

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
При этом, как правило, не рассматриваются какие-либо меры количества
и качества информации.
Синтактическая гипотеза. Суть синтактической гипотезы ясна из определения термина “синтактика”. Как следует из п. 1.3, в рамках этой гипотезы не учитывается смысловое содержание термина “информация”. Оно является как бы “вторичным”. На первый план выступают количественные показатели информации, такие как количество информации, скорость и пропускная способность канала передачи информации и т. п.
В рамках этой гипотезы можно выделить следующие подходы (варианты): комбинаторный, вероятностно-статистический, алгоритмический, сигнальный (компьютерный).
В комбинаторном подходе количество информации определяется как функция числа элементов конечного множества с учетом их комбинаторных отношений. Примером комбинаторной меры количества информации (неопределенности) является мера Р. Хартли, определяемая через логарифм числа исходов некоторого события:
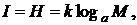 (1.1.9)
(1.1.9)
где I – количество информации, получаемое при наступлении события или которое может быть получено, когда наступает какой-либо исход события;
M – число возможных исходов (вариантов, комбинаций, состояний) события;
а – основание логарифма; k – коэффициент пропорциональности (при а = 2
и k = 1 единица количества информации называется битом, при а = e и k = 1 – нитом (натом), при а = 10 и k = 1 – дитом и т. д.; при k = 1,38×10–23 Дж/K и а = e получаем физическую шкалу измерений энтропии (информации) по Больцману.
Выбор функции log = loga объясняется желанием, чтобы мера количества ин-формации удовлетворяла требованию (условию) аддитивности. Согласно рассуж-дениям Хартли, если в заданном множестве, содержащем М элементов, выделен какой-то элемент х, о котором заранее известна лишь его принадлежность этому множеству, то, чтобы найти х, необходимо получить количество информации, равное log 2 M битов. А вот если надо угадать элемент х из множества в М1 элементов и одновременно y из множества в М2 элементов, то число комбинаций будет М1М2, следовательно, ![]() Это и есть свойство аддитивности.
Это и есть свойство аддитивности.
Использование меры Хартли позволяет решать многие задачи. Приведем одну из них.
В римском лагере в 135 году н. э. произошло восстание иудеев против римского господства, руководимое Бар-Кохбой. В лагерь был послан лазутчик. Его поймали, отрезали ему язык и отрубили руки. Лазутчик вернулся к своим, но не мог ни говорить, ни писать. Однако Бар-Кохба получил всю нужную информацию, задавая вопросы в форме “да или нет”. Несчастный лазутчик смог отвечать на них кивком головы. Не здесь ли зародыш двоичной системы (вспомните алгебру Буля, азбуку Морзе и т. п.)? Отсюда родилась игра “Бар-Кохба” по угадыванию задуманного числа с помощью минимального количества бинарных вопросов. Так, например, по мере Хартли, для того чтобы угадать, какое число из 32 возможных загадал партнер, нужно задать пять вопросов, так как log232 = 5. Используем метод половинного деления. Первый вопрос: “Это число больше 16, да или нет?” (32 разделили на две половины). Далее делим пополам 16, 8, 4 и 2. Либо можно задать все пять вопросов сразу, если попросить партнера записать число в двоичном коде, а пять вопросов формулировать так: верно ли, что на первом месте задуманного числа стоит единица (или единица стоит на первом месте, на втором, на пятом)? Для числа 01110 получим: “нет, да, да, да, нет”, а 01110 означает 14 в десятичной системе. Это
и есть загаданное число.
Существенным недостатком меры Р. Хартли является то, что она не учитывает возможные неравные шансы появления разных элементов множества. Например, ее нельзя использовать для определения и сравнения информативности буквы “а” латинского и/или русского алфавитов в смысловом тексте, так как разные буквы встречаются не одинаково часто в каждом тексте не только в силу того, что число букв алфавита разное, но и в силу строения слов, фраз, предложений на латыни, в английском, немецком, французском или русском языках.
