

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
· длина последовательности. Если сортируется последовательность небольшой длины, то следует отдать предпочтение простым методам (как метод пузырька), несмотря на их неблагоприятную асимптотическую сложность;
· знания о степени упорядоченности исходной последовательности. Если ее элементы упорядочены не случайным образом, то методы сортировки благоприятны для использования по-разному;
· побочные условия технического характера. Если последовательность не может быть обработана с использованием только оперативной памяти, а для этого приходится использовать и внешнюю память, то следует принимать во внимание и технические характеристики используемых видов внешней памяти, например время доступа.
Если последовательность в процессе сортировки хранится целиком в оперативной памяти, то говорят о внутренней сортировке. Если же последовательность хранится во внешней памяти, например, организована в файлы, то говорят о внешней сортировке. Как правило, быстрая сортировка (quicksort) наиболее удобна для внутренней сортировки больших последовательностей со случайным упорядочением элементов. Для внешней сортировки предпочтительнее метод слияния.
Понятие: Пути в графах для решения практических задач информатики.
Комментарий: Многие практические задачи информатики могут быть отображены на отношения и графы, описывающие пути. При этом типичны проблемы, связанные с существованием путей в графах. Простейшей постановкой задачи, например, является достижимость (существование пути) в графе, которая родственна образованию транзитивного замыкания для отношения. Другие часто используемые алгоритмы решают вопрос о равенстве структур графов, например, установление изоморфности графов, или другие вопросы эквивалентности.
Понятие: Упорядоченные ориентированные и отсортированные деревья в информатике (как графы).
Комментарий: В указанном подходе имеет место взгляд на деревья как на графы, причем данные представляются в корне и листьях поддеревьев в качестве меток вершин, а функции доступа (селекторы) представляются ребрами. Неориентированное дерево с этой точки зрения есть неориентированный связный ациклический граф. Два неориентированных дизъюнктивных дерева могут быть объединены путем добавления ребра между любыми двумя вершинами, по одной из каждого дерева, в единое неориентированное дерево. Ориентированное дерево есть направленный связный ациклический граф, который содержит одну вершину, называемую корнем, такую, что каждая вершина графа может быть достигнута, исходя из корня, единственным путем. Корень дерева определен однозначно. Лист дерева в представлении дерева в виде графа является вершиной без наследников. Упорядоченное дерево в графовом представлении есть ориентированное дерево, на поддеревьях которого задан порядок следования. Упорядоченные деревья с точки зрения вычислительной структуры могут быть описаны следующим объявлением типа:
sort ordtree = ordtree(m root, seq ordtree subtrees).
Число непосредственных поддеревьев соответствует длине последовательности в дереве в приведенном выше представлении типа. Это число называется степенью ветвимости дерева. Считается, что z-максимальная степень ветвимости какого-либо дерева, если оно само и все его поддеревья имеют степень ветвимости не превосходящую z.
Двоичное дерево является частным случаем упорядоченного дерева. Двоичные деревья имеют максимальную степень ветвимости 2. В дальнейшем, если речь идет об ориентированных деревьях, будет употреблено просто «деревья».
Максимальное число вершин в путях по дереву называется высотой дерева. Высота пустого дерева, таким образом, равна нулю, а высота одноэлементного дерева есть 1. Высота hi(b) дерева b определяется самым длинным путем в дереве. Дерево называется полным, если все его поддеревья имеют одинаковую степень ветвимости и все пути доступа от корня к его листьям имеют одинаковые длины.
Пусть #b есть число вершин в дереве, а m-максимальная степень ветвимости. Для непустого, полного дерева справедливо
hi(b)-1£logmb.
В соответствии с этим в полном дереве число его вершин растет экспоненциально с высотой дерева.
Если на вершинах дерева задан линейный порядок, то ориентированное дерево называется отсортированным, если прохождение по порядку следования вершин дает возрастающую последовательность их содержимого.
Понятие: Представление деревьев массивами.
