


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
42
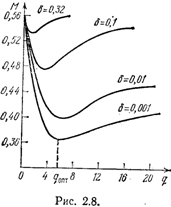 Ведь если в динамическом мире смена ситуаций происходит с большой частотой, то инерционность вряд ли может служить хорошим средством для существования в этом мире. В'едь в динамическом мире надо быстро, оперативно следить за возникающими изменениями среды. И для каждого динамического мира нужна своя наилучшая глубина памяти, выбранная в зависимости от скорости изменения обстановки, а вовсе не по принципу «чем больше, тем лучше». Это означает, что не приходится и мечтать о том, что рассмотренные нами конструкции зверушек будут вести себя целесообразно во всех динамических средах. И эксперименты неумолимо свидетельствуют об этом. На рис. 2.8 можно увидеть результаты одного такого эксперимента. Он проводился с помощью ЭВМ. Испытывались автоматы с линейной тактикой, имеющие различное число состояний в лепестках. Для простоты считалось, что автоматы могут выбирать
Ведь если в динамическом мире смена ситуаций происходит с большой частотой, то инерционность вряд ли может служить хорошим средством для существования в этом мире. В'едь в динамическом мире надо быстро, оперативно следить за возникающими изменениями среды. И для каждого динамического мира нужна своя наилучшая глубина памяти, выбранная в зависимости от скорости изменения обстановки, а вовсе не по принципу «чем больше, тем лучше». Это означает, что не приходится и мечтать о том, что рассмотренные нами конструкции зверушек будут вести себя целесообразно во всех динамических средах. И эксперименты неумолимо свидетельствуют об этом. На рис. 2.8 можно увидеть результаты одного такого эксперимента. Он проводился с помощью ЭВМ. Испытывались автоматы с линейной тактикой, имеющие различное число состояний в лепестках. Для простоты считалось, что автоматы могут выбирать
одно из двух действий. Переключающаяся среда была устроена тоже достаточно просто. Она состояла из двух стационарных сред, отличающихся друг от друга перестановкой вероятностей штрафов за действия (и этим она была похожа на пару сред в сказке об Иванушке-дурачке). В первой среде за первое действие вероятность штрафа была весьма велика, а за второе действие мала. В другой среде эти вероятности относились уже ко второму и первому действиям, т. е. ситуация была обратной. Обозначим через б вероятность смены сред (значения этого параметра надписаны над кривыми, показанными на рис. 2.8). По оси абсцисс отложена глубина памяти автомата, а по оси ординат — математическое ожидание накапливаемого штрафа.
Результаты эксперимента ясно показывают, что для каждого значения б существует своя оптимальная глубина памяти автомата с линейной тактикой, при
43
которой накапливаемый штраф минимизируется. Аналогичную картину можно наблюдать и при использовании в переключающейся среде автоматов других конструкций, целесообразно ведущих себя в стационарных случайных средах.
Итак, в динамических средах найденные нами конструкции автоматов оказываются не самыми лучшими. И единственный выход из этого положения — использовать какую-нибудь гибкую конструкцию, которая изменяется вместе с тем миром, где она функционирует.
Ученики и продолжатели дела предложили несколько конструкций зверушек, способных целесообразно функционировать в динамических средах. Самой известной из них является предложенная одним из авторов этой книги модель автомата с переменной структурой.
Предположим, что вы на своей автомашине ежедневно добираетесь из дома на работу. В вашем распоряжении есть два возможных маршрута, и вы вольны выбирать любой из них. Так как вы всегда выезжаете в одно и тоже время, то обстановка на каждом из маршрутов как бы стационарна. И, анализируя эту обстановку, вы убедились, что один из маршрутов лучше другого: времени тратится меньше — движение здесь менее интенсивное, чем по другому маршруту, да и светофоров не так много. Но вот беда. Время от времени из-за каких-то строительных работ движение здесь резко снижается, образуются пробки, и можно потерять много времени, пока они ликвидируются. В этих условиях данный маршрут становится намного хуже другого. Вы бы потеряли куда меньше времени и не опоздали бы на работу, выбрав в эти неудачные дни другой маршрут. Если нет никакой информации о частоте строительных работ на трассе первого маршрута, то при выезде из дома нет никаких шансов угадать, по какому маршруту лучше сегодня ехать. Однако день за днем вы накапливаете некоторую информацию. Учитесь на своем горьком опыте. Выясняется, что чаще всего пробки образуются в среду и пятницу и вероятность этих пробок достаточно велика. Тогда, выбирая в остальные дни недели первый маршрут, вы в среду и пятницу без колебаний выбираете менее хороший маршрут поездки.
