

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
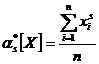 (7.4.4)
(7.4.4)
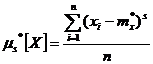 (7.4.5)
(7.4.5)
Все эти определения полностью аналогичны данным в главе 5 определениям числовых 'характеристик случайной величины, с той разницей, что в них везде вместо математического ожидания фигурирует среднее арифметическое. При увеличении числа наблюдений, очевидно, все статистические характеристики будут сходиться по вероятности к соответствующим математическим характеристикам и при достаточном n могут быть приняты приближенно равными им.
Нетрудно доказать, что для статистических начальных и центральных моментов справедливы те же свойства, которые были выведены в главе 5 для математических моментов. В частности, статистический первый. центральный момент всегда равен нулю:
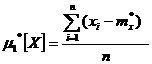 =
=![]() - m*x = m*x - m*x = 0
- m*x = m*x - m*x = 0
Соотношения между центральными и начальными моментами также сохраняются:
 =
=![]() - 2m*x
- 2m*x![]() +(m*x)2=α*2 - (m*x)2
+(m*x)2=α*2 - (m*x)2
и т. д.
При очень большом количестве опытов вычисление характеристик,10 формулам (7.4.1) — (7.4.5) становится чрезмерно громоздким, и можно применить следующий прием: воспользоваться теми же ^разрядами, на которые был расклассифицирован статистический материал для построения статистического ряда или гистограммы, и считать приближенно значение случайной величины в каждом разряде Постоянным и равным среднему значению, которое выступает в роли «представителя» разряда. Тогда статистические числовые характеристики будут выражаться приближенными формулами:
m*x = M*[X] = ![]() , (7.4.7)
, (7.4.7)
D*x = D* [X] =![]() , (7.4.8)
, (7.4.8)
![]() =
= ![]() (7.4.9)
(7.4.9)
![]()
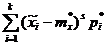 (7.4.10)
(7.4.10)
где xt — «представитель» 1-го разряда, р* — частота 1-го разряда, k — число разрядов.
Как видно, формулы (7.4.7) — (7.4.10) полностью аналогичны формулам п°п° 5.6 и 5.7, определяющим математическое ожидание, дисперсию, начальные и центральные моменты прерывной случайной
величины X, с той только разницей, что вместо вероятностей р{ в них стоят частоты р*, вместо математического ожидания тх — статистическое среднее тх*, вместо числа возможных значений случайной величины — число разрядов.
В большинстве руководств по теории вероятностей и математической статистике при рассмотрении вопроса о статистических аналогиях для характеристик случайных величин применяется терминология, несколько отличная от принятой в настоящей книге, а именно, статистическое среднее именуется «выборочным средним», статистическая дисперсия—«выборочной дисперсией» и т. д. Происхождение этих терминов следующее. В статистике, особенно сельскохозяйственной и биологической, часто приходится исследовать распределение того или иного признака для весьма большой совокупности индивидуумов, образующих статистический коллектив (таким признаком может быть, например, содержание белка в зерне пшеницы, вес того же зерна, длина или вес тела какого-либо из группы животных и т. д.). Данный признак является случайной величиной, значение которой от индивидуума к индивидууму меняется. Однако, для того, чтобы составить представление о распределении этой случайной величины или о ее важнейших характеристиках, нет необходимости обследовать каждый индивидуум данной обширной совокупности; можно обследовать некоторую выборку достаточно большого объема для того, чтобы в ней были выявлены существенные черты изучаемого распределения. Та обширная совокупность, из которой производится выборка, носит в статистике название генеральной совокупности. При этом предполагается, что число членов (индивидуумов) N в генеральной совокупности весьма велико, а число членов п в выборке ограничено. При достаточно большом N оказывается, что свойства выборочных/статистических) распределений и характеристик практически не зависят от N; отсюда естественно вытекает математическая идеализация, состоящая в том, что генеральная совокупность, из которой осуществляется выбор, имеет 'бесконечный объем. При этом отличают точные характеристики (закон распределения, математическое ожидание, дисперсию и т. д.), относящиеся к генеральной совокупности, от аналогичных им «выборочных» характеристик. Выборочные характеристики отличаются от соответствующих характеристик генеральной совокупности за счет ограниченности объема выборки n; при неограниченном увеличении а, естественно, все выборочные характеристики приближаются (сходятся по вероятности) к соответствующим характеристикам генеральной совокупности. Часто возникает вопрос о том, каков должен быть объем выборки п для того, чтобы по