
- вибираємо серед статистичних функцій СРЗНАЧА
- відповідно до вказівок – виділяємо діапазон Х, натискаємо ОК, одержуємо в осередку результат-
Аналогічно проводяться розрахунки виправленої дисперсії (функція ДИСПА) і середньоквадратичного відхилення (функція СТАНДОТКЛОНА). Результати приведені в таблиці 3.1.
Побудова довірчого інтервалу
Довірчий інтервал будується симетрично щодо середнього арифметичних ![]() . У математичній статистиці показано, що симетричний довірчий інтервал, у якому з імовірністю 1-a знаходиться n - щире значення випадкової величини xi (середнє генеральної сукупності[W2] ) для вибірок невеликого обсягу n (n<50) визначається нерівністю
. У математичній статистиці показано, що симетричний довірчий інтервал, у якому з імовірністю 1-a знаходиться n - щире значення випадкової величини xi (середнє генеральної сукупності[W2] ) для вибірок невеликого обсягу n (n<50) визначається нерівністю
![]()
s - виправлене среднеквадратическое відхилення
tq – критичне значення розподілу Стьюдента (критерію Стьюдента) для заданого рівня значимості a і числі ступенів волі [W3] k=n-1.
Таблиця 3.1.[W4]
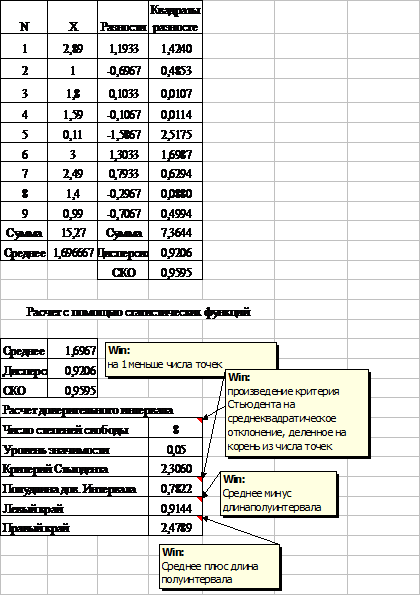
Число ступенів волі випадкової величини визначається, як число значень цієї величини мінус число параметрів, обумовлених з цієї величини. З вибірки визначається один параметр – середнє арифметичне, тому, з числа крапок віднімається 1
Для практичних розрахунків у середовищі Excel критичне значення розподіл Стьюдента можна знайти в розділі «Статистичні функції» (СТЬЮДРАСПОБР). Ввівши в роботу цю функцію, Ви повинні задати рівень значимості (імовірність () і число ступенів волі, що на 1 менше числа крапок. Приклад розрахунку – у таблиці 3.1.
5.4 Зв'язані вибірки. Коефіцієнт кореляції
Часто виникає ситуація, коли потрібно перевірити, як впливає деяка величина Х на випадкову величину Y (наприклад, як впливає концентрація реагенту на швидкість реакції). Для цього проводять спостереження величини Y при різних значеннях Х. Відзначимо, що величина Х не є випадкової, вона може бути змінена і зафіксована за бажанням спостерігача. Ця величина називається фактором. Величина Y є випадковою величиною і називається відгуком.
Ми можемо розглядати Х и Y як зв'язані вибірки. Їхні значення задаються парами {xi, yi}, звичайно, у виді таблиць. Кожну з вибірок значень Х и Y можна обробити порізно, розраховуючи для них середнє арифметичне і среднеквадратическое (невиправлене) відхилення:
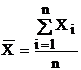
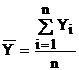
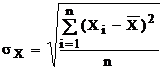
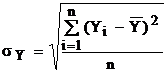
Для оцінки сили взаємодії між Y і Х розраховується коефіцієнт кореляції rXY (його ще називають коефіцієнтом парної кореляції)
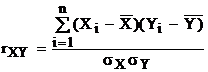
Коефіцієнт парної кореляції характеризує силу залежності між Y і Х
Властивості коефіцієнта кореляції
1.Коефіцієнт кореляції може змінюватися в інтервалі від –1 до 1
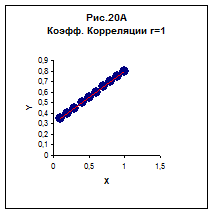
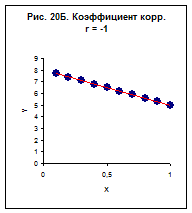
2.Якщо коефіцієнт кореляції дорівнює 1 чи –1 – це свідчить, що всі крапки залежності Y(X) ідеально лежать на прямої (рис 20А, Б)
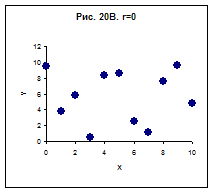
3.Якщо коефіцієнт кореляції дорівнює нулю – на графіку залежності Y від Х усі крапки лежать хаотично, між відгуком і фактором немає ніякого зв'язку (Рис. 20 В)
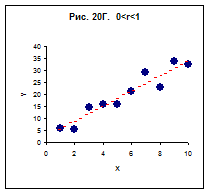
4.У проміжному випадку крапки групуються навколо деякої прямої(Рис. 20М). Тобто, між фактором і відгуком є деякий зв'язок, ускладнена дією випадкових причин.
