

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
МИНИСТЕРСТВО СЕЛЬСКОГО ХОЗЯЙСТВА РОССИЙСКОЙ ФЕДЕРАЦИИ
ФГБОУ ВПО «КУБАНСКИЙ ГОСУДАРСТВЕННЫЙ АГРАРНЫЙ УНИВЕРСИТЕТ»
МЕТОДЫ ИССЛЕДОВАНИЯ В
МЕНЕДЖМЕНТЕ
Методические указания для практических занятий и
самостоятельной работы студентов
для направления 080200.68
Государственное и муниципальное управление
Краснодар
2013
УДК
ББК
Л7
Л74 Методы исследования в менеджменте: методические указания для практических занятий и самостоятельной работы студентов для направления 080200.68 «Государственное и муниципальное управление» / – Краснодар, 2012. – 23с.
Издание содержит перечень заданий для практических занятий и задания для самостоятельной работы студентов по основным темам курса дисциплины «Методы исследования в менеджменте».
УДК
ББК
© , 2012
© ФГБОУ ВПО «Кубанский
государственный аграрный
университет», 2012
Тема - Понятие и особенности прикладного научного исследования
Задание для самостоятельной работы:
Рассмотреть формы организации научного знания и составить терминологический словарь в форме таблицы:
научный факт, положение, понятие, категория, принцип, закон, теория, метатеория, идея, доктрина, парадигма, проблема, гипотеза.
Темы рефератов
1. Понятие науки и особенности научной работы.
2. Статус прикладного исследования в современной науке.
3. Структура прикладного исследования.
Тема - Математико-статистические методы изучения связей
Исследуя природу, общество, экономику, необходимо считаться со взаимосвязью наблюдаемых процессов и явлений.
Формы проявления взаимосвязей весьма разнообразны. В качестве двух самых общих их видов выделяют функциональную (полную) и корреляционную (неполную) связи. В первом случае величине факторного признака строго соответствует одно или несколько значений функции. В экономике примером может служить прямо пропорциональная зависимость между производительностью труда и увеличением производства продукции.
Корреляционная связь (которую также называют неполной, или статистической) проявляется в среднем, для массовых наблюдений, когда заданным значениям зависимой переменной соответствует некоторый ряд вероятных значений независимой переменной.
В наиболее общем виде задача в области изучения взаимосвязей состоит в количественной оценке их наличия и направления, а также характеристике силы и формы влияния одних факторов на другие. Для ее решения применяются две группы методов, одна из которых включает в себя методы корреляционного анализа, а другая – регрессионный анализ. В то же время ряд исследователей объединяет эти методы в корреляционно-регрессионный анализ, что имеет под собой некоторые основания: наличие целого ряда общих вычислительных процедур, взаимодополнения при интерпретации результатов и др.
Задачи собственно корреляционного анализа сводятся к измерению тесноты связи между варьирующими признаками, определению неизвестных причинных связей и оценке факторов оказывающих наибольшее влияние на результативный признак.
Задачи регрессионного анализа лежат в сфере установления формы зависимости, определения функции регрессии, использования уравнения для оценки неизвестных значении зависимой переменной.
Задание. Крупная компания занимается торговлей автомобильными запчастями и принадлежностями. Руководство компании намерено разработать модель оценки годового объема продаж для каждого региона страны. Поскольку, если можно будет прогнозировать региональный объем продаж, то это возможно будет сделать и для совокупных продаж. Кроме того, хорошая модель позволит составить региональный каталог потребителей, что позволит более точно делать заказы поставщикам фирмы. Менеджер по сбыту предложил использовать две переменные: 1) текущее количество розничных продаж в каждом регионе и 2) количество зарегистрированных автомобилей по состоянию на 30 апреля 20ХХ г. Получены следующие данные:
Таблица 1 – Данные для регрессионного анализа
Регион | Объем продаж за год, млн. долл. Y | Количество розничных продаж на рынке сбыта, X1 | Количество зарегистрированных автомобилей, млн. ед. Х2 |
1 | 52,5 | 1780,0 | 21,5 |
2 | 24,6 | 2470,0 | 20,2 |
3 | 18,5 | 450,0 | 6,1 |
4 | 15,6 | 440,0 | 11,5 |
5 | 32,2 | 1650,0 | 9,2 |
6 | 45,0 | 2102,0 | 10,6 |
7 | 33,0 | 2305,0 | 18,9 |
8 | 3,6 | 121,0 | 4,3 |
9 | 34,7 | 1801,0 | 9,1 |
10 | 24,6 | 1130,0 | 5,6 |
11 | 40,0 | 1650,0 | 8,7 |
Решение. Прогнозное уравнение составлено с помощью инструмента программы Microsoft Office Excel «Пакет анализа». Программа представляет решение в форме таблицы – 2.
