
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Литература. , «Модифицированный алгоритм построения многомерной полиномиальной регрессии по избыточному описанию»
Вестник НТУУ «ХПИ» « Системный анализ, управление и информационные технологии» - принято к печати 31.01.2012г. (г. Харьков)
Обобщения
1. Очевидно, что полученные результаты применимы для случая, когда выражение (6.19) вместо переменных 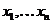 содержит переменные
содержит переменные ![]() ,
, ![]() , где
, где 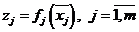 , и компонентами векторов
, и компонентами векторов ![]() являются компоненты вектора
являются компоненты вектора ![]() , а также множества компонент векторов
, а также множества компонент векторов 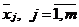 , не пересекаются;
, не пересекаются; ![]() – непрерывные функции, ограниченные при ограниченных значениях своих аргументов.
– непрерывные функции, ограниченные при ограниченных значениях своих аргументов.
2. Задача построения многомерной регрессии очевидным образом обобщается на случай, когда при построении одномерных регрессий на модель действуют разные случайные величины ![]() (
(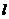 – номер одномерной регрессии),
– номер одномерной регрессии), ![]()
![]() В общем виде распределения случайных величин
В общем виде распределения случайных величин ![]() (при фиксированном
(при фиксированном ![]() ) могут не совпадать между собой. Анализ формул (6.9), (6.10), (6.18) показывает, что при построении одномерных регрессий в экспериментах на регрессионную модель аддитивно могут воздействовать независимые случайные величины
) могут не совпадать между собой. Анализ формул (6.9), (6.10), (6.18) показывает, что при построении одномерных регрессий в экспериментах на регрессионную модель аддитивно могут воздействовать независимые случайные величины ![]() с различными распределениями, имеющие нулевые математические ожидания и одинаковые дисперсии, для фиксированного . Для разных дисперсии
с различными распределениями, имеющие нулевые математические ожидания и одинаковые дисперсии, для фиксированного . Для разных дисперсии ![]() могут быть различными.
могут быть различными.
6.1.3 Примеры
Пример 1 (одномерная регрессия)
Истинная модель имеет вид
![]() (6.25)
(6.25)
Регрессионная модель всегда должна задаваться избыточной. В нашем примере исследователь знает, что регрессионная модель является полиномом не выше пятой степени. Случайная величина Е имеет нулевое математическое ожидание, равномерное распределение, 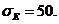 Входные значения
Входные значения ![]() равномерно распределены по отрезку (–50, 50) с шагом
равномерно распределены по отрезку (–50, 50) с шагом ![]() .
.
Имитируются эксперименты с помощью реализаций случайной величины Е. Исходные данные 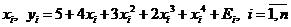 ;
; ![]() – реализация случайной величины Е.
– реализация случайной величины Е.
Для генерации случайных чисел использована часть библиотеки расширений для C++ boost – http://www. boost. org/doc/libs/1_36_0/libs/random/index. html.
Для восстановления зависимости (6.25), по формуле (6.8) строятся 6 нормированных ортогональных полиномов, а по формуле (6.15) оценки коэффициентов в линии регрессии (6.18). Результаты эксперимента показаны ниже.
Одномерная регрессия, равномерное распределение ![]() . Исходные коэффициенты: (5,4,3,2,1,0); цифра в квадратных скобках – это количество чисел в круглых скобках.
. Исходные коэффициенты: (5,4,3,2,1,0); цифра в квадратных скобках – это количество чисел в круглых скобках.