Комментарий: В машине дерево может быть представлено в виде списка. В этом представлении для хранения дерева требуется дополнительное место для указателей на поддеревья в вершинах. Однако дерево можно так же представить в виде массива, для чего следует расположить дерево в массиве по слоям. Путем использования заполняющих элементов можно представлять и неполные деревья. Впрочем, при этом представлении пропадает много места в памяти, если представляемое дерево является существенно неполным. Также и перестройка так представленных деревьев путем перестановки поддеревьев требует больших затрат и весьма затруднительна.
Понятие: AVL-деревья.
Комментарий: Отсортированное двоичное дерево есть двоичное дерево типа tree m, в котором все вершины в левом поддереве не больше, а в правом поддереве не меньше корня и все поддеревья также отсортированы. Тогда обход дерева в порядке следования вершин (левое поддерево, корень, правое поддерево) дает упорядоченную последовательность. Логическая функция проверяющая отсортированность двоичного дерева, имеет вид:
fct sortiert= (tree m t) bool:
if isempty(t) then true
else sortiert(left(t))Ù
sortiert(right(t))Ù
allnodes(left(t), (m x) bool: x£root(t))Ù
allnodes(right(t), (m x) bool: root(t)£x)
fi
При этом вызов allnodes(t, p) предписания allnodes проверяет, все ли вершины в дереве t выполняют предикат p.
fct allnodes= (tree m t, fct(m) bool p) bool:
if isempty(t) then true
else allnodes(left(t), p)Ù
allnodes(right(t), p)Ù
p(root(t))
fi
AVL-дерево есть отсортированное двоичное дерево, в котором во всех его поддеревьях высоты левого и правого поддеревьев отличаются не более, чем на единицу. Такое дерево называется также сбалансированным. Булевское предписание, проверяющее сбалансированность дерева, имеет вид:
fct isbal=(tree m t) bool:
if isempty(t) then true
else isbal(left(t)Ùisbal(right(t))Ù
· 1£hi(left(t))-hi(right(t))£1
fi
AVL-деревья являются компромиссом между полными и произвольными деревьями. AVL-дерево b высоты hi(b) содержит по меньшей мере 2(hi(b)/3)-2 вершин. Это можно показать индукцией по высоте деревьев. В AVL-деревьях число вершин растет также экспоненциально с высотой дерева.
Понятие: B-деревья.
Комментарий: Другой концепцией для специальных деревьев с интересными свойствами для эффективного управления большими множествами данных являются B-деревья. Хотя для невырожденных двоичных деревьев их высота растет логарифмически с ростом числа вершин, все же реализация с помощью указателей приводит к заметным дополнительным затратам памяти для целей управления. Компромиссом здесь являются так называемые B-деревья. B-дерево либо пусто, либо содержит по меньшей мере n и самое большее 2n непосредственных поддеревьев. B-дерево над типом m, на котором пусть задан линейный порядок, является тогда элементом приведенного ниже объявления типа btree:
sort btree=emptyôcbt(btree first, seq cell rest)
sort cell=mc(m d, btree bt).
При этом для B-деревьев с порядком n предполагается, что все их последовательности поддеревьев содержат от n до 2n элементов. Элементы данных линейно упорядочены в последовательных вершинах. Таким образом, B-дерево есть упорядоченное дерево со степенью ветвимости между n и 2n.
Добавление элемента в B-дерево делается очень просто. Если для вершины последовательности не находится места (поскольку длина последовательности равна 2n), то эту последовательность можно разбить на две последовательности (длины n) и тем самым снова получить B-дерево.
На основании правил работы с массивами обеспечивается, что эти массивы всегда заполнены, по меньшей мере, наполовину. B-деревья используются, в частности, при хранении больших множеств данных во внешней памяти в связи с банками данных.
Понятие: Эффективное представление множеств.
Комментарий: Вычислительная структура множество встречается во многих приложениях. И хотя множества являются конечными, они все же могут иметь очень большую мощность. Эффективность алгоритмов, в которых встречается много операций доступа к большим множествам данных, в решающей мере зависит от того, могут ли быть быстро выполнены операции доступа к множествам. Поэтому для представления больших множеств часто выбирают сложные структуры данных, на которых операции доступа могут быть реализованы эффективно.