Позитивна величина коефіцієнта кореляції свідчить, що зі збільшенням значення фактора значення відгуку, у середньому, зростає. Зростання в середньому говорить про тенденцію у всій сукупності крапок. При цьому, для окремих крапок можливе порушення тенденції
|
|
|
|
5.[W5] Негативна величина коефіцієнта кореляції свідчить, що значення відгуку, у середньому, убуває зі зростанням значення фактора
Таким чином, величина коефіцієнта кореляції свідчить про характер і силу впливу X на Y і про силу лінійної залежності між ними
Поряд з коефіцієнтом кореляції для характеристики зв'язку між вибірками використовують коефіцієнт детермінації, що представляє собою квадрат коефіцієнта кореляції.
R2=(rXY)2
Коефіцієнт детермінації вказує, яку частку в загальну суму квадратів відхилень щодо середнього 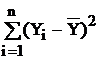 вносить сума квадратів, обумовлена лінійною залежністю між Y і Х.
вносить сума квадратів, обумовлена лінійною залежністю між Y і Х.
Перевірка значимості коефіцієнта кореляції
Оскільки коефіцієнт кореляції обчислюється, виходячи з випадкових значень відгуку, він сам є величиною випадкової.
При розрахунках коефіцієнта кореляції, особливо, якщо його значення невелике по абсолютній величині, виникає питання, наскільки значиме цей коефіцієнт, тобто, наскільки істотно він відрізняється від нуля. Іншими словами потрібно визначити, який ризик того, що, при відсутності залежності між X і Y, випадково відібрана сукупність обмеженого числа крапок групується в тім чи іншому ступені уздовж деякої прямої.
Для встановлення значимості коефіцієнта кореляції перевіряють статистичну гіпотезу r=0 при конкуруючій (альтернативної) гіпотезі r¹0.
1.Обчислюють випадкову величину:
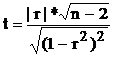
У статистику доводиться, що ця випадкова величина має розподіл Стьюдента
2.Знаходять з розподілу Стьюдента критичне значення tq(a, n-2) по заданому рівні значимості і числу крапок.
3.Якщо t< tq – коефіцієнт кореляції незначимий відрізняється від нуля (відмінності від 0 з імовірністю 1-a можуть бути приписані дії випадкових причин). У противному випадку коефіцієнт кореляції значимо.
По техніці виконання перевірка – така ж, як описана в розділі 3. Расчет характеристик выборки в среде Excel
6. Розрахунок коефіцієнтів кореляції в середовищі Excel
Розрахунок можна робити вручну, шляхом побудови таблиць і розрахунків середніх і среднеквадратических відхилень. Для зручності роботи до складу статистичних функцій Excel внесена функція КОРРЕЛ, що розраховує коефіцієнт кореляції.
Для розрахунку коефіцієнта кореляції з використанням цієї функції необхідно:
1.Побудувати таблиці значень Х и Y
2.Виділити осередок, у якій буде поміщений коефіцієнт кореляції.
3.На панелі інструментів натиснути кнопку f(x)
4.Викликати з меню статистичні функції
5.З меню статистичних функцій вибрати КОРРЕЛ
6.У меню функції КОРРЕЛ – натиснути на кольорову кнопку біля віконця з написом «Масив 1»
7.За допомогою миші виділити в таблиці дані значення Х
8.Натиснути на кольорову кнопку віконця, знову очутитися в меню КОРРЕЛ
9.У меню функції КОРРЕЛ – натиснути на кольорову кнопку біля віконця з написом «Масив 2»
10. За допомогою миші виділити в таблиці дані значення Y
11. Натиснути на кольорову кнопку віконця, знову очутитися в меню КОРРЕЛ
12. Натиснути кнопку ОК. Меню КОРРЕЛ зникне, у виділеному осередку з'явиться шукане значення коефіцієнта кореляції.