В определенной мере этот недостаток устраняет вероятностно-ста-тистический подход, основателем которого является Клод Элвуд Шеннон, опубликовавший в 1948 году книгу “Математические основы теории связи” (обратите внимание на название: основы теории связи, а не информации, хотя К. Шеннона после этой книги стали считать “отцом” именно теории информации). Его подход основан на следующих посылках. Во-первых, на фундаментальной роли количественной меры неопределенности – энтропии (в ее математической трактовке!). Во-вторых, на случайности природы (и, следовательно, вероятностного описания) носителей информации – сигналов (о других возможных описаниях сигналов речь будет идти далее). В-третьих, на необходимости введения ее количественной меры в виде
|
 ,
,
что для случая отсутствия шумов в канале связи дает – log [вероятность появления данного события для приемника до приема сообщения].
Под информацией здесь понимается уменьшаемая, снимаемая неопределенность, а под количеством информации – разность количественных мер неопределенностей до и после получения информации. Рассмотрим два примера, поясняющих суть подхода.
П р и м е р 1. Пусть получатель сообщения Y имеет некоторые представления о возможных наступлениях интересующих его n событий Х. Эти представления в общем случае недостоверны, а степень их возможного появления определяется вероятностями р1, р2, ... , рn. Величина
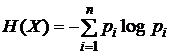 (1.1.10)
(1.1.10)
называется шенноновской энтропией (средней, математической, вероятностной), в отличие от физической S, и характеризует неопределенность априорных (до получения сообщения) знаний получателя об этих событиях. Например, если X – дискретная случайная величина, принимающая значения х1, ..., хn с вероятностями р1, р2, ... , рn, то H(Х) – мера неопределенности этой величины.
Если сообщения Y касаются состояний Х системы, которая может находиться
в состояниях х1, х2, ... , хn с вероятностями р1, р2, ... , рn, то Н(Х)-энтропия – мера неопределенности – количество априорной неопределенности о положении (состоянии) системы. Предположим, что после приема сообщения Y о состояниях системы получатель приобрел некоторое дополнительное количество информации I{X,Y} о состояниях системы, уменьшивших его априорную неосведомленность настолько, что апостериорная (послеопытная, после получения сообщения) неопределенность о состояниях X системы стала H(X/Y). Тогда количество информации I{X,Y} о состояниях Х системы, полученной в сообщении Y о них, определяется разностью
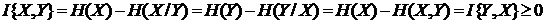 , (1.1.11)
, (1.1.11)
где
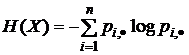 ; (1.1.12)
; (1.1.12)
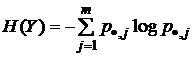 ; (1.1.13)
; (1.1.13)
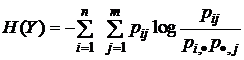 ; (1.1.14)
; (1.1.14)
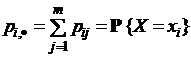 ;
; 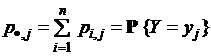 ;
; 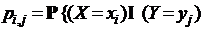 ; H(X), H(Y), H(X,Y) – энтропия величин Х, Y или вектора (X, Y);
; H(X), H(Y), H(X,Y) – энтропия величин Х, Y или вектора (X, Y); ![]() {×} – вероятностная мера, вероятность события
{×} – вероятностная мера, вероятность события ![]() .
.
Что касается основания логарифма log, то оно может быть любым. Обычно выбирают логарифм по основанию 2 (тогда единица измерения называется битом), реже по основанию натурального логарифма e (нит, нат). Один бит есть количество информации, получаемое при раскрытии неопределенности, содержащейся в двух равновероятных исходах, состояниях. Величина I{X,Y} и есть количество информации (по К. Шеннону) для дискретных случайных величин X и Y (рис. 1.1.12 и последующие). Нетрудно убедиться, что если X и Y независимы (сообщение не снимает неопределенность о состояниях системы X), т. е если H(Х) = H(X/Y), то H(X,Y) = H(Х) + H(Y) и I{X,Y} = 0. Если же Y = Х, т. е. сообщение Y раскрывает всю неопределенность о состояниях системы X, то I{X,Y} = Н(X). В этом смысле говорят, что энтропия есть максимальное количе ство информации о состояниях Х системы или мера недостающей информации. Обратим внимание на то, что здесь мы говорим о неопределенности как наших сведений (знаний) о системе (объекте), так и самой системы (объекта).
