

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Из: (с. 134-160) Сборник трудов участников Пятой Международной конференции «Горизонты прикладной лингвистики и лингвистических технологий» (MegaLing-2009), Украина, Киев, 21-26 сентября 2009 года. Киев, ДОВИРА, 2009. – 528с.
РОЛЬ ТРИАДЫ И МЕТОНИМИИ В СЕМАНТИЧЕСКОЙ ОРГАНИЗАЦИИ
СОСТАВНОГО ТЕРМИНА
Виктор Глумов
Нижний Новгород, Россия
Филиал Российского Государственного Гуманитарного Университета в г. Нижний Новгород
Аннотация. Выявленные в английских и русских составных терминах (компаундах – compounds) и формально описанные 20 семантических признаков вида инструментальность, количественность, локативность и т. п. считаются уточнителями некоторого центра в семантической структуре компаунда. Этим центром предлагается считать универсальную семантическую триаду <субъект-процесс-объект>, реализуемую в компаунде полностью или частично. Прямые или косвенные отношения между элементами компаунда зафиксированы в специальном тезаурусе. Формализация содержания связей в пределах компаунда затрудняется широко распространенным явлением метонимии. Возникающие своеобразные метонимические провалы (pits) между смыслами элементов компаунда предлагается «мостить» каскадом, составленным из базовых 3-членных предложений (примитивов). Каждый хранимый в тезаурусе примитив выражает прямые парадигматические связи между признаками терминируемого понятия. Предлагаемый подход может способствовать построению эффективных лексических единиц, столь ожидаемых многочисленными приложениями.
Ключевые слова: составные термины (компаунды), семантическая структура термина, онтология, примитивы, метонимия, каскадирование.
Annotation. Recognized within English and Russian multiword terms (compounds) and represented formally, 20 semantic features similar to instrumentality, quantitativeness, locativeness and the like are thought to specify some core or centre within a lineally-arranged compound semantic structure. A certain universal semantic triad <subject-process-object> is suggested to be such a centre. Direct and indirect relations within the body of a compound are specially declared in the thesaurus. Formalizing interelement relations within a compound is heavily hampered by the presence of widely spread metonymy. The emerging metonymical pits between the semantic features of the compound are suggested to be bridged via certain cascades compiled of basic 3-member sentences called primitives. Each thesaurus-held primitive declares immediate paradigmatic links between features of the notion concerned. The approach suggested may be found useful for constructing efficient lexical units so much awaited by their numerous applications.
Keywords: compounds, term semantic structure, ontology, primitives, metonymy, cascading.
Автоматический анализ и синтез текста, машинный перевод, автоматическое извлечение информации из текста (data mining), объектно-признаковые языки, языки программирования, а также многоязычный поиск информации (cross-language search) (в котором дескриптор чаще всего имеет вид составного термина и на дескриптор порой накладывается требование по длине), нормализация и стандартизация отраслевых терминологий, сфера образования (где эффективно построенный термин может способствовать оптимальному усвоению отраслевых понятий) – вот далеко не полный перечень областей, нуждающихся в оптимально построенном термине.
Планируя наблюдение над внешней и глубинной структурами термина, мы считаем, что наибольшими трудностями в этом наблюдении могут быть:
1) определение объема содержания понятия «терминоэлемент» (Этот термин впервые был предложен в [10]). Это понятие является принципиальным при нормализации и стандартизации терминологий, при формировании терминосистем с наименьшим количеством терминоэлементов, при описании процессов свертывания и развертывания терминоструктуры и т. д.;
2) распознавание терминированности или нетерминированности того или иного терминоэлемента; например, в термине первая космическая скорость следует распознавать специальное отраслевое значение, возложенное на обыденное слово первая. Терминированность, а именно значение количественности, следует видеть и в терминах вида легкий бетон [9,с.22], тяжелый бетон [9,с.26], особо тяжелый бетон [9,с. 26].
В нашем случае объектом исследования являются английские и русские составные термины (компаунды) английского и русского подъязыков цифровой вычислительной техники и программирования.