5.6 Проста лінійна регресія
Установивши наявність кореляційного зв'язку (розрахувавши коефіцієнт кореляції і переконавши в його значимості) можна вирішити задачу перебування лінійної залежності, що проходить через дану сукупність крапок деяким щонайкраще. Для рішення цієї задачі використовується метод найменших квадратів. Постановка задачі: задана сукупність з n крапок {x1,y1},{x2,y2},…{xn, yn}... Потрібно побудувати пряму, що проходить через ці крапки, тобто, коефіцієнти а0,а1 рівняння прямої y = a0 + a1x
Цю задачу можна вирішити однозначно, якщо шукати коефіцієнти а0,а1 такими, щоб зробити мінімальної суму квадратів відхилень по всіх крапках між заданими значеннями y і значеннями y, що лежать на розрахунковій прямій
Математично ця задача формулюється в такий спосіб:
![]()
У крапці мінімуму частки похідні ![]() і
і ![]() дорівнюють нулю:
дорівнюють нулю:
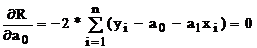
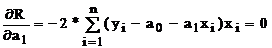
Групуючи члени, одержуємо систему лінійних алгебраїчних рівнянь із двома невідомими:
![]()
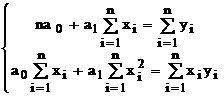
Розрахувавши всі суми і вирішивши цю систему, можна знайти коефіцієнти прямої, тобто, побудувати задану пряму на сукупності крапок.
Рівняння прямої, побудоване методом найменших квадратів, називається рівнянням регресії (простої лінійної регресії).
У середовищі Excel для побудови рівняння регресії маються статистичні функції ВІДРІЗОК і НАХИЛ.
Для перебування коефіцієнтів регресії спочатку будується таблиця значень x і y. Для розрахунку коефіцієнта а0:
1.Виділяємо осередок, у якій буде значення коефіцієнта а0
2.Викликаємо функцію ВІДРІЗОК, що знаходиться серед статистичних функцій.
3.Виділяємо осередок, у якій буде значення коефіцієнта а0
4.У меню цієї функції – натискаємо кольорову кнопку біля вікна з написом Изв_знач_y
5.Виділяємо стовпець значень y, натисканням кольорової кнопки повертаємося в меню функції ВІДРІЗОК
6.У меню цієї функції – натискаємо кольорову кнопку біля вікна з написом Изв_знач_х
7.Виділяємо стовпець значень х, натисканням кольорової кнопки повертаємося в меню функції ВІДРІЗОК
8.Натискаємо кнопку ОК. У виділеному осередку з'являється значення коефіцієнта а0
Аналогічно, шляхом виклику статистичної функції НАХИЛ, розраховується коефіцієнт а1
5.7 Дослідження рівняння регресії
Лінію регресії можна провести через будь-яку сукупність крапок, у тому числі, через крапки з нульовим коефіцієнтом кореляції. Тому після розрахунку коефіцієнтів регресії варто провести дослідження рівняння регресії з метою з'ясування значимості цього рівняння, а також – коефіцієнтів регресії.
8.1. Установлення значимості рівняння регресії.
Найпростіша модель явища може бути побудована в припущенні, що на нього не впливають ніякі фактори, тобто, вона має вид:
![]()
Використовуючи лінійну регресійну модель Y = A0 + A1*X, ми ускладнюємо картину, уводячи 2 параметри (А0 і А1) замість одного (Ycp). Установлення значимості моделі означає перевірку, наскільки істотно на якості моделі позначається це ускладнення. Якщо модель незначима – ускладнення не має змісту.
Порівняння засноване на теоремі розкладання залишкової суми квадратів щодо середнього:
![]()
Yвi – значення відгуку, розраховане по рівнянню регресії в i-й крапці.
Перша сума (SSост) зветься залишкової суми квадратів (суми квадратів відхилень, обумовлених регресією), друга – сумою квадратів щодо регресії (SSотн). Кожне з приведених доданків має своє число ступенів волі:
Складова | Позначення | Число ступенів волі | Дисперсія |
|
| n-1 |
|
|
| n-2 |
|
|
| 1 |
|
Розділивши кожну із сум на число її ступенів волі, відповідно, одержимо загальну дисперсію, залишкову дисперсію і дисперсію щодо регресії.