44
Этот пример мы привели для того, чтобы у читателя возникли необходимые ассоциации с поведением автомата с переменной структурой в переключающейся среде. Опишем теперь его структуру и функционирование на более строгом уровне.
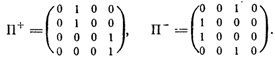 |
Вернемся снова к автомату с линейной тактикой показанному на рис. 2.3. Его структура может был задана в виде двух матриц, определяющих смену состояний при получении сигнала нештраф и при получении сигнала штраф. Каждая такая матрица содержит 12 строк и 12 столбцов по числу различных состояний автомата. И в каждой строке этих матриц имеется одна единица, показывающая, как осуществляется переход. Выписывание этих матриц слишком громоздко. Поэтому вместо автомата с четырьмя состояния
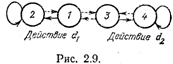 ми в каждом лепестке и тремя действиями рассмотрим автомат с линейной тактикой с двумя состояниями в лепестке и двумя действиями (рис. 2.9) Для такого автомата матрицы имеют вид
ми в каждом лепестке и тремя действиями рассмотрим автомат с линейной тактикой с двумя состояниями в лепестке и двумя действиями (рис. 2.9) Для такого автомата матрицы имеют вид
Эти матрицы определяют детерминированную структуру нашего автомата. Если автомат вероятностный (как, например, упоминавшийся нами автомат ), то вместо единиц и нулей в матрицах П+ и П - будут стоять значения вероятностей смены состояний. Если, например, автомат с линейной тактикой, показанный на рис. 2.9, заменить автоматом , то соответствующие матрицы примут вид
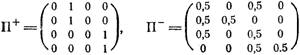 |
В отличие от детерминированного и вероятностного автоматов, у которых матрицы П+ и П - в процессе их функционирования остаются неизменными, для
45
автомата с переменной структурой П+ и П - не постоянны. В зависимости от результатов функционирования (наказаний или поощрений, получаемых от среды) автомат меняет свою структуру.
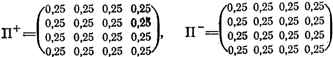 |
В начальном периоде своей работы такой автомат находится в «безразличном» состоянии, когда вероятности всех переходов между состояниями для него абсолютно одинаковы. Для условий, показанных на рис. 2.9, это соответствует тому, что начальный вид матриц смены состояний для автомата с переменной структурой задается следующим образом:
Пусть для определенности начальным состоянием автомата было состояние с номером 1 и автомат, выполнив действие d1, соответствующее этому состоянию (см. рис. 2.9), с помощью равновероятного выбора по матрице П+ перешел в состояние 4. И пусть после этого он получил сигнал штраф. Получение подобного сигнала заставляет автомат считать свой переход 1-->4 при нештрафе за действие d1 ошибкой. Эта информация фиксируется следующим образом. Вероятность П14+ уменьшается на некоторую величину А. Но сумма вероятностей в любой строке матрицы должна быть равна 1, и поэтому уменьшение П14+ на Дельту должно привести к увеличению всех
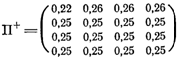 |
остальных вероятностей в этой строке, например, на величину Дельта/3, что позволит сохранить нормировку строк. Если взять Дельта== 0,03, то после этого шага матрица П - останется прежней, а матрица П+ примет вид
На очередном шаге автомат делает действие d2, соответствующее состоянию 4, и выбирает очередное состояние на основании матрицы П - (так как в текущем акте общения со средой он находится в условиях последнего сигнала от среды—штрафа).
46
Пусть он выбрал переход 4—>4 и вновь получил штраф. Теперь уже меняется матрица П-, а матрица П+ остается неизменной. В матрице же П- четвертая строка приобретает вид (0,26 0,26 0,26 0,22). На очередном шаге взаимодействия автомат опять использует вероятностный переход по матрице П-, и в зависимости от оценочного сигнала меняются значения вероятностей в четвертой строке матрицы и совершается очередной выбор либо по матрице П - (если последний пришедший оценочный сигнал был наказанием), либо по матрице П+.
Так постепенно происходит перестройка матриц П+ и П - в зависимости от сигналов, формируемых средой. Возникает вопрос: будут ли эти матрицы стремиться к какому-нибудь устойчивому значению, например к матрицам из нулей и единиц, соответствующих автомату с линейной тактикой, или какому-либо другому автомату, целесообразно ведущему себя в стационарных случайных средах? Если бы ответ был положительным, то это означало бы, что из механизма случайного выбора мы могли бы. формировать структуру зверушки, целесообразно функционирующей в статических случайных средах. Конечно, тот или иной ответ на поставленный нами вопрос зависит от тех законов изменения элементов в П+ и П-, которые мы будем использовать.
