
5.3.6 Чи всі статистики критеріїв нормально розподілені? Не всі, але більшість з них або мають нормальний розподіл, або мають розподіл, зв'язаний з нормальним і обчислюється на основі нормального, таке як t, F чи хи-квадрат. Звичайно ці критеріальні статистики вимагають, щоб аналізовані перемінні самі були нормально розподілені в сукупності. Багато спостерігаємі перемінні дійсно нормально розподілені, що є ще одним аргументом на користь того, що нормальний розподіл представляє "фундаментальний закон". Проблема може виникнути, коли намагаються застосувати тести, засновані на припущенні нормальності, до даних, що не є нормальними В цих випадках ви можете вибрати одне з двох. По-перше, ви можете використовувати альтернативні "непараметричні" тести (так називані "вільно розподілені критерії", Однак це часто незручно, тому що звичайно ці критерії мають меншу потужність і мають меншу гнучкість. Як альтернативу, у багатьох випадках ви можете усе-таки використовувати тести, засновані на припущенні нормальності, якщо упевнені, що обсяг вибірки досить великий. Остання можливість заснована на надзвичайно важливому принципі, що дозволяє зрозуміти популярність тестів, заснованих на нормальності. А саме, при зростанні обсягу вибірки, форма вибіркового розподілу (тобто розподіл вибіркової статистики критерію, цей термін був уперше використаний у роботі Фишера, Fisher 1928a) наближається до нормального, навіть якщо розподіл досліджуваних перемінних не є нормальним.
5.3.7 Як довідатися наслідку порушень припущень нормальності? Хоча багато тверджень інших розділів Елементарних понять статистики можна довести математично, деякі з них не мають теоретичного обґрунтування і можуть бути продемонстровані тільки емпірично, за допомогою так званих експериментів Монте-Карло. У цих експериментах велике число вибірок генерується на комп'ютері, а результати отримані з цих вибірок, аналізуються за допомогою різних тестів. Цим способом можна емпірично оцінити тип і величину чи помилок зсувів, що ви одержуєте, коли порушуються визначені теоретичні припущення тестів, використовуваних вами. Дослідження за допомогою методів Монте - Карло інтенсивно використовувалися для того, щоб оцінити, наскільки тести, засновані на припущенні нормальності, чуттєві до різних порушень припущень нормальності. Загальний висновок цих досліджень полягає в тому, що наслідку порушення припущення нормальності менш фатальні, чим спочатку передбачалося. Хоча ці висновки не означають, що припущення нормальності можна ігнорувати, вони збільшили загальну популярність тестів, заснованих на нормальному розподілі.
5.4 Статистичні характеристики вибірки
5.4.1Випадкові величини і їхні характеристики Величини, що у рівнобіжних спостереженнях, проведених у тих самих умовах, щораз приймають різні значення, називаються випадковими. Поняття «ті самі умови» означає, що обличчю, що проводить спостереження, відомі фактори, що істотно впливають на величину, що спостерігається. Ці чи фактори підтримуються на постійному рівні, чи, принаймні, їхні величини точно фіксуються. Однак, крім відомих факторів, на величину, що спостерігається, впливають невідомі спостерігачу фактори, що їм не фіксуються і не контролюються. Це є причиною розкиду значень величини, що спостерігається, у рівнобіжних спостереженнях.
Будь-яку випадкову величину А можна представити у виді:
А = ( + (
a - щире значення величини, що спостерігається
e - випадкова складова, обумовленою дією неврахованих факторів.
Вивченням випадкових величин, одержуваних у результаті спостережень, займається наука математична статистика.
Співвідношення між a і e може служити мірою інформації про систему, у якій виробляється спостереження: чим більше e у порівнянні з a, тим вище невизначеність системи (тим більше неврахованих невідомих факторів впливає на величину, що спостерігається,).
Виходячи з цього, конкретне значення величини, що спостерігається, в окремому спостереженні непередбачено. Однак, якщо проводити багаторазові рівнобіжні спостереження в тих самих умовах, можна одержати стійкі (тобто, що мало залежать від кількості спостережень) характеристики випадкової величини:
- математичне чекання:
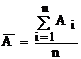
- дисперсію
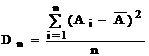
n – кількість спостережень.
Набір з n значень випадкової величини називається вибіркою.
У математичній статистиці доводиться, що величина математичного чекання (середнє арифметичне) служить оцінкою для щирого значення випадкової величини, що спостерігається. При n®¥ ця величина збігається з щирою величиною.
