
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Задача построения базиса известного размера для разложения словаря
, ,
В конструировании электронных словарей возникает задача, состоящая в том, чтобы для компактного представления входящих в словарь слов выбрать не более чем заранее заданное число подстрок, на которые разложимы все слова словаря. В работе предложено несколько методов решения этой задачи.
1. Постановка задачи
При конструировании электронных словарей часто используется флективное представление входящих в него слов, состоящее в том, что словоформа разбивается на две части — общую для всех форм слова основу и изменяемое окончание (флексию). При построении морфологических (частеречевых) электронных словарей такое двучленное деление слов удобно с технической точки зрения. Более детальное членение слова на морфы хотя и используется, но не столько с академической целью отразить словообразование, сколько как один из способов компактного представления слов. По этой же причине в качестве флексий могут использоваться хвосты словоформ, мало соотносящиеся с морфами–окончаниями.
Слова, формы которых имеют одинаковый набор флексий, относятся к одному флективному классу. Тогда для представления группы словоформ, соответствующих одному слову, достаточно хранить основу и номер класса. Устройство такого словаря подробно описано в [1] и именно с таким морфологическим словарем русского языка пришлось иметь дело авторам. Хотя число основ заметно меньше числа исходных словоформ, а длина основы, как правило, меньше длины слова, тем не менее задача сжатого представления остается актуальной и при переходе от словаря словоформ к соответствующему ему словарю основ.
Для ускорения поиска в словаре он разбит на подсловари по первой букве основы, то есть в одном подсловаре содержатся основы, начинающиеся с буквы «а», в другом — с буквы «б» и т. д. Это имеет смысл даже несмотря на несбалансированность разбиения (например, число Е–основ равно 394, тогда как П–основ — 28542). Характеристики словаря основ приведены в первых трех столбцах табл. 1. Ниже, говоря о словаре, мы будем иметь в виду подсловарь основ, начинающихся с какой-то буквы, например, Ж–словарь, П–словарь. Аналогично, под словами понимаются элементы словаря, то есть основы, причем без первой буквы. Первые буквы основ в словаре не хранятся.
Каждая в отдельности основа сжимается путем кодирования ее в «алфавите подстрок». (В силу процедуры использования словаря, требуется сжатие именно каждой основы в отдельности, а не всего словаря в целом.) Так, если в алфавит подстрок входят 4 подстроки «актир», «л», «лак» и «тир», то основу «лактир» можно закодировать как «лак–тир» и «л–актир», или, занумеровав подстроки от 0 до 3, как <1,2> и <3,1>. Длина обоих представлений равна 2.
Алфавит подстрок, используемых для кодирования основ, будем называть базисом разложения словаря, а строки базиса — компонентами или просто строками. Компонента при записи основы кодируется своим номером в базисе разложения. Если размер базиса не больше 256, то для записи номера достаточно одного байта, если не больше 216 — двух байтов. Поскольку другие способы кодировки не рассматриваются, естественным ограничением на размер базиса является 256. Каждый подсловарь может обладать одним приписанным ему базисом. Заметим, что качество разложения можно улучшить даже малым изменением устройства словаря, а именно допустив использование двух базисов — первого для первой компоненты основы («префикса») и второго для всех остальных. Однако любые конструкторские решения, как и лингвистическое наполнение словаря, априори вынесены за рамки данной статьи, хотя, очевидно, именно они, а не проработка попутно возникающих формальных задач, предопределяют качество словаря.
Сопоставим каждой основе минимальное число экземпляров компонент базиса, нужное для ее записи. Просуммировав эти величины по всем основам, получим минимальное число экземпляров компонент, нужное для разложения словаря по данному базису. Задача состоит в том, чтобы построить базис, мимизирующий эту сумму или, что то же самое, максимизирующий число символов, в среднем приходящееся на одну компоненту при разложении словаря.
2. Предварительное обсуждение
Обратившись к табл. 1, видим, что размеры подсловарей основ варьируются в широком интервале от 24 (Й–основы) до 28542 (П–основы). Если в первом случае задача имеет тривиальное решение, состоящее в том, чтобы объявить компонентами базиса сами основы, то при числе различных основ, большем допустимого размера базиса, возникает необходимость в методе, который бы давал удовлетворительные решения и при числе основ, незначительно превосходящем допустимый размер базиса, и при числе основ, гораздо большем этого размера.
Начнем с определений. Назовем частостью f(w) строки w число ее вхождений в слова словаря. Назовем l–строкой строку длиной l. Базисом словаря назовем любой набор строк, такой что каждое словарное слово представимо в виде конкатенации строк набора (разложимо на него). Назовем m–разложением основы ее разложение по базису, содержащее m, в том числе «одноименных», компонент. В зависимости от величины m, основа может не иметь ни одного или иметь одно или несколько разложений. В частности, у основы может быть несколько минимальных разложений, то есть таких, что разложения на меньшее число компонент в данном базисе не существует. Длиной (минимального) разложения основы будем называть число компонент в ее (минимальном) разложении. Назовем тиражом t(w) строки–компоненты w базиса B число ее использований в минимальных разложениях всех основ. Тираж компоненты зависит от выбранной схемы разложения и однозначно определяется тройкой <базис, основа, процедура разложения>.
