

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Основные понятия математической статистики
вариационный ряд (статистический закон распределения случайной величины) | набор пар случайной выборки {xi, wi} (или {xi, ni}), в котором варианты ранжированы (см. «ранжирование») | |
вероятность события А | Классическое определение вероятности: P(A)=m/n, где n — число всех исходов опыта, m – число исходов, благоприятствующих событию A. Статистическое определение вероятности: | |
дискретная случайная величина | случайная величина, чьи значения могут быть заранее перечислены | |
дисперсия случайной величины | число, равное математическому ожиданию (среднему) случайной величины (X – M(X))2, или | |
закон распределения случайной величины | всякое соотношение, устанавливающее связь между возможными значениями случайной величины ( | |
математическая статистика | дисциплина, изучающая методы оценивания и сравнения распределений случайных величин и их характеристик по наблюдениям случайных величин | |
математическое ожидание |
- аналог среднего арифметического; для непрерывной случайной величины - интеграл от произведения ее значений х на плотность распределения вероятностей | |
медиана | варианта, находящаяся в середине ранжированного ряда распределения. Медиана делит ряд на две равные (по числу единиц) части – со значениями меньше медианы и со значениями больше медианы. | |
мода | величина (варианта), которая наиболее часто встречается в случайной выборке, т. e. это варианта, имеющая наибольшую частоту | |
непрерывная случайная величина | случайная величина, чьи значения не могут быть заранее перечислены и непрерывно заполняют некоторый промежуток | |
объем выборки | количество опытных данных в выборке | |
нормальный закон распределения (закон Гаусса). | предельный закон, к которому приближаются другие законы распределения при весьма часто встречающихся типичных условиях; плотность распределения для этого закона определяется выражением
| |
полигон распределения (полигон частот) | графическое изображение вариационного ряда – ломаная линия, соединяющая точки с координатами {xi, w}i ({xi, ni}) | |
ранжирование случайной выборки | упорядочивание элементов выборки по возрастанию. | |
распределение генеральной совокупности | закон распределения случайной величины | |
репрезентативная выборка | выборка, которая правильно представляет пропорции генеральной совокупности, т. е. элементы генеральной совокупности отбирались в выборку равновероятным образом | |
случайная величина | величина (событие), которая в результате опыта может принять то или иное значение, каких именно заранее неизвестно | |
случайная выборка | последовательность значений случайной величины | |
случайное событие | событие, которое в данном опыте может произойти, а может и не произойти. | |
среднее выборочное вариационного ряда | среднее арифметическое значений случайной выборки: | |
«трех сигм» правило | практически достоверно, что отклонения от центра нормально распределенной величины будут меньше утроенного значения | |
частота i-й варианты | число повторений i–ой варианты в случайной выборке; относительная частота i-ой варианты в выборке (статистическая вероятность) - |
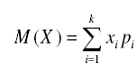 для дискретной случайной величины: сумма произведений всех ее возможных значений
для дискретной случайной величины: сумма произведений всех ее возможных значений 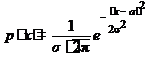 , где σ и а – некоторые параметры распределения (константы).
, где σ и а – некоторые параметры распределения (константы).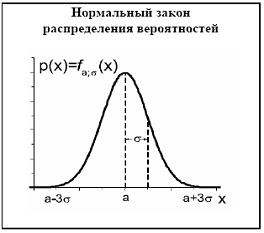
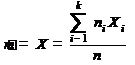
Статистические функции
Расчет неизвестных параметров распределения случайной величины в электронных таблицах MS EXCEL (OpenOffice CALC).
Введите Ваши статистические данные в столбец А электронных таблиц.
В предположении, что данная неизвестная величина распределена по нормальному закону, неизвестные параметры распределения этой величины можно посчитать следующим образом:
1. Расчет среднего значения случайной величины (оценка математического ожидания): функция СРЗНАЧ (или AVERAGE) (Вставка/Функция/СРЗНАЧ из категории «Статистические»). В поле аргумента «Число1» введите ваш диапазон данных из столбца А.
2. Расчет среднеквадратического (стандартного) отклонения случайной величины: функция СТАНДОТКЛОН (STDEV) (Вставка/Функция/ СТАНДОТКЛОН из категории «Статистические»). В поле аргумента «Число1» введите ваш диапазон данных из столбца А.
3. Расчет доверительного интервала. В свободную ячейку введите функцию ДОВЕРИТ (CONFIDENCE) (Вставка/Функция/ ДОВЕРИТ из категории «Статистические»). Альфа — это уровень значимости используемый для вычисления уровня надежности. Уровень надежности равняется 100*(1 - альфа) процентам, или, другими словами, альфа равное 0,05 означает 95-процентный уровень надежности.
4. В поле «Станд_откл» введите адрес ячейки с рассчитанным ранее стандартным отклонением. В поле «Размер» введите количество данных из столбца А.
Нижняя граница интервала:
Среднее значение минус полученная с помощью функции «ДОВЕРИТ» величина.
Верхняя граница интервала:
Среднее значение плюс полученная с помощью функции «ДОВЕРИТ» величина.
5. Для нахождения коэффициента корреляции :
Функция КОРРЕЛ (CORREL) (из категории «статистические»).
В качестве исходных массивов выбираются 2 ряда данных из 1 и 2 столбцов таблицы.
Прочие статистические функции:
РАНГ (RANK) — вычисляет ранг значений в выборке
МАКС (MAX) - вычисляет максимальное значение из списка аргументов
МИН (MIN) - вычисляет минимальное значение из списка аргументов
СЧЕТ (COUNT) — подсчитывает количество числовых значений в диапазоне, игнорирую иные типы данных (для расчета объема выборки)
СТЬЮДРАСПОБР (TINV) - таблица коэффициентов Стьюдента. Вычисляет t(b,k).
МЕДИАНА (MEDIAN)-вычисляет медиану заданных чисел. Медиана — это число, которое является серединой множества чисел, то есть половина чисел имеют значения большие, чем медиана, а половина чисел имеют значения меньшие, чем медиана.
МОДА (MODE)- вычисляет наиболее часто встречающееся или повторяющееся значение в массиве или интервале данных. Как и функция МЕДИАНА, функция МОДА является мерой взаимного расположения значений.
Альтернативой может стать обращение к средствам анализа данных. Они доступны через команду Анализ данных меню Если этой команды нет в меню, необходимо загрузить надстройку Пакет анализа в меню Сервис. Исчерпывающую информацию о неизвестных параметрах распределения даст Описательная статистика. Это средство анализа служит для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
