

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
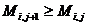 ,
, 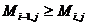
![]() .
.
Для элементов главной диагонали и выше неё утверждение очевидно: они все равны 1. Элементы под главной диагональю вычисляются по формуле 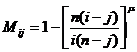 . Докажем, что они возрастают по строке (возрастание по столбцу доказывается аналогично). Примем n и i как постоянные, переменную j назовем х, и рассмотрим элементы строки как функция от х.
. Докажем, что они возрастают по строке (возрастание по столбцу доказывается аналогично). Примем n и i как постоянные, переменную j назовем х, и рассмотрим элементы строки как функция от х.
![]() ,
, ![]() .
.
Вычислим производную этой функции:
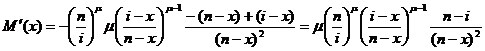 .
.
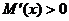 , поскольку
, поскольку 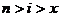 , следовательно,
, следовательно, ![]() – возрастающая функция, т. е. элементы матрицы возрастают.
– возрастающая функция, т. е. элементы матрицы возрастают.
ВЫПУКЛЫЕ КРИВЫЕ КАК ПРЕДЕЛ СЛУЧАЙНЫХ ЛОМАНЫХ
, Ф.
Международный институт теории прогноза землетрясений
и математической геофизики РАН
Работа посвящена проблеме аппроксимации гладких выпуклых кривых с помощью целочисленных выпуклых ломаных, которая в известном смысле является обратной по отношению к проблеме предельной формы (см. [1]).
Пусть g – ограниченная неубывающая выпуклая функция, заданная на некотором отрезке [0,а], причем g(0)=0. Предположим, что функция g непрерывна на [0, а], а ее производная g'(u) непрерывна всюду, кроме, быть может, конечного числа точек. Производная g'(a) может быть бесконечной, g'(a)≤ ∞. Обозначим через ![]() график функции g, и пусть
график функции g, и пусть ![]() – множество всех таких кривых. Очевидно, множество L выпуклых ломаных содержится в
– множество всех таких кривых. Очевидно, множество L выпуклых ломаных содержится в ![]() . Заметим, что в силу наших предположений всякая кривая γ
. Заметим, что в силу наших предположений всякая кривая γ ![]()
![]() спрямляема. Наконец, определим функцию
спрямляема. Наконец, определим функцию ![]()
![]()
![]()
![]()
![]() , полагая
, полагая
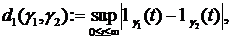
![]()
![]() . (1)
. (1)
Можно показать, что функция ![]() (·,·) задает метрику, эквивалентную обычной метрике Хаусдорфа d(·,·) на множестве компактов в
(·,·) задает метрику, эквивалентную обычной метрике Хаусдорфа d(·,·) на множестве компактов в ![]() :
:
![]()
Общая проблема аппроксимации выпуклых кривых с помощью выпуклых ломаных теперь может быть поставлена следующим образом.
Пусть дана выпуклая кривая γ![]()
![]() , задаваемая функцией
, задаваемая функцией ![]() (u), 0 ≤ u ≤ 1. Будем называть ломаную Г
(u), 0 ≤ u ≤ 1. Будем называть ломаную Г![]() “ε – аппроксимирующей” для γ, если при масштабном преобразовании относительно начала координат с коэффициентом
“ε – аппроксимирующей” для γ, если при масштабном преобразовании относительно начала координат с коэффициентом ![]() ломаная Г попадает в ε-окрестность кривой γ в метрике
ломаная Г попадает в ε-окрестность кривой γ в метрике ![]() , т. е.
, т. е. ![]() ,
,
где ![]() - множество ломаных
- множество ломаных ![]() с правым концом в точке
с правым концом в точке ![]() .
.
Основной результат работы состоит в том, что для данной С3-гладкой строго выпуклой кривой γ![]()
![]() , на множестве выпуклых ломаных можно построить распределение вероятностей
, на множестве выпуклых ломаных можно построить распределение вероятностей ![]() так, что для любого ε>0 подавляющее большинство ломаных
так, что для любого ε>0 подавляющее большинство ломаных 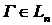 (по мере
(по мере ![]() ) окажутся ε-аппроксимирующими для γ. Иными словами, по отношению к распределению
) окажутся ε-аппроксимирующими для γ. Иными словами, по отношению к распределению ![]() предельная форма ломаных будет задаваться исходной кривой γ.
предельная форма ломаных будет задаваться исходной кривой γ.
