
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Федеральное агентство по образованию
Уральский государственный технический университет - УПИ
МОДЕЛИРОВАНИЕ ИЕРАРХИЧЕСКИХ ОБЪЕКТОВ
СРЕДСТВАМИ РЕЛЯЦИОННЫХ СУБД
Научный редактор проф., д-р техн. наук
Печатается по решению редакционно-издательского совета
УГТУ-УПИ от 01.01.2001 г.
Екатеринбург
УГТУ-УПИ
2007
УДК 004.652(075.8)
ББК 32.973-018.2я73
Е72
Рецензенты:
Институт математики УрО РАН, зав. лаб. компьютерных технологий, с. н. с. , к. ф.-м. н..
Е72 Моделирование иерархических объектов средствами реляционных СУБД: учебное пособие/ . Екатеринбург: УГТУ-УПИ, 2007.-132 с.
ISBN
Учебное пособие содержит сведения о способах моделирования произвольных абстрактных иерархических объектов (деревьев) средствами реляционных СУБД. Описаны базовые способы отображения абстрактных иерархических структур в реляционные структуры данных: рекурсивный, правого и левого коэффициентов, вспомогательной таблицы. Для каждого из способов рассмотрены возможности выполнения операций выборки поддерева, нахождения корневых элементов и листьев деревьев, добавления элементов в иерархии и их удаления. Также рассматриваются два частных случая: иерархия с ограниченным количеством уровней и иерархия с ограниченным количеством потомков для всех узлов. Пособие содержит варианты заданий для самостоятельной работы по данной теме.
Издание предназначено для студентов специальностей 230201 – Информационные системы и технологии и 080801 – Прикладная информатика в экономике.
Библиогр.: 13 назв. Табл. 16. Рис. 87.
Подготовлено кафедрой «Анализ систем и принятие решений»
УДК 004.652(075.8)
ББК 32.973-018.2я73
ISBN
© ГОУ ВПО «Уральский государственный технический университет – УПИ», 2007
© 2007 г.
Оглавление
1. Основные понятия и определения.. 4
1.1. Иерархическая модель данных.. 4
1.2. Реляционная модель данных.. 9
1.3. Задача моделирования.. 9
2. Три базовых способа моделирования иерархий.. 11
2.1. Рекурсивный способ представления иерархии.. 11
2.2. Способ правого и левого коэффициентов.. 59
2.3. Способ вспомогательной таблицы.. 94
3. Два важных частных случая.. 119
3.1. Случай ограниченного количества уровней иерархии 119
3.2. Случай ограниченного числа потомков.. 122
Заключение. 124
Библиографический список.. 130
1. Основные понятия и определения
1.1. Иерархическая модель данных
"Дерево" может быть определено как иерархия узлов с попарными связями, в которой:
· самый верхний уровень иерархии имеет единственный узел, называемый корнем;
· каждый узел, кроме корня, связан с одним и только одним узлом, находящимся на более высоком уровне по сравнению с ним самим.
И т. д.
"Дерево" может быть представлено как специальный вид направленного графа. Графы – структуры данных, состоящие из узлов, связанных дугами. Каждая дуга показывает однонаправленную связь между двумя узлами. Вершина графа называется корнем (рис. 1). Остальные элементы называют узлами иерархии.
Узел, связанный с данным узлом и находящийся на более низком уровне в иерархии, называют дочерним узлом или потомком данного узла.
Узел, связанный с данным узлом и находящийся на более высоком уровне в иерархии, называют родительским узлом или предком данного узла. Потомки, или дети, родительского узла – все узлы в поддереве, имеющие родительский узел корнем.
Узлы дерева, которые не имеют потомков, называют листьями (рис. 1).
В общем случае, дерево называется n-мерным, если его некоторый узел может иметь не более чем n узлов - потомков. Все элементы иерархии показаны на рис. 2 – 5.
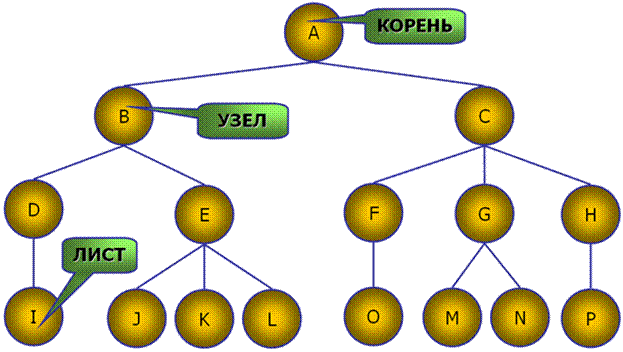
Рис. 1. Основные элементы иерархии

Рис. 2. Уровни иерархии
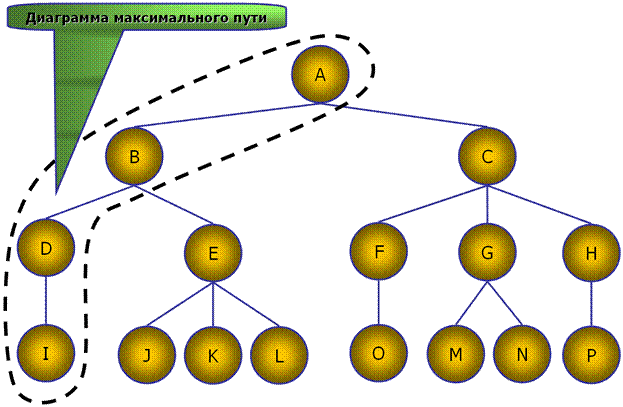
Рис. 3. Диаграмма максимального пути

Рис. 4. Глубина пути в иерархии
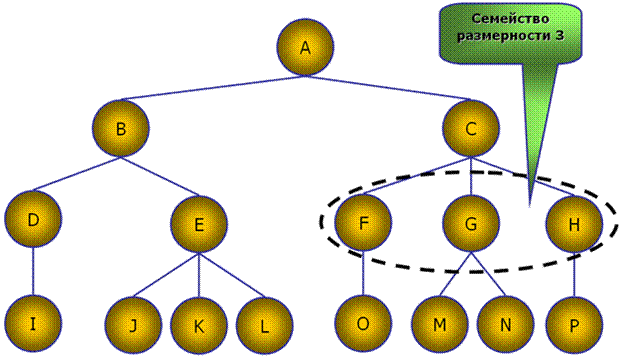
Рис. 5. Семейство и размерность семейства иерархии

Рис. 6. Стандартное графическое представление иерархии в ОС MS Windows
Другой способ представления иерархий – вложенные множества. Здесь корень дерева – это внешнее или объемлющее множество, содержащее все узлы дерева. Каждый узел в дереве рассматривается как множество своих потомков (рис. 7).