Уравнение регрессии имеет вид:
Y=10,968+0,012Х1+0,043Х2
Y-объем продаж в год, млн. долл.
Х1 – количество розничных продаж в регионе,
Х2 – количество автомобилей, зарегистрированных в каждом регионе.
b1 – увеличение количества розничных продаж на 1 ед. при сохранении на прежнем уровне число зарегистрированных автомобилей может привести к увеличению годового уровня продаж на 12 тыс. долл.,
b2 – увеличение количества зарегистрированных автомобилей в регионе на 1 млн. ед. при сохранении на прежнем уровне количества розничных продаж может привести к увеличению годового уровня продаж на 43 тыс. долл.
Тестирование модели включает в себя два аспекта:
1) тестирование регрессии в целом,
2) тестирование отдельных параметров регрессии.
Тестирование регрессии в целом включает следующие оценки:
1) Множественный R – множественный коэффициент корреляции рассчитывается при наличии линейной связи между результативным признаком и факторными признаками. Чем ближе его значение к 1, тем интенсивнее корреляционная связь и тем меньше наблюдаемые значения изучаемого показателя отклоняются от линии множественной регрессии. В данном случае Множественный R= 0,73, связь квалифицируется как средняя.
2) Совокупный коэффициент множественной детерминации R2 показывает, какая часть общего изменения годового объема продаж определяется изменением выше обозначенных факторов вместе взятых по данному уравнению регрессии. В данном случае 52,6% изменения продаж объясняется влиянием факторов.
3) Нормированный R2 определяет чувствительность коэффициент множественной детерминации R2 к количеству наблюдений, входящих в регрессию. Должно быть пространство для изменения зависимой переменной (годового объема продаж), т. е. число наблюдений должно быть больше числа введенных переменных в 3-4 раза. Данный аспект связан с понятием «степени свободы» df . df=n-k-1, n – показывает количество наблюдений, k - количество независимых переменных. В нашем случае df=11-2-1=8
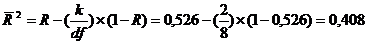
В распечатке такое же значение. Приемлемым считается, когда нормированный R2 ≥ 0,75.
4) F-тестирование на полную статистическую значимость с помощью критерия Фишера (F). Фактический уровень (Fфакт) сравнивается с теоретическим (табличным) значением
В компьютерной распечатке представлено расчетное значение F, его необходимо сопоставить с критическим значением F по таблице. Критическое значение F-критерия – это верхний предел значений F, которые возможны в случае выполнения т. н. нулевой гипотезы, по которой все истинные регрессионные параметры равны нулю, а значит, нет связи между зависимой переменной и независимыми.
Таблица – это матрица критических значений F с уровнем значимости 0,05 и 0,01, что соответствует уровням доверия 95 и 99% соответственно (мы установили 95%). Для того чтобы воспользоваться таблицей необходимо знать число степеней свободы в числителе (k) и в знаменателе (n-k-1). В нашем случае k=2, n-k-1=8, уровень значимости 0,05, значит критическое значение F по таблице равно 4,46 (рисунок 1). Это значит, что если нулевая гипотеза выполняется, то вероятность превышения F=4,46 составляет 5%. Иначе говоря, если расчетное значение F превышает 4,46, то мы на 95% можем быть уверены, что коэффициенты регрессии не равны нулю. В нашем случае расчетное значение F=4,44. Расчетное значение F-критерия ведется по формуле: ![]()
F=4,44 означает, что объяснимая (факторная) дисперсия в 4,44 раза больше чем необъяснимая (остаточная).
Если Fфакт > Fтеор, уравнение адекватно отражает сложившуюся в исследуемом ряду динамики тенденцию.
В данном случае расчетное значение F-критерия меньше критического значения, таким образом, построенная регрессионная модель статистически незначима.