Опишем конструкцию меры ![]() . По аналогии с [1,2], введем на множестве
. По аналогии с [1,2], введем на множестве ![]() (пространство финитных функций) вероятностную меру
(пространство финитных функций) вероятностную меру ![]() , полагая
, полагая
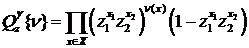 ,
, 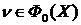 , ( 2 )
, ( 2 )
где , – параметры (параметрические функции), такие что 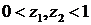 . Подчеркнем, что параметры
. Подчеркнем, что параметры ![]() , вообще говоря, зависят от
, вообще говоря, зависят от![]() . Тогда
. Тогда ![]() определяется как условное распределение, порожденное условием
определяется как условное распределение, порожденное условием 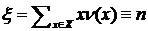 (см. работу [1]).
(см. работу [1]).
Подчиним выбор функций , естественному асимптотическому условию
![]() ,
, ![]() , (3)
, (3)
где ![]() – длина той части ломаной Г, где наклон звеньев не превосходит t, а
– длина той части ломаной Г, где наклон звеньев не превосходит t, а ![]() – математическое ожидание относительно
– математическое ожидание относительно ![]() . Обозначим
. Обозначим ![]()
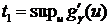 . Положим также
. Положим также ![]() ,
, ![]() ,
, ![]() и
и ![]() . Для
. Для ![]() обозначим
обозначим ![]() . Записывая
. Записывая ![]() в виде
в виде
![]() ,
, ![]() , (4)
, (4)
можно показать, что следующий выбор функций ![]() обеспечивает выполнение условия (3):
обеспечивает выполнение условия (3): ![]() , если
, если ![]() или
или ![]() , а при
, а при ![]() :
:
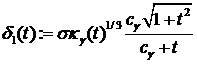 ,
, 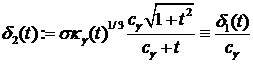 , (5)
, (5)
где ![]() – дзета-функция Римана.
– дзета-функция Римана.
Следующая теорема устанавливает функциональный закон больших чисел по отношению к распределению ![]() на
на ![]() , причем роль предела играет заданная выпуклая кривая γ.
, причем роль предела играет заданная выпуклая кривая γ.
Теорема 1. Предположим, что кривая γ является ![]() -гладкой и ее кривизна равномерно ограничена снизу положительной константой. Пусть
-гладкой и ее кривизна равномерно ограничена снизу положительной константой. Пусть ![]() таким образом, что. Если параметрические функции
таким образом, что. Если параметрические функции ![]() ,
,![]() выбраны в соответствии с формулами (3), (4), то для любого ε>0
выбраны в соответствии с формулами (3), (4), то для любого ε>0
![]() .
.
В заключение сформулируем локальную предельную теорему для асимптотической оценки при 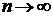 вероятности
вероятности 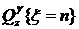 . Этот результат играет фундаментальную роль при переходе от безусловного распределения
. Этот результат играет фундаментальную роль при переходе от безусловного распределения ![]() к условному распределению
к условному распределению ![]() (в работе [1] – от
(в работе [1] – от ![]() к
к ![]() соответственно). Поскольку случайные величины
соответственно). Поскольку случайные величины ![]() определены равенствами:
определены равенствами:
![]() ,
, ![]() , (6)
, (6)
то мы имеем здесь дело с двумерной локальной теоремой для независимых неодинаково распределенных слагаемых. При этом схема суммирования в нашем случае отличается от классической, поскольку число слагаемых заранее не фиксируется, а сами слагаемые и порядок их суммирования определяются в результате сравнения значений вспомогательного случайного поля ![]() .
.