Количество испытаний . Ортогональные полиномы:
[1] (0,316228)
[2] (0,0550482, 0,0110096)
[3] (–0,348155, 0,00435194, 0,000435194)
[4] (–0,12955, –0,0250104, 0,000269896, 1,79931·10–5)
[5] (0,336581, –0,0155824, –0,00148033, 1,55824·10–5, 7,79122·10–7)
[6] (0,214834, 0,0384315, –0,00134272, –8,35467·10–5, 8,95144·10–7, 3,58057·10–8)
Оценки коэффициентов:
[6] (8,21467, 4,40095, 2,99323, 1,99954, 1,1,00514·10–7)
Дисперсии коэффициентов:
[6] (1001,17, 6,21366, 0,0106413, 1,88666·10–5, 3,52078·10–9, 3,20513·10–12)
Количество испытаний . Ортогональные полиномы:
[1] (0,141421)
[2] (0,00489996, 0,00489996)
[3] (–0,158019, 0,000379853, 0,000189927)
[4] (–0,0112385, –0,0112235, 2,2513·10–5,7,50433·10–6)
[5] (0,15878, –0,00127706, –0,000637333, 1,19511·10–6, 2,98776·10–7)
[6] (0,0176422, 0,0175761, –9,91938·10–5, –3,29849·10–5, 5,97553·10–8, 1,19511·10–8)
Оценки коэффициентов:
[6] (5,15354, 3,91832, 3,00231, 2,00013, 0,999999, –3,05835·10–8)
Дисперсии коэффициентов:
[6] (176,607, 1,15167, 0,00113153, 2,86437·10–6, 2,32095·10–10, 3,57069·10–13)
В табл. 6.2 приведены оценки коэффициентов (точное значение которых равно 5, 4, 3, 2, 1, 0 соответственно) для числа испытаний 10; 50; 100; 200; 300; 500; 1000; 5000; 10000.
Таблица 6.2 – Оценки коэффициентов
n | θ0=5 | θ1=4 | θ2=3 | θ3=2 | θ4=1 | θ5=0 |
10 | 8,21467 | 4,40095 | 2,99323 | 1,99954 | 1 | 1,1005×10–7 |
50 | 5,15354 | 3,91832 | 3,00231 | 2,00013 | 0,999999 | –3,05835×10–8 |
100 | 4,13942 | 3,92085 | 3,00063 | 2,00003 | 0,999999 | 1,21093×10–8 |
200 | 4,5745 | 3,92143 | 3,00406 | 2,00005 | 0,999999 | –2,61741×10–9 |
300 | 5,39774 | 3,89625 | 2,99871 | 2,00013 | 1 | –3,14599×10–8 |
500 | 5,23945 | 4,03909 | 3,00081 | 1,99996 | 1 | 11189×10–8 |
1000 | 4,8637 | 4,00444 | 2,99924 | 2 | 1 | –3,30327×10–9 |
5000 | 5,20518 | 4,01987 | 2,99942 | 1,99997 | 1 | 5823×10–9 |
10000 | 4,95045 | 3,98802 | 3,0003 | 2,00002 | 1 | –8,36543×10–9 |
Из таблицы 6.2 видно, что для числа испытаний ![]() погрешность оценки коэффициентов не превышает: для
погрешность оценки коэффициентов не превышает: для 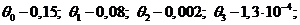
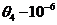 ;
; 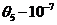 .
.
Таким образом, в результате моделирования достаточного количества испытаний можно создать статистические таблицы, каждая из которых составлена для фиксированных концов отрезка принадлежности аргумента ![]() и содержит для ряда статистически обоснованных вероятностей значения погрешностей нахождения коэффициентов
и содержит для ряда статистически обоснованных вероятностей значения погрешностей нахождения коэффициентов 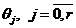 (зависящих от
(зависящих от ![]() или ее верхней оценки
или ее верхней оценки ![]() ) для различного количества испытаний.
) для различного количества испытаний.
Такие таблицы позволят заранее определить минимально необходимое число испытаний, для которых оценки коэффициентов ![]() (кроме, возможно,
(кроме, возможно, ![]() ) находятся с приемлемой для практики точностью.
) находятся с приемлемой для практики точностью.
Примечание. Очевидно, чем больше длина интервала изменений аргумента х, тем меньше минимально необходимое число испытаний.
Пример 2 (многомерная регрессия)
Исходная модель линии регрессии задается в виде избыточного полинома:
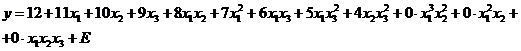 (6.26)
(6.26)
Обозначим через ![]() коэффициенты линии регрессии, которые считаются неизвестными.
коэффициенты линии регрессии, которые считаются неизвестными.
![]() – случайная величина, имеющая нормальное распределение
– случайная величина, имеющая нормальное распределение 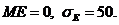
В этом примере 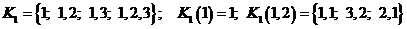 ;
; ![]()
![]() Аналогично определяются все
Аналогично определяются все 

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
