


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
}
void CStack::Push(int a)
{
CItem * it = new(CItem); //нельзя писать CItem it;
it->el = a;
it->next = first;
first = it;
}
int CStack::Pop(void)
{
int a = first->el;
first = first->next;
return a;
}
int CStack::Get(void)
{
return first->el;
}
void CStack::Show(void)
{
CItem *it = first;
while (it) //!=NULL
{
cout << (it->el) << " ";
it = it->next;
}
}
// mystack. cpp
--------------
#include "stdafx. h"
#include "stack. h"
#include <iostream. h>
int main(int argc, char* argv[])
{
CStack s;
s. Push(10);
s. Push(20);
s. Push(30);
s. Push(40);
s. Show();
int i;
cin >> i;
return 0;
}
Недостатки:
1) элементом стека является int. Другие типы нельзя поместить в стек.
2) Если попытаться извлечь элемент из пустого стека, то произойдет ошибка и программа завершит работу.
Для того, чтобы убрать первый недостаток необходимо использовать шаблоны классов.
Обратите внимание, что реализация функций-шаблонов делается в *.h-файле.
stack. h
--------
#ifndef __STACK_H__
#define __STACK_H__
#include <iostream. h>
template <class TE>
class CItem
{
public:
TE el;
CItem * next;
};
template <class TE>
class CStack
{
CItem <TE>* first;
public:
CStack(void);
void Push(TE a);
TE Pop(void);
TE Get(void);
void Show(void);
};
template <class TE>
CStack<TE>::CStack(void)
{
first = NULL;
}
template <class TE>
void CStack<TE>::Push(TE a)
{
CItem <TE> * it = new(CItem<TE>);
it->el = a;
it->next = first;
first = it;
}
template <class TE>
TE CStack<TE>::Pop(void)
{
//если first ==NULL, то ошибка
if (first == NULL) throw "Стек пуст";
TE a = first->el;
first = first->next;
return a;
}
template <class TE>
TE CStack<TE>::Get(void)
{
return first->el;
}
template <class TE>
void CStack<TE>::Show(void)
{
CItem <TE> *it = first;
while (it) //!=NULL
{
cout << (it->el) << " ";
it = it->next;
}
}
#endif
Файл stack. cpp не нужен.
mystack. cpp
------------
#include "stdafx. h"
#include "stack. h"
#include <iostream. h>
int main(int argc, char* argv[])
{
CStack<int> s;
s. Push(10.8);
s. Push(20.8);
s. Push(30.8);
s. Push(40.8);
s. Show();
int i;
try
{
i = s. Pop();
cout << i;
i = s. Pop();
cout << i;
i = s. Pop();
cout << i;
i = s. Pop();
cout << i;
i = s. Pop(); //при 5-ом вызове Pop - исключение - переход на catch
cout << i; //эти команды выполняться не будут
i = s. Pop(); //
cout << i; //
i = s. Pop(); //
cout << i; //
}
catch (char * p)
{
cout << "Произошло исключение: ";
cout << p;
}
CStack<double> s2;
s2.Push(10.8);
s2.Push(20.8);
s2.Show();
cin >> i;
return 0;
}
// struct. cpp : Главный файл программы
//
#include "stdafx. h"
#include "spisok. h"
int main(int argc, char* argv[])
{
SStud * first1=0;
SStud * first2=0;
SStud st1; SStud st2; SStud st3; SStud st4;
SStud st5; SStud st6;
st1.next = st2.next = st3.next = st4.next = st5.next = st6.next = 0;
ChangeFamAndName(&st1, "Ivanov", "Ivan");
ChangeFamAndName(&st2, "Petrov", "Petr");
ChangeFamAndName(&st3, "Nikolov", "Nikita");
ChangeFamAndName(&st4, "Leonov", "Lev");
ChangeFamAndName(&st5, "Kalinin", "Niola");
ChangeFamAndName(&st6, "Martov", "Evgeniy");
first1 = AddNewToEnd(first1, &st1);
first1 = AddNewToEnd(first1, &st2);
first1 = AddNewToEnd(first1, &st3);
first2 = AddNewToBegin(first2, &st4);
first2 = AddNewToEnd(first2, &st5);
first2 = AddNewToBegin(first2, &st6);
ShowSpisok(first1);
ShowSpisok(first2);
return 0;
}
//-----------------------------------------------------------
//Это файл spisok. h
struct SStud
{
char Fam[20], Name[20];
SStud * next;
};
SStud * AddNewToEnd(SStud * first, SStud * ns);
SStud * AddNewToBegin(SStud * first, SStud * ns);
void ChangeFamAndName(SStud * st, char * Fam, char * Nam);
void AddNewAfter(SStud * first, SStud * st, SStud * ns);
void ShowSpisok(SStud * first);
//-----------------------------------------------------------
//Это файл spisok. cpp
#include "stdafx. h"
#include "spisok. h"
#include "string. h"
#include "iostream. h"
SStud * FindEnd(SStud * first)
{
if (!first) return 0;
SStud * s=first;
while(s->next)
{
s=s->next;
}
return s;
}
SStud * AddNewToEnd(SStud * first, SStud * ns)
{
SStud * se = FindEnd(first);
if (se)
se->next = ns;
else
first = ns;
return first;
}
SStud * AddNewToBegin(SStud * first, SStud * ns)
{
ns->next = first;
first = ns;
return first;
}
void ChangeFamAndName(SStud * st, char * Fam, char * Nam)
{
strncpy(st->Fam, Fam,
(strlen(Fam) <= strlen(st->Fam))?