 КОЛИЧЕСТВО ИНФОРМАЦИИ ПО К. Э. ШЕННОНУ
КОЛИЧЕСТВО ИНФОРМАЦИИ ПО К. Э. ШЕННОНУ
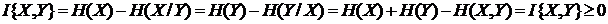
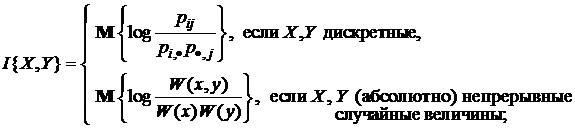
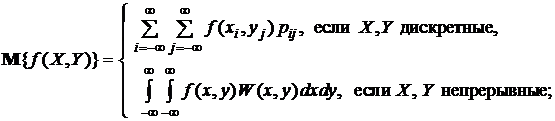
– М{log pi,·} – энтропия дискретной случайной величины Х,
– М{logW(X)} – дифференциальная энтропия непрерывной
величины Х.
![]() или
или ![]() ;
;
![]() ,
, 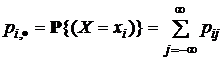 ;
;
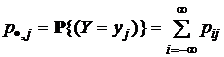 ; Р{A} – вероятность событий А;
; Р{A} – вероятность событий А;
W(x),W(y),W(x,y) – плотности распределения величин X или Y и вектора (X,Y).
I{X,Y} = 0, если X и Y – независимы, т. е. p ij = p i,· p·, j, или W(x,y) = W(x)W(y);
I{X,Y} = H(X) = H(Y), если X = Y.
Рис. 1.1.12. Соотношения между мерой количества неопределенности,
энтропией и шенноновской мерой количества информации
П р и м е р 2. Первый вариант. Пусть 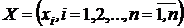 – дискретная совокупность возможных различных независимых символов алфавита на входе канала связи, т. е. Х – дискретная величина, принимающая значения х1, ..., хn;
– дискретная совокупность возможных различных независимых символов алфавита на входе канала связи, т. е. Х – дискретная величина, принимающая значения х1, ..., хn;
рi, · = pi = P{X = xi} = P(xi) – априорная вероятность символа xi.
Второй вариант: Х – непрерывная случайная величина с плотностью W X (x) = W(x), описывающая значения некоторой физической величины на входе канала связи.
