 3.00 |
Ш | 4349 | 3593 | 3774 | 1.91 | 2.31 | 2.20 | 2.85 |
Щ | 332 | 215 | 211 | 2.82 | 4.35 | 4.44 | |
Э | 5301 | 4451 | 4569 (4550) | 2.18 | 2.59 | 2.53 (2.54) | 2.84 |
Ю | 331 | 176 | 143 | 2.24 | 4.22 | 5.20 | |
Я | 601 | 374 | 276 | 2.16 | 3.47 | 4.71 | |
* В нескольких случаях, помимо быстрого алгоритма построения базиса, использовался и полный (с выведением строк из базиса по пересечению конкатенаций). Полученные им результаты приведены в скобках после значений быстрого алгоритма. |
Благодарности
Мы благодарны людям, без чьей помощи наша работа не была бы выполнена: , предоставившей свой компьютер для продолжительных обсчетов словарей, и , практически полностью профинансировавшей работу. Тот факт, что у них не было ни рациональных причин поддерживать эту работу, ни малейшей заинтересованности в ее результатах, лишь увеличивает нашу признательность.
Литература
1. , Кузнецов средства автоматизированных информационных систем. М. 1983.
2. Апология истории. М. 1986.
3. Бузикашвили величины среднего покрытия словаря. // Настоящий сборник.
4. , , N-граммы в лингвистике. // Методы работы с документами. М. 2000.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