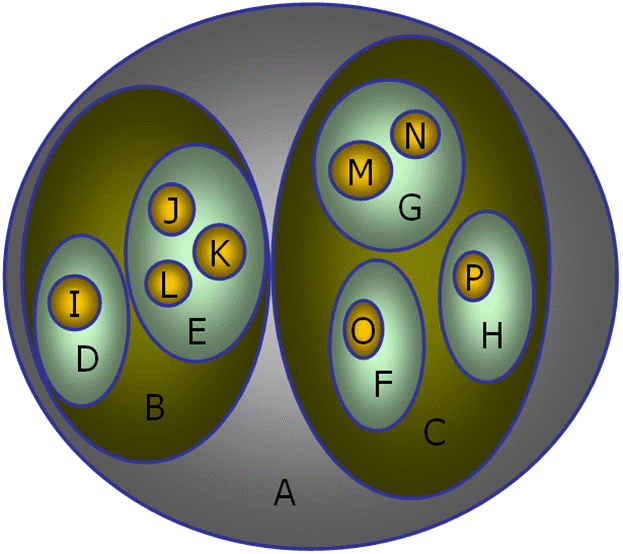
Рис. 7. Представление иерархии как набора вложенных множеств
В качестве примеров использования иерархий для моделирования объектов реального мира можно отметить организационные диаграммы (графы), генеалогические деревья, карты как описания географических объектов и т. п.
Для работы с данными этого типа еще в 60-70 гг. прошлого века были разработаны иерархические СУБД, например IBM IMS, выполняющаяся на компьютерах IBM с архитектурой System/360, System/370, System/390, System z. Однако подобные продукты в настоящее время в нашей стране не имеют широкого распространения. Другие средства работы с иерархиями предоставляются XML.
1.2. Реляционная модель данных
Реляционные СУБД создавались таким образом, чтобы пользователи воспринимали их как совокупность таблиц. Архитектура реляционных баз данных ориентирована на хранение в отношениях (таблицах) информации о сущностях и связях между ними. Важной особенностью реляционной модели является наличие простого и мощного языка запросов SQL.
1.3. Задача моделирования
В реляционных СУБД организация хранения информации о независимых друг от друга экземплярах сущностей (так называемых «плоских» данных) не вызывает никаких затруднений. Однако в реляционной модели и языке SQL нет встроенных средств поддержки иерархических структур данных. Практически любая промышленная база данных должна обладать возможностями хранения данных с иерархической организацией. На практике, при построении информационных систем, приходится обеспечивать хранение в реляционной БД информации о «вложенных» друг в друга сущностях, т. е. иерархические данные (самой распространенной иерархической структурой является организационная структура предприятия, в которой отражаются отношения между различными подразделениями и их служащими, представляющиеся при помощи деревьев). Организация хранения такой информации в реляционных БД не очевидна.
Наиболее часто возникают следующие задачи, характерные только для иерархий:
· определить, находится ли узел А в поддереве, вершиной которого является узел Б;
· выбрать непосредственного родителя узла А;
· выбрать всех родителей узла А в порядке их уровня в дереве;
· выбрать все узлы, находящиеся в поддереве, вершиной которого является узел А;
· выбрать все узлы, непосредственным родителем которых является узел А;
· определить наиболее близкого общего родителя для узлов А и B.
Кроме того, существуют более сложные задачи, например задача объединения деревьев, обратная задача – выделение (удаление) поддерева из иерархии, получение количества всех потомков у данного элемента, вычисление того, на каком уровне находится некоторый узел, или требуется получить список всех потомков заданного узла, у которых, в свою очередь, нет потомков и т. п.
2. Три базовых способа моделирования иерархий
В реальности каждый элемент иерархии имеет содержательную часть и должен быть снабжён уникальным идентификатором (вставить пример о больнице). При изучении способов моделирования иерархических структур средствами реляционных СУБД мы будем рассматривать абстрактную иерархию, представленную на рис. 1, где содержимое узла иерархии и его уникальный идентификатор полагаем совпадающими.