Обозначим ![]() , и пусть
, и пусть ![]() – симметричная положительно определенная матрица, такая что
– симметричная положительно определенная матрица, такая что ![]() (заметим, что
(заметим, что ![]() существует в силу невырожденности
существует в силу невырожденности ![]() ). Обозначим через
). Обозначим через ![]() плотность двумерного нормального распределения с нулевым средним и единичной ковариационной матрицей:
плотность двумерного нормального распределения с нулевым средним и единичной ковариационной матрицей:
![]() , (7)
, (7)
и пусть ![]() – плотность нормального распределения с математическим ожиданием
– плотность нормального распределения с математическим ожиданием ![]() и ковариационной матрицей
и ковариационной матрицей ![]() :
:
![]()
Теорема 2. Положим ![]() , где – вектор с неотрицательными целыми компонентами. Тогда равномерно по т
, где – вектор с неотрицательными целыми компонентами. Тогда равномерно по т
![]()
![]()
Для эффективного использования этой теоремы при переходе от ![]() к условному распределению
к условному распределению ![]() необходима оценка абсолютной погрешности
необходима оценка абсолютной погрешности 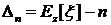 . Поскольку параметры
. Поскольку параметры ![]() подбираются из условия малости относительной погрешности, то
подбираются из условия малости относительной погрешности, то 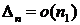 . Этого, однако, недостаточно для наших целей, поскольку корень из дисперсии (точнее, норма матрицы
. Этого, однако, недостаточно для наших целей, поскольку корень из дисперсии (точнее, норма матрицы ![]() ) имеет порядок
) имеет порядок ![]() . Следующая теорема играет ключевую роль:
. Следующая теорема играет ключевую роль:
Теорема 3. При
![]() . (8)
. (8)
Доказательство этой теоремы является довольно сложным в аналитическом плане и требует привлечения ряда тонких методов, включая выбор оптимального контура интегрирования в формуле обращения преобразования Меллина и использование некоторых известных оценок поведения дзета-функции в критической полосе (в частности, теоремы Вале-Пуссена). Здесь технические трудности возрастают из-за зависимости параметров ![]() от
от ![]() . Однако удается получить более слабую оценку
. Однако удается получить более слабую оценку
![]()
(ср.[1]), которой тем не менее достаточно для доказательства теоремы о предельной форме (Теорема 1).
ЛИТЕРАТУРА
Bogachev L. V., Zarbaliev S. M. Approximation of convex curves by random lattice polygons. Preprint NI04003, Isaac Newton Institute for Mathematical Sciences. Cambridge. –P.33, 2004.http://www. newton. cam. ac. uk/preprints/NI04003.pdf
Sinai Ya. G. Probabilistic approach to the analysis of statistics for convex polygonal lines. Funct. Anal. Appl. –V. 28. –PP.108-113, 1994.Академия народного хозяйства при правительстве Р. Ф., г. Москва
В наших совместных работах с были изучены прочностные характеристики одного класса полимеров, что привело к необходимости решения уравнения:
![]() . (1)
. (1)
Было установлено, что участок эластичности деформационной кривой аппроксимируется интегральной кривой уравнения (1).
В данной работе проанализировано уравнение (1) и его решения. Подействуем на обе части уравнения (1) оператором ![]() . Здесь, как и раньше,
. Здесь, как и раньше, ![]() – оператор дробного интегрирования в смысле Римана-Лиувилля порядка 1/3 , т. е.
– оператор дробного интегрирования в смысле Римана-Лиувилля порядка 1/3 , т. е.
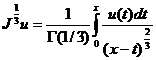 .
.
Тогда получим
![]() . (2)
. (2)
Так как
![]() ,
,
![]() ,
,
то (2) можно переписать в виде:
![]() .
.
Уравнение (2) переходит в уравнение:
![]() , (3)
, (3)
так как, мы в нашей модели предполагаем, что видоизмененная задача Коши для уравнения (1) поставлена с нулевыми начальными условиями.
Самым важным моментом в построенных моделях, в частности, в уравнении (3)
является то, что оператор ![]() является диссипативным. Справедливо также и более сильное утверждение: оператор
является диссипативным. Справедливо также и более сильное утверждение: оператор ![]() является секториальным.
является секториальным.
ПРАВДОПОДОБНЫЕ РАСПРЕДЕЛЕНИЯ ВЕРОЯТНОСТЕЙ ДЛЯ
НЕПАРАМЕТРИЧЕСКИХ ЗАДАЧ ВЫБОРА ГИПОТЕЗ О СЛУЧАЙНЫХ
ВЕЛИЧИНАХ НА ОГРАНИЧЕННЫХ СЕГМЕНТАХ
Столичный бизнес колледж, г. Москва.
Задача ставится следующим образом. По данной выборке независимых реализаций случайной величины x, о которой извеcтно, что ее значения сосредоточены на некотором известном сегменте, определить правило решения о выборе одной их двух сложных гипотез Mx£q1, против Mx³q2.
А также получить оценки вероятностей ошибок первого и второго рода соответственно и принять решение о том, что верна гипотеза 1 при условии, что верна гипотеза 2, и принять решение о том, что верна гипотеза 2 при условии, что верна гипотеза 1.
