
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
-- на существование родительского узла!
-- Добавляем строку с новым листом
-- во вспомогательную таблицу
INSERT INTO T_Helper(UID, ParentID, [Level])
VALUES (@NewID, @ParentID, 1);
-- Добавляем во вспомогательную таблицу строки
-- указывающие предков предка
INSERT INTO T_Helper(UID, ParentID, [Level])
SELECT @NewID, ParentID, [Level]+1
FROM T_Helper
WHERE UID=@ParentID AND
-- условие [Level]>0 нужно для отсечения
-- вставки дублей записей
-- указывающих на корень дерева
-- (иначе получаем сообщение об ошибке)
[Level]>0;
-- ВНИМАНИЕ! Тут должна быть проверка результатов и,
-- если были ошибки, откат транзакции!
COMMIT TRANSACTION AddNodeTransaction;
END;
Создадим эту хранимую процедуру (рис. 81)
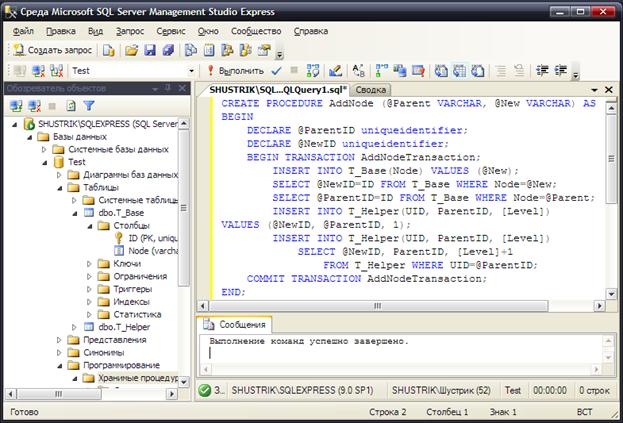
Рис. 81. Создание хранимой процедуры
При помощи этой процедуры добавим в нашу иерархию новый узел Z – потомок узла P:
EXEC AddNode 'P', 'Z';
Проверим правильность добавления узла Z, выбрав всех его предков:
SELECT T_Base. Node, T_Helper. Level
FROM T_Base, T_Helper
WHERE T_Base. ID=T_Helper. ParentID and
T_Helper. UID=(
SELECT ID FROM T_Base WHERE Node='Z')
ORDER BY T_Helper. Level DESC;
В результате должен быть получен следующий набор узлов: A–C–H–P (рис. 82).
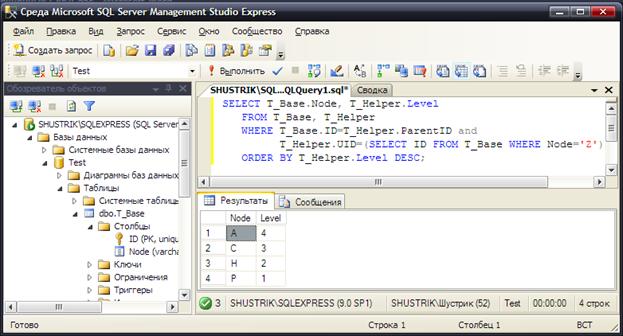
Рис. 82. Проверка правильности добавления узла Z
Эта хранимая процедура, добавляющая узлы, требует наличия уже существующей записи для корневого узла. Для добавления корневого узла создадим специальную хранимую процедуру:
CREATE PROCEDURE AddRootNode (@NewRoot VARCHAR) AS
-- Добавляем корневой элемент иерархии
-- ВНИМАНИЕ! Тут должна быть проверка
-- входного параметра!
-- После каждой операции необходима проверка ошибок,
-- отсутствующая в данном примере!
BEGIN
DECLARE @RootID uniqueidentifier;
-- Транзакция
BEGIN TRANSACTION AddNodeTransaction;
-- Добавляем строку нового узла в базовую таблицу
INSERT INTO T_Base(Node) VALUES (@NewRoot);
-- Получаем уникальный идентификатор нового элемента
SELECT @RootID=ID FROM T_Base WHERE Node=@NewRoot;
-- Добавляем строку корневого элемента во вспомогательную таблицу
INSERT INTO T_Helper(UID, ParentID, [Level])
VALUES (@RootID, @RootID, 0);
-- ВНИМАНИЕ! Тут должна быть проверка результатов и,
-- если были ошибки, откат транзакции!