Пусть ![]() – совокупность символов на выходе этого канала связи, р·, j = pj = P{Y = yj} = P(yj) – априорная вероятность появления символа yj на выходе системы. Иначе говоря, пусть Y – дискретная случайная величина (для варианта 1) либо непрерывная случайная величина с плотностью распределения вероятностей WY(y) (для варианта 2). Пусть
– совокупность символов на выходе этого канала связи, р·, j = pj = P{Y = yj} = P(yj) – априорная вероятность появления символа yj на выходе системы. Иначе говоря, пусть Y – дискретная случайная величина (для варианта 1) либо непрерывная случайная величина с плотностью распределения вероятностей WY(y) (для варианта 2). Пусть ![]()
![]() – совместная вероятность появления на выходе системы символа y j, если на входе был символ x i, или вероятность того, что величина Х примет значение xi,
– совместная вероятность появления на выходе системы символа y j, если на входе был символ x i, или вероятность того, что величина Х примет значение xi,
а Y – значение y j (для врианта 1) либо W(x,y) – двумерная совместная плотность распределения вероятностей вектора (Х,Y) (для варианта 2). Далее пусть ![]() – апостериорная вероятность передачи символа xi, если был принят символ yj;
– апостериорная вероятность передачи символа xi, если был принят символ yj; 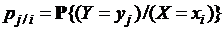 – условная вероятность появления на выходе системы символа yj, если на входе был символ xi, т. е. рi/j, рj/i – соответствующие условные вероятности величин Х и Y. Аналогично WX (x/y) = W(x/y), WY (y/x) = W(y/x) – условные плотности распределения вероятностей непрерывных случайных величин X и Y. Напомним, что
– условная вероятность появления на выходе системы символа yj, если на входе был символ xi, т. е. рi/j, рj/i – соответствующие условные вероятности величин Х и Y. Аналогично WX (x/y) = W(x/y), WY (y/x) = W(y/x) – условные плотности распределения вероятностей непрерывных случайных величин X и Y. Напомним, что
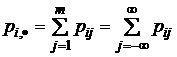 ;
; 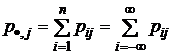 ,
,
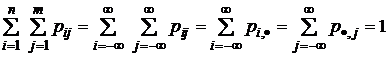 . (1.1.15)
. (1.1.15)
Введем символ операции усреднения по вероятностной мере (математического ожидания) ![]() :
:
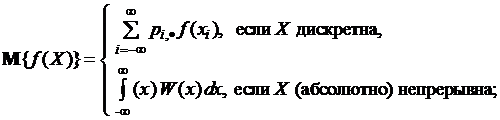 (1.1.16)
(1.1.16)
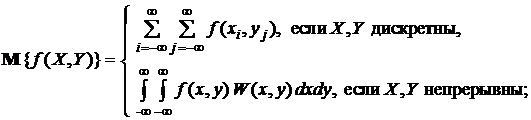 (1.1.17)
(1.1.17)
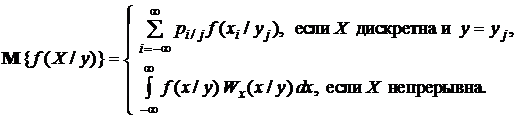 (1.1.18)
(1.1.18)
Обозначим через Q вероятность Р или плотность W. Тогда собственная информация символа хi (значения хi или х), т. е. количество информации, доставляемое самим символом хi или любым другим однозначно с ним связанным символом, определяется формулой (сравните с мерой Хартли)
I(хi) = – logQ(хi), т. е. I(хi) = – log P(хi) или I(x) = – log W(x). (1.1.19)
Условная собственная информация символа хi при известном yj есть
I(хi / yj) = –log Q(хi / yj). (1.1.20)
Взаимная информация двух символов хi и yj относительно друг друга, т. е. количество информации относительно символа хi, доставляемое симво-
лом yj, равно
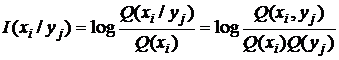 , (1.1.21)
, (1.1.21)
собственная информация совместного события хi, yj есть
I(хi, yj) = – log Q(хi, yj). (1.1.22)
Среднее (шенноновское) количество информации, доставляемое принятым символом yj относительно множества всех переданных символов Х, есть
![]() . (1.1.23)
. (1.1.23)
Среднее (шенноновское) количество взаимной информации по множеству значений (символов) Y при фиксированных значениях хi есть
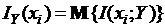 . (1.1.24)
. (1.1.24)
Полное среднее (шенноновское) количество взаимной информации Y (в множестве символов Y) относительно всех X (количество информации по
К. Шеннону) есть (см. формулы (2.17), (2.22))
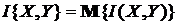 . (1.1.25)
. (1.1.25)
Средняя собственная информация дискретного алфавита (дискретной случайной величины) Х есть
![]() , (1.1.26)
, (1.1.26)
т. е. равна энтропии – количественной мере неопределенности о сообщении до его приема.