2.1. Рекурсивный способ представления иерархии[1]
Классически проблема представления иерархий решается с помощью рекурсивной связи, что позволяет хранить в одной таблице дерево любой глубины и размерности. Приведём пример такой таблицы для иерархии, представленной на рис. 8, табл. 1.

Рис. 8. Пример иерархии или дерева
Таблица 1
Реляционная модель иерархии, представленной на рис. 8
Уникальный идентификатор узла | Указатель на непосредственного предка узла | Содержательная часть |
A | A или NULL | A |
B | A | B |
C | A | C |
D | B | D |
E | B | E |
F | C | F |
G | C | G |
H | C | H |
I | D | I |
J | E | J |
K | E | K |
L | E | L |
O | F | O |
M | G | M |
N | G | N |
P | H | P |
Таблицу можно создать следующим предложением SQL:
CREATE TABLE T (Id INT NOT NULL IDENTITY PRIMARY KEY,
Parent INT NOT NULL REFERENCES T(Id)[Ш1] ,
Data VARCHAR);
Здесь создаётся таблица с именем T и тремя столбцами Id, Parent и Data (рис. 9).
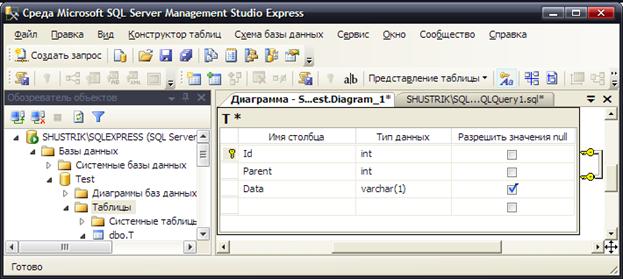
Рис. 9. Просмотр созданного отношения в среде MS SQL Server Management Studio Express.
Столбец с именем Id должен содержать уникальные идентификаторы текущих узлов. В примере для него определён целочисленный тип данных с автоматическим наращиванием, хотя можно использовать и любой другой, наилучшим образом соответствующий описываемой предметной области. Для создания искусственных уникальных идентификаторов во многих диалектах SQL имеется специальный тип данных uniqueidentifier. Столбец Id не должен иметь неопределённых значений. Кроме того, он объявляется первичным ключом.
Parent – это столбец, значения которого указывают на непосредственного предка текущего элемента. Тип данных этого столбца должен соответствовать типу данных столбца Id. В столбце Parent могут находиться только те значения, которые уже имеются в столбце Id, т. е. значения в этом поле являются ссылками (указателями) на поле Id – внешним ключом при замыкании таблицы на себя. Наличие неопределённых значений в этом столбце запрещено[Ш2] .
При решении практических задач данная таблица должна быть снабжена
столбцами для хранения содержательной части узлов дерева. В приведённом выше предложении SQL, создающим таблицу, – это столбец с именем Data.
Заполним таблицу данными в соответствии с рис. 8, с помощью следующих предложений SQL:
INSERT INTO T (Parent, Data) VALUES (1, 'A');
INSERT INTO T (Parent, Data) VALUES (1, 'B');
INSERT INTO T (Parent, Data) VALUES (1, 'C');
INSERT INTO T (Parent, Data) VALUES (2, 'D');
INSERT INTO T (Parent, Data) VALUES (2, 'E');
INSERT INTO T (Parent, Data) VALUES (3, 'F');
INSERT INTO T (Parent, Data) VALUES (3, 'G');
INSERT INTO T (Parent, Data) VALUES (3, 'H');
INSERT INTO T (Parent, Data) VALUES (4, 'I');
INSERT INTO T (Parent, Data) VALUES (5, 'J');
INSERT INTO T (Parent, Data) VALUES (5, 'K');
INSERT INTO T (Parent, Data) VALUES (5, 'L');
INSERT INTO T (Parent, Data) VALUES (6, 'O');
INSERT INTO T (Parent, Data) VALUES (7, 'M');
INSERT INTO T (Parent, Data) VALUES (7, 'N');
INSERT INTO T (Parent, Data) VALUES (8, 'P');
После заполнения данными из примера на рис. 8, таблица получает следующий вид (рис. 10).
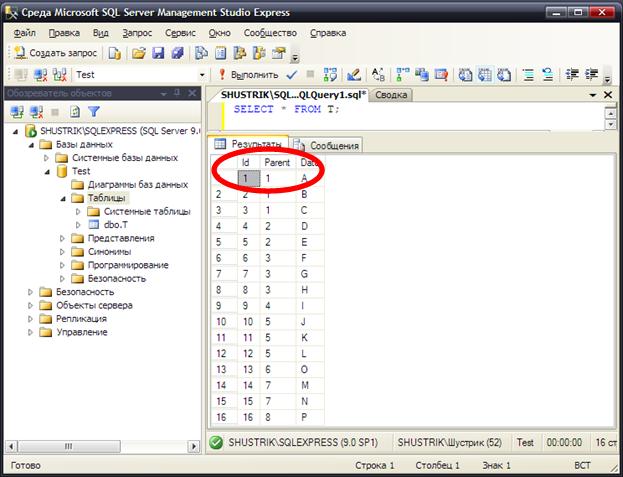
Рис. 10. Таблица заполнена данными
Обратите внимание. Корневой элемент иерархии не может иметь предка по определению. Таблица, полученная в результате выполнения нашего SQL предложения, не допускает неопределённых значений ни в одном из столбцов. Поэтому, при добавлении в таблицу соответствующей записи, для корневого элемента дерева следует указать в качестве непосредственного предка идентификатор самого корневого элемента.