Примечание 1. Современная литература на английском языке для названия «составной термин» предлагает однословный термин – компаунд (a compound), а сам же процесс построения компаунда назван компаундированием (compounding). Нужно признать, что эти английские имена отличает отсутствие описательности и присутствие системности (a compound – compounding). По-видимому, это есть как раз тот случай, когда калькирование иностранного термина полезно, а не вредно. Назвать же составной термин «соединением», а процесс формирования таких соединений каким-то туманным сочетанием (вспомним «соединение химическое», «соединение военное» и т. п.) – такая попытка чревата еще большей неразберихой. Это лишний раз подтверждает мысль о важности эффективно построенного терминологического знака.
Каждый термин может одновременно иметь как пре-, так и постпозицию.
Извлеченный текстовый термин подвергался двухэтапной обработке:
1) моделированию его внешней или поверхностной структуры [4; 6] и
2) моделированию его семантической (или глубинной) структуры [4].
ПЕРВЫЙ ЭТАП НАБЛЮДЕНИЯ НАД ТЕРМИНОСТРУКТУРОЙ
На первом этапе исследования каждый элемент в наблюдаемом компаунде был представлен тремя формальными признаками – морфологическим, позиционным и синтагматическим.
Такое – безусловно трудоемкое – описание терминоэлемента отвечало особенностям внешнего выражения связей в английских и русских терминах. Позиционный и синтагматический признаки особенно необходимы для представления английских терминов, ибо – согласно классику английского языкознания Г. Суиту (Henry Sweet) и Ч. Фризу (Ch. C. Fries) [20,с.94] – само местоположение слова в словосочетании имеет вполне определенное значение. Эту роль позиции элемента в так называемой «формуле» строения сложных лингвистических образований подчеркивал и [13,с.19; 14,с.37].
Укажем особенности формирования нашей поверхностной модели компаунда.
1) Описание каждого элемента компаунда с помощью вышеуказанных признаков составляет поверхностную модель компаунда. Признак «поверхностная» несколько условен, ибо распознать термин в тексте, затем распознать в нем элементы, соотнести каждый элемент с одним из морфологических классов (tagging), зафиксировать связь между элементами – эти операции возможны лишь на логико-семантических основаниях.
2) Компонентом нашей модели является и сам термин. В результате, такая модель – однажды сформированная – становится неким микробанком, к которому можно программно и неоднократно обращаться с запросами – разумеется, в пределах тех сведений, что были вручную заложены в него предварительно [4;5].
3) В терминах нижеуказанных видов мы усматривали присутствие двух элементов.
Примечание 2: На этапе предмашинной обработки термина границы между его элементами обозначались следующими условными знаками: грамматически главный элемент (т. е. ядро) обозначался знаком * (звезда); искусственно созданная граница между элементами обозначалась знаком #, а знаком ^ обозначалось, напротив, объединение двух наборов символов – например, *оператор GO^TO.
Укажем некоторые примеры.
а) H- #*data; холлеритные *данные; C- # *compiler (т. е. транслятор программ, написанных на языке С, или транслятор С-программ); GOTO *statement оператор GOTO;
б) many-sided *configuration; многосторонняя *конфигурация; read-only *memory; постоянная *память;
в) FORTRAN - #*compiler; ФОРТРАН- #*транслятор (т.е. транслятор для ФОРТРАН-программ); RAM - #*memory (= random - #access *memory, т.е. память с произвольной выборкой/доступом). Если же термин вида ФОРТРАН-транслятор имел и описательный вид – скажем, транслятор для ФОРТРАН-программ, тогда фиксировалось наличие 4 элементов: *транслятор для ФОРТРАН- #программ. (Второе значение этого термина здесь не обсуждается.)
4) Формирование поверхностной модели предполагает разбиение составного термина на элементы. Такое разбиение возможно только на семантических основаниях. Например, искусственный пробел ставился в случае дельта - #* конфигурация, но не ставился в случае delta-like дельтообразный, потому что delta и delta-like принимались нами выражающими один и тот же семантический признак <сходство, подобие>. (Сравните также присутствие <сходства> в рыбном термине *рыба - #звезда и в строительном термине сэндвич- #*панель).
По мере усложнения содержания информационных потребностей описательные возможности нашей модели можно наращивать, т. е. встраивать новые внешние (а со временем и глубинные) признаки и этим готовить модель для удовлетворения все более растущих «интеллектуальных» потребностей пользователя.