Что же показали проведенные исследования? Оказалось, что линейные законы изменения переходных вероятностей Пij в матрицах П+ и П-, описанных выше, не всегда приводят к оптимальным конструкциям, подобным автоматам или Г. Роббинса. Но если ввести нелинейное изменение элементов указанных матриц, то исходные «размазанные» матрицы с одинаковыми значениями Пij сходятся к матрицам из нулей и единиц, соответствующих автоматам, наилучшим образом ведущих себя в стационарных случайных средах.
Но не это главное. В стационарных случайных средах нет нужды тратить время на обучение автомата с переменной структурой, ибо заранее известны конструкции, успешно решающие в этих средах поведенческие задачи. Главное — поведение в динамических и, в частности, в переключающихся средах. Что дает использование автоматов с переменной структурой здесь?
47
Вернемся к рис. 2.8. Как мы уже знаем, для авто--матов с линейной тактикой существует оптимальное значение глубины памяти, зависящее от скорости переключения стационарных сред, при котором суммарный штраф, накапливаемый автоматом, становится минимальным. Но глубина памяти тесно связана с вероятностью пребывания автомата на том или ином лепестке и, следовательно, с вероятностью выполнения того или иного действия. Для автоматов с переменной структурой экспериментально (путем моделирования перестройки их структуры на ЭВМ) получен следующий фундаментальный результат:
с течением времени функционирование автомата с переменной структурой в переключающихся средах, в которых автомат с линейной тактикой действует целесообразно, неограниченно приближается к функционированию автомата с линейной тактикой, обладающему оптимальной глубиной памяти. Другими словами, автомат с переменной структурой сам находит эту оптимальную глубину памяти. Это весьма важно, так как значение qопт, показанное на рис. 2.8, нельзя априорно определять аналитическим путем, а оно должно подбираться в процессе функционирования в среде, на что автомат с линейной тактикой просто неспособен.
И еще одно. Вспомним наш пример с Иванушкой-дурачком. Нетрудно подобрать многочисленные примеры переключающихся сред, в которых эффект непрерывного битья все время будет преследовать автомат с линейной тактикой. Только он подстроится под определенную среду, как среда уже изменилась, и битье продолжается. Для этого достаточно условия, что среда переключается быстрее, чем автомат покидает свой лепесток и переходит на другой. Если бы заяц менял окраску шкурки в противофазе со сменой зимы и лета, затрачивая на это время, соизмеримое с полугодом, то он давно бы исчез с лица земли. Для автомата с переменной структурой подобного положения не существует. Как было сказано в одной из первых работ по таким автоматам, «миниальный штраф выплачивается в том случае, когда за вчерашние грехи сегодня награждают и в том случае, когда грехи остаются грехами».
В заключение этого параграфа приведем результат одного эксперимента с автоматом с переменной
48
структурой, имеющим восемь состояний и моделирующим поведение в среде, в которой автомат с линейной тактикой имел бы оптимальную глубину памяти, равную двум. Этот результат приведен на рис. 2.10. По оси абсцисс на этом рисунке отложено число тактов взаимодействия автомата со средой, а по оси ординат — средняя величина штрафа в расчете на одно взаимодействие. Горизонтальная пунктирная прямая соответствует значению 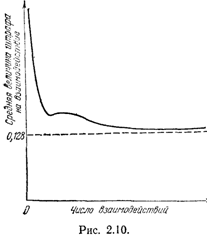 математического ожидания штрафа для автомата с линейной тактикой с глубиной памяти, равной двум. Как мы видим, автоматы с переменной структурой на начальном этапе весьма быстро приближаются к наилучшему режиму работы автомата с линейной тактикой, а потом неуклонно асимптотически стремятся к этому оптимуму.
математического ожидания штрафа для автомата с линейной тактикой с глубиной памяти, равной двум. Как мы видим, автоматы с переменной структурой на начальном этапе весьма быстро приближаются к наилучшему режиму работы автомата с линейной тактикой, а потом неуклонно асимптотически стремятся к этому оптимуму.
Такая явная связь между автоматами с линейной тактикой и с переменной структурой наводит на мысль о естественности этих конструкций, об их «эволюционной» связи.