COMMIT TRANSACTION AddNodeTransaction;
END;
Теперь первичное заполнение структуры данных можно реализовать следующей последовательностью вызовов хранимых процедур:
EXEC AddRootNode 'A';
EXEC AddNode 'A', 'B';
EXEC AddNode 'A', 'C';
EXEC AddNode 'B', 'D';
EXEC AddNode 'B', 'E';
EXEC AddNode 'D', 'I';
EXEC AddNode 'E', 'J';
EXEC AddNode 'E', 'K';
EXEC AddNode 'E', 'L';
EXEC AddNode 'C', 'F';
EXEC AddNode 'C', 'G';
EXEC AddNode 'C', 'H';
EXEC AddNode 'F', 'O';
EXEC AddNode 'G', 'M';
EXEC AddNode 'G', 'N';
EXEC AddNode 'H', 'P';
Удаление одиночных узлов и поддеревьев может быть выполнено при помощи триггера. Триггер назначается таблице T_Base на операцию удаления записей. Будем полагать, что при удалении узла удаляются и все его потомки.
CREATE TRIGGER DeleteNode
ON T_Base
INSTEAD OF DELETE
AS
-- Добавляем узлы дерева
-- ВНИМАНИЕ! После каждой операции необходима
-- проверка наличия ошибок, отсутствующая
-- в данном примере!
DECLARE @ID uniqueidentifier;
-- Определяем уровень вложенности триггера
-- (используются средства MS SQL Server)
-- Выполняем только для внешнего удаления
-- (операция DELETE запрошена вне триггера)
IF TRIGGER_NESTLEVEL(OBJECT_ID('DeleteNode'))=1
BEGIN
-- Внимание! В реальном триггере нужно учесть,
-- что может быть удалено несколько строк
-- Получаем уникальный идентификатор
-- удаляемого элемента
SELECT @ID=ID FROM deleted;
-- Собираем список удаляемых узлов
-- во временной таблице #TempTBL
-- Удаляем временную таблицу
-- (на всякий случай, вдруг она существует)
DROP TABLE #TempTBL;
SELECT DISTINCT UID INTO #TempTBL FROM T_Helper
WHERE ParentID=@ID
-- Удаляем всех потомков удаляемого узла из
-- вспомогательной таблицы
DELETE FROM T_Helper WHERE UID IN (
SELECT * FROM #TempTBL);
-- Удаляем все записи вспомогательной таблицы для
-- удаляемого узла
DELETE FROM T_Helper WHERE UID=@ID;
-- Удаляем всех потомков из основной таблицы
-- Эта операция приводит к рекурсивному запуску
-- данного триггера
DELETE FROM T_Base WHERE ID IN (
SELECT * FROM #TempTBL);
-- Удаляем все записи основной таблицы
-- для удаляемого узла
-- Эта операция приводит к рекурсивному запуску
-- данного триггера
DELETE FROM T_Base WHERE ID=@ID;
END
ELSE
-- Случай рекурсивного вызова триггера
-- (триггер запущен операцией DELETE
-- выполненной в триггере)
BEGIN
-- Удаляем всех потомков из основной таблицы
DELETE FROM T_Base WHERE ID IN (
SELECT * FROM #TempTBL);
-- Удаляем все записи основной таблицы
-- для удаляемого узла
DELETE FROM T_Base WHERE ID=@ID;
END
Обратите внимание. При создании триггера используется параметр INSTEAD OF для того, чтобы триггер полностью заменял собой команду DELETE, приводящую к его запуску. Это нужно потому, что базовая и вспомогательная таблицы связаны между собой и удаление записей из базовой таблицы невозможно, если существуют основанные на них записи во вспомогательной таблице!
Удалим добавленный в предыдущем примере узел Z (рис. 83):
DELETE FROM T_Base WHERE Node='Z';
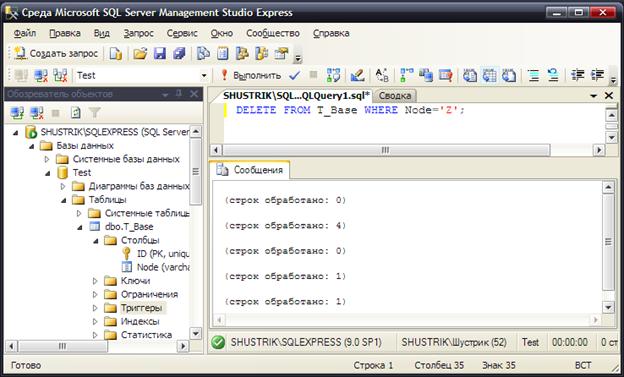
Рис. 83. Удаление узла Z
Теперь попробуем удалить узел C и всё поддерево, для которого этот узел является корнем (рис. 84):
DELETE FROM T_Base WHERE Node='C';
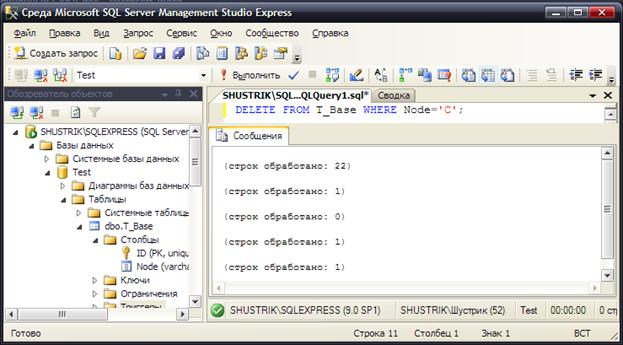
Рис. 84. Удаление поддерева
Проверим результат выполнения операции удаления, выбрав все узлы дерева, начиная с корня:
SELECT T_Base.Node, T_Helper.[Level]
FROM T_Base, T_Helper
WHERE T_Base. ID=T_Helper. UID and
T_Helper. ParentID=(
SELECT ID FROM T_Base WHERE Node='A')
ORDER BY T_Helper.[Level] ASC, T_Base. Node;
Результат не должен содержать узлов C F G H O M N P (рис. 85-86).