В этой части рассматривается структура данных множества со следующими операциями доступа: включение элемента в множество, выяснение принадлежности элемента множеству и-с определенными ограничениями операцию исключения элемента из множества.
Если рассматриваются маленькие множества и необходимы операции пересечения и объединения, то можно порекомендовать представление множеств в виде битовых векторов. При этом подмножества основного множества представляются векторами битов, длина которых соответствует мощности основного множества. Если какой-либо элемент принадлежит множеству, то в соответствующий бит заносится значение true, в противном случае значение false. Такое представление плохо подходит для очень большого основного множества, поскольку теряется много памяти, особенно в том случае, когда должны представляться подмножества с относительно малой мощностью. В этом случае предлагается рассматриваемое ниже представление, а именно методика хеширования.
Понятие: Вычислительная структура множеств с доступом по ключу
Комментарий: В приложениях часто бывают, нужны структуры денных, которые содержат большое количество данных, и доступ, к которым осуществляется с помощью ключей. Пусть дано множество ключей с помощью типа
sort key.
fct key=(data) key.
Выше приведенная функция осуществляет доступ к порциям данных типа data, содержащих в себе компоненту типа key.
При этом предполагается, что каждая порция данных идентифицируется своим ключом. Тогда обращаться к нужной порции данных можно путем задания ключа. Необходимо найти тип store, который позволяет заносить порции данных и получить эффективный доступ к ним. При этом используются следующие функции:
fct emptystore=store,
fct get=(store, key) data,
fct insert=(store, data) store,
fct delete=(store, key) store.
Способ действия этих функций можно представить следующими равенствами:
k = key(d) Þ get(insert(s, d), k) = d
k ¹ key(d) Þ get(insert(s, d), k) = get(s, k),
delete(emptystore, k) = emptystore,
k = key(d) Þ delete(insert(s, d), k) = delete(s, k),
k ¹ key(d) Þ delete(insert(s, d), k) = insert(delete(s, k), d).
Понятие: Метод хэширования.
Комментарий: Метод хэширования позволяет хранить множество элементов в линейном массиве длиной z. Для этого нужна функция расстановки («рассыпания»):
h: keyà[0:z-1],
которая каждый элемент типа key отображает на индекс в множестве [0:z-1]. Эта функция устанавливает, под каким индексом будет храниться данный элемент в массиве. Используем h(m) в качестве индекса (также называемого ключом) для запоминания элемента данных в массиве
sort store = [0:z-1] array data a.
Как правило, число элементов типа key значительно больше, чем z. Тогда функция h наверняка неинъективна. Возможно хранение элемента b с ключом m в массиве a под индексом h(m). Получаются следующие реализации функций:
fct emptystore = store: emptyarray,
fct get = (store a, key k) data: a[h(k)]
fct insert = (store a, data d) store: update(a, h(key(d)), d),
fct delete = (store a, key k) store: update(a, h(k), empty).
Здесь предполагается, что empty обозначает элемент типа data, который играет роль держателя места. Функции работают корректно, пока для всех встречающихся ключей значения функции расстановки различны. Возникает проблема, когда нужно запоминать два различных элемента с ключами m1 и m2, и при этом оказывается h(m1)=h(m2). В этом случае говорят о коллизии.
Для использования метода хэширования надо справиться со следующими проблемами:
· определения величины массива и тем самым числа z значений индексов,
· выбор функции расстановки h,
· определение способа разрешения коллизий.
При этом имеются экспериментальные данные относительно того, сколь большим должен быть выбран массив a, чтобы, с одной стороны, вероятность коллизий не была слишком велика и, с другой стороны, не пропадало слишком много памяти, если заняты не все позиции массива.
Размер массива должен быть выбран таким, чтобы массив был занят не более чем на 90%.
