


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Удаление элемента из БДП
Удаление элемента из БДП является самым сложным из рассматриваемых алгоритмов. Возможны три случая.
a) Требуется удалить лист.
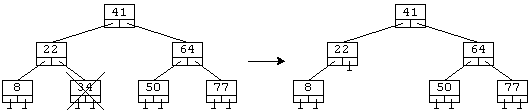
Удаляем лист и указателю, который на него указывал, присваиваем 0.
б) Требуется удалить элемент, который имеет только одно поддерево.
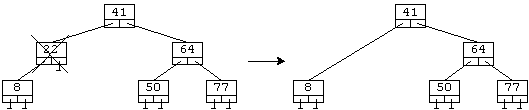
Запоминаем адрес единственного поддерева этого элемента, удаляем сам элемент, после чего указателю, который на него указывал, присваиваем адрес поддерева. Очевидно, при подобном удалении дерево остается БДП.
в) Требуется удалить элемент, у которого есть левое и правое поддеревья.
Вначале найдем этот элемент, используя рекурсию. Он является корнем некоторого поддерева, и сам имеет левое и правое поддеревья.
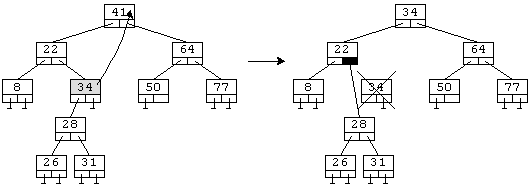
Пусть в дереве, изображенном на рисунке, требуется удалить элемент со значением 41. Вначале найдем элемент, значение которого непосредственно предшествует значению корневого элемента. Таковым является самый правый элемент в левом поддереве корня (на рисунке это элемент со значением 34). Перепишем значение этого элемента в корневой, после чего удалим этот элемент. Заметим, что поскольку он – самый правый в левом поддереве, то у него нет правого поддерева. Следовательно, для его удаления достаточно присвоить указателю, ранее указывавшему на него, адрес его левого поддерева.
Можно привести еще один, симметричный предыдущему, алгоритм удаления: чтобы удалить элемент с двумя поддеревьями, достаточно найти самый левый элемент в его правом поддереве (значение которого непосредственно следует за данным), и перед удалением переписать его значение в исходный.
Приведем рекурсивную процедуру удаления элемента из БДП.
void FindAndDelMostRight(Node ** p)
{
Node * v;
if ((*p)->right!=0)
FindAndDelMostRight((*p)->right)
else
{
r->data=(*p)->data;
v=*p;
*p=(*p)->left;
delete v;
}
}
void Delete(DataType x; PNode & r)
{
PNode v;
if (r==0) return;
if (x<r->data)
Delete(x, r.left)
else if (x>r->data)
Delete(x, r.right)
else if (r. left==0) && (r. right==0) // случай а)
{
Dispose(r);
r:=0;
}
else if (r. left==0) // случай б)
{
v=r;
r=r->right;
Dispose(v);
}
else if (r. right==0) then // случай б)
{
v=r;
r=r->left;
Dispose(v);
}
else FindAndDelMostRight(r->left); // случай в)
}
Случай в) реализуется здесь локальной процедурой FindAndDelMostRight(p), удаляющей в дереве с корнем p самый правый элемент. Вначале эта процедура рекурсивно ищет такой элемент, опускаясь вправо по ветвям дерева. Если движение вправо уже невозможно, значит, мы нашли самый правый элемент и p является ячейкой, хранящей его адрес (она выделена черным прямоугольником на последнем рисунке). Теперь достаточно присвоить значение найденного элемента корневому, изменить указатель p на левое поддерево удаляемого элемента и удалить элемент, на который указывает p.
Класс «Множество» на базе бинарного дерева поиска
Основные операции при работе с множеством – это добавление, удаление элемента и проверка элемента на принадлежность к множеству. Используем делегирование, реализовав множество с помощью бинарного дерева поиска, соответствующие операции для которого мы рассмотрели в предыдущем пункте.
Пусть операции с БДП целых описаны в модуле IntBST. Тогда реализация класса множества DataSet в модуле IntSet имеет вид:
unit IntSet;
interface
uses IntBST;
type
DataSet = class
private
root: PNode;
public
constructor Create;
destructor Destroy;
procedure Include(x: DataType); // добавить элемент
procedure Exclude(x: DataType); // удалить элемент
function Contains(x: DataType): boolean; //принадлежит ли
//элемент множеству
end;
implementation
constructor DataSet. Create;
begin
root:=nil;
end;
destructor DataSet. Destroy;
begin
IntBST. Destroy(root);
end;
procedure DataSet. Include(x: DataType);
begin
IntBST. Add(x, root);
end;
procedure DataSet. Exclude(x: DataType);
begin
IntBST. Delete(x, root);
end;
function DataSet. Contains(x: DataType): boolean;
begin
Result := BST. Search(x, root)<>nil;
end;
end.
