
5.2.9 Чому слабкі зв'язки можуть бути значимі доведені тільки на великих вибірках. Приклад з попереднього розділу показує, що якщо зв'язок між перемінними "об'єктивно" слабка (тобто властивості вибірки близькі до властивостей популяції), те не існує іншого способу перевірити таку залежність крім як досліджувати вибірку досить великого обсягу. Навіть якщо вибірка, що знаходиться у вашому розпорядженні, зовсім репрезентативна, ефект не буде статистично значимим, якщо вибірка мала. Аналогічно, якщо залежність "об'єктивно" (у популяції) дуже сильна, тоді вона може бути виявлена з високим ступенем значимості навіть на дуже маленькій вибірці. Розглянемо приклад. Представте, що ви кидаєте монету. Якщо монета злегка несиметрична, і при підкиданні орел випадає частіше решки (наприклад, у 60% підкидань випадає орел, а в 40% решка), то 10 підкидань монети було б не досить, щоб переконати кого б те ні було, що монета асиметрична, навіть якщо був би отриманий, здавалося, зовсім репрезентативний результат: 6 орлів і 4 решки. Чи не випливає звідси, що 10 підкидань узагалі не можуть довести що-небудь? Ні, не випливає, тому що якщо ефект, у принципі, дуже сильний, те 10 підкидань може виявитися цілком достатньо для його доказу. Представте, що монета настільки несиметрична, що всякий раз, коли ви її кидаєте, випадає орел. Якщо ви кидаєте таку монету 10 разів, і всякий раз випадає орел, більшість людей рахують це переконливим доказом того, що з монетою щось не то. Іншими словами, це послужило б переконливим доказом того, що в популяції, що складається з нескінченного числа підкидань цієї монети орел буде зустрічатися частіше, ніж решка. У підсумку цих міркувань ми дійдемо висновку: якщо залежність сильна, вона може бути виявлена з високим рівнем значимості навіть на малій вибірці.
5.2.10 Чи можна відсутність зв'язків розглядати як значимий результат? Ніж слабкіше залежність між перемінними, тим більшого обсягу потрібно вибірка, щоб значимо її знайти. Представте, як багато кидків монети необхідно зробити, щоб довести, що відхилення від рівної імовірності випадання орла і решки складає тільки .000001%! Необхідний мінімальний розмір вибірки зростає, коли ступінь ефекту, якім потрібно довести, убуває. Коли ефект близький до 0, необхідний обсяг вибірки для його виразного доказу наближається до нескінченності. Іншими словами, якщо залежність між перемінними майже відсутня, обсяг вибірки, необхідний для значимого виявлення залежності, майже дорівнює обсягу всієї популяції, що передбачається нескінченним. Статистична значимість представляє імовірність того, що подібний результат був би отриманий при перевірці всієї популяції в цілому. Таким чином, усе, що отримано після тестування всієї популяції було б, по визначенню, значимим на найвищому, можливому рівні і це відноситься до всіх результатів типу "немає залежності".
5.2.11 Як вимірити величину залежності між перемінними. Статистиками розроблено багато різних мір взаємозв'язку між перемінними. Вибір визначеної міри в конкретному дослідженні залежить від числа перемінних, використовуваних шкал виміру, природи залежностей і т. д. Більшість цих мір, проте, підкоряються загальному принципу: вони намагаються оцінити залежність, що спостерігається, порівнюючи її з "максимальною мислимою залежністю" між розглянутими перемінними. Говорячи технічно, звичайний спосіб виконати такі оцінки полягає в тім, щоб подивитися як варіюються значення перемінних і потім підрахувати, яку частину всієї наявної варіації можна пояснити наявністю "загальної" ("спільної") варіації двох (чи більш) перемінних. Говорячи менш технічною мовою, ви порівнюєте те "що є загального в цих перемінних", з тим "що потенційно було б у них загального, якби перемінні були абсолютно залежні". Розглянемо простий приклад. Нехай у вашій вибірці, середній показник (число лейкоцитів) WCC дорівнює 100 для чоловіків і 102 для жінок. Отже, ви могли б сказати, що відхилення кожного індивідуального значення від загального середніх (101) містить компоненту зв'язану з підлогою суб'єкта і середня величина її дорівнює 1. Це значення, таким чином, представляє деяку міру зв'язку між перемінними Стать і WCC. Звичайно, це дуже бідна міра залежності, тому що вона не дає ніякої інформації про тім, наскільки велика цей зв'язок, скажемо щодо загальної зміни значень WCC. Розглянемо крайні можливості:
a. Якщо всі значення WCC у чоловіків були б точно рівні 100, а в жінок 102, то усі відхилення значень від загального середніх у вибірці цілком порозумівалися б підлогою індивідуума. Тому ви могли б сказати, що Стать абсолютно коррелирован (зв'язана) з WCC, іншими словами, 100% розходжень, що спостерігаються, між суб'єктами в значеннях WCC порозуміваються підлогою суб'єктів.