Не рекомендуется создавать корневой элемент с неопределённым значением для поля указателя на предка, а затем накладывать ограничение FOREIGN KEY, так как восстановление такой базы данных из резервной копии будет невозможно (попробуйте самостоятельно ответить на вопрос – почему в этом случае будет невозможно восстановление базы из резервной копии).
Чтобы получить из таблицы T все корневые элементы, достаточно выполнить запрос:
SELECT * FROM T WHERE Parent=Id;
Результат выполнения запроса представлен на рис. 11.
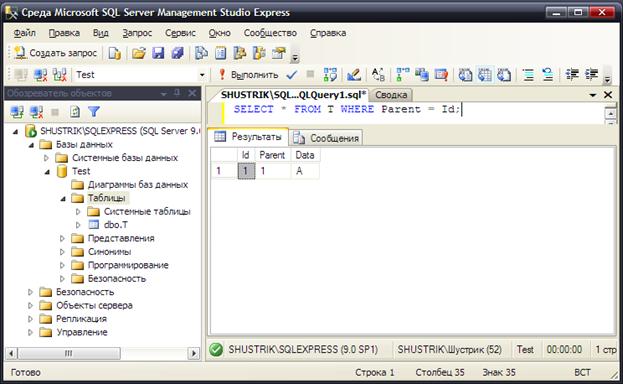
Рис. 11 Результат выполнения запроса на получение корневого элемента иерархии
В вариантном исполнении ограничение на то, что поле, указывающее непосредственного предка, не может содержать неопределённые значения, может быть снято. Тогда наличие неопределённого значения может быть использовано как признак корня дерева.
SELECT * FROM T WHERE Parent=NULL;
В общем случае (кроме случая совпадения идентификатора узла и идентификатора его предка) в качестве признака того, что элемент является корневым, может быть любое значение столбца Parent, которое не используется в качестве уникального идентификатора узла.
Идентификаторы узлов можно получить следующим предложением SQL:
SELECT Id FROM T;
В этом примере результат этого запроса будет следующий (рис. 12).

Рис. 12. Список идентификаторов всех узлов иерархии
Если в таблице хранится несколько независимых иерархий, все корневые элементы можно определить таким образом:
SELECT * FROM T WHERE Parent NOT IN (SELECT Id FROM T);
Далее, если не оговорено иное, будем полагать, что структуры данных используются для представления единственной иерархии.
Обратите внимание. Столбец «Указатель на непосредственного предка узла» содержит список всех узлов дерева, имеющих потомков, т. е. не являющихся листьями.
Если идентификатор узла не содержится в столбце «Указатель на непосредственного предка узла», это значит, что данный узел не имеет потомков (данный узел является листом дерева). Когда в таблице хранится единственная иерархия, для того, чтобы получить список всех листьев, нужно выбрать те значения из столбца «Уникальный идентификатор узла», которые отсутствуют в столбце «Указатель на непосредственного предка узла».
Для того что бы выбрать все узлы (без повторов), имеющие потомков, выполняется следующее SQL-предложение (рис. 13):
SELECT DISTINCT Parent FROM T;
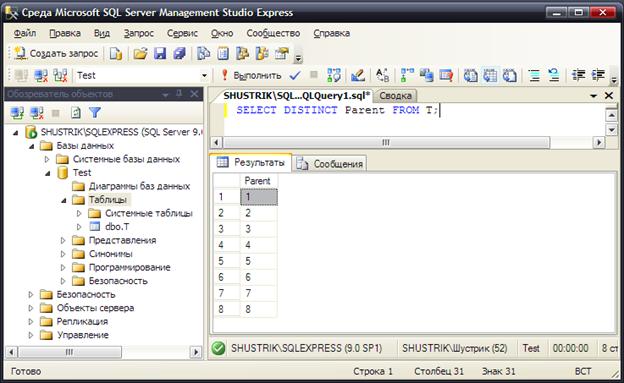
Рис. 13. Список всех узлов, имеющих потомков
Тогда список узлов, не имеющих потомков, получаем как выборку имён узлов, не входящих в список узлов, являющихся предками других узлов (рис. 14):
SELECT DISTINCT Id, Data FROM T
WHERE Id NOT IN (SELECT DISTINCT Parent FROM T);
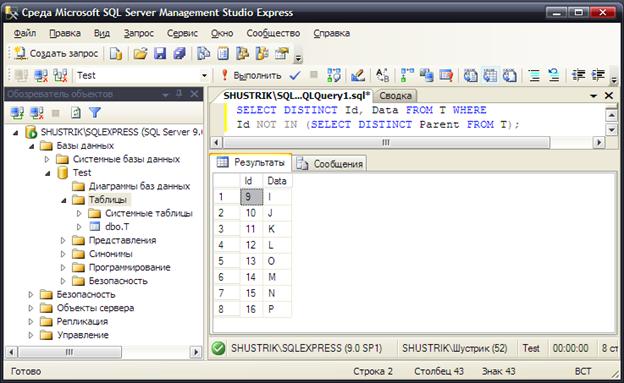
Рис. 14 Список листьев (список узлов, не имеющих потомков)
Другой вариант запроса с таким же результатом, но с использованием EXIST (рис. 15):
SELECT * FROM T AS E1 WHERE NOT EXISTS
(SELECT * FROM T AS E2 WHERE E1.Id=E2.Parent);
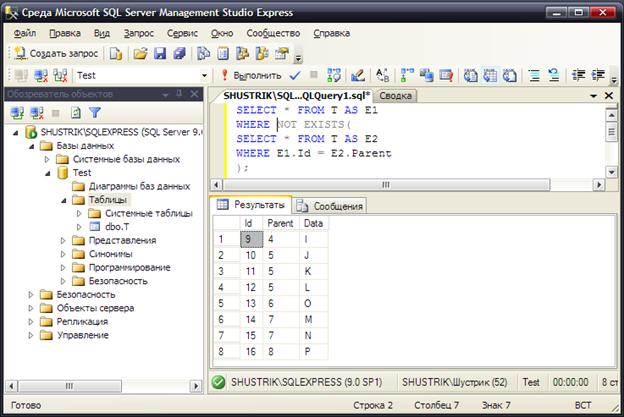
Рис. 15. Результат выполнения запроса на поиск листьев с использованием оператора EXIST
Данная структура является минимально необходимой и достаточной для организации иерархии в реляционной СУБД. Её называют структурой со ссылкой на предка. Пользуясь такой таблицей, легко можно найти родителя или потомка некоторого произвольного элемента.