Для выбора функции расстановки следует обратить внимание, что во многих практических применениях множество возможных ключей значительно больше числа допустимых значений индексов. В частности, обычно приходится исходить из того, что должна запоминаться только небольшая часть значений ключей, но при этом заранее не известно, каковы эти значения. Тогда существует заинтересованность в том, чтобы функция расстановки по возможности равномерно отображала множество значений ключей на значения индексов. Таким образом, принимаются предположения статистики.
Если сами ключи также заданы в виде натуральных чисел, например, из интервала от 0 до s-1, где число s значительно больше числа z, то в качестве функции расстановки можно просто взять
h(i) = i mod z.
Эта функция фактически обладает тем свойством, что значения ключей равномерно распределяются по области значений индекса. Таким образом, если с помощью трансформационного отображения возможно значения ключей однозначно отобразить на интервал натуральных чисел, то эту функцию можно использовать в качестве функции расстановки. Впрочем, если имеются какие-то дополнительные статистические данные о распределении ключей, отличном от равномерного, то следует использовать другую, более подходящую функцию расстановки. Следует также обратить внимание, что вычисление этой функции не должно быть слишком трудоемким.
Примером, когда невозможно исходить из равномерного распределения ключей, является запоминание в хэш-памяти слов из некоторого текста. При наивном подходе напрашивается следующий способ действий: последовательные буквы слова кодировать двоичными цифрами и слово текста хранить в полученной таким образом двоичной кодировке, а в качестве функции расстановки принять просто проекцию - например, в качестве значения функции принять код первой буквы слова. Однако этот способ, как правило, неудачен, так как он не сможет обеспечить равномерного распределения ключей по области значений индекса.
Для разрешения коллизий следует поступить следующим образом. Если при возникновении коллизии оба ключа должны быть запомнены в хэш-памяти, то дополнительно к собственно индексу для занесения в хэш-память должен быть найден заменяющий индекс. Здесь речь идет об открытой адресации в методе хэширования.
Предлагается и следующий, принципиально иной способ действий. На каждый индекс в хэш-памяти предусматривается занесение не одного содержимого, а целого их множества. Это может быть реализовано, например, путем образования списка из заносимых значений. Речь идет о непосредственном сцеплении. В этом случае после определения индекса для ключа надо просмотреть этот список и проверить, было ли занесение по этому индексу, и если да, то заносимый элемент должен быть внесен в этот список. Такой способ требует контроля за переполнением хэш-массива, а потому необходимости выделения дополнительной памяти для размещения приводящих к коллизии элементов, которые не удается разместить непосредственно в хэш-памяти. В этом случае говорится о закрытой адресации в методе хэширования.
При открытой адресации дополнительные элементы при коллизии помещаются в самом хэш-массиве. Поиск места в хэш-массиве для занесения элемента в случае возникновения коллизии будем называть зондированием.
Если при вычислении значения индекса для заданного ключа выясняется, что по этому индексу уже занесен элемент данных с другим ключом, то по определенному правилу вычисляется следующий индекс, по которому и заносится элемент данных. Если по этому индексу был уже занесен элемент данных, то вычисляется следующий индекс и т. д. - до тех пор, пока не будет найдено свободное место в массиве.
Если обращаться к какому-либо элементу в хэш-массиве для его чтения, то может случиться так, что по индексу для заданного ключа находится элемент с другим ключом. В таком случае аналогично тому, как это делалось при занесении элементов данных, надо перебирать последовательность значений индекса, по которым мог быть записан этот элемент.
Различают линейное и квадратичное зондирование. При линейном зондировании позиции хэш-массива просматриваются с постоянным шагом, а при квадратичном, исходя из значения h(i),-значения индекса
h(i)+1 mod z, h(i)+4 mod z, h(i)+9 mod z,…,h(i)+j2 mod z.
