


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Имеется несколько важных классов бинарных деревьев. Бинарное дерево называется идеально сбалансированным, если для каждого его узла количество узлов в левом и правом поддеревьях отличается максимум на единицу. Бинарное дерево называется полным, если все его уровни полностью заполнены. Нетрудно подсчитать, что количество узлов в полном бинарном дереве глубины k составляет ![]() .
.
Приведем примеры идеально сбалансированных деревьев:





Из них полными являются первое, третье и последнее.
Для создания бинарного дерева в программе потребуется следующая структура, определяющая узел дерева:
struct Node
{
DataType data;
Node *left,*right;
}
Здесь left и right – указатели на левое и правое поддерево, DataType – описанный ранее тип, для которого определены операции сравнения =, >, <. Если в дереве целые числа, то можно использовать тип int. Нам потребуется также функция NewNode, возвращающая узел дерева с заполненными полями:
Node * NewNode(DataType x, Node * left, Node * right)
{
Node * node = new Node;
node->data:=x;
node->left:=left;
node->right:=right;
return node;
};
Приведем решения нескольких задач на бинарные деревья. Все они имеют простые рекурсивные решения, что является следствием рекурсивной природы определения дерева.
Задача 1. Создать идеально сбалансированное дерево с n узлами, заполненными случайными значениями.
Решение. Для решения создадим корень дерева, и рекурсивно создадим его левое и правое поддеревья, которые являются идеально сбалансированными и содержат n/2 и n-n/2 – 1 узлов соответстванно.
Node * CreateTree(int n)
{
if (n==0)
return 0;
else
return NewNode(rand(100), CreateTree(n/2),
CreateTree(n - n/2 - 1));
end;
Очевидно, полученное дерево идеально сбалансировано, поскольку количество узлов в поддеревьях отличается максимум на 1 и поддеревья идеально сбалансированы.
Задача 2. Разрушить бинарное дерево.
Решение. Если дерево пусто, то оно уже разрушено, в противном случае следует разрушить левое поддерево, затем правое поддерево и, наконец, корень:
void Destroy(Node * r);
{
if (r==0) return;
Destroy(r->left);
Destroy(r->right);
delete r;
}
Задача 3. Выдать узлы бинарного дерева в инфиксном порядке.
Решение. По определению инфиксного обхода, если дерево непустое, то надо вначале обойти его левое поддерево в инфиксном порядке, затем корень и, наконец, правое поддерево в инфиксном порядке. При обходе корня следует вывести его поле данных:
void InfixPrintTree(Node * r)
{
if (r==0) return;
InfixPrintTree(r->left);
cout << r->data << ' ';
InfixPrintTree(r->right);
}
Очевидно, если в последних трех операторах поместить оператор вывода на первое место, то мы получим вывод дерева в префиксном порядке, если на последнее, то в постфиксном.
Задача 4. Дано бинарное дерево. Найти его глубину.
Решение. Глубина дерева на единицу больше максимальной глубины его поддеревьев. Поскольку глубина дерева из одного элемента равна 0, то естественно считать глубину пустого дерева равной -1.
int TreeDepth(Node * r)
{
if (r==0) return -1;
else return max(TreeDepth(r. left),TreeDepth(r. right))+1;
}
Обратим внимание, что во всех задачах глубина рекурсии совпадает с глубиной дерева. Более того, если вызов подпрограммы представлять в виде узла дерева и считать его сыновьями рекурсивные вызовы подпрогрмм, то множество всех рекурсивных вызовов образует дерево. Этот факт подчеркивает тесную связь деревьев и рекурсии.
Бинарные деревья поиска (БДП)
Бинарное дерево называется бинарным деревом поиска (БДП, BST – Binary Search Tree), если значение каждого его узла не меньше значений узлов левого поддерева и не больше значений узлов правого поддерева.
Ниже на рисунке изображено полное бинарное дерева поиска глубины 3:
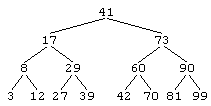
БДП обладают одним замечательным свойством: при их обходе в инфиксном порядке мы получаем неубывающую последовательность. Так, инфиксный обход дерева, приведенного на рисунке, даст следующую последовательность:
3 8 12 17 27 29 39 41 42 60 70 73 81 90 99
Оценим количество операций при добавлении в БДП. Мы знаем, что в полном дереве с k уровнями количество элементов n = ![]() . Очевидно, если дерево близко к полному (в частности, если оно идеально сбалансировано), то
. Очевидно, если дерево близко к полному (в частности, если оно идеально сбалансировано), то ![]() , следовательно, количество уровней