Сутність установлення значимості рівняння регресії полягає в перевірці гіпотезу про рівність (однорідності) двох дисперсій – дисперсії щодо регресії і залишкової дисперсії. Для цього розраховуємо так називане F-відношення – відношення більшої дисперсії до меншого (у нашому випадку – дисперсії щодо регресії до залишкової дисперсії):
![]()
Ця випадкова величина має розподіл імовірностей, називаний розподілом Фишера чи F-розподілом, що залежить від рівня значимості, а також, числа ступенів волі більшої і меншої дисперсії. У Excel можна реалізувати 2 типи перевірки: розрахувати імовірність того, то при даному F – відношенні дисперсії однакові (при заданих числах ступенів волі). Це робиться за допомогою статистичної функції FРАСПР. Якщо ця імовірність виявляється менше довірчої імовірності – гіпотеза рівності дисперсій відкидається, приймається, що рівняння регресії значиме. У противному випадку регресія незначима (розкид у даних слабко змінився в порівнянні з найпростішою моделлю).
Друга можливість – за заданим значенням числа ступенів волі і довірчої інформації розрахувати критичне значення F, вище якого гіпотеза рівності дисперсій відкидається. Це робиться за допомогою функції FРАСПА. Виклик цих функцій – такої ж, як критерію Стьюдента.
Перевірка значимості коефіцієнтів регресії
Значимість коефіцієнтів регресії означає встановлення, значиме чи ні вони відрізняються від нуля.
Коефіцієнти регресії – випадкові величини, що мають розподіл Стьюдента.
Для перевірки значимості для кожного коефіцієнта обчислюють відношення
![]()
![]() - среднеквадратическое відхилення коефіцієнта Аі
- среднеквадратическое відхилення коефіцієнта Аі
Перевірку значимості проводять також, як при проверке значимости коэффициента корреляции
Якщо коефіцієнт регресії незначимо – його можна дорівняти до нуля і перерахувати дані для більш простої моделі.
Розрахунок среднеквадратических відхилень коефіцієнтів проводять по формулах:
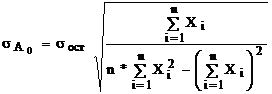
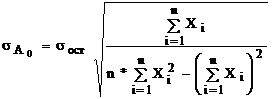
![]() - залишкове среднеквадратическое відхилення
- залишкове среднеквадратическое відхилення
9. Прогноз і довірчий інтервал прогнозу
Після розрахунку і дослідження рівняння регресії, у випадку його значимості, можна перейти до використання цього рівняння для прогнозування. Для цього треба підставити в рівняння регресії значення фактора, для якого проводиться прогноз (Х0) і розрахувати прогноз Y0
Y0=A0 + A1*X0
Оскільки прогнозне значення – випадкова величина, необхідно оцінити границі інтервалу, у яких знаходиться прогноз з визначеною імовірністю, тобто, побудувати довірчий інтервал прогнозу. Для прогнозованого значення Y0 напівширину довірчого інтервалу в крапці Х0
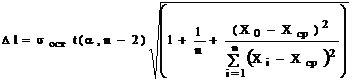
Тоді, щире значениеY з імовірністю 1-a буде знаходиться між Y-Dl і Y+Dl
[W1]То есть, величин, которые измеряются в каких-то единицах (килограммах, штуках, метрах)
[W2]Полный, в том числе – бесконечный набор всех возможных значений случайной величины называется генеральной совокупностью. В математической статистике истинное значение случайной величины – это математическое ожидание генеральной совокупности, то есть, ее наиболее вероятное значение.
[W3] Число степеней свободы случайной величины определяется, как число значений этой величины минус число параметров, определяемых из этой величины. Из выборки определяется один параметр – среднее арифметическое, поэтому, из числа точек вычитается 1
[W4]Для перевода таблицы в формат Excel установите курсор на таблицу и дважды щелкните левой кнопкой мыши. Для просмотра таблицы используйте горизонтальную и вертикальную полосы прокрутки. Разберитесь, как составлены формулы ячейки. Для выхода из таблицы – установите курсор на текст и щелкните правой кнопкой мыши
[W5]Возрастание в среднем говорит о тенденции во всей совокупности точек. При этом, для отдельных точек возможно нарушение тенденции

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