Хеширование. Хеш-таблицы
Хеширование – это способ хранения данных, обеспечивающий быстрый поиск и добавление элементов. Суть его состоит в следующем. Каждому элементу, для которого осуществляется поиск или добавление, ставится в соответствие целое число, называемое его хеш-значением или хеш-кодом (англ. hash — перемешивание). Тем самым все возможные элементы разбиваются на группы (классы эквивалентности). К одной группе (одному классу эквивалентности) относятся элементы с одним хеш-значением.
При поиске вначале вычисляется хеш-значение элемента, после чего этот элемент ищется только среди элементов с тем же самым хеш-значением. Например, при поиске слова в английском словаре мы вначале определяем его первую букву (хеш-значение слова), после чего ищем его только среди слов на эту букву, в результате чего поиск на первом же шаге сокращается примерно в 26 раз (количество букв в латинском алфавите). Добавление осуществляется аналогично: вычисляется хеш-значение добавляемого элемента, после чего он добавляется в группу элементов с таким же хеш-значением.
Совокупность элементов, сгруппированных по их хеш-значениям, называется хеш-таблицей. Функция, сопоставляющая элементу его хеш-значение, называется хеш-функцией. Обычно в качестве хеш-функции целого числа x используется следующая функция: Hash(x)=x mod N, где N — число, определяющее количество классов эквивалентности (рекомендуется выбирать N простым числом).
Наиболее наглядным способом хранения хеш-таблиц является массив списков. Элементы массива нумеруются от 0 до N-1 и представляют собой списки, при этом i-й список хранит элементы с хеш-значением, равным i. Так организованная таблица называется хеш-таблицей с открытым хешированием. Схематически она изображена на следующем рисунке:
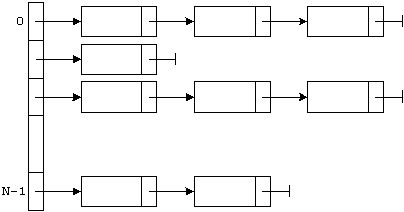
Заметим, что если в списках находится примерно равное количество элементов, то поиск одинаково эффективен для всех возможных значений. Например, пусть N=1001 и в каждом списке максимум 3 элемента, а во всей хеш-таблице — 2048 элементов. Тогда после вычисления хеш-значения элемента последовательный поиск в списке с этим номером потребует максимум три итерации. Бинарный же поиск потребует 11 итераций (![]() ).
).
Если количество элементов в разных списках отличается значительно, то эффективность хеширования падает. Самый плохой случай — если один список содержит все элементы, а остальные списки — пустые. Для поиска в этом случае может потребоваться 2048 итераций. Поэтому следует стремиться к тому, чтобы хеш-функция хорошо перемешивала элементы, заполняя хеш-таблицу как можно более равномерно для любых значений (отсюда и название метода — хеширование, т. е. перемешивание). В частности, именно поэтому число N стремятся выбирать простым.
Реализуем хеш-таблицу целых в виде класса на основе динамического массива списков. Поскольку список обеспечивает удаление элемента, наша хеш-таблица будет также позволять удалять элементы.
uses IntList;
const sz = MaxInt div sizeof(List);
type
PArr = ^Arr;
Arr = array [0..sz-1] of List;
HashTable = class
private
a: PArr;
N: integer;
public
constructor Create(nn: integer);
destructor Destroy;
function Hash(x: DataType); integer;//хеш-функция элемента x
procedure Include(x: DataType);
procedure Exclude(x: DataType);
procedure Contains(x: DataType): boolean;
end;
constructor HashTable. Create(nn: integer);
var i: integer;
begin
N:=nn;
GetMem(a, N*sizeof(List));
for i:=0 to N-1 do
a^[i]:=List. Create;
end;
destructor HashTable. Destroy;
var i: integer;
begin
for i:=0 to N-1 do
a^[i].Destroy;
FreeMem(a);
end;
function HashTable. Hash(x: integer); integer;
begin
Result:=x mod N;
end;
procedure HashTable. Include(x: integer);
begin
if not Has(x) then
a^[Hash(x)].AddLast(x);
end;
procedure HashTable. Exclude(x: integer);
begin
a^[Hash(x)].Remove(x);
end;
function HashTable. Contains(x: integer): boolean;
begin
Result:=a^[Hash(x)].Find(x);
end;

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
