
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Заметим, что пересчёт правого и левого коэффициентов дерева, выполненный в объемлющем языке, работает быстрее, чем реализованный в «чистом» SQL.
Таким образом, главный недостаток метода вложенных множеств состоит в том, что при изменении в структуре дерева (удалении, добавлении узлов) приходится заново пересчитывать значения правого и левого коэффициентов для всей таблицы. Это довольно трудоёмкая процедура, особенно в случае больших иерархий. Поэтому такой способ годится только для небольших и/или редко изменяемых таблиц.
Обратите внимание. Порядок узлов внутри каждого уровня уже задан значениями правого/левого коэффициентов. Если требуется поддерживать несколько различных вариантов упорядочения узлов внутри уровней, можно добавить дополнительные пары левого и правого коэффициентов для каждого варианта упорядочивания.
Задачи
Создайте таблицу, описывающую абстрактную иерархию со структурой с правым и левым коэффициентами. Заполните её данными. На основе этой таблицы сформируйте и выполните SQL-предложения, решающие следующие задачи:
1. Определить корневой элемент иерархии.
2. Определить непосредственного предка некоторого заданного элемента.
3. Определить, что заданный элемент не имеет потомков.
4. Выбрать все элементы иерархии, не имеющие потомков (листья).
5. Выбрать всех потомков заданного элемента (выбрать поддерево, начиная с заданного узла).
6. Выбрать всех предков для заданного узла.
7. Определить расстояние от корня до заданного узла.
8. Определить уровень в иерархии заданного узла относительно другого узла.
Задачи повышенной сложности
1. Выбрать всех непосредственных потомков для некоторого заданного элемента.
2. Найти ближайшего общего предка для нескольких наперёд заданных узлов.
3. Написать хранимые процедуры для пересчёта правого и левого коэффициентов при удалении узлов в иерархии.
4. Написать хранимые процедуры для пересчёта правого и левого коэффициентов при добавлении узлов в иерархию.
5. Рассмотреть вариант модели, когда значения правого и левого коэффициентов для листьев в дереве устанавливаются равными.
2.3. Способ вспомогательной таблицы
Способ, описанный Ральфом Кимбаллом, может рассматриваться как расширенный вариант рекурсивного способа. Здесь модель дерева строится на основе двух таблиц. Первая таблица (базовая) хранит список всех узлов, снабжённых уникальными идентификаторами, и всю содержательную информацию по каждому узлу.
Таблица 5
Пример основной таблицы
Уникальный идентификатор узла | Содержательная часть |
A | A |
B | B |
C | C |
D | D |
E | E |
F | F |
G | G |
H | H |
I | I |
J | J |
K | K |
L | L |
M | M |
N | N |
O | O |
P | P |
Создадим эту таблицу:
CREATE TABLE T_Base
(ID uniqueidentifier DEFAULT NEWID() primary key,
Node varchar not null);
В этом примере для идентификаторов узлов дерева, хранимых в столбце ID, использован тип данных UNIQUEIDETIFIER, который будет заполняться автоматически при добавлении записей в таблицу (значение по умолчанию для этого столбца генерируется функцией NEWID()) и является первичным ключом.
Заполним таблицу данными (значения для столбца ID вводить не требуется):
INSERT INTO T_Base (Node) VALUES ('A');
INSERT INTO T_Base (Node) VALUES ('B');
INSERT INTO T_Base (Node) VALUES ('C');
INSERT INTO T_Base (Node) VALUES ('D');
INSERT INTO T_Base (Node) VALUES ('E');
INSERT INTO T_Base (Node) VALUES ('F');
INSERT INTO T_Base (Node) VALUES ('G');
INSERT INTO T_Base (Node) VALUES ('H');
INSERT INTO T_Base (Node) VALUES ('I');
INSERT INTO T_Base (Node) VALUES ('J');
INSERT INTO T_Base (Node) VALUES ('K');
INSERT INTO T_Base (Node) VALUES ('L');
INSERT INTO T_Base (Node) VALUES ('M');
INSERT INTO T_Base (Node) VALUES ('N');
INSERT INTO T_Base (Node) VALUES ('O');
INSERT INTO T_Base (Node) VALUES ('P');
Выберем все столбцы и строки полученной таблицы, отсортировав строки по полю Node:
SELECT * FROM T_Base ORDER BY Node;
Результат выполнения этого предложения SQL в среде SQL Server Management Studio Express представлен на рис. 75.