Простой способ линейного зондирования для определения нового значения индекса в случае коллизии состоит в том, что значение индекса (по модулю z) по мере необходимости увеличивается на 1, пока не будет найдено свободное место в массиве. Впрочем, этот способ имеет то недостаток, что при некоторой статистике скоплений могут возникнуть сгущения в хэш-массиве. Это может привести к тому, что значительные области массива будут интенсивно загружены, вследствие чего потребуется длительный поиск свободного места для заносимого элемента, в то время как другие области будут заняты очень слабо.
Более подходящей будет такая функция разрешения коллизий, которая равномерно распределяет ключи по остальному множеству свободных мест. Однако этот способ может быть очень дорогим. Поэтому на практике ищут компромисс - берут, например, функцию, которая как это показано выше, распределяет ключи квадратичным образом. Впрочем, может случиться, что в процессе поиска по хэш-массиву не будет найдено свободного места для размещения элемента. При квадратичном зондировании будет просматриваться, по меньшей мере, половина массива, если в качестве его длины взято простое число.
Метод хэширования весьма эффективен, если используются только рассмотренные операции над элементами множеств. Если же в определенных приложениях должны использоваться все элементы данных, например, обработка типа сортировки или такие операции над множествами, как объединение и пересечение, то этот метод менее удобен. Чтобы и в этих случаях можно было эффективно работать с хэш-массивами, необходима трудоемкая предварительная сортировка.
Анализ статистики показывает, что метод хэширования чрезвычайно эффективен, если нет слишком большого заполнения хэш-массива. Даже его заполнение на 90% при достаточно удачно выбранном способе зондирования для занесения или выбора нужного элемента в среднем требует 2,56 шага зондирования. Это значение существенно зависит от степени загрузки массива. Поэтому размер хэш-массива следует выбирать таким, чтобы в процессе работы он заполнялся не более чем на 90%.
Отсюда вытекают и недостатки метода хэширования. Если размер массива выбрать слишком большим по отношению к числу фактически хранимых в нем элементов, то значительная часть выделенной памяти будет просто пропадать. Если же размер массива окажется слишком малым, то будет возникать слишком много коллизий, для их устранения придется просматривать длинные списки элементов и по затратам времени метод окажется неэффективным. Недостаток, прежде всего, состоит в том, что размер хэш-массива должен быть выбран и зафиксирован предварительно и этот размер не может быть динамически подогнан к числу фактически заносимых элементов.
Другой недостаток состоит в том, что весьма сложна процедура удаления элементов - особенно в тех случаях, когда используется техника размещения элементов, вызывающих коллизию. В этом случае при удалении элемента придется осуществлять перезапоминание элементов, которые размещались в памяти в результате разрешения коллизии, а это влечет за собой весьма сложные преобразования соответствующих списков.
Существует много различных вариантов метода хэширования. Рафинированные способы хэширования получаются при так называемом “grid file”, когда в хэш-памяти размещается информация с двумерными и многомерными китчами с помощью функций хэширования. Для этого плоскость или пространство делят не растры точками, которые хранятся в таблице, и отсюда определяют функцию хэширования.
Понятие: Методы описаний в программировании. Формализмы для спецификаций.
Комментарий: Существует много различных стилей и формализмов для описания требований, данных и алгоритмов которые находят применение при проектировании, разработке и анализе программных систем. Программы – это вычислительные предписания, а потому они в общем случае подлежат формализации в соответствие с примененным к ним нотациям (смысловым установкам). Различные формализмы по-разному удовлетворяют общим требованиям к нотации, таким, как:
· простота чтения и понимания,
· легкость овладения,
· мощность (границы возможностей нотации),
· выполнимость,
· эффективность выполнения.
Какие веса придать этим критериям, сильно зависит от специфики приложений. В данной главе мы дадим краткое введение в некоторые основные методы описания и программирования.
Для формулирования эффективных алгоритмов, безусловно, требуется точно установить, что должно быть вычислено, не вникая сначала в то, как (по какому алгоритму) это будет вычисляться. Тогда говорят о спецификации задачи или о спецификации требований.