выборочным характеристикам можно было с достаточной точностью судить о неизвестных характеристиках генеральной совокупности или о том, с какой степенью точности при заданном объеме выборки можно судить о характеристиках генеральной совокупности. Такой методический прием, состоящий в параллельном рассмотрении бесконечной генеральной совокупности, из которой осуществляется выбор, и ограниченной по объему выборки, является совершенно естественным в тех областях статистики, где фактически приходится осуществлять выбор из весьма многочисленных совокупностей индивидуумов. Для практических задач, связанных с вопросами стрельбы и вооружения, гораздо более характерно другое положение, когда над исследуемой случайной величиной (или системой случайных величин) производится ограниченное число опалов с целью определить те или иные характеристики этой величины, например, когда с целью исследования закона рассеивания при стрельбе производится некоторое количество выстрелов, или с целью исследования ошибки наводки производится серия опытов, в каждом из которых ошибка наводки регистрируется с помощью фотопулемета, и т. д. При этом ограниченное число опытов связано не с трудностью регистрации и обработки, а со сложностью и дороговизной каждого отдельного опыта. В этом случае с известной натяжкой можно также произведённые n опытов мысленно рассматривать как «выборку» из некоторой чисто условной «генеральной совокупности», состоящей из бесконечного числа возможных или мыслимых опытов, которые можно было бы произвести в данных условиях. Однако искусственное введение такой гипотетической «генеральной совокупности»! при данной постановке вопроса не вызвано необходимостью и вносит в рассмотрение вопроса, по существу, излишний элемент идеализации, не вытекающий из непосредственной реальности задачи.
Поэтому мы в данном курсе не пользуемся терминами «выборочное среднее», «выборочная дисперсия», «выборочные характеристики» и т. д., заменяя их терминами «статистическое среднее», «статистическая дисперсия», «статистические характеристики».
2.5. Выравнивание статистических рядов
Во всяком статистическом распределении неизбежно присутствуют элементы случайности, связанные с тем, что число наблюдений ограничено, что произведены именно те, а не другие опыты, давшие именно те, а не другие результаты. Только при очень большом числе наблюдений эти элементы случайности сглаживаются, и случайное явление обнаруживает в полной мере присущую ему закономерность. На практике мы почти никогда не имеем дела с таким большим числом наблюдений и вынуждены считаться с тем, что любому статистическому распределению свойственны в большей или меньшей, мере черты случайности. Поэтому при обработке статистического материала часто приходится решать вопрос о том, как подобрать для данного статистического ряда теоретическую кривую распределения, выражающую лишь существенные черты статистического материала, но не случайности, связанные с недостаточным объемом экспериментальных данных. Такая задача называется задачей выравнивания (сглаживания) статистических рядов.
Задача выравнивания заключается в том, чтобы подобрать теоретическую плавную кривую распределения, с той или иной точки зрения наилучшим образом описывающую данное статистическое распределение (рис. 7.5.1).
Задача о наилучшем выравнивании статистических рядов, как и вообще задача о наилучшем аналитическом представлении эмпирических функций, есть задача в значительной мере неопределенная, t и решение ее зависит от того, что условиться считать «наилучшим». Например, при сглаживании эмпирических зависимостей очень часто исходят из так называемого принципа или метода наименьших квадратов (см. п° 14.5), считая, что наилучшим приближением к эмпирической зависимости в данном классе функций является такое, при котором сумма квадратов отклонений обращается в минимум. При этом вопрос о том, в каком именно классе функций следует искать наилучшее приближение, решается уже не из математических соображений, а из соображений, связанных с физикой решаемой задач»} с учетом характера полученной эмпирической кривой и степени точности произведенных наблюдений. Часто принципиальный характер функции, выражающей исследуемую зависимость, известен заранее из теоретических соображений, из опыта же требуется получить лишь некоторые численные параметры, входящие в выражение функции; именно эти параметры подбираются с помощью метода наименьших квадратов.
Аналогично обстоит дело и с задачей выравнивания статистических рядов. Как правило, принципиальный вид теоретической кривой выбирается заранее из соображений, связанных с существом задачи,

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