strlen(Fam)+1:strlen(st->Fam)+1);
strncpy(st->Name, Nam,
(strlen(Nam) <= strlen(st->Name))?
strlen(Nam)+1:strlen(st->Name)+1);
}
void AddNewAfter(SStud * first, SStud * st, SStud * ns)
{
SStud *s = st->next;
st->next = ns;
ns->next = s;
}
void ShowSpisok(SStud * first)
{
cout << endl << "---------------------------- begin" << endl;;
SStud * s = first;
do
{
cout << s->Fam << " " << s->Name << endl;
s = s->next;
}
while (s);
cout << "---------------------------- end--" << endl;
}
Деревья
Дерево — это совокупность элементов, называемых вершинами, или узлами, связанных между собой отношениями вида «родитель – сын». Отношения отображаются в виде линий, которые называются рёбрами, или ветвями дерева. Узел дерева, не имеющий предков, называется корнем дерева, а узлы, не имеющие потомков, называются листьями дерева.
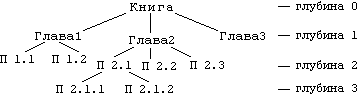
Деревья обычно отображаются по уровням. На нулевом уровне находится корень дерева, на первом – его сыновья, на втором – сыновья этих сыновей и т. д. Уровень каждого элемента называется также его глубиной, а количество уровней в дереве называется глубиной дерева. Дерево называется бинарным (двоичным), если каждый его узел имеет максимум двух сыновей.
Приведем ряд примеров деревьев.
Пример 1. Дерево глав и пунктов книги.
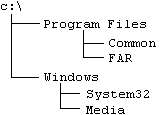
Пример 2. Дерево папок на диске.
Пример 3. Дерево разбора выражения a+b*c.
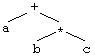
Дерево, приведенное в примере 3, является бинарным, поскольку операции + и * – бинарные. Каждый узел этого дерева, не являющийся листом, содержит знак операции, а два операнда данной операции являются сыновьями этого узла. Сын является либо листом и тогда представляет переменную, либо корнем поддерева. Например, сыновьями узла, содержащего операцию +, являются операнд a и операнд b*c, который также представляется в виде дерева.
Из примеров мы видим, что деревья имеют рекурсивную природу. Действительно, любой узел дерева либо является листом, либо имеет сыновей, каждый из которых является корнем поддерева. Приведем другое, рекурсивное определение дерева:
Дерево ::= <пусто>
│ Корень СписокПоддеревьев
СписокПоддеревьев ::= <пусто>
│ Дерево СписокПоддеревьев
Порядки обхода деревьев
Как обойти дерево, посетив каждый его узел один раз?
Имеется несколько стандартных вариантов обхода деревьев. Все определения будем давать для произвольного дерева, состоящего из корня К и n поддеревьев ![]() , и для бинарного дерева, используя для иллюстрации дерево разбора выражения a+b*c:
, и для бинарного дерева, используя для иллюстрации дерево разбора выражения a+b*c:
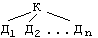
Заметим, что все порядки обхода формулируются как рекурсивные процедуры, что отражает рекурсивность определения самого дерева.
1) Инфиксный порядок обхода.
Для произвольного дерева. Вначале обходится первое поддерево в инфиксном порядке, затем корень и затем – остальные поддеревья в инфиксном порядке:
Д1 K Д2 ... Дn
Для бинарного дерева. Левое поддерево в инфиксном порядке, корень, правое поддерево в инфиксном порядке:
a + b * c
2) Префиксный порядок обхода.
Для произвольного дерева. Вначале обходится корень, а потом все поддеревья в префиксном порядке:
К Д1 Д2 ... Дn
Для бинарного дерева. Корень, левое поддерево в префиксном порядке, правое поддерево в префиксном порядке:
+ a * b c
3) Постфиксный порядок обхода.
Для произвольного дерева. Вначале обходятся все поддеревья в постфиксном порядке, потом корень:
Д1 Д2 ... Дn К
Для бинарного дерева. Левое поддерево в постфиксном порядке, правое поддерево в постфиксном порядке, корень:
a b c * +
Отметим, что порядок обхода бинарного дерева разбора выражения соответствует форме записи этого выражения: при инфиксном обходе дерева получаем инфиксную форму, при префиксном — префиксную, при постфиксном — постфиксную.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