Для того чтобы получить всех потомков, например узла E, нужно использовать его уникальный идентификатор - Id в том же самом запросе как идентификатор родителя.
Получаем идентификатор узла E (рис.16):
SELECT Id FROM T WHERE Data='E';
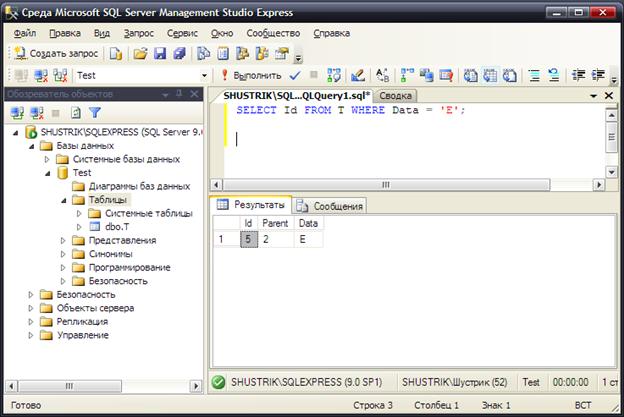
Рис. 16. Результат выборки идентификатора узла E
Далее выбираем все узлы, для которых идентификатор непосредственного предка равен идентификатору узла E:
SELECT * FROM T WHERE Parent=5;
Результат этого запроса будет выглядеть следующим образом (рис. 17).
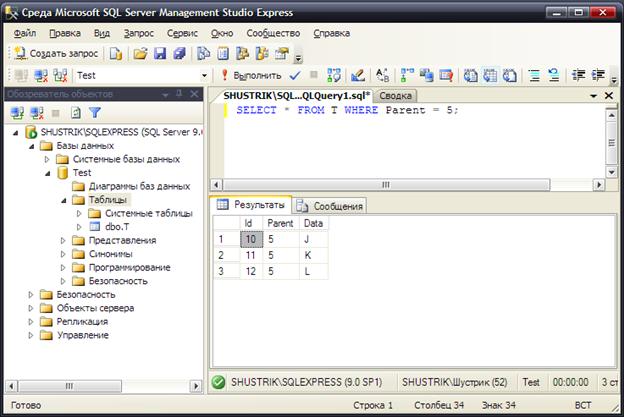
Рис. 17. Список узлов, являющихся непосредственными потомками узла E
Объединив эти два предложения SQL, получаем (рис. 18)
SELECT * FROM T WHERE
Parent=(SELECT Id FROM T WHERE Data='E');

Рис. 18. Выбираем всех потомков узла E единым SQL-предложением
Аналогично определяется непосредственный предок заданного узла, например узла E:
SELECT * FROM T WHERE
Id=(SELECT Parent FROM T WHERE Data='E');
Результат выполнения такого запроса представлен на рис. 19.