И еще одно интересное наблюдение. Автомат с переменной структурой все время стремится уйти от штрафа, уйти в область благоприятных для себя действий. Это значит, что он чаще получает поощрения, а не наказания (если только среда не устроена так, что наказания в ней имеют значительно большую
49
вероятность, чем поощрения). А это в свою очередь означает, что матрица П+ изменяется сильнее, чем П-. Автомат как бы настраивается на хорошее функционирование в благоприятных мирах. К функционированию в таких условиях он лучше адаптирован.
Поведение автоматов в стационарных средах мы сравнивали с результатами экспериментов по альтернативному выбору решений людьми. Аналогичные эксперименты были проведены теми же авторами (, , ) и в случае переключающихся сред. В процессе эксперимента по нажатию кнопок без ведома испытуемого происходило переключение среды. Если в предшествующий период (75—100 нажатий кнопок) имела место среда с E1==(0,8, 0,2), то на следующий период нажатий она сменялась на среду с Е2==(0,2, 0,8). Каков же результат этого эксперимента? Вывод, к которому пришли экспериментаторы, оказался парадоксальным. Человек в среднем лучше решает задачу адаптации к переключающейся среде, чем задачу для стационарной среды. Вернемся снова к рис. 2.5. При решении задачи в случае стационарной среды человек время от времени отказывается от хорошего выбора и как бы пробует, что получится, если сменить стратегию. И это характерно для любого испытуемого. Что кроется за этим феноменом? Наиболее ярко он проявляется, когда предпочтительность того или иного выбора близка к предельной. При близких вероятностях штрафа за выбор кнопки уходы с предпочтительной стратегии более редки. А чем яснее и проще решение, тем менее устойчиво поступает человек. Какая особенность его психики скрывается за этим? Почему в стационарной среде с Е = (0,8, 0,2) процент поощрений равен 62%, а в переключающейся среде, где E2 =(0,2, 0,8), он равен 72%? И это только на 1% ниже того, что достигает в данной динамической среде автомат с линейной тактикой с оптимальной глубиной памяти. Ответов на поставленные вопросы пока нет. Это еще один аргумент в пользу того, что поведение человека зачастую не только не оптимально, но и нецелесообразно. В сложном мире от зверушки до человека огромная качественная дистанция.
50
§ 2.6. «Доживем до понедельника»
Так назывался известный фильм из школьной жизни. Но то, о чем мы хотим поговорить здесь, ничем кроме названия не ассоциируется с этим давним фильмом. У нас речь пойдет о возможности организации зверушкой такого управления внешней средой или приспособления к ней, которое обеспечивает ей максимальный срок «жизни». Однако прежде нам нужно дать содержательную постановку задачи, а уже затем ее формальное описание.
Биологами хорошо исследована модель охоты летучих мышей, в частности, охота на ночных бабочек, способных воспринимать локационный ультразвуковой сигнал летучих мышей. Экспериментальный материал, относящийся к этой ситуации, можно суммировать следующим образом.
Летучая мышь испускает с помощью своего голосового аппарата направленный ультразвуковой сигнал. Встретив препятствие, сигнал отражается от него. Летучая мышь способна улавливать отраженный сигнал и с большой скоростью и точностью различать и идентифицировать его, что позволяет отличать неподвижные цели от подвижных, отражения от поверхности земли от отражений от воздушных целей, большие размеры от малых (например, отраженные сигналы от летящих птиц и комаров). Кроме того, отраженный сигнал позволяет летучей мыши с весьма большой точностью определять направления и расстояния до потенциальных целей.
Ночные бабочки в свою очередь способны принять локационный сигнал летучей мыши, определить местоположение источника, из которого был послан сигнал, а также определить интенсивность последнего. Поведение ночной бабочки различно в зависимости от того, как далеко от нее находится летучая мышь и сколь интенсивен сигнал. Если расстояние достаточно велико или интенсивность мала, то ночная бабочка производит маневр, направленный на уход от летучей мыши. В экспериментальных ситуациях наблюдалось три способа выполнения такого маневра. Либо бабочка разворачивалась и двигалась в сторону, противоположную своему предшествующему движению, либо она использовала маневр
51
в вертикальной плоскости, уходя со своего прежнего курса вверх или вниз. Если же расстояние до летучей мыши было мало или интенсивность локационного сигнала была очень велика, то ночная бабочка переходила на хаотический полет. Это происходит потому, что органы слуха бабочки в таких условиях начинают работать в режиме насыщения, и бабочка уже не может определить положение летучей мыши и направление ее движения. Хаотический полет состоит из чередования пассивного падения со сложенными крыльями, крутых поворотов, петель, пикирования. Другими словами, бабочки переходили на такую траекторию полета, которая максимально затрудняла для нападающего предсказание последующей точки на этой траектории. Интересно, что, как показывают эксперименты, более чем в 70% случаев хаотическое движение оказывалось для ночных бабочек спасительным.