Вышеуказанные проблемы возникают в задачах о приемке или браковке изделий, когда контроль каждого не является полным, о пределах значений средней эффективности некоторого устройства по его случайным реализациям, об освоении месторождения некоторого ископаемого по имеющимся пробам его концентрации в породе, также об эффективности подготовки специалиста по результатам тестирования.
Если мы будем придерживаться принципа Лапласа, в котором полагается, что события равновероятны, если нет никаких сведений о характере распределений на множестве событий, то для данной последовательности независимых реализаций случайной величины x1,…,xn наиболее правдоподобной из множества распределений таких, что Mx£q1, будет распределение:
![]() ,
, ![]() если
если ![]()
![]() q1
q1
P(![]() )={q1
)={q1![]() ,
, ![]() если
если 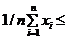 q2
q2
1-q1/(1/n![]() ), y=0. (1)
), y=0. (1)
Из множества распределений таких, что Mx³q2 , будет распределение:
1/n, y = xi, i =1,…,n; если 1/n S xi>q2.
P(x2=y/x)={ (1-q2)/(n-![]() xi), y = xi,i=1,…,n; если 1/n
xi), y = xi,i=1,…,n; если 1/n ![]() xi£q2
xi£q2
1-(1-q2)/(n- ![]() xi), y =1. (2)
xi), y =1. (2)
Другими словами, при использовании принципа Лапласа максимально правдоподобным распределением будет такое, что все ненаблюдаемые при данной выборке значения случайной величины для гипотезы 1 сосредоточены в точке 0, а при гипотезе 2 в точке 1.
Таким образом, вероятность реализации выборки x1,…,xn имеет вид:
(1/n)n, если 1/n ![]() xi£q1.
xi£q1.
Pq1(x)=![]() q1 (xi) =q1/(1/n
q1 (xi) =q1/(1/n ![]() xi), если 1/n S xi>q1
xi), если 1/n S xi>q1
(1/n)n , если 1/n S xi³q2.
Pq2(x)= ![]() Pq2 (xi) = (1– q2)/(1–1/n
Pq2 (xi) = (1– q2)/(1–1/n ![]() xi), если 1/n
xi), если 1/n ![]() xi<q1.
xi<q1.
В данном случае можно использовать процедуру выбора из двух простых гипотез: истинно распределение (1) или (2). Известен результат Неймана-Пирсона [4] в задаче о нахождении наилучшей решающей функции j (x) (вероятность принять гипотезу 1 при данной реализации x, которая обеспечивает минимум вероятности ошибки первого рода, если вероятность ошибки второго рода не более заданной величины) достаточно ограничиться детерминированной функцией:
j(x)=1, если f1(x)/f2(x)>k, и j(x)=0, если f1(x)/f2(x) <k. (3)
В данной работе рассматривается апостериорная (условная) вероятность ошибок первого и второго рода при данной выборке x, для которой выбирается коэффициент k, обеспечивающий требуемые характеристики a и b.
Кроме того, для данного коэффициента k возможно нахождение априорно наихудших распределений вышеуказанного вида. Следуя результатам Чебышева и Маркова, касающихся функций, на которых достигаются предельные значения интегралов при фиксированных значениях первых моментов [7], а также учитывая независимость испытаний, получим, что такие априорно наихудшие распределения будут функциями, имеющими не более двух скачков.
Тогда, для некоторых данных k и n априорные ошибки первого и второго рода не будут превышать значения (q1/( q1-k1/n(1-q2)))n.
С помощью соответствующих таблиц возможно априорное и апостериорное определение приемлемых значений a, b, k, n лицом, ответственным за проведение соответствующих испытаний.
Известно, что с помощью последовательных решающих процедур те же вероятности ошибок могут получаться за счет меньшего числа испытаний [8].
Пусть на каждом шаге проверяются неравенства: если P1n/P2n ³В, то принять гипотезу 1. Если P1n/P2n£A, то принять гипотезу 2. Иначе продолжить испытания. Тогда рассмотрения подобные [5] приводят к оценкам вероятностей первого и второго рода a£1/B, b£A.
Помимо постановок задач вида (3) имеет значение также задача о нахождении решающей функции j(х), обеспечивающей значение min max(W*a, V*b), где веса W, V – стоимости ошибок первого и второго рода соответственно.
Для такой задачи рандомизация решений улучшает их среднюю эффективность [1].