5) Средняя стандартная ошибка – еще один способ статистического тестирования уравнения регрессии. Она определяет разброс случайных наблюдаемых значений Y относительно оцененных значений Y по уравнению регрессии: 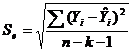
В данном случае разброс случайных наблюдаемых значений от теоретической линии регрессии объема продаж составляет 10,8 млн. руб.
В условии задачи просят определить, сколько погрешностей входи в прогноз для 1-го и 3-го регионов.
Прогноз для 1-го региона:
Y1=10,968+0,012×1780+0,043×21,5=33,25 млн. долл.
Расхождение составляет 52,5-33,25=19,25, т. е. в прогноз входит 19,25/10,8=1,78 погрешностей.
Прогноз для 3-го региона:
Y1=10,968+0,012×450+0,043×6,1=16,63 млн. долл.
Расхождение составляет 18,5-16,63=1,87, т. е. в прогноз входит 1,87/10,8=0,17 погрешностей.
Тестирование отдельных параметров регрессии включает следующие оценки:
1) t-статистика или t-соотношение:
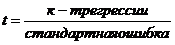
Если стандартная ошибка мала по сравнению с оцениваемым параметром, то это значит, что параметр близок к истинному значению.
t-соотношение показывает сколько стандартных ошибок содержится в коэффициенте регрессии. В нашем примере:
в параметре а – 1,4 погрешности,
в параметре b1 – 2,1 погрешность,
в параметре b2 – 0,06 погрешностей.
2) оценка статистической значимости отдельных переменных в регрессионной модели.
Расчетное t-соотношение сравнивают с критическим t-соотношение в таблице. Критическое t-соотношение определяется исходя из выбранного уровня значимости (в нашем случае это 0,05) и соответствующего числа степеней свободы (8 в нашем случае). Если расчетное t-соотношение больше критического, то гипотеза о том, что bi=0 отвергается, а переменная Xi статистически значима на уровне ɑ (т. е. выбранного уровня значимости).
Находим критическое t-соотношение:
на уровне значимости ɑ =0,05,
ɑ/2=0,025,
df=8,
критическое t-соотношение=2,306 (рисунок 2).
Поскольку расчетное t-соотношение для переменной Х1 равно 2,146, а для переменной Х2 равно 0,056, т. е меньше критического, обе переменные являются статистически незначимыми.
3) доверительные интервалы для коэффициентов регрессии выведены в распечатке.
Доверительный интервал определяется по формуле:
bi±tɑ/2×Sbi
Поскольку мы задали уровень надежности 95%, то для b1=0,012 95%-й доверительный интервал составляет:
b1=0,012±2,306×0,0058, т. е. от -0,00093 до 0,0259 (в распечатке),
b2=0,043±2,306×0,7682, т. е. от -1,7287 до 1,8144 (в распечатке).
Менеджер по сбыту не удовлетворен результатами регрессии, построенная модель не имеет прогнозной силы. Он предлагает включить в неё флуктуации региональных экономических условий. Для их учета предлагается ввести новую переменную – личный годовой доход для региона, получена следующая информация.
Таблица 3 - Введение новой переменной
Регион | Объем продаж за год, млн. долл. Y | Количество розничных продаж на рынке сбыта, X1 | Количество зарегистрированных автомобилей, млн. ед. Х2 | Личный доход, млрд. долл. Х3 |
1 | 52,5 | 1780,0 | 21,5 | 97,2 |
2 | 24,6 | 2470,0 | 20,2 | 32,5 |
3 | 18,5 | 450,0 | 6,1 | 34,6 |
4 | 15,6 | 440,0 | 11,5 | 30,2 |
5 | 32,2 | 1650,0 | 9,2 | 65,3 |
6 | 45,0 | 2102,0 | 10,6 | 92,7 |
7 | 33,0 | 2305,0 | 18,9 | 62,1 |
8 | 3,6 | 121,0 | 4,3 | 18,6 |
9 | 34,7 | 1801,0 | 9,1 | 65,2 |
10 | 24,6 | 1130,0 | 5,6 | 60,5 |
11 | 40,0 | 1650,0 | 8,7 | 82,0 |
Задание для самостоятельной работы: оцените новую модель прогноза продаж с учетом введенной переменной.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