Абстракция в спецификации
В программировании оказывается полезным различать абстрактные вычислительные структуры (называемые также абстрактными типами данных) и структуры данных. При этом речь идет исключительно о разных взглядах на типы и на функции, имеющиеся для них в распоряжении.
Абстрактные структуры данных представляют вид доступа для типа s или для семейства типов s. При этом устанавливается, какие основные операции имеются в распоряжении для элементов данных этого типа. Для этого в сигнатуре задаются доступные для использования функции и их функциональности. Относительно символов функций делается различие между:
· селекторами для доступа к составным частям элемента данных,
· функциями опроса для установления определенных свойств данных (дискриминаторами),
· функциями для построения элементов данных (конструкторами).
В дальнейшем будет использоваться простой частный случай, когда задается вычислительная структура для описания структуры доступа только для одного типа s. Конечно, эти вычислительные структуры опираются на другие типы, которые предполагаются заданными. Функции-конструкторы в качестве типа результата принципиально имеют тип s. Если аргументы функции-конструктора также имеют тип s, то описываемый тип будем называть рекурсивным. При рекурсивных типах также и определенные функции-селекторы имеют тип результата s.
Если в связи с типом s говорится о структуре данных, то тем самым имеется в виду внутреннее строение элементов данных типа s. Это определяет, каким образом структурируются элементы данных внутри себя и как конкретно они реализуются в памяти ЭВМ.
Различение аспектов реализации (англ. Glass Box View) и доступа (англ. Black Box View) является существенным для разработки программы. Аспект доступа определяет интерфейс (разрез) для типа или вычислительной структуры. Этого разреза достаточно для корректного использования типа и имеющихся для него операций. Для оценки эффективности нужны только данные о сложности по времени и по памяти используемых операций.
Аспект реализации касается лишь реализатора типа и содержит в себе все детали реализации. Аспект доступа представляет собой абстракцию аспекта реализации. Существует много структур данных для реализации одних и тех же абстрактных вычислительных структур. При использовании вычислительной структуры пользователю нужно знать лишь аспект доступа, реализация же может быть скрыта от него (англ. information hiding). Это имеет решающие преимущества:
· пользователь не обязан знать порой сложные, трудно просматриваемые детали реализации вычислительной структуры, ему достаточно знать лишь ее абстрактный аспект доступа. Этот аспект служит для документирования;
· реализация может производиться параллельно с программированием, при котором используется эта вычислительная структура. Основой для взаимопонимания служит аспект доступа;
· реализация может быть изменена, и пользователь может даже не знать об этом, если только сохраняется аспект доступа.
Центральным для этого метода разделения аспектов доступа и реализации является понятие точки разреза, или интерфейса (англ. interface). Последовательное разделение этих аспектов является показателем хорошего стиля разработки программного оборудования, особенно при создании сложных программных систем. Этот принцип используется не только применительно к структурам данных - он может быть перенесен и на другие программные единицы, такие, как процедуры, модули и классы.
Для методов информатики особенно типично, что взгляды на типы как абстрактные структуры данных и как структуры данных разбиваются на слои. Здесь говорится об уровнях абстракции. Так, над абстрактной вычислительной структурой Р, которая описывает платформу реализации, с помощью определенных функций можно построить аспект структуры данных для другой вычислительной структуры А. Здесь говорится о реализации одной из вычислительных структур. А над вычислительной структурой Р.
Спецификация абстрактных, вычислительных структур, в том числе для аспектов интерфейса информационных систем.
При разработке программных систем одной из важнейших задач является выбор и спецификация основных вычислительных структур. Для описания вычислительных структур предлагаются следующие возможности:
· моделирование с помощью заданных структур (способ, ориентированный на модели), например через множества, отношения, абстрактные машины;
· характеризация свойств через логику предикатов или через законы равенств ("алгебраическая спецификация").
Ниже кратко обрисована техника алгебраических спецификаций, так как она особенно хорошо подходит для описания аспектов интерфейса информационных систем (ИС). Вычислительную структуру можно алгебраически специфицировать путем
(1) задания сигнатуры,
(2) задания законов, характеризующих отображения.