b. Якщо ж значення WCC лежать у межах 0-1000, то та ж різниця (2) між середніми значеннями WCC чоловіків і жінок, виявлена в експерименті, складала б настільки малу частку загальної варіації, що отримане розходження (2) вважалося б пренебрежимо малим. Розгляд ще одного суб'єкта могло б змінити чи різниця навіть змінити її знак. Тому всяка гарна міра залежності повинна брати до уваги повну мінливість індивідуальних значень у вибірці й оцінювати залежність по тому, наскільки ця мінливість порозумівається досліджуваною залежністю.
5.3 Статистичні критерії
5.3.1 Загальна конструкція більшості статистичних критеріїв. Тому що кінцева мета більшості статистичних критеріїв (тестів) складається в оцінюванні залежності між перемінними, більшість статистичних тестів додержуються загального принципу, поясненому в попередньому розділі. Говорячи технічною мовою, ці тести являють собою відношення мінливості, загальної для розглянутих перемінних, до повної мінливості. Наприклад, такий тест може являти собою відношення тієї частини мінливості WCC, що визначається підлогою, до повної мінливості WCC (обчисленої для об'єднаної вибірки чоловіків і жінок). Це відношення звичайне називається відношенням поясненої варіації до повної варіації. У статистику термін пояснена варіація не обов'язково означає, що ви даєте їй "теоретичне пояснення". Він використовується тільки для позначення загальної варіації розглянутих перемінних, іншими словами, для вказівки на те, що частина варіації однієї перемінної "порозумівається" визначеними значеннями інший перемінної і навпаки.
5.3.2 Як обчислюється рівень статистичної значимості. Припустимо, ви вже обчислили міру залежності між двома перемінними (як порозумівалося вище). Наступний питання, що коштує перед вами: "наскільки значима ця залежність?" Наприклад, чи є 40% поясненої дисперсії між двома перемінними достатнім, щоб вважати залежність значимої? Відповідь: "у залежності від обставин". Саме, значимість залежить в основному від обсягу вибірки. Як уже порозумівалося, у дуже великих вибірках навіть дуже слабкі залежності між перемінними будуть значимими, у той час як у малих вибірках навіть дуже сильні залежності не є надійними. Таким чином, для того щоб визначити рівень статистичної значимості, вам потрібна функція, що представляла би залежність між "величиною" і "значимістю" залежності між перемінними для кожного обсягу вибірки. Дана функція вказала б вам точно "наскільки ймовірно одержати залежність даної величини (чи більше) у вибірці даного обсягу, у припущенні, що в популяції такої залежності ні". Іншими словами, ця функція давала би рівень значимості (p - рівень), і, отже, імовірність помилково відхилити припущення про відсутність даної залежності в популяції. Ця "альтернативна" гіпотеза ( що складається в тім, що немає залежності в популяції) звичайно називається нульовою гіпотезою. Було б ідеально, якби функція, що обчислює імовірність помилки, була лінійної і мала тільки різні нахили для різних обсягів вибірки. На жаль, ця функція істотно більш складна і не завжди точно та сама. Проте, у більшості випадків її форма відома, і її можна використовувати для визначення рівнів значимості при дослідженні вибірок заданого розміру. Більшість цих функцій зв'язано з дуже важливим класом розподілів, називаним нормальним.