На основе предложенной К. Шенноном и его последователями меры количества информации были получены важные понятия и результаты. Например, такие, как скорость создания и передачи информации, избыточность сигналов, пропускная способность канала связи. Доказана возможность обеспечить передачу информации без потерь при любых помехах и шумах в канале связи, что породило поиск методов такой передачи и привело к созданию теории кодирования. Создан инструментарий для решения задач определения минимального количества шагов и поиска стратегий при выборе вариантов в условиях статистической (вероятностной) априорной неопределенности. Примером может служить определение минимального количества взвешиваний при поиске единственной фальшивой монеты из множества монет путем взвешивания на рычажных весах без гирь. Допустим, что имеется 24 монеты, одна из которых фальшивая, отличающаяся от других весом (массой). Какое минимальное количество взвешиваний надо произвести, чтобы: а) просто узнать, легче она или тяжелее, б) найти фальшивую монету? Попробуйте решить эту задачу, используя меры Хартли и Шеннона.
Помимо шенноновской есть и другие вероятно-статистические меры количества информации. Так, например, в математической статистике вводится количество информации (по Фишеру) о скалярном q или векторном ![]() = (q1, ..., qk) параметре, содержащемся в одном наблюдении хi случайной величины Х. Для скалярного параметра это количество определяется как
= (q1, ..., qk) параметре, содержащемся в одном наблюдении хi случайной величины Х. Для скалярного параметра это количество определяется как
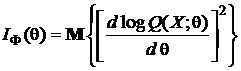 , (1.1.27)
, (1.1.27)
а для N независимых значений (выборки объема N) х1, х2,..., х N количество информации будет равно NI(q) (свойство аддитивности!), где Q(х, q) – это P(х, q) или W(х, q). Для векторного параметра ![]() вводится информационная матрица Фишера
вводится информационная матрица Фишера
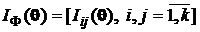 , (1.1.28)
, (1.1.28)
где
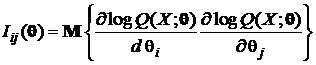 . (1.1.29)
. (1.1.29)
Мера количества информации по Кульбаку, которая представляет собой меру неопределенности величины X, имеющей распределение вероятностей Q1(x) относительно величины Y с распределением вероятностей Q2(y),
имеет вид
![]() , (1.1.30)
, (1.1.30)
где оператор ![]() берется по распределению Q1(x), например, для дискретных X и Y:
берется по распределению Q1(x), например, для дискретных X и Y:
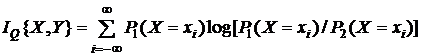 . (1.1.31)
. (1.1.31)
Одним из принципиальных недостатков вероятностно-статистических мер количества информации является привлечение именно вероятностно-статистического описания объектов, имеющих ограниченную область приложений, т. е. применимость такой меры только к множеству объектов, ситуаций, а не к отдельным из них.
Что касается комбинаторной меры Хартли, то она, во-первых, также не применима к индивидуальным объектам (исходам), во-вторых, предполагает как бы равную неопределенность обо всех комбинациях, ситуациях, состояниях.
В этом перед ними имеют преимущество алгоритмические методы.
Алгоритмический подход к определению количества информации связан с именем академика АН СССР – “отца” аксиоматической теории вероятностей. Он предложил (1962 – 1965) определять меру количества информации через алгоритмическое понятие сложности (Согласно результатам К. Геделя, логически доказать сложность или минимальность длительности алгоритма невозможно, нужна интуиция, невзирая на это, данный подход имеет свою целесообразную область приложения.), отражающей меру упорядоченности объекта, а именно: в качестве меры количества информации он предложил минимальную длину записанной в виде последовательности 0 и 1 программы, которая позволяет построить x, имея в своем распоряжении y (где x и y – некоторые числовые последовательности). В формальном виде алгоритмическая мера имеет вид
I К (x, y) = h(x) – h(x/y) ¹ I K (y/x), (1.1.32)
где h(x) и h(x/y) – алгоритмическая и условная алгоритмическая энтропии индивидуальных объектов x и y. В (2.32) h(x) интерпретируется как количество информации, необходимое для воспроизведения x (речь идет о последовательностях двоичных разрядов); h(x/y) – как количество информации, которое необходимо добавить к информации, содержащейся в y, чтобы восстановить x.