В алгебраической спецификации абстрактная вычислительная структура описывается через ее сигнатуру и ее законы.
Спецификация функций.
Одной из самых элементарных концепций математики являются функции и абстракции функций. Программы (вычислительные предписания) в простейшем случае реализуют (вычисляют) определенные функции. Тем самым спецификация программ соответствует спецификации функций.
Чтобы специфицировать функцию f, сначала задается ее функциональность. Например, пишется
Fct f= (s1,…..,sn) Sn+1.
Для заданной S - вычислительной структуры могут быть специфицированы с помощью равенств.
При этом задается некоторое количество правил, которые устанавливают требования к f, но не обязательно описывают функцию однозначно. В этом случае говорят, что функция f не полностью специфицирована.
Пример (спецификации функций). На вычислительной структуре BOX можно специфицировать, например, следующие функции.
(1) Увеличение на единицу всех элементов конечного множества:
дополнительно к функциональности
fct incr_all = (set nat) set nat,
задаются следующие два равенства:
incr_all(put(b, x)) = put(succ(b), incr_all(x)), incr_all(emptybox) = emptybox.
(2) Функция выбора для множества: дополнительно к функциональности
fct any = (set data s: not(isempty(s))) data задается следующее равенство:
iselem(put(b, x), any(put(b, x))) = true.
Наряду с равенствами для спецификации функций используются также общие предикаты. С помощью предикатов задаются, какие отношения существуют между входом и выходом.
Обращается внимание на то, что для многих постановок задач вовсе не обязательно, чтобы спецификация задавала функцию однозначно. Здесь говорится о степенях свободы в спецификации, о неполной спецификации или об открытости принятия решений по проекту.
Спецификация операторов.
Оператор представляет собой функцию (или - в недетерминированном случае - отношение) между состояниями. Состояния можно понимать как специальный объект некоторого типа. Представляются состояния как отображения множества программных переменных в VAR на значения из DATA. Тем самым для множества состояний STATE справедливо.
STATE = defVAR -> DATA.
Соответственно этому предикаты на состояниях можно представить в виде отображений вида
PRED: STATE -> В.
Эти предикаты могут использоваться в качестве утверждений для спецификации операторов. Оператор соответствует отображению
STATE -> STATE.
Метод утверждений позволяет специфицировать программу путем задания предикатов. Оператор специфицируется двумя предикатами, называемыми предусловием Q и постусловием R. При этом имеет место R, Q Î PRED. Оператор
f: STATE -> STATE
удовлетворяет этой спецификации, если справедливо следующее высказывание:
" s ÎSTATE: Q(s) => R(f(s)).
Таким образом, оператор специфицируется парой предикатов (Q, R). Утверждение Q может пониматься как предположение об исходном состоянии, а R специфицирует утверждение о выходном состоянии в случае выполнения предположения. Поэтому говорится также s спецификациях предположение/утверждение (англ. rely/guarantee или также assumption/commitment).
Понятие: Базы данных и информационные системы (ИС) – с позиций алгебры логики (информатики).
Комментарий: Отметим, что в первичные структуры данных полезны для формулирования алгоритмов вычисления определенных функций. Однако наряду с вычислением функций одной из центральных задач информатики является длительное хранение данных и контролируемый доступ к ним. Эти задачи обсуждаем под терминами (компьютерные) информационные системы (ИС) и базы данных (БД).
Базы данных (БД) в рамках задачи управления информацией охватывают:
1. описание имеющихся данных,
2. управление данными как частью вычислительной (информационной) системы;
3. доступ к данным.
Информационная система (ИС) содержит информацию, необходимую для управления и контроля задачами пользователя.
При разработке какой-либо базы данных (БД) для определенного применения необходимо построить модель данных, в которой представлены все виды информации, которые будут храниться в базе данных.
Но модель данных, независимо от задачи описания базы данных, также должна быть применима для всех релевантных данных для определенного применения.
Понятие: Моделирование отношений сущность/связь – построение модели данных при проектировании информационных систем.