Попробуем формализовать описанную ситуацию, несколько упростив ее. Это упрощение не является принципиальным. На основе той упрощенной модели, которую мы опишем, ряд исследователей построил совсем не игрушечные модели «преследуемый — преследователь», в том числе и для моделирования поведения ночной бабочки, спасающейся от летучей мыши.
Посмотрим на рис. 2.11. На нем изображен граф смены состояний некоторого вероятностного автомата. Его особенность состоит в том, что для каждой группы состояний (на рисунке группы состояний оконтурены пунктирными линиями) имеется ненулевая вероятность перейти в особое состояние, в котором автомат погибает (на рисунке оно заштриховано). Состояния можно интерпретировать, например, следующим образом: 1 — летучая мышь производит поиск и с вероятностью 0,3 обнаруживает бабочку, а с вероятностью 0,7 пропускает ее (для первой группы состояний); 2—летучая мышь определяет направление своего движения и расстояние до жертвы, причем с вероятностью 0,8 цель при этом не теряется; 3 — летучая мышь настигает бабочку и уничтожает ее с вероятностью 0,95. Что же может противопоставить преследователю бабочка? В чем заключаются ее действия? Будем рассматривать каждую группу состояний автомата как определенную
52
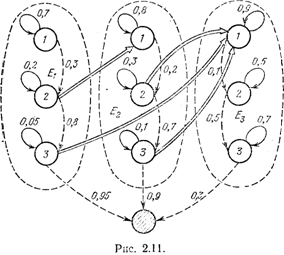 |
среду, задаваемую той стратегией бабочки, которой она придерживается. Трем группам состояний, показанных на рис. 2.11, можно, например, соотнести следующие стратегии: прямой полет (E1), пикирование или кабрирование (E2) и хаотическое движение (Ез). Действия бабочки сводятся к смене сред, переключению их. При этом бабочка может реализовать действие лишь в состояниях 2 и 3. На рис. 2.11 эти действия показаны двойными стрелками
переходов. В остальных состояниях бабочка выдает в среду нейтральный сигнал (другими словами, не меняет своих действий). После ухода от летучей мыши бабочка опять возвращается к движению по горизонтальной траектории, обеспечивающей ей возможность выполнения ее жизненного назначения — продолжения потомства. Эти переходы — действия на рисунке не показаны, чтобы не загромождать картину погони, которую мы анализируем.
В примере с ночной бабочкой и летучей мышью картина весьма прозрачна. Действия по переключению сред, показанные на рис. 2.11, позволяют бабочке максимально увеличить вероятность своего спасения. Однако в общем случае выбор оптимальной последовательности переключении, максимизирующей время жизни автомата, далеко не тривиален.
53
Пусть, например, как и в нашем примере, имеется три случайных среды, которые автомат может переключать своими действиями. И пусть имеется три обычных состояния и три поглощающих (летальных), в которых автомат погибает. Первые три мы, как и ранее, будем обозначать цифрами 1, 2, 3, а поглощающие состояния — цифрами 4, 5, 6. Вместо рисунка, подобного рис. 2.11, зададим три матрицы переходов автомата в трех возможных средах (табл 2.1)
Таблица 2.1
Состо | ЯНИЯ | ||||||
Среда | Состояния | 1 | 2 | 3 | 4 | 5 | 6 |
1 | 0,9 | 0,1 | |||||
2 | 0,95 | 0,05 | |||||
Е1 | 3 4 | 0,8 | 1 | 0,2 | |||
5 | 1 | ||||||
6 | 1 | ||||||
1 | 0,9 | 0,1 | |||||
2 | 0,7 | 0,3 | |||||
E2 | 3 4 | 0,95 | 1 | 0,05 | |||
5 | 1 | ||||||
6 | 1 | ||||||
1 | 0,9 | 0,1 | |||||
2 | 0,92 | 0,08 | |||||
E3 | 3 4 | 0,7 | 1 | 0,3 | |||
5 | 1 | ||||||
6 | 1 |
В табл. 2.1 указаны только ненулевые значения переходных вероятностей Пиij. Если начальное состояние автомата есть i (i== 1, 2, 3), то время жизни автомата можно вычислить по формуле

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 |
