Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ВЫСШАЯ МАТЕМАТИКА
Контрольная работа №3
для экономических специальностей заочной формы обучения
Вариант 10
1. Пяти полевым радиостанциям разрешено во время учений работать на 6 радиоволнах. Выбор волны на каждой станции производится наудачу. Найти вероятность того, что будут использованы различные радиоволны.
Решение:
Воспользуемся классическим определением вероятности. Определим событие А – будут использованы различные радиоволны.
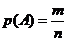
где n – общее число исходов
m – число исходов, благоприятствующих наступлению события А.
Определим значения n и m:
Каждая из радиостанций может использовать любую частоту, т. е.
n = 6*6*6*6*6
Число перестановок 5 предметов на 6 местах равно:
m = 6*5*4*3*2 = 720 = 6!
Следовательно, искомая вероятность равна:
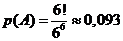
2. Девушка забыла последнюю цифру номера телефона своего жениха и набрала ее наугад. Определить вероятность того, что ей придется набирать номер не более трех раз.
Решение:
Определим событие А – девушке пришлось набирать номер не более трех раз. Это событие состоит из 3 независимых событий:
![]() – набрала верный номер с первого раза;
– набрала верный номер с первого раза;
![]() – набрала верный номер со второго раза;
– набрала верный номер со второго раза;
![]() – набрала верный номер с третьего раза;
– набрала верный номер с третьего раза;
Тогда искомая вероятность может быть найдена как сумма:
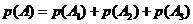
Определим вероятности элементарных событий:
![]() – набрала верный номер с первого раза;
– набрала верный номер с первого раза;
Вероятность угадать одну цифру из 10 равна ![]()
![]() – набрала верный номер со второго раза;
– набрала верный номер со второго раза;
Вероятность этого события определим, пользуясь теоремой о произведении вероятностей. Так, чтобы угадать номер телефона со второй попытки должно произойти два последовательных события: не угадал первую цифру и угадал вторую. Вероятность «неугадать» первую цифру равна ![]() (9 из 10 цифр неправильные), а угадать вторую равна
(9 из 10 цифр неправильные), а угадать вторую равна ![]() (одна цифра из 10 уже выбрана в первой попытке, следовательно, осталось 9 и из них только одна правильная). Следовательно,
(одна цифра из 10 уже выбрана в первой попытке, следовательно, осталось 9 и из них только одна правильная). Следовательно, ![]()
Рассуждая аналогичным образом, найдем вероятность «угадывания» цифры с третьей попытки:
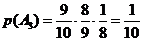
Таким образом, вероятность события А равна:
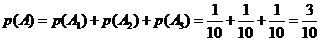
3. В первом ящике содержится 20 деталей, из них 15 стандартных; во втором – 30 деталей, из них 24 стандартных; в третьем – 10 деталей, из них 6 стандартных. Найти вероятность того, что наудачу извлеченная деталь из наудачу взятого ящика – стандартная.
Решение:
Воспользуемся формулой полной вероятности:
![]()
где
А – событие, вероятность которого необходимо определить.
![]() – гипотезы
– гипотезы
![]() – вероятности гипотез
– вероятности гипотез
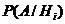 – вероятность наступления события А, при выборе i-ой гипотезы.
– вероятность наступления события А, при выборе i-ой гипотезы.
Определим событие А – наудачу извлеченная деталь из наудачу взятого ящика – стандартная.
Гипотезы ![]() заключаются в выборе соответственно 1, 2, 3 ящика. Эти события равновероятны, следовательно
заключаются в выборе соответственно 1, 2, 3 ящика. Эти события равновероятны, следовательно 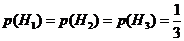 . Найдем условные вероятности:
. Найдем условные вероятности:
Вероятность извлечь стандартную деталь из первого ящика равна 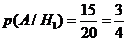 ; из второго –
; из второго – ![]() , из третьего –
, из третьего – ![]() .
.
Таким образом, искомая вероятность равна:
![]()
4. Решить задачи, используя формулу Бернулли и теоремы Муавра-Лапласа.
а) Вероятность появления некоторого события в каждом из 5 независимых опытов равна 0,2. Определить вероятность появления этого события по крайней мере 3 раза.