Комментарий: Модель данных можно задать с помощью спецификации вычислительной структуры. В народнохозяйственных применениях информатики встречаются большие множества однотипных данных. Примерами являются данные о наличии клиентов, товаров или сотрудников предприятия. Такие данные тоже можно охватить через вычислительные структуры. Однако для таких больших множеств данных удобнее применять специальные способы описания. Общим методом описания для информационных систем (ИС) и баз данных (БД), и в частности для моделирования данных с большим их числом, является так называемая сущность/связь-модель (англ. Entity/Relationship Model), или, короче, E/R-модель. При этом наличные данные представляются множествами элементов данных, а связи между основными элементами представляются через отношения.
При проектировании информационной системы (ИС) создание модели нужно для того, чтобы охватить задачи управления, лежащие в основе информационной системы (ИС). В моделировании данных охватывается вся информация, имеющая значение для применений.
Типичным образом модели данных и базы данных содержат определенные основные единицы информации, называемые сущностями. Каждая сущность имеет обозначение и представляет множество элементов (записи) определенного типа. Запись называется проявлением (воплощением) сущности. Тип определяет совокупность всех записей, которые могут рассматриваться как сущность. Между сущностями имеются определенные связи, называемые отношениями, которые устанавливают "семантические связи" между сущностями.
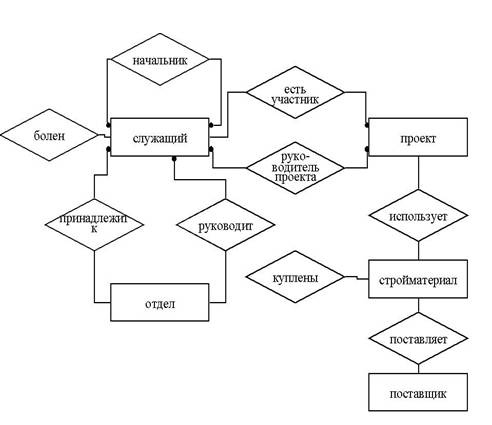
Рис 1. Диаграммы сущность/связь.
Характеризация связей
Связь состоит из обозначения и указания фигурирующих сущностей, а также типа связи. В соответствии с числом вовлеченных сущностей говорится о n-местном отношении (или также об отношении степени n).
Обычно связи между сущностями обусловлены их свойствами, используемыми в данной области применений. Например, один сотрудник может участвовать в нескольких проектах, но может принадлежать только одному из отделов предприятия.
Многие E/R-диаграммы позволяют характеризовать такие свойства отношений взаимосвязи, как:
· во всех допустимых состояниях сущностей элементы присутствуют в кортежах отношения в количестве, лежащем в некотором заданном интервале;
· отношение является однозначным справа, однозначным слева, взаимно однозначным (n:1-, 1:n - и 1:1-взаимосвязи).
В зависимости от мощности языка описаний для модели баз данных могут быть выражены более или менее сложные взаимосвязи.
Атрибуты могут быть также определены и для связей между множествами сущностей. Это значит, что для каждого элемента в связи (каждого элемента кортежа) специфицируются дополнительные значения.
Пример (атрибуты между взаимосвязями). Взаимосвязь "есть руководитель проекта" могла бы иметь атрибут "с: дата" и "предшественник: сотрудник".
Во многих приложениях встречаются специальные взаимосвязи, как, например, "есть тот-то" - взаимосвязь, которая допускает классификацию сущностей. Если, например, существуют сущности "руководитель отдела" и "сотрудник", то между ними может иметь место взаимосвязь "есть тот-то". Эта взаимосвязь разрешает перенесение атрибутов. Если какой-то руководитель отдела является сотрудником предприятия, то все атрибуты сотрудника наследуются и руководителем отдела (переносятся на него). Определенные конструкции "представления знаний", такие, как "фреймы" и формы "объектно-ориентированного" моделирования, используют подобного рода концепции наследования, иерархии и образования классов в качестве базы для спецификаций.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