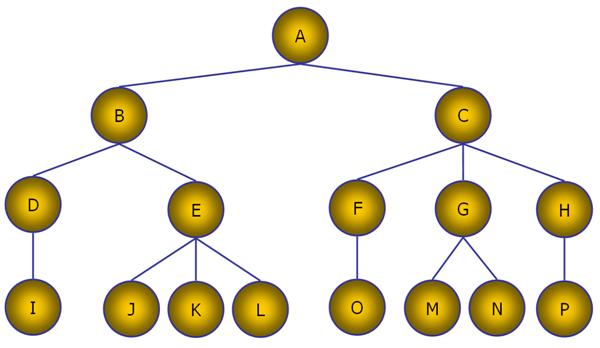
Рис. 85. Удаление узлов C F G H O M N P
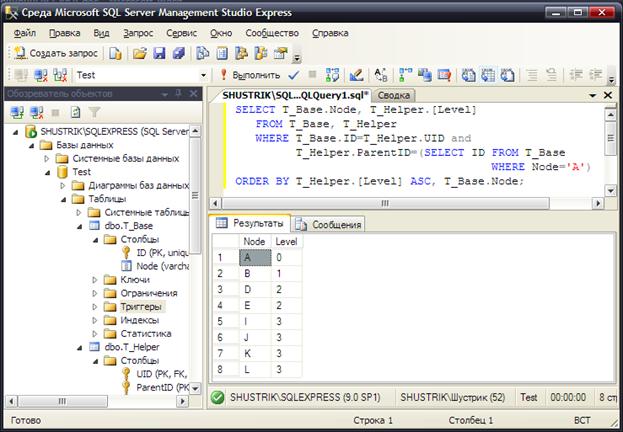
Рис. 86. Иерархия после удаления поддерева с корневым узлом C
Контроль отсутствия петель в дереве может осуществляться проверкой записей во вспомогательной таблице – в ней не должно быть записей, в которых узел является сам себе предком с ненулевым расстоянием (рис. 87).
SELECT T_Base. Node, T_Helper.[Level]
FROM T_Base, T_Helper
WHERE T_Base. ID=T_Helper. UID AND
T_Helper. ParentID=T_Helper. UID AND
-- Исключаем корневые узлы
T_Helper.[Level]>0
ORDER BY T_Base. Node;
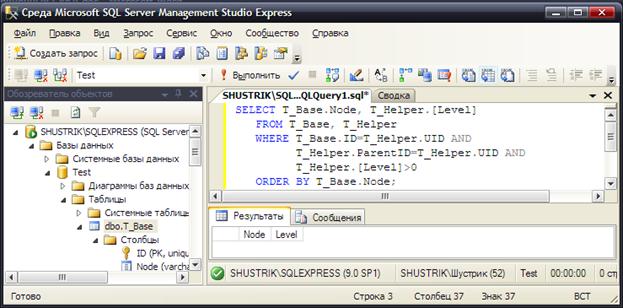
Рис. 87. Проверка на наличие/отсутствие петель
Тем не менее, возможность образования петель сохраняется, но на операциях выборки не может образоваться бесконечный цикл.
Данный способ, на сегодняшний день, считается наиболее универсальным для представления иерархий средствами реляционной СУБД. Однако он наследует такой недостаток способа со структурой со ссылкой на предка, как возможность образования петель. Трудности может вызвать поддержка целостности для полных путей от корня дерева до указанного узла. Кроме того, этот способ отличается некоторой избыточностью хранимых данных.