б) Всхожесть семян данного сорта растений составляет 90%. Найти вероятность того, что из 900 посаженых семян число проросших будет: 1) равно 800, 2) заключено между 805 и 820.
Решение:
а) Воспользуемся формулой Бернулли. Определим событие А – указанное событие появлялось по крайней мере 3 раза из 5, т. е. 3, 4 или 5.
Вычислим вероятности этих событий и найдем вероятность исходного, воспользовавшись формулой суммы. Формула Бернулли:
![]()
По условию задачи p = 0,2. Откуда q = 1 – p = 0,8, n = 5, а m последовательно принимает значения 3, 4, 5.
Т. о.
![]()
![]()
![]()
Следовательно,
![]()
б)
1) Воспользуемся локальной теоремой Муавра-Лапласа, которая применяется вместо формулы Бернулли при большом количестве испытаний.
![]()
Согласно условию задачи p = 0,9. Откуда q = 1 – p = 0,1, n = 900, а k=800. Следовательно,
![]()
2) воспользуемся интегральной функцией Лапласа
![]()
Вычислим
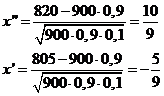
Тогда искомая вероятность равна:
![]()
При решении задания б) использованы таблицы локальной и интегральной функций Лапласа и их свойства (локальная функция – четная, интегральная – нечетная).
5. Дискретная случайная величина Х имеет только два возможных значения: x1 и x2, причем x1 < x2. Вероятность того, что Х примет значение x1 равно 0,3. Найти закон распределения Х, зная математическое ожидание М[X] = 2,7 и дисперсию D[X] = 0,21.
Решение:
Составим таблицу закона распределения
|
|
|
| 0,3 | Х |
Согласно условия дискретная случайная величина может принимать только 2 значения, а следовательно сумма вероятностей должна быть равной 1. Откуда находим Х = 1 – 0,3 = 0,7.
Используя формулы для нахождения математического ожидания и дисперсии, а также их значения, данные в условии задачи. Найдем значения ![]() и
и ![]() .
.
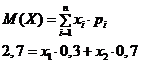
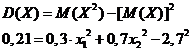
Получили систему двух уравнений с двумя переменными, решая которую и найдем значения ![]() и
и ![]() .
.
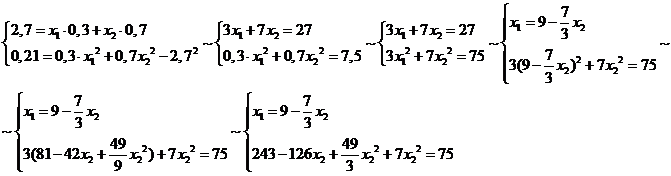 Из второго уравнения системы получаем:
Из второго уравнения системы получаем:
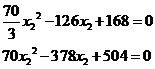
Решая квадратное уравнение, получаем два действительных корня: 2,4 и 3. Откуда, значения ![]() соответственно равны 3,4 и 2. Учитывая, что по условию задачи x1 < x2, решением данной задачи будут значения 2,4 и 3,4. Окончательно закон распределения имеет вид:
соответственно равны 3,4 и 2. Учитывая, что по условию задачи x1 < x2, решением данной задачи будут значения 2,4 и 3,4. Окончательно закон распределения имеет вид:
| 2,4 | 3,4 |
| 0,3 | 0,7 |
6. Непрерывная случайная величина Х задана функцией распределения
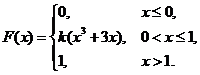
Найти: а) параметр k; б) математическое ожидание; в) дисперсию.
Решение:
а) параметр k найдем из условия непрерывности функции F(x). Т. е.
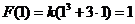
Откуда получаем значение параметра k:
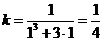
Следовательно, функция распределения имеет вид:
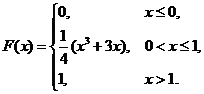
б) Математической ожидание непрерывной случайной величины определяется по формуле:
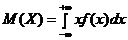
где f(x) – плотность случайной величины, которая равна производной от функции распределения. Т. о.