5.3.3 Чому важливо Нормальний розподіл. Нормальний розподіл важливо з багатьох причин. У більшості випадків воно є гарним наближенням функцій, визначених у попередньому розділі (більш докладний опис див. у “Чи усі статистики критеріїв є нормально розподілені?”). Розподіл багатьох статистик є нормальним чи може бути отримане з нормальних за допомогою деяких перетворень. Міркуючи філософськи, можна сказати, що нормальний розподіл являє собою одну з емпірично перевірених істин щодо загальної природи дійсності і його положення може розглядатися як один з фундаментальних законів природи. Точна форма нормального розподілу (характерна "дзвінообразна крива") визначається тільки двома параметрами: середнім і стандартним відхиленням.
5.3.4 Характерна властивість нормального розподілу полягає в тому, що 68% усіх його спостережень лежать у діапазоні ±1 стандартне відхилення від середнього, а діапазон ±2 стандартні відхилення містить 95% значень. Іншими словами, при нормальному розподілі, стандартизовані спостереження, менші -2 чи великі +2, мають відносну частоту менш 5% (Стандартизоване спостереження означає, що з вихідного значення віднятий середнє і результат поділений на стандартне відхилення (корінь з дисперсії)). Якщо задати z-значення (тобто значення випадкової величини, що має стандартний нормальний розподіл) рівним 4, що відповідає ймовірнісний рівень буде менше .0001, оскільки при нормальному розподілі практично всі спостереження (тобто більш 99.99%) потраплять у діапазон ±4 стандартні відхилення.
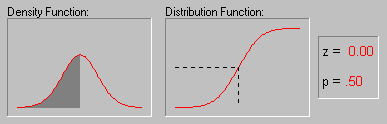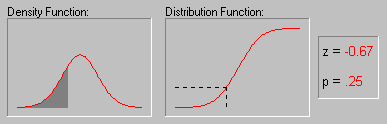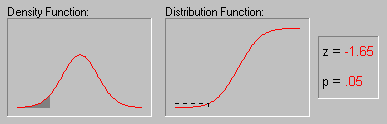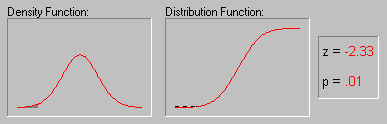
5.3.5 Ілюстрація того, як нормальний розподіл використовується в статистичних міркуваннях (індукція). Нагадаємо приклад, що обговорювалися вище, коли пари вибірок чоловіків і жінок вибиралися із сукупності, у якій середнє значення WCC для чоловіків і жінок було в точності те саме. Хоча найбільш ймовірний результат таких експериментів (одна пара вибірок на експеримент) полягає в тому, що різниця між середніми WCC для чоловіків і жінок для кожної пари близька до 0, час від час з'являються пари вибірок, у яких ця різниця істотно відрізняється від 0. Як часто це відбувається? Якщо обсяг вибірок досить великий, то різниці "нормально розподілені" і знаючи форму нормальної кривої, ви можете точно розрахувати імовірність випадкового одержання результатів, що представляють різні рівні відхилення середнього від 0 - значення гіпотетичного для всієї популяції. Якщо обчислена імовірність настільки мала, що задовольняє прийнятому заздалегідь рівню значимості, то можна зробити лише один висновок: ваш результат краще описує властивості популяції, чим "нульова гіпотеза". Варто пам'ятати, що нульова гіпотеза розглядається тільки по технічних розуміннях як початкова крапка, з яким зіставляються емпіричні результати. Відзначимо, що все це міркування засноване на припущенні про нормальність розподілу цих повторних вибірок (тобто нормальності вибіркового розподілу). Це припущення обговорюється в наступному розділі.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