Дисперсія є мірою розкиду значень випадкової величини щодо середнього значення (математичного чекання). У статистичних розрахунках використовують не тільки дисперсію Dn, що називається невиправленою дисперсією, але, також, виправлену дисперсію Dn-1:
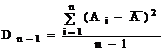
Виправлена дисперсія точніше передає розбору щодо середнього в малих вибірках
Поряд з дисперсією, як міру відхилення від середнього, використовують среднеквадратическое відхилення(виправлене чи невиправлене):
![]()
![]()
Зручність середньоквадратичного відхилення – у тім, що для розмірних випадкових величин [W1] воно виміряється в тих же одиницях, що сама випадкова величина, у той час, як дисперсія – у відповідних квадратних одиницях
5.4.2 Перевірка статистичних гіпотез. Довірчі інтервали.
Загальне правило роботи з випадковими величинами: усі судження про випадкові величини носять вероятностный характер, тобто, супроводжуються часткою ризику. Ця частка ризику, називана довірчою імовірністю, задається заздалегідь і характеризує імовірність того, що висловлене Вами судження щодо випадкової величини є помилковим.
Звичайно в статистичних розрахунках застосовують рівень значимості (=0,05. Тобто, у середньому, помилку можна допустити в одному випадку з 20
Судження, висловлювані про випадкові величини (їхніх значеннях у порівнянні з іншими чи величинами законах їхні розподіли) називаються статистичними гіпотезами, а встановлення їх выполнимости з заданою часткою ризику зветься перевірки статистичних гіпотез.
Особливістю статистичних гіпотез є те, що судженню, що перевіряється, (нульовій гіпотезі) обов'язково протиставляється альтернативне судження. Наприклад, якщо ми перевіряємо нульову гіпотезу «Випадкове число А=5», те цьому судженню може бути 3 альтернативи:
1.А>5
2.A<5
3.А не дорівнює 5
У залежності, від того, яка з цих альтернатив обрана, при заданому рівні значимості можна одержати різні результати про виконання нульової гіпотези.
Перевірка статистичних гіпотез полягає в побудові з випадкової величини, що перевіряється, деякої іншої випадкової величини, для якої відомий закон розподілу імовірностей. Виходячи з відомого закону розподілу, можна визначити, з якою імовірністю з'явилася б розрахована величина, якби була вірна перевіря не, а альтернативна гіпотеза. При цьому значення, що перевіряється, з'явилося б чисто випадково. Знайдена в такий спосіб імовірність називається критичної. Якщо критична імовірність менше довірчої – ми приймаємо нульову (тобто, що перевіряється гіпотезу). У противному випадку гіпотеза, що перевіряється, відкидається. Другий варіант перевірки – по заданій довірчій імовірності розрахувати критичне значення самої випадкової величини, якби була вірна альтернативна гіпотеза. Якщо розрахункове значення величини менше критичного – приймається основна гіпотеза, у противному випадку – альтернативна. Приклади розрахунків – у розділах
«Установлення значимості коефіцієнта кореляції»
«Установлення значимості рівняння регресії»
«Установлення значимості коефіцієнтів регресії»
Для перевірки статистичних гіпотез застосовують обоє описаних способу, причому, другий – частіше.
Знайшовши критичне значення випадкової величини, можна побудувати довірчий інтервал – інтервал, усередині якого знаходиться щире значення випадкової величини з імовірністю 1-a. Приклад розрахунку – у розділі «Расчет характеристик выборки в среде Excel»
5.4.3. Розрахунок характеристик вибірки в середовищі Excel»
Задача:
По заданій вибірці визначити математичне чекання (середнє арифметичне), виправлені дисперсію і среднеквадратическое відхилення. Побудувати доверительный интервал довірчийарифметичного з надійністю 1-a=0,95
Вихідна вибірка
N | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
X | 2,89 | 1,00 | 1,80 | 1,59 | 0,11 | 3,00 | 2,49 | 1,40 | 0,99 |
Задачу розрахунку середнього і дисперсії можна вирішити двома методами: «вручную» і с использованием статистических функций.
1.Рішення вручну
А. Спочатку будується таблиця значень Х
Б. У нижньому осередку виробляється підсумовування (натискання клавіш Alt - +)
М. Розраховується середнє розподілом суми на число елементів вибірки
Д. Пристроюємо до таблиці графи «Різниці» і «квадрати разностей»
Е. У перших клітках нових граф створюємо формули осередку для розрахунку разностей Х-Хср і їхніх квадратів. У формулі осередку закріплюємо значення Хср за допомогою знака $.
Ж. Виділяємо отримані значення і протягаємо їх по всій таблиці
З. Розраховуємо суму квадратів відхилень і дисперсію. Витягаючи корінь – розраховуємо середньоквадратичне відхилення.
Приклад розрахунку розглянутий у таблиці 3.1
2. Розрахунок за допомогою статистичних функцій.
Розрахунок середнього.
- виділяємо осередок, у якій буде результат
- натискаємо кнопку f(x) на панелі інструментів
- вибираємо в меню Статистичні функції

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