В качестве рандомизированной решающей функции в [6] рассматривается j(х)=1/(1+P1(x)/P2(x)) и показана состоятельность такого критерия при n®¥ и оценки ошибок a, b£O(1/n), равномерных на классах функций распределения.
В заключение укажем на возможность использования условия максимального правдоподобия в непараметрическом варианте без привлечения принципа Лапласа (минимальной информации) для получения решающих правил выбора из сложных гипотез о значении математического ожидания случайных величин.
Этому соответствует следующая постановка задачи:
Найти max ![]() ln pi, (4)
ln pi, (4)
![]() pi+p0=1,
pi+p0=1, ![]() xipi=q1, 0£pi£1.
xipi=q1, 0£pi£1.
Применяя теорему Куна-Такера для функции Лагранжа [9], получим условия для максимально правдоподобного распределения вероятностей для данной выборки x1,…,xn при условии, что математическое ожидание для этого распределения соответствует сложной гипотезе 1.
L(p,l)=![]() lnpi - l1(
lnpi - l1(![]() pi +p0-1)-l2(
pi +p0-1)-l2(![]() xipi-q1)-
xipi-q1)-![]() li(pi-1).
li(pi-1).
l=( l1, l2,l1,…,ln). (5)
Тогда, если p* локальный условный экстремум функции, то функция Лагранжа имеет максимум по p и минимум по l в точке (p*,l*): pi³0, l1³0, l2 ³0, li ³0, i =1,…,n. Таким образом:
L(p*,l*)=![]()
![]() (p,l)=
(p,l)=![]()
![]() (p,l). (6)
(p,l). (6)
Здесь имеет место состояние равновесия для функции Лагранжа, и одна из компонент этой точки равновесия представляет собой максимально правдоподобное распределение из класса с ограничениями на значение математического ожидания Mx£q1 для полученной выборки х. Дифференцируя функцию Лагранжа по pi и приравнивая значения частных производных к нулю, получаем аналитическое представление для значений вероятностей для максимально правдоподобного распределения pi = 1/(l1+l2xi+li).
Численные значения этих вероятностей с оценкой точности решений можно получить с помощью алгоритма [1].
Для альтернативной гипотезы задача определения максимально правдоподобного распределения имеет вид:
Найти max ![]() ln pi, (7)
ln pi, (7)
![]() pi+p0=1,
pi+p0=1, ![]() xipi+p0=q2, 0£pi£1.
xipi+p0=q2, 0£pi£1.
Достижимые оценки сверху для значений априорных и апостериорных вероятностей ошибок первого и второго рода получаем также как и в случае использования принципа Лапласа при получении максимально правдоподобных распределений. Отметим, что вышеуказанные методы и вычислительные процедуры подходят для более широкого класса задач различения случайных величин.
Действительно, определим тройку ([ab],F,PT),
где [a, b] – отрезок,
F – s-алгебра подмножеств из отрезка [a, b].
PT– s-аддитивная функция на некотором подмножестве ТÍF, PqT(Èf, fÎТ)£1.
Таким образом, определяется целый класс вероятностных мер.
Получив последовательность независимых испытаний х1,….,xn, следует принять гипотезу о том, что случайная величина принадлежат классу ([a1,b1], F1, PT1), ее математическое ожидание равно q1, или случайная величина принадлежит классу
([a2,b2], F2, PT2), ее математическое ожидание равно q2. Также как и в частном случае, можно использовать принцип Лапласа и находить максимально правдоподобное распределение для гипотез 1 и 2.
Дальнейшим обобщением является проблема выбора между гипотезами 1 и 2, когда для соответствующих классов известны первые моменты m11,…,m1n1, m21,…,m2n2. Тогда достижимые оценки ошибок первого и второго рода достигаются на функциях, имеющих не более чем n1 +1 и n2 +1 скачков [7].
ЛИТЕРАТУРА
1. Рогов методы в теории принятия решений. – М.: Компания «Спутник», 2007.
2. Рогов методы при формировании и использовании тестов для разделения качества подготовки специалистов по направлениям: информационные технологии и аналитические методы в разных областях профессиональной деятельности // Труды Всероссийской научно-практической конференции «Информационные технологии в образовании и науке». – М.: МФЮА, 2007 г.
3. Математические методы статистики. – М., 1975.
4. Проверка статистичесих гипотез. – М.: Наука, 1979.
5.. Последовательный анализ. – М: Физматгиз, 1960.
6.. Статистические решающие функции. В сб. Позиционные игры. – М.: Наука, 1967.