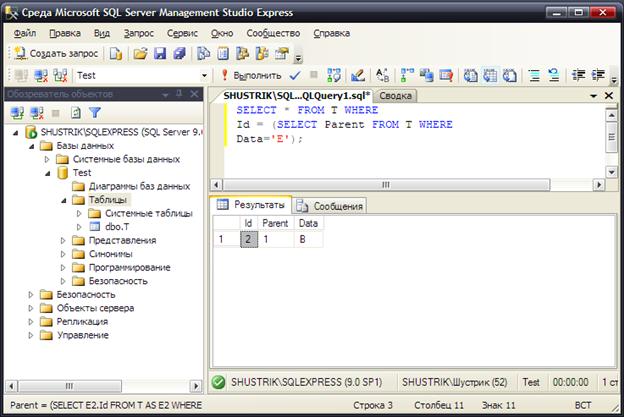
Рис. 19. Непосредственный предок узла E
Для того чтобы вывести два уровня в дереве (все пары непосредственный предок – непосредственный потомок), необходимо написать более сложный запрос (рис. 20):
SELECT T1.Data, T2.Data
FROM T AS T1, T AS T2, T AS T3
WHERE T1.Id=T2.Parent AND T3.Id=T2.Parent;
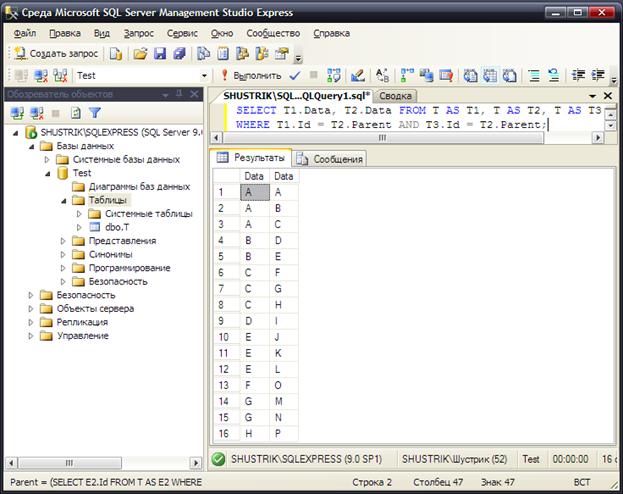
Рис. 20. Получаем два уровня иерархии (набор всех пар – непосредственный предок – непосредственный потомок)
Для того чтобы выбрать значения более чем на два уровня глубже в иерархии, просто расширяем предыдущий запрос (рис. 21):
SELECT DISTINCT T1.Data, T2.Data, T3.Data
FROM T AS T1, T AS T2, T AS T3, T AS T4
WHERE T1.Id=T2.Parent AND
T2.Id=T3.Parent AND
T3.Id=T4.Parent;
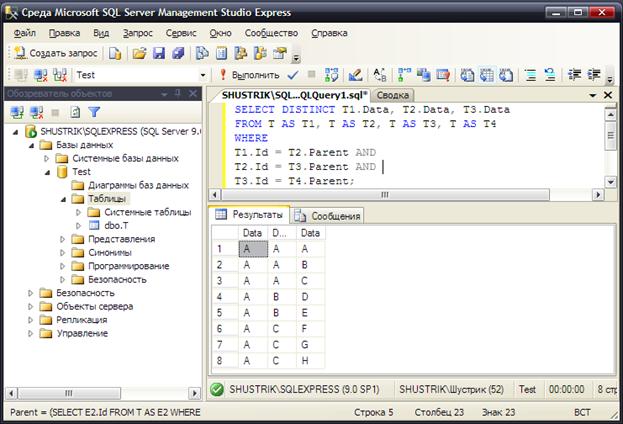
Рис. 21. Три уровня иерархии
К сожалению, в общем случае неизвестно, насколько глубоко дерево, так что для нахождения полного пути в дереве нужно расширять этот запрос, пока не получится в результате пустое множество.
Для выполнения выборок потомков некоторого заданного узла или его предков используются рекурсивные запросы.
Выборка поддерева по заданному узлу средствами MS SQL Server будет иметь следующий вид:
WITH SubTree ([Id], [Parent], [Data], [Level]) AS
(
-- Задаем начальное значение для счетчика уровней 1
SELECT [Id], [Parent], [Data], 1 FROM T
-- Задаем корень искомого поддерева (Parent=1)
WHERE [Parent]=1
UNION ALL
-- Выполняем рекурсивную выборку с
-- наращиванием счетчика уровней
SELECT T.[Id], T.[Parent], T.[Data], [Level]+1
FROM T
INNER JOIN SubTree ON T.[Parent]=SubTree.[Id]
-- исключаем корень
WHERE SubTree.[Parent]<>SubTree.[Id]
)
SELECT [Id], [Parent], [Data], [Level] FROM SubTree;
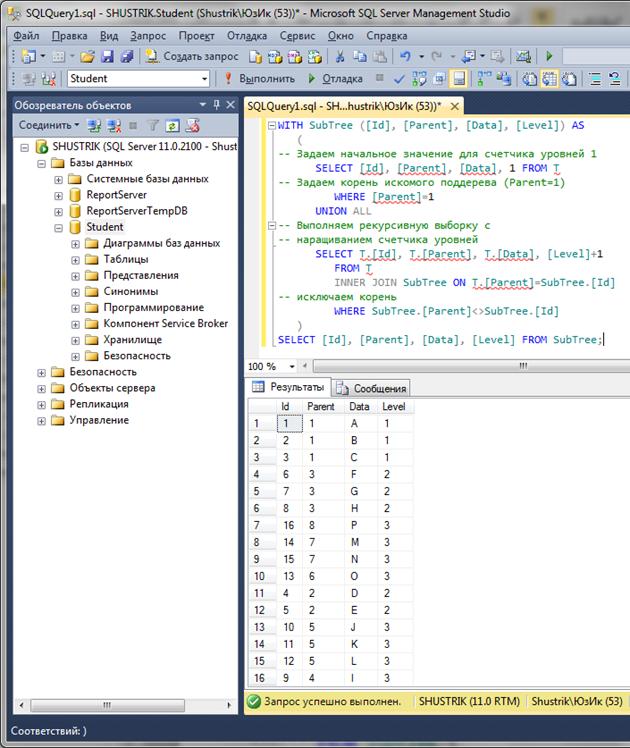
Выборка всех предков для заданного узла (путь к узлу от корня) выполняется аналогично:
WITH SubTree ([Id], [Parent], [Data], [Level]) AS
(
SELECT [Id], [Parent], [Data], 1 FROM T
WHERE [Id]=4 -- Уникальный идентификатор узла
UNION ALL
SELECT T.[Id], T.[Parent], T.[Data], Level+1 FROM T
INNER JOIN SubTree ON T.[Id]=SubTree.[Parent] AND
SubTree.[Parent]<>SubTree.[Id]
)
SELECT [Id], [Parent], [Data],