Разность между ними и есть количество информации, содержащейся в y об x. Основу этой меры составляет измерение относительной сложности индивиду-
ального конечного объекта “x” (слова, конечной последовательности натуральных чисел и т. д.) при заданном конечном объекте “у” через длину самой короткой последовательности (алгоритма, программы ее формирования) “p”, состоящей из 0 и 1, по которой, используя “y”, можно восстановить “x”. Например, есть две последовательности (два сообщения): первая и вторая . Какое из этих сообщений сложнее? Второе, так как оно менее упорядоченное. Алгоритм (программа) генерации первой последовательности прост: (01)8 или “напиши 01 восемь раз”. Второе сообщение имеет алгоритм (программу) той же длины, что и сообщение. Второй пример. Надо написать число p = 3,141. Экономная программа: а) просто буква p; б) отношение длины окружности к диаметру.
Сигнальный (компьютерный) подход. Его идея сводится к фактической замене информации и меры ее количества на материальные носители информации – статические и динамические сигналы (данные, знания-1, сообщения)
и количественные меры измерения для них. Еще раз обратим внимание на наличие разных определений терминов “сигналы”, “данные”, “знания”, “сооб-щения”. Определения терминов, приведенные в п. 1.4, даны исходя из их прагматической направленности. Добавим к ним еще замечания по определению терминов “знания” и “сообщения”.
Под “знаниями” понимают: 1) результат, полученный познанием; 2) систему суждений с принципиальной и единой организацией, основанную на объективной закономерности; 3) “проверенный практикой результат познания реальной и виртуальной действительности, верное ее отражение в мышлении человека”; 4) “целостную и систематизированную совокупность научных понятий о закономерностях природы, общества и мышления, накопленную человечеством...”; 5) формализованную информацию, на которую ссылаются или которую используют в процессе логического вывода; 6) “хранимую в ЭВМ информацию, формализованную в соответствии с определенными структурными правилами”. Знания принято делить на ф а к т ы (фактические знания, теории, идеи и пр.), п р а в и л а (знания для принятия решения) и м е т а з н а н и я (знания о знаниях).
Под “сообщениями” обычно понимают: 1) форму изложения содержания мышления о чем-либо в виде письменного текста, устной речи, доклада, цифровых данных, знаковых сигналов, изображений и т. п.; 2) данные определенного формата, предназначенные для передачи и приема (по каналу связи);
3) форму представления информации для ее хранения, обработки, преобразования или непосредственного использования [25 – 27].
В сигнальном подходе понятия “информация”, “сигнал”, “данные”, “зна-ния”, “сообщения” как бы отождествляются, причем зачастую без понимания разницы между ними. Например, словосочетания “передача, прием, обработка данных” и “передача, прием, обработка информации” воспринимаются как равноправные, хотя это принципиально разные понятия, поскольку те же данные могут подвергаться совершенно разным методам передачи, приема, обработки в зависимости от того, какую информацию мы хотим извлечь из них (например, восстановить на приемном конце значения, траекторию физического сигнала, переданного на передающем конце, или измерить какую-либо характеристику принятого сигнала – математическое ожидание (среднее арифметическое), дисперсию, корреляционно-спектральную и т. п.