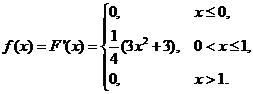
Откуда получаем математическое ожидание:
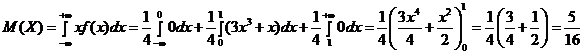
в) Дисперсия непрерывной случайной величины определяется по формуле:
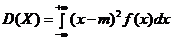
где m – математическое ожидание, т. е. ![]()
Откуда
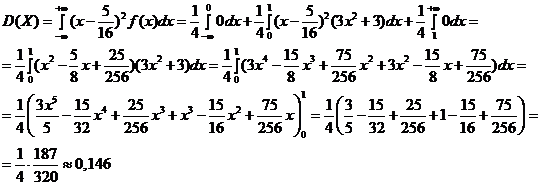
7. Известны математическое ожидание а=9 и среднее квадратичное отклонение s=4 нормально распределенной случайной величины Х. Найти вероятность: а) попадания этой величины в заданный интервал (2, 10); б) отклонения этой величины от математического ожидания не более, чем на d=5.
Решение:
Для вычисления соответствующей вероятности воспользуемся функцией Лапласа.
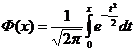
Значения данной функции в точке х находятся в специальных таблицах.
а) Вероятность попадания в интервал (α;β) нормально распределенной случайной величины равен:
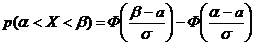
Следовательно,
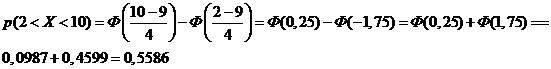
б) отклонение d от математического ожидания вычислим по формуле:
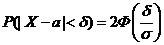
Т. е.
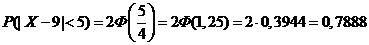
8. Из генеральной совокупности извлечена выборка, которая представлена в виде интервального вариационного ряда.
а) Предполагая, что генеральная совокупность имеет нормальное распределение, построить доверительный интервал для математического ожидания с доверительной вероятностью g=0,95.
б) Вычислить коэффициенты асимметрии и эксцесса, используя упрощенный метод вычислений, и сделать соответствующие предположения о виде функции распределения генеральной совокупности.
в) Используя критерий Пирсона, проверить гипотезу о нормальности распределения генеральной совокупности при уровне значимости a=0,05.
x | 3,0-3,6 | 3,6-4,2 | 4,2-4,8 | 4,8-5,4 | 5,4-6,0 | 6,0-6,6 | 6,6-7,2 |
n | 6 | 10 | 35 | 43 | 22 | 15 | 7 |
Решение:
а) Вычислим основные числовые характеристики данного вариационного ряда, используя упрощенный метод расчета моментов. Для этого вместо интервального ряда введем дискретный, записав вместо интервалов только середины интервалов, а результаты занесем в таблицу. По упрощенному методу вводим новую переменную
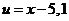
xi | ni | ui | niui |
|
|
|
3,3 | 6 | -1,8 | -10,8 | 19,44 | -34,99 | 62,99 |
3,9 | 10 | -1,2 | -12 | 14,40 | -17,28 | 20,74 |
4,5 | 35 | -0,6 | -21 | 12,60 | -7,56 | 4,54 |
5,1 | 43 | 0 | 0 | 0 | 0 | 0 |
5,7 | 22 | 0,6 | 13,2 | 7,92 | 4,75 | 2,85 |
6,3 | 15 | 1,2 | 18,0 | 21,60 | 25,92 | 31,10 |
6,9 | 7 | 1,8 | 12,6 | 22,68 | 40,82 | 73,48 |
S | 138 | 0 | 0 | 98,64 | 11,66 | 195,70 |
Далее, в соответствии с данными таблицы получаем
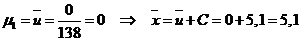
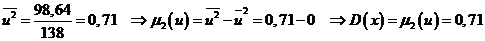
Однако выборочная дисперсия является смещенной оценкой, т. е. она дает заниженное значение дисперсии генеральной совокупности. Поэтому вместо выборочной дисперсии используют исправленную выборочную дисперсию
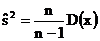
В данном случае
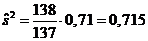
Тогда среднеквадратичное отклонение равно
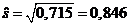
Доверительным интервалом (a,b) для статистического параметра q называется интервал, который с заданной вероятностью g "накрывает" неизвестное значение параметра, т. е.