(SELECT MAX(Level) FROM SubTree) AS [Level]
FROM SubTree;

Проверка на вхождение узла в поддерево, определяемое заданным корневым элементом, может быть выполнена следующим запросом:
WITH SubTree([Id], [Parent], [Data], [Level]) AS
(
SELECT [Id], [Parent], [Data], 1 FROM T
WHERE [Id]=6 -- проверяемый узел
-- попробуйте изменять это значение
UNION ALL
SELECT T.[Id], T.[Parent], T.[Data], [Level]+1 FROM T
INNER JOIN SubTree ON T.[Id]=SubTree.[Parent] AND
SubTree.[Parent]<>SubTree.[Id]
)
SELECT result=
CASE WHEN EXISTS
(
SELECT 1 FROM SubTree
WHERE [Id]=3 -- корень поддерева
-- попробуйте изменять это значение
)
THEN 'Узел входит в поддерево'
ELSE 'Узел НЕ входит в поддерево'
END;
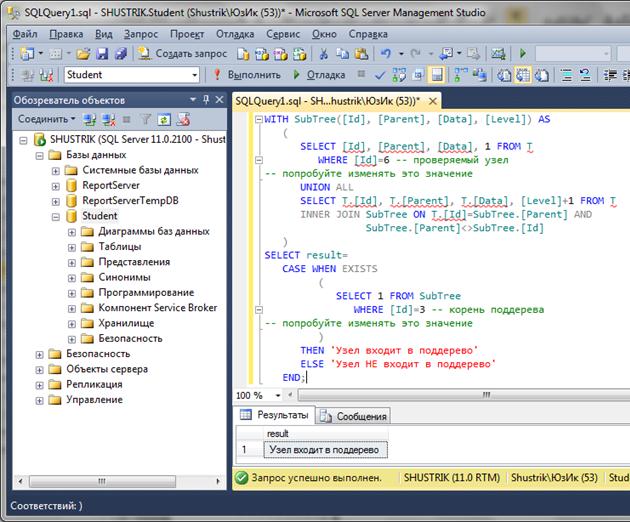
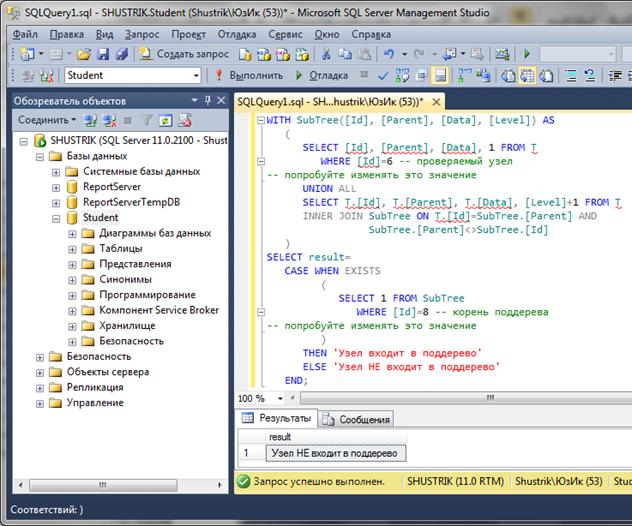
Если СУБД не умеет выполнять такие запросы, то для получения аналогичного результата придется использовать другие механизмы, например, временные таблицы и хранимые процедуры и функции.
Сначала рассмотрим более простую задачу – поиск всех предков для некоторого, наперёд заданного узла. Для этого по заданному идентификатору узла выбираем идентификатор его непосредственного предка, по идентификатору предка – предка предка и т. д., пока не достигнем корня, который в нашем случае определяется как узел, указывающий как на предка на самого себя. Приведём пример создания такой функции.
CREATE FUNCTION GetParents
(@NodeName AS varchar(1))
RETURNS @tree table
(
Name VARCHAR(1) NOT NULL,
Level int NOT NULL
)
AS
BEGIN
DECLARE @ID int;
DECLARE @Parent int;
DECLARE @Level int;
-- ВНИМАНИЕ!
-- После каждой операции необходима
-- проверка наличия ошибок,
-- отсутствующая в данном примере!
-- По имени узла получаем его идентификатор и
-- идентификатор его непосредственного предка.
-- Если б не требовалась организация цикла,
-- можно было бы обойтись только идентификатором предка.
SELECT @ID=ID, @Parent=Parent
FROM T
Where Data=@NodeName;
-- Для самого узла указываем нулевое расстояние до предка
SET @Level=0;
-- Добавляем запись в возвращаемую таблицу
INSERT INTO @tree (Name, Level) VALUES (@NodeName, @Level);
-- Пока не доберёмся до корневого элемента иерархии...