Задачи
Создайте таблицу, описывающую абстрактную иерархию со структурой со вспомогательной таблицей. Заполните её данными. На основе этой таблицы сформируйте и выполните SQL-предложения, решающие следующие задачи:
1. Определить корневой элемент иерархии.
2. Определить непосредственного предка некоторого заданного элемента.
3. Определить, что заданный элемент иерархии не имеет потомков.
4. Выбрать все элементы иерархии, не имеющие потомков (листья).
5. Выбрать всех потомков заданного элемента (выбрать поддерево, начиная с заданного узла).
6. Выбрать всех предков для заданного узла.
7. Определить расстояние от корня до заданного узла.
8. Определить уровень в иерархии заданного узла относительно другого узла, не являющегося предком данного.
9. Выбрать всех непосредственных потомков для некоторого заданного элемента.
10. Найти ближайшего общего предка для заданных узлов.
11. Удалить заданный узел. Учесть возможность существования потомков у удаляемого узла.
12. Добавить в иерархию новый элемент как потомка заданного узла. Написать триггер, добавляющий во вспомогательную таблицу строки для указания предков, не являющихся для добавляемого узла непосредственными.
13. Написать хранимую процедуру, проверяющую структуру на отсутствие петель.
14. Проверить все узлы иерархии на наличие нескольких предков.
Попробуйте решить предложенные задачи при условии, что в таблицах хранится несколько несвязанных иерархий.
3. Два важных частных случая
В общем случае дерево может иметь любое количество уровней, а узел – любое количество потомков. В практических задачах число уровней и/или количество потомков может быть ограничено. Для этих случаев существуют специальные варианты моделирования иерархий средствами реляционных СУБД, которые мы здесь кратко рассмотрим.
3.1. Случай ограниченного количества уровней иерархии
Пусть иерархия не может иметь более n уровней, а каждый узел может иметь любое количество потомков. Тогда её можно представить в виде следующей таблицы:
Таблица 9
Модель иерархии с ограниченным количеством предков
Идентификатор узла | Предок 1 | … | Предок n-1 | Содержательная часть |
Для нашего примера абстрактной иерархии (рис. 8), состоящей из 4 уровней, если полагать количество уровней в ней фиксированным, заполненная таблица будет выглядеть следующим образом:
Таблица 10
Заполненная таблица модели иерархии с ограничением по числу предков
Уникальный идентификатор узла | Предки | Содержательная часть | ||
1 | 2 | 3 | ||
A | NULL | NULL | NULL | A |
B | A | NULL | NULL | B |
C | A | NULL | NULL | C |
D | A | B | NULL | D |
E | A | B | NULL | E |
F | A | C | NULL | F |
G | A | C | NULL | G |
H | A | C | NULL | H |
I | A | B | D | I |
J | A | B | E | J |
K | A | B | E | K |
L | A | B | E | L |
O | A | C | F | O |
M | A | C | G | M |
N | A | C | G | N |
P | A | C | H | P |
Как в случае вспомогательной таблицы, в этом способе в таблице хранятся все полные пути от корня до каждого из узлов иерархии. В отличие от способа вспомогательной таблицы, для каждого полного пути от корня до узла используется только одна строка таблицы. Поэтому соответствующие выборки данных будут выполняться быстрее.
При работе с данной структурой данных некоторую сложность может составить определение уровня конкретного узла в иерархии. Уровень можно определить как количество столбцов идентификаторов предков, имеющих в строке данного узла неопределённое значение.
Трудности возникают при неожиданном увеличении количества уровней в иерархии. В такой ситуации может потребоваться не только добавление в таблицу новых столбцов, но и переработка прикладного ПО.
Иногда, в зависимости от сложности иерархии, в столбцах, где хранятся идентификаторы предков элементов, может быть большое количество неопределённых значений (говорят, что таблица получается «рыхлой»). В этом случае можно использовать вариант данного подхода, где для каждого уровня иерархии создаётся отдельная таблица.
Вот как в этом случае может быть представлена наша абстрактная иерархия из четырёх уровней (табл.
Таблица 11
Таблица, описывающая первый уровень (корень дерева)
Уникальный идентификатор узла | Содержательная часть | |
A | A |
|
Таблица 12
Таблица второго уровня
Уникальный идентификатор узла | Предки | Содержательная часть |
1 | ||
B | A | B |
C | A | C |
Таблица 13
Таблица третьего уровня
Уникальный идентификатор узла | Предки | Содержательная часть | |
1 | 2 | ||
D | A | B | D |
E | A | B | E |
F | A | C | F |
G | A | C | G |
H | A | C | H |
Таблица 14

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