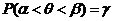 .
.
Доверительный интервал для математического ожидания a, в случае нормального распределения с неизвестным средним квадратичным отклонением (точнее, известна только его оценка), имеет вид
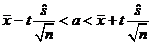 ,
,
где t – коэффициент, связанный с распределением Стьюдента и определяемый объемом выборки n и доверительной вероятностью g. Коэффициент t обычно находится из таблиц по заданным степеням свободы k=n–1 и доверительной вероятности g (или уровню значимости a=1–g).
В рассматриваемом случае n = 138, следовательно k = 137. Тогда, при g = 0,95, по таблицам для распределения Стьюдента, находим,
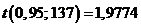
В результате получаем
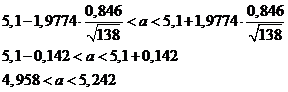
Отсюда
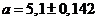
б) Найдем теперь выборочные значения начальных и центральных моментов:
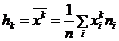 ,
, ![]() .
.
По упрощенному методу, сначала вычисляется центральный момент для новой переменной mk(u), а затем находят моменты для заданной переменной mk(x) по формуле
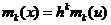 .
.
Между начальными и центральными моментами существует взаимосвязь:
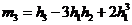 ,
, ![]() .
.
Здесь нужно иметь в виду, что ![]() ,
, 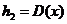 .
.
Найдем начальные моменты по данным таблицы:
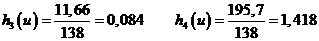
Тогда
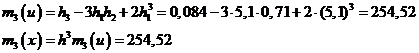
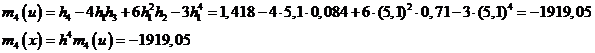
Зная моменты 3-го и 4-го порядков, можно вычислить коэффициент асимметрии и эксцесс:
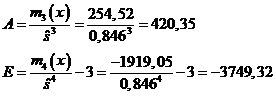
Асимметрия положительна и имеет достаточно большое значение, что свидетельствует о том, что распределение характеризуется значительной правосторонней асимметрией. Отрицательный эксцесс указывает на более плосковершинное распределение по сравнению с нормальным. Его абсолютное значение очень сильно отличается от 0.
Определим теперь значимость коэффициентов асимметрии и эксцесса. Для этого вычислим погрешность вычислений по формулам
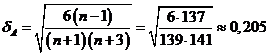
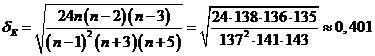
Посмотрим теперь, попадают ли найденные значения в "трехсигмовый" интервал:

Из полученных неравенств следует, что коэффициент асимметрии значимо отличается от нуля, есть основания полагать, что распределение генеральной совокупности не является нормальным, однако эксцесс значимо отличается от нуля, поэтому хвосты распределения «тяжелее», а пик более «приплюснутый», чем у нормального распределения.
в) Критерием согласия называется критерий поверки гипотезы о предполагаемом законе распределения. В соответствии с критерием Пирсона сначала вычисляется величина
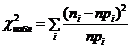 ,
,
где pi – вероятности, полученные по некоторому теоретическому закону распределения. Заметим, что c2-распределение можно применять только при достаточно большом объеме выборки (n > 50) и достаточно больших частотах (ni ³ 5). Ту группу вариационного ряда, для которых последнее условие не выполняется, объединяют с соседней и, соответственно, уменьшают число интервалов.