Машинной обработке подвергались 4 экспериментальных массива, а именно: 1) массив из 2000 английских составных терминов, 2) массив из 2000 русских составных терминов, 3) массив из 2000 английских поверхностных моделей и 4) массив из 2000 русских поверхностных моделей. В терминологических массивах один термин употреблялся только один раз. Английские термины на русский язык не переводились. И английские и русские термины извлекались из неадаптированных текстов [4].
Предлагаемая поверхностная 3-хпризнаковая модель позволяет выявить частоты длин составных терминов (длина измеряется в терминоэлементах), частоты морфологических категорий в терминоструктуре, частоты морфологических конструкций терминов, а также выявить частоты появления конкретных морфологических категорий в той или иной позиции терминоструктуры.
Также возникает возможность:
а) сформировать ранжированный перечень синтагматических цепей вида
![]() ,
,  ,
,  и т. д.;
и т. д.;
б) выявить частотность классов лексических значений, возникающих в той или иной точке терминоструктуры слева или справа от ядра термина, если ядро занято конкретным семантическим (глубинным) признаком.
Ниже укажем некоторые статистико-вероятностные результаты машинной обработки поверхностных моделей [4; 5].
Примечание 3: В примерах и рисунках применялись следующие условные обозначения.
а) английские морфологические классы: N – английское существительное общего падежа; Nacr – существительное-акроним (например, элемент ROM- в термине ROM- #*memory постоянное запоминающее устройство, ПЗУ; N-1 и N1 – существительное в 1-ой препозиции или 1-ой постпозиции относительно ядра; ING и ED – причастие-I и причастие-II; VN – отглагольное существительное; GER*– герундий, являющийся ядром составного термина; ADJ– полное или краткое прилагательное; ADJ1 – сложно-составное прилагательное вида errorproof устойчивый от ошибок, сбоеустойчивый; I– идентификатор, т. е., например, зависимый элемент RESIDENT в термине RESIDENT-#*routine стандартная *программа RESIDENT.
б) русские морфологические классы: C и Cрод – существительное именительного и родительного падежей;
На Рис. 1 в круглых скобках указаны сами предлоги.
А) СТАТИСТИКО-ВЕРОЯТНОСТНОЕ ПОВЕДЕНИЕ МОРФОЛОГИЧЕСКИХ КЛАССОВ
В АНГЛИЙСКОМ ТЕРМИНЕ
На Рис. 1 для каждой позиции структуры английского термина перечислены морфологические классы и указаны вероятности их появления в этой позиции. Сумма вероятностей появления всех английских морфологических классов в данной позиции равна единице. Классы или предлоги с вероятностью меньше 0,01 в столбцах не указаны.
На этом рисунке с помощью «волн» мы хотим лишь показать некую динамику изменений активности морфологических классов в конкретных позициях влево и вправо от ядра термина.
Опираясь на содержание наших семантических признаков, которые будут описаны во второй части этого доклада, кратко опишем поведение некоторых морфологических классов в зависимости от того, какой семантический признак появляется в ядерной позиции термина, т. е. становится грамматически господствующим.
Возьмем на Рис.1 конкретную точку терминоструктуры, а именно 1-ую препозицию. На рисунке видно, что в этой точке самым активным является существительное. Если и ядро выражено существительным, тогда мы имеет конструкцию N-1 – N*.