В качестве меры количества информации (данных, сигнала, знаний, сообщения) при этом чаще всего используют меры объема: выборки, памяти и т. п. Например, объем данных Vд измеряется количеством символов (разрядов) в байтах (8 битов), дитах (десятичных разрядах); количеством V = N чисел определенной разрядности; количеством V = N отчетов выборки (сигнала) или длиной Т его траектории (реализации) – длиной временного отрезка, в течение которого получена (представлена) траектория, и т. д. Производные от этой меры количества информации – такие понятия, как коэффициент сжатия (уплотнения) данных (информации), представляющий собой отношение объема V1 до применения процедур уплотнения к объему V2 после применения процедуры уплотнения к тому же массиву данных (V1/V2), коэффициент (степень) информативности (лучше – лаконичности) сообщения как отношение количества информации (в каком-либо одном и том же для сравниваемых сообщений измерении) к объему данных (kc = I/Vд ) и им подобные.
Следует признать наибольшую распространенность во многих дисциплинах в области информатики и вычислительной техники именно этого подхода и его мер количества информации.
Семантическая гипотеза. В основе этой гипотезы лежит подход, связанный с измерением не столько количества, сколько качества информации, причем содержательного, смыслового. Под информацией здесь понимается то содержательное, смысловое, семантическое, ценное, что несут в себе <данные>, операнды об объекте, т. е. сведения, смысл, знания-2 (семантика символьных записей, изображений, сигналов), содержащиеся в <данных>, операндах как носителях; совокупность содержательных сведений, новых знаний-2, которые могут быть выработаны, собраны, переработаны, воспроизведены, проанализированы, интерпретированы, использованы и пр. Например, Д. Обэр-Крис под информацией понимает знания, полученные из анализа данных. Под (семантическим) количеством информации здесь понимается величина Ic = CVд, где
С – коэффициент содержательности. Второй характеристикой является
тезаурус пользователя – совокупность <данных> и сведений, которыми располагает пользователь или информационная система в какой-либо области о каком-либо объекте. В определенном смысле тезаурус – один из элементов культурной среды, о которой шла речь ранее (см. рис. 1.1.1, 1.1.2). Сторонники данного подхода убеждены, что между семантическим количеством информации Ic, воспринимаемой и накапливаемой ее получателем (пользователем), т. е. воспринимаемой и включаемой им в дальнейшем в свой тезаурус, и объемом тезауруса Sр существует детерминированная зависимость типа изображенной на рис. 1.1.13 (вряд ли все так просто, может быть, это все-таки нечто типа поведения в среднем, тенденция). При малом Sр® 0 пользователь не в состоянии воспринимать информацию, не понимает ее (она для него недоступна или не представляет интереса), а при больших Sр® ¥ пользователь уже все знает об объекте и поступающая информация не добавляет ничего нового, не нужна ему. Подобный вид имеет также зависимость эффективности Еff решения конкретной задачи от имеющейся при этом информации I (рис. 1.1.13). На рис. 1.1.13 Sp opt и Ip opt – оптимальные (лучшие) в смысле максимума Ic и Eff значения Sp и I.
Потребительская (практическая) гипотеза. Основной упор в этой гипотезе делается не столько на количество или семантическое качество, сколько на пользовательские показатели качества, отвечающие на вопросы, какая (по содержанию и качеству), какому (какой категории потребителей), когда (к какому сроку) и в какой форме (форма, вид представления) информация нужна потребителю согласно его запросам. При этом подходе информация характеризуется следующими показателями.
Ценность (полезность) – свойство информации, определяемое ее пригодностью к практическому использованию в различных областях целенаправленной человеческой деятельности для достижения определенной цели, т. е. свойство, определяющее ту максимальную пользу, которую данное количество информации способно принести при должном ее использовании. В литературе можно встретить как разные меры ценности информации, так и отрицание [16] ценностного подхода к информации, мотивируемое тем, что такой подход автоматически эквивалентен субъективному подходу к самому понятию информации. Если это физическая величина, то она должна иметь только одну однозначно определенную меру, например, ее имеют энергия, длина, масса, количество вещества (ведь здесь не ставится вопрос о ценности этих объектов!). Отрицание ценностного подхода к информации не означает отрицания ценностного подхода вообще, а означает лишь перенос рассмотрения ценности с информации к информационным системам (не путать ценность с ценой!).