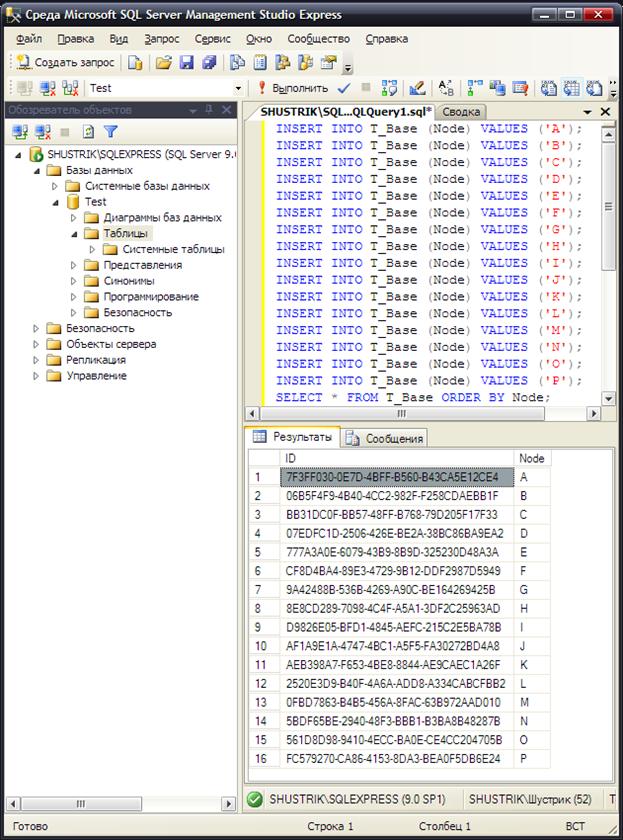
Рис. 75. Заполнение основной таблицы модели иерархии
Теперь дополним основную таблицу, содержащую перечень всех узлов иерархии, вспомогательной таблицей. Конечно, иерархию можно было представить и в виде одной таблицы, но в этом случае содержательная часть каждого узла будет повторяться для всех строк, связанных с каждым из узлов, что нежелательно с точки зрения нормализации.
Вспомогательная таблица по своей структуре похожа на таблицу со ссылкой на непосредственного предка, но, в отличие от неё, содержит все полные пути от корневого элемента до каждого узла иерархии в виде наборов пар «родитель-потомок». Здесь потомок может не быть непосредственным (прямым) потомком родителя, поэтому для каждой такой пары указывается расстояние («степень родства») от предка до потомка.
Корневые узлы деревьев могут быть обозначены как имеющие в качестве предка самих себя с нулевым расстоянием или, в вариантном исполнении, запись, соответствующая корневому узлу дерева, может просто отсутствовать во вспомогательной таблице.
Первичный ключ во вспомогательной таблице составят все три столбца.
Структура такой таблицы и ее содержимое для иерархии, представленной на рис. 1, показана в таблице 6.
Таблица 6
Пример структуры вспомогательной таблицы
Уникальный идентификатор узла | Указатель на предка узла | Расстояние до предка |
A | A или NULL | 0 |
B | A | 1 |
C | A | 1 |
D | A | 2 |
D | B | 1 |
E | A | 2 |
E | B | 1 |
F | A | 2 |
F | C | 1 |
G | A | 2 |
G | C | 1 |
H | A | 2 |
H | C | 1 |
I | A | 3 |
I | B | 2 |
I | D | 1 |
J | A | 3 |
J | B | 2 |
J | E | 1 |
K | A | 3 |
K | B | 2 |
K | E | 1 |
L | A | 3 |
L | B | 2 |
L | E | 1 |
O | A | 3 |
O | C | 2 |
O | F | 1 |
M | A | 3 |
M | C | 2 |
M | G | 1 |
N | A | 3 |
N | C | 2 |
N | G | 1 |
P | A | 3 |
P | C | 2 |
P | H | 1 |
Создадим вспомогательную таблицу для уже имеющейся базовой таблицы с помощью следующего предложения SQL:
CREATE TABLE T_Helper (
UID uniqueidentifier references T_Base(ID) NOT NULL,
ParentID uniqueidentifier references T_Base(ID) NOT NULL,
[Level] int NOT NULL,
PRIMARY KEY (UID, ParentID, [Level]));
После заполнения данными базовая таблица имеет следующий вид:
Таблица 7
Таблица T_Base после заполнения данными
ID | Node |
7F3FF030-0E7D-4BFF-B560-B43CA5E12CE4 | A |
06B5F4F9-4B40-4CC2-982F-F258CDAEBB1F | B |
BB31DC0F-BB57-48FF-B768-79D205F17F33 | C |
07EDFC1DE-BE2A-38BC86BA9EA2 | D |
777A3A0EB9-8B9D-325230D48A3A | E |
CF8D4BA4-89EB12-DDF2987D5949 | F |
9A42488B-536B-4269-A90C-BEB | G |
8E8CDC4F-A5A1-3DF2C25963AD | H |
D9826E05-BFD1-4845-AEFC-215C2E5BA78B | I |
AF1A9E1A-4747-4BC1-A5F5-FA30272BD4A8 | J |
AEB398A7-F653-4BE8-8844-AE9CAEC1A26F | K |
2520E3D9-B40F-4A6A-ADD8-A334CABCFBB2 | L |
0FBD7863-B4B5-456A-8FAC-63B972AAD010 | M |
5BDF65BEF3-BBB1-B3BA8B48287B | N |
561D8DECC-BA0E-CE4CC204705B | O |
FC579270-CADA3-BEA0F5DB6E24 | P |
Обратите внимание! Значения в столбце ID на каждом рабочем месте будут свои! Они также будут различаться и на одном рабочем месте при каждой новой попытке заполнения таблицы.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