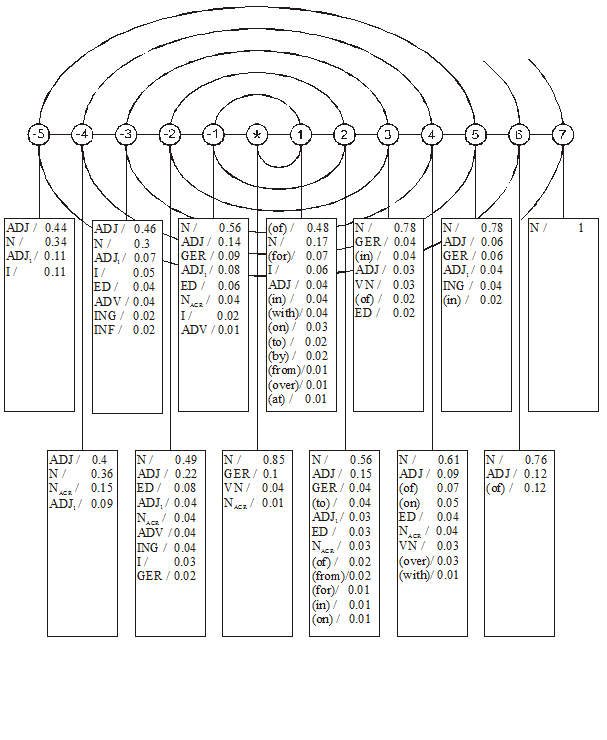
Рис.1. Вероятности появления английских морфологических классов в позициях терминоструктуры
Частоту этой морфологической конструкции отмечают многие исследователи. Мы же пойдем дальше и попытаемся описать семантически причины появления морфологического класса в 1-й препозиции.
Случай 1. N-1 – N* (ядро хранит <действие>)
Итак, для случая N-1 – N* что будет происходить в 1-ой препозиции, если ядерная позиция будет занята глубинным признаком <действие>?
а) Тогда в 1-й препозиции может появиться признак <объект>-существительное.
Например: program compilation трансляция программ; image digitization отцифровка изображений;
б) может появиться признак <инструментальность>-существительное.
Например, computer programming машинное программирование (т. е. программирование с помощью машин); computer synthesis машинный синтез (т. е. автоматизированный синтез или синтез с помощью ЭВМ).
Случай 2. N-1 – GER* (ядро хранит <действие>)
Если ядро занято признаком <действие>, но оно выражено морфологическим классом «герундий», тогда 1-ую препозицию может оккупировать <инструментальность>: laser programming лазерное программирование.
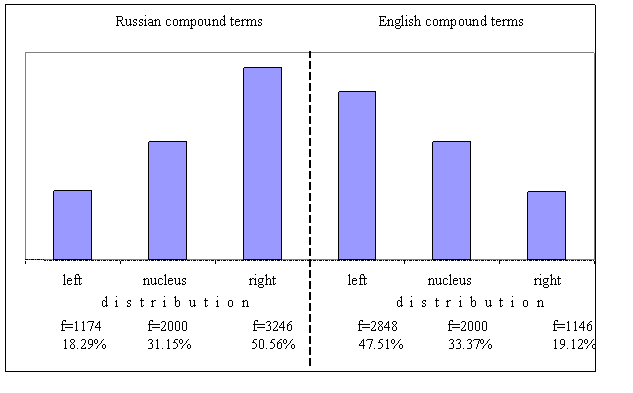

Гистограмма 2. Распределение вероятностей появления морфологических классов
в пре - и постпозициях русской и английской терминоструктур
Случай 3. N-1 – N* (ядро хранит <часть>)
В этом случае 1-ую препозицию может занять семантический признак <целое>: computer memory машинная память (т. е. память машины).
Случай 4. ADJ-1 – VN* (ядро хранит <действие>)
Если мы имеем случай «прилагательное – отглагольное существительное», тогда при
ядре-<действие> 1-ую препозицию может занять признак <инструментальность>: automatic processing автоматическая обработка; half-automatic processing полуавтоматическая обработка; manual processing ручная обработка.
На Рис.1 прилагательное оккупирует 1-ую препозицию с вероятностью 0,14, но это не значит, что эта вероятность принадлежит только <инструментальности>. Здесь прилагательное может выражать и другие глубинные признаки.
Случай 5. (N-2 + ED-2 )ins – N* action (ядро хранит <действие>)
В этом случае в 1-ой препозиции может возникать причастие прошедшего времени (ED-1), а во 2-ой препозиции – существительное (N-2). Отметим, что в данном случае инструментальность выражается двумя терминоэлементами – (N-2 + ED-1 )ins : computer-aided analysis автоматизированный анализ (т. е. анализ с помощью ЭВМ); computer-aided design машинное проектирование; computer-based data processing автоматизированная обработка данных. (Сравните выражение инструментальности морфологической конструкцией «наречие – причастие прош. вр.» в терминах другой тематической области: ionically-damaged layers слои кристалла, разрушаемые ионным способом (т. е. с помощью ионов).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