, следовательно, количество уровней ![]() . Например, при n = 1024 элемента глубина хорошо сбалансированного дерева близка к 10. Поскольку при каждом рекурсивном шаге операции добавления мы спускаемся вниз по дереву на один уровень и делаем одну операцию, глубина рекурсии и количество операций при добавлении равны глубине дерева k, т. е. составляют примерно
. Например, при n = 1024 элемента глубина хорошо сбалансированного дерева близка к 10. Поскольку при каждом рекурсивном шаге операции добавления мы спускаемся вниз по дереву на один уровень и делаем одну операцию, глубина рекурсии и количество операций при добавлении равны глубине дерева k, т. е. составляют примерно ![]() .
.
На алгоритме добавления в БДП основана очень эффективная сортировка деревом. В ней используется свойство БДП выдавать отсортированную последовательность при инфиксном обходе. Алгоритм такой сортировки прост: в первоначально пустое БДП с повторяющимися элементами добавляем все элементы с помощью процедуры Add, после чего выдаем все элементы, обходя дерево в инфиксном порядке. Если в процессе добавления дерево остается сбалансированным, то при добавлении в него n элементов количество операций составляет примерно 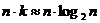 . Ровно такая оценка была получена в алгоритме быстрой сортировки; для произвольных данных улучшить эту оценку нельзя.
. Ровно такая оценка была получена в алгоритме быстрой сортировки; для произвольных данных улучшить эту оценку нельзя.
При выводе этой оценки мы исходили из того, что БДП является достаточно сбалансированным. Это не всегда так. Например, при добавлении возрастающей последовательности элементов каждый следующий элемент добавляется в правое поддерево листа и дерево вырождается в список:
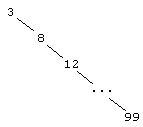
Это – самый плохой случай: количество операций при вставке имеет порядок n, а не ![]() , поэтому количество операций в алгоритме сортировки деревом составляет примерно
, поэтому количество операций в алгоритме сортировки деревом составляет примерно ![]() .
.
Однако в среднем (если данные случайны и добавляются в случайном порядке) количество операций при сортировке деревом составляет примерно 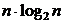 . Отметим также, что мы получили компактный рекурсивный алгоритм сортировки всего с одним циклом (!), совпадающий по оценке количества операций с одним из самых производительных алгоритмов сортировки – быстрой сортировкой:
. Отметим также, что мы получили компактный рекурсивный алгоритм сортировки всего с одним циклом (!), совпадающий по оценке количества операций с одним из самых производительных алгоритмов сортировки – быстрой сортировкой:
r:=nil;
for i:=1 to 10 do
Add(r);
InfixPrintTree(r);
Основные операции при работе с БДП
Основными операциями при работе с БДП являются добавление, удаление и поиск элемента. Все указанные операции реализуются рекурсивно.
Добавление элемента в БДП
При добавлении элемента в дерево возможно несколько ситуаций. Если дерево пусто, то элемент необходимо добавить в его корень. В противном случае, если значение элемента меньше значения поля данных в корне, элемент необходимо добавить в левое поддерево, а если больше, то в правое поддерево:
void Add(DataType x, Node ** r)
{
if (*r==0)
*r:=NewNode(x,0,0);
else if (x < (*r)->data)
Add(x, &(r->left));
else if (x > (*r)->data)
Add(x, &(r->right));
}
Заметим, что после добавления элемента дерево остается деревом поиска. Заметим также, что при таком алгоритме добавления мы получим БДП без повторяющихся элементов. Чтобы получить БДП с повторяющимися элементами, достаточно удалить отрезок кода if (x>(*r)->data)
Поиск элемента в БДП
Поиск в БДП осуществляется по той же схеме, что и добавление. Пусть ищется элемент со значением x. Если дерево пусто, то элемент не найден. Если значение x совпадает со значением корневого элемента, то элемент найден. Если значение x меньше значения корневого элемента, то рекурсивно ищем x в левом поддереве, а если больше, то в правом поддереве. В случае успешного поиска будем возвращать указатель на элемент, в противном случае будем возвращать 0:
Node * Search(DataType x, Node * r)
{
if (r==0)
return 0;
else if (r->data==x)
return r;
else if (r->data<x)
return Search(x, r->right);
else return Search(x, r->left);
}

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