WHILE (@ID <> @Parent)
BEGIN
SELECT @ID=ID, @Parent=Parent, @NodeName=Data
FROM T
WHERE ID=@Parent;
-- Наращиваем расстояние до предка
SET @Level=@Level+1;
-- Добавляем запись в возвращаемую таблицу
INSERT INTO @tree (Name, Level) VALUES
(@NodeName, @Level);
END
RETURN
END
При помощи этой функции получим всех предков, например, узла O:
select * from GetParents('O') ORDER BY Level DESC;
Результат выполнения этого запроса представлен на рис. 22.
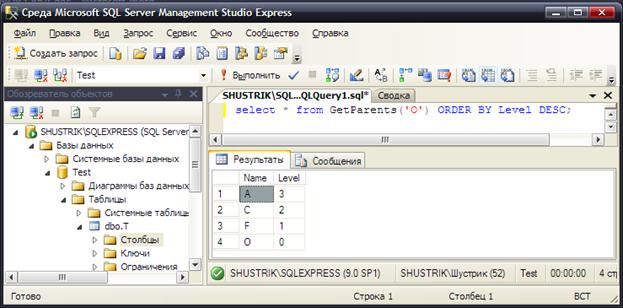
Рис. 22. Использование функции нахождения всех предков некоторого узла для узла O
Теперь при помощи функции GetParents можно решить задачу о нахождении ближайшего общего предка для двух узлов. Пусть заданы узлы I и K. Их общий ближайший предок – узел B (см. рис. 8).
С помощью запросов
select [name] from GetParents('I');
и
select [name] from GetParents('K');
получим списки всех предков этих узлов (рис. 23).
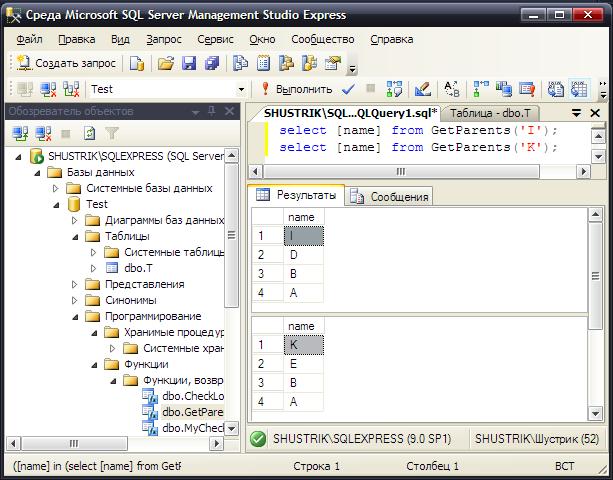
Рис. 23 Все предки узлов I и K
Запрос
select * from GetParents('I') where
([name] in (select [name] from GetParents('K')));
даст список всех общих предков для узлов I и K (рис. 24).
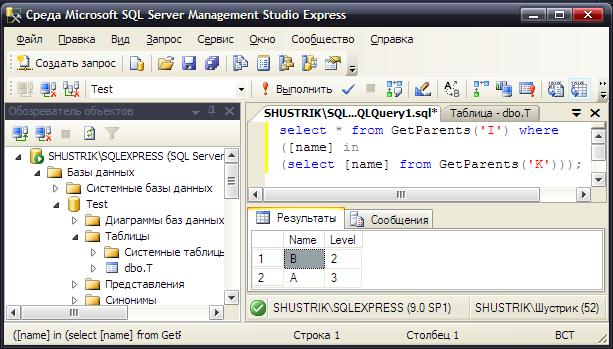
Рис. 24. Список всех общих предков для узлов I и K
Из этого списка надо выбрать элемент с минимальным значением поля Level (рис. 25).
select MIN([level]) from GetParents('I') where
[name] in (select [name] from GetParents('K'));
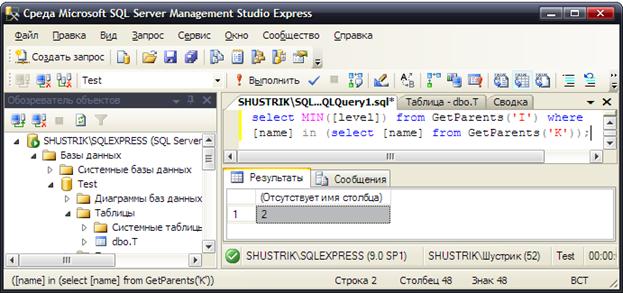
Рис. 25. Получаем элемент с минимальным значением в поле Level
Окончательно получаем ближайшего общего предка для узлов I и K при помощи следующего предложения SQL (рис. 26):
select [name] from GetParents('I') where
([name] in (select [name] from GetParents('K'))
And ([level]=((
select MIN([level]) from GetParents('I') where
[name] in (select [name] from GetParents('K'))))));
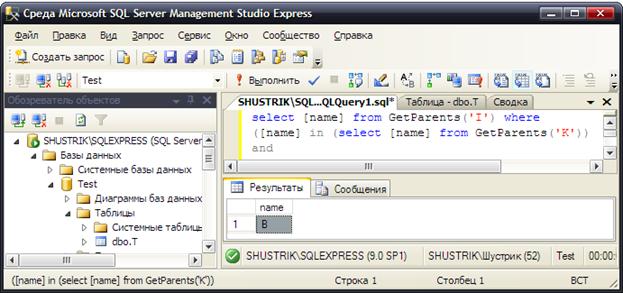
Рис. 26. Получаем ближайшего общего предка для узлов I и K

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