Процедура разложения может порождать либо ровно одно, либо все минимальные разложения основы. Если специально не оговорено, предполагается, что каждой основе сопоставлено одно минимальное разложение, единообразно получаемое для каждого слова.
Наконец, средним покрытием M(B, V) базисом B слов словаря V назовем отношение суммы длин всех основ к сумме длин их минимальных разложений. Задача состоит в отыскании базиса B, имеющего максимальное M(B, V) среди всех базисов заданного размера.
Если словарь содержит {Nl} основ длины l£L, где L — маскимальная длина, то общее число строк длины k, являющихся подстроками основ, равно
(Строки могут совпадать и не обязаны быть собственными подстроками основ.)
Число всевозможных (m+1)–разложений (l+1)–слова (0 £ m £ l, 0 £ l) равно Clm, общее число разложений (l+1)–слова — åClm =2l. Наконец, общее число всех комбинаций разложений всех основ словаря
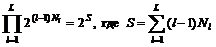
Для прямого перебора всех вариантов разложения входящих в словарь основ это число несколько велико.
Возможен и другой вариант перебора. Если выписать все входящие в основы строки, то, откинув повторы, получим то множество из P строк, из которого нужно выделить базис. Но вариантов выделения базиса размером N из множества P строк также немало — CPN, что, по приближению Стирлинга lnk! » k(lnk–1), составляет приблизительно
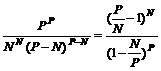
Когда P равно нескольким тысячам, а N = 256, вряд ли можно надеяться найти за обозримое время базис, перебирая множество всех строк.
Конечно, из того, что задача неразрешима полным перебором, никак не следует ее неразрешимость. Ведь умеем же мы без перебора находить максимум функции f(x) = x на любом интервале. Однако мы не знаем никакого точного и эффективного (требующего приемлемого времени) способа максимизации M(B, V).
Когда исходная задача не имеет точного эффективного решения, можно 1) решать ее приближенно, либо 2) точно или приближенно решать другую задачу, решение которой само является приближенным решением исходной. (Есть, впрочем, и третий путь — как исходную сразу сформулировать «другую» задачу, но это уже вопрос адекватности.) Производя подмену (2) неплохо представлять, в чем и каково различие задач и их решений.
Реально доступными являются только приближенные методы решения задачи максимизации M(B, V). Но в таком случае хотелось бы знать, насколько они эффективны. Помимо сравнения результатов методов между собой, это означает еще и желательность иметь, пусть и грубые, но оценки того, каким бы мог быть лучший и худший результат на данном словаре. Грубые оценки величины среднего покрытия получены в [3].
Табл. 1. Характеристики словарей основ и верхние оценки среднего покрытия
1–я буква | Общее число основ / число различных основ | Средн. длина основы | Оценка | 1–я буква | Общее число основ / число различных основ | Средн. длина основы | Оценка | ||
А | 3232 | 2826 | 8.69 | 2.40 | П | 28542 | 18970 | 7.90 | 2.14 |
Б | 3812 | 3276 | 7.89 | 2.18 | Р | 7673 | 5242 | 7.94 | 2.42 |
В | 9626 | 6556 | 6.94 | 1.98 | С | 12212 | 9061 | 7.52 | 2.02 |
Г | 3347 | 2773 | 7.71 | 2.35 | Т | 3917 | 3111 | 7.39 | 2.29 |
Д | 5575 | 4089 | 7.58 | 2.24 | У | 4161 | 2634 | 6.24 | 2.65 |
Е | 394 | 334 | 7.21 | Ф | 1734 | 1489 | 8.20 | 2.68 | |
Ж | 822 | 646 | 6.61 | Х | 1378 | 1076 | 7.11 | 3.00 | |
З | 7795 | 4966 | 7.15 | 2.27 | Ц | 576 | 470 | 7.36 | |
И | 4078 | 2809 | 7.67 | 2.39 | Ч | 1077 | 885 | 7.21 | 3.00 |
Й | 24 | 20 | 6.17 | Ш | 1472 | 1128 | 6.63 | 2.85 | |
К | 7003 | 5723 | 7.85 | 2.14 | Щ | 212 | 144 | 5.42 | |
Л | 2216 | 1825 | 6.83 | 2.58 | Э | 1365 | 1214 | 9.45 | 2.84 |
М | 4703 | 3977 | 8.08 | 2.22 | Ю | 146 | 125 | 6.09 | |
Н | 9544 | 7244 | 8.01 | 2.11 | Я | 270 | 241 | 5.81 | |
О | 11304 | 7194 | 6.87 | 2.05 | |||||
Примечание: средние длины основ даны с учетом первой буквы (включая ее) | |||||||||
3. Метод наичастого
В отличие от остального материала данной статьи, этот метод изобретен не нами. В этой связи мы выражаем глубокую признательность (Cognitive Technologies) за ознакомление с реализацией метода и разрешение на его публикацию. Помимо метода формирования базиса (в терминах авторов метода, построения таблицы упаковки), ими предложена и процедура разложения основ (упаковки).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