i | xi–xi+1 | ni |
|
|
|
|
|
1 | 3,0-3,6 | 6 | -0,4934 | -0,4616 | 0,0318 | 0,1908 | 176,87 |
2 | 3,6-4,2 | 10 | -0,4616 | -0,3554 | 0,1062 | 1,062 | 75,22396 |
3 | 4,2-4,8 | 35 | -0,3554 | -0,136 | 0,2194 | 7,679 | 97,20498 |
4 | 4,8-5,4 | 43 | -0,136 | 0,136 | 0,272 | 11,696 | 83,78424 |
5 | 5,4-6,0 | 22 | 0,136 | 0,3554 | 0,2194 | 4,8268 | 61,10027 |
6 | 6,0-6,6 | 15 | 0,3554 | 0,4616 | 0,1062 | 1,593 | 112,8359 |
7 | 6,6-7,2 | 7 | 0,4616 | 0,4934 | 0,0318 | 0,2226 | 206,3484 |
138 | 0,9868 | 27,2702 | 813,3678 |
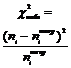
В предположении, что имеет место нормальное распределение, были оценены два параметра этого распределения: ![]() и
и ![]() . Если изучаемое распределение подчинено нормальному распределению, то вероятность того, что случайная величина X примет значение из интервала (xi<X<xi+1), находится по формуле
. Если изучаемое распределение подчинено нормальному распределению, то вероятность того, что случайная величина X примет значение из интервала (xi<X<xi+1), находится по формуле
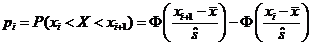 ,
,
где
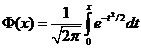
– функция Лапласа, значения которой табулированы и приводятся в таблицах. Следует отметить, что функция Лапласа является нечетной функцией, т. е. F(–x)=–F(x).
Из расчетной таблицы видно, что
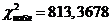
Теперь найдем критическое значение ![]() . Поскольку у предполагаемой модели были неизвестны оба параметра, поэтому k=2; при расчете критерия использовались восемь интервалов r=7 Таким образом, число степеней свободы n=r–1–k=4 При заданном уровне значимости из таблиц для c2-распределения находим
. Поскольку у предполагаемой модели были неизвестны оба параметра, поэтому k=2; при расчете критерия использовались восемь интервалов r=7 Таким образом, число степеней свободы n=r–1–k=4 При заданном уровне значимости из таблиц для c2-распределения находим
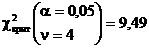
Поскольку ![]() , то гипотезу о распределении с равномерной плотностью, следует считать неправдоподобной.
, то гипотезу о распределении с равномерной плотностью, следует считать неправдоподобной.
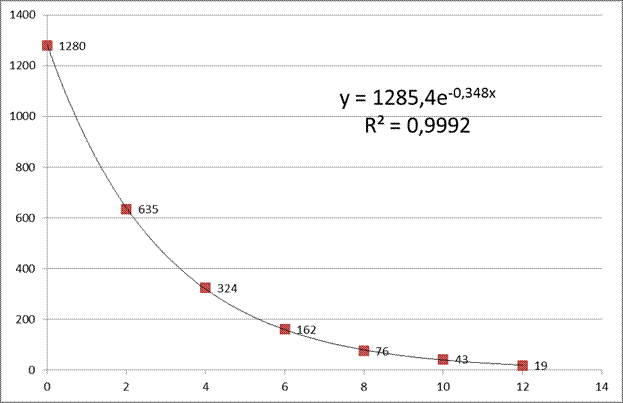
9. Методом наименьших квадратов подобрать функцию ![]() по табличным данным и сделать чертеж.
по табличным данным и сделать чертеж.
x | 0 | 2 | 4 | 6 | 8 | 10 | 12 |
y | 1280 | 635 | 324 | 162 | 76 | 43 | 19 |
Решение:
Выполним линеаризующую подстановку: ![]()
Тогда исходная таблица в новых переменных будет иметь вид:
v | 0 | 2 | 4 | 6 | 8 | 10 | 12 |
u | 7,1546 | 6,4536 | 5,7807 | 5,0876 | 4,3307 | 3,7612 | 2,9444 |
Используя МНК построим линейную зависимость между v и u, а затем выполним обратный переход к переменным у и х с помощью обратного преобразования: 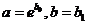 , где
, где ![]() и
и ![]() – коэффициенты линейной модели.
– коэффициенты линейной модели.
Для построения линейной модели выполним дополнительные расчеты:
n = 7
![]()
![]()
![]()
![]()
Составим систему для нахождения коэффициентов линейной регрессии:
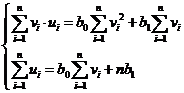 или
или 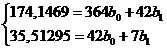
Решая систему получаем
![]()
Выполним обратный переход:
![]()
Т. о. искомая функция имеет вид: 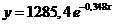
По полученным данным выполним чертеж. Построение выполнено в программе Excel. При этом на графике отображается коэффициент корреляции, значение которого очень близко к 1, что говорит о хорошем качестве построенной функции.