Секретность (защищенность) – это свойство, характеризующее уровень, степень возможного несанкционированного использования информации.
Репрезентативность информации связана с ее способностью полно, адекватно отражать интересующие пользователя свойства исследуемого (изучаемого, проектируемого) им объекта.
Содержательность (существенность) информации означает ее семантическую емкость и определяется, в частности, через семантическое количество Ic, коэффициент информативности kc .
Достаточность (полнота, избыточность) информации – свойство, характеризующее наличие в ней минимального, но достаточного количества сведений, необходимых для принятия правильного решения (создания моделей, проекта, плана) или выполнения какой-либо функции. Заметим, что как неполная, т. е. недостаточная для принятия правильного решения, так и избыточная информация снижают эффективность (Eff) принимаемых пользователем решений (рис. 1.1.13).
Доступность информации для восприятия и применения пользователем – свойство, связанное как с формой ее представления и восприятия, так и с тезаурусом пользователя.
Актуальность – свойство, характеризующее способность информации сохранять семантическую ценность для принятия решений в момент ее использования в зависимости от динамики изменения ее пригодности для решения задач пользователя, соответствие информации временным границам в отображении ситуации, для которой необходимо принимать решения.
 МЕРЫ КОЛИЧЕСТВА ИНФОРМАЦИИ
МЕРЫ КОЛИЧЕСТВА ИНФОРМАЦИИ
Физико-модельная (минимально-символьная)
![]() – число элементов k-го алфавита в i-й подсистеме
– число элементов k-го алфавита в i-й подсистеме
Комбинаторная Хартли (максимально-разнообразностная)
![]() M – число возможных разнообразий (состояний, вариантов)
M – число возможных разнообразий (состояний, вариантов)
Вероятностно-статистическая Шеннона (максимально-неопределeнностная)
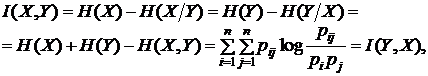
H(·) – вероятностная энтропия
Алгоритмическая Колмогорова (минимально-сложностная)
![]()
h(·) – алгоритмическая энтропия
Сигнальная
Объем данных (сигнала) Vд.
Коэффициент информативности (лаконичности) данных kс = I /Vд.
Семантическая
Семантическое количество I с = CVд.
Объем тезаураса пользователя Sп.
Прагматические
Ценность, защищенность, репрезентативность, содержательность, достаточность, доступность, актуальность, своевременность, точность, достоверность (истинность), устойчивость, интенсивность
Рис. 1.1.13. Меры количества информации
Своевременность информации – свойство, отражающее возможность и факт ее поступления точно в момент времени, согласованный с временем решения задачи пользователем, незапаздывания ее к моменту принятия решения. Например, для выработки и принятия решения существует промежуток времени, после которого эффективность его воздействий падает, а затем может вообще не иметь смысла. В системах с обратной связью несвоевременность поступления сигнала обратной связи может привести к катастрофическим последствиям.
Точность информации – свойство, определяющее степень близости получаемой информации (образа, построенного с ее помощью) реальному объекту (его структуре, свойствам, процессам). К ним примыкают такие понятия, как “точность измерений, вычислений”, в частности “формальная точность вычислений”, измеряемая значением единицы младшего разряда числа; “реальная точность”, определяемая значением единицы последнего разряда числа, верность которого гарантируется; “максимальная точность”, которая достигается в конкретных условиях; “необходимая точность”, определяемая назначением, и т. д.).
Достоверность, истинность, верность информации – свойства, определяющие ее способность отражать реально существующие объекты с необходимой адекватностью, точностью или идентичностью. В измерительных задачах количественной мерой достоверности является обычно доверительный интервал погрешности результата или доверительная вероятность, т. е. вероятность того, что отображаемое информацией значение результата (например, измеренное значение физической величины) отличается от истинного значения в пределах допустимой погрешности.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