7. Марков труды по тeории непрерывных дробей и теории функций, наименее уклоняющихся от нуля. – М-Л: Гостехиздат, 1948.
8. О минимаксном подходе к задаче проверки гипотез / Cеминар по теории вероятностей и математической статистики в Математическом институте АН СССР 7 мая 1974 г. – Т. ХХI. – №2, 1976.
9. Математическая экономика. – М., 1972.
О КОМБИНАЦИОННОМ СПОСОБЕ ЧИСЛЕННОГО ИССЛЕДОВАНИЯ ФУНКЦИЙ
,
Институт машиноведения им. РАН, г. Москва
Несмотря на постоянное совершенствование вычислительной техники (растут объемы памяти и быстродействие ЭВМ), проблемы вычислительной эффективности того или иного алгоритма исследования функций при решении практических задач всегда будут актуальными, так как также постоянно меняется (усложняется) характер решаемых задач (хотя бы по числу оцениваемых параметров и критериев качества работы динамических систем). Но в то же время именно постоянное усовершенствование ЭВМ позволяет, по нашему мнению, упрощать способы исследования функций за счет уменьшения аналитической составляющей способа (но, отнюдь не избегая ее) и увеличения возможности прямого численного анализа (арифметической составляющей). Очевидно, что к таким способам относятся методы Монте-Карло, в том числе и методы ЛП-поиска [1], в основе которых лежат принципы случайного поиска решения задачи, что и делает такие подходы универсальными. Но платой за такую универсальность является определенная “слепота”, и это приводит к громадным объемам вычислений, что затрудняет интерпретацию получаемой информации при проведении вычислительных экспериментов. Более усовершенствованная технология проведения математического эксперимента связана с использованием идей планирования экспериментов реализована в методе ПЛП-поиска [2]. В настоящей работе проводится идея о том, что комбинация методов [1] и [2] ([1] + [2] + [1] и [2] + [3]) позволяет во многих практических случаях, не прибегая к регулярным методам, получать вполне приемлемые результаты. Идея рассматривается в применении комбинации [2] + [1] к тестовым функциям 1) – 5) (оригинальным (функции 1 и 2) и взятым из литературных источников [3,4,5] (соответственно функции 3, 4 и 5)) и проверяется в сопоставлении с результатами, полученных на этих же функциях с применением метода [1]. Обратим внимание на то, что функции 1), 2) и 3) имеют первую и вторую производные по параметрам, т. е., достаточно гладкие, а функции 4) и 5) – только первые производные по параметрам, что совершенно невыгодно для случайного поиска, когда экстремумы находятся на границах области поиска, как в данном случае.
1) 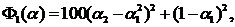 2)
2) 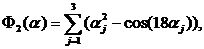
3) 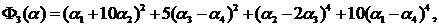
4) 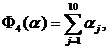 5)
5) 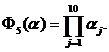
Для функции 1) в области изменения параметров ![]() минимум
минимум ![]() =0;
=0;
Для функции 2) в области изменения параметров ![]() минимум
минимум ![]() =0;
=0;
для функции 3) в области изменения параметров ![]() минимум
минимум ![]() =0;
=0;
для функции 4) в области изменения параметров ![]() минимум
минимум ![]() =10, а максимум
=10, а максимум ![]() =20;
=20;
для функции 5) в области изменения параметров ![]() минимум
минимум ![]() =1, а максимум
=1, а максимум ![]() =1024; (при этом для функций 4) и 5) экстремумы достигаются на границах диапазона изменения параметров.
=1024; (при этом для функций 4) и 5) экстремумы достигаются на границах диапазона изменения параметров.
Все итоговые результаты вычислений и сопоставлений приведены в табл 1. В столбцах 2 и 3 указаны значения экстремумов ![]() и
и ![]() , полученные методом из [1] для большого числа NO =10000 вычислительных экспериментов (испытаний). В столбцах 5 и 6 приведены значения экстремумов и соответствующие им количества испытаний, затраченных при применении комбинации [2] + [1]. В столбцах 9, 10, 11 и 12 приведены простые сравнительные оценки применения этой комбинации.
, полученные методом из [1] для большого числа NO =10000 вычислительных экспериментов (испытаний). В столбцах 5 и 6 приведены значения экстремумов и соответствующие им количества испытаний, затраченных при применении комбинации [2] + [1]. В столбцах 9, 10, 11 и 12 приведены простые сравнительные оценки применения этой комбинации.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
